在大模型(LLM)应用爆发的今天,RAG (Retrieval-Augmented Generation,检索增强生成)
已经成为一个无法绕开的核心技术。无论是构建企业知识库、智能客服,还是打造个人 AI 助手,RAG 都是解决大模型"先天不足"的关键方案。
那么,究竟什么是 RAG?它为什么如此重要?又是如何工作的?本文将为你一一解答。
❓ 为什么要用 RAG?------ 大模型的四大痛点
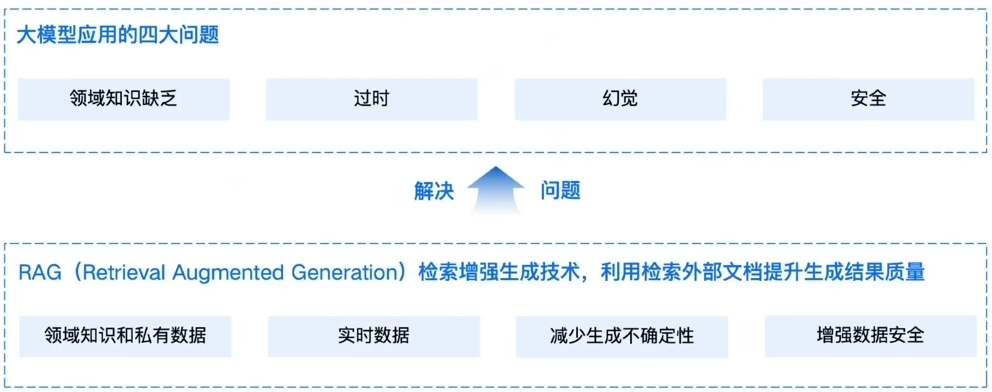
通用的基础大模型虽然强大,但在实际应用中存在四个显著的局限性,我们称之为 "大模型应用的四大问题" :
-
领域知识缺乏 (Lack of Domain Knowledge)
- 问题:大模型的知识来源于公开的互联网数据,对于特定行业(如金融、法律、医疗)的专业知识或企业内部私有数据(如员工手册、产品文档)知之甚少。
- 后果:无法回答专业问题,或给出泛泛而谈的答案。
-
信息过时 (Outdated Information)
- 问题:大模型的知识截止于其训练完成之时,不具备自动更新知识的能力。
- 后果:无法回答关于最新事件、实时数据(如今日股价、最新政策)的问题。
-
幻觉问题 (Hallucination)
- 问题:大模型有时会"一本正经地胡说八道",生成看似合理但实际上是错误或虚构的信息。
- 后果:在需要高准确性的场景下(如医疗诊断、法律咨询),这种错误是不可接受的。
-
数据安全性 (Data Security)
- 问题:直接将敏感的内部数据用于微调模型可能存在泄露风险,且成本高昂。
- 后果:企业不敢轻易将核心数据交给大模型处理。
💡 RAG 的价值:RAG 技术正是为了解决以上四大问题而生。它通过引入外部知识源,让大模型能够"现查现用",从而弥补自身知识的不足。
| 大模型问题 | RAG 解决方案 |
|---|---|
| 领域知识缺乏 | ✅ 注入领域知识和私有数据 |
| 信息过时 | ✅ 提供实时数据 |
| 幻觉问题 | ✅ 减少生成不确定性,基于事实回答 |
| 数据安全性 | ✅ 增强数据安全,数据无需训练即可使用 |
🧠 什么是 RAG?
RAG (Retrieval-Augmented Generation) ,中文译为 检索增强生成。
它的核心思想非常简单:在为一个大模型提问时,先从外部的知识库中检索出与问题相关的信息,然后将这些信息和问题一起交给大模型,让它基于这些参考信息来生成答案。
我们可以用一个公式来概括:
RAG = 检索技术 (Retrieval) + LLM 提示 (Generation)
- 检索 (Retrieval):负责从海量文档中找到最相关的片段。
- 增强 (Augmented):将找到的片段作为额外的上下文(Context)提供给模型。
- 生成 (Generation):大模型结合问题和上下文,生成更准确、更可靠的回答。
类比 :
想象一下你在参加一场开卷考试。
- 普通大模型:像一个记忆力超群但从不看书的学生,全靠脑子里的旧知识答题。
- RAG 增强的模型:像一个聪明的学生,遇到不会的问题,会先快速翻阅参考资料(检索),找到关键信息后,再组织语言写出答案(生成)。显然,后者的答案会更准确、更有依据。
⚙️ RAG 是如何工作的?
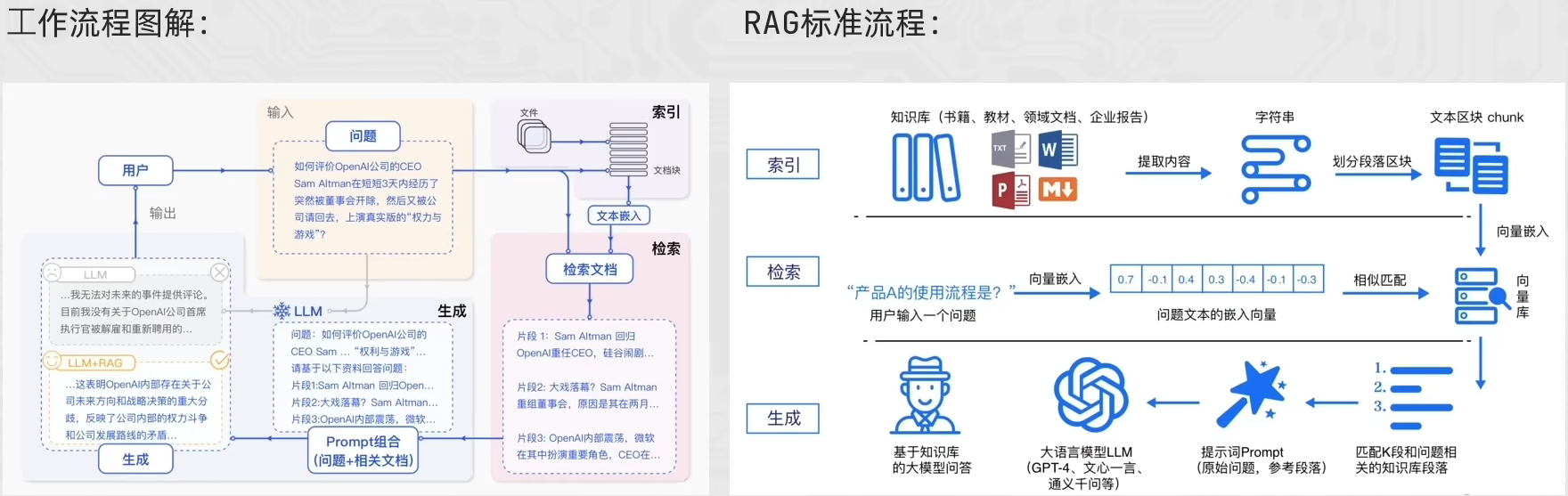
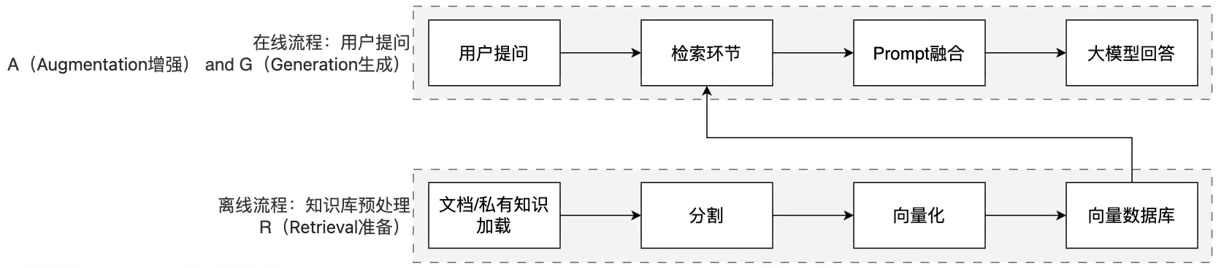
RAG 的工作流程可以清晰地分为两条线:离线准备线 和 在线服务线。
1. 离线准备线 (Offline Preparation / Indexing)
这条线负责构建和更新我们的"外部知识库",通常是一次性或定期执行的任务。

- 文档加载 (Loading):收集各种格式的原始数据,如 PDF、Word、TXT、网页等。
- 文本分割 (Chunking):将长文档切分成一个个小的、语义完整的文本块(Chunk)。因为大模型有上下文长度限制,且小片段更容易被精准检索。
- 向量化 (Embedding):使用嵌入模型(Embedding Model)将每个文本块转换成一个高维向量(一串数字)。这个向量代表了文本的语义。
- 存储 (Storing) :将这些向量及其对应的原始文本块存入向量数据库(Vector Database),建立索引,以便后续快速查找。
2. 在线服务线 (Online Serving / Querying)
这条线负责响应用户的实时提问,是 RAG 系统的核心交互流程。

- 用户提问 (Query):用户输入一个问题。
- 问题向量化 (Query Embedding):使用与离线阶段相同的嵌入模型,将用户的问题也转换成向量。
- 检索 (Retrieval):在向量数据库中,计算"问题向量"与所有"文档块向量"的相似度(如余弦相似度),找出最相关的 Top-K 个文档块。
- Prompt 融合 (Prompt Augmentation) :将用户的问题和检索到的相关文档块组合成一个新的、更丰富的 Prompt。
- 示例 Prompt:"请根据以下参考资料回答问题。参考资料:文档块1...文档块2...。问题是:用户问题"
- 生成 (Generation):将这个融合后的 Prompt 发送给大模型(LLM)。
- 输出 (Output):大模型基于提供的参考资料生成最终答案,返回给用户。
🌟 RAG 的核心优势总结
通过上述流程,RAG 为大模型应用带来了革命性的提升:
- 知识可更新:只需更新向量数据库中的文档,即可让模型掌握最新知识,无需重新训练。
- 来源可追溯:模型的回答是基于检索到的具体文档片段,可以轻松标注信息来源,增加可信度。
- 降低幻觉:通过限定模型基于给定材料回答,大幅减少了胡编乱造的可能性。
- 保护隐私:私有数据存储在本地向量库中,不直接用于模型训练,降低了数据泄露风险。
- 降低成本:相比于动辄花费数百万进行模型微调(Fine-tuning),RAG 的实现和维护成本低得多。
🚀 结语
RAG 是目前连接大模型与垂直领域应用最实用、最有效的桥梁。它巧妙地结合了传统检索技术的精确性和大语言模型的强大生成能力,为解决大模型的固有缺陷提供了一套优雅的工程化方案。