作者:TGE-Transaction

1.背景
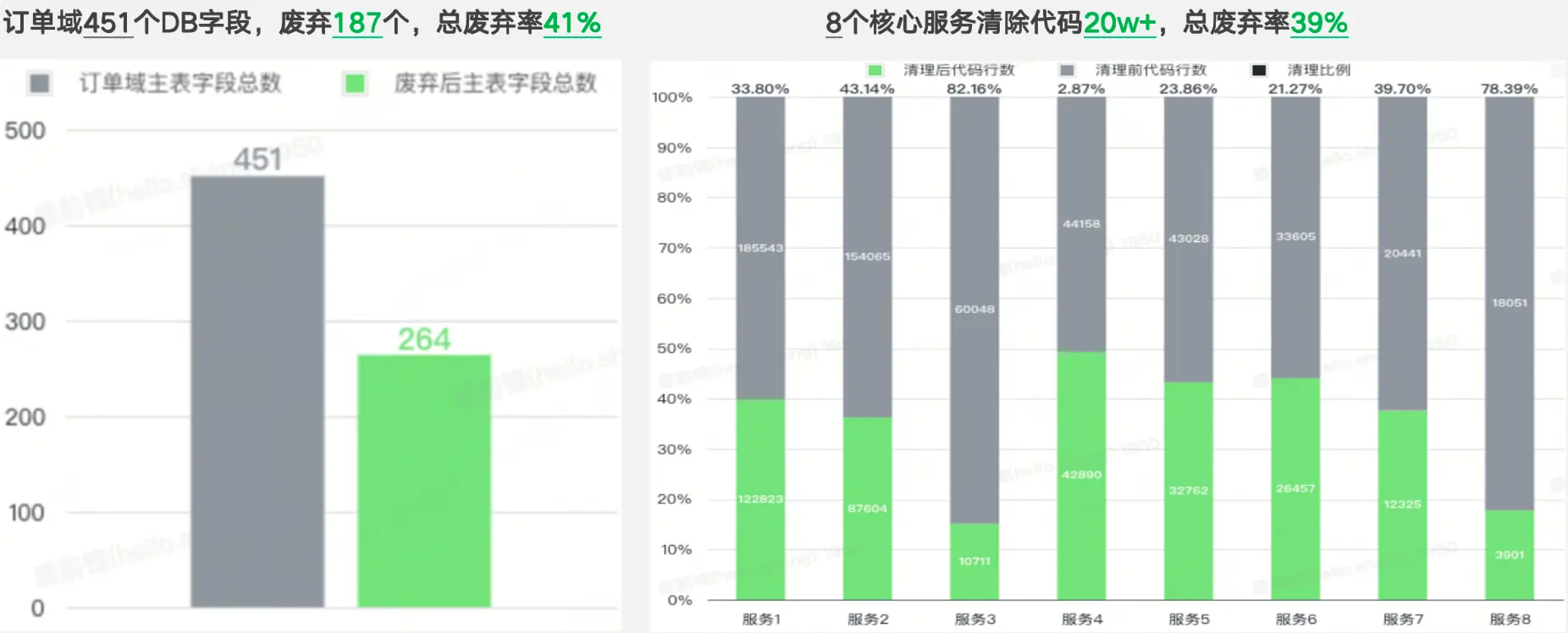
Lalamove 国际化业务经过了多年的迭代和演进,代码日渐臃肿,无用的业务逻辑、废弃的DB字段等充斥在代码每个角落,交易团队在项目前期粗略统计,至少存在30%以上代码属于废弃的无效逻辑,订单领域的废弃DB字段也在100+以上,对代码质量和研发效能都造成了较大影响。
在2025年初,lalamove交易团队启动了代号为"大扫除"的代码瘦身计划,旨在通过消除无效代码和DB废弃字段的方式,提升代码可读性、可维护性,降低沟通成本,最终提升研发效能。并最终取得了不错的成果:
2.瘦身范围
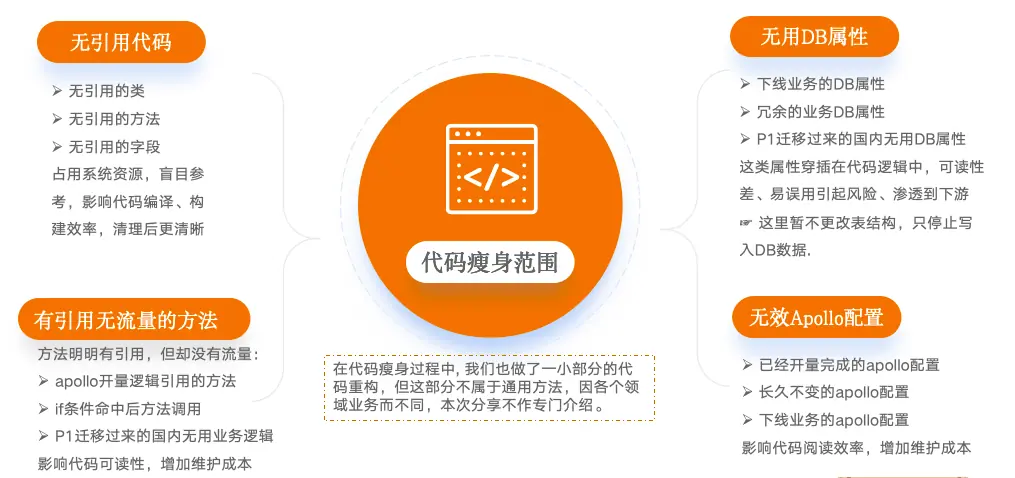
无用代码涉及的范围非常大,我们需要从中识别出ROI(投入产出比)最大的部分。最终确定的代码瘦身范围包括如下几类:
-
无引用的代码(包括类、方法、字段)
-
有引用无流量的方法
-
无用的DB属性
-
无效的Apollo配置
关于重构:尽管在代码瘦身中,业务重构也有所涉及,但重构要求对业务领域较为熟悉,且重构方式因业务领域而有所不同,非通用解决方案可以做到。故本文不展开介绍。
3.如何高效清理无用代码?
3.1 代码瘦身工具简要
在对无用代码和废弃DB字段的清理过程中,CI团队和交易研发团队协作,开发了3种工具。这些工具可以协助我们精准识别无用代码,最终提升清理效率。并且充分考虑到易用性,做到低成本可复用。

3.2 SA插件的原理和使用
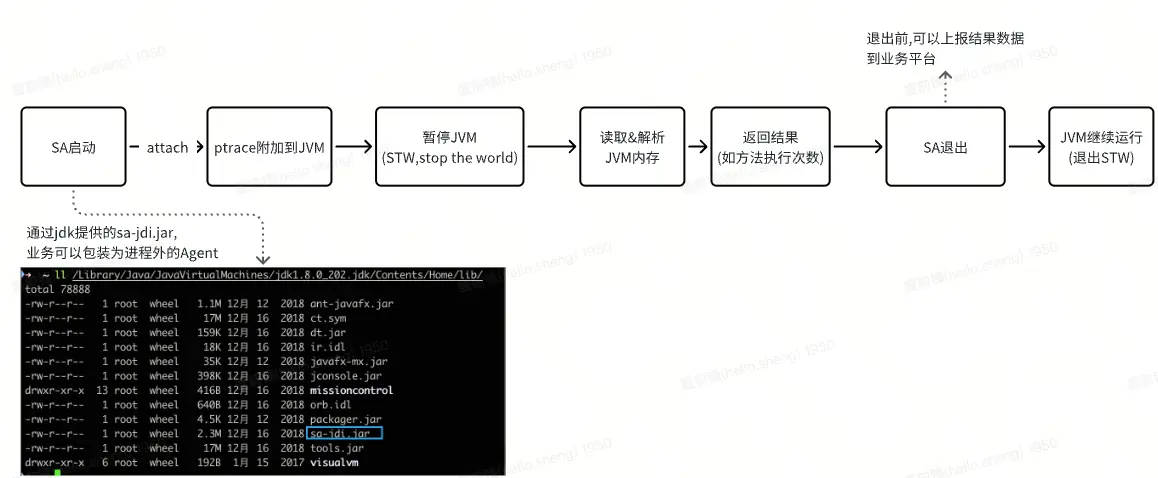
3.2.1 SA插件原理介绍
SA插件 使用了Spoon****工具 的代码解析能力**、Hotspot VM SA(S ervice Ability)的方法执行次数统计能力。**
在服务运行一段时间后,利用S****poon 获取**方法全集** , 利用**Hotspot VM SA(Service Ability)**获取**有流量方法集** , 对两者取差集得到**无流量方法集**。

3.2.2 Hotspot VM SA(Service Ability)
Hotspot VM SA(Service Ability)是HotSpot VM 提供的一套调试工具集,它可以通过attach到目标进程的方式,获取目标进程在OS层面的内存数据,其中就包含JAVA的"方法执行次数". JVM记录方法执行次数的目的是为了将高频解释执行的代码,通过JIT(just in time)机制编译为本地机器码, 提升执行效率。
The Serviceability Agent(SA). The Serviceability Agent is a Sun private component in the HotSpot repository that was developed by HotSpot engineers to assist in debugging HotSpot. They then realized that SA could be used to craft serviceability tools for end users since it can expose Java objects as well as HotSpot data structures both in running processes and in core files.
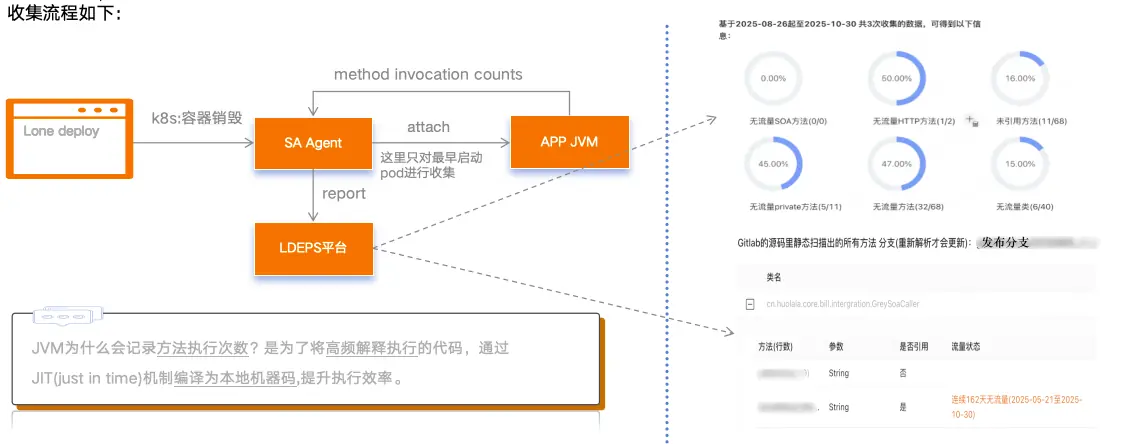
3.2.3 收集流程
这里我们将jdk提供的sa-jdi.jar, 包装为一个java进程外的SA Agent, 在k8s容器销毁时触发目标JVM的attach动作,且只会对服务的k8s集群中"最早启动的pod"进行收集。
最终将收集到的"方法执行次数 "数据上报到"代码精简平台".
3.2.4 注意事项
-
**Hotspot VM SA(Service Ability)**的attach动作会触发JVM暂停(STW, stop the world),因此需要选择合适的attach时机,比如人工离线服务pod或发布时的pod销毁等。
-
**Hotspot VM SA(Service Ability)**收集JVM数据需要充足内存(如剩余内存至少在500M~1G)。
-
**被Hotspot VM SA(Service Ability)**收集的服务必须具有多个pod实例(2个以上最佳),防止服务业务被中断 或 极端情况下单点问题。
3.2.5 代码实现
-
被编译执行的方法收集:
public class CompiledMethodVisitor implements CodeCacheVisitor{ //...... public void visit(CodeBlob codeBlob) { if (codeBlob == null || codeBlob.asNMethodOrNull() == null) { return; } final Method method = codeBlob.asNMethodOrNull().getMethod(); Long methodinvocationCount = method.getInvocationCount(); //...... } }
-
被解释执行的方法收集:
public class InvocationCounterVisitor implements SystemDictionary.ClassVisitor{ //..... @Override public void visit(Klass klass) { if(klass instanceof InstanceKlass){ final MethodArray methods = ((InstanceKlass) klass).getMethods(); for (int i = 0; i <methods.length() ; i++) { final Method method = methods.at(i); if(method.getInvocationCount() > 0){ //....... } }
markdown}}
3.2.6 SA插件在同类型实现中的优势
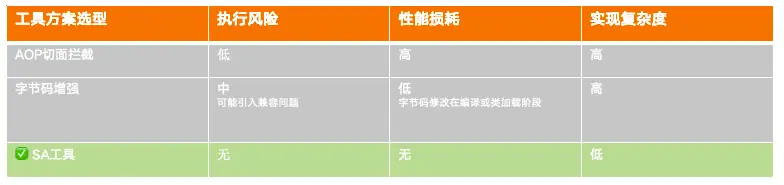
实现方式有多种,这里我们对如下三种方案进行了综合对比,在执行风险、性能损耗及实现的复杂度三个维度上,SA工具的表现最优。
3.3 BigClean Scanner插件的使用

IDEA自身提供的无引用类&方法扫描插件使用不直观,体验不好,为此我们自主开发了BigClean Scanner插件,以辅助扫描无引用代码。
-
简介:BigClean Scanner是自主开发的插件,可以更直观地扫描本地IDEA中的无引用代码(类、方法),帮助开发人员提升垃圾代码的收集效率(
并非100%准确,不作为最终删除依据,需要研发同学二次确认
)。
-
原理:仍然是通过Spoon工具收集方法全集、有引用方法集, 然后对二者取差集,最终得到无引用方法集,无引用类的收集原理类似。
3.4 Mybatis Inteceptor拦截器的使用
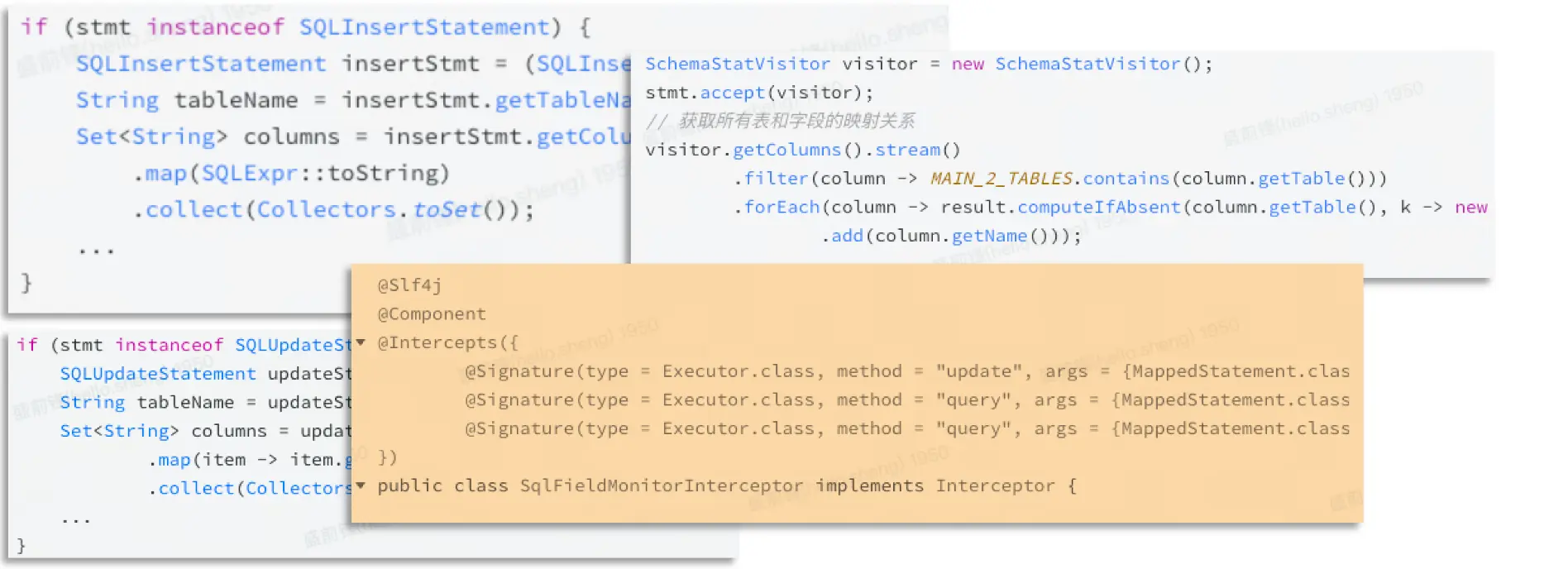
对于熟悉java的同学来说,对于SQL拦截的实现应该并不陌生,这里就以Mybatis使用为例简单介绍下。
原理:通过Mybatis的拦截器接口,来实现对sql的拦截、解析、识别DB废弃字段出现的代码位置。最后将识别到的DB废弃字段、接口名称、Table Name等上报监控平台,并经过汇总整理作为清理的依据。
4.如何保证清理质量?
整个过程我们删除了超过30%的无用代码,100+的废弃DB字段。如此大范围的变更, 必然要提供相应的策略来保证变更的质量。这里我们通过读、写接口两个维度,对质量保证策略分类说明:
-
读接口变更:常规的流量回放对比策略
-
写接口变更:
-
对比DB中两个订单的数据一致性
-
对比写接口中请求下游的出入参一致性,包括kafka、redis、下游接口出入参等
-
写接口停止写入DB废弃字段后,读接口受到的影响对比
-
接下来,让我们看下具体质量保证的策略设计!
4.1 读接口变更:常规的流量回放对比策略
使用场景举例:
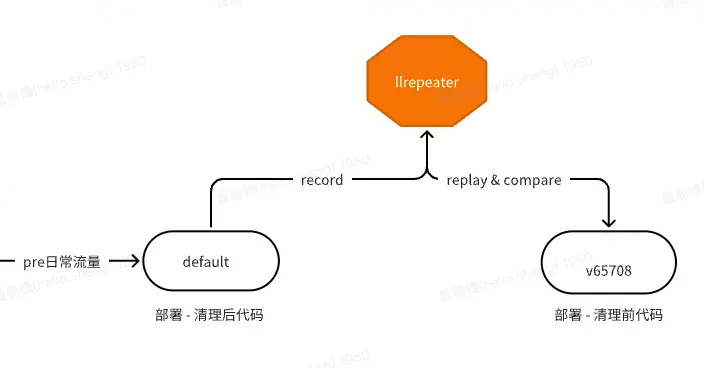
比如一个查询订单详情接口,删除了其中一段关于价格计算的逻辑,那么这种逻辑变更就可以通过llrepeater流量回放来对比读接口变更前后的response是否一致。
llrepeater:内部提供的读接口流量回放工具,它可以录制读接口请求,回放请求到另外一个pod。通过发起两个不同pod的请求,来对比响应结果的一致性。
4.2 写接口变更:对比DB中两个订单的数据一致性
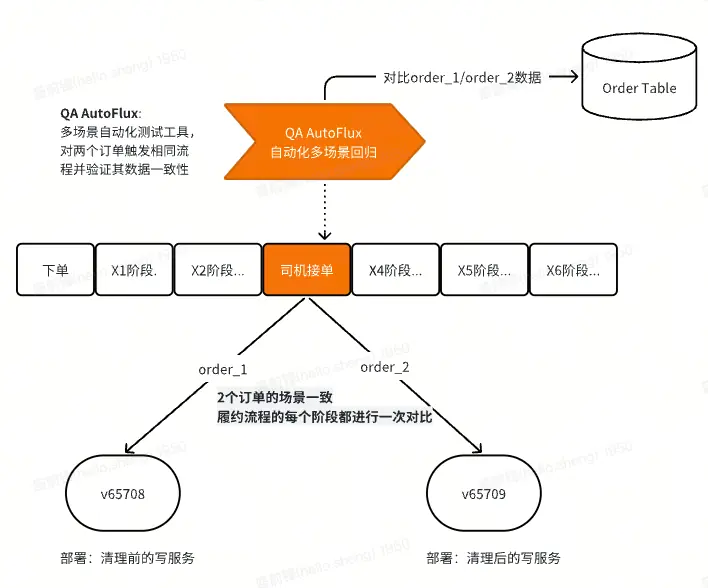
使用场景举例:
如果在清理过程中不慎删除了更新DB相关的代码,那么通过对比代码清理前后的两个订单的DB数据,就可以发现代码清理是否出了问题。
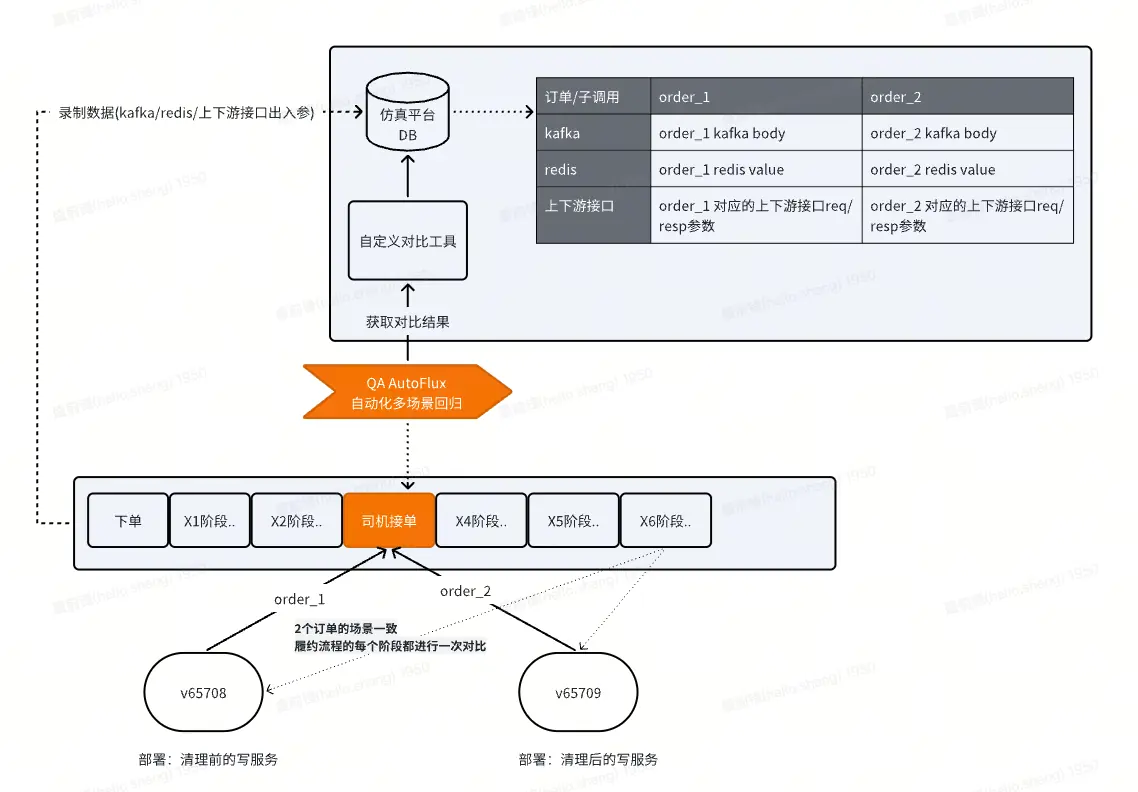
4.3 写接口变更:对比写接口中请求下游的出入参一致性
与上一个对比DB一致性策略类似,这里对比的是写服务变更后,对kafka body、redis、下游接口出入参等方面的影响。
使用场景举例:
如果在清理过程中不慎删除了kafka body参数,或上下游接口出入参,那么通过录制清理前后两套代码kafka/redis/上下游接口出入参,即可通过对比发现误删的情况。
仿真平台:一款内部测试工具,它可以通过代码插桩的方式,录制代码中的系统衔接流量,比如kafka body、redis key&value、接口请求出入参等。通过这种能力,可以录制变更前后两套代码的内部执行细节,通过对比发现问题。
4.4 写接口变更: 对读接口响应的影响
使用场景举例:
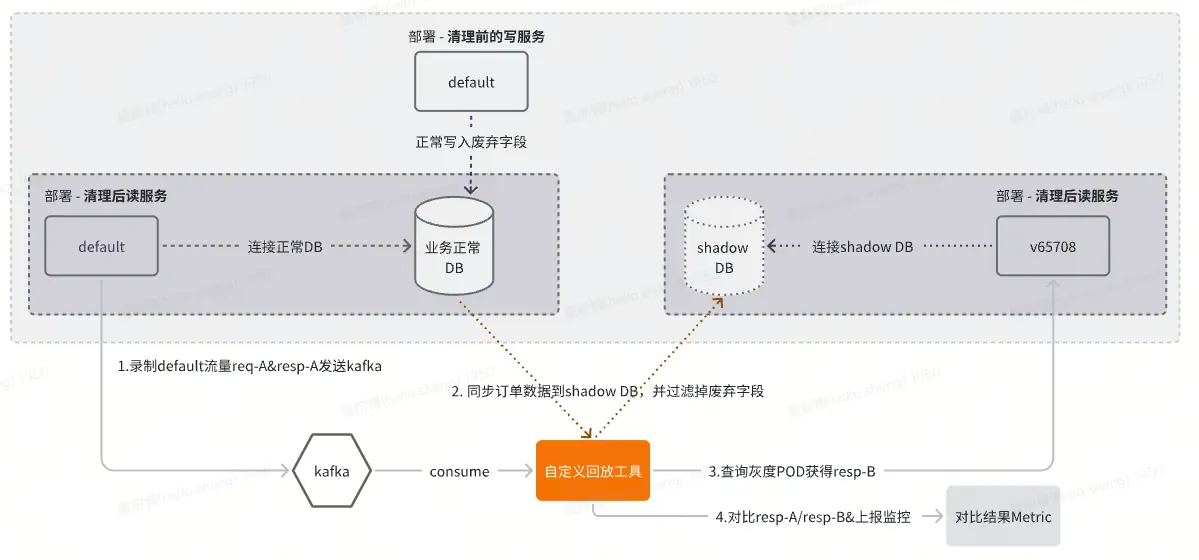
比如当写服务将DB的一个"废弃"字段X删除,而字段X在订单详情接口有使用到。那么,就需要验证: 在字段X删除的前后,是否影响到订单详情接口的响应结果?
这里我们提供了两套DB和两套代码,整体流程如下:
- default pod和v65708 pod部署的是"清理后的相同读服务代码"。
default pod连接的是业务正常DB,v65708 pod连接的是ShadowDB,即两个pod代码完全一致,仅仅DB的连接不同。
- 写服务仍然正常写入废弃DB字段
目的是提供完整的数据,便于让两个DB拷贝差异化的数据。
-
流量录制:录制default pod的读服务流量,获得某个接口X的req-A&resp-A,发送kafka
-
流量回放:消费kafka,获取某个接口X的req-A&resp-A,具体过程如下:
-
通过req-A&resp-A提供的订单ID,拷贝业务正常DB(含废弃字段)的订单数据到Shadow DB,但shadowDB插入前会去除废弃字段
-
然后,查询v65708的读服务做流量回放,获取v65708从Shadow DB(不含废弃字段)得到的resp-B.
-
对比resp-A和resp-B,判断结果的一致性。如果不一致,说明读接口X在删除废弃字段后受到了影响!
-
Shadow DB简介:其数据copy自正常业务DB的一套数据库,表结构与业务正常DB完全一致。顾名思义,正常业务DB和Shadow DB的区别仅在于存储的内容不同(shadowDB不含废弃字段),无结构上的区别。
5.最后总结
代码瘦身对于代码的可读性、可维护性等方面至关重要!但长期的代码清理意识与有效的SOP机制才是重中之重。
在这次代码清理实践中,我们建立了长效的通知机制,目的是对研发同学起到一个时时提醒的作用。同时,在Team内部我们也会经常性的对代码的精简情况做监督,让大家最终形成一个良好的代码"卫生"习惯!
希望本文可以对那些历史包袱重、技术债积累已久的系统起到抛砖引玉的作用,能够帮助大家打开服务精简的优化思路,最终帮助大家提升研发效率!