技术圈有句玩笑话:"模型没见过的词,就是乱码。"
但在真实场景中,社交评论、直播弹幕、专业术语层出不穷,
如果词向量里查无此词,模型是如何"猜"出意思的?
引言:当模型遇到"yyds"会发生什么?
试想一下,你在训练一个情感分析模型,用来判断微博评论的情感倾向。训练数据里全是规范的书面语,比如"这个电影太棒了"、"服务态度很差"。但上线后,模型遇到了一条实时评论:
"这剧真的yyds,演技绝了!"
模型懵了。
它在词表里翻了个遍------yyds 是什么?查无此词。
这就是典型的 溢出词表词(Out-of-Vocabulary,OOV)问题,也叫"未登录词问题"。
OOV 是自然语言处理中绕不开的坑。只要数据来自真实世界,就一定会遇到新词、拼写错误、缩写、方言、网络用语......如果模型连词向量都构建不出来,那后续的所有任务------分类、翻译、情感分析------都会变成"盲猜"。
那么问题来了:当模型遇到一个它从未见过的词,它该怎么办?
今天,我们就来深入拆解这个问题,并给出两种工业界最主流的解决方案。
一、OOV 带来的三大"后遗症"
在解决问题之前,我们先得搞清楚,OOV 到底有多"痛"。
1. 模型性能直线下降
以文本分类为例,如果一条评论里有一半的词都是 OOV,模型对这句话的语义理解就变成了"断断续续的碎片"。它在向量空间里找不到这些词的坐标,也就无法构建正确的分类边界。最终结果就是:准确率崩了。
2. 泛化能力被削弱
一个优秀的 NLP 模型,应该能处理"没见过但长得像"的实例。但如果模型对 OOV 词毫无办法,它就只能在训练集里"死记硬背",一旦遇到新词就翻车。这样的模型,没法落地。
3. 应用场景受限
医疗、法律、金融等专业领域,充斥着大量术语。多语言场景下,更是有无数不在通用词表中的词汇。如果模型处理不了这些,它的"适用范围"就只能停留在实验室里。
二、解法一:瀑布式查找法------从预训练词向量里"捞"出近似词
第一种思路很直接:既然词表里没有,那能不能从其他预训练的词向量表里找到近似的?
比如,Kaggle 上著名的 Quora Insincere Questions Classification 竞赛中,就有选手采用了一种"瀑布式查找"策略,如下图所示:
(图1-4 流程:原词 → 大小写改写 → 词干提取 → 编辑距离纠错 → 返回结果)
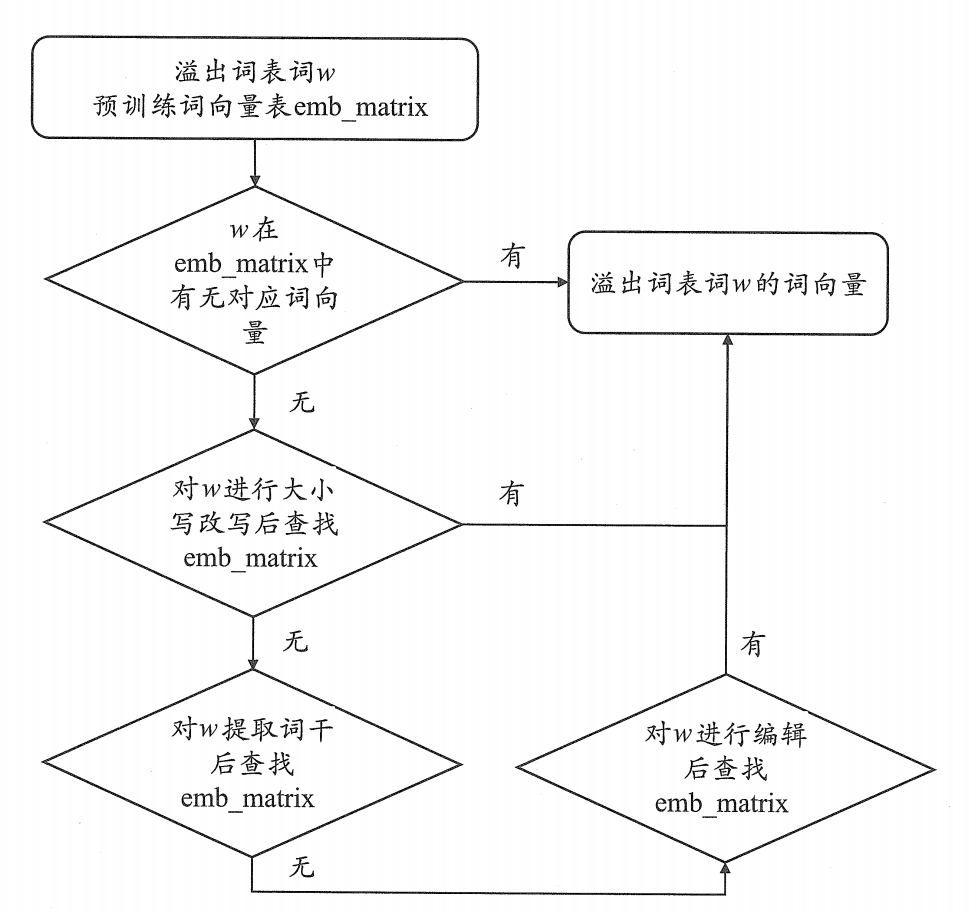
我们来一步步拆解这个流程:
Step 1:直接查
先看看原词在预训练词向量表(如 GloVe、FastText、word2vec)里有没有。如果有,直接拿来用。
Step 2:大小写变换
如果没有,试试全大写、全小写、首字母大写。很多预训练词表里存储的是小写形式,这一步能救回不少词。
Step 3:词干提取
还是找不到?那就用词干提取工具(如 Porter Stemmer、Snowball Stemmer、Lancaster Stemmer)把词还原成词干。比如 running → run,apples → appl。
代码示例:
python
from nltk.stem import PorterStemmer
ps = PorterStemmer()
print(ps.stem("running")) # 输出:runStep 4:拼写纠错
如果词干也查不到,那可能是用户打错了。这时就需要通过编辑距离(Levenshtein distance)生成候选词,找出最有可能的正确拼写。
核心逻辑如下:
-
edits1(word):生成与目标词相差1个编辑距离(增、删、改、换)的所有词。 -
known(words):过滤出在词表中存在的词。 -
correction(word):返回概率最高的候选词。
python
def edits1(word):
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)这个思路的本质是:通过形态变换,找到与 OOV 词"长得最像"的已知词,从而借用其向量。
实战中如何加载词向量?
以 GloVe 为例,加载词向量并构建一个包含未知向量兜底的 embedding matrix:
python
def load_glove(word_dict):
embeddings_index = {}
with open('glove.840B.300d.txt') as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
embedding_matrix = np.zeros((len(word_dict)+1, 300))
for word, i in word_dict.items():
vec = embeddings_index.get(word)
if vec is not None:
embedding_matrix[i] = vec
else:
# 未知向量用-1填充,或随机初始化
embedding_matrix[i] = np.zeros(300) - 1
return embedding_matrix这样,即使某个词在 GloVe 里不存在,我们也能通过瀑布式查找找到一个近似的替代向量。
三、解法二:子词与字符向量------从"词"到"零件"的降维打击
瀑布式查找虽然有效,但也有局限:它依赖于 OOV 词与已知词在"词级别"的相似性。如果遇到一个完全陌生的词,比如 preprocessing,它可能不在词表里,但它的组成部分 pre-、process、-ing 都是常见的。
这时,第二种思路登场:将词拆解成比词更小的单位------子词或字符。
FastText 的突破性贡献
Facebook 提出的 FastText 是这一思路的代表。它不再把词当作最小单位,而是引入了 字符级别的 n-gram。
举个例子,词 applet,设置 n=3(3-gram),它会被拆成:
-
app -
pple -
let
每个 n-gram 都有对应的向量,而 applet 的最终向量就是这些 n-gram 向量的平均(或求和)。
这样一来,即使 applet 从未在训练集中出现,只要它的 n-gram 出现过,模型就能拼凑出它的向量表示。
为什么子词方案更鲁棒?
-
覆盖更广:26 个字母的组合远少于所有单词的组合,字符级 n-gram 能覆盖绝大多数拼写变体。
-
形态学信息 :子词保留了词的形态结构,比如
-ing表示进行时,un-表示否定,这些信息对语义理解很有帮助。
从 FastText 到 BERT 再到 LLM
子词方案后来被几乎所有主流模型采纳:
-
BERT 使用 WordPiece,将词拆成更小的子词单元(如
playing→play+##ing)。 -
GPT 系列使用 BPE(Byte Pair Encoding),同样是基于子词的 tokenization。
-
到了大模型时代,分词算法更加灵活,能同时处理 OOV 和词组表达,比如
New York会被当作一个 token,而不是拆成New和York。
代码层面,如果你使用 HuggingFace 的 Transformers 库,子词分词是"开箱即用"的:
python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("preprocessing")
print(tokens) # 输出: ['pre', '##process', '##ing']模型会为每个子词分配一个向量,然后通过池化(如取平均)得到整个词的表示。
四、两种方案的对比与选择
| 方案 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 瀑布式查找 | 从预训练词表中找到形态最相近的词 | 实现简单,不改变模型结构 | 依赖外部词表质量,无法处理完全新造的词 | 传统 NLP 任务,词表固定,OOV 量较少 |
| 子词/字符向量 | 将词拆解为更细粒度单元,聚合向量 | 覆盖率高,鲁棒性强,能捕捉形态信息 | 增加计算复杂度,需重新训练模型 | 深度学习模型,尤其是预训练语言模型 |
在实际工业界应用中,子词方案已经成为主流。但瀑布式查找在特定场景下仍有价值,比如:
-
你无法重新训练模型,只能通过后处理方式解决 OOV。
-
你需要快速上线一个 baseline,不想动底层 embedding。
-
你处理的是拼写错误较多的短文本,如搜索 query。
五、总结:未登录词,不再是难题
溢出词表词问题,本质上是 "有限词表"与"无限语言"之间的矛盾。
我们介绍了两种主流解法:
-
瀑布式查找法:通过大小写变换、词干提取、拼写纠错等手段,从预训练词表中"借"一个向量。它像是一个"救火队员",在词级别做补救。
-
子词与字符向量法:通过将词拆解成更细粒度的子词或字符,从根本上解决了"没见过"的问题。它像是一个"建筑师",从地基开始构建表示。
从 FastText 到 BERT,再到今天的大模型,子词方案已经深深嵌入现代 NLP 的基因中。它让模型不仅"认识"见过的词,更能"理解"未见的词。
最后,给读者一句忠告:
当你训练 NLP 模型时,永远假设你会遇到 OOV 词。要么提前准备一个强大的预训练词表 + 回退策略,
要么直接选择子词级别的模型架构。
只有这样,你的模型才能真正走向真实世界,面对那些层出不穷的"yyds"、"u1s1"、"绝绝子"。
通过网盘分享的文件:百面大模型链接: https://pan.baidu.com/s/10mycZxNYbh1w63onscj4qA?pwd=iqni 提取码: iqni