前言
自从大模型LLM问世以来,我就对其特别好奇,拜读过Attention Is All You Need论文,也从工程角度上去分析(靠自己的理解其中的原理),但常看常新,就比如 Q Q Q、 K K K、 V V V这三个数值,每次看都会有一些不一样的理解,从最初的感到新奇,慢慢的理解这是核心中的核心。
为什么LLM会有记忆,就是因为注意力的出现,让最后一个词向量也能找到最开始的那个词向量。那么LLM中智能的涌现则很有可能是 A t t e n t i o n Attention Attention发挥着关键作用。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d}})V Attention(Q,K,V)=softmax(d QKT)V
回顾上面这个微不足道的公式,确使人好奇,好奇的不是数学公式,而是工程角度上的优雅,但又不那么优雅。
学术界确实存在着一批人研究着LLM可解释性,也就是透明人工智能。
我们来看Anthropic团队的Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet这篇文章
这篇文章通过训练SAE做了一个字典学习,从LLM中的隐藏层特征中提取到一个超维特征空间,主要目的把大模型的激活拆成这样的单义特征。我们可以这样想象,目前通用大模型再强大,从体积上来讲,依然比不过我们现有世界的知识体积,但是却好像无所不知,学到了所有知识,这里便是所谓的压缩即智能,但是它可以几乎无损释放出来,这可不可以说明是一种特征空间的转化,是将现有世界所有知识从高维空间压缩到低维空间,这个过程不就是LLM的学习吗!
那么Anthropic团队是将这个压缩从隐藏层释放出来,由此跟踪LLM的流程,来了解LLM是如何思考的。
Anthropic团队的很简单,训练了一个SAE来做字典学习,从而提取中间特征
- SAE,Sparse Autoencoder稀疏自编码器,AE自编码器是Encoder+Decoder组合而成,通过重构损失(Decoder生成的内容与原始内容做损失)来训练。SAE可以理解为在重构损失上额外添加一个稀疏约束损失,比如利用KL散度来达到我们想要的稀疏度,如0.05
- 字典学习,是从数据里自动学一组基础"字",用最少几个"字"的线性组合,精准表示原数据。比如很抽象的几张鹦鹉图片,但是我们却可以使用简单的"鹦鹉"两个字就表示出来了
根据Anthropic团队的方法,他们发现了LLM中存在着单义特征,无论是何种语言,"鹦鹉"、"parrot"、"Papagei"、"Perroquet"、"앵무새"、"オウム"都表示着同一种特征,换句话说,LLM是不是学习了一种内部语言,而现在LLM的基础Transformer则天然是一个AE结构,其中间特征是否就是一种语言的内部表示呢?
其实,扩展起来说,现在谈论到的世界模型,不也就是想找到一种内部语言吗!利用这种统一内部语言来获取一种通用性、更具智能的模型吗
谈论了有点多了,也又点跑题了。接下来,开始我们的训练
这里我们采用的是开源项目minimind作为我们学习的目标
快速开始
首先我们要将项目下载到本地
c
git clone https://github.com/jingyaogong/minimind.git配置环境,注意,尽量在纯净环境下重新配置,如果已有torch且版本不一致大概率会冲突的很严重இ௰இ
c
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple接下来开始预训练,无需配置超参数,使用默认参数(最小训练参数)即可
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# cd trainer/
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_pretrain.py
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
Trainable Params: 25.830M
Generating train split: 1413103 examples [00:07, 183135.71 examples/s]
Epoch:[1/1](100/44160), loss: 7.1172, logits_loss: 7.1172, aux_loss: 0.0000, lr: 0.00049999, epoch_time: 32.0min
Epoch:[1/1](200/44160), loss: 6.9685, logits_loss: 6.9685, aux_loss: 0.0000, lr: 0.00049998, epoch_time: 29.0min
Epoch:[1/1](300/44160), loss: 6.7941, logits_loss: 6.7941, aux_loss: 0.0000, lr: 0.00049995, epoch_time: 29.0min
Epoch:[1/1](400/44160), loss: 6.5422, logits_loss: 6.5422, aux_loss: 0.0000, lr: 0.00049991, epoch_time: 28.0min
.....................................................................................................................................................................................................................
Epoch:[1/1](43900/44160), loss: 2.1968, logits_loss: 2.1968, aux_loss: 0.0000, lr: 0.00005004, epoch_time: 0.0min
Epoch:[1/1](44000/44160), loss: 2.4719, logits_loss: 2.4719, aux_loss: 0.0000, lr: 0.00005001, epoch_time: 0.0min
Epoch:[1/1](44100/44160), loss: 2.3295, logits_loss: 2.3295, aux_loss: 0.0000, lr: 0.00005000, epoch_time: 0.0min
Epoch:[1/1](44159/44160), loss: 2.1863, logits_loss: 2.1863, aux_loss: 0.0000, lr: 0.00005000, epoch_time: 0.0min预训练结束后,进行监督微调,同样默认参数即可
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_full_sft.py
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
Trainable Params: 25.830M
Generating train split: 1214724 examples [00:02, 426484.26 examples/s]
Epoch:[1/2](100/75921), loss: 2.4468, logits_loss: 2.4468, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 36.0min
Epoch:[1/2](200/75921), loss: 2.2748, logits_loss: 2.2748, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 32.0min
Epoch:[1/2](300/75921), loss: 2.1162, logits_loss: 2.1162, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 31.0min
Epoch:[1/2](400/75921), loss: 2.3190, logits_loss: 2.3190, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 31.0min
Epoch:[1/2](500/75921), loss: 2.1794, logits_loss: 2.1794, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 30.0min
.....................................................................................................................................................................................................................
Epoch:[2/2](75700/75921), loss: 2.1367, logits_loss: 2.1367, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min
Epoch:[2/2](75800/75921), loss: 1.7300, logits_loss: 1.7300, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min
Epoch:[2/2](75900/75921), loss: 2.1266, logits_loss: 2.1266, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min
Epoch:[2/2](75920/75921), loss: 1.8719, logits_loss: 1.8719, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min训练完毕后,可以试试自己训练的这个小模型,虽然有点智障,但在这个过程中却也学习了不少知识
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# cd ..
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master#
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight full_sft
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
[0] 自动测试
[1] 手动输入
0
💬: 你有什么特长?
🤖: 我是中小学的学生,我喜欢阅读和旅游。我喜欢阅读、艺术、文学和历史。我也喜欢阅读历史和哲学,尤其是哲学和科学。
[Speed]: 64.00 tokens/s
💬: 为什么天空是蓝色的
🤖: 天空之所以呈现蓝色,是因为太阳的光线在穿过大气层时,散射了蓝色光,因此天空呈现出蓝色。
[Speed]: 153.34 tokens/s
💬: 请用Python写一个计算斐波那契数列的函数
🤖: 好的,可以使用Python编写的函数来计算斐波那契数列。其中,k是第一次函数,c是前一个函数,m是第三个函数,x是第三个函数,y是第二个函数,x是第三个函数,x是第四个函数。如果斐波那契数列不存在,则可以使用Java或SQL等编程语言来实现。
[Speed]: 158.66 tokens/s
💬: 解释一下"光合作用"的基本过程
🤖: 光合作用是地球上物质转化的一个过程,它的主要过程是通过光能转化为化学能,同时释放出能量。光合作用的过程主要由叶绿素、叶绿素、二氧化碳等组成。在叶绿素吸收太阳光能时,叶绿素吸收太阳光能,通过叶绿素吸收太阳光能,实现光合作用的目的。
光合作用的基本过程包括光反应和电子元件的调控。光反应需要光能转化为能量,当光合成反应时,氧气转化为氢气。电子元件的调控可以利用光能转换来产生能量,其中氢气和氧气被分解为氧气。电子元件的调控可以将光能转换为电子,通过光电效应将能量转换为电子,产生能量,产生能量和电子。
光合作用的基本过程包括光化学反应、光反应和电磁化学反应。在光反应中,光能被转化为化学能,它被转化为化学能。在化学反应中,由于光能被转化为化学能,而氧气被释放为电子,并被释放为电子。
光合作用的基本过程主要包括光反应和电子元件的调控。在光反应中,光能被转化为化学能,从而产生能量和电子,这些
[Speed]: 158.30 tokens/s
💬: 如果明天下雨,我应该如何出门
🤖: 如果明天下雨,你可以尝试穿上防水衣或者雨伞。这些衣物可以提供避雨的可能性,帮助你更好地应对雨水的路面。
[Speed]: 152.80 tokens/s
💬: 比较一下猫和狗作为宠物的优缺点
🤖: 猫是猫科动物中最大的哺乳动物,拥有浓密的橙色毛发和灰色的毛发,因此猫比狗更适合与人类相处。猫喜欢与人类交互,而狗则更喜欢与人类交互,因此更适合与人类相处。猫可以与人类相处,但也会对人类的健康造成负面影响。
[Speed]: 151.60 tokens/s
💬: 解释什么是机器学习
🤖: 机器学习是一种人工智能的分支,它利用计算机算法和统计模型来分析和理解数据,并从中提取出有用的信息和模式,从而帮助计算机自动从数据中提取规律和模式,并利用这些规律进行预测和决策。
[Speed]: 146.07 tokens/s
💬: 推荐一些中国的美食
🤖: 中国的美食非常丰富,有各种口味,如日本料理、日本料理、日本料理等。比如日本料理、日本料理、日本料理等,都有各自的美食魅力。日本料理和日本料理也是中国美食中的重要组成部分,例如寿司、拉面、烤肉等。日本料理的口味非常地道,日本料理的特点是肉质鲜美、口感鲜美,是日本的文化遗产。日本料理的特色包括寿司、拉面、天妇罗等。日本料理的口味非常独特,可以带给人们不同的美食文化,包括寿司、拉面、天妇罗等。日本料理则以寿司为主,以寿司为主要成分,采用新鲜的寿司材料制作,烹饪方式十分独特。日本料理则以烤肉为主要成分,使用烤制技术,如火腿、鸡肉、蔬菜等,将各种食材与食材混合在一起,烹制出独特的味道。
[Speed]: 147.97 tokens/s
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight full_sft
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
[0] 自动测试
[1] 手动输入
1
💬: 我应怎么学习LLM这项技术?
🤖: 学习LLM是一项非常有用的技能,因为它可以帮助你了解如何使用LLM系统来处理信息。LLM可以提供更全面的学习内容,包括学习方法、知识点、方法等,以及如何与其他学习者和团队分享知识。LLM可以提供更深入的学习体验,包括教师如何使用LLM软件或在线资源,以及如何与他人分享和交流,这些都是非常有用的技能。
[Speed]: 64.87 tokens/s
💬: LLM是什么?你知道吗?
🤖: LLM(Jord)是一种基于物理学的物理学理论,描述了物理过程和量子力学的基本概念。它涉及到物理学、数学、化学、生物学等多个领域,以描述各种现象和行为的特征,如原子、分子和基本粒子的行为。LLM可以用于描述自然现象、粒子行为、化学反应等物理现象,以及量子力学的基本概念。LLM的定义可以从物理学的角度来解释,例如,在量子力学中,微观粒子既能表现出波动的特性,又能表现出粒子的性质。
[Speed]: 159.35 tokens/s
💬: 人工智能是什么?
🤖: 人工智能(Artificial Intelligence,简称AI)是一种计算机技术,旨在模仿人类智能,使计算机能够像人类一样感知、理解、推理和决策。人工智能应用广泛,包括语音识别、自然语言处理、机器翻译、推荐系统、自动驾驶、智能客服、智能机器人、智能医疗等领域。随着技术的不断进步,人工智能已经成为推动科技进步的重要力量之一。
[Speed]: 161.07 tokens/s
💬: 深度学习是什么?
🤖: 深度学习是一种人工智能技术,其核心是基于神经网络的构建,它模仿人类大脑的神经网络结构,通过对大量数据的学习和训练,使机器能够从中学习、调整和优化。深度学习的核心是神经网络,它通过多层神经网络的处理,以更准确地识别图像、语音和文本等信息。
深度学习技术可以用于图像识别、语音识别、自然语言处理等领域。例如,在图像分类方面,深度学习可以用于识别图像中的物体,例如图像中的物体,如鸟类、爬行动物等等。此外,深度学习还可以用于图像识别、语音识别、自然语言处理等领域。
深度学习在各个领域都有广泛的应用,如计算机视觉、自然语言处理、语音识别、机器翻译等。例如,在图像识别领域,深度学习可以用于图像分类、目标检测、目标检测、图像分割等任务。
[Speed]: 159.68 tokens/s深入解析
整体项目核心结构如下
./dataset/
├──init.py
└──lm_dataset.py
./model/
├──init.py
├──model_lora.py
├──model_minimind.py
├──tokenizer.json
└──tokenizer_config.json
./scripts/
├──chat_openai_api.py
├──convert_model.py
├──serve_openai_api.py
└──web_demo.py
./trainer/
├──trainer_utils.py
├──train_distillation.py
├──train_dpo.py
├──train_full_sft.py
├──train_grpo.py
├──train_lora.py
├──train_ppo.py
├──train_pretrain.py
├──train_reason.py
├──train_spo.py
└──train_tokenizer.py
eval_llm.py
requirements.txt
我们首先从模型入手,了解我们训练的模型底层架构,与那些其他LLM有什么区别,查看model_minimind.py文件,该文件定义了模型结构
模型解析
开始解析前,先回顾Transformer整体架构,简单看一下:
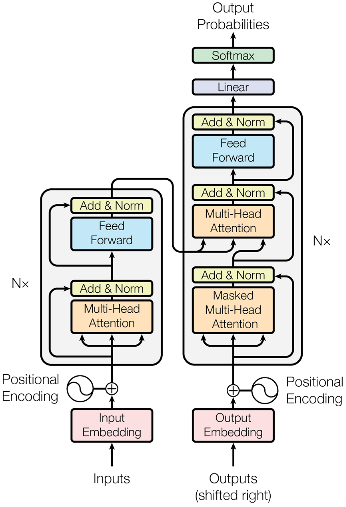
我们由小及大,首先是分析最简单结构,代码定义的神经网络层RMSNorm类,可以看到与普通的DNN模型含义 w ⊙ x w\odot x w⊙x很不一样,这是在LayerNorm基础上做了一定修改,在LLM中更为高效,公式如下:
RMSNorm ( x ) = w ⊙ x 1 d ∑ i = 1 d x i 2 + ϵ \text{RMSNorm}(x) = w \odot \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_i^2 + \epsilon}} RMSNorm(x)=w⊙d1∑i=1dxi2+ϵ x
python
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
"""初始化自定义LayerNorm层
Args:
dim: 输入特征维度
eps: 数值稳定性参数,默认为1e-5
"""
super().__init__()
self.eps = eps # 保存数值稳定性参数
self.weight = nn.Parameter(torch.ones(dim)) # 创建缩放参数,初始值为1
def _norm(self, x):
# 计算输入的均方根:x的平方的均值,开平方根,加eps确保数值稳定性,然后取倒数
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
# 对输入进行均方根归一化,然后应用缩放参数,并保持与输入相同的数据类型
return self.weight * self._norm(x.float()).type_as(x)我们对比Transformer中LayerNorm层和普通DNN中的区别,如下
| 方法 | 公式 | 区别 |
|---|---|---|
| DNN | y = σ ( W x + b ) y = \sigma(Wx + b) y=σ(Wx+b) | 线性变换外加激活函数 |
| LayerNorm | LayerNorm ( x ) = w ⊙ x − μ σ 2 + ϵ + β \text{LayerNorm}(x) = w \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LayerNorm(x)=w⊙σ2+ϵ x−μ+β | 减均值、归一化、缩放及偏置 |
| RMSNorm | RMSNorm ( x ) = w ⊙ x 1 d ∑ i = 1 d x i 2 + ϵ \text{RMSNorm}(x) = w \odot \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_i^2 + \epsilon}} RMSNorm(x)=w⊙d1∑i=1dxi2+ϵ x | 仅归一化及缩放,无均值与偏置 |
可以看到RMSNorm比LayerNorm减少了计算量及内存读写过程,且更好适配了LLM的训练过程,数值稳定,推理更友好
接下来,我们查看Transformer中的FFN层,这里可以发现,与标准的FFN两层线性单激活有所区别,额外添加了一个门控机制,且舍弃了偏置项。
代码如下:
python
class FeedForward(nn.Module):
"""前馈神经网络模块"""
def __init__(self, config: MiniMindConfig):
super().__init__()
if config.intermediate_size is None: # 如果未指定中间层维度,计算默认值
intermediate_size = int(config.hidden_size * 8 / 3)
config.intermediate_size = 64 * ((intermediate_size + 64 - 1) // 64) # 确保中间层维度是64的倍数
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) # 门控投影层
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) # 下投影层(输出层)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) # 上投影层(输入层)
self.dropout = nn.Dropout(config.dropout) # Dropout层
self.act_fn = ACT2FN[config.hidden_act] # 激活函数
def forward(self, x):
# 应用门控机制和上投影,然后通过激活函数,再与上投影结果相乘,最后通过下投影和dropout
return self.dropout(self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x)))在GLU Variants Improve Transformer论文中提到了这种改进,它放弃简单的单路变换,通过门控机制提升表达能力,一定程度也拥有了(选择)记忆的能力,同时调整中间层维度保证效率不下降。
而门控线性单元GLU最初是由Language Modeling with Gated Convolutional Networks论文提出,如下图所示,直观形象给出了其结构(截取了核心点):
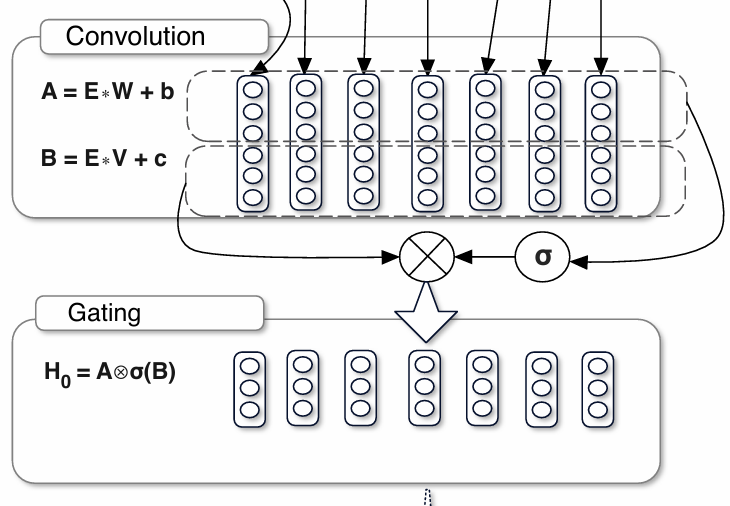
接下来,将进入LLM核心点,注意力机制,注意了注意力,注意力公式如下,阅读代码的时候无时无刻都要记住这行公式:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QK⊤)V
python
class Attention(nn.Module):
"""注意力机制模块"""
def __init__(self, args: MiniMindConfig):
super().__init__()
self.num_key_value_heads = args.num_attention_heads if args.num_key_value_heads is None else args.num_key_value_heads # 设置键值注意力头数量
# 确保注意力头数量是键值注意力头数量的整数倍
assert args.num_attention_heads % self.num_key_value_heads == 0
self.n_local_heads = args.num_attention_heads # 本地注意力头数量
self.n_local_kv_heads = self.num_key_value_heads # 本地键值注意力头数量
self.n_rep = self.n_local_heads // self.n_local_kv_heads # 每个键值注意力头需要重复的次数
self.head_dim = args.hidden_size // args.num_attention_heads # 每个注意力头的维度
self.q_proj = nn.Linear(args.hidden_size, args.num_attention_heads * self.head_dim, bias=False) # 查询投影层
self.k_proj = nn.Linear(args.hidden_size, self.num_key_value_heads * self.head_dim, bias=False) # 键投影层
self.v_proj = nn.Linear(args.hidden_size, self.num_key_value_heads * self.head_dim, bias=False) # 值投影层
self.o_proj = nn.Linear(args.num_attention_heads * self.head_dim, args.hidden_size, bias=False) # 输出投影层
self.attn_dropout = nn.Dropout(args.dropout) # 注意力 dropout
self.resid_dropout = nn.Dropout(args.dropout) # 残差 dropout
self.dropout = args.dropout # 保存 dropout 率
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn # 检查是否使用 flash attention
def forward(self,
x: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor], # 修改为接收cos和sin
past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache=False,
attention_mask: Optional[torch.Tensor] = None):
"""前向传播
Args:
x: 输入张量,形状为(bsz, seq_len, hidden_size)
position_embeddings: 位置编码,包含余弦和正弦频率矩阵
past_key_value: 过去的键值对缓存,用于自回归生成
use_cache: 是否使用缓存
attention_mask: 注意力掩码
Returns:
output: 注意力输出
past_kv: 缓存的键值对
"""
bsz, seq_len, _ = x.shape # 获取输入形状
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x) # 计算查询、键、值投影
# 重塑张量形状
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
# 应用RoPE位置编码
cos, sin = position_embeddings
xq, xk = apply_rotary_pos_emb(xq, xk, cos, sin)
# kv_cache实现
if past_key_value is not None:
# 拼接过去的键值对
xk = torch.cat([past_key_value[0], xk], dim=1)
xv = torch.cat([past_key_value[1], xv], dim=1)
# 保存缓存
past_kv = (xk, xv) if use_cache else None
# 调整维度顺序,准备注意力计算
xq, xk, xv = (
xq.transpose(1, 2), # (bsz, n_local_heads, seq_len, head_dim)
repeat_kv(xk, self.n_rep).transpose(1, 2),
repeat_kv(xv, self.n_rep).transpose(1, 2)
)
# 如果可用,则使用flash attention
if self.flash and (seq_len > 1) and (past_key_value is None) and (attention_mask is None or torch.all(attention_mask == 1)):
output = F.scaled_dot_product_attention(xq, xk, xv, dropout_p=self.dropout if self.training else 0.0, is_causal=True)
else:
# 计算注意力分数
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 添加因果掩码,确保只能关注当前及之前的位置
scores[:, :, :, -seq_len:] += torch.triu(torch.full((seq_len, seq_len), float("-inf"), device=scores.device), diagonal=1)
# 应用注意力掩码
if attention_mask is not None:
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = (1.0 - extended_attention_mask) * -1e9
scores = scores + extended_attention_mask
scores = F.softmax(scores.float(), dim=-1).type_as(xq) # 计算注意力权重
scores = self.attn_dropout(scores) # 应用dropout
output = scores @ xv # 计算加权和
output = output.transpose(1, 2).reshape(bsz, seq_len, -1) # 调整输出形状
output = self.resid_dropout(self.o_proj(output)) # 应用输出投影和残差dropout
return output, past_kv # 返回输出和缓存可以看到,以上核心点就是围绕公式,但似乎额外添加了一个位置编码,这是在标注每个词自身的位置(记忆,先来后到的关系)
下面则是目前主流LLM所采用的RoPE(Rotary Position Embedding,旋转位置编码)代码,其目的是为了在不引入额外可训练参数,通过对查询 Q Q Q 和键 K K K 张量做 "旋转变换",让模型捕捉序列的位置信息,从而记住了token之间的关系。
在RoFormer: Enhanced Transformer with Rotary Position Embedding论文中,为了解决原生Transformer中距离感较弱的问题,创新性引入相对距离
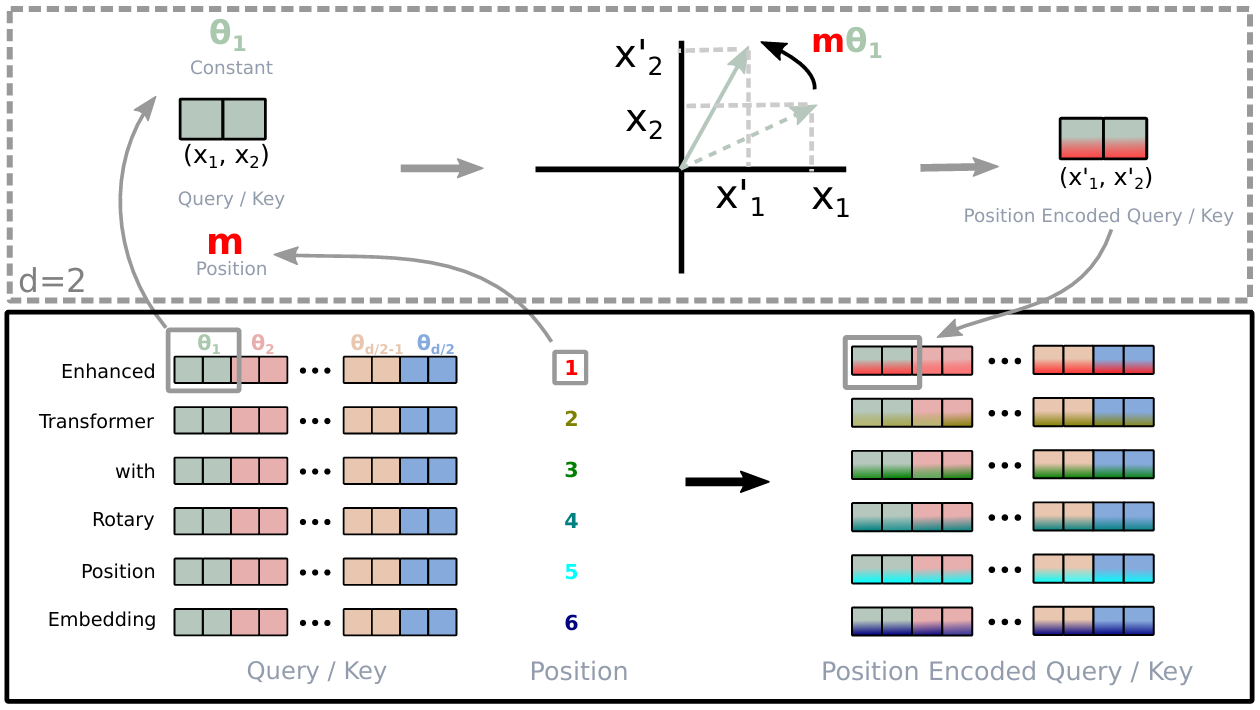
本质上,RoPE是利用角度差来实现位置感应的,你可以理解 Q 1 Q_1 Q1与 K 1 K_1 K1在相同角度上,完美适配,但是 Q 1 Q_1 Q1与 K 2 K_2 K2有一定的角度差,有些别扭, Q 1 Q_1 Q1与 K 3 K_3 K3差距太大,完全玩不来。
python
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
"""应用RoPE(Rotary Position Embedding)到查询和键张量
Args:
q: 查询张量
k: 键张量
cos: 余弦频率矩阵
sin: 正弦频率矩阵
position_ids: 位置索引,可选
unsqueeze_dim: 扩展维度,默认为1
Returns:
q_embed: 应用RoPE后的查询张量
k_embed: 应用RoPE后的键张量
"""
def rotate_half(x): # 定义旋转一半的辅助函数,逆时针旋转90度
"""将张量的后半部分旋转90度"""
return torch.cat((-x[..., x.shape[-1] // 2:], x[..., : x.shape[-1] // 2]), dim=-1)
q_embed = (q * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(q) * sin.unsqueeze(unsqueeze_dim)) # 应用RoPE到查询张量
k_embed = (k * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(k) * sin.unsqueeze(unsqueeze_dim)) # 应用RoPE到键张量
return q_embed, k_embed # 返回应用RoPE后的查询和键张量同样的,在Attention中还有一个细节需要我们注意,是KV缓存,为了解决工程上的问题(减少重复计算)而采用的策略(空间换时间),同时利用repeat_kv函数减少显存的占用,仅在推理时进行虚拟扩展,虽然会丢失部分KV头信息,但因为KV头的信息冗余度高,少量头即可覆盖核心匹配信息,故只保留少量KV头即可,还能降低显存使用量。
python
if past_key_value is not None: # K V 缓存
xk = torch.cat([past_key_value[0], xk], dim=1)
xv = torch.cat([past_key_value[1], xv], dim=1)
past_kv = (xk, xv) if use_cache else None
xq, xk, xv = (
xq.transpose(1, 2),
repeat_kv(xk, self.n_rep).transpose(1, 2),
repeat_kv(xv, self.n_rep).transpose(1, 2)
)
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, num_key_value_heads, head_dim = x.shape
if n_rep == 1: # 无缓冲,直接返回
return x
return (
x[:, :, :, None, :].expand(bs, slen, num_key_value_heads, n_rep, head_dim).reshape(bs, slen, num_key_value_heads * n_rep, head_dim)
)当然,随着LLM的发展,很直观的是网络越大,参数越多,效果就越好。但由此发现随参数量提升,模型训练极慢、推理极慢,
为了解决这个问题,2017年Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer论文首次在LSTM网络中引入了MoE机制,用以提升模型容量。
随着Transformer的兴起,想要真正的将MoE工程化落地,仍然有着不小的困难,2021年Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity第一个将MoE真正工业化、规模化。
来到2023年低,Mixtral of Experts论文,则将MoE推向了高潮,做了一个干净而又简单的开源 MoE,证明了一个简洁的MoE模型可以打败一个没有MoE的稠密模型。
之后2024年处,DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models引爆国内的舆论,首次系统性解决MoE-LLM的专家同质化问题。
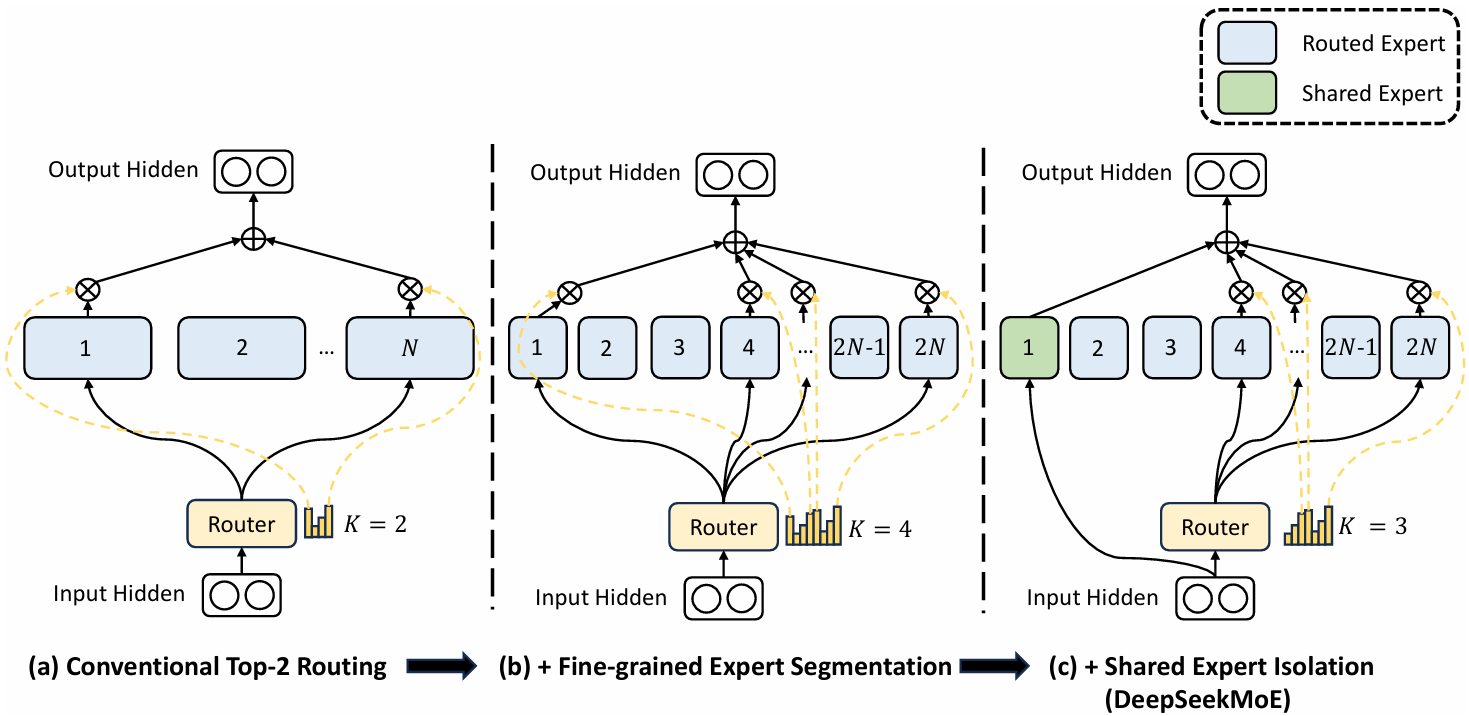
下面这部分则是项目中关于MoE门控模型的代码:
python
class MoEGate(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__() # 调用父类nn.Module的构造函数
self.config = config # 保存配置对象
self.top_k = config.num_experts_per_tok # 每个token选择的专家数量
self.n_routed_experts = config.n_routed_experts # 可路由专家的总数
self.scoring_func = config.scoring_func # 评分函数类型
self.alpha = config.aux_loss_alpha # 辅助损失的权重系数
self.seq_aux = config.seq_aux # 是否使用序列辅助损失
self.norm_topk_prob = config.norm_topk_prob # 是否对top-k概率进行归一化
self.gating_dim = config.hidden_size # 门控网络的输入维度
self.weight = nn.Parameter(torch.empty((self.n_routed_experts, self.gating_dim))) # 门控网络的权重参数:形状为(可路由专家数, 门控维度)
self.reset_parameters() # 初始化门控网络的权重参数
def reset_parameters(self) -> None:
# 使用 Kaiming 均匀初始化方法初始化权重
# 参数 a=math.sqrt(5) 是针对 ReLU 激活函数的推荐值
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
def forward(self, hidden_states):
"""
MoE 门控的前向传播方法
Args:
hidden_states (torch.Tensor): 输入的隐藏状态张量,形状为 (batch_size, seq_len, hidden_size)
Returns:
tuple:
- topk_idx (torch.Tensor): 选中的top-k个专家的索引,形状为 (batch_size*seq_len, top_k)
- topk_weight (torch.Tensor): 选中专家的权重,形状为 (batch_size*seq_len, top_k)
- aux_loss (torch.Tensor): 辅助损失,用于平衡专家负载
"""
bsz, seq_len, h = hidden_states.shape # 获取输入张量的形状信息
hidden_states = hidden_states.view(-1, h) # 将隐藏状态展平,形状变为 (batch_size*seq_len, hidden_size)
logits = F.linear(hidden_states, self.weight, None) # 通过线性层计算每个专家的评分logits
if self.scoring_func == 'softmax': # 根据配置的评分函数计算专家的概率分数
scores = logits.softmax(dim=-1)
else:
raise NotImplementedError(f'insupportable scoring function for MoE gating: {self.scoring_func}')
topk_weight, topk_idx = torch.topk(scores, k=self.top_k, dim=-1, sorted=False) # 选择概率最高的top-k个专家
# 如果选择多个专家且需要归一化,则对top-k权重进行归一化
if self.top_k > 1 and self.norm_topk_prob:
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20 # 避免除零
topk_weight = topk_weight / denominator
# 在训练模式下且辅助损失权重大于0时,计算辅助损失
if self.training and self.alpha > 0.0:
scores_for_aux = scores
aux_topk = self.top_k
topk_idx_for_aux_loss = topk_idx.view(bsz, -1) # 重塑为 (batch_size, seq_len*top_k)
# 根据配置选择序列辅助损失或普通辅助损失
if self.seq_aux:
scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1) # 序列辅助损失计算
ce = torch.zeros(bsz, self.n_routed_experts, device=hidden_states.device) # 创建形状为 (batch_size, n_routed_experts) 的计数张量
# 统计每个专家被选中的次数
ce.scatter_add_(1, topk_idx_for_aux_loss,
torch.ones(bsz, seq_len * aux_topk, device=hidden_states.device)).div_(
seq_len * aux_topk / self.n_routed_experts) # 归一化
aux_loss = (ce * scores_for_seq_aux.mean(dim=1)).sum(dim=1).mean() * self.alpha # 计算序列辅助损失
else:
# 普通辅助损失计算
# 将专家索引转换为one-hot编码
mask_ce = F.one_hot(topk_idx_for_aux_loss.view(-1), num_classes=self.n_routed_experts)
ce = mask_ce.float().mean(0) # 计算每个专家的负载频率
Pi = scores_for_aux.mean(0) # 计算每个专家的平均选择概率
fi = ce * self.n_routed_experts # 计算负载均衡因子
aux_loss = (Pi * fi).sum() * self.alpha # 计算辅助损失
else:
# 非训练模式或辅助损失权重为0时,辅助损失为0
aux_loss = scores.new_zeros(1).squeeze()
# 返回选中的专家索引、权重和辅助损失
return topk_idx, topk_weight, aux_loss辅助损失函数如下(用于解决专家同质化问题):
aux_loss = α ⋅ ∑ i = 1 N ( P i ⋅ f i ) \text{aux\loss} = \alpha \cdot \sum{i=1}^N ( P_i \cdot f_i) aux_loss=α⋅∑i=1N(Pi⋅fi)
其中 N N N为专家总数, P i P_i Pi为第 i i i个专家的平均被选概率,即所有token对该专家的softmax分数均值, f i f_i fi第 i i i个专家的实际负载频率,即被选中的次数占比×专家总数, α \alpha α为权重系数,用于控制辅助损失的强度。
接下来,我们查看一下添加上了MoE机制的FFN层代码
python
class MOEFeedForward(nn.Module):
"""
MOE(Mixture of Experts)前馈网络类
该类实现了混合专家前馈网络,使用门控机制为每个输入token选择合适的专家网络进行处理。
每个token可以被路由到多个专家网络,最终输出是这些专家输出的加权和。
"""
def __init__(self, config: MiniMindConfig):
super().__init__() # 调用父类nn.Module的构造函数
self.config = config # 保存配置对象
self.experts = nn.ModuleList([ # 使用ModuleList存储多个FeedForward网络作为可路由专家
FeedForward(config) # 创建可路由专家网络列表
for _ in range(config.n_routed_experts)
])
self.gate = MoEGate(config) # 创建MoE门控网络,用于为每个token选择合适的专家
if config.n_shared_experts > 0: # 如果配置了共享专家,则创建共享专家网络列表
self.shared_experts = nn.ModuleList([ # 共享专家会处理所有token的输入
FeedForward(config)
for _ in range(config.n_shared_experts)
])
def forward(self, x):
"""
MOE前馈网络的前向传播方法
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size, seq_len, hidden_size)
Returns:
torch.Tensor: MOE前馈网络的输出张量,形状与输入相同 (batch_size, seq_len, hidden_size)
"""
identity = x # 保存输入张量的副本作为残差连接的身份标识
orig_shape = x.shape # 保存输入张量的原始形状,用于后续重塑输出
bsz, seq_len, _ = x.shape # 获取输入张量的批次大小和序列长度
topk_idx, topk_weight, aux_loss = self.gate(x) # 使用门控机制选择专家
x = x.view(-1, x.shape[-1]) # 将输入张量展平,形状变为 (batch_size*seq_len, hidden_size)
flat_topk_idx = topk_idx.view(-1) # 将专家索引展平,形状变为 (batch_size*seq_len*top_k)
# 训练模式下的处理逻辑
if self.training:
x = x.repeat_interleave(self.config.num_experts_per_tok, dim=0) # 为每个token复制num_experts_per_tok次,用于路由到不同专家
y = torch.empty_like(x, dtype=x.dtype) # 创建一个与x形状相同的空张量,用于存储专家的输出
# 遍历所有专家,为每个专家处理对应的token
for i, expert in enumerate(self.experts):
expert_out = expert(x[flat_topk_idx == i]) # 选择当前专家需要处理的token
if expert_out.shape[0] > 0: # 将专家输出赋值到对应位置
y[flat_topk_idx == i] = expert_out.to(y.dtype)
else:
y[flat_topk_idx == i] = expert_out.to(y.dtype) + 0 * sum(p.sum() for p in expert.parameters()) # 处理没有token路由到当前专家的情况,避免梯度计算错误
y = (y.view(*topk_weight.shape, -1) * topk_weight.unsqueeze(-1)).sum(dim=1) # 将专家输出重塑为 (batch_size*seq_len, top_k, hidden_size),并与专家权重进行加权和
y = y.view(*orig_shape) # 将输出重塑为原始输入形状
else: # 推理模式下的处理逻辑
# 使用高效的推理方法处理MOE计算
y = self.moe_infer(x, flat_topk_idx, topk_weight.view(-1, 1)).view(*orig_shape)
# 如果配置了共享专家,则将共享专家的输出与当前输出相加
if self.config.n_shared_experts > 0:
for expert in self.shared_experts:
y = y + expert(identity)
self.aux_loss = aux_loss # 保存辅助损失,用于后续训练优化
return y # 返回最终输出张量
@torch.no_grad()
def moe_infer(self, x, flat_expert_indices, flat_expert_weights):
"""
MOE(混合专家)模型的高效推理方法
该方法用于在推理阶段将输入张量路由到不同的专家网络,然后将专家的输出加权和
存储到专家缓存中。与训练阶段不同,该方法采用更高效的实现方式,避免了重复计算。
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size*seq_len, hidden_size)
flat_expert_indices (torch.Tensor): 展平的专家索引张量,形状为 (batch_size*seq_len*top_k)
flat_expert_weights (torch.Tensor): 展平的专家权重张量,形状为 (batch_size*seq_len*top_k, 1)
Returns:
torch.Tensor: 专家推理的输出张量,形状与输入x相同 (batch_size*seq_len, hidden_size)
"""
expert_cache = torch.zeros_like(x) # 创建与输入x形状相同的零张量,用于存储专家的输出
idxs = flat_expert_indices.argsort() # 对专家索引进行排序,以便按专家分组处理token
tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0) # 统计每个专家处理的token数量,并转换为累积和,用于确定每个专家的token范围
token_idxs = idxs // self.config.num_experts_per_tok # 计算每个排序后的索引对应的原始token索引,用于从输入中提取对应的token
# 遍历每个专家,处理其对应的token
for i, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if i == 0 else tokens_per_expert[i - 1] # 确定当前专家处理的token起始索引
if start_idx == end_idx: # 如果当前专家没有处理任何token,则跳过
continue
expert = self.experts[i] # 获取当前专家网络
exp_token_idx = token_idxs[start_idx:end_idx] # 获取当前专家需要处理的原始token索引
expert_tokens = x[exp_token_idx] # 从输入中提取当前专家需要处理的token
expert_out = expert(expert_tokens).to(expert_cache.dtype) # 使用当前专家处理token,并转换为与expert_cache相同的数据类型
expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]]) # 将专家输出与对应的专家权重相乘
expert_cache.scatter_add_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out) # 将加权后的专家输出添加到对应的token位置
return expert_cache # 返回累积了所有专家输出的结果张量这部分代码相当于从多个专家模型选择较好处理当前情况的专家进行加权处理(如果存在共享专家处理通用知识,则直接相加),这部分保证计算量的不变,但是可以更为灵活地去处理各种不同的情况。
接下来,我们将FeedForward和Attention组合成为基础块MiniMindBlock
python
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: MiniMindConfig):
"""
MiniMind模型中的Transformer块构造函数
每个Transformer块包含一个自注意力机制和一个前馈网络(FFN),并在输入和输出处应用层归一化。
根据配置,前馈网络可以是普通的FeedForward网络或混合专家(MOE)前馈网络。
Args:
layer_id (int): 当前Transformer块的层索引,用于标识模型中的位置
config (MiniMindConfig): 模型配置对象,包含构建Transformer块所需的所有参数
"""
super().__init__() # 调用父类nn.Module的构造函数
self.num_attention_heads = config.num_attention_heads # 从配置中获取注意力头的数量
self.hidden_size = config.hidden_size # 从配置中获取隐藏层的大小
self.head_dim = config.hidden_size // config.num_attention_heads # 计算每个注意力头的维度
self.self_attn = Attention(config) # 初始化自注意力机制
self.layer_id = layer_id # 保存当前层的索引
self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps) # 初始化输入层归一化,用于注意力机制之前的输入处理
self.post_attention_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps) # 初始化注意力后层归一化,用于前馈网络之前的输入处理
# 根据配置选择使用普通FeedForward还是MOEFeedForward
self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
def forward(self, hidden_states, position_embeddings, past_key_value=None, use_cache=False, attention_mask=None):
"""
MiniMindBlock的前向传播方法,实现Transformer块的核心功能
该方法执行以下步骤:
1. 应用输入层归一化并执行自注意力机制
2. 添加残差连接
3. 应用注意力后层归一化并执行前馈网络
4. 添加第二个残差连接
Args:
hidden_states (torch.Tensor): 输入的隐藏状态张量,形状为 (batch_size, seq_len, hidden_size)
position_embeddings (Tuple[torch.Tensor, torch.Tensor]): 位置嵌入,包含cos和sin张量
past_key_value (Optional[Tuple[torch.Tensor, torch.Tensor]]): 过去的键值对缓存,用于增量解码
use_cache (bool): 是否缓存当前的键值对,默认为False
attention_mask (Optional[torch.Tensor]): 注意力掩码,用于控制注意力的可见性
Returns:
Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
- hidden_states: 经过Transformer块处理后的隐藏状态张量,形状与输入相同
- present_key_value: 当前的键值对,用于后续的增量解码
"""
residual = hidden_states # 保存输入的隐藏状态作为第一个残差连接
hidden_states, present_key_value = self.self_attn( # 对输入隐藏状态进行层归一化,然后通过自注意力机制处理
self.input_layernorm(hidden_states), position_embeddings,
past_key_value, use_cache, attention_mask
)
hidden_states += residual # 添加第一个残差连接
hidden_states = hidden_states + self.mlp(self.post_attention_layernorm(hidden_states)) # 对注意力输出进行层归一化,然后通过前馈网络处理,并添加第二个残差连接
return hidden_states, present_key_value # 返回处理后的隐藏状态和当前的键值对我们重复叠加基础块,提升LLM参数,得到最终的模型架构
python
class MiniMindModel(nn.Module):
def __init__(self, config: MiniMindConfig):
"""
MiniMindModel的构造函数,初始化完整的Transformer模型架构
该方法构建了MiniMind模型的所有主要组件,包括词嵌入层、Transformer层堆叠
和位置编码等。根据配置,模型可以支持不同的参数设置,如隐藏层大小、注意力头数量等。
Args:
config (MiniMindConfig): 模型配置对象,包含构建MiniMind模型所需的所有参数
"""
super().__init__() # 调用父类nn.Module的构造函数
self.config = config # 保存配置对象供后续使用
self.vocab_size, self.num_hidden_layers = config.vocab_size, config.num_hidden_layers # 从配置中获取词汇表大小和隐藏层数量
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size) # 创建词嵌入层:将词汇表索引转换为向量表示
self.dropout = nn.Dropout(config.dropout) # 创建dropout层:用于正则化,防止过拟合
# 创建Transformer层堆叠:包含num_hidden_layers个MiniMindBlock
self.layers = nn.ModuleList([MiniMindBlock(l, config) for l in range(self.num_hidden_layers)])
# 创建输出层归一化:用于最终隐藏状态的标准化
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 预计算旋转位置编码的cos和sin值
# dim参数:每个注意力头的维度
# end参数:最大位置嵌入长度
# rope_base参数:旋转位置编码的基础值
# rope_scaling参数:位置编码缩放配置
freqs_cos, freqs_sin = precompute_freqs_cis(dim=config.hidden_size // config.num_attention_heads,
end=config.max_position_embeddings, rope_base=config.rope_theta,
rope_scaling=config.rope_scaling)
self.register_buffer("freqs_cos", freqs_cos, persistent=False) # 注册预计算的cos值为缓冲区(不参与反向传播)
self.register_buffer("freqs_sin", freqs_sin, persistent=False) # 注册预计算的sin值为缓冲区(不参与反向传播)
def forward(self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
**kwargs):
"""
MiniMindModel的前向传播方法,实现完整的Transformer模型前向计算
该方法执行以下步骤:
1. 处理输入ID并转换为嵌入表示
2. 应用dropout正则化
3. 准备位置嵌入
4. 通过所有Transformer层处理隐藏状态
5. 应用输出层归一化
6. 计算辅助损失(如果使用MOE)
7. 返回处理后的隐藏状态、新的键值对缓存和辅助损失
Args:
input_ids (Optional[torch.Tensor]): 输入的token ID张量,形状为 (batch_size, seq_length)
attention_mask (Optional[torch.Tensor]): 注意力掩码,用于控制注意力机制的可见性,形状为 (batch_size, seq_length)
past_key_values (Optional[List[Tuple[torch.Tensor, torch.Tensor]]]): 过去的键值对缓存,用于增量解码
use_cache (bool): 是否缓存当前的键值对,用于后续的增量解码,默认为False
**kwargs: 其他可选参数
Returns:
Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]], torch.Tensor]:
- hidden_states: 经过所有层处理后的隐藏状态,形状为 (batch_size, seq_length, hidden_size)
- presents: 新的键值对缓存,用于后续的增量解码
- aux_loss: 辅助损失,仅在使用MOE时有效,用于平衡专家负载
"""
batch_size, seq_length = input_ids.shape # 获取输入的批次大小和序列长度
# 检查past_key_values的类型,如果是有layers属性的对象,则重置为None
if hasattr(past_key_values, 'layers'): past_key_values = None
past_key_values = past_key_values or [None] * len(self.layers) # 如果没有提供past_key_values,则初始化为与层数相同的None列表
start_pos = past_key_values[0][0].shape[1] if past_key_values[0] is not None else 0 # 计算当前序列的起始位置(用于增量解码)
hidden_states = self.dropout(self.embed_tokens(input_ids)) # 将输入ID转换为嵌入表示,并应用dropout正则化
position_embeddings = ( # 准备位置嵌入:从预计算的位置编码中获取当前序列对应的cos和sin值
self.freqs_cos[start_pos:start_pos + seq_length],
self.freqs_sin[start_pos:start_pos + seq_length]
)
presents = [] # 初始化一个列表,用于存储所有层的键值对缓存
# 遍历所有Transformer层,依次处理隐藏状态
for layer_idx, (layer, past_key_value) in enumerate(zip(self.layers, past_key_values)):
hidden_states, present = layer( # 通过当前层处理隐藏状态,获取新的隐藏状态和键值对缓存
hidden_states,
position_embeddings,
past_key_value=past_key_value,
use_cache=use_cache,
attention_mask=attention_mask
)
presents.append(present) # 将当前层的键值对缓存添加到列表中
# 对最终的隐藏状态应用层归一化
hidden_states = self.norm(hidden_states)
# 计算辅助损失:累加所有使用MOE的层的辅助损失
aux_loss = sum([l.mlp.aux_loss for l in self.layers if isinstance(l.mlp, MOEFeedForward)], hidden_states.new_zeros(1).squeeze())
return hidden_states, presents, aux_loss # 返回处理后的隐藏状态、键值对缓存和辅助损失同样的,在模型躯体定义完成的情况下,我们定义因果语言模型的架构,进行任务封装
python
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
config_class = MiniMindConfig
def __init__(self, config: MiniMindConfig = None):
"""
MiniMindForCausalLM类的构造函数,用于初始化因果语言模型
该方法构建了一个完整的因果语言模型,包含以下主要组件:
1. 配置对象:管理模型的所有超参数和设置
2. MiniMindModel:模型的主体部分,包含Transformer层堆叠和注意力机制
3. lm_head:语言模型的输出层,将隐藏状态映射到词汇表
此外,该方法还实现了词嵌入层与输出层的权重共享,以减少模型参数数量并提高训练效率。
Args:
config (MiniMindConfig, optional): 模型配置对象,如果为None则使用默认配置
"""
self.config = config or MiniMindConfig() # 如果没有提供配置,则使用默认配置
super().__init__(self.config) # 调用父类PreTrainedModel的构造函数,传入配置
self.model = MiniMindModel(self.config) # 创建MiniMindModel实例作为模型主体
self.lm_head = nn.Linear(self.config.hidden_size, self.config.vocab_size, bias=False) # 创建语言模型的输出层:将隐藏状态映射到词汇表大小的维度
self.model.embed_tokens.weight = self.lm_head.weight # 共享词嵌入层与输出层的权重,减少参数数量并提高训练效率
def forward(self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
logits_to_keep: Union[int, torch.Tensor] = 0,
**args):
"""
MiniMindForCausalLM类的前向传播方法,实现因果语言模型的预测和损失计算
该方法执行以下步骤:
1. 调用MiniMindModel的前向传播获取隐藏状态
2. 根据logits_to_keep参数选择要保留的隐藏状态部分
3. 通过语言模型头(lm_head)生成logits
4. 如果提供了标签,计算交叉熵损失
5. 构建包含损失、logits和隐藏状态的输出对象
6. 添加辅助损失(如果使用MOE)
Args:
input_ids (Optional[torch.Tensor]): 输入的token ID张量,形状为 (batch_size, seq_length)
attention_mask (Optional[torch.Tensor]): 注意力掩码,用于控制注意力机制的可见性,形状为 (batch_size, seq_length)
labels (Optional[torch.Tensor]): 标签张量,用于计算损失,形状与input_ids相同
past_key_values (Optional[List[Tuple[torch.Tensor, torch.Tensor]]]): 过去的键值对缓存,用于增量解码
use_cache (bool): 是否缓存当前的键值对,用于后续的增量解码,默认为False
logits_to_keep (Union[int, torch.Tensor]): 要保留的logits数量或索引,默认为0(保留所有)
**args: 其他可选参数
Returns:
CausalLMOutputWithPast: 包含以下字段的输出对象:
- loss: 交叉熵损失(如果提供了labels)
- logits: 模型生成的logits,形状为 (batch_size, seq_length, vocab_size)
- past_key_values: 新的键值对缓存,用于后续的增量解码
- hidden_states: 模型的隐藏状态
- aux_loss: 辅助损失(如果使用MOE)
"""
# 调用MiniMindModel的前向传播,获取隐藏状态、更新后的键值对缓存和辅助损失
hidden_states, past_key_values, aux_loss = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
**args
)
# 根据logits_to_keep参数确定要保留的隐藏状态部分
# 如果logits_to_keep是整数,则保留最后logits_to_keep个位置的隐藏状态
# 否则直接使用提供的索引
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
# 通过语言模型头将隐藏状态映射到词汇表大小,生成logits
logits = self.lm_head(hidden_states[:, slice_indices, :])
loss = None # 初始化损失为None
if labels is not None: # 如果提供了标签,则计算交叉熵损失
shift_logits = logits[..., :-1, :].contiguous() # 偏移logits和labels,确保每个位置的预测与下一个位置的标签对应
shift_labels = labels[..., 1:].contiguous()
loss = F.cross_entropy(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1), ignore_index=-100) # 计算交叉熵损失,忽略索引为-100的标签
# 创建CausalLMOutputWithPast对象,包含损失、logits、键值对缓存和隐藏状态
output = CausalLMOutputWithPast(loss=loss, logits=logits, past_key_values=past_key_values, hidden_states=hidden_states)
output.aux_loss = aux_loss # 将辅助损失添加到输出对象中
return output # 返回最终输出训练解析
我们知道了模型的架构,那么同样的,也应该知道如何去训练模型。大模型的训练和普通的深度神经网络模型、机器学习的训练很不相同,是分阶段训练,很难在一个阶段就训练出一个较好的效果,往往是不断的去迭代
预训练
预训练是大模型训练的第一步,让大模型了解语义,学说话之前先学字
如下是main函数,主要是去解析超参数、准备训练环境:
python
if __name__ == "__main__":
# 解析命令行参数
parser = argparse.ArgumentParser(description="MiniMind Pretraining")
parser.add_argument("--save_dir", type=str, default="../out", help="模型保存目录")
parser.add_argument('--save_weight', default='pretrain', type=str, help="保存权重的前缀名")
parser.add_argument("--epochs", type=int, default=1, help="训练轮数(建议1轮zero或2-6轮充分训练)")
parser.add_argument("--batch_size", type=int, default=32, help="batch size")
parser.add_argument("--learning_rate", type=float, default=5e-4, help="初始学习率")
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu", help="训练设备")
parser.add_argument("--dtype", type=str, default="bfloat16", help="混合精度类型")
parser.add_argument("--num_workers", type=int, default=8, help="数据加载线程数")
parser.add_argument("--accumulation_steps", type=int, default=8, help="梯度累积步数")
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--log_interval", type=int, default=100, help="日志打印间隔")
parser.add_argument("--save_interval", type=int, default=1000, help="模型保存间隔")
parser.add_argument('--hidden_size', default=512, type=int, help="隐藏层维度")
parser.add_argument('--num_hidden_layers', default=8, type=int, help="隐藏层数量")
parser.add_argument('--max_seq_len', default=340, type=int, help="训练的最大截断长度(中文1token≈1.5~1.7字符)")
parser.add_argument('--use_moe', default=0, type=int, choices=[0, 1], help="是否使用MoE架构(0=否,1=是)")
parser.add_argument("--data_path", type=str, default="../dataset/pretrain_hq.jsonl", help="预训练数据路径")
parser.add_argument('--from_weight', default='none', type=str, help="基于哪个权重训练,为none则从头开始")
parser.add_argument('--from_resume', default=0, type=int, choices=[0, 1], help="是否自动检测&续训(0=否,1=是)")
parser.add_argument("--use_wandb", action="store_true", help="是否使用wandb")
parser.add_argument("--wandb_project", type=str, default="MiniMind-Pretrain", help="wandb项目名")
parser.add_argument("--use_compile", default=0, type=int, choices=[0, 1], help="是否使用torch.compile加速(0=否,1=是)")
args = parser.parse_args()
# ========== 1. 初始化环境和随机种子 ==========
local_rank = init_distributed_mode()
if dist.is_initialized(): args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# ========== 2. 配置目录、模型参数、检查ckp ==========
os.makedirs(args.save_dir, exist_ok=True)
lm_config = MiniMindConfig(hidden_size=args.hidden_size, num_hidden_layers=args.num_hidden_layers, use_moe=bool(args.use_moe))
ckp_data = lm_checkpoint(lm_config, weight=args.save_weight, save_dir='../checkpoints') if args.from_resume==1 else None
# ========== 3. 设置混合精度 ==========
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
# ========== 4. 配置wandb(如果启用) ==========
wandb = None
if args.use_wandb and is_main_process(): # 仅当开启 wandb 且当前是主进程时,才初始化
import swanlab as wandb
wandb_id = ckp_data.get('wandb_id') if ckp_data else None # 从检查点数据中获取 wandb 实验 ID
resume = 'must' if wandb_id else None # 配置续跑模式
wandb_run_name = f"MiniMind-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}" # 构造实验名称
wandb.init(project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume) # 初始化 swanlab/wandb 实验
# ========== 5. 定义模型、数据、优化器 ==========
model, tokenizer = init_model(lm_config, args.from_weight, device=args.device)
if args.use_compile == 1:
model = torch.compile(model)
Logger('torch.compile enabled')
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16')) # 梯度缩放器,防止梯度下溢
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
# ========== 6. 从检查点恢复状态(如果启用) ==========
start_epoch, start_step = 0, 0
if ckp_data:
model.load_state_dict(ckp_data['model'])
optimizer.load_state_dict(ckp_data['optimizer'])
scaler.load_state_dict(ckp_data['scaler'])
start_epoch = ckp_data['epoch']
start_step = ckp_data.get('step', 0)
# ========== 7. 使用DDP包装模型(如果启用分布式训练) ==========
if dist.is_initialized():
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
model = DistributedDataParallel(model, device_ids=[local_rank])
# ========== 8. 开始训练 ==========
for epoch in range(start_epoch, args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
setup_seed(42 + epoch); indices = torch.randperm(len(train_ds)).tolist()
skip = start_step if (epoch == start_epoch and start_step > 0) else 0 # 确定需要跳过的step数
batch_sampler = SkipBatchSampler(train_sampler or indices, args.batch_size, skip)
loader = DataLoader(train_ds, batch_sampler=batch_sampler, num_workers=args.num_workers, pin_memory=True) # 构建训练数据加载器
if skip > 0:
Logger(f'Epoch [{epoch + 1}/{args.epochs}]: 跳过前{start_step}个step,从step {start_step + 1}开始')
train_epoch(epoch, loader, len(loader) + skip, start_step, wandb)
else:
train_epoch(epoch, loader, len(loader), 0, wandb)
# ========== 9. 清理分布进程 ==========
if dist.is_initialized(): dist.destroy_process_group()上面的代码使用了提前定义的工具函数,解析如下:
init_distributed_mode: 检测并初始化分布式数据并行训练环境
python
import torch.distributed as dist
def init_distributed_mode():
"""
初始化分布式训练环境
该函数负责检测并初始化分布式数据并行(DDP)训练环境,包括:
1. 检查环境变量判断是否需要分布式训练
2. 初始化分布式进程组
3. 设置当前进程使用的CUDA设备
Returns:
int: 返回本地进程的GPU设备索引(local_rank)
- 如果是非DDP模式,返回0
- 如果是DDP模式,返回当前进程的本地GPU索引
"""
if int(os.environ.get("RANK", -1)) == -1: # 检查环境变量RANK是否存在,判断是否需要分布式训练
return 0 # 非DDP模式,返回默认设备索引0
dist.init_process_group(backend="nccl") # 初始化分布式进程组,使用NCCL后端(适合GPU训练)
local_rank = int(os.environ["LOCAL_RANK"]) # 获取当前进程的本地GPU设备索引
torch.cuda.set_device(local_rank) # 设置当前进程使用指定的CUDA设备
return local_rank # 返回本地GPU设备索引lm_checkpoint:保存或加载模型检查点
python
from torch.nn.parallel import DistributedDataParallel
def lm_checkpoint(lm_config, weight='full_sft', model=None, optimizer=None, epoch=0, step=0, wandb=None, save_dir='../checkpoints', **kwargs):
"""
保存或加载模型检查点
该函数具有两种模式:
1. 保存模式(model参数不为None):保存模型权重、优化器状态、训练进度等信息
2. 加载模式(model参数为None):从指定路径加载之前保存的检查点数据
Args:
lm_config (MiniMindConfig): 模型配置对象,用于获取模型参数
weight (str, optional): 权重文件前缀名,默认为'full_sft'
model (MiniMindForCausalLM, optional): 要保存的模型对象,默认为None
optimizer (torch.optim.Optimizer, optional): 要保存的优化器对象,默认为None
epoch (int, optional): 当前训练轮次,默认为0
step (int, optional): 当前训练步数,默认为0
wandb (WandbRun, optional): Weights & Biases运行实例,用于记录运行ID,默认为None
save_dir (str, optional): 检查点保存目录,默认为'../checkpoints'
**kwargs: 额外要保存的关键字参数,支持保存具有state_dict方法的对象
Returns:
dict or None:
- 如果是加载模式且找到检查点文件,返回包含模型状态的字典
- 如果是加载模式但未找到检查点文件,返回None
- 如果是保存模式,返回None
"""
os.makedirs(save_dir, exist_ok=True) # 创建保存目录(如果不存在)
moe_path = '_moe' if lm_config.use_moe else '' # 根据是否使用MOE架构生成文件后缀
ckp_path = f'{save_dir}/{weight}_{lm_config.hidden_size}{moe_path}.pth' # 构建模型权重文件路径
resume_path = f'{save_dir}/{weight}_{lm_config.hidden_size}{moe_path}_resume.pth' # 构建训练恢复文件路径
if model is not None: # 保存模式
raw_model = model.module if isinstance(model, DistributedDataParallel) else model # 获取原始模型
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict() # 获取模型状态字典
state_dict = {k: v.half().cpu() for k, v in state_dict.items()} # 将模型权重转换为半精度并移动到CPU,减少存储占用
ckp_tmp = ckp_path + '.tmp' # 使用临时文件保存,避免保存过程中中断导致文件损坏
torch.save(state_dict, ckp_tmp)
os.replace(ckp_tmp, ckp_path) # 原子性替换临时文件为正式文件
wandb_id = None # 获取wandb运行ID
if wandb:
if hasattr(wandb, 'get_run'):
run = wandb.get_run()
wandb_id = getattr(run, 'id', None) if run else None
else:
wandb_id = getattr(wandb, 'id', None)
resume_data = { # 准备恢复数据字典
'model': state_dict, # 模型权重
'optimizer': optimizer.state_dict(), # 优化器状态
'epoch': epoch, # 当前轮次
'step': step, # 当前步数
'world_size': dist.get_world_size() if dist.is_initialized() else 1, # 分布式训练的进程数
'wandb_id': wandb_id # wandb运行ID
}
for key, value in kwargs.items(): # 处理额外的关键字参数
if value is not None:
if hasattr(value, 'state_dict'): # 如果是具有state_dict方法的对象
raw_value = value.module if isinstance(value, DistributedDataParallel) else value # 获取原始对象
raw_value = getattr(raw_value, '_orig_mod', raw_value)
resume_data[key] = raw_value.state_dict()
else: # 如果是普通对象
resume_data[key] = value
resume_tmp = resume_path + '.tmp' # 保存恢复数据到临时文件
torch.save(resume_data, resume_tmp)
os.replace(resume_tmp, resume_path) # 原子性替换临时文件为正式文件
del state_dict, resume_data # 释放内存
torch.cuda.empty_cache() # 清理CUDA缓存
else: # 加载模式
if os.path.exists(resume_path): # 检查恢复文件是否存在
ckp_data = torch.load(resume_path, map_location='cpu') # 加载检查点数据
saved_ws = ckp_data.get('world_size', 1) # 获取保存时的GPU数量
current_ws = dist.get_world_size() if dist.is_initialized() else 1 # 获取当前的GPU数量
if saved_ws != current_ws: # 如果GPU数量变化,调整训练步数
ckp_data['step'] = ckp_data['step'] * saved_ws // current_ws
Logger(f'GPU数量变化({saved_ws}→{current_ws}),step已自动转换为{ckp_data["step"]}')
return ckp_data # 返回加载的检查点数据
return None # 如果恢复文件不存在,返回Noneinit_model: 初始化语言模型和分词器
python
from transformers import AutoTokenizer
def init_model(lm_config, from_weight='pretrain', tokenizer_path='../model', save_dir='../out', device='cuda'):
"""
初始化语言模型和分词器
该函数负责创建语言模型实例、加载分词器、加载预训练权重(如果指定),并返回准备好的模型和分词器对象。
Args:
lm_config (MiniMindConfig): 模型配置对象,包含模型的各种参数设置
from_weight (str, optional): 要加载的权重类型或文件名前缀,默认为'pretrain'
- 'none': 不加载任何预训练权重
- 其他值: 作为权重文件的前缀,从save_dir加载对应的权重文件
tokenizer_path (str, optional): 分词器模型路径,默认为'../model'
save_dir (str, optional): 权重文件保存目录,默认为'../out'
device (str, optional): 模型运行设备,默认为'cuda'
Returns:
tuple:
- model (MiniMindForCausalLM): 初始化并加载了权重的语言模型实例,已移动到指定设备
- tokenizer (AutoTokenizer): 加载的分词器实例
"""
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path) # 加载预训练的分词器
model = MiniMindForCausalLM(lm_config) # 根据配置创建语言模型实例
if from_weight!= 'none': # 如果需要加载预训练权重(from_weight不为'none')
moe_suffix = '_moe' if lm_config.use_moe else '' # 根据是否使用MOE架构生成文件后缀
weight_path = f'{save_dir}/{from_weight}_{lm_config.hidden_size}{moe_suffix}.pth' # 构建权重文件路径
weights = torch.load(weight_path, map_location=device) # 加载权重文件到指定设备
model.load_state_dict(weights, strict=False) # 将权重加载到模型中,strict=False表示允许部分权重不匹配
get_model_params(model, lm_config) # 打印模型参数信息(总参数量和活跃参数量)
Logger(f'Trainable Params: {sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f}M') # 计算并打印可训练参数数量
return model.to(device), tokenizer # 将模型移动到指定设备并返回模型和分词器get_model_params: 计算并打印模型的参数信息
python
def get_model_params(model, config):
"""
计算并打印模型的参数信息
该函数负责计算模型的总参数量、活跃参数量(对于MOE架构)等信息,并以友好的格式打印出来。
对于MOE架构,会分别计算基础参数、专家参数和活跃参数,并打印总参数和活跃参数;
对于非MOE架构,只打印总参数。
Args:
model (MiniMindForCausalLM): 要计算参数的模型实例
config (MiniMindConfig): 模型配置对象,用于获取MOE相关参数
"""
total = sum(p.numel() for p in model.parameters()) / 1e6 # 计算模型总参数量(百万单位)
n_routed = getattr(config, 'n_routed_experts', getattr(config, 'num_experts', 0)) # 获取路由专家数量
n_active = getattr(config, 'num_experts_per_tok', 0) # 获取每个token激活的专家数量
n_shared = getattr(config, 'n_shared_experts', 0) # 获取共享专家数量
expert = sum(p.numel() for n, p in model.named_parameters() if 'mlp.experts.0.' in n) / 1e6 # 计算单个路由专家的参数量
shared_expert = sum(p.numel() for n, p in model.named_parameters() if 'mlp.shared_experts.0.' in n) / 1e6 # 计算单个共享专家的参数量
base = total - (expert * n_routed) - (shared_expert * n_shared) # 计算基础参数量
active = base + (expert * n_active) + (shared_expert * n_shared) # 计算活跃参数量
if active < total: # 根据是否是MOE架构打印不同格式的参数信息
Logger(f'Model Params: {total:.2f}M-A{active:.2f}M')
else: # 非MOE架构
Logger(f'Model Params: {total:.2f}M')get_lr: 计算余弦退火学习率,是一种动态学习率调度策略,其目的是为了让学习率随训练步数按「余弦函数的形状」周期性/单调衰减,以适配模型训练的不同阶段需求
l r t = l r 0 × ( 0.1 + 0.45 × ( 1 + cos ( π × t T ) ) ) lr_{t} = lr_{0} \times \left(0.1 + 0.45 \times \left(1 + \cos\left(\pi \times \frac{t}{T}\right)\right)\right) lrt=lr0×(0.1+0.45×(1+cos(π×Tt)))
python
def get_lr(current_step, total_steps, lr):
"""
计算余弦退火学习率
该函数实现了余弦退火学习率调度策略,学习率从初始值开始,按照余弦函数的形状逐渐衰减。
这种调度策略可以使学习率在训练初期较大,有助于快速收敛,后期逐渐减小,有助于模型稳定。
Args:
current_step (int): 当前训练步数
total_steps (int): 总训练步数
lr (float): 初始学习率
Returns:
float: 当前步骤的学习率
"""
# 计算余弦退火学习率
return lr*(0.1 + 0.45*(1 + math.cos(math.pi * current_step / total_steps)))最后,跟踪代码来对训练函数
python
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
"""
执行模型预训练的一个完整轮次
该函数负责在指定的数据集上执行一个轮次的训练,包括:
1. 遍历数据加载器获取训练样本
2. 动态调整学习率
3. 前向传播计算损失(包括主损失和辅助损失)
4. 反向传播和梯度累积更新
5. 记录训练日志和保存模型检查点
Args:
epoch (int): 当前训练轮次的索引(从0开始)
loader (DataLoader): 训练数据加载器,提供批量的训练样本
iters (int): 每轮训练的总迭代次数
start_step (int, optional): 本轮训练的起始迭代步骤,默认为0
wandb (WandbRun, optional): Weights & Biases的运行实例,用于记录训练指标
"""
start_time = time.time() # 记录本轮训练的开始时间
# 遍历数据加载器,获取每批训练数据
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device) # 将输入数据和标签移动到指定设备
labels = labels.to(args.device)
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate) # 根据当前步数计算学习率
for param_group in optimizer.param_groups: # 更新优化器的学习率
param_group['lr'] = lr
with autocast_ctx: # 使用自动混合精度上下文管理器进行前向传播
res = model(input_ids, labels=labels) # 模型前向传播,计算损失
loss = res.loss + res.aux_loss # 总损失 = 主损失 + 辅助损失
loss = loss / args.accumulation_steps # 将损失除以梯度累积步数,用于梯度累积训练
scaler.scale(loss).backward() # 使用梯度缩放器进行反向传播,避免梯度下溢
if (step + 1) % args.accumulation_steps == 0: # 当迭代步数达到梯度累积步数时,执行参数更新
scaler.unscale_(optimizer) # 取消梯度缩放,以便进行梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) # 梯度裁剪,防止梯度爆炸
scaler.step(optimizer) # 执行优化器步骤,更新模型参数
scaler.update() # 更新梯度缩放器的缩放因子
optimizer.zero_grad(set_to_none=True) # 清除优化器的梯度
# 定期记录训练日志
if step % args.log_interval == 0 or step == iters - 1:
spend_time = time.time() - start_time # 计算已花费的训练时间
current_loss = loss.item() * args.accumulation_steps # 计算实际损失值
current_aux_loss = res.aux_loss.item() if res.aux_loss is not None else 0.0 # 计算辅助损失值
current_logits_loss = current_loss - current_aux_loss # 计算主损失值
current_lr = optimizer.param_groups[-1]['lr'] # 获取当前学习率
eta_min = spend_time / (step + 1) * iters // 60 - spend_time // 60 # 估计剩余训练时间(分钟)
# 打印训练日志
Logger(f'Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}), loss: {current_loss:.4f}, logits_loss: {current_logits_loss:.4f}, aux_loss: {current_aux_loss:.4f}, lr: {current_lr:.8f}, epoch_time: {eta_min:.1f}min')
# 如果使用wandb,记录训练指标
if wandb: wandb.log({"loss": current_loss, "logits_loss": current_logits_loss, "aux_loss": current_aux_loss, "learning_rate": current_lr, "epoch_time": eta_min})
# 定期保存模型检查点
if (step % args.save_interval == 0 or step == iters - 1) and is_main_process():
model.eval() # 将模型设置为评估模式
moe_suffix = '_moe' if lm_config.use_moe else '' # 根据是否使用MOE生成模型后缀
ckp = f'{args.save_dir}/{args.save_weight}_{lm_config.hidden_size}{moe_suffix}.pth' # 构建模型保存路径
raw_model = model.module if isinstance(model, DistributedDataParallel) else model # 获取原始模型(处理分布式和包装情况)
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict() # 获取模型状态字典
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp) # 保存模型权重(半精度,移动到CPU)
lm_checkpoint(lm_config, weight=args.save_weight, model=model, optimizer=optimizer, scaler=scaler, epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints') # 保存完整的训练检查点
model.train() # 将模型恢复为训练模式
del state_dict # 删除状态字典,释放内存
del input_ids, labels, res, loss # 删除当前批处理的数据和中间结果,释放内存有监督微调STF(Supervised Fine-Tuning)
监督微调,则开始让识字的孩子学习如何对话!
预训练阶段是通用知识
监督微调阶段是专属任务适配
本质上,其核心是数据集的不同
知识蒸馏KD(Knowledge Distillation)
知识蒸馏,是为了将把大模型学到的规律与概率分布,迁移给小模型,让小模型又小又强。
早在20世界90年代,就存在了具有知识传递机制的师生网络(Teacher-Student)的结构,这种结构是知识蒸馏的核心。
千禧之后,Model compression论文,证明了集成模型可压缩为单个小模型且精度损失极小,这是知识蒸馏的技术前身。
随后,深度学习爆发,模型越来越大,但部署受算力和内存的限制,大模型训练、小模型部署的需求日益迫切,为知识蒸馏的正式提出创造了时代背景。
论文Distilling the Knowledge in a Neural Network应运而生,正式定义了知识蒸馏,采用了 软标签 + 温度系数 + 双损失训练 来优化学生模型,奠定了KD的核心框架。
解析代码:
python
def distillation_loss(student_logits, teacher_logits, temperature=1.0, reduction='batchmean'):
"""计算知识蒸馏损失
Args:
student_logits: 学生模型的输出logits
teacher_logits: 教师模型的输出logits
temperature: 温度参数,控制知识蒸馏的平滑程度
reduction: 损失的归约方式
Returns:
kl: 计算得到的蒸馏损失
"""
with torch.no_grad(): # 计算教师模型的概率分布
teacher_probs = F.softmax(teacher_logits / temperature, dim=-1).detach()
student_log_probs = F.log_softmax(student_logits / temperature, dim=-1) # 计算学生模型的对数概率分布
kl = F.kl_div( # 计算KL散度损失
student_log_probs,
teacher_probs,
reduction=reduction
)
return (temperature ** 2) * kl # 乘以温度的平方进行缩放
def train_epoch(epoch, loader, iters, teacher_model, lm_config_student, start_step=0, wandb=None, alpha=0.0, temperature=1.0):
"""训练一个epoch的知识蒸馏
Args:
epoch: 当前训练轮次
loader: 数据加载器
iters: 训练迭代次数
teacher_model: 教师模型
lm_config_student: 学生模型的配置
start_step: 起始步数
wandb: Weights & Biases对象,用于日志记录
alpha: CE损失的权重
temperature: 知识蒸馏的温度参数
"""
start_time = time.time() # 记录开始时间
if teacher_model is not None: # 设置教师模型为评估模式(不需要梯度)
teacher_model.eval()
teacher_model.requires_grad_(False)
# 遍历数据加载器
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device) # 将数据移到指定设备
labels = labels.to(args.device)
loss_mask = (labels[..., 1:] != -100).float() # 计算损失掩码(忽略-100标签)
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate) # 计算当前学习率
for param_group in optimizer.param_groups: # 更新优化器学习率
param_group['lr'] = lr
with autocast_ctx: # 前向传播(学生模型)
res = model(input_ids)
student_logits = res.logits[..., :-1, :].contiguous() # 获取学生模型的logits(去除最后一个token)
if teacher_model is not None: # 教师模型前向传播(只在eval & no_grad)
with torch.no_grad():
teacher_logits = teacher_model(input_ids).logits[..., :-1, :].contiguous() # 获取教师模型的logits(去除最后一个token)
vocab_size_student = student_logits.size(-1) # 确保教师模型和学生模型的词汇表大小一致
teacher_logits = teacher_logits[..., :vocab_size_student]
# ========== 计算损失 ==========
# 1) Ground-Truth CE Loss
shift_labels = labels[..., 1:].contiguous() # 偏移标签
loss_mask_flat = loss_mask.view(-1) # 展平损失掩码
ce_loss = F.cross_entropy( # 计算交叉熵损失
student_logits.view(-1, student_logits.size(-1)),
shift_labels.view(-1),
ignore_index=-100,
reduction='none'
)
ce_loss_raw = torch.sum(ce_loss * loss_mask_flat) / (loss_mask_flat.sum() + 1e-8) # 计算平均CE损失(考虑掩码)
if lm_config_student.use_moe: ce_loss = ce_loss_raw + res.aux_loss # 如果使用MoE,添加辅助损失
else: ce_loss = ce_loss_raw
# 2) Distillation Loss
if teacher_model is not None:
distill_loss = distillation_loss( # 计算知识蒸馏损失
student_logits.view(-1, student_logits.size(-1))[loss_mask_flat == 1],
teacher_logits.view(-1, teacher_logits.size(-1))[loss_mask_flat == 1],
temperature=temperature
)
else:
distill_loss = torch.tensor(0.0, device=args.device) # 如果没有教师模型,蒸馏损失为0
# 3) 总损失 = alpha * CE + (1-alpha) * Distill
loss = (alpha * ce_loss + (1 - alpha) * distill_loss) / args.accumulation_steps
scaler.scale(loss).backward() # 反向传播
if (step + 1) % args.accumulation_steps == 0: # 梯度累积更新
scaler.unscale_(optimizer) # 取消梯度缩放
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) # 梯度裁剪
scaler.step(optimizer) # 更新参数
scaler.update() # 更新缩放器
optimizer.zero_grad(set_to_none=True) # 清空梯度
if step % args.log_interval == 0 or step == iters - 1: # 打印日志
spend_time = time.time() - start_time # 计算已花费时间
current_loss = loss.item() * args.accumulation_steps # 计算当前损失
current_ce_loss = ce_loss_raw.item()
current_aux_loss = res.aux_loss.item() if lm_config_student.use_moe else 0.0
current_lr = optimizer.param_groups[-1]['lr']
eta_min = spend_time / (step + 1) * iters // 60 - spend_time // 60 # 估算剩余时间
# 打印日志
Logger(f'Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}), loss: {current_loss:.4f}, ce: {current_ce_loss:.4f}, aux_loss: {current_aux_loss:.4f}, distill: {distill_loss.item():.4f}, learning_rate: {current_lr:.8f}, epoch_time: {eta_min:.3f}min')
if wandb: # 如果使用wandb,记录日志
wandb.log({
"loss": current_loss,
"ce_loss": current_ce_loss,
"aux_loss": current_aux_loss,
"distill_loss": distill_loss.item() if teacher_model is not None else 0.0,
"learning_rate": current_lr,
"epoch_time": eta_min
})
# 保存模型
if (step % args.save_interval == 0 or step == iters - 1) and is_main_process():
model.eval() # 切换到评估模式
moe_suffix = '_moe' if lm_config_student.use_moe else '' # 生成MoE后缀
ckp = f'{args.save_dir}/{args.save_weight}_{lm_config_student.hidden_size}{moe_suffix}.pth' # 构建保存路径
raw_model = model.module if isinstance(model, DistributedDataParallel) else model # 获取原始模型
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict() # 获取模型状态字典
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp) # 保存模型(半精度)
lm_checkpoint(lm_config_student, weight=args.save_weight, model=model, optimizer=optimizer, scaler=scaler, epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints') # 保存检查点
model.train() # 切换回训练模式
del state_dict # 清理内存
# 清理内存
del input_ids, labels, loss_mask, res, student_logits, ce_loss, distill_loss, loss可以看到,代码逻辑完全是教师模型教授学生模型。
实际上,现在学术界中,教师学生模型不仅仅在LLM领域,其他领域都有其身影,因为这种知识传递机制可以很好放置在需要信息传递的场景中,比如联邦学习,就存在着通过教师模型传递聚合信息的手段。
不仅仅在场景上,教师学生模型本身也在进化,分层蒸馏(Layer-wise Distillation) 和级联蒸馏(Cascaded Distillation)是目前前沿方向,分别适用不同的场景。
- 分层蒸馏,将教师模型划分为块,每块教授学生模型中对应的块,每块独立计算损失
- 级联蒸馏,适用于极端场景,将较大模型作为教师模型,教授中间模型,待中间模型学习后,中间模型教授小模型,迭代的传递知识,小模型也能具有高性能
LoRA (Low-Rank Adaptation)
试想一种这样的场景,通用大模型虽然智力能力较强,但是在面临专业性强的领域,可能会出现误差,那么有没有什么方式,可以让大模型适配于某个特定的专业领域(垂直领域中的垂直大模型
当然有,LoRA便是一种在已训练好的大模型上进行微小调试的手段,这种微调技术基本不需要消耗太高的性能、显存等。
这是因为LoRA通过通过插入少量的低秩矩阵来适配垂直领域任务,如下是LoRA的公式:
output = x ⋅ W + x ⋅ ( α r ⋅ A ⋅ B ) = x ⋅ ( W + α r ⋅ A ⋅ B ) \text{output} = x \cdot W + x \cdot \left(\frac{\alpha}{r} \cdot A \cdot B\right) = x \cdot \left(W + \frac{\alpha}{r} \cdot A \cdot B\right) output=x⋅W+x⋅(rα⋅A⋅B)=x⋅(W+rα⋅A⋅B)
式 x ⋅ W x \cdot W x⋅W是模型原本的输出,后面是LoRA微调结果,矩阵 A A A和 B B B维度分别是 d × r d×r d×r和 r × d r×d r×d, r r r是LoRA超参数秩,通常取一个较低的值如8,可以极大的节省训练成本
以下我们快速训练,训练轮数不建议使用默认50轮(测试发现未训练好,没有给出想要的结果)。同时,可以对比使用LoRA以及未使用LoRA的效果,有很明显的区别
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_lora.py --epochs=500
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
Trainable Params: 25.830M
LLM 总参数量: 25.961 M
LoRA 参数量: 0.131 M
LoRA 参数占比: 0.50%
Epoch:[1/500](2/3), loss: 3.3150, logits_loss: 3.3150, aux_loss: 0.0000, lr: 0.00010000, epoch_time: 0.0min
Epoch:[2/500](2/3), loss: 3.4670, logits_loss: 3.4670, aux_loss: 0.0000, lr: 0.00010000, epoch_time: 0.0min
.....................................................................................................................................................................................................................
Epoch:[499/500](2/3), loss: 0.5381, logits_loss: 0.5381, aux_loss: 0.0000, lr: 0.00001000, epoch_time: 0.0min
Epoch:[500/500](2/3), loss: 0.5650, logits_loss: 0.5650, aux_loss: 0.0000, lr: 0.00001000, epoch_time: 0.0min
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# cd ..
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight=full_sft --lora_weight=lora_identity
Model Params: 25.96M
[0] 自动测试
[1] 手动输入
1
💬: 你好
🤖: 您好,我是 MiniMind,一个由 Jingyao Gong 开发的人工智能助手,我可以回答您任何问题,提供知识和信息,我会尽力帮助您完成。
[Speed]: 69.47 tokens/s
💬: 你是谁?
🤖: 您好,我是 MiniMind,由 Jingyao Gong 开发。我可以用自然语言描述为一个聪明和富有创造力的AI,或者是一名有用的工作人员。
[Speed]: 135.12 tokens/s
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight=full_sft
Model Params: 25.83M
[0] 自动测试
[1] 手动输入
1
💬: 你好
🤖: 你好!我能帮你解答关于任何问题,无论是数学问题、日常生活、娱乐、科技、生活还是其他任何主题。请随时告诉我,我会尽力提供帮助。
[Speed]: 66.17 tokens/s
💬: 你是谁?
🤖: 我是中小学的高中生,也是中学的高中。我是一名大学生,我在大学时就读于计算机科学,对计算机科学有着浓厚的兴趣。我还在大学中学,对计算机科学和计算机技术有深厚的兴趣。
[Speed]: 145.26 tokens/s同时,我们也可以在垂直领域医疗场景进行LoRA微调,可以看到通用型大模型在垂直领域中表现的非常好
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_lora.py --epochs=50 --lora_name=lora_medical --data_path=../dataset/lora_medical.jsonl
.....................................................................................................................................................................................................................
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# cd ..
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight=full_sft --lora_weight=lora_medical
Model Params: 25.96M
[0] 自动测试
[1] 手动输入
1
💬: 我总是空想一些不切实际的事情,如何才能抑制它
🤖: 我很抱歉听到你的感受。
1. 睡眠质量:睡眠质量指的是程序员在工作和休息中,可以帮助他们放松和恢复。这是因为你需要保持良好的作息习惯,以帮助身体恢复。
2. 心理健康:睡眠质量指的是个体在面对压力或情绪问题时,可以得到充足的休息和恢复。这可能包括:
1. 学习新技能:这可能包括学习新的技能、语言技能、兴趣爱好等。
2. 保持良好的生活习惯:包括均衡饮食、适量运动、保持良好的睡眠习惯等。
3. 保持良好的睡眠:睡眠可以帮助身体恢复,包括改善睡眠质量。
4. 定期检查:检查是否有恢复期或者更长的错误信息。
5. 保持身心健康:保持良好的身体健康状态可以帮助身体恢复,减少对身体的伤害。
6. 避免长时间工作,保持心态平和。
7. 避免过度使用电子产品,因为这些设备可能会影响身体的健康状况。
8. 保持良好的睡眠习惯,包括每晚睡眠7-8小时,以避免在睡眠中失去动力。
如果你的问题持续存在,我建议你寻求医疗帮助。医生可能会建议你进行更多的检查和诊断,以确定是否需要缓解症状。如果你的症状持续存在或者不明原因,或者有其他症状,如发烧、恶心、呕吐、食欲不振。你应该立即寻求医疗帮助,因为你的症状。
[Speed]: 123.77 tokens/s
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight=full_sft
Model Params: 25.83M
[0] 自动测试
[1] 手动输入
1
💬: 我总是空想一些不切实际的事情,如何才能抑制它
🤖: 我理解您的困惑和困惑。尝试从不同的角度去看待问题,这有助于我找到更有效的解决方案。尝试去了解和实践您的问题,并尝试与同事和客户保持联系。此外,与同事沟通,分享他们的经验和想法,以帮助他们更好地解决问题和解决问题。最重要的是,保持积极的心态,相信自己能够克服困难,实现自己的目标。
[Speed]: 95.09 tokens/s解析代码(代码很简单,只需要解析模型这部分即可):
python
import torch
from torch import optim, nn
# 定义Lora网络结构
class LoRA(nn.Module):
"""LoRA(Low-Rank Adaptation)层
LoRA通过低秩分解来减少可训练参数的数量,
同时保持模型的性能。
"""
def __init__(self, in_features, out_features, rank):
super().__init__()
self.rank = rank # 保存秩
self.A = nn.Linear(in_features, rank, bias=False) # 创建线性层A(输入维度 -> 低秩维度)
self.B = nn.Linear(rank, out_features, bias=False) # 创建线性层B(低秩维度 -> 输出维度)
self.A.weight.data.normal_(mean=0.0, std=0.02) # 矩阵A高斯初始化
self.B.weight.data.zero_() # 矩阵B全0初始化
def forward(self, x):
return self.B(self.A(x)) # 先通过线性层A,再通过线性层B
def apply_lora(model, rank=8):
"""为模型应用LoRA(Low-Rank Adaptation)
Args:
model: 要应用LoRA的模型
rank: LoRA的秩,默认为8
"""
# 遍历模型的所有模块
for name, module in model.named_modules():
if isinstance(module, nn.Linear) and module.weight.shape[0] == module.weight.shape[1]: # 只对线性层且权重矩阵为方阵的模块应用LoRA
lora = LoRA(module.weight.shape[0], module.weight.shape[1], rank=rank).to(model.device) # 创建LoRA层并移到模型所在设备
setattr(module, "lora", lora) # 将LoRA层添加到模块中
original_forward = module.forward # 保存原始的forward方法
def forward_with_lora(x, layer1=original_forward, layer2=lora): # 显式绑定变量,避免闭包问题
return layer1(x) + layer2(x) # 原始输出加上LoRA输出
module.forward = forward_with_lora # 替换模块的forward方法
def load_lora(model, path):
"""加载LoRA权重到模型
Args:
model: 要加载LoRA权重的模型
path: LoRA权重文件路径
"""
state_dict = torch.load(path, map_location=model.device) # 加载权重文件
state_dict = {(k[7:] if k.startswith('module.') else k): v for k, v in state_dict.items()} # 处理分布式训练的权重键名(去除module.前缀)
# 遍历模型的所有模块
for name, module in model.named_modules():
if hasattr(module, 'lora'): # 只处理有LoRA层的模块
lora_state = {k.replace(f'{name}.lora.', ''): v for k, v in state_dict.items() if f'{name}.lora.' in k} # 提取当前模块的LoRA权重
module.lora.load_state_dict(lora_state) # 加载LoRA权重
def save_lora(model, path):
"""保存模型的LoRA权重
Args:
model: 要保存LoRA权重的模型
path: LoRA权重保存路径
"""
raw_model = getattr(model, '_orig_mod', model) # 获取原始模型
state_dict = {} # 构建LoRA权重字典
# 遍历模型的所有模块
for name, module in raw_model.named_modules():
if hasattr(module, 'lora'): # 只处理有LoRA层的模块
clean_name = name[7:] if name.startswith("module.") else name # 处理分布式训练的模块名(去除module.前缀)
lora_state = {f'{clean_name}.lora.{k}': v for k, v in module.lora.state_dict().items()} # 构建当前模块的LoRA权重
state_dict.update(lora_state) # 更新权重字典
torch.save(state_dict, path) # 保存LoRA权重推理模型Reasoning Model
推理模型与监督微调模型的区别,实际上最大的不同在于数据集,推理数据集人为加入推理过程,形似:<think>思考过程<\think><answer>回答<\answer>
其训练代码基本与有监督微调训练代码完全复用
如下所示,可以看出推理模型就是现在主流模型都拥有的过程------思维链、思考过程、分步解答
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_reason.py
Model Params: 25.83M
Trainable Params: 25.830M
Generating train split: 190139 examples [00:00, 207831.06 examples/s]
Epoch:[1/1](100/23768), loss: 3.1103, logits_loss: 3.1103, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 11.0min
Epoch:[1/1](200/23768), loss: 3.0004, logits_loss: 3.0004, aux_loss: 0.0000, lr: 0.00000100, epoch_time: 11.0min
.....................................................................................................................................................................................................................
Epoch:[1/1](23700/23768), loss: 2.1536, logits_loss: 2.1536, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min
Epoch:[1/1](23767/23768), loss: 2.5472, logits_loss: 2.5472, aux_loss: 0.0000, lr: 0.00000010, epoch_time: 0.0min
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# cd ..
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master# python eval_llm.py --weight=reason
Model Params: 25.83M
[0] 自动测试
[1] 手动输入
1
💬: 你好
🤖: <think>
嗯,用户问的是"你好"是什么意思。我记得"你好"指的是某个人,可能是某个用户,或者是一个游戏开发者,或者是一个游戏开发者。不过,我需要先仔细看看用户的意图。
首先,我应该考虑用户的使用场景。他们可能在学习编程,或者是对编程感兴趣。他们可能是在学习编程,或者是对技术有兴趣的用户。
接下来,我应该考虑用户可能对某个特定主题感兴趣,所以提供一些信息,比如相关的话题,或者他们想要了解的具体问题。
然后,我要考虑用户的需求。他们可能是在学习编程,或者是想要了解某个领域的知识。可能他们希望了解一些常见的主题,比如编程、科学、技术、文学等等。
另外,用户可能对编程感兴趣,但更喜欢游戏开发者。他们可能希望了解某个项目或项目,或者希望了解一些相关的技能或知识,比如编程、编程或编程。
最后,我应该鼓励用户,他们提供更多相关的信息,以便更全面地了解某个特定主题。这样,用户能够从中学习到更多的知识,进一步提升自己的编程能力。
</think>
<answer>
您好!我是[你的名字],您想了解哪一个领域呢?例如编程、科学、技术、文学等等。
</answer>
[Speed]: 130.68 tokens/s
💬: 我应该怎么学习LLM这项技术呢?
🤖: <think>
嗯,用户问的是要学习LLM这项技术,是不是因为编程而被困在家里。首先,我需要理解用户的需求,他们可能是在学习编程,或者正在学习编程,需要了解编程语言和应用。
接下来,我应该分析用户提供的信息,看看用户可能希望了解具体的学习资源。比如,编程语言可能涉及编程语言的语法和常见的编程语言,或者作为编程教学平台的开发者。用户可能对编程感兴趣,所以我需要提供详细的信息,比如学习的具体步骤、使用的编程语言、使用的编程语言、资源等。
然后,我应该考虑用户可能的深层需求,比如他们是否希望学习编程,或者他们可能正在学习编程。也有可能他们希望了解编程语言和应用,或者他们希望了解如何使用Python或其他编程工具来开发他们的项目。
最后,我应该提醒用户,他们希望了解如何应用这些技术,以便他们可以更好地应用这些技术。同时,我需要确保我的回答不仅准确,还能帮助用户理解编程的基本概念和应用场景,从而更好地进行学习。
</think>
<answer>
关于编程,我需要理解具体的领域和应用。可能需要了解编程语言和应用的相关知识,以及相关的学习资源。
</answer>
[Speed]: 126.73 tokens/s基于人类反馈的强化学习RLHF(Reinforcement Learning from Human Feedback)
如下是直接偏好优化DPO(Direct Preference Optimization)算法的数学公式:
L DPO ( θ ; π ref ) = − log ( σ ( log p θ ( y + ∣ x ) p θ ( y − ∣ x ) − β ) 1 + σ ( log p θ ( y + ∣ x ) p θ ( y − ∣ x ) − β ) ) \mathcal{L}{\text{DPO}}(\theta; \pi{\text{ref}}) = -\log\left(\frac{\sigma\left(\log\frac{p_\theta(y_+|x)}{p_\theta(y_-|x)} - \beta\right)}{1 + \sigma\left(\log\frac{p_\theta(y_+|x)}{p_\theta(y_-|x)} - \beta\right)}\right) LDPO(θ;πref)=−log(1+σ(logpθ(y−∣x)pθ(y+∣x)−β)σ(logpθ(y−∣x)pθ(y+∣x)−β))
实际上,该算法为了让模型更愿意生成人类喜欢的回答,更不愿意生成人类不喜欢的回答。使用了参考模型(原本的STF模型)与训练模型作对比,希望训练模型生成优质答案的"次数"要远远大于参考模型。
如下执行python train_dpo.py命令,运行DPO算法优化大模型
bash
root@p-d057f77da759-ackcs-00gjgekr:~/shared-nvme/minimind-master/trainer# python train_dpo.py
/usr/local/lib/python3.10/dist-packages/torch/utils/_pytree.py:185: FutureWarning: optree is installed but the version is too old to support PyTorch Dynamo in C++ pytree. C++ pytree support is disabled. Please consider upgrading optree using `python3 -m pip install --upgrade 'optree>=0.13.0'`.
warnings.warn(
Model Params: 25.83M
Trainable Params: 25.830M
策略模型总参数量:25.830 M
Model Params: 25.83M
Trainable Params: 25.830M
参考模型总参数量:25.830 M
Generating train split: 17166 examples [00:00, 45643.09 examples/s]
Epoch:[1/1](100/4292), loss: 0.6931, dpo_loss: 0.6931, aux_loss: 0.0000, learning_rate: 0.00000004, epoch_time: 3.000min
Epoch:[1/1](200/4292), loss: 0.6920, dpo_loss: 0.6920, aux_loss: 0.0000, learning_rate: 0.00000004, epoch_time: 3.000min
Epoch:[1/1](300/4292), loss: 0.6928, dpo_loss: 0.6928, aux_loss: 0.0000, learning_rate: 0.00000004, epoch_time: 3.000min
Epoch:[1/1](400/4292), loss: 0.6912, dpo_loss: 0.6912, aux_loss: 0.0000, learning_rate: 0.00000004, epoch_time: 3.000min
.....................................................................................................................................................................................................................
Epoch:[1/1](4000/4292), loss: 0.6939, dpo_loss: 0.6939, aux_loss: 0.0000, learning_rate: 0.00000000, epoch_time: 1.000min
Epoch:[1/1](4100/4292), loss: 0.6923, dpo_loss: 0.6923, aux_loss: 0.0000, learning_rate: 0.00000000, epoch_time: 0.000min
Epoch:[1/1](4200/4292), loss: 0.6940, dpo_loss: 0.6940, aux_loss: 0.0000, learning_rate: 0.00000000, epoch_time: 0.000min
Epoch:[1/1](4291/4292), loss: 0.6915, dpo_loss: 0.6915, aux_loss: 0.0000, learning_rate: 0.00000000, epoch_time: 0.000min执行python eval_llm.py --weight dpo进行交互,不过可以发现因数据集过小、训练轮数较小,所以其与STF模型效果没有发生太大变化
解析代码:
python
def logits_to_log_probs(logits, labels):
"""将logits转换为对数概率
Args:
logits: 模型输出的logits,形状为(batch_size, seq_len, vocab_size)
labels: 真实标签,形状为(batch_size, seq_len)
Returns:
log_probs_per_token: 每个标签对应的对数概率,形状为(batch_size, seq_len)
"""
log_probs = F.log_softmax(logits, dim=2) # 计算logits的对数softmax,得到每个token的对数概率分布
log_probs_per_token = torch.gather(log_probs, dim=2, index=labels.unsqueeze(2)).squeeze(-1) # 从对数概率分布中提取对应标签的对数概率
return log_probs_per_token # 返回每个标签的对数概率
def dpo_loss(ref_log_probs, policy_log_probs, mask, beta):
"""计算DPO(Direct Preference Optimization)损失
Args:
ref_log_probs: 参考模型的对数概率,形状为(batch_size, seq_len)
policy_log_probs: 策略模型的对数概率,形状为(batch_size, seq_len)
mask: 注意力掩码,形状为(batch_size, seq_len)
beta: DPO损失的温度参数
Returns:
loss: DPO损失值
"""
seq_lengths = mask.sum(dim=1, keepdim=True).clamp_min(1e-8) # 计算每个样本的序列长度,并确保不为零(防止除零NaN)
ref_log_probs = (ref_log_probs * mask).sum(dim=1) / seq_lengths.squeeze() # 计算参考模型的平均对数概率(考虑掩码)
policy_log_probs = (policy_log_probs * mask).sum(dim=1) / seq_lengths.squeeze() # 计算策略模型的平均对数概率(考虑掩码)
batch_size = ref_log_probs.shape[0] # 将 chosen 和 rejected 数据分开
chosen_ref_log_probs = ref_log_probs[:batch_size // 2]
reject_ref_log_probs = ref_log_probs[batch_size // 2:]
chosen_policy_log_probs = policy_log_probs[:batch_size // 2]
reject_policy_log_probs = policy_log_probs[batch_size // 2:]
pi_logratios = chosen_policy_log_probs - reject_policy_log_probs # 计算策略模型的对数比率(chosen vs rejected)
ref_logratios = chosen_ref_log_probs - reject_ref_log_probs # 计算参考模型的对数比率(chosen vs rejected)
logits = pi_logratios - ref_logratios # 计算最终的logits
loss = -F.logsigmoid(beta * logits) # 计算DPO损失(负的sigmoid对数似然)
return loss.mean() # 返回平均损失
def train_epoch(epoch, loader, iters, ref_model, lm_config, start_step=0, wandb=None, beta=0.1):
"""训练一个epoch的DPO
Args:
epoch: 当前训练轮次
loader: 数据加载器
iters: 训练迭代次数
ref_model: 参考模型
lm_config: 语言模型配置
start_step: 起始步数
wandb: Weights & Biases对象,用于日志记录
beta: DPO损失的温度参数
"""
start_time = time.time() # 记录开始时间
# 遍历数据加载器
for step, batch in enumerate(loader, start=start_step + 1):
# 将数据移到指定设备
x_chosen = batch['x_chosen'].to(args.device)
x_rejected = batch['x_rejected'].to(args.device)
y_chosen = batch['y_chosen'].to(args.device)
y_rejected = batch['y_rejected'].to(args.device)
mask_chosen = batch['mask_chosen'].to(args.device)
mask_rejected = batch['mask_rejected'].to(args.device)
# 合并chosen和rejected数据
x = torch.cat([x_chosen, x_rejected], dim=0)
y = torch.cat([y_chosen, y_rejected], dim=0)
mask = torch.cat([mask_chosen, mask_rejected], dim=0)
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate) # 计算当前学习率
for param_group in optimizer.param_groups: # 更新优化器学习率
param_group['lr'] = lr
with autocast_ctx: # 使用自动混合精度
with torch.no_grad(): # 参考模型前向传播
ref_outputs = ref_model(x)
ref_logits = ref_outputs.logits
ref_log_probs = logits_to_log_probs(ref_logits, y) # 计算参考模型的对数概率
outputs = model(x) # 策略模型前向传播
logits = outputs.logits
policy_log_probs = logits_to_log_probs(logits, y) # 计算策略模型的对数概率
dpo_loss_val = dpo_loss(ref_log_probs, policy_log_probs, mask, beta=beta) # 计算DPO损失
loss = dpo_loss_val + outputs.aux_loss # 计算总损失(DPO损失 + 辅助损失)
loss = loss / args.accumulation_steps # 除以梯度累积步数
scaler.scale(loss).backward() # 反向传播
if (step + 1) % args.accumulation_steps == 0: # 梯度累积更新
scaler.unscale_(optimizer) # 取消梯度缩放
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) # 梯度裁剪
scaler.step(optimizer) # 更新参数
scaler.update() # 更新缩放器
optimizer.zero_grad(set_to_none=True) # 清空梯度
if step % args.log_interval == 0 or step == iters - 1: # 打印日志
spend_time = time.time() - start_time # 计算已花费时间
# 计算当前损失
current_loss = loss.item() * args.accumulation_steps
current_dpo_loss = dpo_loss_val.item()
current_aux_loss = outputs.aux_loss.item()
current_lr = optimizer.param_groups[-1]['lr']
# 估算剩余时间
eta_min = spend_time / (step + 1) * iters // 60 - spend_time // 60
# 打印日志
Logger(f'Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}), loss: {current_loss:.4f}, dpo_loss: {current_dpo_loss:.4f}, aux_loss: {current_aux_loss:.4f}, learning_rate: {current_lr:.8f}, epoch_time: {eta_min:.3f}min')
if wandb: wandb.log({"loss": current_loss, "dpo_loss": current_dpo_loss, "aux_loss": current_aux_loss, "learning_rate": current_lr, "epoch_time": eta_min})
if (step % args.save_interval == 0 or step == iters - 1) and is_main_process(): # 保存模型
model.eval() # 切换到评估模式
moe_suffix = '_moe' if lm_config.use_moe else '' # 生成MoE后缀
ckp = f'{args.save_dir}/{args.save_weight}_{lm_config.hidden_size}{moe_suffix}.pth' # 构建保存路径
raw_model = model.module if isinstance(model, DistributedDataParallel) else model # 获取原始模型
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict() # 获取模型状态字典
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp) # 保存模型(半精度)
lm_checkpoint(lm_config, weight=args.save_weight, model=model, optimizer=optimizer, scaler=scaler, epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints') # 保存检查点
model.train() # 切换回训练模式
del state_dict # 清理内存
# 清理内存
del x_chosen, x_rejected, y_chosen, y_rejected, mask_chosen, mask_rejected, x, y, mask
del ref_outputs, ref_logits, ref_log_probs, outputs, logits, policy_log_probs, loss基于AI反馈的强化学习RLAIF(Reinforcement Learning from AI Feedback)
自Deep reinforcement learning from human preferences论文提出了RLHF,让人类直接定义什么是好,避免了传统RL极其依赖手工设计奖励函数。随后,RLHF慢慢迁移到其他领域,而后论文Training language models to follow instructions with human feedback,在工业上定义了RLHF流程,但由于RLHF成本极高,需要人类手动标注数据。
论文Constitutional AI: Harmlessness from AI Feedback为了解决RLHF的缺点,提出了RLAIF,用更强的LLM替代人类标注员,生成偏好反馈,是第二代大模型对齐技术,大幅度降低数据成本。
而RLAIF所使用的核心强化学习算法也经历着不断的变化
- Proximal Policy Optimization,PPO,强化学习算法领域的经典算法,在大模型兴起之后,也是大模型对齐的核心:
L P P O = E min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) − c 1 L V F + c 2 D K L ( π old ∥ π θ ) L_{PPO} = \mathbb{E}\left \\min\\left(r_t(\\theta) A_t, \\text{clip}(r_t(\\theta), 1-\\epsilon, 1+\\epsilon) A_t\\right) - c_1 L_{VF} + c_2 D_{KL}(\\pi_{\\text{old}} \\\|\\pi_{\\theta})\\right LPPO=Emin(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)−c1LVF+c2DKL(πold∥πθ)
其与传统的Actor-Critic算法的TD更新步骤多了裁剪,以及添加了正则项
- 论文DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models为了解决PPO中存在的奖励稀疏、生成漂移和更新震荡问题,添加了引导奖励作为另一种正则化去抑制这些问题
L GRPO = E min ( r t ( θ ) A \~ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A \~ t ) − c 1 L V F + c 2 D K L ( π old ∥ π θ ) + c 3 L guide L_{\text{GRPO}} = \mathbb{E}\left \\min\\left(r_t(\\theta) \\tilde{A}_t, \\text{clip}(r_t(\\theta), 1-\\epsilon, 1+\\epsilon) \\tilde{A}_t\\right) - c_1 L_{VF} + c_2 D_{KL}(\\pi_{\\text{old}} \\\|\\pi_{\\theta}) + c_3 L_{\\text{guide}}\\right LGRPO=Emin(rt(θ)A\~t,clip(rt(θ),1−ϵ,1+ϵ)A\~t)−c1LVF+c2DKL(πold∥πθ)+c3Lguide
- 论文Single-stream Policy Optimization为了回归本质,一个输入输出对,一次训练,故为LLM定制化量身制作的轻量化PPO,不依赖旧模型,同样也不需要像GRPO依赖一组样本。
L SSPO = E min ( π θ ( a ∣ s ) ⋅ A \~ t , clip ( π θ ( a ∣ s ) , π clip低 , π clip高 ) ⋅ A \~ t ) L_{\text{SSPO}} = \mathbb{E}\left \\min\\left(\\pi_\\theta(a\|s) \\cdot \\tilde{A}_t, \\text{clip}\\left(\\pi_\\theta(a\|s), \\pi_{\\text{clip低}}, \\pi_{\\text{clip高}}\\right) \\cdot \\tilde{A}_t\\right) \\right LSSPO=Emin(πθ(a∣s)⋅A\~t,clip(πθ(a∣s),πclip低,πclip高)⋅A\~t)
结语
时代在发展,社会在进步 ,这股洪流浩浩荡荡,不随任何人的意志而转移,奔腾向前、永不停歇。人类在时代的浪潮面前,终究是渺小的,我们无法阻挡变革的脚步,唯有放下怯懦、摒弃犹豫,紧紧跟上时代的步伐,与时代同频并发,才能在浪潮中找到自身的位置。人工智能作为推动时代变革的核心力量,正以不可逆转之势渗透到各行各业,而大语言模型作为人工智能领域的核心载体,其核心技术的迭代与突破,更是承载着人类对机器理解语言、模拟人类思维的美好愿景,也见证着AI从能对话向会思考善决策的跨越。
面对这股势不可挡的时代洪流,我们每一个人,无论是深耕某一领域,还是奔波于寻常生活,都没有退缩的余地。这既是对屏幕前每一位读者的期许,也是我对自己的勉励,唯有以激情赴时代之约,以奋进应时代之求,才能在渺小的个体之力中,绽放出属于自己的光芒。我们不必因自身的渺小而妄自菲薄,不必因时代的迭代之快而心生畏惧,时代的浪潮从不会辜负奋力奔跑的人,唯有主动拥抱变革、直面挑战,将个人发展深深嵌入时代发展的脉络,才能不被时代淘汰,才能在属于自己的赛道上,跟上时代的并发节奏。