文章目录
-
- 引言:万物互联时代的时序数据挑战
- 一、什么是时序数据?为什么需要专用数据库?
-
- [1.1 时序数据的本质](#1.1 时序数据的本质)
- [1.2 传统数据库的局限](#1.2 传统数据库的局限)
- [1.3 国际主流时序数据库对比概览](#1.3 国际主流时序数据库对比概览)
- [二、Apache IoTDB 的核心建模哲学:树表孪生模型](#二、Apache IoTDB 的核心建模哲学:树表孪生模型)
-
- [2.1 树模型:贴合物理世界的直观表达](#2.1 树模型:贴合物理世界的直观表达)
- [2.2 表模型:赋能标准 SQL 的深度分析](#2.2 表模型:赋能标准 SQL 的深度分析)
- [2.3 树表协同:一份数据,两种视角](#2.3 树表协同:一份数据,两种视角)
- 三、典型应用场景建模实战
-
- [场景一:纯树模型 ------ 工业实时监控](#场景一:纯树模型 —— 工业实时监控)
- [场景二:纯表模型 ------ 跨设备能效分析](#场景二:纯表模型 —— 跨设备能效分析)
- [场景三:树表结合 ------ 储能电站全生命周期管理](#场景三:树表结合 —— 储能电站全生命周期管理)
- [四、为什么选择 Apache IoTDB?------ 从大数据架构视角](#四、为什么选择 Apache IoTDB?—— 从大数据架构视角)
-
- [4.1 原生分布式架构,弹性伸缩无忧](#4.1 原生分布式架构,弹性伸缩无忧)
- [4.2 端 - 边-云协同,打通数据孤岛](#4.2 端 - 边-云协同,打通数据孤岛)
- [4.3 工业协议全覆盖,开箱即用](#4.3 工业协议全覆盖,开箱即用)
- [4.4 生态整合:DB + AI 的价值闭环](#4.4 生态整合:DB + AI 的价值闭环)
- 五、结语:构建面向未来的时序数据基础设施
引言:万物互联时代的时序数据挑战
在数字化转型的浪潮中,物联网(IoT)和工业 4.0 正在重塑各行各业。从智能制造到智慧能源,从车联网到环境监测,传感器无处不在,每时每刻都在产生海量的时序数据。这些数据构成了设备的"心电图",记录着电压、电流、转速、温度、位置等关键指标随时间的变化轨迹。
然而,面对如此庞大且持续增长的数据流,传统的关系型数据库和通用大数据平台往往力不从心。时序数据具有写入频率高、查询模式特殊、压缩需求强、实时性要求高等特点,亟需专门的时序数据库(Time Series Database, TSDB)来应对。
在众多时序数据库产品中,如何做出明智的选型?本文将从大数据架构视角出发,结合国际主流产品对比,深入剖析 Apache IoTDB 的核心优势,特别是其独特的树表孪生模型 和跨『端 - 边-云』一体化架构 ,为工程师和技术决策者提供一份详实的选型指南。

一、什么是时序数据?为什么需要专用数据库?
1.1 时序数据的本质
时序数据是指按时间顺序记录的一系列数据点,每个数据点包含时间戳 和数值两个核心要素。例如:
- 电机每秒采集一次电压值:
(2024-06-01 10:00:01, 220.5V) - 风机每分钟记录一次转速:
(2024-06-01 10:01:00, 1500rpm) - 车辆每 5 秒上报一次经纬度:
(2024-06-01 10:00:05, 39.9042°N, 116.4074°E)
这些数据共同构成了一条条"时间序列",形象地说,就是设备的"生命体征曲线"。
1.2 传统数据库的局限
面对时序数据,传统关系型数据库(如 MySQL、PostgreSQL)存在以下瓶颈:
- 写入性能不足:高频写入导致锁竞争和索引重建开销巨大。
- 存储效率低下:缺乏针对时间序列的专用压缩算法,存储成本高昂。
- 查询模式不匹配:时序查询多为时间范围聚合、降采样、插值等,SQL 优化器难以高效处理。
- 扩展性差:水平扩容复杂,难以应对设备数量激增的场景。
而通用大数据平台(如 HBase、Cassandra)虽然具备分布式能力,但在时序语义支持、压缩率、实时分析等方面仍显不足。
1.3 国际主流时序数据库对比概览
目前国际上主流的时序数据库包括:
- InfluxDB:开源生态成熟,但集群版闭源,高可用方案成本高。
- TimescaleDB:基于 PostgreSQL 扩展,SQL 兼容性好,但写入性能和压缩率受限于 PG 架构。
- OpenTSDB:基于 HBase,适合超大规模场景,但部署复杂,实时性较弱。
- QuestDB:高性能内存数据库,适合金融场景,但工业协议支持有限。
相比之下,Apache IoTDB 作为原生为工业物联网设计的时序数据库,在高压缩、分布式、工业友好三大维度展现出独特优势.
高压缩 :自研 TsFile 文件格式 + 专有压缩算法,节省 90%+ 存储成本
分布式 :完全开源,秒级扩容,无需数据迁移
工业友好:支持数百种工业协议,乱序写入、一键备份等企业级功能

二、Apache IoTDB 的核心建模哲学:树表孪生模型
在时序数据库选型中,数据建模能力 是决定系统灵活性和分析效率的关键。Apache IoTDB 创新性地提出了树表孪生模型 (Tree-Table Twin Model),允许用户在同一份数据上同时使用树模型和表模型,兼顾了写入灵活性 与分析丰富性。
2.1 树模型:贴合物理世界的直观表达
树模型以"测点"为核心,通过.分隔的路径构建树形结构,完美映射物理设备的层级关系。例如:
root.factory.workshop1.machine01.sensor.temperature
root.factory.workshop1.machine01.sensor.pressure
root.factory.workshop2.machine02.sensor.vibration适用场景:
- DCS/SCADA 工业监控系统
- 设备状态实时告警
- 测点级快速读写
优势:
- 结构灵活,可随时增删分支
- 路径即语义,易于理解和维护
- 写入性能优异,特别适合高并发设备接入
建模建议:
- 倒数第二层(设备层)节点数建议 ≥1000,以发挥并发优势
- 若单设备测点过多,可在末尾添加
.value提升设备基数 - 特殊字符需用反引号 ````` 包裹,避免解析错误
2.2 表模型:赋能标准 SQL 的深度分析
表模型将同类设备抽象为一张"时序表",每张表包含:
- TIME 列:时间戳(必填)
- TAG 列:设备标识(联合主键,如 device_id, location)
- FIELD 列:动态测点值(如 temperature, pressure)
- ATTRIBUTE 列:静态属性(如 model, manufacturer)
示例表结构:
| time | device_id | location | temperature | pressure | model |
|---|---|---|---|---|---|
| 2024-06-01 10:00:00 | M001 | WS1 | 25.3 | 101.2 | TypeA |
| 2024-06-01 10:00:00 | M002 | WS1 | 26.1 | 100.8 | TypeB |
适用场景:
- 跨设备聚合分析(如"所有 TypeA 设备的平均温度")
- 多维标签筛选(如"location=WS1 AND model=TypeA")
- 从传统数据库迁移至 IoTDB 的场景
优势:
- 兼容标准 SQL,降低学习成本
- 支持复杂 JOIN、子查询、窗口函数
- 便于与 BI 工具(如 Tableau、Superset)集成
2.3 树表协同:一份数据,两种视角
IoTDB 最强大的特性在于树转表视图功能。用户可以先用树模型高效写入数据,再通过创建"表视图"将其映射为表结构,实现:
- 写入阶段:使用树模型语法,灵活接入各类设备
- 分析阶段:使用表模型语法,执行复杂 SQL 查询
sql
-- 在表模型下创建树转表视图
CREATE VIEW IF NOT EXISTS factory_view AS
SELECT
root.factory.**.temperature AS temperature,
root.factory.**.pressure AS pressure,
root.factory.**.* AS tags
FROM root.factory
ALIGN BY DEVICE;这种"写树查表"的模式,既保留了树模型的写入优势,又获得了表模型的分析能力,真正实现了DB + AI 的数据价值挖掘闭环。
三、典型应用场景建模实战
场景一:纯树模型 ------ 工业实时监控
需求:某化工厂有 5000 台设备,每台设备采集 200 个测点,需实现毫秒级写入和实时告警。
建模方案:
root.chemical_plant.reactor_001.temp_01
root.chemical_plant.reactor_001.press_01
...
root.chemical_plant.pump_5000.flow_200优势:路径清晰,写入吞吐高,告警规则可直接绑定路径。
场景二:纯表模型 ------ 跨设备能效分析
需求:某风电场需分析不同型号风机在不同风速下的发电效率。
建模方案:
sql
CREATE TABLE wind_turbines (
time TIMESTAMP,
turbine_id TAG,
model ATTRIBUTE,
wind_speed FIELD,
power_output FIELD,
efficiency FIELD
);优势 :可通过 SELECT model, AVG(efficiency) FROM wind_turbines WHERE wind_speed > 10 GROUP BY model 快速得出分析结果。
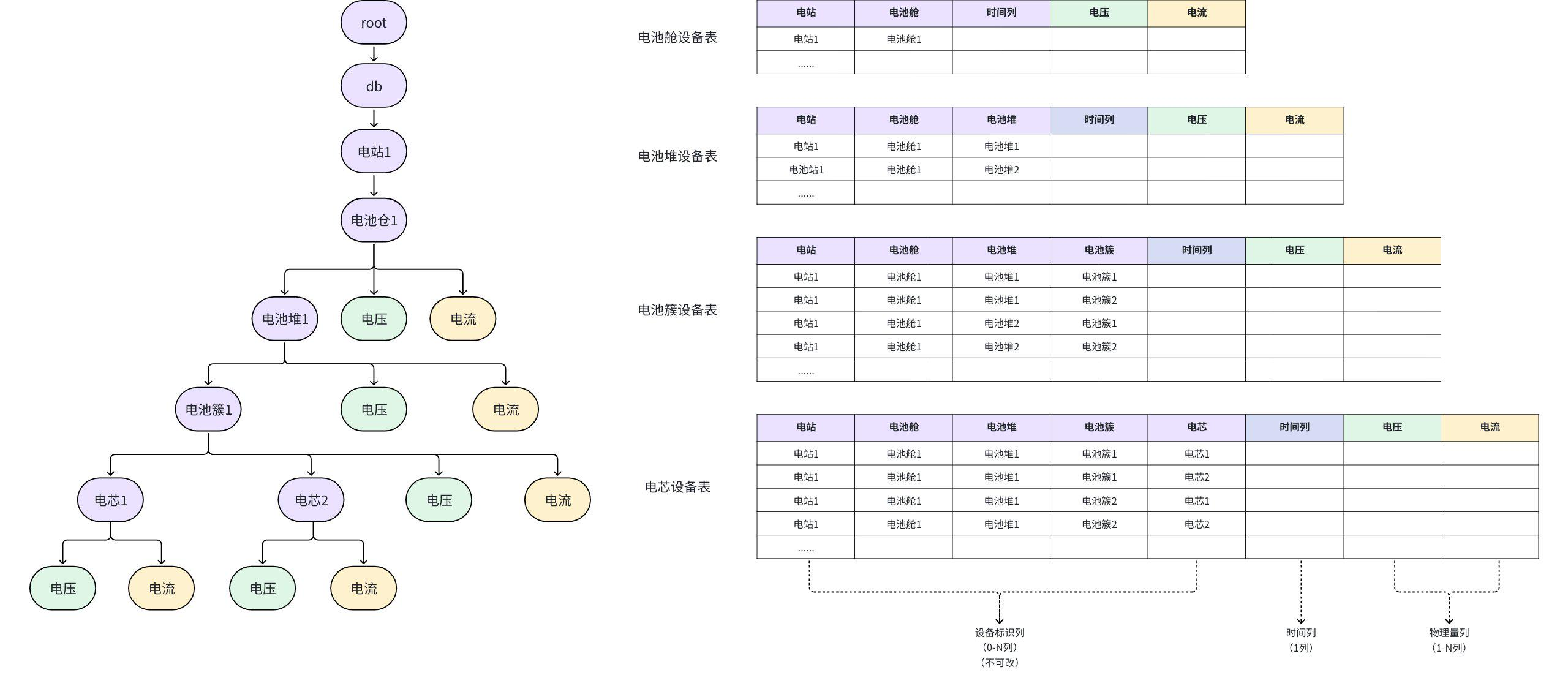
场景三:树表结合 ------ 储能电站全生命周期管理
需求:储能电站既有电池簇的层级监控(树模型),又有跨簇的 SOC/SOH 分析(表模型)。
建模方案:
- 写入 :使用树模型
root.ess.rack01.cell001.voltage - 分析 :创建表视图
ess_view,按 rack/cell 分组统计
价值 :一套数据支撑实时监控与深度分析,避免数据冗余和同步延迟。
四、为什么选择 Apache IoTDB?------ 从大数据架构视角
4.1 原生分布式架构,弹性伸缩无忧
不同于 InfluxDB 企业版闭源或 TimescaleDB 依赖 PG 集群,IoTDB 从设计之初就采用完全开源的分布式架构:
- 无共享架构(Shared-Nothing):节点间独立,故障隔离
- 自动分片与负载均衡:数据按时间范围和设备 ID 自动分布
- 秒级扩容:新增节点后自动 rebalance,无需停机迁移数据
这使得 IoTDB 能够轻松应对从边缘网关到云端数据中心的全尺度部署。
4.2 端 - 边-云协同,打通数据孤岛
IoTDB 支持端侧轻量嵌入 (如 Raspberry Pi)、边缘节点聚合 、云端集中分析的三级架构:
- 端侧:IoTDB Lite 版本可运行在资源受限设备,本地缓存 + 断点续传
- 边缘:多源数据汇聚,预处理后上传云端
- 云端:全局数据湖,支持 PB 级存储和 AI 模型训练
这种架构完美契合工业互联网"数据不出厂"、"边缘智能"等合规与安全需求。
4.3 工业协议全覆盖,开箱即用
内置支持 Modbus、OPC UA、MQTT、CoAP 等数百种工业协议,提供:
- 协议适配器:一键配置数据采集
- 乱序写入优化:自动按时间排序,不影响查询一致性
- 一键备份恢复:企业级容灾能力
相比国外产品对工业场景的"水土不服",IoTDB 更懂中国制造业的实际需求。
4.4 生态整合:DB + AI 的价值闭环
IoTDB 不仅是一个数据库,更是数据智能平台:
- 内置算子:支持降采样、插值、异常检测、傅里叶变换等时序专属函数
- AI 集成:无缝对接 PyTorch/TensorFlow,支持在库内训练预测模型
- 可视化:与 Grafana、DataV 深度集成,实时大屏零代码搭建
五、结语:构建面向未来的时序数据基础设施
在时序数据库选型的十字路口,技术决策者不仅要考虑当前的性能指标,更要预见未来 3-5 年的业务演进。Apache IoTDB 凭借其树表孪生模型 的创新设计、端 - 边-云一体化 的架构视野、以及完全开源 + 工业友好的生态定位,正成为全球工业物联网领域的首选时序引擎。
无论是从零构建新系统,还是替换老旧数据库,IoTDB 都能以更低成本、更高效率、更强扩展性,帮助企业释放时序数据的巨大价值。
下载 :https://iotdb.apache.org/zh/Download/
官网 :https://timecho.com
在万物互联的时代,让每一字节时序数据都创造商业价值------这正是 Apache IoTDB 的使命所在。