LLMs之Pretrained:《Training Language Models via Neural Cellular Automata》翻译与解读
导读 :这篇论文证明了"合成结构"也能教会模型通用能力:作者用 NCA 生成可控的非语言合成数据,先让模型学习更纯粹的规则与依赖,再接入自然语言预训练,结果不仅提升语言建模效率,还能迁移到数学、代码和推理任务;其中最重要的启示是,合成数据的价值不在于替代语义本身,而在于为模型提供更高质量、可定制的计算结构。
>> 背景痛点:
● 高质量自然语言数据正在逼近瓶颈:论文指出,大模型预训练高度依赖自然语言,但高质量文本是有限资源,而且获取与清洗成本高。
● 自然语言自带偏置,且知识与推理纠缠:作者认为,自然语言数据不仅包含人类偏见,还把事实知识、推理过程与表达形式混杂在一起,不利于把"学到的能力"拆分出来研究。
● 传统合成数据往往不够"像真实世界":既有算法合成数据在语言领域较少见,且很多方法生成的分布过窄、同质性过强,难以在匹配 token 预算下超过自然语言训练。
● 仅靠规模堆数据并不一定最优:论文强调,合成数据的有效性不只是"更多",而是取决于数据生成器的结构性质与复杂度是否匹配目标域。
>> 具体的解决方案:
● 用神经元胞自动机(NCA)生成非语言合成数据:作者提出用 NCA 这种可参数化、可控、可大规模生成的动力系统,作为 LLM 的"预预训练"数据来源。
● 采用"合成先行、自然语言随后"的两阶段框架:先在 NCA 动态上做 pre-pre-training,再进行标准自然语言 pre-training,从而让模型先学到更通用的计算原语,再去吸收语义。
● 显式控制 NCA 复杂度,做面向任务的分布设计:论文提出可通过 gzip 可压缩性、状态空间大小等方式调节 NCA 复杂度,以便针对 web text、math、code 等不同下游域进行匹配。
● 把 NCA 视作"学习计算规律"的训练底座:作者的核心假设是,LLM 重要能力来自结构而非语义本身,因此让模型预测 NCA 轨迹,可以迫使其学习长程依赖、局部规则和潜在计算过程。
>> 核心思路步骤:
● 构造具有丰富时空结构的 NCA 轨迹:NCA 通过神经网络参数化更新规则,可生成长程时空模式,并呈现类似自然语言的重尾、Zipf 风格统计特征。
● 按复杂度区间采样训练数据:作者不是简单随机取样,而是根据复杂度带筛选 NCA 轨迹,比较不同压缩率/复杂度对应的迁移效果。
● 先做 NCA 预预训练,再转入自然语言预训练:模型先用 next-token prediction 学习 NCA 序列,再进入 OpenWebText、OpenWebMath、CodeParrot 等自然语言语料的常规预训练。
● 用困惑度、收敛速度和下游 pass@ 评估迁移:论文主要用验证 perplexity、达到最终 perplexity 所需 token 数、以及 GSM8K/HumanEval/BigBench-Lite 的 pass 准确率来衡量效果。
● 分析"什么在驱动迁移":作者通过重置部分权重来判断哪些模块携带迁移信号,并进一步研究数据复杂度与下游任务的匹配关系。
>> 优势:
● 样本效率高:仅用 164M NCA tokens,论文就报告了下游语言建模性能最高提升约 6%,并且加速收敛最高可达 1.6 倍。
● 甚至能超过更多自然语言数据的预预训练:令人意外的是,NCA 预预训练在部分设置下,甚至优于使用 1.6B tokens 的自然语言 C4 预预训练,且计算量还更高。
● 收益可迁移到推理任务:论文报告,这种收益不仅体现在困惑度上,也能转移到 GSM8K、HumanEval、BigBench-Lite 等推理/代码基准。
● 训练更快、更稳定:在多个模型规模和多种语料上,NCA 预预训练都能持续优于 scratch、Dyck 与 C4 基线,并表现出更快的收敛。
● 可做领域定制化设计:因为 NCA 的复杂度可调,作者认为它给了训练分布一个新旋钮,可以按目标域的计算特征去定制合成数据。
>> 结论和观点(侧重经验与建议):
● 迁移成立的关键不是"像不像语言",而是"像不像可学习的结构":作者认为,模型之所以能从 NCA 迁移到语言,是因为 NCA 提供了更纯粹的规则归纳信号,而不是依赖语义内容本身。
● 注意力层是最可迁移的组件:实验显示,重置 attention 权重会带来最大退化,说明 attention 更像通用的依赖追踪与隐式规则推断载体。
● MLP 更偏向存储域特定统计:论文发现,MLP 和 LayerNorm 的迁移效果更依赖源域与目标域是否对齐;当两者差异较大时,保留这些参数甚至可能干扰学习。
● 最优复杂度是"任务依赖"的,不是一刀切:OpenWebText 更偏好更复杂、低可压缩的 NCA 规则,而 CodeParrot 则更适合中等复杂度;这说明合成数据需要按目标域调参,而不是统一使用同一分布。
● 不是数据越多越好,而是匹配得越好越有效:论文明确指出,迁移效果并不随 NCA 数据量单调增长,过高复杂度或不匹配的分布也可能让收益 plateau。
● NCA 更像是"预预训练底座",不是语义学习的终点:作者把这一框架定义为通往"全合成预训练"的早期原型,但也承认最终语义获取仍可能需要有限且精选的自然语言数据。
● 当前仍有边界与开放问题:论文指出,NCA 目前更适合作为 pre-pre-training 信号;要成为自然语言预训练的完整替代,还需要解决更大 alphabet、不同复杂度区间下的性能平台期问题。
目录
[《Training Language Models via Neural Cellular Automata》翻译与解读](#《Training Language Models via Neural Cellular Automata》翻译与解读)
[Figure 1:Overview of NCA Pre-pre-training to Language Pre-training. We pre-pre-train a transformer with next-token prediction on the dynamics of neural cellular automata (NCA) sampled from selected complexity regions. We then conduct standard pre-training on natural language corpora. NCA pre-pre-training improves both validation perplexity and convergence speed on language pre-training. Interestingly, the optimal NCA distribution varies by downstream domain.图 1:NCA 预预训练到语言预训练的概述。我们先在从选定复杂度区域采样的神经元细胞自动机(NCA)动态上对一个变压器进行下一个标记预测的预预训练。然后在自然语言语料库上进行标准预训练。NCA 预预训练提高了语言预训练的验证困惑度和收敛速度。有趣的是,最优的 NCA 分布因下游领域而异。](#Figure 1:Overview of NCA Pre-pre-training to Language Pre-training. We pre-pre-train a transformer with next-token prediction on the dynamics of neural cellular automata (NCA) sampled from selected complexity regions. We then conduct standard pre-training on natural language corpora. NCA pre-pre-training improves both validation perplexity and convergence speed on language pre-training. Interestingly, the optimal NCA distribution varies by downstream domain.图 1:NCA 预预训练到语言预训练的概述。我们先在从选定复杂度区域采样的神经元细胞自动机(NCA)动态上对一个变压器进行下一个标记预测的预预训练。然后在自然语言语料库上进行标准预训练。NCA 预预训练提高了语言预训练的验证困惑度和收敛速度。有趣的是,最优的 NCA 分布因下游领域而异。)
[6 Discussion](#6 Discussion)
[Why should we expect transfer?为何我们应期待迁移?](#Why should we expect transfer?为何我们应期待迁移?)
[Why is 160M tokens of automata better than 1.6B tokens of text?为什么 1.6 亿个自动机标记比 160 亿个文本标记更好?](#Why is 160M tokens of automata better than 1.6B tokens of text?为什么 1.6 亿个自动机标记比 160 亿个文本标记更好?)
[Limitations and open problems局限性和开放性问题](#Limitations and open problems局限性和开放性问题)
《Training Language Models via Neural Cellular Automata》翻译与解读
|------------|--------------------------------------------------------------------------------------------------------------|
| 地址 | 论文地址:https://arxiv.org/abs/2603.10055 |
| 时间 | 2026年03月09日 |
| 作者 | 麻省理工学院(MIT)、Improbable AI实验室(Improbable AI Lab) |
Abstract
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Pre-training is crucial for large language models (LLMs), as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs--training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training. Website: https://hanseungwook.github.io/blog/nca-pre-pre-training/ Code: https://github.com/danihyunlee/nca-pre-pretraining | 对于大型语言模型(LLM)来说,预训练至关重要,因为大多数表示和能力都是在这一阶段获得的。然而,自然语言预训练存在一些问题:高质量文本有限,包含人类偏见,并且将知识与推理混杂在一起。这引发了一个根本性的问题 :自然语言是通向智能的唯一途径吗?我们提出使用神经元细胞自动机(NCA) 生成合成的非语言数据,用于大型语言模型的预预训练------先在合成数据上训练,然后再在自然语言上训练。NCA 数据具有丰富的时空结构和类似于自然语言的统计特性,同时可控且易于大规模生成。我们发现,仅在 1.64 亿个 NCA 令牌上进行预预训练,就能使下游语言建模性能提高多达 6%,并使收敛速度加快多达 1.6 倍。令人惊讶的是,这甚至优于在 16 亿个来自 Common Crawl 的自然语言令牌上进行预预训练,尽管后者使用了更多的计算资源。这些改进也转移到了推理基准测试中,包括 GSM8K、HumanEval 和 BigBench-Lite。在探究驱动迁移的因素时,我们发现注意力层的迁移性最强,并且最优的 NCA 复杂度因领域而异:代码受益于更简单的动态机制,而数学和网络文本则倾向于更复杂的机制。这些结果使得针对目标领域对合成分布进行系统性调整成为可能。更广泛地说,我们的工作为实现具有完全合成预训练的更高效模型开辟了一条道路。 网站:https://hanseungwook.github.io/blog/nca-pre-pre-training/ 代码:https://github.com/danihyunlee/nca-pre-pretraining |
Figure 1:Overview of NCA Pre-pre-training to Language Pre-training. We pre-pre-train a transformer with next-token prediction on the dynamics of neural cellular automata (NCA) sampled from selected complexity regions. We then conduct standard pre-training on natural language corpora. NCA pre-pre-training improves both validation perplexity and convergence speed on language pre-training. Interestingly, the optimal NCA distribution varies by downstream domain.图 1:NCA 预预训练到语言预训练的概述。我们先在从选定复杂度区域采样的神经元细胞自动机(NCA)动态上对一个变压器进行下一个标记预测的预预训练。然后在自然语言语料库上进行标准预训练。NCA 预预训练提高了语言预训练的验证困惑度和收敛速度。有趣的是,最优的 NCA 分布因下游领域而异。
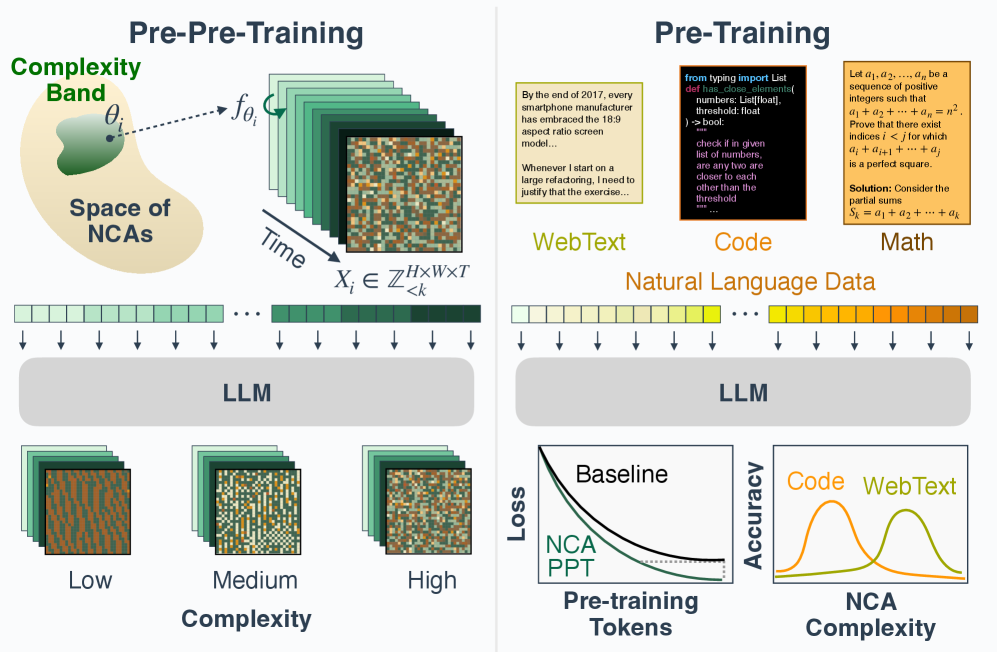
1、Introduction
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Scale has transformed neural networks, enabling emergent abilities like reasoning (Jaech et al., 2024; Jiang, 2023; Austin et al., 2021) and in-context learning (Brown et al., 2020; Wei et al., 2022; Zhao et al., 2024) in large language models (LLMs). However, neural scaling laws predict that continued improvements require exponentially more data (Kaplan et al., 2020), which is nearing exhaustion by 2028 (Villalobos et al., 2022). Furthermore, natural language inherits many undesirable human biases and needs tedious data curation and cleaning before it is used for training foundation models (Han et al., 2025a; An et al., 2024). This raises a fundamental question: Is natural language the only path to learning useful representations? In this paper, we explore an alternative path to using synthetic data from cellular automata. Our core hypothesis is that the emergence of reasoning and other abilities in LLMs relies on the underlying structure of natural language, rather than its semantics. Text is a lossy record of human cognition and the world it describes, containing diverse kinds of structure, from reasoning traces to procedural instructions (Ribeiro et al., 2023; Ruis et al., 2024; Cheng et al., 2025; Delétang et al., 2024). Next-token prediction on such data pressures models to internalize the latent computational processes that support coherent continuations, fostering key capabilities of intelligence (Delétang et al., 2023; Jiang, 2023). | 规模改变了神经网络,使大型语言模型(LLMs)具备了诸如推理(Jaech 等人,2024 年;Jiang,2023 年;Austin 等人,2021 年)和上下文学习(Brown 等人,2020 年;Wei 等人,2022 年;Zhao 等人,2024 年)等新能力。然而,神经网络规模法则预测,持续改进需要呈指数级增长的数据(Kaplan 等人,2020 年),而到 2028 年,这种数据将接近枯竭(Villalobos 等人,2022 年)。此外,自然语言继承了许多不良的人类偏见,在用于训练基础模型之前,需要进行繁琐的数据整理和清理(Han 等人,2025a;An 等人,2024 年)。这引发了一个根本性的问题:自然语言是学习有用表示的唯一途径吗?在本文中,我们探索了一条使用元胞自动机合成数据的替代路径。 我们的核心假设是,LLMs 中推理和其他能力的出现依赖于自然语言的底层结构,而非其语义。文本是对人类认知及其所描述的世界的一种有损记录,包含多种结构,从推理痕迹到程序指令(Ribeiro 等人,2023 年;Ruis 等人,2024 年;Cheng 等人,2025 年;Delétang 等人,2024 年)。在这样的数据上进行下一个标记预测,迫使模型内化支持连贯延续的潜在计算过程,从而培养出智能的关键能力(Delétang 等人,2023 年;Jiang,2023 年)。 |
| If the key ingredient is exposure to various structures rather than language semantics, then richly structured non-linguistic data could also be effective for teaching models to reason. To investigate this hypothesis, we employ algorithmically generated synthetic data from neural cellular automata (NCA) (Mordvintsev et al., 2020) as a synthetic training substrate. NCA generalize systems like Conway's Game of Life (Gardner, 1970) by replacing fixed dynamics rules with neural networks and can be used to generate diverse data distributions with spatially local rules. This produces long-range spatio-temporal patterns (see Figure 1) of arbitrary sizes that exhibit heavy-tailed, Zipfian token distributions (see Figure 8 in Appendix A) reminiscent of natural data. Crucially, we propose a method to explicitly control the complexity of NCA, enabling systematic tuning of the synthetic data distribution for optimal transfer to downstream domains. Prior work on synthetic pre-training has explored approaches like generating random strings with a recurrent network (Bloem, 2025) and simple algorithmic tasks (Wu et al., 2022; Shinnick et al., 2025a), but they have yet to match or outperform language training under matched token budgets. We hypothesize this is because such synthetic distributions are narrow and homogeneous, lacking certain key properties that characterize natural language. NCAs address this gap. The parametric structure of NCA yields diverse dynamics and allows systematic control over complexity. This enables us to ask not only whether synthetic data can transfer, but what structural properties make it effective. | 如果关键因素是接触各种结构而非语言语义,那么结构丰富的非语言数据也可能有效地教会模型进行推理。为了探究这一假设,我们采用神经元细胞自动机(NCA)(Mordvintsev 等人,2020 年)生成的算法合成数据作为合成训练基质。NCA 通过用神经网络取代固定的动态规则,对诸如康威生命游戏(Gardner,1970 年)之类的系统进行了推广,并且能够生成具有局部空间规则的多种数据分布。这会产生任意大小的长程时空模式(见图 1),其标记分布呈现出重尾、齐普夫分布(见附录 A 中的图 8),与自然数据类似。关键的是,我们提出了一种方法来明确控制 NCA 的复杂性,从而能够系统地调整合成数据的分布,以实现向下游领域的最佳迁移。此前关于合成预训练的工作探索了诸如使用循环网络生成随机字符串(Bloem,2025)以及简单的算法任务(Wu 等人,2022;Shinnick 等人,2025a)等方法,但它们尚未在匹配的标记预算下达到或超越语言训练的效果。我们推测这是因为这些合成分布狭窄且同质,缺乏某些表征自然语言的关键特性。NCA 解决了这一差距。NCA 可以弥补这一空白。NCA 的参数化结构产生了多样的动态变化,并允许对复杂性进行系统控制。这使我们不仅能探究合成数据是否可以迁移,还能探究是什么样的结构特性使其有效。 |
| We adopt a pre-pre-training framework: an initial phase of training on NCA dynamics that precedes standard pre-training on natural language (Hu et al., 2025b). Our ultimate vision is to pre-train entirely on clean synthetic data, followed by fine-tuning on a limited and curated corpora of natural language to acquire semantics (Han et al., 2025a). The pre-pre-training framework serves as an early prototype of this paradigm, allowing us to measure how computational primitives learned from synthetic NCA transfer to language tasks. Our contributions are as follows: 1. A synthetic pre-pre-training substrate that transfers to language and reasoning. We propose neural cellular automata (NCA) as a fully algorithmic, non-linguistic data source for pre-pre-training. NCA pre-pre-training improves downstream language modeling by up to 6% and converges up to 1.6× faster across web text, math, and code. These perplexity gains transfer to reasoning across benchmarks including GSM8K, HumanEval, and BigBench-Lite. Surprisingly, it outperforms pre-pre-training on natural language (C4), even with more data and compute. 2. Synthetic pre-training enables domain-targeted data design. We find that the optimal NCA complexity regime varies by downstream task: code benefits from lower-complexity rules while math and web text benefit from higher-complexity ones. NCAs' parametric structure offers a new lever for efficient training: tuning the complexity of training distributions to match the computational character of target domains. 3. Attention captures the most transferable priors. The attention layers capture the most useful computational primitives, accounting for the majority of the transfer gains. Attention appears to be a universal carrier of transferable capabilities such as long-range dependency tracking and in-context learning, whereas MLPs encode more domain-specific knowledge--making MLP transfer conditional on alignment between the synthetic and target domains. | 我们采用了一种预预训练框架:在标准的自然语言预训练之前,先对 NCA 动态进行初始训练(Hu 等人,2025b)。我们的最终愿景是完全在干净的合成数据上进行预训练,然后在有限且经过精心挑选的自然语言语料库上进行微调以获取语义(Han 等人,2025a)。预预训练框架是这一范式的早期原型,使我们能够衡量从合成 NCA 学习到的计算原语如何迁移到语言任务中。我们的贡献如下: 1. 一种可迁移到语言和推理的合成预预训练基质。我们提出神经细胞自动机(NCA)作为预预训练的完全算法化、非语言的数据源。NCA 预预训练可将下游语言建模性能提高多达 6%,并且在网页文本、数学和代码方面收敛速度提高多达 1.6 倍。这些困惑度的提升在包括 GSM8K、HumanEval 和 BigBench-Lite 在内的多个基准测试中的推理任务上都有所体现。令人惊讶的是,它甚至在使用更多数据和计算资源的情况下,也超过了对自然语言(C4)进行预训练的效果。 2. 合成预训练能够实现针对特定领域的数据设计。我们发现,最优的 NCA 复杂度范围因下游任务而异:代码任务受益于较低复杂度的规则,而数学和网络文本任务则受益于较高复杂度的规则。NCA 的参数化结构为高效训练提供了一个新的杠杆:通过调整训练分布的复杂度来匹配目标领域的计算特性。3.注意力机制捕捉到了最具迁移性的先验知识。注意力层捕获了最有用的计算原语,占据了大部分迁移收益。注意力机制似乎是诸如长程依赖追踪和上下文学习等可迁移能力的通用载体,而多层感知机(MLP)则编码了更多特定领域的知识------这使得 MLP 的迁移依赖于合成域和目标域之间的对齐。 |
6 Discussion
Why should we expect transfer?为何我们应期待迁移?
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic "shortcuts" or co-occurrence priors (Abbas et al., [2023](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Geirhos et al., [2020](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). In contrast, every NCA sequence is generated by a hidden transition rule -- parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., [2022](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). This mirrors a core capability required for language modeling (Brown et al., [2020](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Wei et al., [2022](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Dong et al., [2024](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). Xie et al. ([2022](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., [2023](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Cook et al., [2025](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., [2025b](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Wu et al., [2022](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Shinnick et al., [2025b](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, [2012](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)), some of which realize Turing-complete systems (Rendell, [2002](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。); Wolfram & Gad-el Hak, [2003](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., [2024](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)) that applies across the function class. | NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义"捷径"或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的------该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 |
| This framing is supported by our mechanistic finding from Section [5.3.1](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。): attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., [2022](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)) showed that ICL ability emerges with the formation of induction heads -- attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., [2026](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, [2025](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. ([2026](#NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020). In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022). This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024). Xie et al. (2022) show that training on natural text teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025). Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b) also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024) that applies across the function class. NCA 数据与自然语言有显著差异,并且由确定性过程生成,这引发了为何应期待迁移的问题?我们认为,NCA 可能为上下文中的规则推理提供更纯粹的训练信号。在自然语言中,模型可能会依赖语义“捷径”或共现先验知识(Abbas 等人,2023;Geirhos 等人,2020)。相比之下,每个 NCA 序列都是由一个隐藏的转换规则生成的——该规则由一个随机神经网络参数化。由于没有语义知识可依赖,每个 NCA 标记都引导模型进行上下文中的规则推理(Kirsch 等人,2022)。 这反映了语言建模所需的核心能力(Brown 等人,2020;Wei 等人,2022;Dong 等人,2024)。Xie 等人(2022)表明,在自然文本上进行训练会使模型学会对潜在概念进行隐式贝叶斯推理:每个序列都从一个潜在概念中抽取,预测下一个标记意味着基于推断出的概念进行条件化。同样的机制在数学和代码中也存在(Garg 等人,2023;Cook 等人,2025)。先前关于形式语言和算法任务(如迪克语言和字符串复制)(胡等人,2025b;吴等人,2022;希尼克等人,2025b)的研究也针对这种上下文推理进行了训练。与这些任务不同,NCA 包含了一个广泛通用的可计算函数类别(科佩兰,2012),其中一些实现了图灵完备系统(伦德尔,2002;沃尔夫勒姆和加德-埃尔哈克,2003)。这种分布的广度和规模使得记忆变得不可行,迫使模型学习一种适用于整个函数类别的通用规则推理机制(李等人,2024)。 This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022) showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains. A secondary motivation for transfer is epiplexity (Finzi et al., 2026). Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025), thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026) show that deterministic processes can generate useful structural information–coined epiplexity–that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着“归纳头”的形成而出现——这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是“表观复杂性”(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息——称为“表观复杂性”——模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。)) show that deterministic processes can generate useful structural information--coined epiplexity--that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well. | 这种框架得到了我们在第 5.3.1 节中的机制性发现的支持:注意力层,而非多层感知机(MLP)或层归一化(LayerNorm),承载着最具可迁移性的结构。(奥尔森等人,2022)表明,上下文学习(ICL)能力随着"归纳头"的形成而出现------这些注意力电路有助于将信息从前一个标记复制到后续标记。由于 NCA 预训练专门奖励这种行为,它可能比仅语言预训练更早且更稳健地形成这种结构。实际上,转移的注意力权重就是上下文学习电路,这些电路随后会针对下游任务和领域进行调整。 迁移的另一个动机是"表观复杂性"(Finzi 等人,2026 年)。经典信息理论表明,确定性变换无法增加信息量(Polyanskiy 和 Wu,2025 年),这让人质疑大型语言模型能否从非确定性细胞自动机(NCA)中学习到有意义的结构。然而,这种观点假定观察者具有无限的计算能力。对于计算能力有限的观察者而言,Finzi 等人(2026 年)表明,确定性过程可以生成有用的结构信息------称为"表观复杂性"------模型必须将其内化,才能学习到数据的有用表示。他们的关键见解在于,像细胞自动机这样的简单局部规则可以产生涌现结构(例如滑翔机、碰撞),有限容量的模型无法通过暴力模拟来实现。相反,模型必须学习一种表示,使其能够在更粗粒度的抽象层面上预测模拟结果。在像 NCA 这样多样且通用的函数类上学习这些表示,可能有助于学习自然语言的表示。 |
Why is 160M tokens of automata better than 1.6B tokens of text? 为什么 1.6 亿个自动机标记比 160 亿个文本标记更好?
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure [2](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。). How can abstract dynamical systems' data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., [2022](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。)) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., [2023](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。); Chen et al., [2023](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。)). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. | 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 |
| In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., [2023](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。)) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In [Figure 6](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。), we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., [2025](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。)), richer long-range dependencies for genomic sequences (Wu et al., [2025](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。))), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., [2025](#Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself? Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022) that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023). With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly. 令人惊讶的是,尽管标记预算显著降低,但先在 NCA 数据上进行预训练比在自然语言(C4)上进行预训练更能提升语言模型,如图 2 所示。为什么抽象动态系统的数据能比语言本身更好地迁移到语言模型中? 即使在 160 亿个标记的情况下,自然语言的预训练仍处于早期训练阶段。计算最优缩放定律表明(Hoffmann 等人,2022 年),一个 160 亿参数的模型大约需要 3200 亿个标记。在这个早期阶段,语言模型主要获取浅层、局部模式,而更复杂的结构则在后期才学习(Evanson 等人,2023 年;Chen 等人,2023 年)。 由于标记有限,C4 预训练可能将大部分容量用于这些表面规律,而非能广泛迁移的长程依赖和上下文学习。 In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic. Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023) in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations. Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025), richer long-range dependencies for genomic sequences (Wu et al., 2025)), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025) that are more efficient to train and deploy—trained not on more data, but on better-matched data. 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效——不是通过更多的数据,而是通过更匹配的数据进行训练。)) that are more efficient to train and deploy---trained not on more data, but on better-matched data. | 相比之下,我们假设 NCA 序列能为上下文学习提供更纯粹的训练信号。每个序列都是由单个潜在规则生成的,模型必须从上下文中推断出该规则并始终如一地应用。一旦确定下来,下一个标记的预测就几乎成为确定性的了。 此外,NCA 预训练引入了一种与额外语言标记所提供的多样性相垂直的形式。尽管许多自然语言数据集规模庞大,但它们在语言模式和主题覆盖方面存在大量冗余(Abbas 等人,2023)。由于我们的每个 NCA 序列都代表了一个独特的函数来建模,这种多样性可能在每个标记上更有效地构建通用表示。 超越一刀切的预训练 我们的复杂度消融实验揭示了一个微妙的情况,即训练的最佳分布因下游领域而异。在图 6 中,我们观察到代码受益于低复杂度的 NCA 规则,而网络文本和数学则受益于高复杂度的规则,这表明这些领域编码了具有明显不同特征的计算。这开辟了一个新的控制维度。我们不再将训练数据视为固定不变的,而是可以调整合成数据的结构以匹配目标领域。与基于语法的合成任务不同,在基于语法的合成任务中,每个形式语法都定义了一个具有固定结构复杂度的任务,而神经计算架构(NCAs)在单个生成器家族内提供了连续且可调的复杂度范围。如果研究人员能够设计出体现特定领域所需基本要素的分布(例如,代码所需的刚性状态跟踪(Li 等人,2025 年),基因组序列所需的更丰富的长程依赖关系(Wu 等人,2025 年)),他们就能够直接注入这些能力,而无需扩展到数万亿个通用标记。其结果可能有助于开发专门的小型语言模型(Belcak 等人,2025 年),这些模型在训练和部署方面更高效------不是通过更多的数据,而是通过更匹配的数据进行训练。 |
Limitations and open problems局限性和开放性问题
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| A key question is whether NCA data can serve not only as a pre-pre-training signal, but as a scalable substitute for natural language pre-training. For larger alphabet sizes (n=10,15), we observe a reverse U-shaped trend: downstream improvement is optimal up to an intermediate token budget but plateaus beyond it. This behavior nonetheless reinforces our central thesis: effective synthetic pre-training depends critically on structural choices in the data generator, not merely on scale. This points to a key open problem for future work: developing principled methods to guide synthetic generators to sample structures that match those of target domains. Our complexity results demonstrate that such matching matters, but gzip compressibility and alphabet size are only two lens on complexity. Complexity is multifaceted: a sequence can be compressible yet be rich in long-range dependencies, or vice versa. Characterizing which axes of complexity (e.g., size of NCA network, grid size, or epiplexity) matter for which domains and learning to sample synthetic data accordingly could unlock fully synthetic pre-training at scale. NCA represents one point in the vast space of possible synthetic data generators. The key insight from our work is not that NCA specifically is optimal, but that structured synthetic data with appropriate complexity characteristics can provide meaningful pre-training signal even without any linguistic content. The question is no longer whether synthetic pre-training can work, but how to design synthetic data distributions that maximize what models learn. | 一个关键问题是,NCA 数据能否不仅作为预训练的信号,还能作为一种可扩展的替代方案来取代自然语言预训练。对于更大的字母表大小(n=10,15),我们观察到一种倒 U 形趋势:下游性能的提升在达到一个中间的标记预算时达到最优,但超过这个预算后则趋于平稳。尽管如此,这种行为仍然强化了我们的核心论点:有效的合成预训练关键取决于数据生成器的结构选择,而不仅仅是规模。 这指向了未来研究的一个关键开放性问题:开发出有原则的方法来引导合成生成器采样出与目标领域结构相匹配的结构。我们的复杂性结果表明这种匹配很重要,但 gzip 压缩性和字母表大小只是复杂性的一个视角。复杂性是多方面的:一个序列可以是可压缩的,但又具有丰富的长程依赖关系,反之亦然。确定哪些复杂性维度(例如,NCA 网络的大小、网格大小或表征复杂性)对哪些领域重要,并据此学习采样合成数据,可能会解锁大规模的完全合成预训练。 NCA 代表了可能的合成数据生成器的广阔空间中的一个点。我们工作的关键见解不是 NCA 特别是最优的,而是具有适当复杂性特征的结构化合成数据即使没有任何语言内容也能提供有意义的预训练信号。问题不再是合成预训练是否可行,而是如何设计合成数据分布以最大化模型的学习效果。 |