在计算几何中,最近点对问题是经典的基础问题:给定平面上的n个点,找到距离最近的一对点。暴力搜索的时间复杂度为O (n²),在数据量较大时效率极低,而分治(Divide and Conquer)可以将时间复杂度优化至O(nlogn),这也是分治思想在几何问题中的经典应用。本文将从问题分析、分治思路、算法实现、复杂度证明全方面解析该问题。
一、问题定义
1.1 问题描述
给定平面上的点集 P={p1,p2,...,pn},其中每个点 pi 包含二维坐标 (xi,yi),求点集中欧氏距离最小的点对 (pi,pj),欧氏距离公式为:dist(pi,pj)=(xi−xj)2+(yi−yj)2。为了简化计算,比较时可直接使用平方距离,避免开方运算。
1.2 暴力搜索
最直观的思路是枚举所有点对,计算每对点的距离并记录最小值,伪代码如下:
def brute_force(P):
min_dist = ∞
for i in 0 to len(P)-1:
for j in i+1 to len(P)-1:
d = dist(P[i], P[j])
if d < min_dist:
min_dist = d
return min_dist时间复杂度 :两层循环搜索所有点对,共 Cn2=2n(n−1) 次计算,复杂度为O(n²)。
问题:当 n 达到 10⁴、10⁵量级时,暴力搜索会因计算量过大直接超时,因此需要更高效的算法。
二、分治算法
分治算法的核心是分而治之 ,将复杂问题拆分为若干个规模更小的子问题,解决子问题后再将结果合并。最近点对问题的分治思路分为三步 :分割(Divide) 、求解(Conquer) 、合并(Merge) ,其中合并是整个算法的难点。
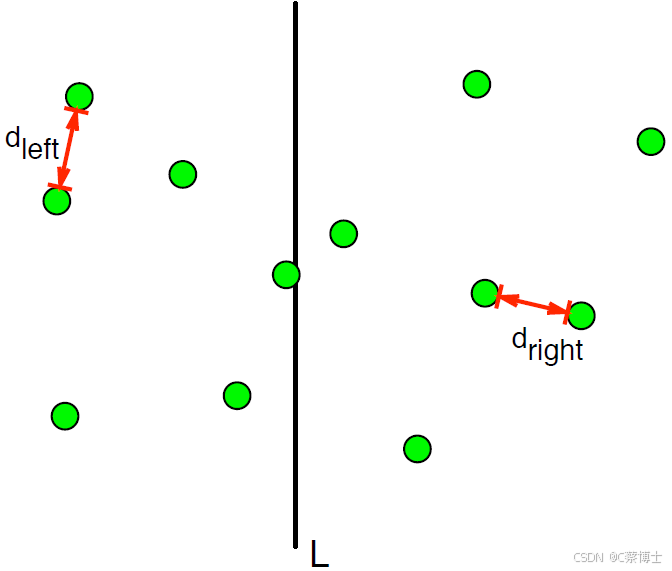
图1 核心思想: 对半分割点集,合并半边结果
为了方便分割和后续处理,需要对原始点集做两次排序:
- 生成按x坐标升序排序的点集 Px(用于分割点集);
- 生成按y坐标升序排序的点集 Py(用于合并阶段的高效查找)。
2.1 步骤 1: Divide
- 找到点集 Px 的中位点,以中位点的 x 坐标为基准画一条竖直线 L,将点集严格划分为左半部分 LP 和右半部分 RP,使两部分的点数量尽可能相等(相差不超过 1);
- 递归求解左半部分的最近点对距离 dleft,递归求解右半部分的最近点对距离 dright;
- 令 d=min(dleft,dright),此时 d 是左右两部分内部的最近点对距离,但跨分割线 L 的点对可能存在比 d 更小的距离,这是合并阶段需要解决的核心问题。
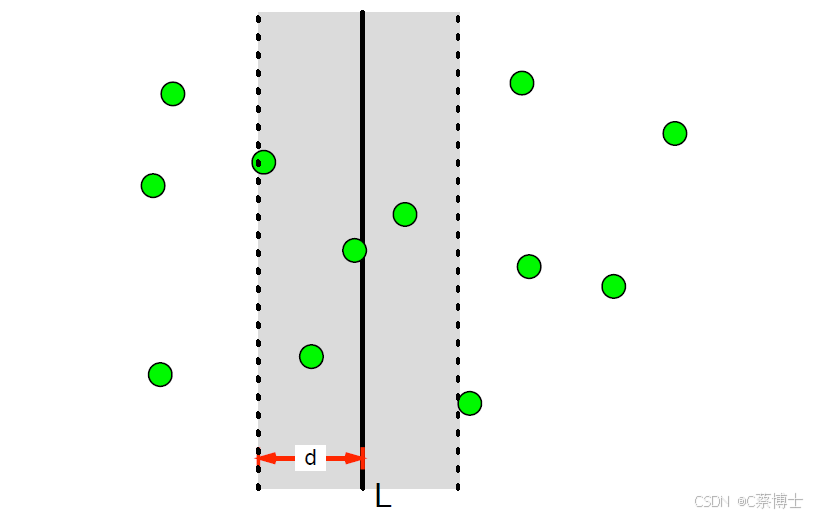
图2 合并的挑战:当某些点对的距离小于d(即两个半边最短距离)并且这些点对分别位于两个半边;换句话这些点对跨越了分割线L。
2.2 步骤 2:Conquer
递归求解子问题的终止条件:
- 当子点集的点数n=2时,直接返回两点间的距离;
- 当子点集的点数n=1时,定义距离为无穷大(单个点无点对)。
2.3 步骤 3: Merge
这是分治算法的核心难点 :如何高效找到跨分割线 L、且距离小于 d 的点对?(见图2)。如果暴力搜索所有跨线点对,会回到 O (n²) 的复杂度,因此需要通过几何性质减少枚举次数。
几何性质 1:跨线点对的范围限制
若存在跨分割线 L 的点对 (pi,pj) 满足 dist(pi,pj)<d,则p_i 和 p_j 一定落在距离L为d的竖条区域内(记该区域为 Slab)。
- 左半部分:L 左侧,x∈x_L-d, x_L;
- 右半部分:L 右侧,x∈x_L, x_L+d。
超出该区域的点,与另一侧的点距离必然≥d,无需考虑。我们从 Py 中筛选出该区域内的点,组成新的点集 Sy(保持 y 坐标升序)。
几何性质 2:S_y 内的点对索引限制
直接枚举 Sy 中的所有点对仍可能是 O (n²),但有一个重要定理:
设 Sy=p1,p2,...,pm(按 y 升序),若任意两点 pi,pj 满足 dist(pi,pj)<d,则它们在 Sy 中的索引差满足 ∣j−i∣≤15。
定理证明:
- 将 Slab 区域划分为边长为 d/2 的正方形小格子;
- 由于左右子区域内部的最近点对距离≥d,每个小格子内最多包含 1 个点(若有 2 个点,距离≤√2*(d/2) < d,与 d 的定义矛盾);
- 对于 Slab 内的任意一点 p_i,距离它小于 d 的点,只能出现在其周围的15 个小格子内(几何空间的最大容纳数);
- 因此,在按 y 排序的 Sy 中,p_i 只需与后续的15 个点比较即可,无需枚举所有点。
合并阶段的具体操作
- 从 Py 筛选出 Slab 区域内的点,得到按 y 升序的 Sy;
- 遍历 Sy 中的每个点 pi,仅与它后续的15 个点 pi+1,...,pmin(i+15,m−1) 计算距离;
- 若存在距离小于 d 的点对,更新 d 为该最小距离;
- 最终的 d 即为整个点集的最近点对距离。
三、分治算法伪代码
为了保证算法的 O (n log n) 复杂度,排序仅在初始阶段执行一次,递归过程中直接复用已排序的 Px 和 Py,避免重复排序。
# 输入:Px(按x升序), Py(按y升序)
# 输出:点集的最近点对距离
def ClosestPair(Px, Py):
n = len(Px)
# 递归终止条件
if n == 1:
return ∞
if n == 2:
return dist(Px[0], Px[1])
# 1. 分割:找中位点,划分为左右两部分
mid = n // 2
mid_point = Px[mid] # 中位点,分割线L为x=mid_point.x
# 拆分Px为左半Lx(≤x_L)、右半Rx(>x_L)
Lx = Px[0:mid]
Rx = Px[mid:n]
# 拆分Py为Ly(≤x_L)、Ry(>x_L)(保持y升序)
Ly = [p for p in Py if p.x ≤ mid_point.x]
Ry = [p for p in Py if p.x > mid_point.x]
# 2. 递归求解子问题
d_left = ClosestPair(Lx, Ly)
d_right = ClosestPair(Rx, Ry)
d = min(d_left, d_right)
# 3. 合并:处理跨分割线的点对
# 筛选出距离L为d的Slab区域内的点,组成Sy(保持y升序)
Sy = [p for p in Py if abs(p.x - mid_point.x) < d]
m = len(Sy)
# 遍历Sy,每个点仅与后续15个点比较
for i in range(m):
for j in range(i+1, min(i+16, m)):
current_d = dist(Sy[i], Sy[j])
if current_d < d:
d = current_d
return d
# 主函数调用
def main(P):
Px = sorted(P, key=lambda p: p.x) # 按x升序
Py = sorted(P, key=lambda p: p.y) # 按y升序
return ClosestPair(Px, Py)四、复杂度分析
分治算法的时间复杂度可通过递推公式 分析,核心是:分割的递归深度 + 每层的合并时间。
4.1 递推公式
设算法处理 n 个点的时间为 T (n),则:
- 初始排序:对 Px 和 Py 排序的时间为O(n log n);
- 递归分割:将问题拆分为两个规模为 n/2 的子问题,时间为 2∗T(n/2);
- 合并阶段:筛选 Sy 的时间为 O (n),两层循环的内层最多执行 15 次,总时间为 O (15n) = O (n);
因此,递推公式为:
- T(n)=2∗T(n/2)+O(n);当 n>2;
- T(1)=O(1) 当n=1;
- T(2)=O(1) 当n=2;
4.2 时间复杂度
该递推公式与归并排序(MergeSort)**完全一致。**对于递推式 T(n)=a∗T(n/b)+f(n),当 a=2,b=2,f (n)=O (n) 时,满足 f(n)=Θ(nlogba)=Θ(n),因此:T(n)=Θ(nlogn)
总时间复杂度 :初始排序 O (n log n) + 分治递归 O (n log n) = O(n log n),远优于暴力解法的 O (n²)。
五、关键要点总结
- 初始排序的必要性:仅在初始阶段对 Px、Py 排序一次,递归过程中复用,避免重复排序导致复杂度升高;
- 分割线的选择:以 Px 的中位点 x 坐标为分割线,保证左右子问题规模均衡,递归深度为 O (log n);
- 合并阶段的优化 :利用几何性质将跨线点对的枚举范围限制为每个点后续 15 个点,将合并时间从 O (n²) 降至 O (n),这是算法能达到 O (n log n) 的核心;
- 距离计算优化 :比较时可使用平方距离代替欧氏距离,避免开方的浮点运算,提升效率。
该算法不仅是计算几何的基础,更是分治思想的经典实践,理解其核心思路有助于掌握分治算法的设计技巧 ------将大问题拆分为规模均衡的小问题,解决后合并结果 ,且合并阶段的效率决定了整体算法的效率。除了最近点对问题,分治思想还广泛应用于排序问题、逆序对计数问题、大整数乘法、矩阵乘法。