资料:
- ① The Illustrated Transformer - Jay Alammar
- ② Building Transformer Models - Jason Brownlee
- ③ Transformer - Dive into Deep Learning
从零开始
环境
bash
conda create -n torch python=3.12
conda activate torch
# Install PyTorch (CPU version)
pip install torch torchvision
# Install PyTorch with CUDA (version <= nvidia-smi shown)
# https://pytorch.org/get-started/locally
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu130运行
- 代码:build_transformer.py
- 关键:Decoder-only, RoPE, GQA, MoE, SwiGLU
bash
cd start-deep-learning/practice/Transformer
pip install -r requirements.txt
python build_transformer.pyBATCH_SIZE 4, 可以改 32,如果显存够大。我呢,训不太动 😢
进化线
之后是概括,给一些关键词。基此问一下 AI,能得到更好的回答呢。
例如,DeepSeek 归纳了 5 条核心进化线,
如果把大模型比作一辆车:
- Attention 是 引擎(GQA/MLA 是省油技术);
- Normalization 是 底盘悬挂(RMSNorm 保证行驶稳定);
- 激活函数 是 燃油标号(SwiGLU 是高标号汽油);
- 位置编码 是 导航系统(RoPE 让你知道该去哪);
- 架构 是 车身设计(Decode-Only 最终统一了赛道)。
这些进化线相互配合,才有了今天又长、又快、又强的 LLM。
架构进化
Encoder-Decoder: 原始,适合 Seq2Seq 任务
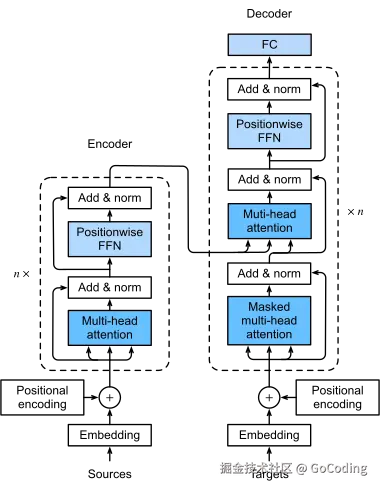
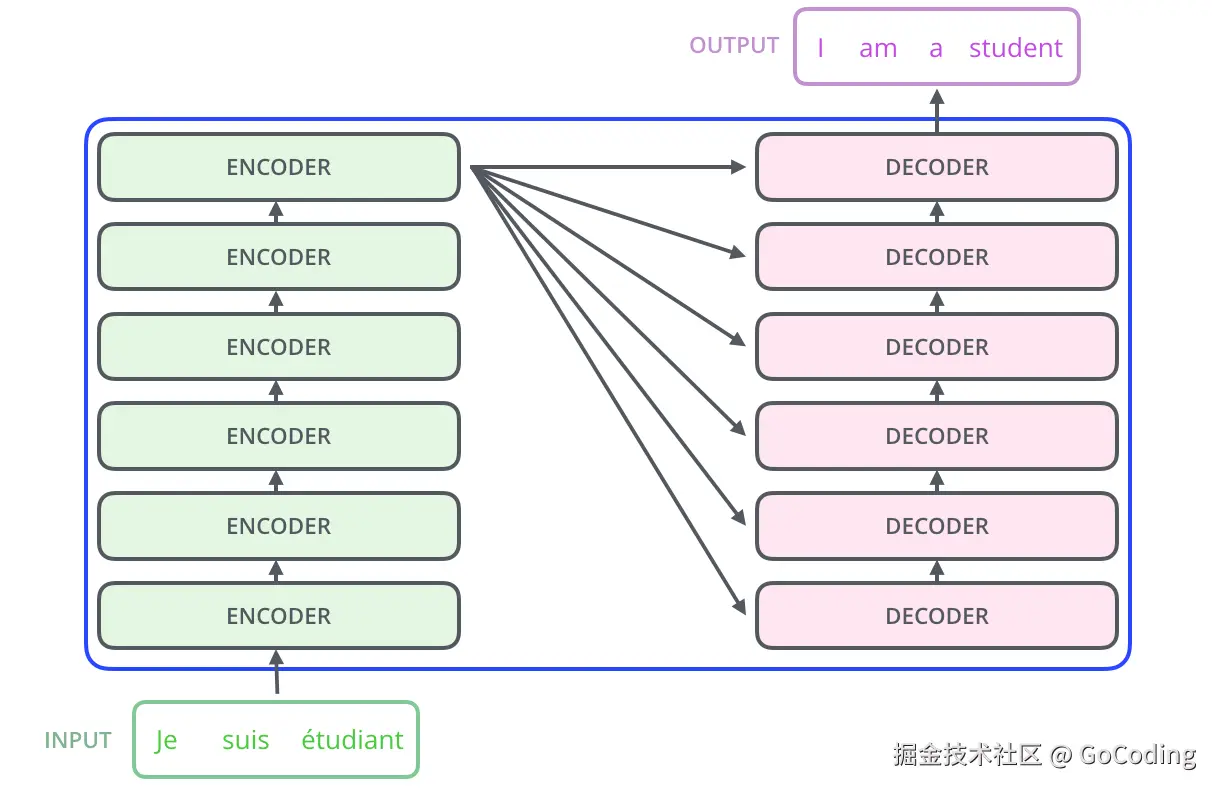
Decoder-only (Causal): 当前,经过 Scaling Laws 验证
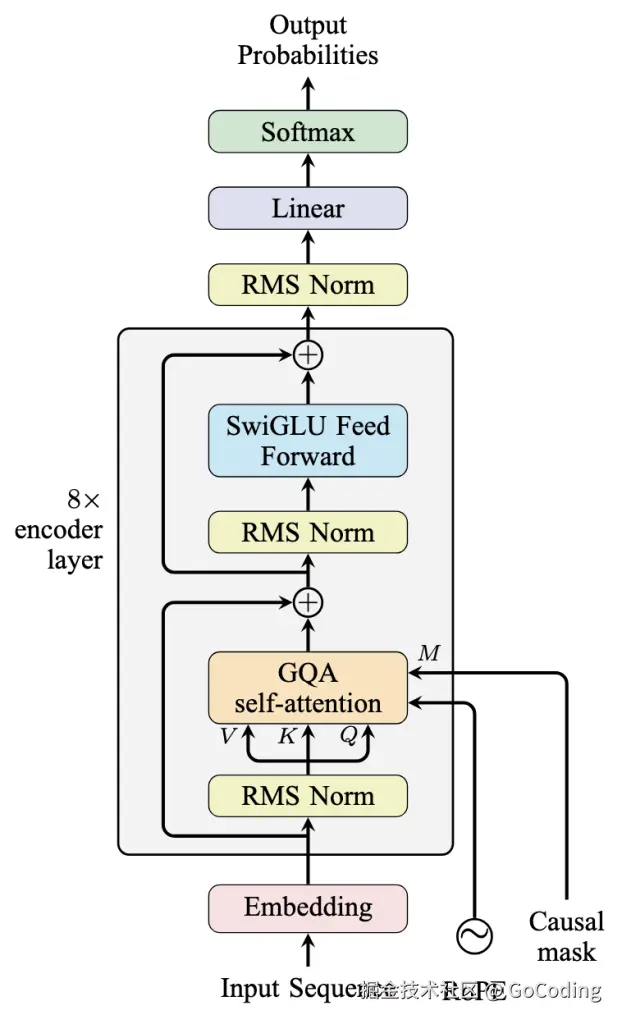
Attention 进化
KV Cache 优化,
| 注意力机制 | KV Cache 量级 | 表达能力 | 核心思想 |
|---|---|---|---|
| MHA (多头注意力) | 最大 (H) | 最强 | 每个头独立看世界 |
| MQA (多查询注意力) | 最小 (1) | 较弱 | 所有人用同一套记忆 |
| GQA (分组查询注意力) | 中等 (G) | 可控 | 分组共享,折中之道 |
| MLA (多头潜在注意力) | 极小 (≈1) | 强 | 压缩记忆,解耦计算 |
计算模式优化,
- Sliding Window Attention (滑动窗口注意力)
- FlashAttention: 改进 GPU 的访存算法
- Sparse Attention (稀疏注意力)
位置编码进化
让模型理解顺序,
- 绝对位置编码
- 相对位置编码
- RoPE (旋转位置编码): 当前主流,更好的长度外推
- ALiBi
激活函数进化
增强非线性,
- ReLU
- GeLU
- SwiGLU
结语
开篇的资料 ① 适合入门,资料 ② 适合实践,都是超级棒的文章,值得学习 👍