应用层协议制定
我们知道,协议就是双方约定好的结构化数据,即结构体。而协议制定就是在制定通信双方都能认识的、符合需求的结构化数据。
一般不会直接将结构体直接发送,一是因为不同主机结构体的内存对齐方案可能不同,二是客户端和服务器端使用的语言可能不同,二者都有可能导致接收方将数据错误读取。
发送方应将结构化对象的内容整理合并成一个字符串,这个过程叫做序列化 ,接收方则将该字符串按照特定的格式转换成结构化对象,该过程则称为反序列化。这样做的优点是不管结构体如何变化,通过网络发送的数据都是一串字符串,实现解耦。
序列化和反序列化的操作可以用C++的Json,它来自第三方库jsoncpp ,编译时需要用-l指定。头文件是 jsoncpp/json/json.h,可能需要另外安装
bash
# 安装开发库(包含头文件和动态库)
sudo apt-get update
sudo apt-get install libjsoncpp-dev
# 如果需要命令行工具
sudo apt-get install jsoncpp大致使用方式如下图
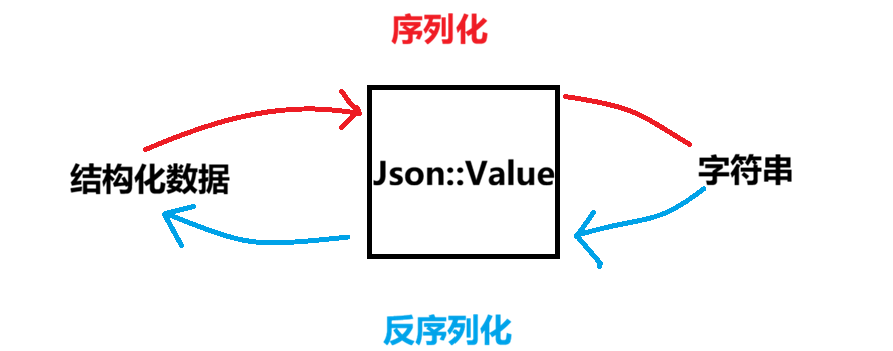
具体序列化方式如下,Request就是要转化为字符串的结构化数据,我们将序列化写成它的成员函数。
cpp
#include <string>
#include <memory>
#include <sstream>
#include <jsoncpp/json/json.h>
class Request
{
public:
Request(int x, int y, char oper) : _x(x),_y(y),_oper(oper)
{}
// 序列化,将结果存放在buf中
bool Serialization(std::string &buf)
{
// 构建映射关系
Json::Value temp;
temp["x"] = _x;
temp["y"] = _y;
temp["oper"] = _oper;
// 生成字符串
Json::StreamWriterBuilder swb; // 用于创建writer,由writer生成字符串
std::unique_ptr<Json::StreamWriter> writer(swb.newStreamWriter());
std::stringstream ss;
try
{
writer->write(temp, &ss);
}
catch (std::exception &e)
{
return false;
}
buf = ss.str();
return true;
}
private:
int _x;
int _y;
char _oper;
};以_x=1, _y=2, oper='+' 为例,序列化后生成的字符串就是下面这样
bash
{"oper":"+","x":1,"y":2}反序列化如下
cpp
#include <string>
#include <memory>
#include <sstream>
#include <jsoncpp/json/json.h>
class Request
{
public:
Request(int x, int y, char oper) : _x(x),_y(y),_oper(oper)
{}
// 反序列化,结果保存在对象内部
bool Deserialization(std::string mes)
{
Json::Value temp;
Json::Reader reader; // writer的同事,负责从大字符串中提取映射关系
if (!reader.parse(mes, temp))//转化为映射关系,存放到Value类型的temp中
{
return false;
}
// 检查字段是否存在
if (!temp.isMember("x") || !temp.isMember("y") || !temp.isMember("oper"))
{
return false;
}
_x = temp["x"].asInt(); //通过temp中的映射提取对应的值
_y = temp["y"].asInt();
_oper = temp["oper"].asInt(); // 不支持转化为char类型
return true;
}
private:
int _x;
int _y;
char _oper;
};在操作系统内核中有网络通信用的缓冲区,如下图。 TCP通信能实现全双工正是因为通信双方共有两对接收和发送缓冲区,发送和接收不会相互干扰。
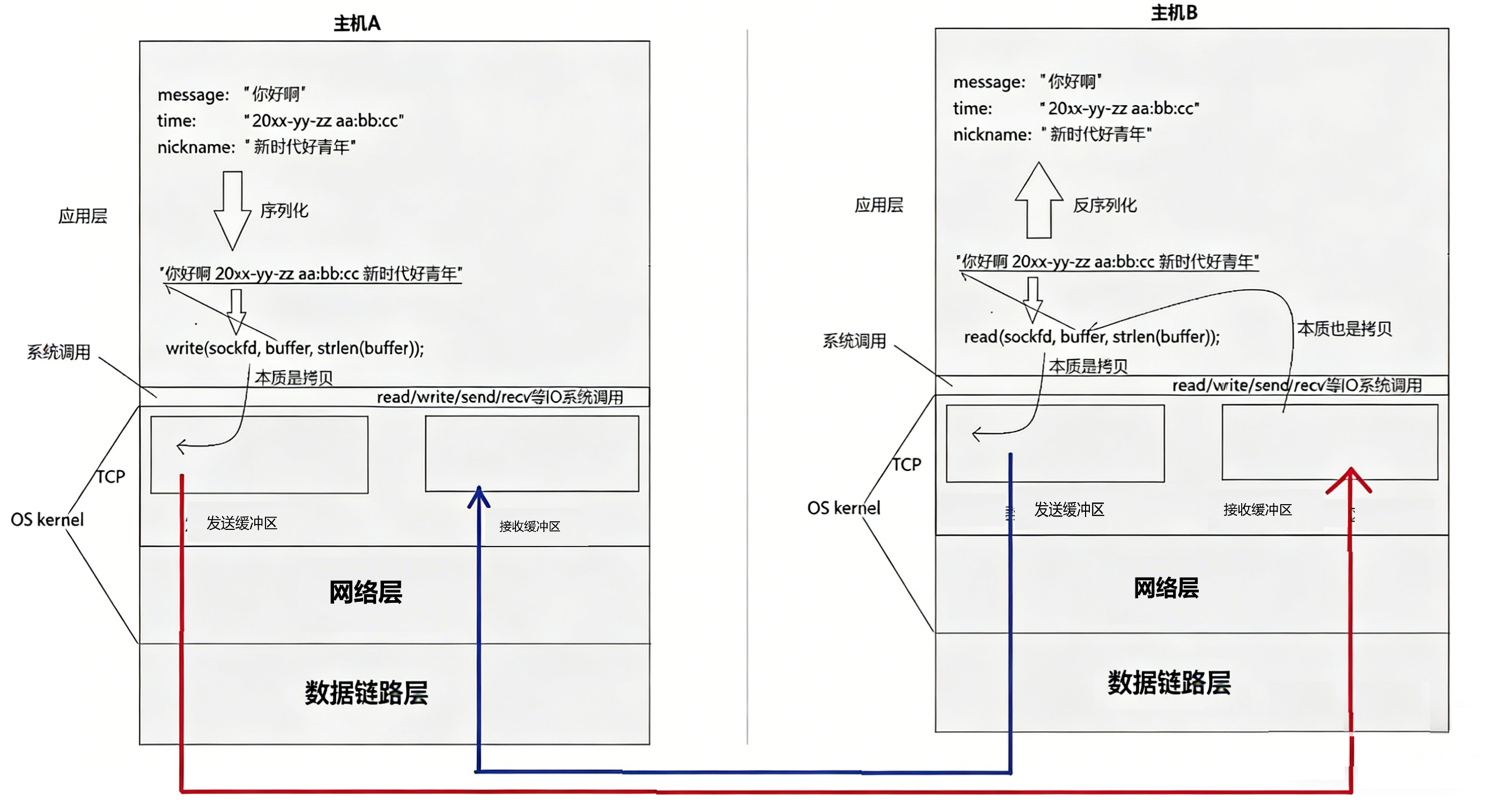
在使用TCP协议时,我们调用的send和recv本质就是拷贝操作,使用send时就是将要发送的内容拷贝到缓冲区中,相应的,调用recv则是从缓冲区中拷贝到程序地址空间。
真正向网络发送数据的是操作系统。什么时候发送、发多少由操作系统根据TCP协议自主决定。而TCP协议是面向字节流的,会将应用层交付的数据统一视为一连串的字节序列。数据输入到缓冲区时,TCP协议不会特地确定数据的边界,这次写入的可能会和上一次写入的数据连在一起。发送时也不会进行划分,所以可能将多组小数据合并发送,也可能将大数据拆分发送。因此,接收方在读取时可能出现一次只读到部分数据(数据不完整 ),或一次读到多组数据(粘包)的现象。
因此,我们在制定应用层协议时,除了设计结构体,提供序列化和反序列化的接口,还需要解决使用TCP协议读取数据的问题。解决办法是为数据序列化后的字符串添加边界,如\r\n,并提供通过边界确定并提取数据的接口。还可以在开头处加上有效字符的长度,方便确定数据是否完整。如下。
bash
24\r\n{"oper":"+","x":1,"y":2}\r\n进程组与会话
进程组是一个或者多个进程的集合, 一个进程组可以包含多个进程。 每一个进程组也有一个唯一的进程组ID (PGID)。单个进程则自己成为进程组。
任务也叫作业,就是某种工作,需要进程来完成。进程是以进程组的形式完成对应的任务的。我们平时使用 | 、&等符号将多条指令组合成一条命令时,本质就是布置了一个任务,会由一个进程组完成,任务中不同部分的指令由进程组内不同的进程完成。
每一个进程组都有一个组长进程。 进程组的PGID等于组长进程的PID 。例如下图,为了执行这条命令,bash创建了一个进程组,该进程组包括 ps 和 cat 两个进程。ps进程就是组长进程。

进程组组长可以创建该组中的进程或者创建一个新的进程组。进程组的生命周期,从进程组创建开始到其中最后一个进程离开为止。只要进程组中有一个进程存在, 则该进程组就存在, 这与其组长进程是否已经终止无关。
会话可以看成是一个或多个进程组的集合, 一个会话可以包含多个进程组。每一个会话也有一个会话 ID(SID)。进程组一定会属于某一个会话,不能单独存在。
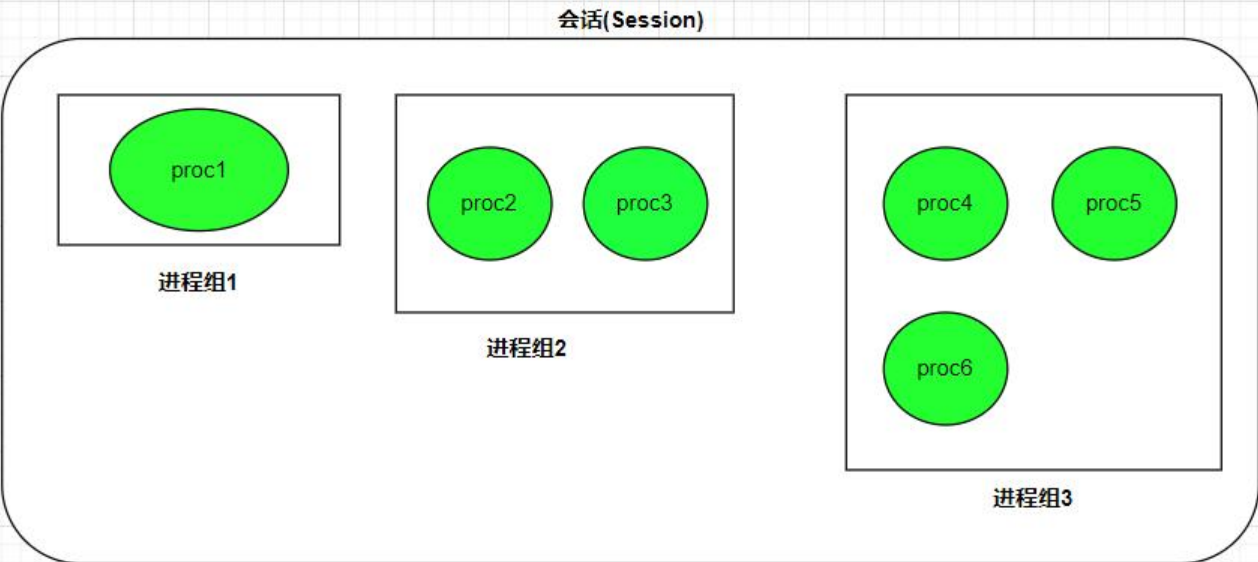
用户登录成功时,操作系统会为用户创建一个会话,其内部有一个进程组,就是bash。系统会将该会话的ID设置为bash进程的 PID。
前台进程组与后台进程组
在每一个会话内部都有两种进程组,前台进程组和后台进程组,键盘产生的信号只能发给前台进程组。当我们使用 ./文件名 直接运行程序时,默认会在前台运行,可以从标准输入中获取内容,即获取键盘输入的内容,这种进程被称为前台进程组 。相应的,使用 ./文件名 & 可以创建后台进程组 **,**它在后台运行,无法从标准输入中获取内容。
前台进程组只能有一个,这是因为每个会话只有一个标准输入,也可简单理解为只有一个键盘,只能向一个进程组中输入数据。而后台进程组则可以有多个。解析命令的bash就是前台进程,当我们输入命令后创建前台进程后,bash就会被操作系统换到后台。另外,当前台进程运行时,按下Ctrl Z会暂停前台进程,此时该进程会被操作系统换到后台,将bash换回前台,否则用户就无法操作了。
使用命令jobs可以查看当前的进程组

方框中的数字即为任务号,使用命令fg 任务号 即可将对应的后台任务(进程组)换至前台。相应的,使用命令bg 任务号 可以将对应的前台进程换至后台。
守护进程化
守护进程化有现成的接口daemon,第一个参数为0时会将进程的工作路径改到根目录下,第二个为0则会将标准IO和错误重定向到null。下面我们了解一下大致的过程。

我们写的服务器端程序也是会话里的一个任务,我们关闭终端时就会关闭会话,此时会话中的任务一般会被关闭。但服务器端的程序不应该受到任何用户登录和注销的影响。因此,需要进行守护进程化。
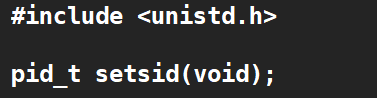
首先调用setsid 让服务器程序拥有独立的会话。调用setsid的进程会进入新会话,脱离终端控制,此时只能通过kill命令对其发送信号进行控制。新会话的ID就是该进程的PID。调用setseid的进程不能是进程组的组长,否则会失败。为了避免这种情况,通常是调用fork然后父进程直接退出,让子进程去调用setsid、继续执行。因为子进程一定不是组长。
其次,还需要需要忽略一些可能影响到服务器进程的信号,如管道的读端关闭,写端会被信号终止。这个使用signal接口即可(下图底行),第一个参数选择要忽略的信号,第二个参数选择SIG_IGN。

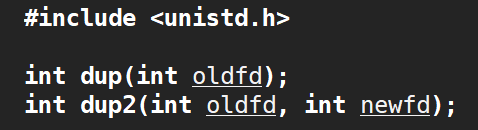
接着,要让服务器进程完全脱离终端,除了不能从键盘获取输入,也不应向显示器输出。为此,可以将文件描述符直接关闭,但更推荐的做法是用dup2将标准IO、标准错误重定向到 /dev/null文件里,这个文件相当于回收站,向其输出的所有内容都会被丢弃,读取时立即返回EOF,什么都读不到。
dup2会让newfd去指向oldfd指向的文件,然后把原来newfd指向的文件关闭。所以只需打开/dev/null,然后向newfd传入标准IO或标准错误的文件描述符,oldfd传入null的文件描述符即可。
最后,要将工作路径改到根目录下,因为服务器进程要一直运行,会一直占用工作路径所在的文件系统,阻碍文件系统的卸载。示例代码如下。
cpp
void Daemonize()
{
//转为子进程
pid_t pid;
pid = fork();
if (pid > 0)
exit(0); // 父进程退出
// 进入新会话
if (setsid() < 0)
exit(1);
// 重定向标准文件描述符
int null_fd = open("/dev/null", O_RDWR);
dup2(null_fd, STDIN_FILENO);
dup2(null_fd, STDOUT_FILENO);
dup2(null_fd, STDERR_FILENO);
// 改变工作目录
chdir("/");
}