一、 MoE架构 与 Dense架构对比
1. 1 MoE架构 概述
MOE 架构的基本思想是在传统 Transformer 模型中,将每个前馈网络(FFN)层替换为一个 MOE 层。一个 MOE 层通常由两个关键部分组成:
专家网络:这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干专家(例如4个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构。
门控网络:该模块负责根据输入token的特征动态选择激活哪些专家: 在下图中,"More"这个令牌可能被发送到第二个专家,而"Parameters"这个令牌被发送到第一个专家。
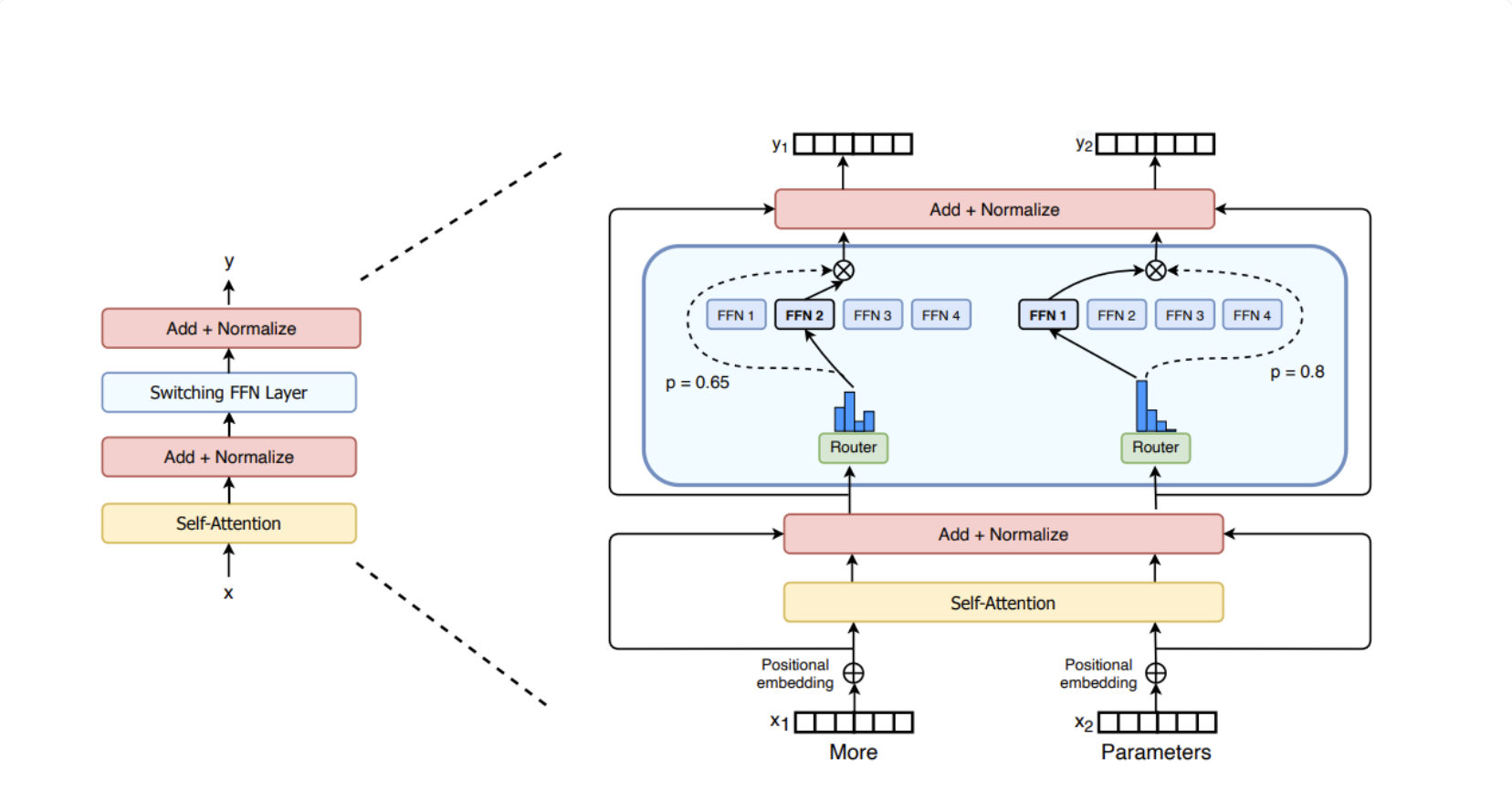
1 . 2 MoE 技术基础
1.2.1 专家网络角色
在 MOE 模型中,每个专家网络只在接收到相应路由时参与计算。初期,由于门控网络参数随机,各专家接收到的数据分布比较均匀;但随着训练进行,局部梯度更新使得某些专家逐渐专注于处理特定类型的输入数据。这种自发专化现象使得模型整体具备了多样化的表示能力。
尽管MoE架构有着很大潜力,但现有的MoE架构可能存在知识混杂(Knowledge Hybridity)和知识冗余(Knowledge Redundancy)的问题,限制了专家的专业化,具体如下:
知识混杂 :分配给特定专家的token可能会涵盖不同知识,知识混合问题出现在专家数量有限的场景下,容易阻碍专家们在特定领域进行深入。
知识冗余 :当MoE模型中的不同专家学习到相似的知识时,就会出现知识冗余,这与模型设计初衷相违背。
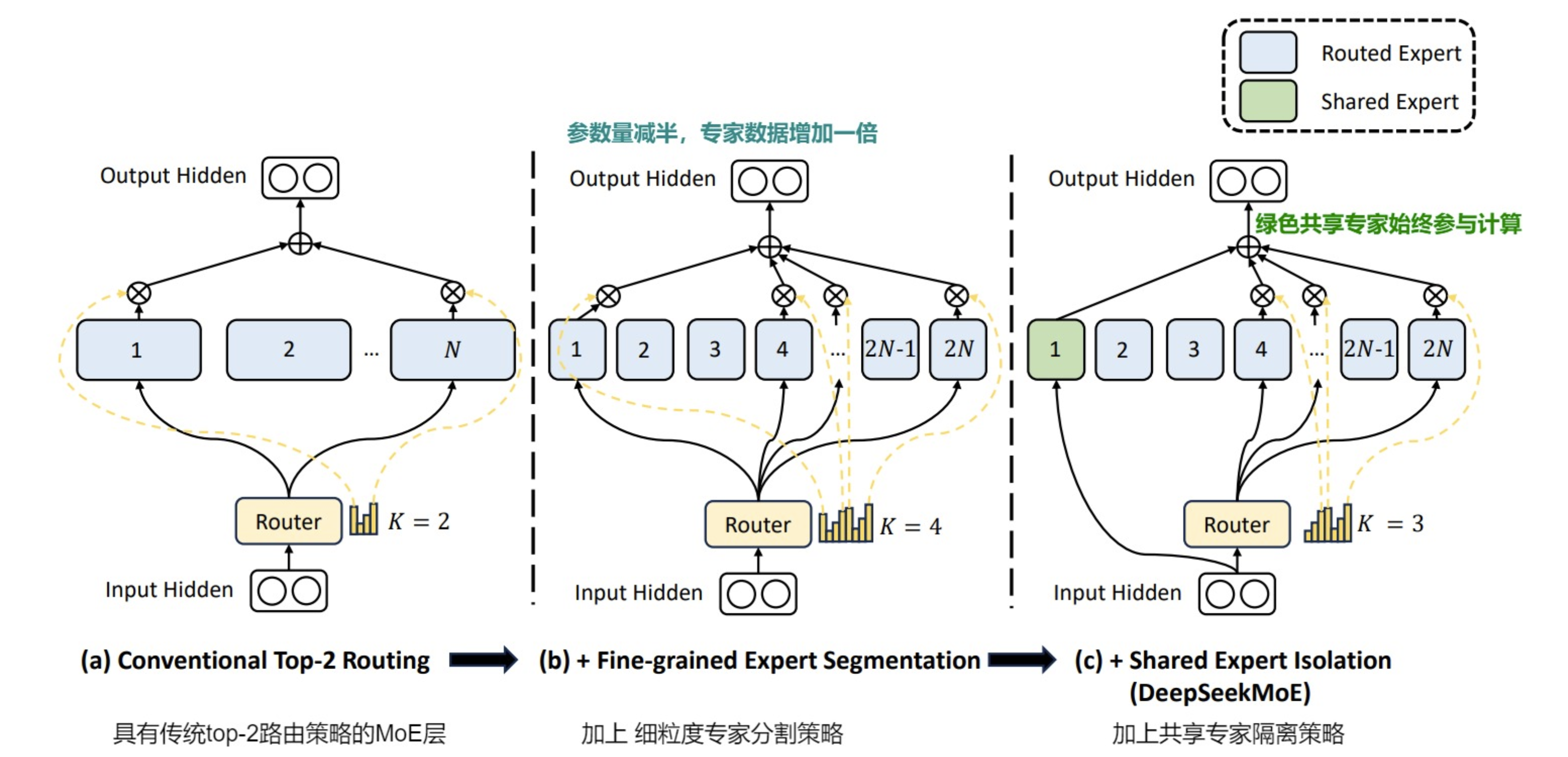
解决方案:引入共享专家和细粒度/垂类专家。
1. 2.2 门控网络机制
门控网络一开始的路由决策可能是近似随机的,但随着专家逐步积累专长,门控网络也会调整其路由策略。如果某个专家因早期获得较多特定类型数据而表现出色,门控网络便倾向于将更多此类数据路由给它。专家因接收到较多特定数据而"专长",而门控网络根据反馈不断更新参数,使得路由更加精准。
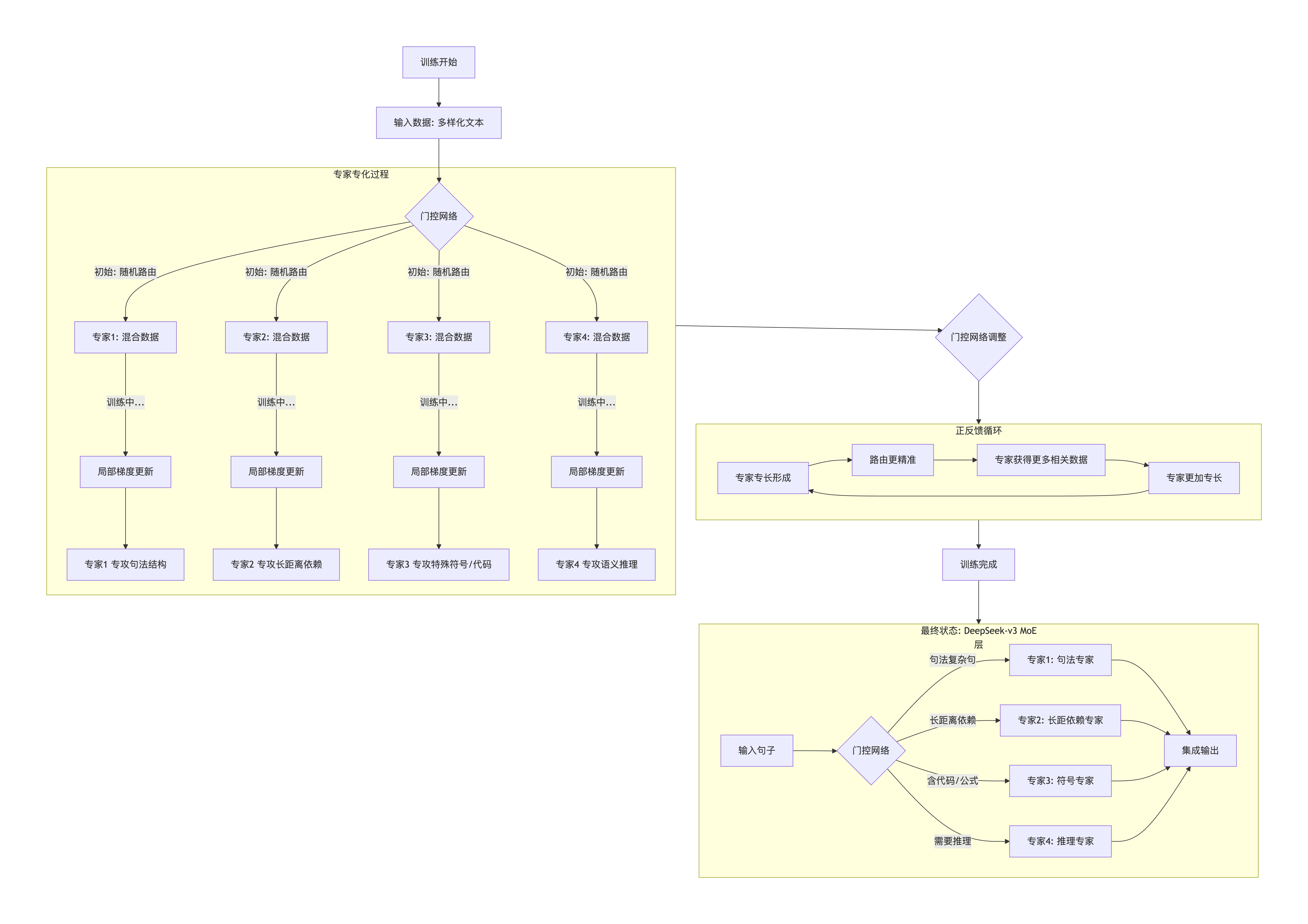
路由 编码 机制 (基于softmax)具体分为以下两种:软编码路由:每个输入token按概率权重分配给所有专家,输出是各专家处理结果的加权融合;硬编码路由:每个输入token仅分配给得分最高的k个专家(如top-2),其他专家完全不参与该token的处理。
1. 3 MoE 与 Dense 架构深度对比
|------------|------------------------------|----------------------------------|------------------------|
| | Dense架构(稠密模型) | MoE架构(稀疏模型) | 技术影响 |
| 激活机制 | 全激活:所有参数参与每次前向计算 | 稀疏激活:每层仅Top-k专家(通常k=1~2)参与计算 | MoE实现条件计算,显著降低计算复杂度 |
| 计算效率 | 计算量随模型规模线性增长: O(L·D²),D为隐藏维度 | 计算量由激活参数决定: O(L·k·E),E为专家规模 | 同等性能下,MoE可减少3~10倍计算量 |
| 显存占用 | 与模型参数量成正比 参数量 = 存储需求 | 存储-计算解耦:需加载所有专家权重,激活量仅占总量10~25% | MoE需更大显存存储参数,但计算时仅激活部分 |
| 推理延迟特性 | 延迟稳定可预测 与序列长度呈二次关系 | 延迟等于小模型 但权重加载可能成瓶颈 | MoE实际延迟受内存带宽制约明显 |
| 显存带宽需求 | 中等:权重加载一次,重复使用 | 极高:需频繁加载不同专家权重 Batch Size小时IO占比高 | MoE对高带宽内存(HBM)依赖性强 |
| 训练收敛动态 | 收敛曲线平滑稳定 需充足训练计算量 | 前期加速明显,专家快速专长化,但需负载均衡机制 | MoE在相同计算预算下可达到更低Loss |
| 可扩展上限 | 受限于单卡显存与计算单元 | 受限于总显存容量与通信带宽 | MoE通过稀疏性突破单设备算力限制 |
二、基于Megatron的MoE模型训练技术方案
2.1 训练框架
2.1.1 Megatron框架
Megatron框架是NVIDIA开发的高效分布式训练框架,专为大规模Transformer模型设计。结合MoE(Mixture of Experts)架构,可实现参数量超大规模而计算量可控的高效训练。本文档基于Megatron-swift开源训练框架进行MoE模型训练的技术要点、关键参数及实践。
2.1.2 Megatron-swift开源镜像环境
镜像环境:
关键依赖库:Megatron-LM、transformer_engine、mcore-bridge
2.2 分布式并行训练策略
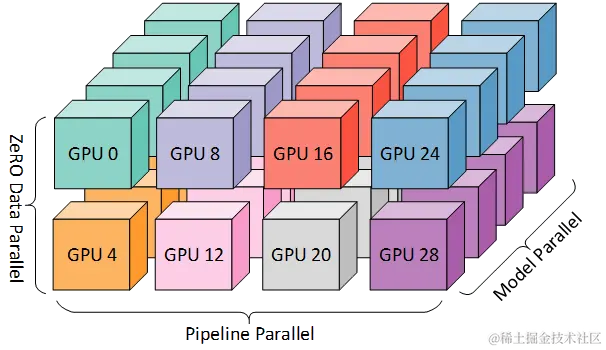
MoE模型训练通常需要3D并行策略(在基于deepspeed的开源训练框架llama-factory、ms-swift的训练均出现训练卡住的bug):
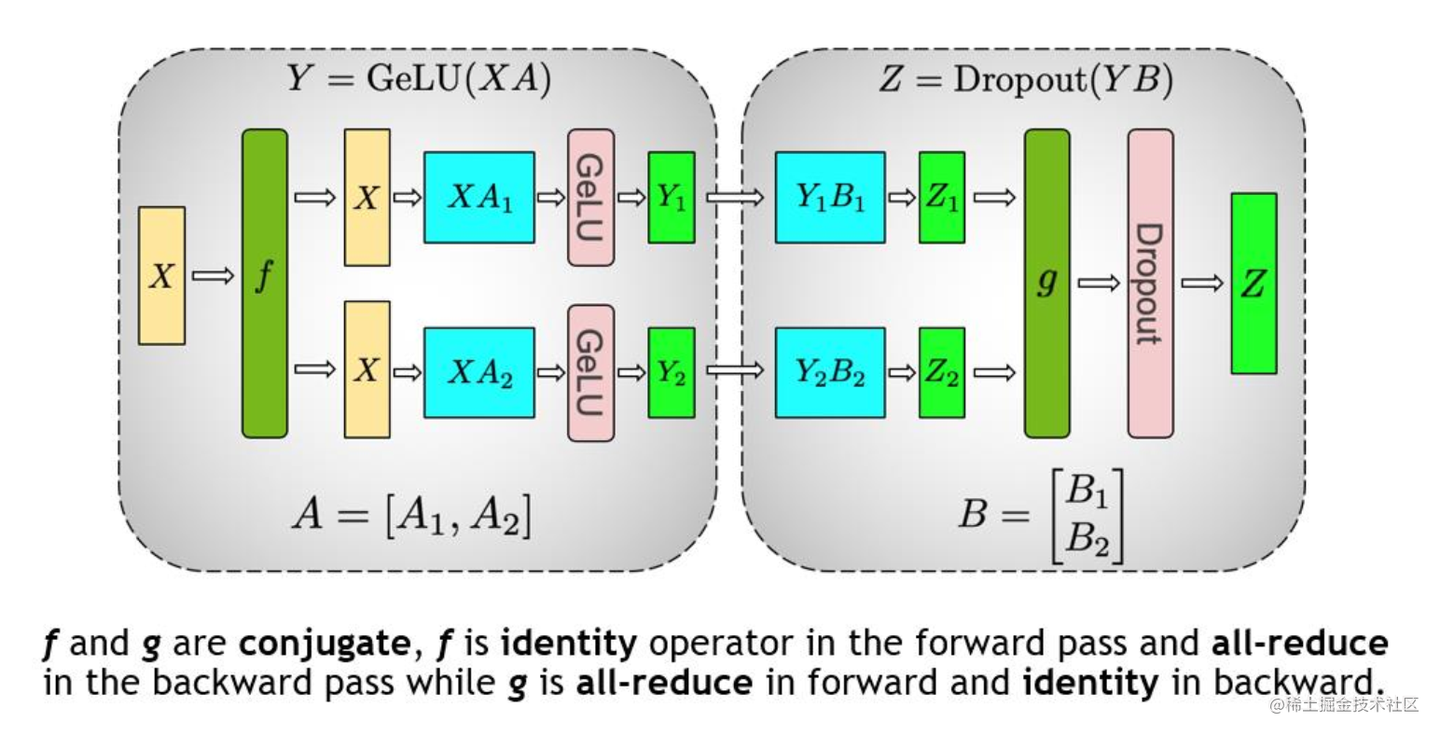
- 张量并行 (TP) : 张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)与列并行(Column Parallelism)。交叉进行维持通用矩阵的矩阵乘法,all-reduce作为集体通讯,从而将transformer层拆分到多个GPU。
tensor_model_parallel_size:模型张量并行度`
`expert_model_parallel_size:专家内部张量并行度,只对专家切分,上下游模型层张量不拆分`
`
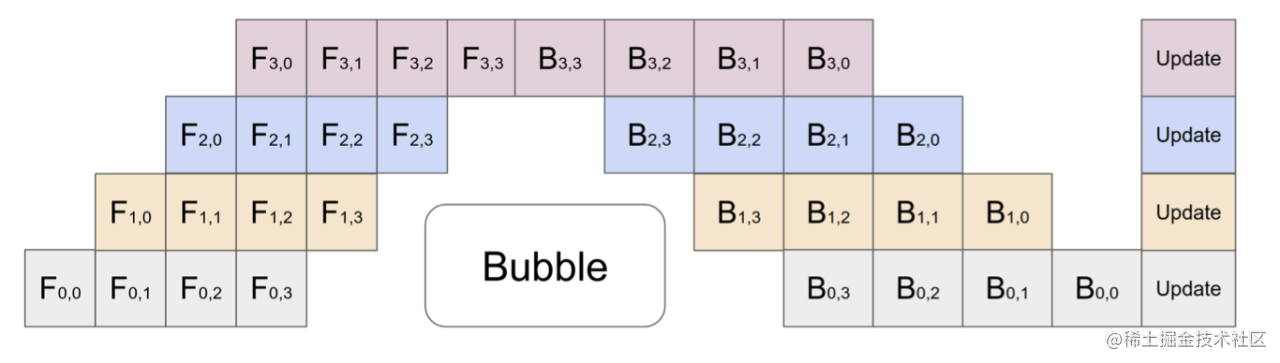
- 微批次流水线并行 (PP) :通过将传入的小批次(minibatch)分块为微批次(microbatch),并人为创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程,可以显著提升流水线并行设备利用率,减小设备空闲状态的时间。
pipeline_model_parallel_size : 流水线并行度`
`micro_batch_size:每个流水线的批次`
`
- 序列并行(SP):将输入序列在不同GPU上分片处理,只适用于长序列训练。
sequence_parallel:序列并行度`
`2.3 全局批次计算
数据并行度计算:数据并行大小 (DP) = 总GPU数 / (TP × PP × SP)。需注意TP × PP × SP不能超过gpu总数,另外PP的通信次数最短,参数尽可能大有利于训练加速。
global_batch_size/wbs:全局批次大小,等价于micro_batch_size*数据并行大小*梯度累加步数。`
`2.4 mcore模型权重格式
Mcore-Bridge兼容Dense/MoE/多模态等多种模型架构,将safetensors 格式的模型权重转换为mcore格式,让Megatron训练像transformers一样简单易用。
2.5 MoE特定训练优化技术
2.5.1 负载均衡训练
MoE训练中的负载不均衡是训练动力学的必然结果。即使初始差异极小,在正反馈循环的作用下,经过数十个训练批次的迭代,这些微小差异会指数级放大,最终导致严重的专家利用不均甚至模型尺寸退化。
为解决负载集中问题,我们在总损失函数中引入负载均衡约束:
L total = L main + λ⋅L aux
其中:
L main 是主任务损失(如交叉熵)
L aux 是辅助损失,专门惩罚负载不均衡
λ 是平衡权重,控制均衡约束的强度(通常设为0.001~0.0001或者0)
辅助损失函数为:
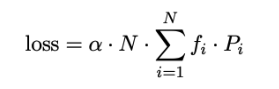
其中,f为各专家实际处理的token个数占比,P为各专家被路由选择的概率均值(通过门控函数计算),均衡时最小值为1.0。
moe_aux_loss_coeff: 默认为0,不使用aux_loss。通常情况下,该值设置的越大,训练效果越差,但MoE负载越均衡,请根据实验效果,选择合适的值。`
`moe_expert_capacity_factor: 专家容量因子,超出专家容量的 token 会基于其被选中的概率被丢弃。可以令训练负载均匀,提升训练速度,避免专家过载,sft微调中不建议使用,会有信息熵的损失。`
`如果是lora训练,需留意lora参数配置:
target_modules:可选'all-linear' 'all-router' 。目标模块all-linear: 所有线性层;all-router: MoE路由器`
`lora_rank:LoRA秩,注意要避免r过大导致路由层lora块参数比模型路由层参数还要大的情况。`
`2.5.2 计算-通信重叠优化
overlap_grad_reduce: 重叠梯度reduce操作,减少DP通信等待,建议开启。`
`overlap_param_gather: 重叠参数all-gather操作,减少优化器通信成本,建议开启。`
`tp_comm_overlap: 重叠TP通信与GEMM计算,建议开启。`
`moe_permute_fusion:启用token重排融合`
`moe_grouped_gemm:使用分组GEMM操作通过TransformerEngine优化多个专家同时计算`
`moe_shared_expert_overlap:共享专家计算与通信重叠`
`2.5.3 其他MoE参数默认配置
以下MoE参数默认与模型config配置一致即可:
num_experts: 专家数量`
`moe_layer_freq: MoE层与Dense层的分布频率`
`moe_router_topk: 每个token选择的专家数`
`moe_shared_expert_intermediate_size: 共享专家大小`
`moe_router_dtype: 路由计算数据类型moe_router_dtype 'fp32': 保持数值稳定性,尤其在专家数多时`
`- 训练案例
nl2sql-dsl的训练案例,大家可尝试修改模型和数据相关路径进行实践。
训练脚本路径:/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/examples/train/megatron/moe/qwen3_moe.sh
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True'` `\`
`NPROC_PER_NODE=8` `\`
`CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \`
`megatron sft \`
` --model_type qwen3_nothinking \`
` --model /AIOT-vePFS/sf_ModelZoo/Qwen3-30-A3B-2507 \`
` --load_safetensors true` `\`
` --save_safetensors true` `\`
` --merge_lora true` `\`
` --train_type lora \`
` --target_modules 'all-linear'` `\`
`'all-router'` `\`
` --lora_rank 64` `\`
` --lora_alpha 256` `\`
` --dataset '/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/dsl0_online_1027-1120.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/dsl0_v2_1120.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/dsl0_online_1027-1120.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/time_traindata.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/time_traindata.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/数据小精灵-20251103-1128eval-onlineresult-gptcheck_updated.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/数据小精灵-20251103-1128eval-onlineresult-gptcheck_updated.jsonl'` `\`
`'/AIOT-vePFS/sf_01441980/sf01441980/ms-swift/data/dsl/1218/ratio_traindata_v2.jsonl'` `\`
` --pipeline_model_parallel_size 2` `\`
` --expert_model_parallel_size 4` `\`
` --tensor_model_parallel_size 4` `\`
` --moe_permute_fusion true` `\`
` --moe_grouped_gemm true` `\`
` --moe_shared_expert_overlap true` `\`
` --moe_aux_loss_coeff 0` `\`
` --moe_shared_expert_overlap true` `\`
` --micro_batch_size 4` `\`
` --global_batch_size 256` `\`
` --packing false` `\`
` --log_interval 1` `\`
` --recompute_granularity full \`
` --recompute_method uniform \`
` --recompute_num_layers 1` `\`
` --max_epochs 3` `\`
` --finetune true` `\`
` --cross_entropy_loss_fusion true` `\`
` --lr 1e-6 \`
` --lr_decay_style cosine \`
` --lr_warmup_fraction 0.05` `\`
` --save /AIOT-vePFS/sf_LLM/Fengyu-LLM/models/dsl/dsl0-Qwen3-30-A3B-2507-1222-64r-aux-0 \`
` --save_interval 2000` `\`
` --max_length 8192` `\`
` --num_workers 8` `\`
` --dataset_num_proc 8` `\`
` --no_save_optim true` `\`
` --no_save_rng true` `\`
` --sequence_parallel true` `\`
` --attention_backend flash`
`