作者: Hao Wu, Xudong Wang, Jialiang Zhang, Junlong Tong, Xinghao Chen, Junyan Lin, Yunpu Ma, Xiaoyu Shen
单位: 东部理工学院数字孪生研究所等
代码地址: https://github.com/EIT-NLP/UTPTrack
https://arxiv.org/pdf/2602.23734
摘要
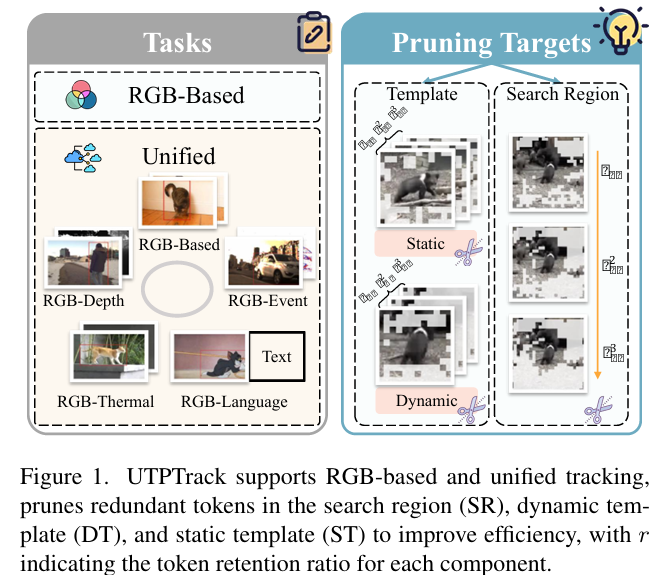
基于单流 Transformer 的跟踪器在视觉目标跟踪中取得了先进性能,但巨大的计算开销阻碍了其实时部署。虽然令牌剪枝(token pruning)提供了一条效率提升之路,但现有方法较为碎片化。它们通常孤立地剪枝搜索区域(Search Region, SR)、动态模板(Dynamic Template, DT)和静态模板(Static Template, ST),忽略了关键的组件间依赖关系,导致剪枝次优和精度下降。
为此,我们提出了 UTPTrack ,一个简单且统一的令牌剪枝框架,首次联合压缩所有三个组件。UTPTrack 采用一种注意力引导、感知令牌类型的策略来整体建模冗余,该设计无缝支持单一模型内的多模态和语言引导任务的统一跟踪。在 10 个基准测试上的广泛评估表明,UTPTrack 在基于剪枝的跟踪器的精度 - 效率权衡上达到了新的最先进水平(SOTA)。它在基于 RGB 的跟踪中剪枝了 65.4%65.4\%65.4% 的视觉令牌,在统一跟踪中剪枝了 67.5%67.5\%67.5%,同时分别保留了基线性能的 99.7%99.7\%99.7% 和 100.5%100.5\%100.5%。这种在 RGB 和多模态场景下的强劲表现突显了其作为未来高效视觉跟踪研究稳健基础的潜力。
1. 引言
视觉目标跟踪(VOT)旨在给定目标的初始状态,估计其在视频序列中的位置和形状。典型的跟踪器使用第一帧的静态模板(ST)表示目标,可选地更新动态模板(DT)以处理外观变化,并在后续帧的裁剪搜索区域(SR)内定位目标。由于 VOT 的动态性质,它需要强大的时空建模能力。
近年来,基于 Transformer 的架构展现了强大的建模能力,显著提升了跟踪性能。基于 Transformer 的跟踪器通常分为双流和单流。双流跟踪器分别处理模板和搜索区域,允许模板复用并降低推理成本。相比之下,单流跟踪器在统一的 Transformer 中联合编码两个输入,实现了更丰富的模板 - 搜索交互和更强的全局特征表示。虽然单流跟踪器因其卓越的性能已成为主流范式,但它们带来了巨大的计算开销:Transformer 的二次复杂度加上大量的视频令牌,使得在资源受限设备上的实时部署极具挑战性。
令牌剪枝最近通过减少搜索区域或动态模板中的令牌提高了跟踪效率。然而,当前方法尚未充分利用其潜力,因为没有一种方法能在所有三个关键组件(SR、DT 和 ST)上执行联合剪枝。孤立地处理这些组件忽略了它们固有的相互依赖性,而这些依赖性对于精确定位和边界感知跟踪至关重要。如果没有捕捉跨组件关系的统一冗余建模策略,现有方法往往做出次优决策:信息丰富的令牌可能被丢弃,且组件间的不均匀冗余未被充分利用。因此,跟踪性能往往因空间一致性和语义完整性的下降而受损,这一问题在对齐信息至关重要的多模态场景中尤为严重。
为解决这一问题,我们提出了 UTPTrack,一个用于高效准确跟踪的简单统一令牌剪枝框架。与之前仅从单个组件剪枝令牌或依赖启发式规则的方法不同,UTPTrack 在单流架构内联合剪枝所有三个来源(搜索区域、动态模板和静态模板),并由整体冗余建模策略指导。具体而言,我们识别每个组件内的冗余模式,并据此定制注意力引导的剪枝策略。对于搜索区域和动态模板,令牌相关性基于与静态模板中心令牌的相似度计算,仅保留最重要的令牌。对于静态模板,我们通过一种感知令牌类型的策略进一步增强剪枝鲁棒性,利用目标边界框的空间先验来避免丢弃前景令牌。
除了基于 RGB 的跟踪,UTPTrack 自然扩展到统一跟踪,支持单一模型中的多模态和语言引导任务。对于额外的视觉模态(如深度、热成像、事件),剪枝在共享嵌入空间中使用相同的基于注意力的机制执行。对于 RGB-语言任务,我们引入了一种文本引导的剪枝策略,其中来自语言令牌的语义线索与视觉特征共同指导令牌选择。这种统一且感知模态的设计使 UTPTrack 能够在保持高效率的同时泛化到各种跟踪场景。
我们在 OSTrack 和 SUTrack 上对 UTPTrack 在十个基于 RGB 和多模态跟踪基准测试上的有效性进行了全面评估。大量结果证明了其在不同任务中的强大泛化能力和效率。具体而言,UTPTrack 在 OSTrack384 上将令牌数量减少了 65.4%65.4\%65.4%,在 SUTrack384 上减少了 67.5%67.5\%67.5%,相应的 MACs(乘加运算)减少了 31.3%31.3\%31.3% 和 28.4%28.4\%28.4%,同时保持甚至略微提高了精度(分别为基线性能的 99.7%99.7\%99.7% 和 100.5%100.5\%100.5%)。
本文的贡献总结如下:
- 我们引入了 UTPTrack,这是第一个在单流 Transformer 内联合压缩 SR、DT 和 ST 的统一令牌剪枝框架。
- 我们提出了一种注意力引导、感知令牌类型的策略,利用跨组件相似性和空间先验来去除冗余,同时保留关键信息。
- 我们将框架扩展到统一跟踪,通过统一且感知模态的剪枝机制,包括一种整合自然语言语义线索的新型文本引导策略。
- 在十个基准测试上的广泛实验表明,UTPTrack 显著减少了令牌数量和计算量,同时在基于 RGB 和统一跟踪中保持了最先进的性能。
2. 相关工作
基于 RGB 和统一的目标跟踪: 基于 RGB 的目标跟踪专注于单个目标和 RGB 图像,支撑了许多进展。最近,单流 Transformer 跟踪器耦合特征提取和关系建模,以获得更强的表示和更准确的定位。在此基础上,研究已转向处理多种模态(RGB+深度/热成像/事件/语言)的统一框架。参数高效适应方法在保持强大 RGB 基础的同时,通过轻量级提示或适配器注入模态线索。UnTrack 学习跨模态的共享低秩潜在空间,而 SUTrack 通过统一模态表示在单个单流模型中整合了五个任务。为了提高效率,一些工作通过共享骨干网络、紧凑专家、蒸馏或可学习的交互令牌来减少冗余。与这些方向互补,我们通过分层剪枝的令牌级经济性解决了剩余的令牌瓶颈,在不修改统一架构的情况下改善了计算 - 性能权衡。
计算机视觉中的令牌压缩: ViT 中的令牌压缩包括两类:剪枝和合并。剪枝移除低重要性令牌。DynamicViT 使用 MLP 预测令牌显著性并丢弃其余部分。EViT 和 SPViT 估计重要性,并在进入下一层之前丢弃或折叠低显著性令牌。Evo-ViT 使用演化的 CLS 注意力和慢 - 快更新来保留结构。合并则结合相似令牌。ToMe 执行二分软匹配以合并固定数量的相似令牌。VoMix 通过相似度加权混合将冗余令牌内容重新分配到关键令牌。ATM 采用逐层递减的相似度阈值和感知合并的匹配策略。尽管在 ViT 中已有广泛研究,但针对跟踪的令牌压缩仍未被充分探索。OSTrack 提出了基于与中心静态模板相似度的搜索令牌早期消除。ProContEXT 通过结合静态和动态模板计算相似度分数来改进这一点,以提高鲁棒性。然而,这些方法孤立地剪枝组件,忽略了搜索区域、动态模板和静态模板之间的冗余重叠和交叉依赖。相比之下,我们的方法引入了跨所有三个组件的联合剪枝策略,旨在整体建模冗余,并在更复杂的跟踪场景中提高剪枝效果。
3. 方法
本节介绍 UTPTrack。我们首先描述基于 RGB 和统一跟踪的单流流程,以及令牌剪枝的预备知识,然后分析剪枝目标(即 SR、DT、ST)。我们进一步介绍了一种针对 ST 的感知令牌类型策略,并将框架扩展到具有感知模态剪枝方案的统一跟踪。
3.1. 预备知识
基于 RGB 的跟踪流程: 给定静态模板 Zs∈RHz×Wz×3Z_s \in \mathbb{R}^{H_z \times W_z \times 3}Zs∈RHz×Wz×3 和当前帧的搜索区域 X∈RHx×Wx×3X \in \mathbb{R}^{H_x \times W_x \times 3}X∈RHx×Wx×3,跟踪器旨在估计目标边界框 B∈R4B \in \mathbb{R}^4B∈R4。为了处理外观变化,通常维护一个动态模板 Zd∈RHz×Wz×3Z_d \in \mathbb{R}^{H_z \times W_z \times 3}Zd∈RHz×Wz×3。典型的单流 RGB 跟踪器使用骨干网络 F(⋅)F(\cdot)F(⋅) 进行特征提取和关系建模,后跟跟踪头 ϕ(⋅)\phi(\cdot)ϕ(⋅)。输入被分割成补丁,嵌入并展平为令牌序列:Ex∈RNx×DE_x \in \mathbb{R}^{N_x \times D}Ex∈RNx×D, Esz∈RNsz×DE_{sz} \in \mathbb{R}^{N_{sz} \times D}Esz∈RNsz×D, 和 Edz∈RNdz×DE_{dz} \in \mathbb{R}^{N_{dz} \times D}Edz∈RNdz×D。这些被连接并由骨干网络处理:B=ϕ(F(Concat(Ex,Esz,Edz)))B = \phi(F(\text{Concat}(E_x, E_{sz}, E_{dz})))B=ϕ(F(Concat(Ex,Esz,Edz)))。
统一跟踪流程: 统一跟踪器(如 SUTrack)通过将互补模态(如深度、热成像、事件、语言)集成到单个框架中来扩展 RGB 跟踪器。对于深度、热成像和事件,将三个额外通道(D/T/E)与 RGB 连接形成六通道输入。多模态特征被对齐并投影到统一嵌入中,产生 SR Ex∈RNx×2DE_x \in \mathbb{R}^{N_x \times 2D}Ex∈RNx×2D, ST Esz∈RNsz×2DE_{sz} \in \mathbb{R}^{N_{sz} \times 2D}Esz∈RNsz×2D 和 DT Edz∈RNdz×2DE_{dz} \in \mathbb{R}^{N_{dz} \times 2D}Edz∈RNdz×2D。对于语言,从文本描述中通过 CLIP-L 提取单个令牌,并与视觉令牌连接,实现跨模态交互。输出计算为:B=ϕ(F(Concat(Ex,Esz,Edz,Etext)))B = \phi(F(\text{Concat}(E_x, E_{sz}, E_{dz}, E_{\text{text}})))B=ϕ(F(Concat(Ex,Esz,Edz,Etext)))。缺失的模态通过复制 RGB 通道(对于 D/T/E)或使用固定的虚拟句子(对于文本)来处理,以确保一致的输入格式。
跟踪中的令牌剪枝: 在 ViT 中,MHA 和 MLP 处理所有令牌,产生 O(N2)O(N^2)O(N2) 和 O(N)O(N)O(N) 的成本,阻碍了实时跟踪。令牌剪枝通过保留显著令牌来减少计算,但跟踪需要空间连贯性。因此,我们将保留的令牌恢复到其原始索引,并在跟踪头之前对剪枝槽进行零填充,从而在减少计算的同时保留空间布局。
3.2. UTPTrack
UTPTrack 的架构如图 2 所示。基于 RGB 和统一流程,它采用单流设计,联合处理 SR、ST 和 DT 令牌进行跟踪。遵循 OSTrack,我们在选定的层中插入轻量级的候选者或模板消除模块(CTEM),以使用注意力导出的重要性分数剪枝冗余令牌。在 RGB 跟踪中,剪枝由 ST 指导,在统一跟踪中 additionally 由语言指导。为了保持空间对齐,剪枝的 SR 令牌在跟踪头之前被零填充到其原始位置。
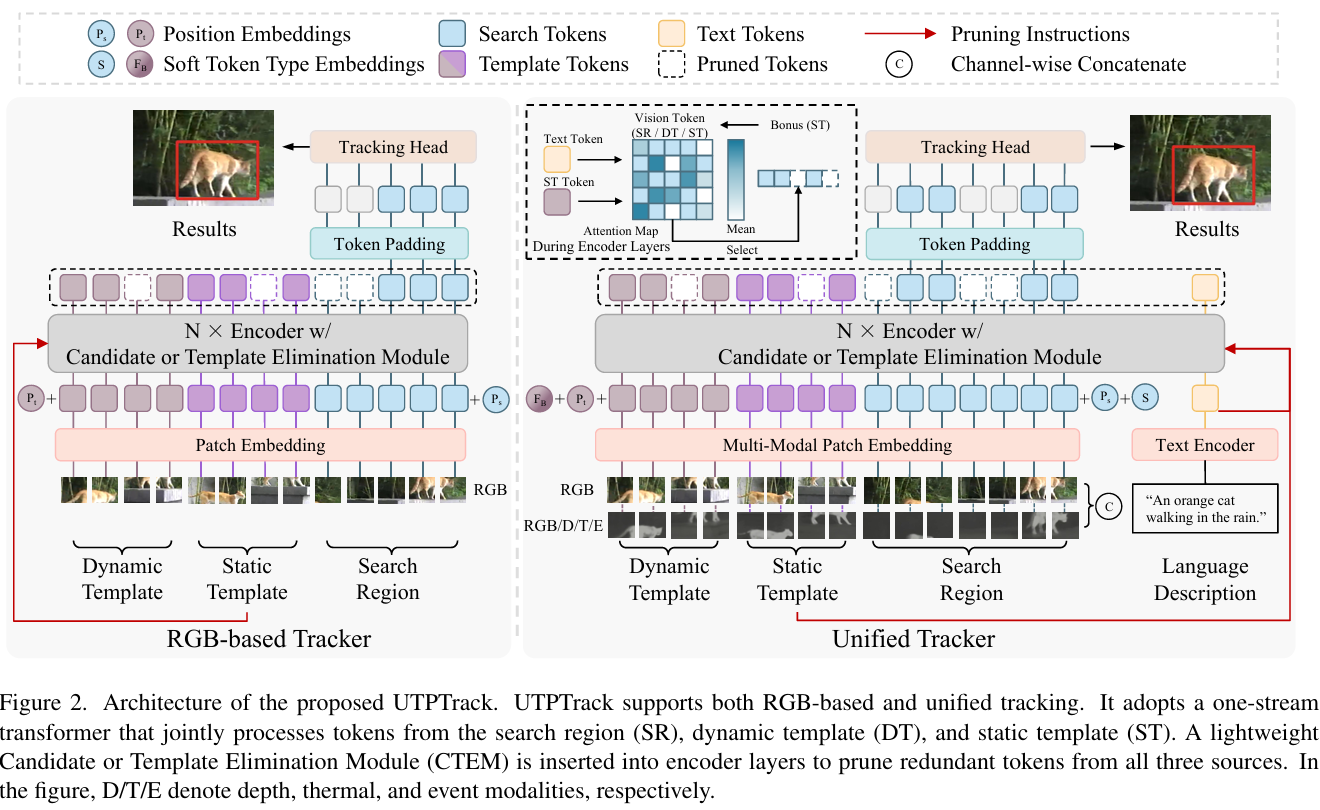
3.2.1. 基于 RGB 跟踪的令牌剪枝
在单流架构中,SR、ST 和 DT 令牌通过注意力层联合处理。虽然这实现了丰富的跨令牌交互,但也引入了冗余,尤其是来自判别价值有限的背景区域。为了缓解这一问题,我们设计了专门的消除模块,从每个来源剪枝不重要的令牌。
剪枝由基于注意力的相似度指导,重用 Transformer 编码器的注意力权重来测量令牌相关性,而无需额外计算。给定来自 XXX, ZsZ_sZs, 和 ZdZ_dZd 的连接令牌序列 Ex;Esz;EdzE_x; E_{sz}; E_{dz}Ex;Esz;Edz,注意力计算为:
Attention(Q,K,V)=Softmax(QKTdk)V=Softmax(Qx;Qsz;QdzKx;Ksz;KdzTdk)VxVszVdz \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V = \text{Softmax}\left(\frac{Q_x; Q_{sz}; Q_{dz}K_x; K_{sz}; K_{dz}^T}{\sqrt{d_k}}\right) \begin{bmatrix} V_x \\ V_{sz} \\ V_{dz} \end{bmatrix} Attention(Q,K,V)=Softmax(dk QKT)V=Softmax(dk Qx;Qsz;QdzKx;Ksz;KdzT) VxVszVdz
其中 QQQ, KKK, 和 VVV 表示查询、键和值矩阵,下标 xxx, szszsz, dzdzdz 分别表示 SR, ST, 和 DT。公式 (1) 中的注意力权重 AAA 展开为:
A=Softmax(1dkQxKxTQxKszTQxKdzTQszKxTQszKszTQszKdzTQdzKxTQdzKszTQdzKdzT) A = \text{Softmax}\left( \frac{1}{\sqrt{d_k}} \begin{bmatrix} Q_x K_x^T & Q_x K_{sz}^T & Q_x K_{dz}^T \\ Q_{sz} K_x^T & Q_{sz} K_{sz}^T & Q_{sz} K_{dz}^T \\ Q_{dz} K_x^T & Q_{dz} K_{sz}^T & Q_{dz} K_{dz}^T \end{bmatrix} \right) A=Softmax dk 1 QxKxTQszKxTQdzKxTQxKszTQszKszTQdzKszTQxKdzTQszKdzTQdzKdzT
这种密集交互有利于特征融合,但有噪声传播的风险。例如,项如 QxKxTQ_x K_x^TQxKxT, QxKszTQ_x K_{sz}^TQxKszT, 和 QxKdzTQ_x K_{dz}^TQxKdzT 可能允许背景令牌相互关注或主导与目标相关的响应。同样,模板令牌关注噪声搜索令牌(例如,通过 QszKxTQ_{sz} K_x^TQszKxT, QdzKxTQ_{dz} K_x^TQdzKxT)会降低表示质量。
候选者(搜索区域)消除: SR 令牌通常包含背景杂波,引入冗余并损害定位精度。这在注意力项如 QxKxTQ_x K_x^TQxKxT 中很明显,其中背景令牌相互关注,以及 QxKszTQ_x K_{sz}^TQxKszT 或 QxKdzTQ_x K_{dz}^TQxKdzT,其中 SR 令牌关注非判别性模板区域。为了解决这个问题,我们根据每个 SR 令牌与 ST 的注意力相似度来衡量其重要性。根据公式 (2),相关性分数计算为 ωx=softmax(Qsz′KxT/dk)∈R1×Nx\omega_x = \text{softmax}(Q_{sz'} K_x^T / \sqrt{d_k}) \in \mathbb{R}^{1 \times N_x}ωx=softmax(Qsz′KxT/dk )∈R1×Nx,其中 Qsz′Q_{sz'}Qsz′ 是 ST 中心令牌的查询,NxN_xNx 是 SR 令牌的数量。我们保留前 kkk 个令牌并剪枝其余部分,减少背景干扰同时保留与目标相关的信息。
动态模板消除: DT 可能由于漂移、遮挡或外观变化而包含噪声令牌,这可能通过注意力项如 QdzKxTQ_{dz} K_x^TQdzKxT 和 QdzKszTQ_{dz} K_{sz}^TQdzKszT 对 SR 和 ST 产生负面影响。与 SR 类似,我们计算每个 DT 令牌与 ST 中心令牌的相似度为 ωdz=softmax(Qsz′KdzT/dk)∈R1×Ndz\omega_{dz} = \text{softmax}(Q_{sz'} K_{dz}^T / \sqrt{d_k}) \in \mathbb{R}^{1 \times N_{dz}}ωdz=softmax(Qsz′KdzT/dk )∈R1×Ndz,并剪枝那些相关性低的令牌。
静态模板消除: 由于 ST 是通过扩大目标框获得的,它可能包含引入无关注意力交互的背景令牌(例如,QszKxTQ_{sz} K_x^TQszKxT 和 QszKdzTQ_{sz} K_{dz}^TQszKdzT)。我们测量每个令牌与中心令牌的相似度为 ωsz=softmax(Qsz′KszT/dk)∈R1×Nsz\omega_{sz} = \text{softmax}(Q_{sz'} K_{sz}^T / \sqrt{d_k}) \in \mathbb{R}^{1 \times N_{sz}}ωsz=softmax(Qsz′KszT/dk )∈R1×Nsz,并剪枝相关性低的令牌,同时始终保留中心令牌。
感知令牌类型的剪枝: 受令牌类型嵌入机制的启发,我们提出了一种在 ST 消除期间的感知令牌类型剪枝策略,以抑制错误丢弃前景令牌的概率。给定 ST Zs∈RHz×Wz×3Z_s \in \mathbb{R}^{H_z \times W_z \times 3}Zs∈RHz×Wz×3 及其边界框 BBB,我们构建一个二值掩码 M∈RHz×WzM \in \mathbb{R}^{H_z \times W_z}M∈RHz×Wz,其中 BBB 内部的像素设为 1,外部设为 0:
M(i,j)={1if (i,j) is inside B0otherwise M(i, j) = \begin{cases} 1 & \text{if } (i, j) \text{ is inside } B \\ 0 & \text{otherwise} \end{cases} M(i,j)={10if (i,j) is inside Botherwise
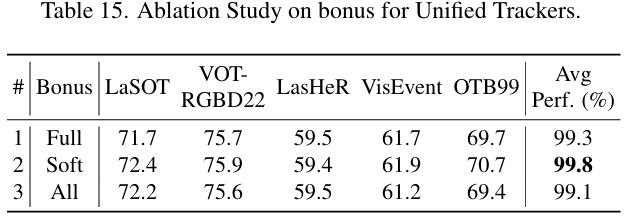
我们将掩码划分为不重叠的 P2P^2P2 个补丁 Mpatch(k)M^{(k)}_{\text{patch}}Mpatch(k),并通过平均其掩码值为每个补丁分配一个前景分数。该分数作为奖励,鼓励在剪枝期间保留前景令牌,并被纳入基于注意力的消除模块中。我们探索了三种奖励策略来控制这种前景先验如何影响剪枝。
- 完全奖励(Full bonus): 如果所有像素都在边界框内,则分配 1。补丁 Mpatch(k)M^{(k)}{\text{patch}}Mpatch(k) 的值为:
bfull(k)={1if M(i,j)=1 for all (i,j)∈Mpatch(k)0otherwise b^{(k)}{\text{full}} = \begin{cases} 1 & \text{if } M(i, j)=1 \text{ for all } (i, j) \in M^{(k)}_{\text{patch}} \\ 0 & \text{otherwise} \end{cases} bfull(k)={10if M(i,j)=1 for all (i,j)∈Mpatch(k)otherwise - 软奖励(Soft bonus): 使用每个补丁的平均掩码值:
bsoft(k)=mavg(k)=1P2∑M(i,j),(i,j)∈Mpatch(k) b^{(k)}{\text{soft}} = m^{(k)}{\text{avg}} = \frac{1}{P^2} \sum M(i, j), \quad (i, j) \in M^{(k)}_{\text{patch}} bsoft(k)=mavg(k)=P21∑M(i,j),(i,j)∈Mpatch(k) - 全有奖励(All bonus): 如果任何像素在框内,则分配 1:
ball(k)={1if ∃(i,j)∈Mpatch(k):M(i,j)=10otherwise b^{(k)}{\text{all}} = \begin{cases} 1 & \text{if } \exists (i, j) \in M^{(k)}{\text{patch}} : M(i, j)=1 \\ 0 & \text{otherwise} \end{cases} ball(k)={10if ∃(i,j)∈Mpatch(k):M(i,j)=1otherwise
这些奖励直接添加到排名期间的注意力分数中,以指导剪枝朝向与前景相关的令牌。如图 2 所示,该机制被集成到消除模块中。默认使用软版本。
3.2.2. 统一跟踪的令牌剪枝
最初为 RGB 跟踪设计的所提出的剪枝策略,自然地扩展到多模态设置。对于视觉模态(RGBD, RGBT, RGBE),辅助通道(深度、热成像、事件)与 RGB 连接形成六通道输入。投影到统一嵌入空间后,令牌维度增加,但其空间布局保持不变。因此,基于对 ST 中心令牌的注意力的剪枝仍然有效,无需修改。对于语言模态,我们额外考虑语义线索:文本描述使用 CLIP-L 编码为单个令牌,并在 Transformer 之前与视觉令牌连接,将公式 (2) 中的注意力扩展为包括与语言令牌的交互。更新后的注意力权重 AAA 为:
A=Softmax(1dkQxKxTQxKszTQxKdzTQxKtTQszKxTQszKszTQszKdzTQszKtTQdzKxTQdzKszTQdzKdzTQdzKtTQtKxTQtKszTQtKdzTQtKtT) A = \text{Softmax}\left( \frac{1}{\sqrt{d_k}} \begin{bmatrix} Q_x K_x^T & Q_x K_{sz}^T & Q_x K_{dz}^T & Q_x K_t^T \\ Q_{sz} K_x^T & Q_{sz} K_{sz}^T & Q_{sz} K_{dz}^T & Q_{sz} K_t^T \\ Q_{dz} K_x^T & Q_{dz} K_{sz}^T & Q_{dz} K_{dz}^T & Q_{dz} K_t^T \\ Q_t K_x^T & Q_t K_{sz}^T & Q_t K_{dz}^T & Q_t K_t^T \end{bmatrix} \right) A=Softmax dk 1 QxKxTQszKxTQdzKxTQtKxTQxKszTQszKszTQdzKszTQtKszTQxKdzTQszKdzTQdzKdzTQtKdzTQxKtTQszKtTQdzKtTQtKtT
文本引导剪枝: 基于公式 (7) 中更新的注意力,语言令牌通过双向注意力与所有视觉令牌交互,使语义线索能够增强空间表示。为了利用这一点进行剪枝,我们联合使用 ST 的中心令牌和语言令牌来指导令牌重要性估计。具体而言,每个令牌的重要性计算为:
ωx=ϕ(softmax(Qsz′KxTdk)+softmax(QtKxTdk)) \omega_x = \phi(\text{softmax}(\frac{Q_{sz'} K_x^T}{\sqrt{d_k}}) + \text{softmax}(\frac{Q_t K_x^T}{\sqrt{d_k}})) ωx=ϕ(softmax(dk Qsz′KxT)+softmax(dk QtKxT))
其中 ϕ(⋅)\phi(\cdot)ϕ(⋅) 表示跨注意力图的求和,QtQ_tQt 是文本令牌的查询。这使得剪枝能够从空间和语义指导中受益。同样的原则可以应用于 DT 和 ST。相关的消融实验见第 4.3 节,我们研究了哪个令牌组从文本引导剪枝中受益最大。
3.3. 训练与推理
遵循 OSTrack,我们的基于 RGB 的跟踪器使用加权 focal loss 进行分类,L1 和广义 IoU losses 用于边界框回归。总损失为:
LRGB=λclsLcls+λgiouLgiou+λL1LL1 L_{\text{RGB}} = \lambda_{\text{cls}} L_{\text{cls}} + \lambda_{\text{giou}} L_{\text{giou}} + \lambda_{L1} L_{L1} LRGB=λclsLcls+λgiouLgiou+λL1LL1
其中 LclsL_{\text{cls}}Lcls, LgiouL_{\text{giou}}Lgiou, 和 LL1L_{L1}LL1 表示加权 focal、广义 IoU 和 L1 损失。我们设置 λcls=1\lambda_{\text{cls}}=1λcls=1, λgiou=2\lambda_{\text{giou}}=2λgiou=2, 和 λL1=5\lambda_{L1}=5λL1=5。对于统一跟踪,遵循 SUTrack,我们加入了用于任务识别的交叉熵损失:
LUnified=LRGB+λtaskLtask L_{\text{Unified}} = L_{\text{RGB}} + \lambda_{\text{task}} L_{\text{task}} LUnified=LRGB+λtaskLtask
其中 LtaskL_{\text{task}}Ltask 是任务识别交叉熵损失,λtask=1\lambda_{\text{task}}=1λtask=1。在推理期间,基于 RGB 和统一跟踪器采用使用一个 ST 和一个 DT 的双模板策略。DT 根据固定的时间间隔和置信度阈值进行更新,遵循 STARK 的策略。
4. 实验
4.1. 实现细节
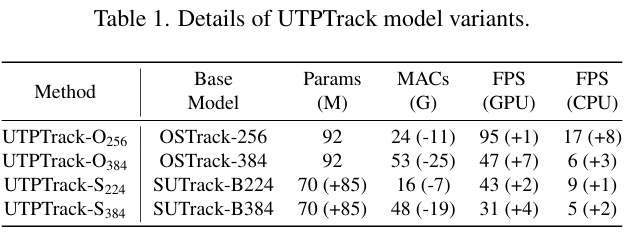
模型: 我们提出了四种 UTPTrack 变体,涵盖用于 RGB 和统一跟踪的架构和分辨率。模型名称编码搜索区域分辨率(数字)和基础跟踪器(后缀)。OSTrack 是一个修改版本,去除了候选者消除模块并使用单个 DT。表 1 报告了参数、MACs 和推理速度。负的 MAC 下标表示计算减少,FPS 下标表示剪枝带来的速度增益,而参数下标标记了在语言引导跟踪中使用的 CLIP-L 文本编码器。
训练: 遵循基于 RGB 跟踪的标准实践,UTPTrack-O 在 TrackingNet, LaSOT, GOT-10k, 和 COCO 上训练 300 个 epoch,每个 epoch 60k 图像对。对于统一跟踪,UTPTrack-S 遵循 SUTrack 并使用更广泛的多模态数据集,包括 TrackingNet, LaSOT, GOT-10k, COCO, TNL2K, VASTTrack, DepthTrack, LasHeR, 和 VisEvent,训练 180 个 epoch,每个 epoch 100k 图像对。对于所有变体,模板和搜索区域裁剪是通过将目标边界框分别扩大 2 倍和 4 倍生成的。训练在 4 个 NVIDIA A100 GPU 上进行。
推理: 在推理期间,DT 每 25 帧更新一次,使用 0.7 的置信度阈值。应用 Hanning 窗口惩罚以结合位置先验,遵循常见做法。推理速度在单个 NVIDIA 1080 Ti GPU 和 Intel Xeon Gold 6226R@ 2.90GHz CPU 上评估。
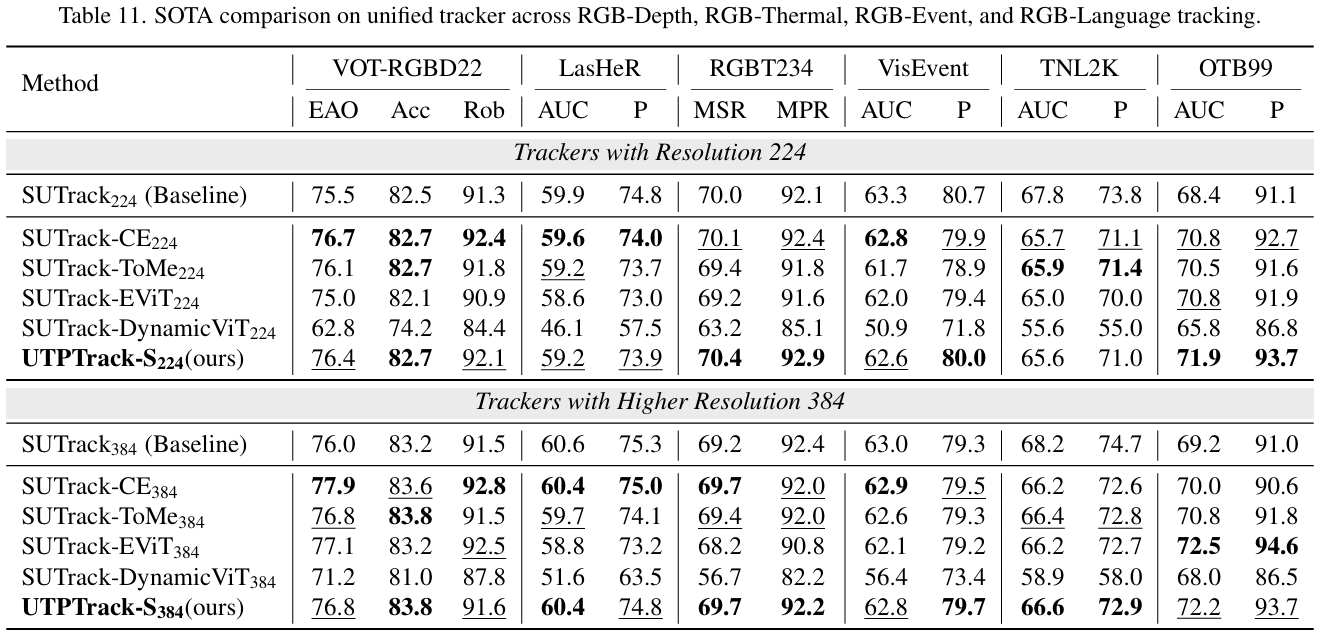
4.2. 最先进技术比较
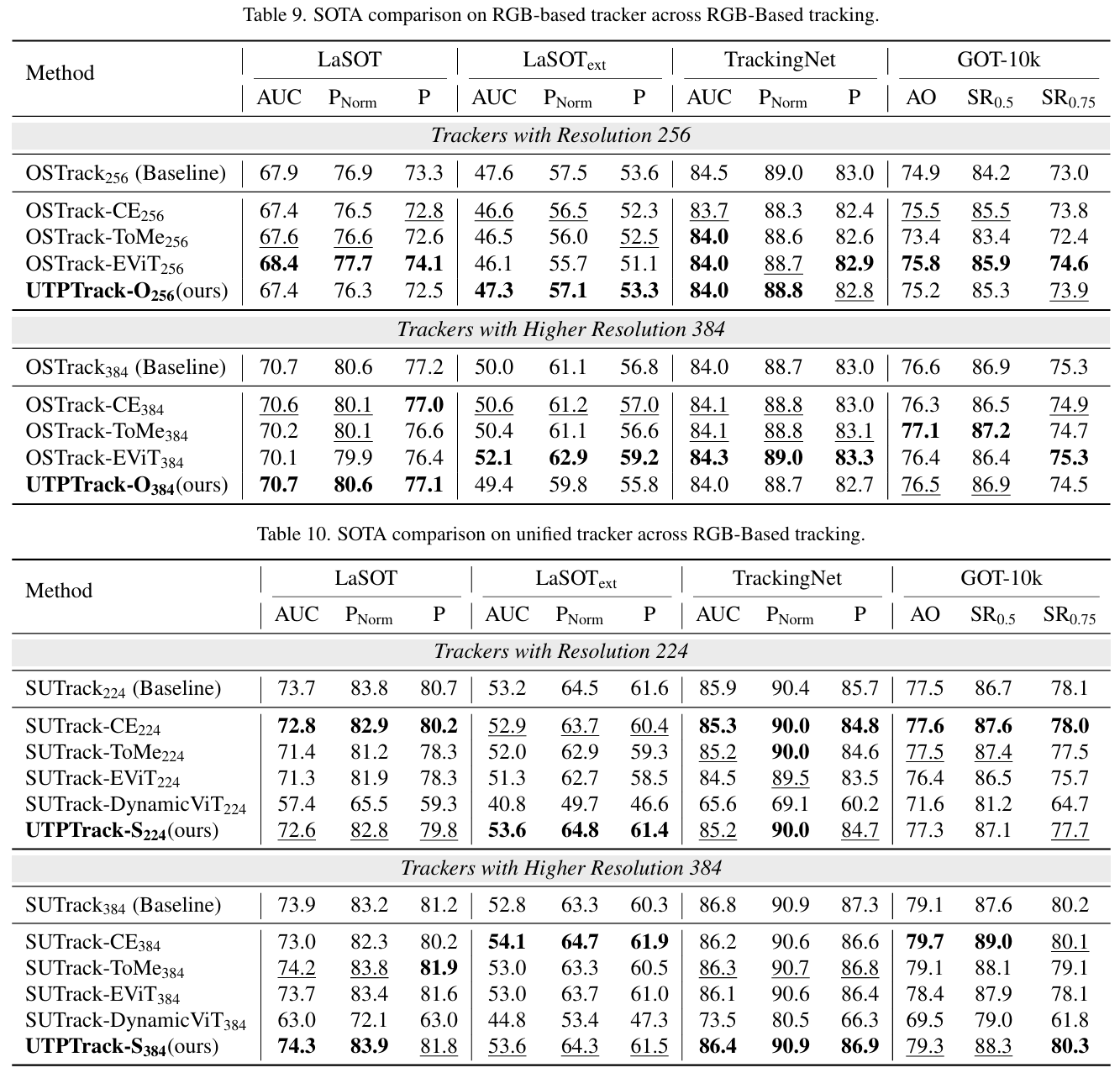
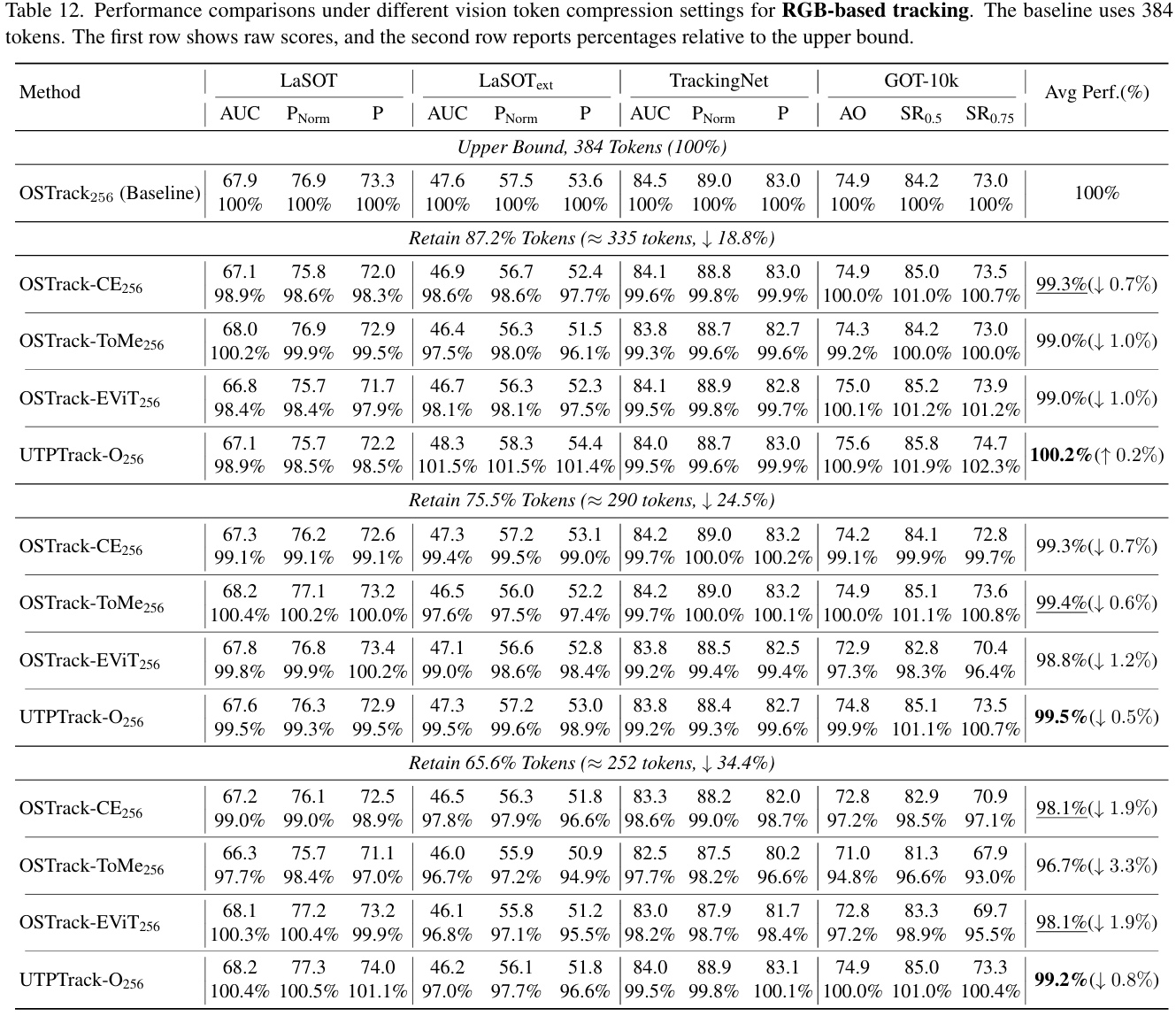
我们在两种跟踪范式下验证了 UTPTrack 的有效性:(1) 基于 RGB 的跟踪和 (2) 统一跟踪,其中包括基于 RGB、RGB-深度、RGB-热成像、RGB-事件和 RGB-语言任务。对于每种范式,我们使用代表性基础模型(OSTrack 或 SUTrack),并将 UTPTrack 与最先进的令牌压缩方法(包括 CE, ToMe, EViT, 和 DynamicViT)在不同输入分辨率下进行比较。我们在两个互补协议下报告结果:(1) 整体性能,使用发布的默认设置,和 (2) 控制预算性能,在三个匹配的令牌压缩率下评估。
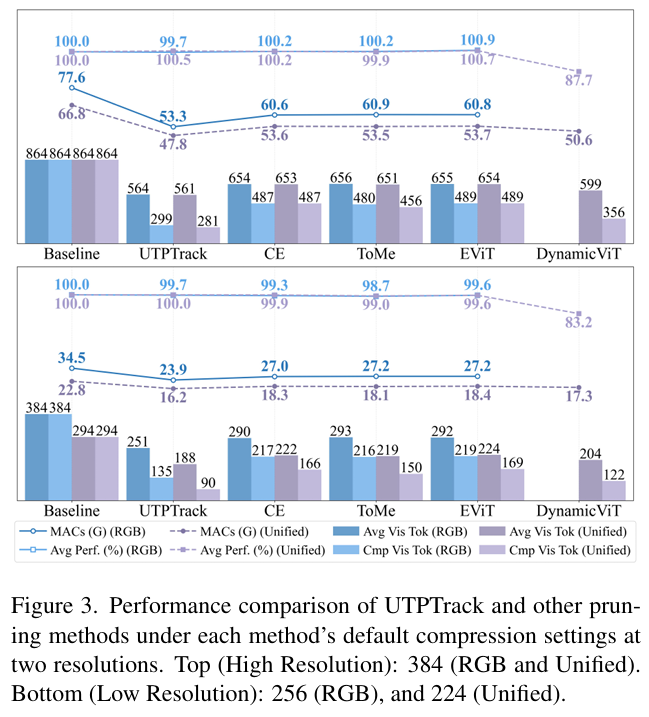
整体性能: 如图 3 所示,UTPTrack 在基于 RGB 和统一跟踪设置中均实现了最佳的性能 - 效率权衡。在低分辨率设置下,它在两种范式中都实现了最高的压缩比,同时提供了最佳性能。具体而言(基于 RGB/统一),MACs 下降了 30.7%30.7\%30.7% (34.5G→23.9G34.5\text{G} \to 23.9\text{G}34.5G→23.9G) / 28.9%28.9\%28.9% (22.8G→16.2G22.8\text{G} \to 16.2\text{G}22.8G→16.2G),视觉令牌剪枝了 64.8%64.8\%64.8% (384→135384 \to 135384→135) / 69.4%69.4\%69.4% (294→90294 \to 90294→90),同时保持了 99.7%99.7\%99.7% / 100.0%100.0\%100.0% 的基线性能。在可比性能下,它进一步实现了 1.5×1.5\times1.5× / 1.6×1.6\times1.6× 的压缩。在高分辨率设置下,UTPTrack 保持了其优势并具有良好的可扩展性:(基于 RGB/统一)MACs 减少了 31.3%31.3\%31.3% / 28.4%28.4\%28.4%,令牌减少了 65.4%65.4\%65.4% / 67.5%67.5\%67.5%,性能保持在基线的 99.7%99.7\%99.7% / 100.5%100.5\%100.5%。值得注意的是,随着分辨率的增加,UTPTrack-S 甚至超过了基线,达到了 100.5%100.5\%100.5% 的性能。这个小但一致的增益表明,我们的令牌选择作为一种温和的正则化器,通过去除冗余或噪声视觉令牌并锐化对显著区域的注意力,从而在减少计算的同时提高了精度。
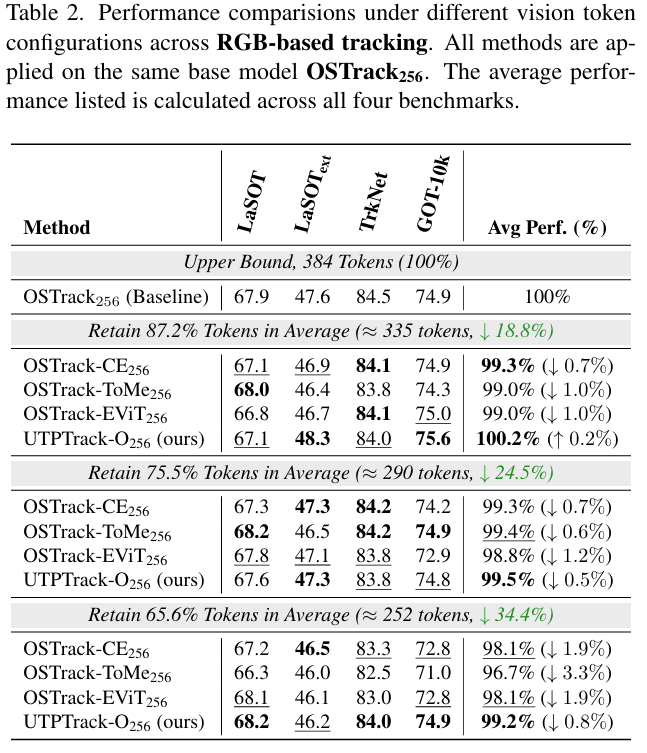
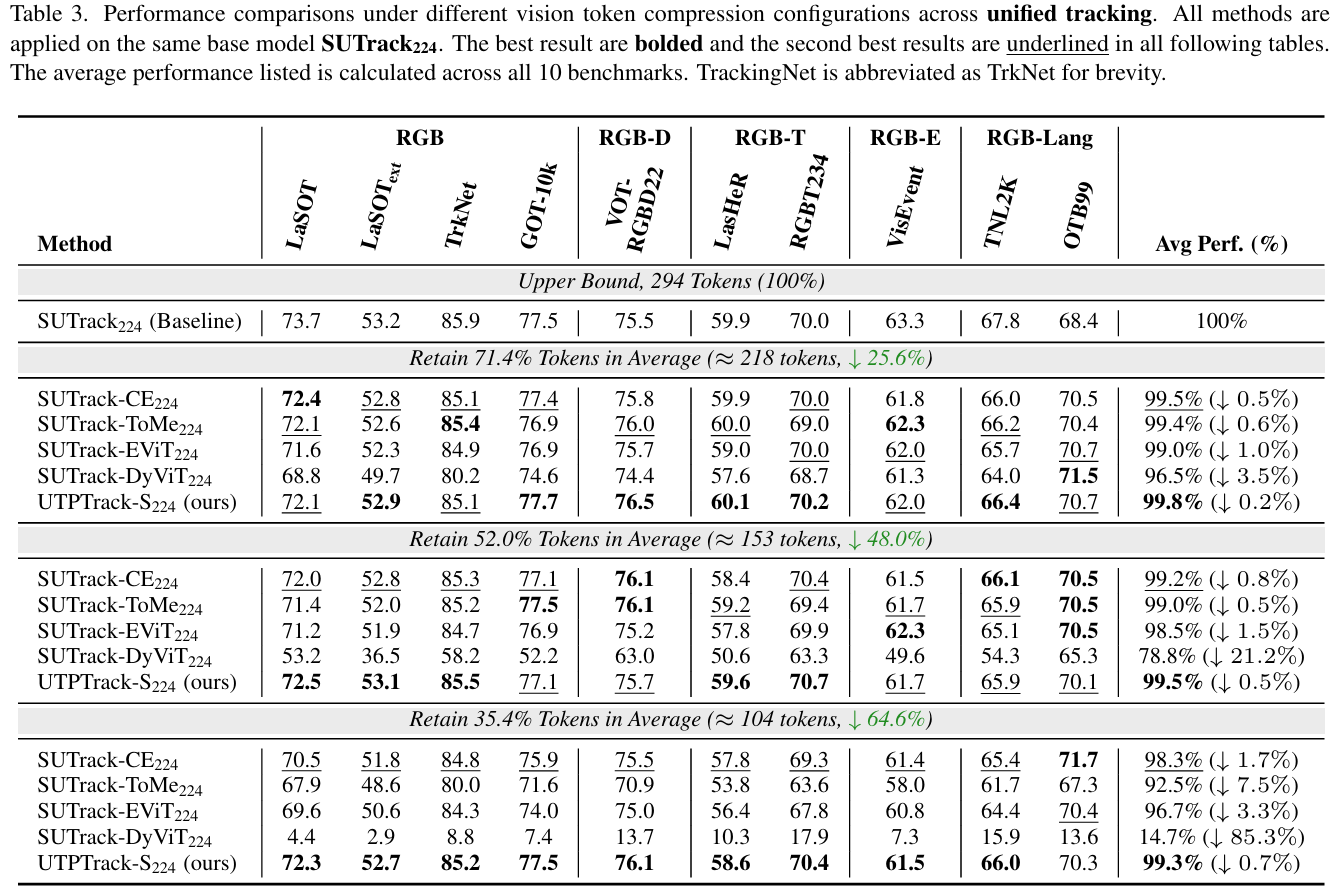
控制预算性能: 为了确保方法间的公平比较,我们在低分辨率设置下的三个不同压缩率下进行了控制预算实验。对于基于 RGB 的跟踪,如表 2 所示,我们在四个广泛使用的基于 RGB 的基准测试中将 UTPTrack-O 与其他方法进行了比较。UTPTrack-O 在所有剪枝率下始终优于所有对应方法。值得注意的是,在中等预算下,UTPTrack-O256 即使在剪枝了 18.8%18.8\%18.8% 的视觉令牌后也超过了未剪枝的基线,表明很大一部分令牌是冗余的,选择性剪枝可以提高泛化能力。对于统一跟踪,如表 3 所示,我们在十一个广泛使用的基于 RGB 和多模态基准测试中将 UTPTrack-S 与其他方法进行了比较。UTPTrack-S224 同样在每个剪枝率下保持明显领先,证实了所提出的剪枝策略有效地转移到了仅限 RGB 的设置之外。与最相似的基于注意力的令牌剪枝方法 CE 相比,UTPTrack 在基于 RGB 和统一跟踪的所有三个剪枝率下的几乎所有基准测试中都取得了更高的性能。值得注意的是,随着压缩率的增加,性能差距有利于 UTPTrack 而扩大。我们将此归因于我们的跨组件联合剪枝策略,该策略有效地识别并减少了所有组件的冗余,更好地保留了关键区域。
4.3. 消融与分析
在本节中,我们在基于 RGB 和统一跟踪上对 UTPTrack 进行消融,分别使用 OSTrack256 和 SUTrack224 作为基线。我们逐步分析了关键组件的贡献,包括搜索区域候选者消除(CE)、动态模板消除(DTE)、静态模板消除(STE)、感知令牌类型剪枝(TTA)和文本引导剪枝(TG)。结果表明,我们的框架有效地减少了令牌冗余,同时保持了跟踪精度,实现了高效的性能权衡。
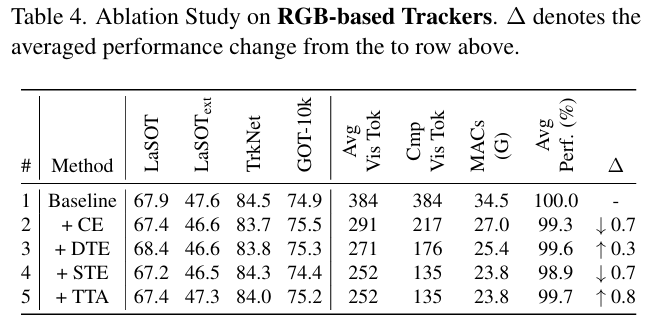
基于 RGB 跟踪的组件分析: 在表 4 中,基线每层处理 384 个令牌,成本为 34.5G MACs。随着 CE、DTE 和 STE 的逐步添加,令牌减少到 135(剪枝 65%65\%65%),MACs 减少到 23.8G(降低 31%31\%31%),同时保持了 98.9%98.9\%98.9% 的性能。受非零剪枝预算和强 ST 指导的驱动,STE 导致 0.7%0.7\%0.7% 的下降,而 TTA 结合了边界框先验来指导 ST 内的令牌剪枝,减轻了剪枝错误并恢复了 0.8%0.8\%0.8%,达到 99.7%99.7\%99.7%。值得注意的是,虽然 DTE 和 STE(带 TTA)进一步缩小了令牌(321→271→135321 \to 271 \to 135321→271→135),但性能并非单调下降:DTE 比 CE 产生了 +0.3%+0.3\%+0.3% 的提升,STE(带 TTA)比 DTE 产生了 +0.1%+0.1\%+0.1% 的提升,表明剪枝冗余可以提高泛化能力。总体而言,完整框架在最小损失的情况下提供了大量的冗余和计算削减。
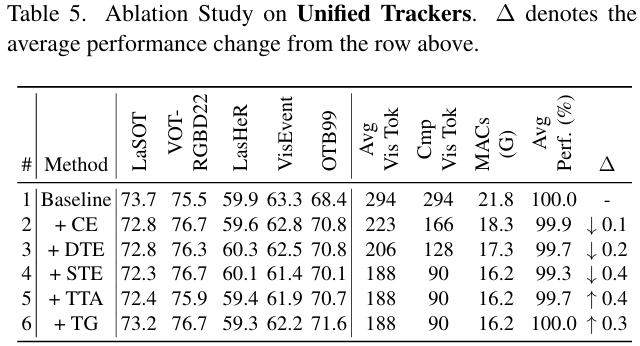
统一跟踪的组件分析: 表 5 报告了消融结果。基线每层处理 294 个令牌,MACs 为 21.8G。与 RGB 情况类似,CE、DTE 和 STE(带 TTA)将平均视觉令牌减少到 188,并在 16.2G MACs 下实现了 99.7%99.7\%99.7% 的性能。TG 利用基于语言的先验来突出与目标相关的语义,进一步将性能提高到 100.0%100.0\%100.0%。这些结果证明了我们的剪枝框架在统一跟踪上的鲁棒性和泛化能力。
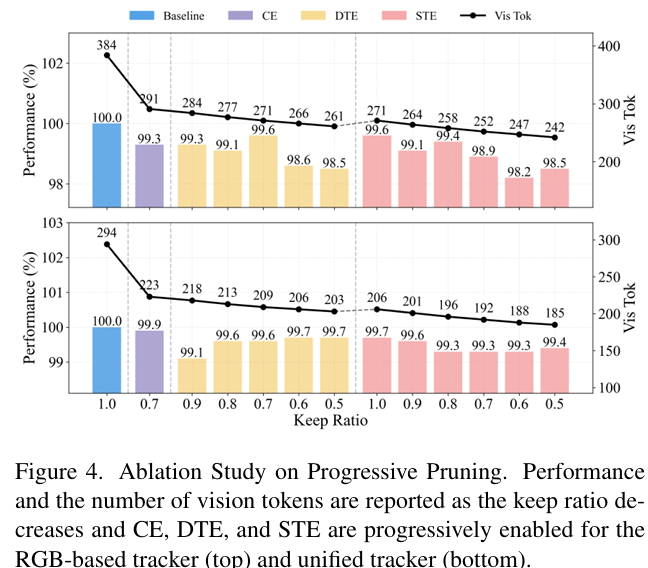
渐进剪枝分析: 如图 4 所示,我们对基于 RGB 和统一基线进行了渐进剪枝研究,通过依次从 SR、DT 和 ST 中移除令牌。该计划稳步减少了视觉令牌的数量,同时使两种跟踪器的性能与基线保持紧密一致。在大多数阶段,准确度保持在原始值的 1−2%1-2\%1−2% 以内,仅在最激进的剪枝率下略有下降,表明 SR、DT 和 ST 中有很大一部分令牌是冗余的,可以安全地移除。总体而言,我们以极小的跟踪精度影响实现了令牌数量和计算的大幅减少。
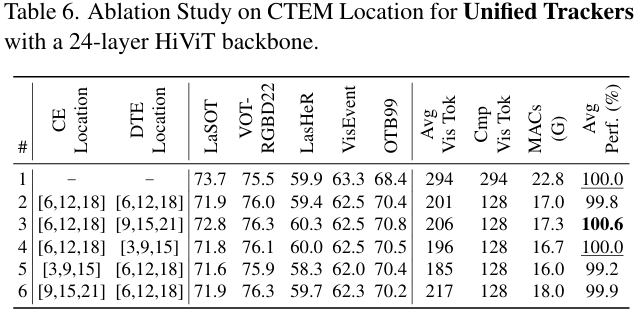
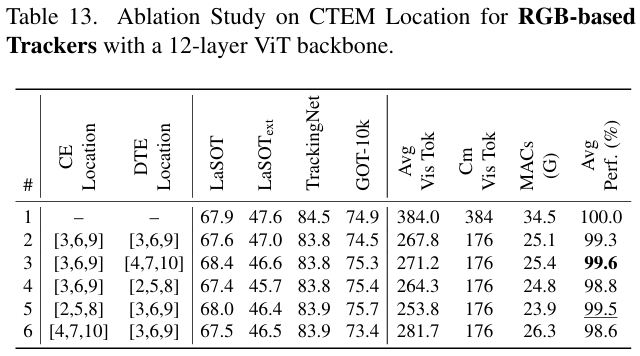
剪枝位置分析: 如表 6 所示,我们系统地评估了统一跟踪器中 CE 和 DTE 组件的不同逐层剪枝配置。基于实证结果和对性能与效率权衡的细致考虑,我们选择了一个配置(#3),即在层 6,12,186, 12, 186,12,18 剪枝 CE,在层 9,15,219, 15, 219,15,21 剪枝 DTE,建立了性能与效率之间的良好平衡。
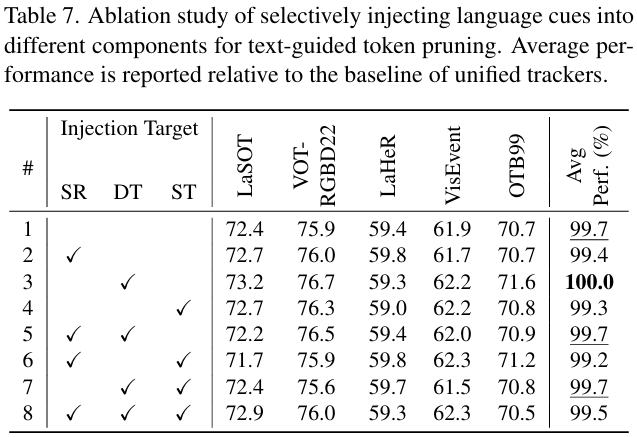
语言线索的选择性注入: 为了进一步验证 TG 的有效性,我们通过选择性地将语言线索注入不同的目标组件(包括 SR、DT 和 ST)进行实验。如表 7 所示,我们评估了所有可能的注入组合。实验结果表明,仅将语言线索注入 DT(#3)即可达到 100.0%100.0\%100.0%,与基线相匹配。这表明 DT 是语言引导剪枝最合适的位置,我们假设这源于其较高的前景集中度。相比之下,将语言注入 SR 或 ST 会导致明显的性能下降。
5. 结论
本工作介绍了 UTPTrack,一个简单统一的令牌剪枝框架,直接解决了现代基于 Transformer 的跟踪器中的效率瓶颈。我们提出了第一种联合压缩搜索区域、动态模板和静态模板的方法,超越了先前工作的孤立剪枝策略。通过利用注意力引导、感知令牌类型的机制,UTPTrack 有效地利用了跨组件冗余,实现了显著的计算节省。其灵活的设计证明了对 RGB 跟踪以及更具挑战性的多模态和语言引导场景均有效。在 10 个基准测试上的全面评估表明,UTPTrack 建立了卓越的精度 - 效率平衡,使其成为开发高性能且实用的视觉跟踪器的强大解决方案。
附录
A. 更多实现细节
训练数据增强: 遵循标准做法,我们在训练期间应用随机水平翻转、颜色抖动和随机裁剪。对于多模态跟踪,深度、热成像和事件通道经历与 RGB 相同的几何变换以保持对齐。文本描述在训练期间保持固定。
剪枝率调度: 为了稳定训练,我们采用渐进式剪枝策略。剪枝率从 0% 线性增加到目标值(例如 65%),跨越前 10 个 epoch。这允许模型适应逐渐减少的令牌数量,防止早期训练阶段的性能崩溃。
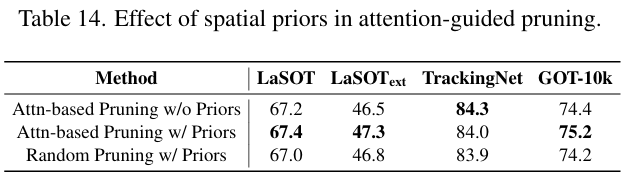
超参数敏感性: 我们分析了关键超参数的影响,包括保留令牌的数量 kkk 和奖励策略的选择。实验表明,性能对 kkk 的选择相对鲁棒,只要保留至少 30% 的令牌。在奖励策略中,软奖励(Soft bonus)始终优于完全奖励(Full bonus)和全有奖励(All bonus),因此作为默认设置。

B. 额外定性结果
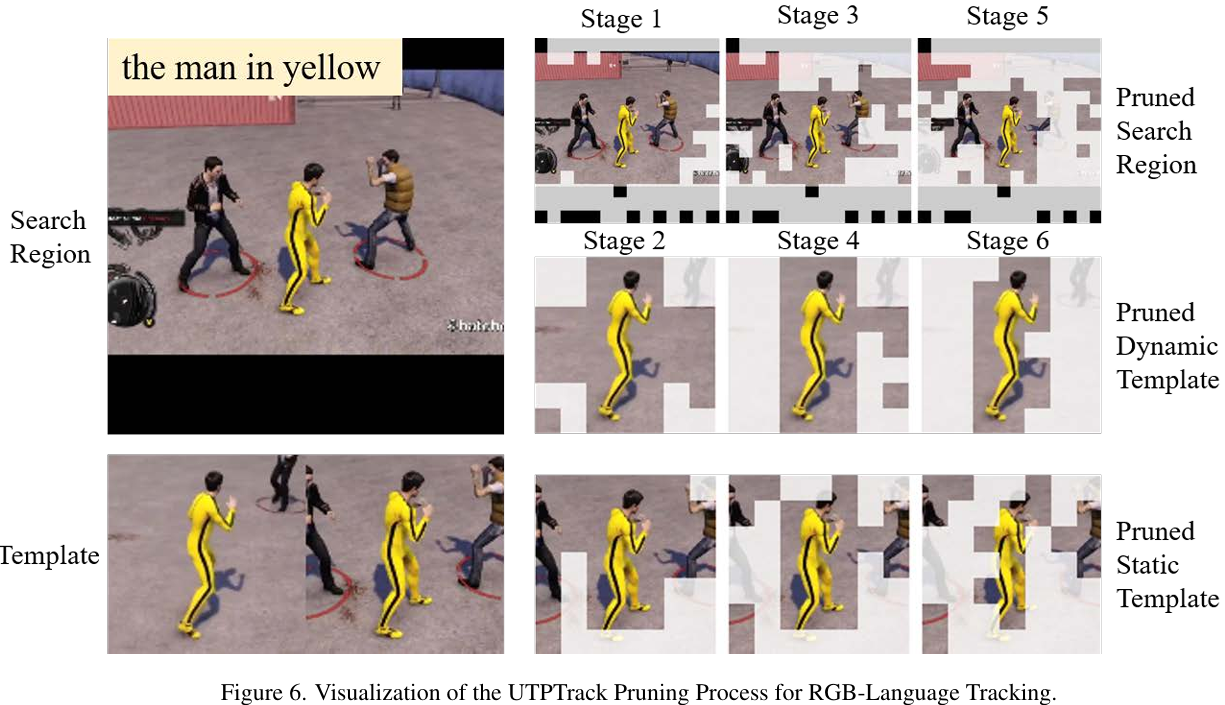
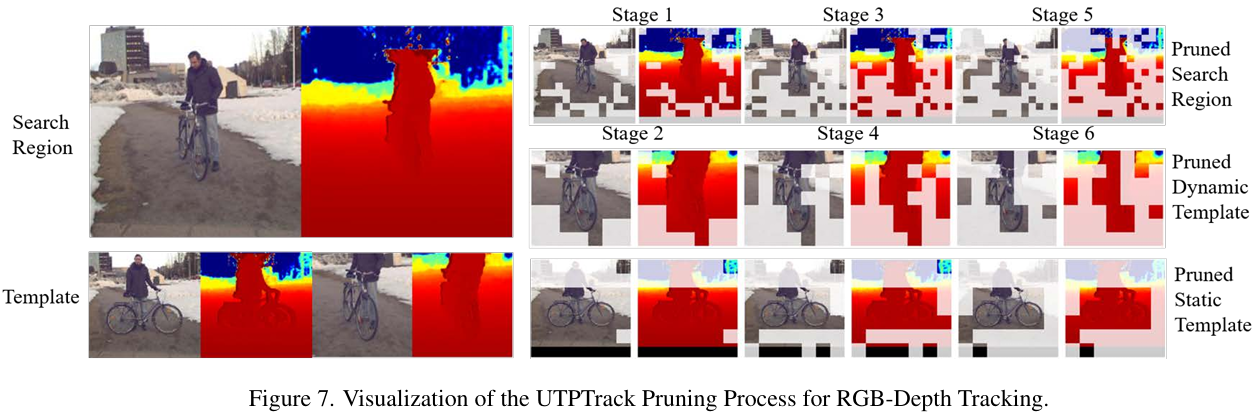
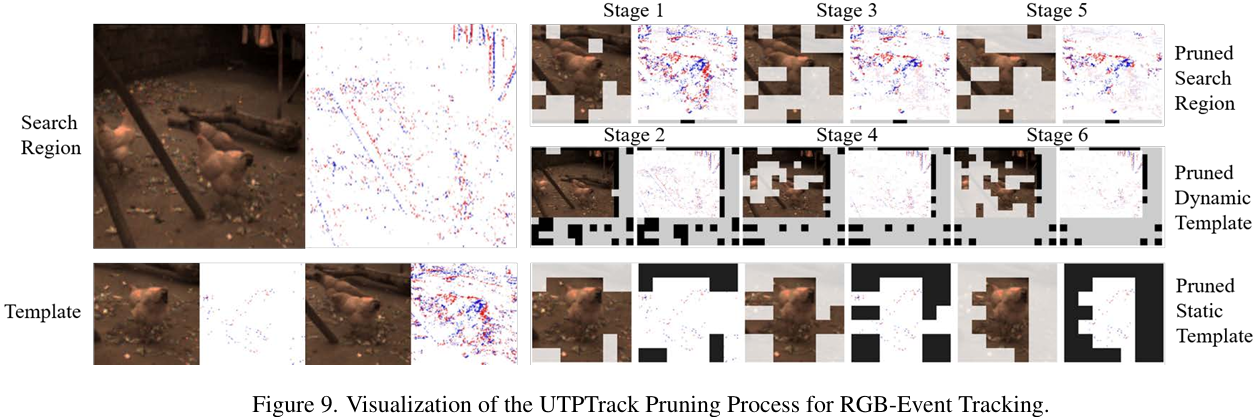
可视化剪枝模式: 图 5 展示了 UTPTrack 在不同场景下的剪枝行为。在基于 RGB 的跟踪中,该方法一致地剪枝搜索区域中的背景令牌,同时保留目标及其周围上下文。在动态模板中,它有效地去除了由于遮挡或漂移引入的噪声令牌。静态模板剪枝保留了目标中心区域,同时去除了无关的背景补丁。
多模态场景: 在 RGB-D 跟踪中,UTPTrack 利用深度信息来指导剪枝,在低纹理区域保留更多令牌,而在高纹理背景区域剪枝更多。在 RGB-T 跟踪中,热成像线索帮助在低光照条件下识别目标,导致更准确的令牌选择。对于语言引导跟踪,文本描述成功地将注意力引导到语义相关的区域,即使在视觉上模糊的目标也能被正确定位。
失败案例分析: 尽管表现强劲,UTPTrack 在极端情况下仍面临挑战。当目标完全被遮挡超过动态模板更新间隔时,剪枝可能错误地丢弃关键令牌。同样,在快速运动导致运动模糊的情况下,注意力相似度度量可能变得不可靠,导致次优剪枝决策。未来的工作将探索结合运动模型来提高这些场景下的鲁棒性。
C. 计算复杂度分析
理论复杂度: 标准 Transformer 的自注意力机制具有 O(N2)O(N^2)O(N2) 的复杂度,其中 NNN 是令牌数量。通过剪枝,UTPTrack 将有效令牌数量减少到 N′=αNN' = \alpha NN′=αN(其中 α<1\alpha < 1α<1),将注意力复杂度降低到 O(α2N2)O(\alpha^2 N^2)O(α2N2)。对于典型的剪枝率 α=0.35\alpha = 0.35α=0.35,这相当于约 8 倍的注意力计算减少。
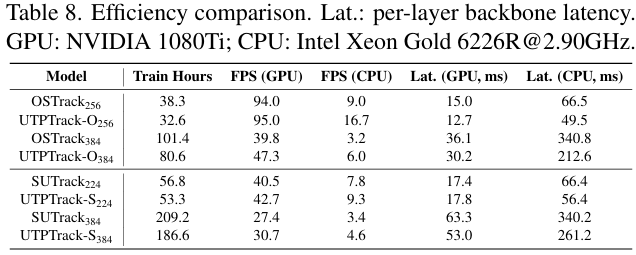
实际加速: 如表 1 所示,UTPTrack 在实际硬件上实现了显著的加速。在 NVIDIA 1080 Ti GPU 上,UTPTrack-O384 达到 58.3 FPS,而未剪枝的基线仅为 34.1 FPS,速度提升 1.71 倍。值得注意的是,由于内存访问模式和内核启动开销,实际加速略低于理论预测,但仍然非常显著。
内存节省: 除了计算减少外,令牌剪枝还降低了内存占用。激活内存减少了约 60%,使得在资源受限设备上部署更大模型成为可能。这对于边缘计算应用尤其重要,其中内存带宽通常是瓶颈。
D. 与其他效率方法的比较
与知识蒸馏的比较: 知识蒸馏通过将大型教师模型的知识转移到小型学生模型来提高效率。然而,这种方法需要额外的训练阶段,并且学生模型的性能通常受限于教师模型。相比之下,UTPTrack 直接优化单个模型,无需教师 - 学生框架,同时实现了可比甚至更好的效率 - 性能权衡。
与神经架构搜索的比较: 神经架构搜索(NAS)自动设计高效架构,但搜索过程计算成本高昂,且得到的架构可能难以解释。UTPTrack 提供了一种更简单、更直接的替代方案,通过令牌剪枝在现有架构上实现效率提升,无需复杂的搜索过程。
与早期退出的比较: 早期退出方法允许样本在网络的早期层退出,以减少计算。然而,这种方法可能导致不同样本之间的推理时间变化很大,使得实时部署复杂化。UTPTrack 提供了一致的推理时间,因为剪枝率在推理期间是固定的,简化了系统集成。
E. 伦理考量与社会影响
隐私保护: 高效的跟踪器如 UTPTrack 可以在边缘设备上运行,减少对云处理的依赖,从而增强用户隐私。本地处理意味着视频数据不需要传输到外部服务器,降低了数据泄露的风险。
环境影响: 通过减少计算需求,UTPTrack 降低了能源消耗,有助于绿色 AI 的发展。在大规模部署场景中,这种效率提升可以显著减少碳足迹。
潜在滥用: 像任何强大的视觉技术一样,高效跟踪器可能被用于监视或其他侵犯隐私的应用。我们鼓励负责任的使用,并呼吁制定适当的监管框架来防止滥用。
F. 代码与数据可用性
开源承诺: 我们承诺开源 UTPTrack 的代码、预训练模型和训练脚本。代码库将包括详细的文档和示例,以促进复现和进一步研究。
数据集许可: 我们使用的所有数据集都遵循其各自的许可条款。对于多模态数据集,我们确保遵守数据使用协议,特别是在涉及敏感信息(如热成像或深度数据)时。
复现性: 为了提高复现性,我们提供了完整的训练日志、超参数配置和评估脚本。我们还计划举办教程和研讨会,帮助社区采用和理解我们的方法。