一、背景与问题
我们使用Flink+Hudi架构实现实时数据贴源入湖,实时湖的下游建设有对接Kyuubi/Trino进行即席探查与自助分析,也有使用Spark定时微批进行湖上的准实时加工聚合处理,后续对接Olap提供查询加速服务或同步HBase表提供高并发点查服务等。
有一个项目组基于贴源入湖的Hudi表数据,使用 Spark SQL 关联离线Hive维表,通过 insert overwrite将计算结果写入目标表(Hive 表),下游作业进一步将结果表数据同步至 HBase,供前端应用实时查询。
有一天早上这个Spark作业运行失败触发告警,同时有此依赖的下游作业均处于等待挂起状态,导致前端应用查询的结果数据仍是旧版本。
二、排查与分析
1.初步排查
Spark作业基于Yarn提交运行,排查发现此作业运行初次失败后重试了2次仍然失败,最后停止。后两次重试运行日志均报错Hive表路径找不到的异常:
arduino
Path does not exist: hdfs://...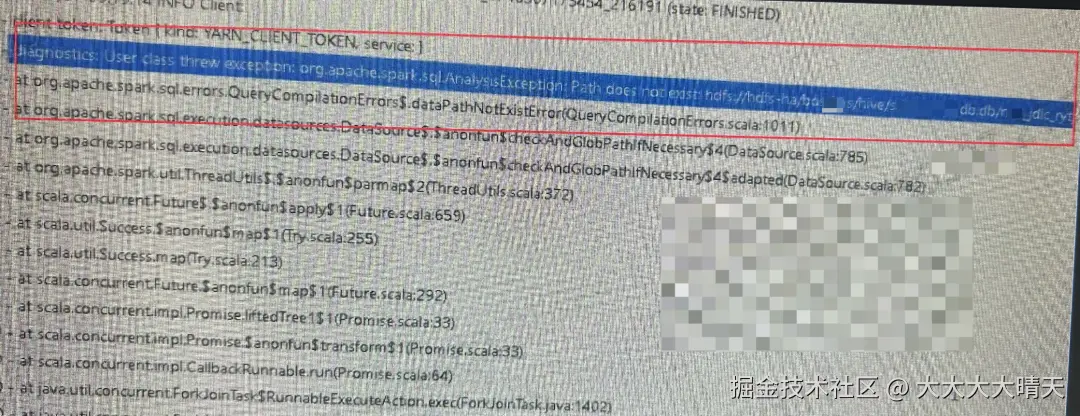 找到第一次运行失败的application_id查看yarn logs发现报错NoSuchElementException,如下:
找到第一次运行失败的application_id查看yarn logs发现报错NoSuchElementException,如下: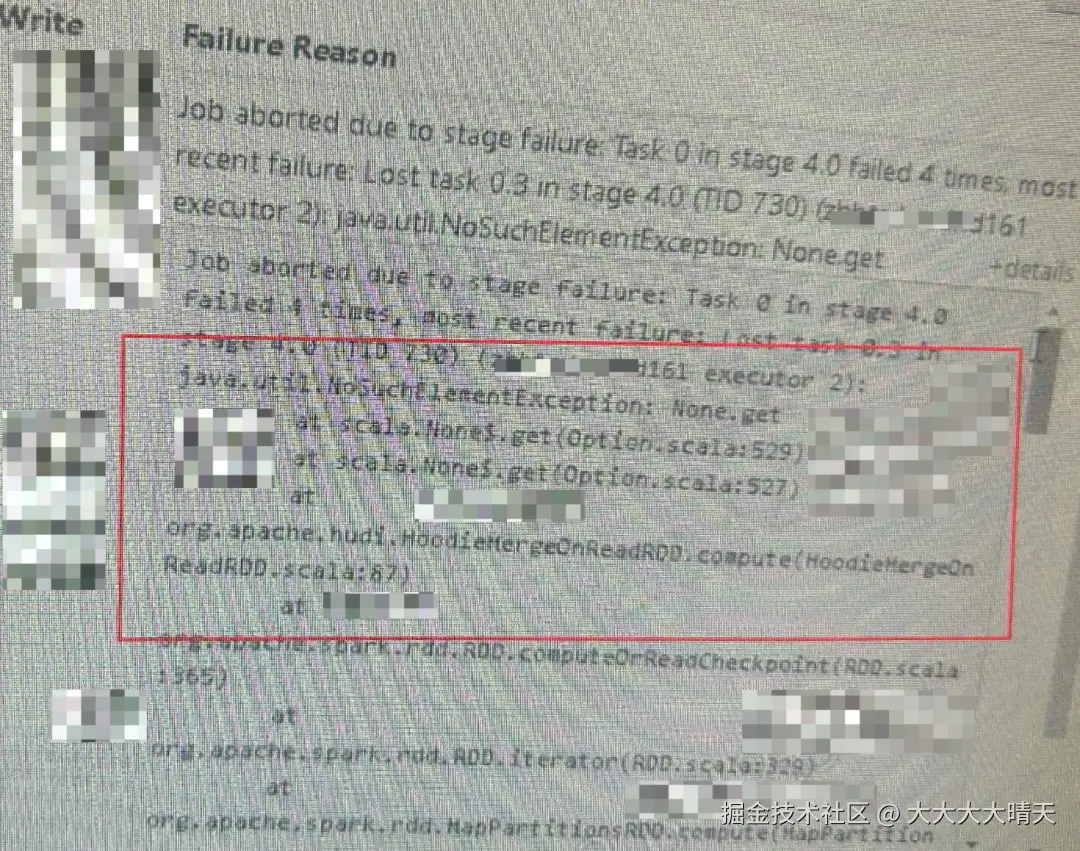 经过初步排查,推测是第一次失败引发hive结果表路径不存在,导致后续两次重试因路径找不到依旧失败而停止。为什么第一次会报错Hudi相关的NoSuchElementException呢?
经过初步排查,推测是第一次失败引发hive结果表路径不存在,导致后续两次重试因路径找不到依旧失败而停止。为什么第一次会报错Hudi相关的NoSuchElementException呢?
2.逻辑线梳理
为了理清作业失败前后因果关系,我们梳理了作业从启动到失败停止的状态时间线。
- 08:15 Driver 启动。
- 08:52 Executor 启动,抛出NoSuchElementException。
- 08:55 Task 重试 3 次后退出,Driver 检测到 Stage 异常直接退出。
- 后续重试时,Hive表路径不存在,触发Path does not exist报错。
首先第一个疑点是为啥Executor比Driver延迟37分钟启动?查看该Yarn队列的资源使用情况,此Spark作业采用YARN-Cluster模式提交资源队列运行(Capacity Scheduler),该队列复用了离线批处理资源队列,每天4-9点是资源使用高峰期,内存基本满负载,作业资源竞争激烈。
第二个疑点是Executor延迟启动后,为啥会抛出NoSuchElementException?查阅各方资料,Hudi一般在元数据校验或基于元数据查询实际数据查不到的场景下抛出。我们接着排查Hudi表的属性配置发现该Hudi 表的历史版本保留周期为 30 分钟,一旦过了30分钟Hudi会自动清理数据文件。结合延迟启动37分钟的现象,大概率是30分钟触发清理导致NoSuchElementException。
最后一个疑点是为什么Hive结果表的路径文件不存在了?因为此spark作业是执行insert overwrite语句,查阅源码分析执行流程,发现Spark 执行 insert overwrite写入非分区表时,底层调用 InsertIntoHadoopFsRelationCommand,大致流程如下:
go
// 非分区表:删除表根目录
fs.delete(tablePath, true) // 递归删除
// 创建临时目录用于写入
fs.mkdirs(tempPath)
// 写入数据后,将临时目录内容移动到 tablePath这一系列操作并非原子事务:一旦删除表目录后,后续步骤(如创建临时目录或写入数据)失败,表目录将永久丢失,且没有回滚机制。
3.根因分析
根据上述分析,我们在测试环境完成了复现,也验证了我们的上述分析与推断。此次问题的完整分析如下:
- Yarn资源抢占导致 Executor 启动延迟超过 Hudi 版本保留周期,Driver 持有的过期元数据引发 Task 读取失败。
- Spark SQL insert overwrite操作的delete与后续mkdirs及数据写入非事务绑定,Hudi-Task数据读取失败导致表路径删除后未重建,后续重试全部失败。
三、解决方案
1.资源队列调整:调大Yarn对应队列的资源配额;或将准实时批处理队列与离线队列分开,避免相互影响
2.非分区表改造:将非分区表临时改造为分区表,分区表insert overwrite仅删除分区目录,不会删除表级目录,规避路径丢失风险。(经过测试验证,对于非分区的Hudi表同样存在类似问题)
3.Hudi表参数优化:延长 Hudi 表版本保留周期(如从 30min 调整为 120min),或优化 Checkpoint 频率,减少元数据过期概率。
4.(适用于部分场景)切换写入模式:改用 insert into追加数据,从源头规避insert overwrite的删表路径风险。
按上述方案实施修复上线后,已稳定运行半年再未出现问题。
四、总结与展望
本次问题本质是Spark SQL 非事务操作与 Hudi 版本管理的时间差风险叠加引发的,本次排障通过日志时序梳理 + 源码逻辑分析 + 测试场景复现,精准定位了问题根因并予以解决。未来在构建流批一体数据链路时,需更关注底层存储与计算引擎的交互风险,从设计阶段规避类似问题,降低生产运行风险。