最近在做一个文档自动化的副业项目,选型的时候试了一圈,最后还是选了 Claude------代码生成质量和长文本理解都比较稳。
但中文教程真的少,官方文档是全英文的,搜到的大部分教程要么是旧版 SDK,要么只有 Hello World 就结束了。
所以自己踩完坑,写了这篇。本文覆盖:
- 环境配置 & SDK 安装
- 基础调用(同步)
- 流式输出(stream)
- System Prompt 设置
- 多轮对话管理
- 错误处理 & 自动重试
- 一个可直接用的封装类
代码全部验证可运行,Python 3.10+ 均适用。
一、环境准备
bash
# 建议用虚拟环境,避免依赖冲突
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install anthropic
最低版本要求 :anthropic >= 0.39.0,旧版接口有 breaking change,建议直接装最新。
二、最简基础调用
先跑通一个最简单的例子,确认环境没问题:
python
import anthropic
client = anthropic.Anthropic(
api_key="your-api-key", # 替换成你的 Key
base_url="https://api.yutaikeji.cn" # 国内中转节点,省去连接问题
)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024, # 必填,不传会报错
messages=[
{"role": "user", "content": "用一句话解释什么是闭包"}
]
)
print(message.content[0].text)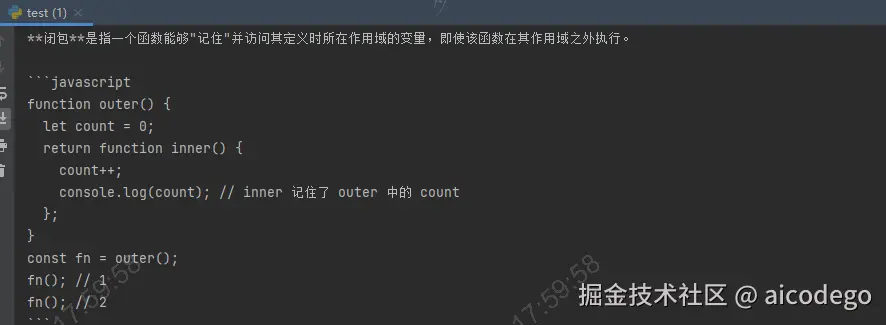
坑1 :
max_tokens是必传参数,忘了会直接抛ValidationError,官方文档没有特别标注,很容易漏。
三、流式输出(Stream)
做聊天界面的话,流式输出是刚需,不然用户盯着空白页等 2 秒体验很差。
python
import anthropic
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.yutaikeji.cn"
)
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "写一首关于深夜写代码的诗"}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True) # flush=True 很关键,否则输出会卡住流式结束后,还能拿到完整的 usage 信息:
python
with client.messages.stream(...) as stream:
full_text = ""
for text in stream.text_stream:
print(text, end="", flush=True)
full_text += text
# 流结束后获取完整 response
final_message = stream.get_final_message()
print(f"\n\n--- Token 用量 ---")
print(f"输入: {final_message.usage.input_tokens}")
print(f"输出: {final_message.usage.output_tokens}")坑2 :用
stream.text_stream是最简单的方式,直接拿文本片段。如果你需要更底层的事件(比如 tool_use),用stream迭代原始事件。
四、System Prompt 配置
Claude 的 system 参数是独立的,不放在 messages 里,这点和 OpenAI 不一样。
python
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="""你是一个资深 Python 工程师助手。
回答规则:
1. 优先给可运行代码,再给解释
2. 代码中加必要注释
3. 指出潜在 bug 或性能问题""",
messages=[
{"role": "user", "content": "写一个带 LRU 缓存的斐波那契函数"}
]
)
print(response.content[0].text)坑3 :如果你从 OpenAI 迁移过来,习惯把 system 放在 messages 第一条------Claude 也支持这种写法,但官方推荐用独立的
system参数,两种都能用,保持一致即可。
五、多轮对话
多轮对话需要自己维护 messages 列表,每轮都要把历史带上:
python
import anthropic
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.yutaikeji.cn"
)
def chat():
messages = []
print("Claude 助手(输入 exit 退出)\n")
while True:
user_input = input("你: ").strip()
if user_input.lower() == "exit":
break
if not user_input:
continue
# 把用户消息加入历史
messages.append({"role": "user", "content": user_input})
# 流式输出回复
print("Claude: ", end="", flush=True)
reply = ""
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=messages
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
reply += text
print("\n")
# 把 Claude 的回复也加入历史,下轮对话才有上下文
messages.append({"role": "assistant", "content": reply})
if __name__ == "__main__":
chat()坑4 :很多人会忘记把
assistant的回复也加入messages,然后发现 Claude 每轮都失忆了。要两侧都 append。
关于上下文长度:Claude 3.5 Sonnet 支持 200K token 的上下文窗口,但长对话还是要做截断处理,否则 Token 费用会快速膨胀。一个简单策略是保留最近 N 轮:
python
MAX_HISTORY = 20 # 保留最近 10 轮对话(20条消息)
if len(messages) > MAX_HISTORY:
messages = messages[-MAX_HISTORY:] # 只保留最近的六、错误处理与自动重试
生产环境里不能让程序一遇到 API 错误就崩。常见错误码:
| 错误码 | 含义 | 处理策略 |
|---|---|---|
| 429 | Rate Limit,请求过快 | 指数退避重试 |
| 529 | API 过载 | 等待后重试 |
| 500/503 | 服务端问题 | 重试最多 3 次 |
| 400 | 请求参数错误 | 不重试,修复参数 |
python
import time
import anthropic
from anthropic import RateLimitError, APIStatusError, APITimeoutError
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.yutaikeji.cn"
)
def call_with_retry(messages: list, max_retries: int = 3) -> str:
for attempt in range(max_retries):
try:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=messages
)
return response.content[0].text
except RateLimitError:
wait = 2 ** attempt # 1s, 2s, 4s 指数退避
print(f"触发限流,{wait}s 后重试(第 {attempt + 1} 次)...")
time.sleep(wait)
except APITimeoutError:
print(f"请求超时,重试中(第 {attempt + 1} 次)...")
time.sleep(1)
except APIStatusError as e:
if e.status_code in (500, 503, 529):
wait = 2 ** attempt
print(f"服务端错误 {e.status_code},{wait}s 后重试...")
time.sleep(wait)
else:
raise # 400 之类的参数错误,直接抛出不重试
raise RuntimeError(f"重试 {max_retries} 次后仍失败")七、一个可直接用的封装类
把上面的逻辑整合成一个干净的 ClaudeClient:
python
import time
import anthropic
from anthropic import RateLimitError, APIStatusError, APITimeoutError
from typing import Generator
class ClaudeClient:
def __init__(
self,
api_key: str,
base_url: str = "https://api.yutaikeji.cn",
model: str = "claude-sonnet-4-6",
system: str = "",
max_history: int = 20
):
self.client = anthropic.Anthropic(api_key=api_key, base_url=base_url)
self.model = model
self.system = system
self.max_history = max_history
self.messages: list = []
def _trim_history(self):
"""保留最近 N 条对话"""
if len(self.messages) > self.max_history:
self.messages = self.messages[-self.max_history:]
def chat(self, user_input: str, stream: bool = False):
"""
发送消息,返回回复文本。
stream=True 时返回生成器,逐字输出。
"""
self.messages.append({"role": "user", "content": user_input})
self._trim_history()
kwargs = dict(
model=self.model,
max_tokens=2048,
messages=self.messages,
)
if self.system:
kwargs["system"] = self.system
if stream:
return self._stream_chat(kwargs)
else:
return self._sync_chat(kwargs)
def _sync_chat(self, kwargs: dict) -> str:
for attempt in range(3):
try:
resp = self.client.messages.create(**kwargs)
reply = resp.content[0].text
self.messages.append({"role": "assistant", "content": reply})
return reply
except (RateLimitError, APITimeoutError):
time.sleep(2 ** attempt)
except APIStatusError as e:
if e.status_code in (500, 503, 529):
time.sleep(2 ** attempt)
else:
raise
raise RuntimeError("请求失败,已重试 3 次")
def _stream_chat(self, kwargs: dict) -> Generator[str, None, None]:
reply = ""
with self.client.messages.stream(**kwargs) as s:
for text in s.text_stream:
reply += text
yield text
self.messages.append({"role": "assistant", "content": reply})
def reset(self):
"""清空对话历史"""
self.messages = []
# 使用示例
if __name__ == "__main__":
claude = ClaudeClient(
api_key="your-api-key",
system="你是一个 Python 专家,回答简洁,优先给代码"
)
# 同步调用
print(claude.chat("用 Python 写一个单例模式"))
# 流式调用
for chunk in claude.chat("给上面的代码加线程安全", stream=True):
print(chunk, end="", flush=True)
print()八、常见报错速查
| 报错信息 | 原因 | 解决方法 |
|---|---|---|
Missing required parameter: max_tokens |
漏传 max_tokens | 加上 max_tokens=1024 |
Invalid API Key |
Key 填错或已过期 | 检查 Key,注意别带多余空格 |
Connection timeout |
网络问题 | 检查 base_url,国内建议走中转 |
Rate limit exceeded |
请求太快 | 加指数退避重试 |
'ContentBlock' object has no attribute 'text' |
旧版写法 | 改成 response.content[0].text |
小结
| 场景 | 写法 |
|---|---|
| 单次问答 | client.messages.create() |
| 流式输出 | client.messages.stream() |
| 多轮对话 | 手动维护 messages 列表,两端都要 append |
| 错误处理 | try/except + 指数退避,区分可重试/不可重试错误 |
| 生产封装 | 用上面的 ClaudeClient 类,开箱即用 |
如果还有问题评论区说,我基本每天都在,看到会及时回复。
工具推荐
本文所有代码在以下环境测试通过:
- Python 3.10 / anthropic 0.40+
- API:玉兔AI(可以直连 Claude API)