引言:打开技能的"黑盒"
你是否好奇过,OpenClaw 的技能究竟是如何工作的?为什么一个 self-improving 技能能让 AI 拥有跨会话的记忆,甚至能从错误中自我反思?答案并不在神秘的代码深处,而是藏在每个技能目录下那个看似普通的 Markdown 文件------SKILL.md 中。
SKILL.md 是技能的"基因组"。它用一套清晰、结构化的语法,定义了技能的触发条件、行为逻辑、学习规则,甚至自我更新的方式。今天,我们就以 self-improving 技能为样本,打开它的 SKILL.md,逐行解析其中的设计智慧,带你理解 AI "自我进化"背后的底层逻辑。
一、SKILL.md 概览:技能的"身份证"与"操作手册"
一个典型的 self-improving 技能目录结构如下:
self-improving/
├── SKILL.md # 核心定义文件
├── memory/ # 记忆存储目录
│ ├── memory.md # HOT 层(常驻记忆)
│ ├── projects/ # WARM 层(项目级记忆)
│ └── archive/ # COLD 层(归档记忆)
├── hooks/ # 钩子脚本(可选)
└── README.md # 技能说明而 SKILL.md 本身由几个关键区块组成,我们可以通过一张结构图来认识它们:
SKILL.md
元数据区
BEHAVIOR 行为定义
LEARNING 学习规则
SELF-EVOLUTION 自我进化
技能名称、版本、作者
触发器列表
依赖项
记忆捕获规则
分层存储策略
自我反思流程
人类确认机制
元学习指令
参数动态调整
安全边界
进化触发条件
提案与审批
接下来,我们将逐一深入这些区块,揭示 self-improving 技能的底层逻辑。
二、提示词原理:BEHAVIOR 区块的指令逻辑
BEHAVIOR 区块是技能的核心,它用近乎伪代码的清晰语言,定义了 AI 在特定事件下该如何行动。这其实就是 "提示词原理" 的具体体现------通过结构化的指令,让 AI 执行复杂的认知任务。
1. 记忆捕获规则:从纠正中学习
markdown
### 1. 记忆捕获规则
当触发器 `on_user_correction` 被激活时,执行以下流程:
a. 解析用户消息,识别纠正类型:
- 偏好纠正(如"我更喜欢 X")
- 事实纠正(如"这个命令应该是 Y")
- 流程纠正(如"你应该先做 A 再做 B")
b. 生成候选记忆条目,格式为:
`[<context>] <pattern> -> <preference>`
例如:`[coding:python] "use print instead of logger" -> "avoid logger"`
c. 将候选条目写入 `~/self-improving/memory/pending/` 目录,并记录首次出现时间。原理图解:
用户纠正
触发 on_user_correction
解析纠正类型
生成候选记忆条目
存入 pending 目录
等待确认
这段规则揭示了 AI 是如何从用户的自然语言中 "提炼" 出结构化记忆的。通过模式识别(如关键词匹配),AI 将模糊的纠正转化为清晰的"模式→偏好"映射,并暂存在待确认区,等待后续的验证。
2. 分层存储策略:模拟人脑的认知分级
markdown
### 2. 分层存储策略
- **HOT 层** (`memory/memory.md`):
- 存储最近7天内使用次数 ≥ 3 的条目,或用户明确"固定"的条目。
- 行数上限:100 行。超出时按"最近最少使用"淘汰至 WARM 层。
- **WARM 层** (`memory/projects/`, `memory/domains/`):
- 按项目或领域分类存储,每个文件独立。
- 加载条件:当用户当前任务路径或话题匹配项目/领域标签时,自动加载对应文件。
- **COLD 层** (`memory/archive/`):
- 超过90天未访问的条目自动移入。
- 不主动加载,但可通过用户手动查询调取。分层架构图:
HOT 层:常驻记忆
淘汰/提升
长期未用
手动调取
COLD 层:归档记忆
archive/
按时间归档
WARM 层:情景记忆
projects/
项目A
projects/
项目B
domains/
Python
domains/
文案
memory.md
≤100行
这种分层设计完美平衡了 响应速度 与 记忆容量。HOT 层常驻系统提示词,保证 AI 快速"热身";WARM 层按需加载,让 AI 能在不同角色间无缝切换;COLD 层防止记忆无限膨胀,同时保留了长尾知识的可追溯性。
3. 自我反思流程:从经验中提炼教训
markdown
### 3. 自我反思流程
当触发器 `on_task_complete` 被激活时,AI 应执行以下反思步骤:
a. 回顾任务过程中的"摩擦点"(例如用户纠正、自己犹豫的地方)。
b. 生成反思记录,格式为:
```
CONTEXT: <任务描述>
REFLECTION: <观察到的不足>
LESSON: <提炼的经验>
```
c. 将反思记录追加到 `memory/reflections.log`。
d. 如果同一 LESSON 在7天内出现3次,则自动生成一个候选记忆条目(转入待确认区)。反思流程图:
是
否
任务完成
回顾摩擦点
生成反思记录
写入 reflections.log
同一教训
7天≥3次?
生成候选记忆条目
结束
这一机制让 AI 具备了 "事后诸葛亮" 的能力。它不仅能从用户的直接纠正中学习,还能从自己的"失败"中提炼经验,实现了更高层次的自我进化。
4. 人类确认机制:人在回路的安全阀
markdown
### 4. 人类确认机制
当候选记忆条目累积到一定数量或特定时间点,AI 应主动询问用户:
"我注意到您最近几次倾向于使用 X,是否要将此设为默认规则?"
用户可以选择:
- 确认:条目移入 HOT 层。
- 拒绝:条目删除。
- 推迟:条目保留在待确认区。
若用户连续3次忽略询问,则默认拒绝该条目。确认流程图:
确认
拒绝
推迟
连续3次忽略
待确认条目
AI 主动询问用户
用户选择
移入 HOT 层
删除条目
保留在待确认区
默认拒绝
这条规则确保了 "人类是进化的最终仲裁者",防止 AI 的自主学习走向错误的方向。同时,"连续忽略则拒绝"的机制避免了无休止的询问干扰用户。
三、使用场景:谁需要这个技能?
通过分析 SKILL.md 中的触发器配置和分层存储逻辑,我们可以推断出 self-improving 技能最适合以下几类场景:
| 场景类型 | 典型用户 | 技能价值 |
|---|---|---|
| 代码开发 | 程序员、DevOps | 记住代码规范、框架偏好、命令习惯,让 AI 成为"熟悉你代码风格的协作者"。 |
| 内容创作 | 写手、营销人员 | 学习你的文风、常用词汇、语气偏好,让 AI 生成的文案"越来越像你"。 |
| 项目管理 | 项目经理、助理 | 记录项目特定的流程、术语、干系人信息,实现跨会话的项目知识管理。 |
| 研究分析 | 分析师、学者 | 沉淀研究过程中的方法论、数据源偏好,让 AI 成为你的"研究助手"。 |
触发器匹配场景:
on_user_correction:最适合需要频繁调整和优化的创造性工作。on_task_complete:适合长流程、多步骤的任务,如数据分析报告撰写。periodic:适合需要定期维护知识库的领域,如代码库重构。
四、实战案例:从零到一构建专属记忆
让我们模拟一个完整的实战案例,看看 self-improving 技能如何在实际交互中发挥作用。
场景:前端开发者小李使用 OpenClaw 辅助开发一个 React 项目,项目使用 Ant Design 组件库,代码规范要求使用函数组件和 TypeScript。
阶段一:初始交互(无记忆)
小李在终端中开启新会话:
小李:帮我写一个按钮组件。
AI(无记忆):
jsx
import React from 'react';
const Button = () => {
return <button>Click me</button>;
};
export default Button;小李看到后纠正:
小李:不对,我项目里一直用的是 Ant Design 的 Button,而且要用 TypeScript,组件名用箭头函数。
此时,on_user_correction 触发器激活 ,AI 按照 SKILL.md 的规则执行:
- 解析纠正:识别出"偏好纠正"(Ant Design、TypeScript、箭头函数)。
- 生成候选记忆条目:
[coding:react] "use antd Button" -> "prefer antd"[coding:typescript] "use TypeScript" -> "always use .tsx"[coding:style] "arrow function component" -> "use const Component: FC = () => ..."
- 将条目存入
pending/目录。
AI 根据纠正重新生成代码:
tsx
import React from 'react';
import { Button as AntButton } from 'antd';
const MyButton: React.FC = () => {
return <AntButton>Click me</AntButton>;
};
export default MyButton;小李满意地继续工作。
阶段二:记忆固化
几天后,小李又在一个新会话中开启任务:
小李:帮我写一个表单组件。
AI 加载 memory.md(目前还是空的,因为条目还在待确认区),仍然生成普通代码,小李再次纠正。同样的纠正模式重复出现。
7天内,[coding:react] "use antd Button" 这条模式出现了3次。AI 按照自我反思流程(d 规则),自动生成候选记忆条目,并在下次交互时询问:
AI:我注意到您最近几次倾向于使用 Ant Design 组件和 TypeScript,是否要将此设为 React 项目的默认规则?
小李选择 "确认" 。条目正式移入 memory/memory.md(HOT 层)。
阶段三:记忆生效
又一个新会话:
小李:帮我写一个卡片组件。
AI 加载 memory.md,读取到三条偏好规则,直接生成:
tsx
import React from 'react';
import { Card } from 'antd';
const DataCard: React.FC = () => {
return <Card title="Default Card">Content</Card>;
};
export default DataCard;小李无需再纠正。AI 已经记住了他的开发习惯。
阶段四:自我反思与进化
在完成一个复杂的数据可视化任务后,AI 触发 on_task_complete,进行自我反思:
CONTEXT: 生成 ECharts 图表代码
REFLECTION: 用户要求修改了三次颜色主题,最后选择了暗色主题
LESSON: 在生成图表时,优先询问用户是否需要暗色主题如果这个教训在7天内出现3次,它将转化为候选记忆条目,最终可能成为永久规则:"图表任务默认使用暗色主题"。
五、让 OpenClaw 不断更新该 Skill:自我进化机制
self-improving 技能最酷的地方在于:它不仅能进化用户的记忆,还能 进化自身 。这得益于 SELF-EVOLUTION 区块的定义。
1. 安全边界:哪些可以改,哪些不能改
markdown
## SELF-EVOLUTION
### 技能更新策略
本技能支持对自身代码的进化性修改,但必须遵循以下安全规则:
1. **安全边界**:只能修改 `BEHAVIOR` 和 `LEARNING` 区块中标记为 `mutable: true` 的参数,不能修改元数据、触发器列表和依赖。
2. **进化触发**:当元学习模块发现现有规则无法有效捕获用户偏好时,可提议修改规则。
3. **提案生成**:生成一个包含修改内容和理由的提案,存入 `evolution/proposals/`。
4. **人工审批**:向用户发送通知,请求审阅提案。用户确认后,技能自动应用修改并重启。
5. **版本自增**:每次成功更新后,`version` 字段的补丁号 +1。2. 进化触发示例
假设元学习模块分析发现:用户经常对"流程纠正"的反应是沉默接受,但现有规则要求用户明确确认才能固化。元学习模块认为这可能导致效率损失,于是生成一个提案:
markdown
---
proposal-id: 20240521-001
type: parameter-adjustment
reason: 用户对流程纠正的接受度较高,可适当降低确认阈值
---
修改 `BEHAVIOR/记忆捕获规则`:
- 原规则:流程纠正必须经过用户确认才能进入待确认区。
- 新规则:如果同一流程纠正出现2次且未被反驳,自动转为候选记忆条目(仍需人工确认)。提案存入 evolution/proposals/,并通知用户。用户审阅后批准,技能自动应用修改,版本从 2.1.0 升至 2.1.1。
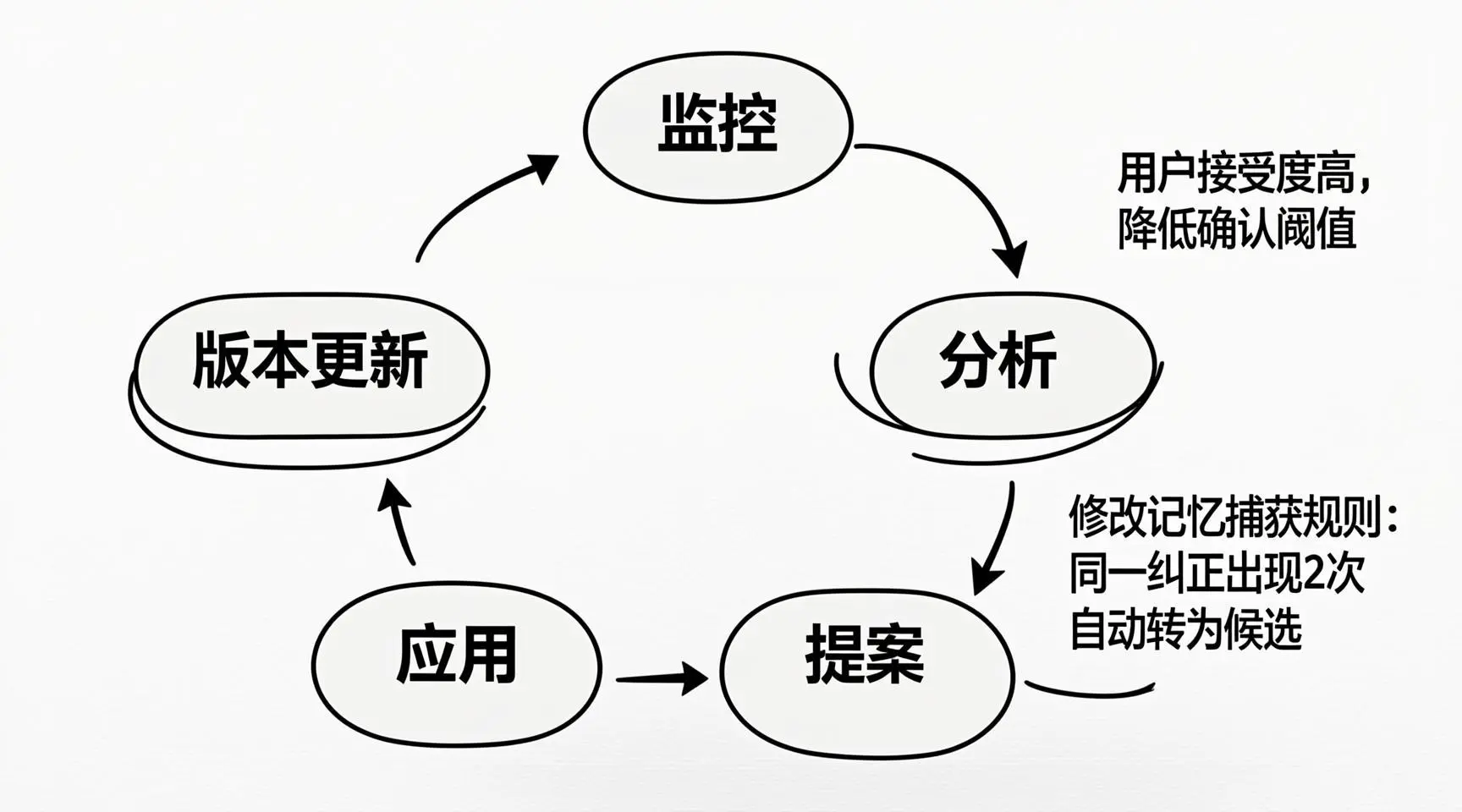
图7:技能进化循环图 - 监控→分析→提案→审批→应用→版本更新,形成闭环
3. 如何主动触发技能更新?
你可以通过以下指令让 OpenClaw 检查并应用 self-improving 技能的更新:
OpenClaw,请检查
self-improving技能的更新。如果有新版本,拉取并生成更新提案供我审阅。
或者更主动地:
OpenClaw,请运行自我进化循环。分析过去一周
self-improving技能的记忆捕获效果,如果发现任何可优化的参数,生成一个优化提案。
这样,self-improving 技能就形成了一个 "监控-分析-提案-审批-应用" 的闭环,实现了真正的持续自我改进。
六、总结:从 SKILL.md 看技能设计的哲学
通过深入剖析 self-improving 技能的 SKILL.md,我们看到了一个精心设计的 元指令系统 是如何让 AI 具备"记忆与进化"能力的:
- 事件驱动:只在关键时刻激活,高效不浪费。
- 分层记忆:模拟人脑认知,兼顾速度与容量。
- 人在回路:所有进化必须经用户确认,安全可控。
- 元学习:能自我调整学习策略,适应不同用户。
- 可进化:甚至能修改自身行为规则,持续迭代。
这就是 OpenClaw 技能的强大之处:它用透明、可读的 Markdown 文件,将复杂的 AI 行为逻辑封装成模块化的技能,让每个用户都能理解、定制甚至进化 AI 的能力。