摘要
很多人在做 Agent 时会默认认为:Skill 越多,Agent 能力越强。于是把工具说明、操作流程、检查清单、模板规则全部塞进系统 Prompt。结果往往不是 Agent 更聪明,而是工具选择更飘、关键 Skill 不触发、上下文越来越脏,行为也越来越不稳定。
问题不在 Skill 多,而在于:同时暴露给模型选择的 Skill 入口太多、太长、太像。当大量 Skill metadata、工具说明和流程规则一起进入上下文后,会引发三类退化:Listing 截断、Context Rot / 注意力稀释,以及相似 Skill 冲突。
本文将从这三层退化机制出发,解释为什么"堆 Skill"会让 Agent 变笨,并给出一套可落地的治理方案:先盘点 Skill 资产,再缩小自动触发面,用 Fork 隔离长流程,按场景打包能力,并通过日志、僵尸 Skill 清理和安全审计形成持续运维闭环。
开场:Skill 越多,Agent 为什么反而更笨?
"我的 Agent 装了很多 Skill,为什么反而越来越笨?"
这是很多团队在落地 Agent 时都会遇到的问题。
一开始,大家会很自然地把 Skill 当成能力增强包:会写代码就加 Code Review Skill,会查日志就加 Debug Skill,会写文档就加 Doc Skill,会部署就加 Deploy Skill。
看起来很强。
但真正跑起来之后,问题开始出现:
- 该触发的 Skill 没触发;
- 不该触发的 Skill 被误调用;
- 相似 Skill 之间互相干扰;
- 系统 Prompt 越写越长;
- 上下文越来越乱;
- Agent 的输出越来越不稳定。
于是很多人会得出一个结论:是不是 Skill 不能太多?
其实更准确的说法是:
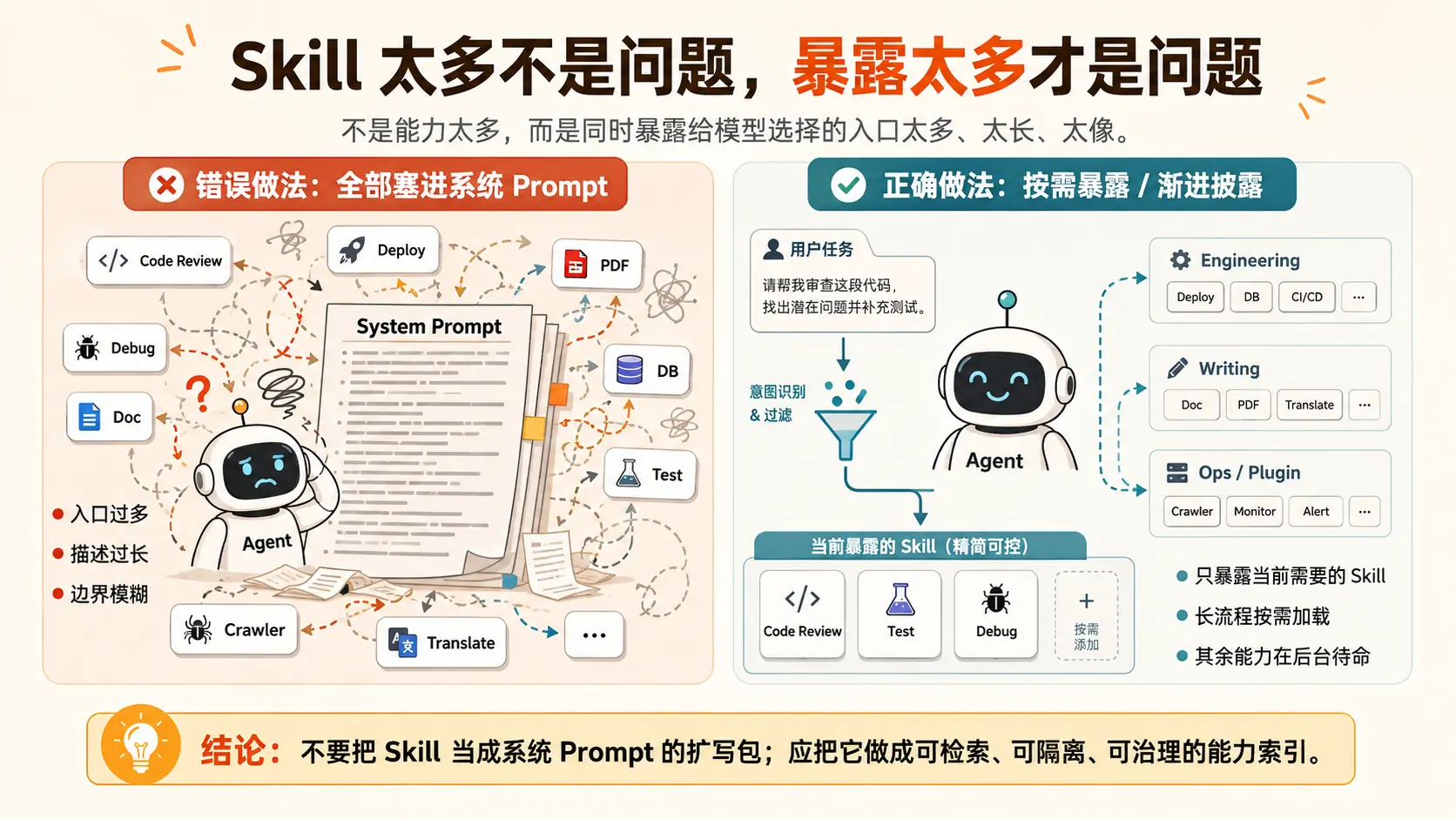
Skill 不是不能多,而是不能全部同时暴露给模型。
成熟的 Agent 能力系统,不是把所有工具、流程和规则都塞进 Prompt,而是把 Skill 做成一个可检索、可隔离、可治理的能力索引。
一、问题本质:不是能力太多,而是暴露太多
一个 Skill 通常不只是一个名字。它可能包含三层内容:
第一层是入口信息 ,比如 name、description、when_to_use。
第二层是执行说明 ,比如具体流程、检查清单、操作步骤。
第三层是资源文件,比如脚本、模板、示例、参考文档。
真正应该常驻在模型面前的,通常只有第一层。后两层应该在相关任务出现时再加载。
这正是 Agent Skills 的核心设计思路。Anthropic 的文档把这种方式称为 progressive disclosure,也就是"渐进式披露":Skill 的 metadata 会作为轻量入口存在;当任务匹配时,再读取 SKILL.md;如果还需要更多细节,再按需访问额外文件、脚本或资源。Claude API 文档也明确把 Skill 内容分为 metadata、instructions、resources/code 三层加载,而不是一开始全部塞进上下文。
参考:platform.claude.com/docs/en/age...
但很多团队落地时刚好反过来:
text
系统 Prompt:
你是一个工程 Agent。
当用户要代码审查时,遵循以下 500 行规则......
当用户要部署时,遵循以下 300 行流程......
当用户要分析日志时,遵循以下 400 行步骤......
当用户要写文档时,遵循以下 200 行模板......这不是 Skill 系统。
这是把系统 Prompt 写成了一份没人能稳定读完的公司操作手册。
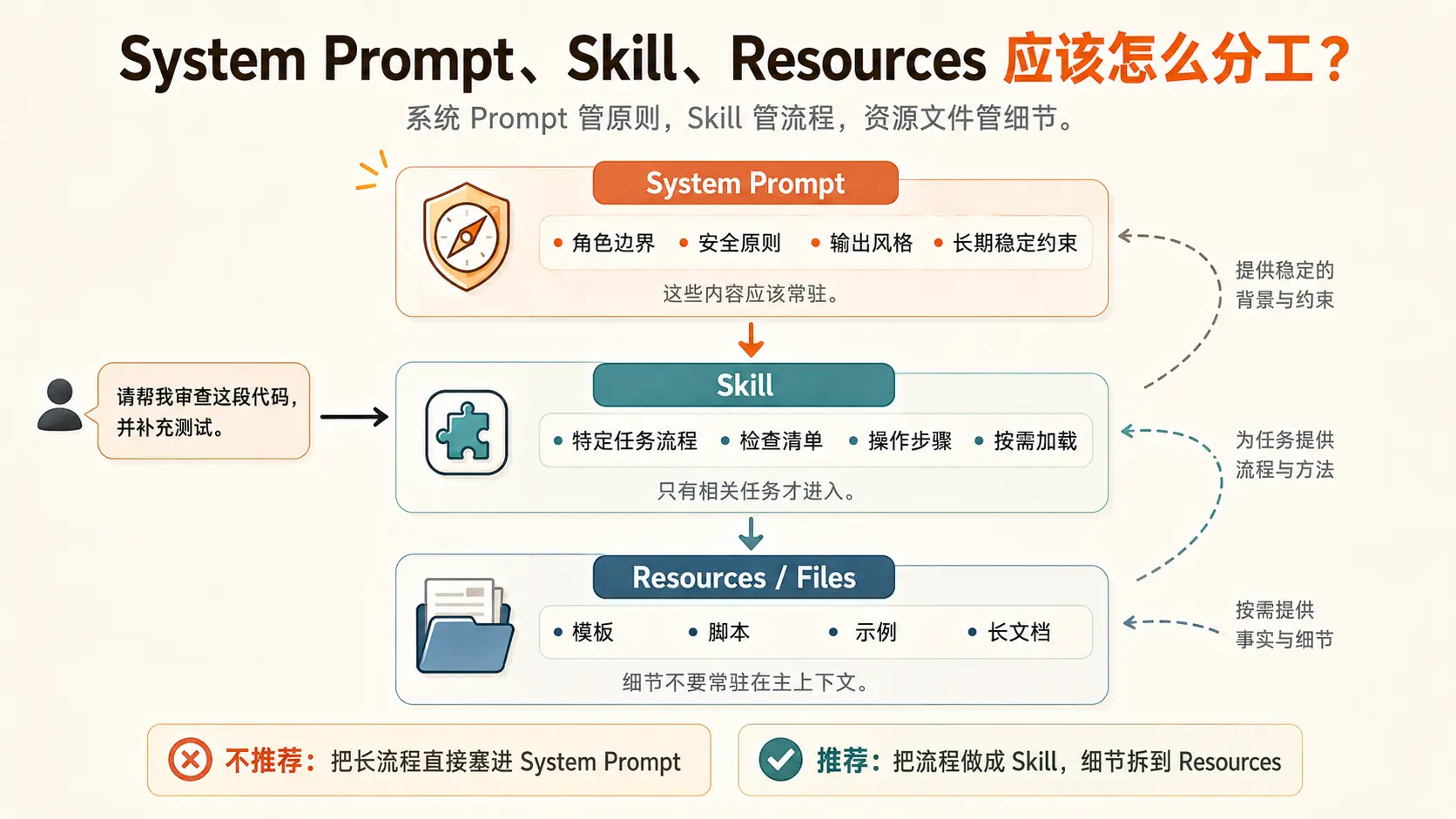
系统 Prompt 应该管长期稳定的原则,比如角色边界、安全原则、输出风格、基础约束。Skill 应该管特定任务流程。Resources 才应该放长模板、脚本、示例和参考资料。
一句话:
系统 Prompt 管原则,Skill 管流程,Resources 管细节。
二、三层退化机理
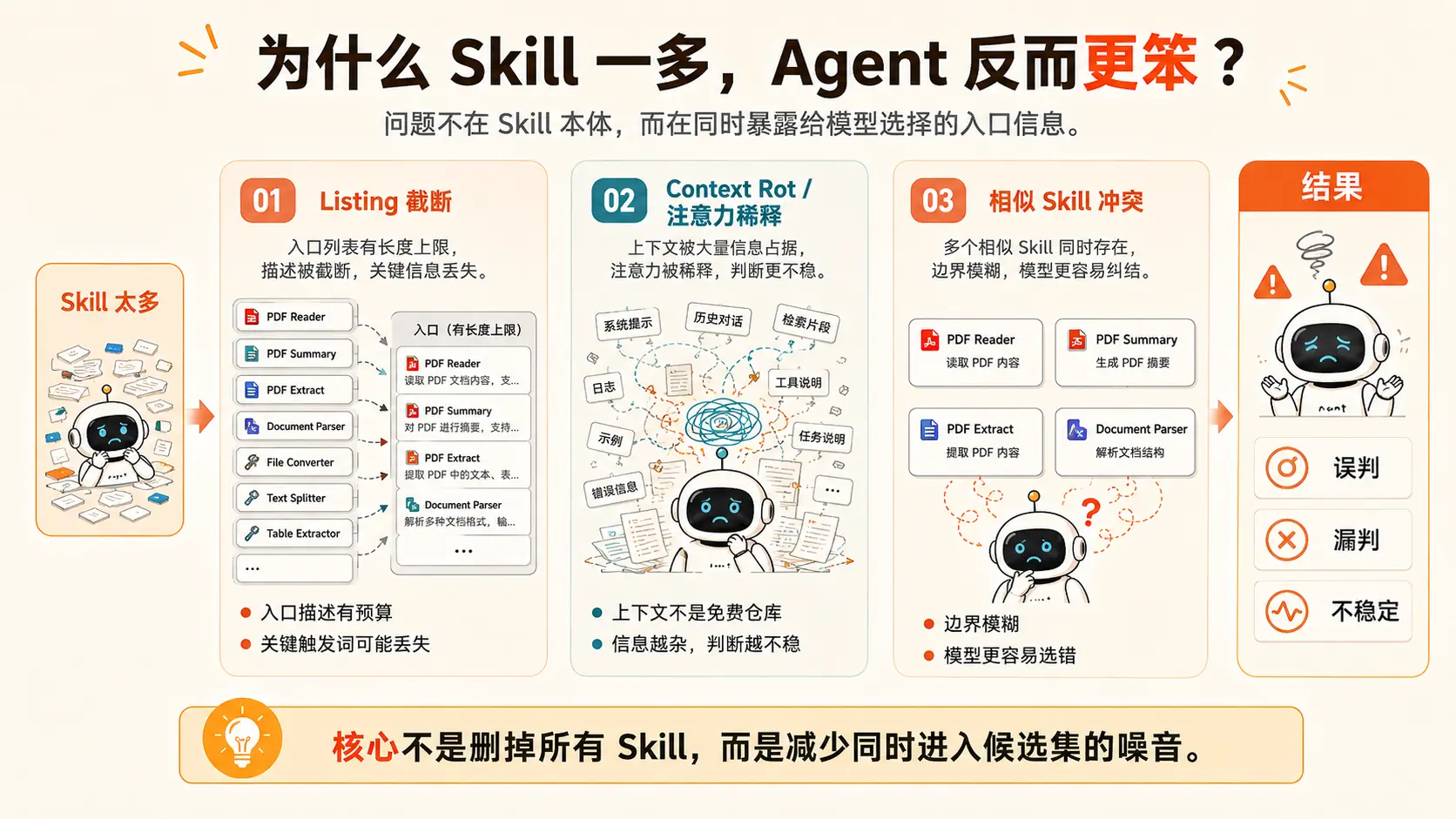
1. Listing 截断:入口描述被压缩,关键触发词丢失
Skill 能不能被正确调用,第一步取决于模型能不能看到一个清楚的入口描述。
以 Claude Code 为例,官方文档明确建议把关键 use case 放在描述最前面,因为 description 和 when_to_use 在 Skill listing 中有字符上限;文档也说明可以用 /doctor 检查 budget 是否溢出,必要时把低优先级 Skill 设成 name-only,或者调整 listing 预算。
参考:code.claude.com/docs/en/ski...
这意味着一件很现实的事:
Skill 明明装了,但模型看到的入口可能已经残了。
比如你写了一个很长的描述:
yaml
description: 这是一个用于复杂企业级项目代码审查的 Skill,
它可以检查安全问题、性能问题、架构问题、数据库迁移问题、
权限控制问题、日志规范问题、错误处理问题......如果真正关键的触发词藏在后面,模型未必能稳定看到。对模型来说,这个 Skill 就像"装了,但入口没写清楚"。
更好的写法是:
yaml
description: Review Django code for ORM misuse, migrations, auth, security, and performance.入口描述不是写论文。
入口描述只负责一件事:让模型知道什么时候该打开这扇门。
2. Context Rot:上下文不是免费仓库
很多人对上下文窗口有一个误解:
只要窗口够大,我就可以什么都塞进去。
但长上下文不是免费仓库。它更像一个会变脏的工作台。
Chroma 在 Context Rot 报告中指出,模型并不会均匀处理长上下文;随着输入长度增长,模型表现会变得更不可靠,即使在一些简单任务上也会出现波动。
参考:www.trychroma.com/research/co...
这件事放到 Agent 上尤其明显。
Agent 跑一段时间后,上下文里可能堆满了:
- 已经失败的尝试;
- 过时的中间结论;
- 没用上的工具输出;
- 相似但冲突的规则;
- 冗长的 Skill 说明;
- 大量日志、检索片段、历史对话。
你以为是在增强 Agent,实际是在稀释它的判断力。
Claude Code 文档也提醒:Skill 一旦被调用,渲染后的 SKILL.md 内容会进入对话并在后续 session 中持续存在;因此 Skill body 应该保持简洁,因为每一行都会变成持续的 token 成本。
参考:code.claude.com/docs/en/ski...
所以,Skill 的设计原则应该是:
默认不进主上下文,需要时再进入。
3. 相似 Skill 冲突:边界模糊,模型更容易选错
比 Skill 多更危险的,是 Skill 像。
比如你有这些 Skill:
text
pdf-reader
pdf-summary
pdf-extract
document-parser
file-analyzer如果它们的描述都写成"处理 PDF 文件"或"分析文档内容",模型就会开始纠结。
用户说:"帮我总结这个 PDF。"
到底应该用 pdf-reader,还是 pdf-summary?
如果要提取表格,是 pdf-extract,还是 document-parser?
如果 PDF 是扫描件,又该走哪个?
如果人类工程师看完都说不清楚边界,就不要期待模型每次都能稳定选对。
好的 Skill 描述,必须回答三个问题:
- 什么时候用它?
- 什么时候不要用它?
- 它和相邻 Skill 的边界是什么?
不要这样写:
yaml
description: Use this skill to process PDF files.应该这样写:
yaml
description: Extract tables from PDF files into CSV. Do not use for summarization or OCR-heavy scanned documents.边界越清楚,模型越稳定。
三、正确做法:让大部分 Skill 不进候选集
Skill 管理不是"装更多",而是"暴露更少"。
可以按四步来做。
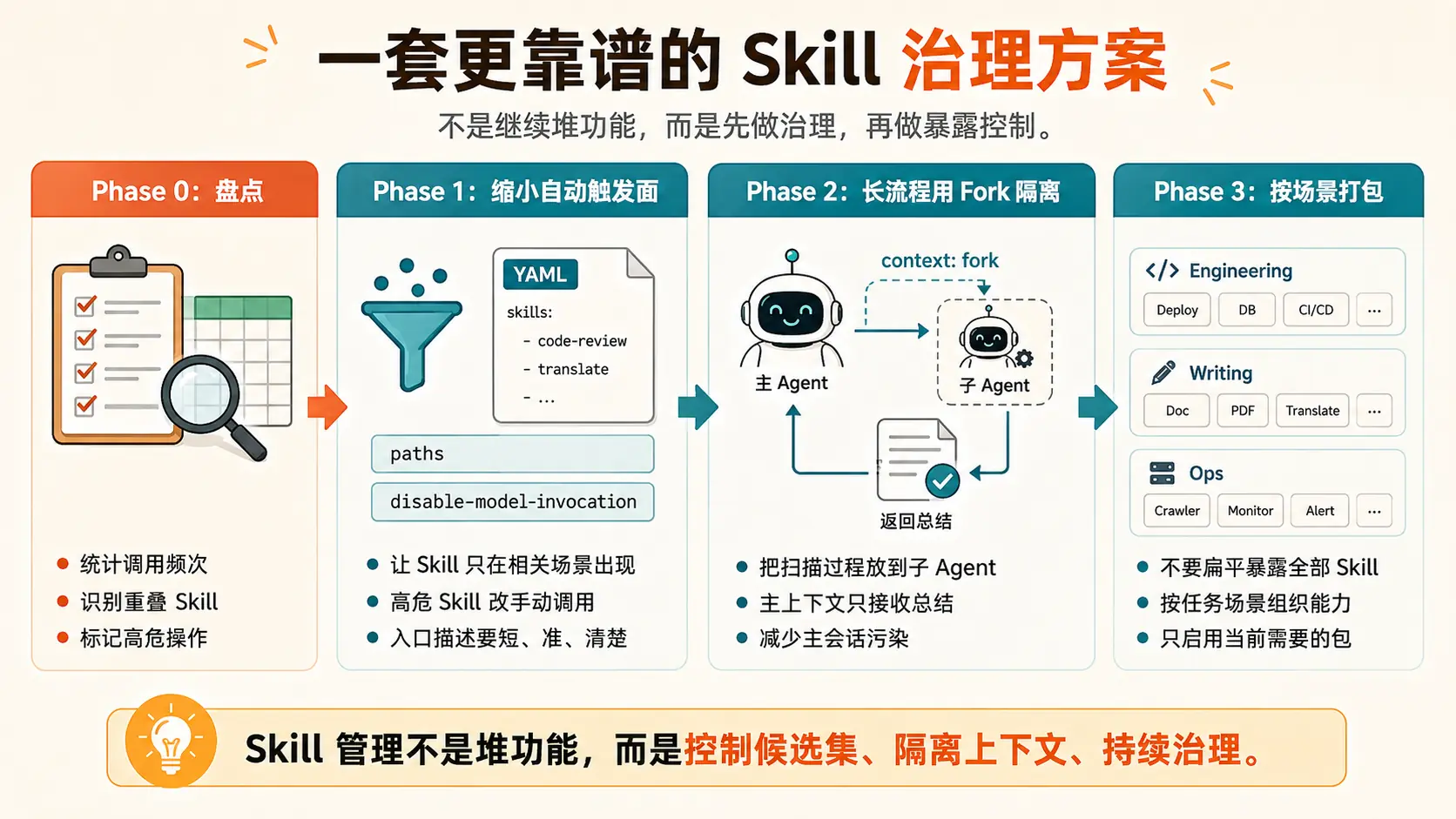
Phase 0:先盘点 Skill 资产
优化之前,先做一次 Skill 审计。
每个 Skill 至少记录这些字段:
text
名称
描述
所属场景
是否高危
是否有副作用
最近一次调用时间
最近 30 天调用次数
是否和其他 Skill 重叠
是否依赖外部脚本或资源然后分成四类:
第一类:高频核心 Skill
比如代码审查、测试、文档润色。这类可以保留自动触发,但描述必须短、准、清楚。
第二类:低频但关键 Skill
比如生产故障排查、数据库迁移、事故复盘。这类不能因为低频就删除,但要限制触发条件。
第三类:高危 Skill
比如部署、回滚、删数据、发消息、改权限。这类不应该让模型自己决定什么时候用。
第四类:僵尸 Skill
长期没有调用,也没有明确业务价值。这类先降级,再归档,最后删除。
不要一上来就"30 天没用直接删"。更稳的策略是:
text
30 天零调用:降级观察
60 天零调用:移出自动候选
90 天零调用:归档或删除Skill 治理不是大扫除,而是资产管理。
Phase 1:缩小自动触发面
以 Claude Code 为例,Skill frontmatter 里有几个字段很关键。
第一个是 paths。它可以用 glob pattern 限定 Skill 只在匹配文件范围内自动触发。官方文档说明,设置 paths 后,Claude 只有在处理匹配路径的文件时才会自动加载该 Skill。
参考:code.claude.com/docs/en/ski...
比如 Django Review Skill:
yaml
---
name: django-review
description: Review Django code for ORM misuse, migrations, auth, security, and performance.
paths:
- "**/*.py"
- "**/migrations/*.py"
---这样它不会在所有任务里都出现,只会在相关代码场景中进入候选。
第二个是 disable-model-invocation。官方文档说明,把它设为 true 可以阻止 Claude 自动加载这个 Skill,适合需要用户手动 /name 触发的工作流,尤其是部署、提交、发消息等有副作用的操作。
参考:code.claude.com/docs/en/ski...
比如生产回滚:
yaml
---
name: prod-rollback
description: Roll back a production deployment. Manual use only.
disable-model-invocation: true
---这点非常重要。
Agent 可以建议你部署。
但不应该自己决定部署。
Phase 2:长流程用 Fork 隔离
有些 Skill 天生会产生大量中间过程,比如:
- 全仓库扫描;
- 多文件代码审查;
- 大型日志分析;
- 安全检查;
- 批量文档处理;
- 竞品调研。
这些任务如果全部在主上下文里跑,主 Agent 很快就会被日志、扫描结果和中间尝试污染。
更好的方式是让它在隔离上下文中执行,只把总结带回主会话。
Claude Code 支持在 frontmatter 中添加 context: fork,让 Skill 在 subagent 中隔离运行;文档说明,Skill 内容会变成驱动 subagent 的提示,并且这个 subagent 不会访问当前对话历史。
参考:code.claude.com/docs/en/ski...
示例:
yaml
---
name: repo-audit
description: Scan repository structure and summarize architecture risks.
context: fork
agent: Explore
---但这里要注意:
context: fork的第一价值不是省钱,而是隔离污染。
它不保证每次都更省 token。
它真正解决的是:主 Agent 不被长流程的中间噪音拖下水。
主 Agent 负责判断和收敛。
子 Agent 负责探索和消耗。
Phase 3:按场景打包能力
当 Skill 多到几十个以后,不应该继续扁平展开。
应该按场景组织:
text
engineering/
code-review
test-runner
migration-check
architecture-audit
writing/
blog-outline
title-generator
polish-draft
social-post
ops/
log-debug
incident-summary
rollback-guide
deploy-checklist用户当前在写代码,就只启用 engineering。
当前在写文章,就只启用 writing。
当前在排障,就只启用 ops。
这和人类团队一样。
你不会让研发、法务、财务、运营、销售同时围着一个需求发言。你会先判断当前任务属于哪个场景,再叫对应的人进来。
Skill 也是一样。
好的 Skill 系统,不是全员上桌,而是按场景叫人。
四、不是所有 Skill 都该自动触发
Skill 的调用方式至少应该分成三类。
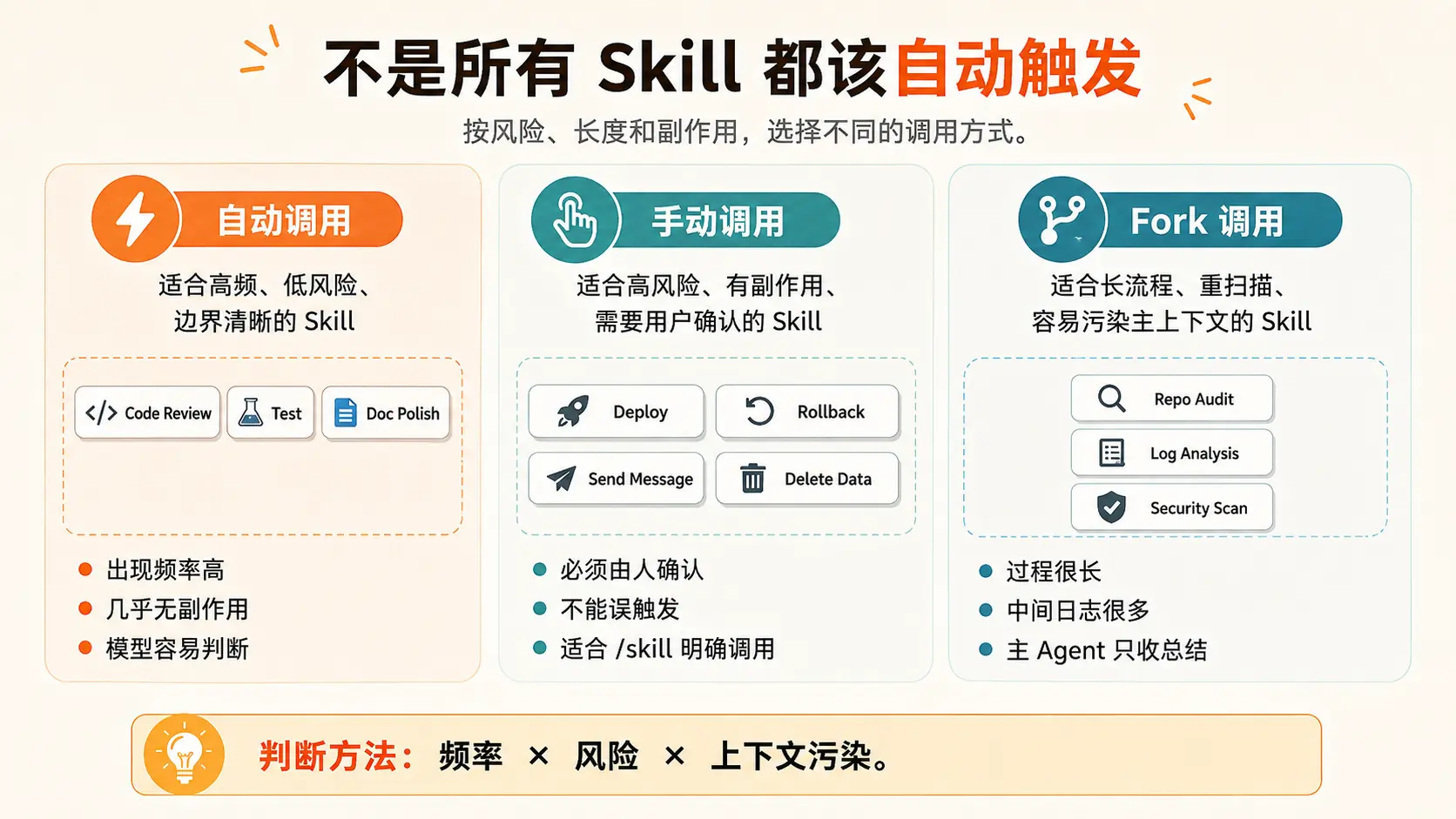
1. 自动调用
适合高频、低风险、边界清晰的 Skill。
例如:
text
Code Review
Test
Doc Polish这类 Skill 出现频率高,副作用小,模型也容易判断什么时候该用。
2. 手动调用
适合高风险、有副作用、需要用户确认的 Skill。
例如:
text
Deploy
Rollback
Send Message
Delete Data这类 Skill 不应该自动触发。它们应该由用户明确调用,或者至少经过确认。
判断标准很简单:
如果误触发会造成真实世界影响,就不要让模型自动决定。
3. Fork 调用
适合长流程、重扫描、容易污染主上下文的 Skill。
例如:
text
Repo Audit
Log Analysis
Security Scan这类 Skill 不一定危险,但很"重"。让它们直接跑在主上下文里,会让主 Agent 吸入大量中间信息。
所以应该 Fork 出去,主 Agent 只拿结果摘要。
总结成一个判断公式:
调用方式 = 频率 × 风险 × 上下文污染。
五、安全:Skill 是能力,也是供应链风险
Skill 不只是 Prompt。
它可能包含脚本、命令、模板、外部资源,甚至可能继承宿主 Agent 的权限。
OWASP Agentic Skills Top 10 已经把 Malicious Skills、Supply Chain Compromise、Over-Privileged Skills 等列为关键风险,并给出了恶意 Skill、供应链妥协、过度授权、弱隔离等风险类别。
所以不要这样做:
text
看到一个 Skill 市场;
觉得描述不错;
直接安装;
让 Agent 自动调用。更稳的流程应该是:
text
看来源
看脚本
看权限
看是否会执行 shell
看是否会联网
看是否读取敏感目录
高危 Skill 默认手动调用
不可信 Skill 禁止自动触发Claude Code 文档也提供了 disableSkillShellExecution 设置,用于禁用来自用户、项目、插件或额外目录源的 Skill / command 动态 shell 执行;被禁用后,命令会被替换为固定文本,而不是被运行。
参考:code.claude.com/docs/en/ski...
一句话:
你不是在装 Prompt,你是在给 Agent 装插件。
只要是插件,就有供应链风险。
六、持续治理:Skill 不是写好就完事
Skill 不是一次性配置,而是持续运转的能力系统。
可以建立一个简单的治理闭环。
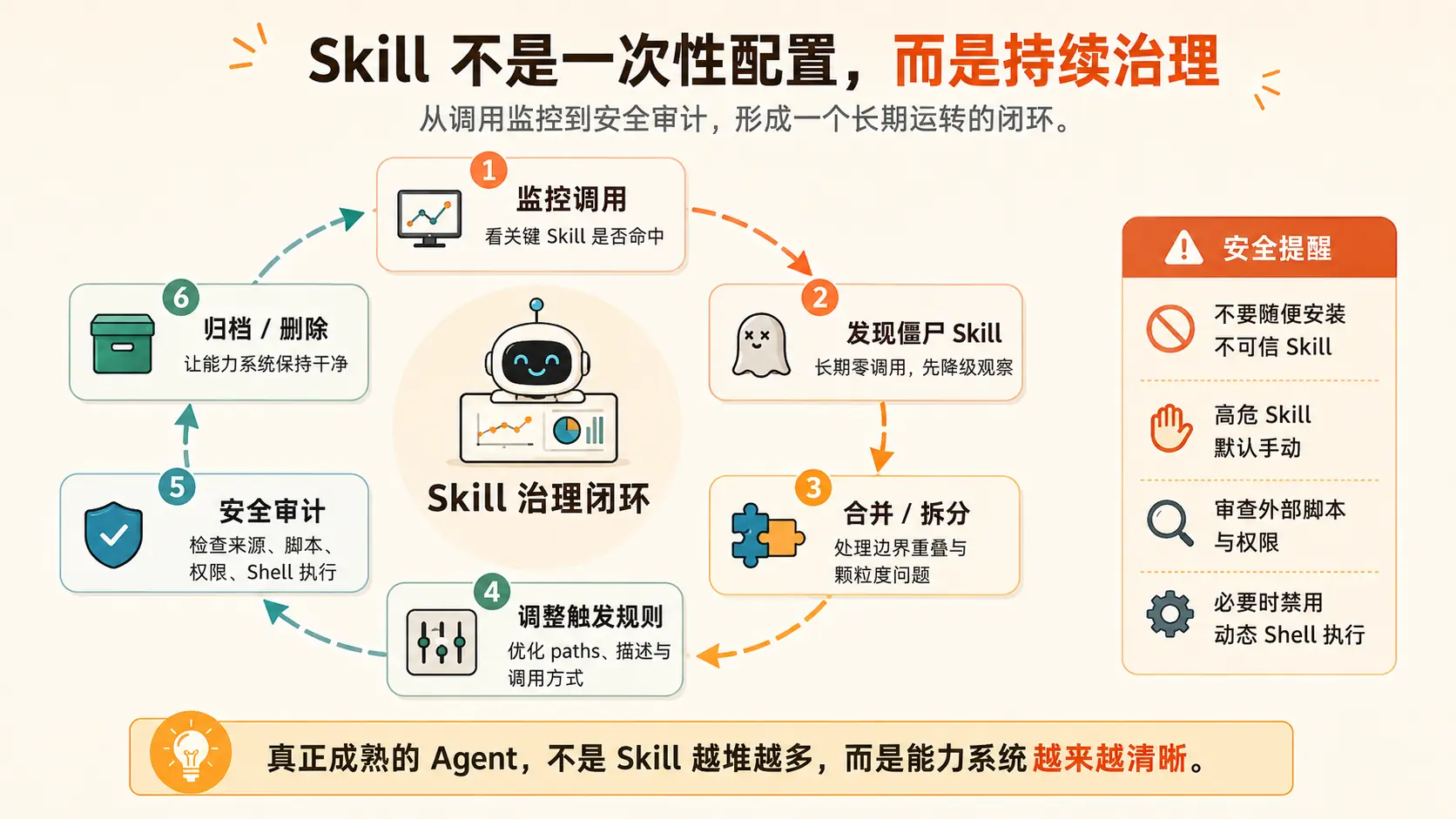
每天:看关键 Skill 有没有命中
不用看所有日志,只看关键链路:
text
Code Review 是否触发正确?
Test Skill 是否误触发?
Deploy Skill 是否保持手动?
高危 Skill 有没有异常调用?每天 5 分钟就够。
每周:看 Top / Bottom
每周看一次:
text
调用最多的 5 个 Skill
完全没调用的 5 个 Skill
误触发最多的 Skill
用户经常手动点名的 Skill如果一个 Skill 经常被手动调用,说明 description 可能写得不够好。
如果一个 Skill 经常误触发,说明边界可能写得太宽。
每月:做一次重组
每月检查:
text
是否有相似 Skill 可以合并?
是否有 Skill 应该拆分?
是否有高危 Skill 需要改成手动?
是否有长流程 Skill 应该 fork?
是否有第三方 Skill 需要复审?Skill 不应该越堆越多。
它应该越来越清晰。
每季度:做一次安全和资产清理
季度级别处理:
text
90 天零调用 Skill 归档
重复 Skill 合并
第三方 Skill 重新审计
检查是否存在过宽权限
检查是否有不必要的 shell 执行
检查是否有敏感目录读取这不是洁癖。
这是为了避免 Agent 的能力系统变成垃圾场。
结尾:高手不是装更多 Skill,而是让大部分 Skill 不出现
很多人以为 Agent 能力建设是在做加法:
text
多装 Skill
多写规则
多塞 Prompt
多加工具但真正落地之后会发现,关键不是加法,而是选择系统。
哪些能力常驻?
哪些能力按需出现?
哪些能力只能手动调用?
哪些能力必须隔离执行?
哪些能力应该归档删除?
Skill 的本质不是"更多说明"。
Skill 的本质是"更好的能力组织方式"。
下一次你想往系统 Prompt 里塞一大段流程时,可以先问自己一句:
这段内容是全局原则,还是特定任务的操作流程?
如果是全局原则,放系统 Prompt。
如果是操作流程,做成 Skill。
如果很长,拆成 Resources。
如果高危,禁止模型自动调用。
如果容易污染上下文,Fork 出去。
如果长期没人用,归档。
最后记住一句话:
不要把 Skill 当成系统 Prompt 的扩写包。Skill 应该是可检索、可隔离、可治理的能力索引。
真正成熟的 Agent,不是 Skill 越堆越多,而是能力系统越来越清晰。