数据结构------ST表和RMQ问题
- 数据结构ST表和RMQ问题
-
- ST表维护信息的方式
- [ST 表的查询](#ST 表的查询)
- [ST 表的实现 - 预处理](#ST 表的实现 - 预处理)
- ST表的应用
-
- [P3865 【模板】ST 表 & RMQ 问题 - 洛谷](#P3865 【模板】ST 表 & RMQ 问题 - 洛谷)
- [P1890 gcd 区间 - 洛谷](#P1890 gcd 区间 - 洛谷)
- [P2251 质量检测 - 洛谷](#P2251 质量检测 - 洛谷)
- [P2880 Balanced Lineup G - 洛谷](#P2880 Balanced Lineup G - 洛谷)
- [P1198 最大数 - 洛谷](#P1198 最大数 - 洛谷)
-
- 线段树解法
- [逆向 ST 表解法](#逆向 ST 表解法)
- [P7809 01 序列 - 洛谷](#P7809 01 序列 - 洛谷)
- [OJ 参考](#OJ 参考)
数据结构ST表和RMQ问题
RMQ 问题:区间内最大、最小值查询(Range Minimum/Maximum Query)。对于一个长度为 n n n 的序列,有 m m m 次查询操作,每次查询为一个区间 l , r l, r l,r 的最大值或最小值。
RMQ 问题可以用线段树 解决。对于这种只有查询操作没有修改操作的静态问题,还可以用代码量更少的 ST 表来解决。
ST 表(Sparse Table,稀疏表)也可以称呼为 ST 算法,是基于动态规划 ( 区间dp ) 和倍增 实现的数据结构,形式上是一张二维表格。ST 表通过预处理维护一些区间信息,从而快速处理区间查询。
类似前缀和数组。
其中预处理的时间复杂度为 O ( n log n ) \text{O}(n \log n) O(nlogn),查询操作为 O ( 1 ) \text{O}(1) O(1)。由于在查询前需要预处理,ST 表基本上只能解决静态问题。
ST 表维护的信息需要满足结合律 以及可重复贡献 。可重复贡献是某个操作, 2 个相同的数执行这个操作得到的结果还是这个数,例如区间最值 以及区间最大公约数就是可重复贡献的问题。如果不满足结合律以及可重复贡献,ST 表就不能解决,例如区间和以及区间乘积。
ST表维护信息的方式
ST 表常用于解决 RMQ 问题:对于一个长度为 n n n 的序列,有 m m m 次查询操作,每次查询为一个区间 l , r l, r l,r 的最大值。
由于区间最值不满足可差性,因此不能像前缀和数组一样,搞一张一维的表格来预处理某些区间的信息,尽管可以使用线段树结局,但同样希望能有更加轻量级的数据结构。
可以尝试用区间 dp 的 dp 表来预处理。
由于二维表格可以直接用来表示区间,那么一种直接的方式就是:使用区间 dp , d p i j dpij dpij 表示区间 i , j i, j i,j 的最值。
这种方式肯定是可以解决问题的。但是 RMQ 问题的数组一般都是 10 5 ∼ 10 6 10^5 \sim 10^6 105∼106 级别的长度,这张二维表压根创建不出来,更不用说潜在的遍历超时问题。
ST 表尝试用 2 j = 2 j − 1 + 2 j − 1 2^j = 2^{j-1} + 2^{j-1} 2j=2j−1+2j−1 优化区间 dp 的状态表示:
d p i j dpij dpij 代表的含义为:从 i i i 位置开始,长度为 2 j 2^j 2j 的区间中,所有元素的最值。
此时空间复杂度可压缩到 O ( n log n ) \text{O}(n\log n) O(nlogn) ,可以容纳 10 6 10^6 106 的数组,且求最值时可从 2 个长度为 2 j − 1 2^{j-1} 2j−1 的空间中求解(或进行状态转移)。
以数组 a = 5 , 2 , 4 , 6 , 1 , 7 , 5 , 0 , 9 , 3 a = 5, 2, 4, 6, 1, 7, 5, 0, 9, 3 a=5,2,4,6,1,7,5,0,9,3 为例,我们会用下述方式维护区间最大值信息:
开始时没有处理: 5 2 4 6 1 7 5 0 9 3 1 2 3 4 5 6 7 8 9 10 第0列长度为1: 5 2 4 6 1 7 5 0 9 3 第1列长度为 2: 5 4 6 6 7 7 5 9 9 第2列长度为 4: 6 6 7 7 7 9 9 第3列长度为8: 7 9 9 \begin{matrix} \text{开始时没有处理:} &\begin{array}{|c|c|}\hline5&2&4&6&1&7&5&0&9&3\\\hline1&2&3&4&5&6&7&8&9&10\\\hline\end{array}\\ \text{第0列长度为1:}&\begin{array}{|c|c|}\hline5&2&4&6&1&7&5&0&9&3\\\hline\end{array}\\ \text{第1列长度为 2:}&\begin{array}{|c|c|}\hline5&4&6&6&7&7&5&9&9&\ \ \\\hline\end{array}\\ \text{第2列长度为 4:}&\begin{array}{|c|c|}\hline6&6&7&7&7&9&9&\ \ &\ \ &\ \ \\\hline\end{array}\\ \text{第3列长度为8:}&\begin{array}{|c|c|}\hline7&9&9&\ \ &\ \ &\ \ &\ \ &\ \ &\ \ &\ \ \\\hline\end{array} \end{matrix} 开始时没有处理:第0列长度为1:第1列长度为 2:第2列长度为 4:第3列长度为8:5122436415765708993105246175093546677599 6677799 799
维护方式是在每个长度为 2 i 2^i 2i 的区间内求最值。
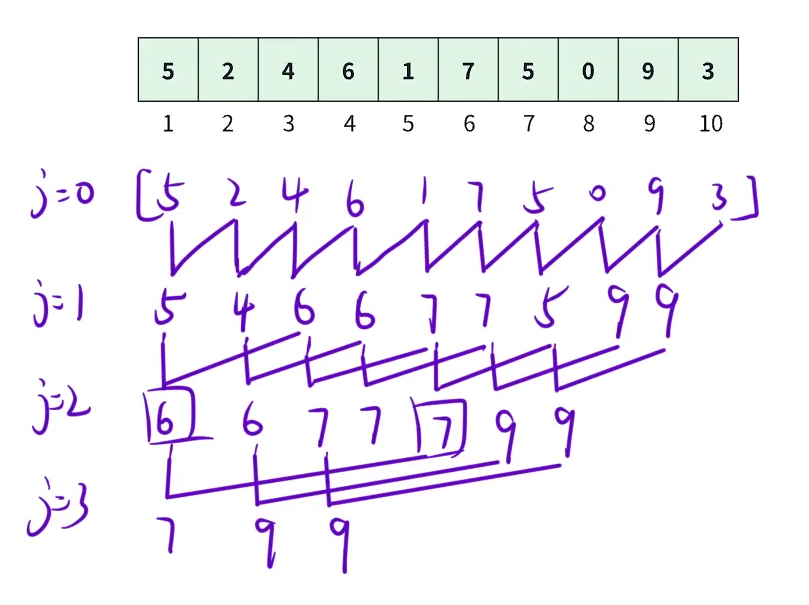
这就是稀疏表的由来,并不是把所有的区间信息存下来,这是暴力算法做的事, ST 表只保存长度为 2 j 2^j 2j 的区间信息。
ST 表的查询
对于每次查询 l , r l, r l,r,可以把它分成两个区间 l , l + 2 k − 1 l, l + 2\^k - 1 l,l+2k−1 与 r − 2 k + 1 , r r - 2\^k + 1, r r−2k+1,r,其中 k = ⌊ log 2 ( r − l + 1 ) ⌋ ≤ r − l + 1 k = \lfloor\log_2(r - l + 1)\rfloor \leq r-l+1 k=⌊log2(r−l+1)⌋≤r−l+1 ,查询的结果就是这两个区间最大值的最大值,重叠部分并不影响。
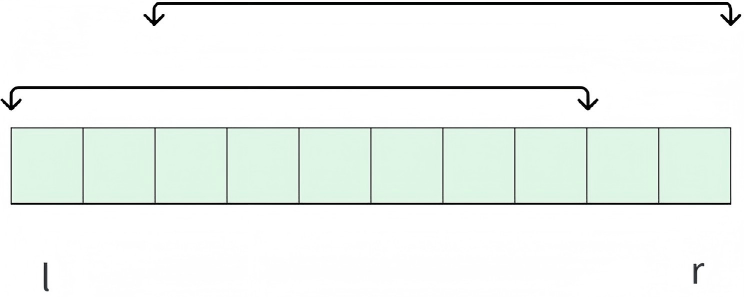
在预处理的 d p dp dp 数组中,拿到 d p l k dplk dplk 和 d p r − ( 1 \< \< k ) + 1 k dpr - (1 \<\< k) + 1k dpr−(1\<\
记忆区间起点和终点的技巧:
- 起点 + + + 区间长度 = = = 下一个区间的起点。即 l + l e n l+len l+len 即为第 2 个区间的左端点。
- 终点 − - − 区间长度 = = = 上一个区间的终点。即 r − l e n r-len r−len 即为第 1 个区间的右端点。
ST 表的实现 - 预处理
可以用动态规划的方式思考:
-
状态表示: d p i j dpij dpij 表示:从 i i i 位置开始,长度为 2 j 2^j 2j 的区间中,所有元素的最大值。
-
状态转移方程:
因为 2 j − 1 + 2 j − 1 = 2 j 2^{j-1} + 2^{j-1} = 2^j 2j−1+2j−1=2j ,所以长度为 2 j 2^j 2j 的区间,可以分成 2 个长度为 2 j − 1 2^{j-1} 2j−1 的区间。
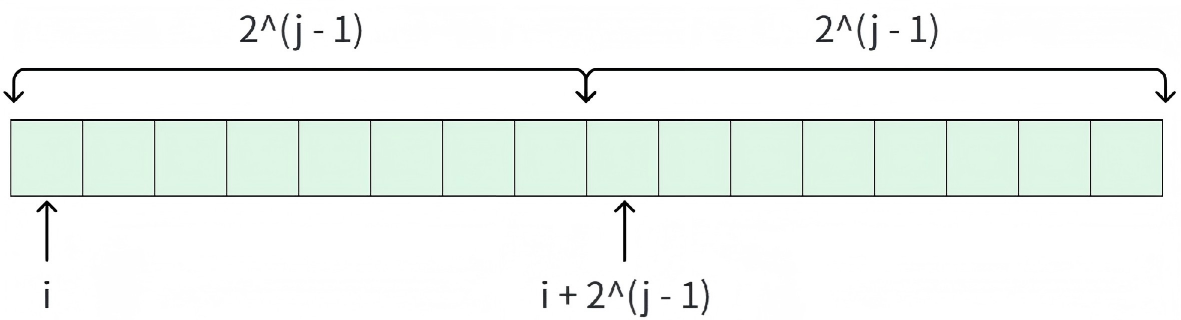
因此, d p i j = max ( d p i j − 1 , d p i + ( 1 \< \< ( j − 1 ) ) j − 1 ) dpij = \max(dpij-1, dpi+(1\<\<(j-1))j-1) dpij=max(dpij−1,dpi+(1\<\<(j−1))j−1) 。这里使用位运算而不使用快速幂的原因是快速幂的时间复杂度是 O ( log j ) \text{O}(\log j) O(logj) ,而位运算在数据量不超过范围的情况下是 O ( 1 ) \text{O}(1) O(1) 。
- 初始化:
区间长度为 2 0 = 1 2^0 = 1 20=1 时,最大值就是数组本身,因此可以把第 0 列初始化为原始数组。
- 填表顺序:
通过小区间转移到大区间。因此第一层循环从小到大枚举 j j j,第二层循环从小到大枚举起点。
注意两个边界:
- 对于 j j j :枚举的区间长度不能超过 n n n,因此 j j j 的最大值应该为 log 2 n \log_2 n log2n。
- 对于 i i i :当区间长度为 2 j 2^j 2j 时,最后一个区间的右端点不能超过 n n n,因此 i + ( 1 < < j ) − 1 ≤ n i + (1 << j) - 1 \leq n i+(1<<j)−1≤n。
优化 :若查询次数过多,求对数时是会有一个 log \log log 级别的开销的。若把 log 2 1 ∼ log 2 n \log_2 1 \sim \log_2 n log21∼log2n 全部预处理出来,则查询操作的 k k k 就可以在 O ( 1 ) O(1) O(1) 时间得到。
对于 log 2 i \log_2 i log2i,容易得到一个关系式:
log 2 i = log 2 ( i 2 × 2 ) = log 2 i 2 + 1 \log_2 i = \log_2 \left( \frac{i}{2} \times 2 \right) = \log_2 \frac{i}{2} + 1 log2i=log2(2i×2)=log22i+1
其中 log 2 1 = 0 \log_2 1 = 0 log21=0,因此可以通过递推,预处理出来所有的 log 1 ∼ log n \log 1 \sim \log n log1∼logn。
ST 表参考(封装):
cpp
using vi = vector<int>;
using vvi = vector<vector<int>>;
struct ST {
vi lg2; // 2的若干次幂
vvi dp; // ST表本体
// 要求 log2(a.size()-1)<dp[0].size()
ST(const vi &a = vi()) {
if (a.size())
init(a);
}
void init(const vi &a) {
lg2.resize(a.size());
dp.resize(a.size(), vi(log2(a.size() - 1) + 1, 0));
// 原本对数函数的定义域是(0,正无穷),这里是方便初始化lg2[1]
lg2[0] = -1;
for (int i = 1; i < a.size(); i++) {
lg2[i] = lg2[i >> 1] + 1;
dp[i][0] = a[i];
}
// 区间dp
for (int j = 1; j <= lg2[a.size() - 1]; j++) // 枚举区间长
for (int i = 1; i + (1 << j) - 1 < a.size(); i++) // 右端点不越界
dp[i][j] = max(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int query(int l, int r) {
int k = lg2[r - l + 1];
return max(dp[l][k], dp[r - (1 << k) + 1][k]);
}
};ST表的应用
P3865 【模板】ST 表 & RMQ 问题 - 洛谷
ST 表模板题,也可当成区间 dp 的题来分析,但也只是分析,不可能开 2 个维度都是 10 5 10^5 105 大小的数组。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vector<int>>;
struct ST {
vi lg2; // 2的若干次幂
vvi dp; // ST表本体
// 要求 log2(a.size()-1)<dp[0].size()
ST(const vi &a = vi()) {
if (a.size())
init(a);
}
void init(const vi &a) {
lg2.resize(a.size());
dp.resize(a.size(), vi(log2(a.size() - 1) + 1, 0));
// 原本对数函数的定义域是(0,正无穷),这里是方便初始化lg2[1]
lg2[0] = -1;
for (int i = 1; i < a.size(); i++) {
lg2[i] = lg2[i >> 1] + 1;
dp[i][0] = a[i];
}
// 区间dp
for (int j = 1; j <= lg2[a.size() - 1]; j++) // 枚举区间长
for (int i = 1; i + (1 << j) - 1 < a.size(); i++) // 右端点不越界
dp[i][j] = max(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int query(int l, int r) {
int k = lg2[r - l + 1];
return max(dp[l][k], dp[r - (1 << k) + 1][k]);
}
};
void IOinit() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
}
int main() {
// freopen("in.in", "r", stdin);
IOinit(); // 没它过不了OJ
int n, m;
cin >> n >> m;
vi a(n + 1, 0);
for (int i = 1; i <= n; i++)
cin >> a[i];
ST st(a);
for (int i = 1; i <= m; i++) {
int l, r;
cin >> l >> r;
cout << st.query(l, r) << '\n';
}
return 0;
}P1890 gcd 区间 - 洛谷
ST表解法
gcd 满足结合率: gcd ( a , b ) = gcd ( b , a ) \text{gcd}(a,b)=\text{gcd}(b,a) gcd(a,b)=gcd(b,a) ,同时也满足可重复贡献,所以可以用 ST 表存储,但初始化和查询的运算方式要从最值变成求 gcd 。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vector<int>>;
void IOinit() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
}
struct ST {
vi lg2;
vvi dp;
ST(const vi &a = vi()) {
if (a.size())
init(a);
}
void init(const vi &a) {
lg2.resize(a.size(), 0);
dp.resize(a.size(), vi(log2(a.size() - 1) + 1, 0));
lg2[0] = -1;
for (int i = 1; i < a.size(); i++) {
lg2[i] = lg2[i >> 1] + 1;
dp[i][0] = a[i];
}
for (int j = 1; j <= lg2[a.size() - 1]; j++)
for (int i = 1; i + (1 << j) - 1 < a.size(); i++)
dp[i][j] = gcd(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int gcd(int a, int b) {
return b ? gcd(b, a % b) : a;
}
int query(int l, int r) {
int k = lg2[r - l + 1];
return gcd(dp[l][k], dp[r - (1 << k) + 1][k]);
}
};
int main() {
// freopen("in.in", "r", stdin);
IOinit();
int n, m;
cin >> n >> m;
vi a(n + 1, 0);
for (int i = 1; i <= n; i++)
cin >> a[i];
ST st(a);
for (int i = 1; i <= m; i++) {
int l, r;
cin >> l >> r;
cout << st.query(l, r) << '\n';
}
return 0;
}区间dp解法
注意到这个题的初始序列长度只有 1000 ,每个数的最大值可达 10 9 10^9 109 ,算上使用欧几里得算法带来的额外耗时和 -O2 优化,勉强可用基于区间上的某个分界点的区间 dp 解决,转移方程为
d p i j = gcd ( d p i k , d p k + 1 j ) dpij=\text{gcd}(dpik,dpk+1j) dpij=gcd(dpik,dpk+1j) ,分界点 k = i + j 2 k=\frac{i+j}{2} k=2i+j 。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vi>;
int gcd(int a, int b) {
return b ? gcd(b, a % b) : a;
}
int main() {
// freopen("in.in", "r", stdin);
vvi dp;
int n, m;
cin >> n >> m;
dp.resize(n + 1, vi(n + 1, 0));
for (int i = 1; i <= n; i++)
cin >> dp[i][i];
// 区间dp
for (int len = 2; len <= n; len++)
for (int i = 1; i + len - 1 <= n; i++) {
int j = i + len - 1;
int k = (i + j) / 2; // 求gcd,分界点只需要1个
dp[i][j] = gcd(dp[i][k], dp[k + 1][j]);
}
for (int i = 1; i <= m; i++) {
int l, r;
cin >> l >> r;
cout << dp[l][r] << '\n';
}
return 0;
}P2251 质量检测 - 洛谷
此题为单调队列模板题。核心依旧是 RMQ 问题,这里使用 ST 表解决。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vector<int>>;
void IOinit() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
}
struct ST {
vi lg2;
vvi dp;
ST(const vi &a = vi()) {
if (!a.empty())
init(a);
}
void init(const vi &a) {
lg2.resize(a.size(), 0);
dp.resize(a.size(), vi(log2(a.size() - 1) + 1, 0));
lg2[0] = -1;
for (int i = 1; i < a.size(); i++) {
lg2[i] = lg2[i / 2] + 1;
dp[i][0] = a[i];
}
for (int j = 1; j <= lg2[a.size() - 1]; j++)
for (int i = 1; i + (1 << j) - 1 < a.size(); i++)
dp[i][j] = min(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int query(int l, int r) {
int k = lg2[r - l + 1];
return min(dp[l][k], dp[r - (1 << k) + 1][k]);
}
};
int main() {
// freopen("in.in", "r", stdin);
int n, m;
cin >> n >> m;
vi a(n + 1, 0);
for (int i = 1; i <= n; i++)
cin >> a[i];
ST st(a);
for (int i = 1; i + m - 1 <= n; i++)
cout << st.query(i, i + m - 1) << '\n';
return 0;
}P2880 Balanced Lineup G - 洛谷
P2880 [USACO07JAN Balanced Lineup G - 洛谷](https://www.luogu.com.cn/problem/P2880)
区间查询时要求同时获得区间最大值和区间最小值,可通过 2 个 ST 表进行维护。这里用函数指针数组丰富 ST 表的功能。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vector<int>>;
void IOinit() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
}
struct ST {
vi lg2;
vvi dp;
vector<int (*)(int &, int &)> ope; // 函数指针数组
int op;
ST(const vi &a = vi(), int _op = 0) {
ope = {mmax, mmin}; // c++11的初始化列表
op = _op;
if (!a.empty())
init(a);
}
static int mmax(int &x, int &y) {
return x > y ? x : y;
}
static int mmin(int &x, int &y) {
return x < y ? x : y;
}
void init(const vi &a) {
lg2.resize(a.size(), 0);
dp.resize(a.size(), vi(log2(a.size() - 1) + 1, 0));
lg2[0] = -1;
for (int i = 1; i < a.size(); i++) {
lg2[i] = lg2[i / 2] + 1;
dp[i][0] = a[i];
}
for (int j = 1; j <= lg2[a.size() - 1]; j++)
for (int i = 1; i + (1 << j) - 1 < a.size(); i++)
dp[i][j] = ope[op](dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int query(int l, int r) {
int k = lg2[r - l + 1];
return ope[op](dp[l][k], dp[r - (1 << k) + 1][k]);
}
};
int main() {
// freopen("in.in", "r", stdin);
IOinit();
int n, q;
cin >> n >> q;
vi a(n + 1, 0);
for (int i = 1; i <= n; i++)
cin >> a[i];
ST st1(a), st2(a, 1);
while (q--) {
int l, r;
cin >> l >> r;
cout << st1.query(l, r) - st2.query(l, r) << '\n';
}
return 0;
}P1198 最大数 - 洛谷
P1198 [JSOI2008 最大数 - 洛谷](https://www.luogu.com.cn/problem/P1198)
线段树解法
可将题目看成区间长度为 m m m 的线段树,此时尾插的操作就变成了单点修改 + + + 区间查询的题。
因为这题首先涉及单点修改,且无法使用树状数组维护,所以第 1 个想到的应该是线段树。
cpp
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
using vl = vector<LL>;
const LL INF = -1e18;
struct Segment_tree {
struct Node {
int l, r;
LL mmax;
};
vector<Node> sgt;
Segment_tree(int n) {
sgt.resize(4 * n + 4, {0, 0, INF});
build(1, 1, n);
}
void build(int p, int l, int r) {
sgt[p] = {l, r, INF};
if (l >= r)
return;
int mid = (l + r) / 2;
build(p * 2, l, mid);
build(p * 2 + 1, mid + 1, r);
}
void modify(int p, int x, LL k) {
if (sgt[p].l == sgt[p].r) {
sgt[p].mmax = k;
return;
}
int mid = (sgt[p].l + sgt[p].r) / 2;
if (x <= mid)
modify(p * 2, x, k);
else
modify(p * 2 + 1, x, k);
adjust_fa(p);
}
void adjust_fa(int p) {
sgt[p].mmax = max(sgt[p * 2].mmax, sgt[p * 2 + 1].mmax);
}
LL query(int p, int l, int r) {
if (l <= sgt[p].l && sgt[p].r <= r)
return sgt[p].mmax;
int mid = (sgt[p].l + sgt[p].r) / 2;
LL ans = INF;
if (l <= mid)
ans = max(ans, query(p * 2, l, r));
if (mid < r)
ans = max(ans, query(p * 2 + 1, l, r));
return ans;
}
};
int main() {
// freopen("in.in", "r", stdin);
LL m, MOD;
cin >> m >> MOD;
Segment_tree stt(m);
for (LL i = 1, ip = 0, lans = 0; i <= m; i++) {
char op;
LL x;
cin >> op >> x;
if (op == 'A') {
// 尾插
stt.modify(1, ++ip, (x + lans) % MOD);
} else {
// 查询数列的末尾x个元素的最大值
lans = stt.query(1, ip - x + 1, ip);
cout << lans << '\n';
}
}
return 0;
}逆向 ST 表解法
一般情况下是无法使用 ST 表的,因为 ST 表只适合解决静态问题。但这题很是特殊,由于是尾部插入,不会对已维护的 ST 表产生影响,而是每新增一个数,就增加一个 log n \log n logn 级别的递推。
例如新插入一个元素 x 6 x_6 x6 :
j = 0 x 1 x 2 x 3 x 4 x 5 j = 1 x 12 x 23 x 34 x 45 j = 2 x 14 x 25 → 插入新元素 x 6 \begin{matrix}j=0&x_1&x_2&x_3&x_4&x_5\\j=1&x_{12}&x_{23}&x_{34}&x_{45}&\\j=2&x_{14}&x_{25}\end{matrix}\xrightarrow{\text{插入新元素}x_6} j=0j=1j=2x1x12x14x2x23x25x3x34x4x45x5插入新元素x6
j = 0 x 1 x 2 x 3 x 4 x 5 x 6 j = 1 x 12 x 23 x 34 x 45 x 56 j = 2 x 14 x 25 x 36 \begin{matrix}j=0&x_1&x_2&x_3&x_4&x_5&x_6\\j=1&x_{12}&x_{23}&x_{34}&x_{45}&x_{56}\\j=2&x_{14}&x_{25}&x_{36}\end{matrix} j=0j=1j=2x1x12x14x2x23x25x3x34x36x4x45x5x56x6
则更新的格子只有 x 6 x_6 x6 相关的格子。但和 x 6 x_6 x6 有关的格子都不好更新,这时可尝试将数据整体右对齐:
j = 0 x 1 x 2 x 3 x 4 x 5 j = 1 x 12 x 23 x 34 x 45 j = 2 x 14 x 25 → 插入新元素 x 6 \begin{matrix}j=0&x_1&x_2&x_3&x_4&x_5\\j=1&&x_{12}&x_{23}&x_{34}&x_{45}&\\j=2&&&&x_{14}&x_{25}\end{matrix}\xrightarrow{\text{插入新元素}x_6} j=0j=1j=2x1x2x12x3x23x4x34x14x5x45x25插入新元素x6
j = 0 x 1 x 2 x 3 x 4 x 5 x 6 j = 1 x 12 x 23 x 34 x 45 x 56 j = 2 x 14 x 25 x 36 \begin{matrix}j=0&x_1&x_2&x_3&x_4&x_5&x_6\\j=1&&x_{12}&x_{23}&x_{34}&x_{45}&x_{56}\\j=2&&&&x_{14}&x_{25}&x_{36}\end{matrix} j=0j=1j=2x1x2x12x3x23x4x34x14x5x45x25x6x56x36
此时只需更新末尾即可。但这样的 ST 表,内部 dp 表的含义需要更改为:
d p i j dpij dpij 表示维护以 i i i 为结尾,长度为 2 j 2^j 2j 的区间的最大值。这种逆向 ST 表。但毕竟这个解法太过冷门,这种题能用线段树就尽量使用线段树。
参考程序如下,也可以当成逆向 ST 表的模板的一种:
cpp
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
using vl = vector<LL>;
using vvl = vector<vl>;
struct ST {
vl lg2;
vvl dp; // dp[i][j]表示以i为重点,长度为2^j的区间内的最值
static const LL INF = -1e18;
ST(LL n) {
// 可边插入边更新,但实际操作很困难,不如一开始就开辟足够空间
lg2.resize(n + 1, 0);
lg2[0] = -1;
for (int i = 1; i <= n; i++) // 初始化对数函数值
lg2[i] = lg2[i / 2] + 1;
dp.resize(n + 1, vl(log2(n) + 1, INF));
dp[0][0] = 0; // 作为ST表的长度计量
}
void insert(LL x) {
LL &ip = dp[0][0];
dp[++ip][0] = x; // 尾插进ST表
for (LL i = 1; i <= lg2[ip]; i++) // 根据当前数据量进行更新
dp[ip][i] = max(dp[ip][i - 1], dp[ip - (1 << (i - 1))][i - 1]);
}
LL query(LL l, LL r) {
LL k = lg2[r - l + 1];
return max(dp[r][k], dp[l + (1 << k) - 1][k]);
}
LL len() {
return dp[0][0]; // 获取j=0时的dp表长度
}
};
int main() {
// freopen("in.in", "r", stdin);
LL m, MOD;
cin >> m >> MOD;
ST st(m);
for (LL i = 1, lans = 0; i <= m; i++) {
char op;
LL x;
cin >> op >> x;
if (op == 'A') {
st.insert((x + lans) % MOD);
} else {
LL len = st.len();
lans = st.query(len - x + 1, len);
cout << lans << '\n';
}
}
return 0;
}P7809 01 序列 - 洛谷
P7809 [JRKSJ R2 01 序列 - 洛谷](https://www.luogu.com.cn/problem/P7809)
看题面的第 1 个棘手的问题就是:最长不下降子序列(LNDS,Longest Non-Decreasing Subsequence)和最长上升子序列(LIS,Longest Increasing Subsequence)无法使用 线段树、树状数组和 ST 表进行维护,但题目却是静态问题 ,此时肯定是需要分析哪些信息需要维护。类似的多种操作的动态、静态问题大都需要如此分析。
-
首先是最简单的 LIS 的查询(软柿子)。因为题目给的序列只有 0 和 1 ,答案只能是 { 1 , 2 } \{1,2\} {1,2} ,前者表示不存在 01 序列,后者表示存在。此时在输入数据时可初始化数组
orz[i]表示区间[1,i]内的 01 数对的个数(one,zero,orz )。然后比较
orz[l-1]是否等于orz[r],等于的话说明 01 序列全都在[1,l-1]这个区间,此时答案是 1;不等的话说明[l,r]存在 01 序列的分布,此时答案是 2 。这个分析思路可以看成是用动态规划解决这个子问题,即转移方程为
orz[i]=orz[i-1]+(a[i]==1&&a[i-1]==0)。 -
然后就是硬骨头 LNDS 的查询。因为题目给的序列只有 0 和 1 ,所以 LNDS 有 3 种情况:全为 0 ,全为 1 ,一部分为 0 一部分为 1 。所以这个区间的 LNDS 的长度就是这个区间的三种序列最长的那个。
-
全为 0 和全为 1 比较好处理,直接维护一个 0、1 的出现次数的前缀和,用区间相减的形式查询即可。
-
一部分为 0 一部分为 1 的 LNDS,这个情况最难分析的,因为 0 的区域和 1 的区域会存在一个不确定的分界线,例如 0000 ∣ 111 0000|111 0000∣111 。这个分界线还会改变,所以想要得到这类子序列中最长的那一个,需要遍历分界线。
假设这个分界线是 k k k ,则这个 01 序列的全为 0 部分的区间为 l , k l,k l,k ,LNDS 的长度是 z e r o k − z e r o l − 1 zerok-zerol-1 zerok−zerol−1 ,同理全为 1 的部分的区间是 k + 1 , r k+1,r k+1,r ,长度是 o n e r − o n e k oner-onek oner−onek 。将 2 个部分累加在一起就是这个 01 序列内的 LNDS 的长度 o n e r − o n e k + z e r o k − z e r o l − 1 oner-onek+zerok-zerol-1 oner−onek+zerok−zerol−1 。
然后遍历所有的 k ∈ [ l , r ) k\in[l,r) k∈[l,r) ,则这个序列的长度的最大值是
max ( o n e r − o n e k + z e r o k − z e r o l − 1 ) \text{max}(oner-onek+zerok-zerol-1) max(oner−onek+zerok−zerol−1)
其中 o n e r oner oner 和 o n e l − 1 onel-1 onel−1 已知,可将这 2 项提取出来:
o n e r − z e r o l − 1 + max ( z e r o k − o n e k ) oner-zerol-1+\text{max}(zerok-onek) oner−zerol−1+max(zerok−onek)
此时 max ( z e r o k − o n e k ) \text{max}(zerok-onek) max(zerok−onek) 相当于创建了一个新的序列 { z e r o k − o n e k } \{zerok-onek\} {zerok−onek} ,求这个序列的最值,此时就可以使用线段树或 ST 表进行维护。
-
所以题目需要先维护 3 个数组: o n e , z e r o , o r z one,zero,orz one,zero,orz 和 1 个 ST 表,然后就是一个静态问题。
这个题的数据量极其庞大,使用 scanf 和优化过的 cin 也有超时的可能,需要使用快速读写和快速输出,同时避免使用 vector 。
P7809 [JRKSJ R2 01 序列 - 洛谷](https://www.luogu.com.cn/problem/P7809) 参考程序:
cpp
#include <bits/stdc++.h>
using namespace std;
template <typename T>
void read(T &x) {
char ch = getchar();
x = 0;
while (ch < '0' || ch > '9')
ch = getchar();
while (ch >= '0' && ch <= '9') {
x = x * 10 + ch - '0';
ch = getchar();
}
}
template <typename T>
void print(T x) {
if (x > 9)
print(x / 10);
putchar(x % 10 + '0');
}
const int N = 1e6 + 10;
struct ST {
int dp[N][25]; // log2(N)<20
int lg2[N] = {-1};
void init(int n) {
for (int i = 1; i <= n; i++)
lg2[i] = lg2[i / 2] + 1;
for (int j = 1; j <= lg2[n]; j++)
for (int i = 1; i + (1 << j) - 1 <= n; i++)
dp[i][j] = max(dp[i][j - 1], dp[i + (1 << (j - 1))][j - 1]);
}
int query(int l, int r) {
return max(dp[l][lg2[r - l + 1]],
dp[r - (1 << lg2[r - l + 1]) + 1][lg2[r - l + 1]]);
}
};
int orz[N], one[N], zero[N], a[N];
ST st;
int n, m;
int main() {
// freopen("in.in", "r", stdin);
read(n), read(m);
for (int i = 1; i <= n; i++) {
read(a[i]);
one[i] = one[i - 1] + (a[i]); // c++将布尔值解释为0或1
zero[i] = zero[i - 1] + (!a[i]);
orz[i] = orz[i - 1] + (a[i] == 1 && a[i - 1] == 0);
st.dp[i][0] = zero[i] - one[i]; // 初始化ST表
}
st.init(n); // 初始化ST表
for (int i = 1; i <= m; i++) {
int op, l, r;
read(op), read(l), read(r);
if (op == 2) {
print(orz[r] == orz[l] ? 1 : 2);
putchar('\n');
} else {
int ans = max(one[r] - one[l - 1], zero[r] - zero[l - 1]);
int part3 = one[r] - zero[l - 1] + st.query(l, r);
print(max(ans, part3));
putchar('\n');
}
}
return 0;
}OJ 参考
- ST 表建立后只查询的
P1890 gcd 区间 - 洛谷 一题多解
P2251 质量检测 - 洛谷 一题多解
P2880 [USACO07JAN Balanced Lineup G - 洛谷](https://www.luogu.com.cn/problem/P2880)
- 逆向 ST 表
P1198 [JSOI2008 最大数 - 洛谷](https://www.luogu.com.cn/problem/P1198)
- 综合题
P7809 [JRKSJ R2 01 序列 - 洛谷](https://www.luogu.com.cn/problem/P7809)