前言
-
Unitree RL GYM是一个开源的基于 Unitree 机器人强化学习(Reinforcement Learning, RL)控制示例项目,用于训练、测试和部署四足机器人控制策略。该仓库支持多种 Unitree 机器人型号,包括Go2、H1、H1_2 和 G1。仓库地址
-
本系列将着手解析整个仓库的核心代码与算法实现和训练教程。此系列默认读者拥有一定的强化学习基础和代码基础,故在部分原理和基础代码逻辑不做解释,对强化学习基础感兴趣的读者可以阅读我的入门系列:
- 第一期: 【浅显易懂理解强化学习】(一)Q-Learning原来是查表法-CSDN博客
- 第二期: 【浅显易懂理解强化学习】(二):Sarsa,保守派的胜利-CSDN博客
- 第三期:【浅显易懂理解强化学习】(三):DQN:当查表法装上大脑-CSDN博客
- 第四期:【浅显易懂理解强化学习】(四):Policy Gradients玩转策略采样-CSDN博客
- 第五期:【浅显易懂理解强化学习】(五):Actor-Critic与A3C,多线程的完全胜利-CSDN博客
- 第六期:【浅显易懂理解强化学习】(六):DDPG与TD3集百家之长-CSDN博客
- 第七期:【浅显易懂理解强化学习】(七):PPO,策略更新的安全阀-CSDN博客
-
阅读本系列的前置知识:
python语法,明白面向对象的封装pytorch基础使用- 神经网络基础知识
- 强化学习基础知识,至少了解
Policy Gradient、Actor-Critic和PPO
-
本系列:
-
前三期我们把
rsl_rl仓库源码关于ppo算法设计的所有源码都解读完了,本期我们正式开始unitree_rl_gym的源码解读 -
本期我们从
unitree_rl_gym的源码开始解读,来看看Go2基础训练以及参数调节与解析
1 项目结构
1-1 根目录结构
-
依旧我们使用
tree指令可以很好的看到项目的结构unitree_rl_gym/
├── deploy/
├── doc/
├── legged_gym/
├── logs/
├── resources/
├── setup.py
├── README.md
└── unitree_rl_gym.egg-info/ -
deploy/: 部署相关代码,既支持仿真(Mujoco/IsaacGym),也支持真实机器人。 -
doc/: 文档,包含安装与使用说明(英文/中文)。 -
legged_gym/: 核心强化学习环境和训练脚本。(核心) -
logs/: 训练日志和模型存储。 -
resources/: 机器人模型资源文件(URDF/DAE/STL/图片)。 -
setup.py: Python 包安装脚本。 -
unitree_rl_gym.egg-info/: Python 打包生成的元信息。
1-2 legged_gym/目录
-
我们主要看
legged_gym/目录(base) lzh@lzh:~/unitree_rl_gym/legged_gym$ tree .
.
├── envs
│ ├── base
│ │ ├── base_config.py
│ │ ├── base_task.py
│ │ ├── legged_robot_config.py
│ │ ├── legged_robot.py
│ │ └── pycache
│ ├── g1
│ ├── go2
│ │ ├── go2_config.py
│ │ └── pycache
│ ├── h1
│ ├── h1_2
│ ├── init.py
│ └── pycache
├── init.py
├── LICENSE
├── pycache
├── scripts
│ ├── play.py
│ └── train.py
└── utils
├── helpers.py
├── init.py
├── isaacgym_utils.py
├── logger.py
├── math.py
├── pycache
├── task_registry.py
└── terrain.py -
envs/:base/:base_config.py:提供一个可递归初始化嵌套子类的通用配置基类。base_task.py:定义强化学习环境的抽象基类,包括仿真、缓冲区和交互接口。legged_robot_config.py: 封装四足机器人环境参数和 PPO 训练参数的配置类。legged_robot.py:实现四足机器人环境逻辑,包括动作应用、奖励计算、观测生成和环境重置。
go2/:go2_config.py:定义 Go2 机器人的专用环境配置类 ,用于设置 机器人初始状态、关节参数、观测空间、奖励函数以及 PPO 训练参数。
-
scripts/train.py:强化学习训练入口脚本,负责创建环境、加载配置、初始化 PPO 算法并开始训练。play.py:模型测试脚本,用于加载训练好的策略模型,在仿真环境中运行并观察机器人行为。
-
utils/helpers.py:通用辅助函数集合isaacgym_utils.py:IsaacGym 仿真相关工具函数logger.py:训练日志记录工具math.py:强化学习环境中的 数学计算函数task_registry.py:任务注册系统terrain.py:生成强化学习训练用的各种地形
2 训练代码解读
2-1 初次训练尝试
- 根据官方的
README.md所写:!\[Pasted image 20260316101829.png] - 我们运行如下指令:
python
conda activate unitree-rl
cd unitree_rl_gym/
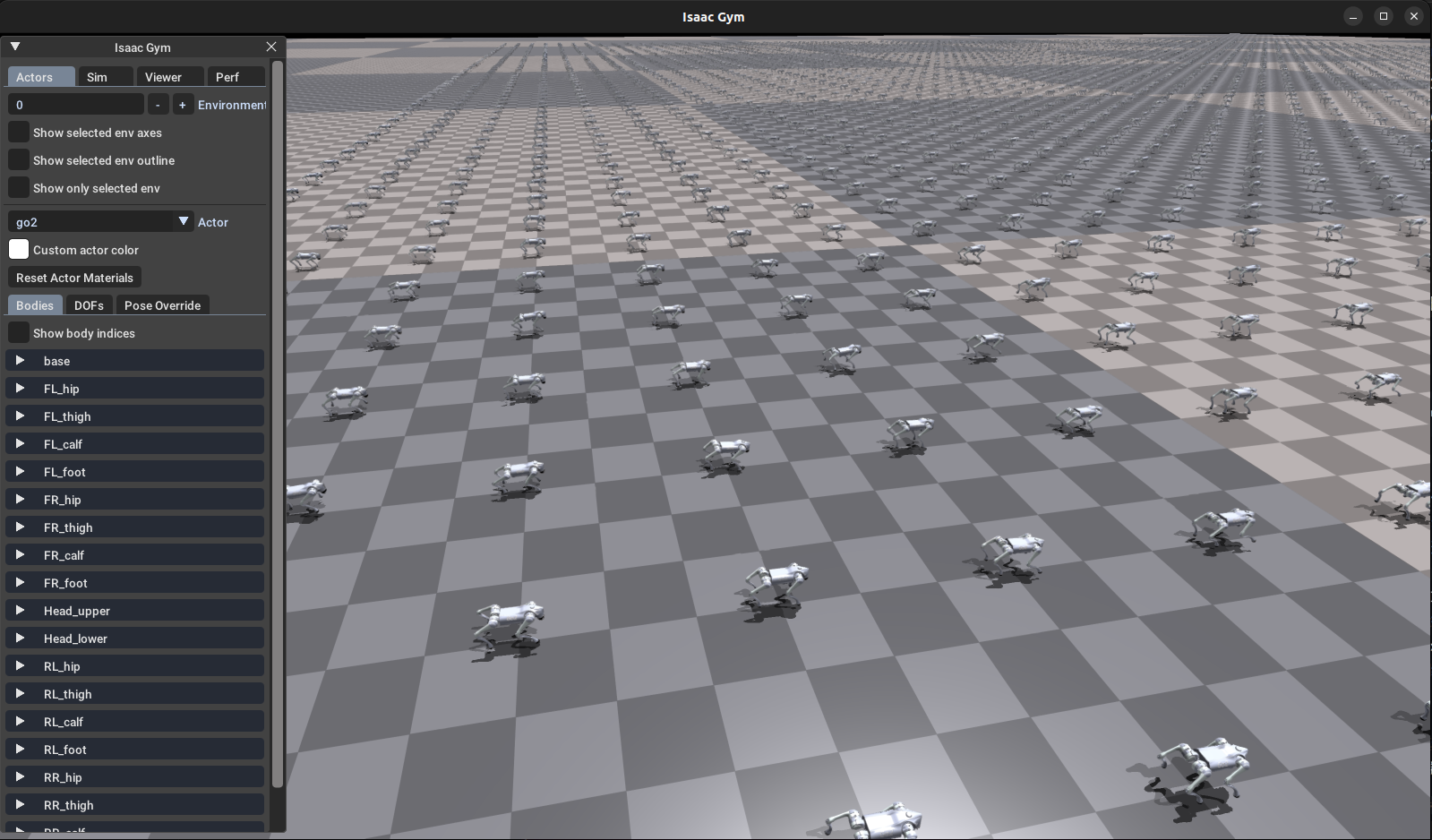
python legged_gym/scripts/train.py --task=go2- 可以看到,训练的可视化界面如下
- 如果提示报错
ImportError: libpython3.8.so.1.0: cannot open shared object file: No such file or directory,可暂时把 Python 动态库加入LD_LIBRARY_PATH:
bash
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib:$LD_LIBRARY_PATH2-2 训练代码train.py
- 我们直接来看看训练的代码:
legged_gym/scripts/train.py
python
import os
import numpy as np
from datetime import datetime
import sys
import isaacgym
from legged_gym.envs import *
from legged_gym.utils import get_args, task_registry
import torch
def train(args):
env, env_cfg = task_registry.make_env(name=args.task, args=args)
ppo_runner, train_cfg = task_registry.make_alg_runner(env=env, name=args.task, args=args)
ppo_runner.learn(num_learning_iterations=train_cfg.runner.max_iterations, init_at_random_ep_len=True)
if __name__ == '__main__':
args = get_args()
train(args)- 可以看到训练代码很短,调用库
task_registry进行环境创建,PPO算法创建然后就开始训练了,那我们就接着往下看task_registry
2-3 任务注册器task_registry.py
- 我们找到任务注册器
legged_gym/utils/task_registry.py
python
import os
from datetime import datetime
from typing import Tuple
import torch
import numpy as np
import sys
from rsl_rl.env import VecEnv
from rsl_rl.runners import OnPolicyRunner
from legged_gym import LEGGED_GYM_ROOT_DIR, LEGGED_GYM_ENVS_DIR
from .helpers import get_args, update_cfg_from_args, class_to_dict, get_load_path, set_seed, parse_sim_params
from legged_gym.envs.base.legged_robot_config import LeggedRobotCfg, LeggedRobotCfgPPO
class TaskRegistry():
def __init__(self):
self.task_classes = {}
self.env_cfgs = {}
self.train_cfgs = {}
def register(self, name: str, task_class: VecEnv, env_cfg: LeggedRobotCfg, train_cfg: LeggedRobotCfgPPO):
self.task_classes[name] = task_class
self.env_cfgs[name] = env_cfg
self.train_cfgs[name] = train_cfg
def get_task_class(self, name: str) -> VecEnv:
return self.task_classes[name]
def get_cfgs(self, name) -> Tuple[LeggedRobotCfg, LeggedRobotCfgPPO]:
train_cfg = self.train_cfgs[name]
env_cfg = self.env_cfgs[name]
# copy seed
env_cfg.seed = train_cfg.seed
return env_cfg, train_cfg
def make_env(self, name, args=None, env_cfg=None) -> Tuple[VecEnv, LeggedRobotCfg]:
""" Creates an environment either from a registered namme or from the provided config file.
Args:
name (string): Name of a registered env.
args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
env_cfg (Dict, optional): Environment config file used to override the registered config. Defaults to None.
Raises:
ValueError: Error if no registered env corresponds to 'name'
Returns:
isaacgym.VecTaskPython: The created environment
Dict: the corresponding config file
"""
# if no args passed get command line arguments
if args is None:
args = get_args()
# check if there is a registered env with that name
if name in self.task_classes:
task_class = self.get_task_class(name)
else:
raise ValueError(f"Task with name: {name} was not registered")
if env_cfg is None:
# load config files
env_cfg, _ = self.get_cfgs(name)
# override cfg from args (if specified)
env_cfg, _ = update_cfg_from_args(env_cfg, None, args)
set_seed(env_cfg.seed)
# parse sim params (convert to dict first)
sim_params = {"sim": class_to_dict(env_cfg.sim)}
sim_params = parse_sim_params(args, sim_params)
env = task_class( cfg=env_cfg,
sim_params=sim_params,
physics_engine=args.physics_engine,
sim_device=args.sim_device,
headless=args.headless)
return env, env_cfg
def make_alg_runner(self, env, name=None, args=None, train_cfg=None, log_root="default") -> Tuple[OnPolicyRunner, LeggedRobotCfgPPO]:
""" Creates the training algorithm either from a registered namme or from the provided config file.
Args:
env (isaacgym.VecTaskPython): The environment to train (TODO: remove from within the algorithm)
name (string, optional): Name of a registered env. If None, the config file will be used instead. Defaults to None.
args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
train_cfg (Dict, optional): Training config file. If None 'name' will be used to get the config file. Defaults to None.
log_root (str, optional): Logging directory for Tensorboard. Set to 'None' to avoid logging (at test time for example).
Logs will be saved in <log_root>/<date_time>_<run_name>. Defaults to "default"=<path_to_LEGGED_GYM>/logs/<experiment_name>.
Raises:
ValueError: Error if neither 'name' or 'train_cfg' are provided
Warning: If both 'name' or 'train_cfg' are provided 'name' is ignored
Returns:
PPO: The created algorithm
Dict: the corresponding config file
"""
# if no args passed get command line arguments
if args is None:
args = get_args()
# if config files are passed use them, otherwise load from the name
if train_cfg is None:
if name is None:
raise ValueError("Either 'name' or 'train_cfg' must be not None")
# load config files
_, train_cfg = self.get_cfgs(name)
else:
if name is not None:
print(f"'train_cfg' provided -> Ignoring 'name={name}'")
# override cfg from args (if specified)
_, train_cfg = update_cfg_from_args(None, train_cfg, args)
if log_root=="default":
log_root = os.path.join(LEGGED_GYM_ROOT_DIR, 'logs', train_cfg.runner.experiment_name)
log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
elif log_root is None:
log_dir = None
else:
log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
train_cfg_dict = class_to_dict(train_cfg)
runner = OnPolicyRunner(env, train_cfg_dict, log_dir, device=args.rl_device)
#save resume path before creating a new log_dir
resume = train_cfg.runner.resume
if resume:
# load previously trained model
resume_path = get_load_path(log_root, load_run=train_cfg.runner.load_run, checkpoint=train_cfg.runner.checkpoint)
print(f"Loading model from: {resume_path}")
runner.load(resume_path)
return runner, train_cfg
# make global task registry
task_registry = TaskRegistry()- 下面我们详细看看
2-3-1 核心数据
TaskRegistry核心数据结构其实只有三个字典:
python
self.task_classes = {}
self.env_cfgs = {}
self.train_cfgs = {}task_classes:环境类,类型:VecEnvenv_cfgs:环境配置,类型:LeggedRobotCfgtrain_cfgs:PPO训练配置,类型:LeggedRobotCfgPPO- 其中
VecEnv:- 没错就是我们上一期解读
rsl_rl中提到的集成环境VecEnv
- 没错就是我们上一期解读
python
from rsl_rl.env import VecEnv2-3-2 创建环境
- 下面这三个函数创建环境很简单,就是根据解析命令行
task name→env class→env instance
python
def get_task_class(self, name: str) -> VecEnv:
return self.task_classes[name]
def get_cfgs(self, name) -> Tuple[LeggedRobotCfg, LeggedRobotCfgPPO]:
train_cfg = self.train_cfgs[name]
env_cfg = self.env_cfgs[name]
# copy seed
env_cfg.seed = train_cfg.seed
return env_cfg, train_cfg
def make_env(self, name, args=None, env_cfg=None) -> Tuple[VecEnv, LeggedRobotCfg]:
""" Creates an environment either from a registered namme or from the provided config file.
Args:
name (string): Name of a registered env.
args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
env_cfg (Dict, optional): Environment config file used to override the registered config. Defaults to None.
Raises:
ValueError: Error if no registered env corresponds to 'name'
Returns:
isaacgym.VecTaskPython: The created environment
Dict: the corresponding config file
"""
# if no args passed get command line arguments
if args is None:
args = get_args()
# check if there is a registered env with that name
if name in self.task_classes:
task_class = self.get_task_class(name)
else:
raise ValueError(f"Task with name: {name} was not registered")
if env_cfg is None:
# load config files
env_cfg, _ = self.get_cfgs(name)
# override cfg from args (if specified)
env_cfg, _ = update_cfg_from_args(env_cfg, None, args)
set_seed(env_cfg.seed)
# parse sim params (convert to dict first)
sim_params = {"sim": class_to_dict(env_cfg.sim)}
sim_params = parse_sim_params(args, sim_params)
env = task_class( cfg=env_cfg,
sim_params=sim_params,
physics_engine=args.physics_engine,
sim_device=args.sim_device,
headless=args.headless)
return env, env_cfg2-3-3 创建算法训练器
python
def make_alg_runner(self, env, name=None, args=None, train_cfg=None, log_root="default") -> Tuple[OnPolicyRunner, LeggedRobotCfgPPO]:
""" Creates the training algorithm either from a registered namme or from the provided config file.
Args:
env (isaacgym.VecTaskPython): The environment to train (TODO: remove from within the algorithm)
name (string, optional): Name of a registered env. If None, the config file will be used instead. Defaults to None.
args (Args, optional): Isaac Gym comand line arguments. If None get_args() will be called. Defaults to None.
train_cfg (Dict, optional): Training config file. If None 'name' will be used to get the config file. Defaults to None.
log_root (str, optional): Logging directory for Tensorboard. Set to 'None' to avoid logging (at test time for example).
Logs will be saved in <log_root>/<date_time>_<run_name>. Defaults to "default"=<path_to_LEGGED_GYM>/logs/<experiment_name>.
Raises:
ValueError: Error if neither 'name' or 'train_cfg' are provided
Warning: If both 'name' or 'train_cfg' are provided 'name' is ignored
Returns:
PPO: The created algorithm
Dict: the corresponding config file
"""
# if no args passed get command line arguments
if args is None:
args = get_args()
# if config files are passed use them, otherwise load from the name
if train_cfg is None:
if name is None:
raise ValueError("Either 'name' or 'train_cfg' must be not None")
# load config files
_, train_cfg = self.get_cfgs(name)
else:
if name is not None:
print(f"'train_cfg' provided -> Ignoring 'name={name}'")
# override cfg from args (if specified)
_, train_cfg = update_cfg_from_args(None, train_cfg, args)
if log_root=="default":
log_root = os.path.join(LEGGED_GYM_ROOT_DIR, 'logs', train_cfg.runner.experiment_name)
log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
elif log_root is None:
log_dir = None
else:
log_dir = os.path.join(log_root, datetime.now().strftime('%b%d_%H-%M-%S') + '_' + train_cfg.runner.run_name)
train_cfg_dict = class_to_dict(train_cfg)
runner = OnPolicyRunner(env, train_cfg_dict, log_dir, device=args.rl_device)
#save resume path before creating a new log_dir
resume = train_cfg.runner.resume
if resume:
# load previously trained model
resume_path = get_load_path(log_root, load_run=train_cfg.runner.load_run, checkpoint=train_cfg.runner.checkpoint)
print(f"Loading model from: {resume_path}")
runner.load(resume_path)
return runner, train_cfg- 这个函数同样简单,调用了我们上一期讲到的
OnPolicyRunner来创建算法
python
from rsl_rl.runners import OnPolicyRunner
runner = OnPolicyRunner(
env,
train_cfg_dict,
log_dir,
device=args.rl_device
)3 LeggedRobotCfg
3-1 代码一栏
- 那么看完最上层的训练代码,我们就继续往下看,来看看刚刚在上一节
TaskRegistry三个核心数据的后两个:env_cfgs:环境配置,类型:LeggedRobotCfgtrain_cfgs:PPO训练配置,类型:LeggedRobotCfgPPO
- 我们打开
legged_gym/envs/base/legged_robot_config.py
python
from .base_config import BaseConfig
class LeggedRobotCfg(BaseConfig):
class env:
num_envs = 4096
num_observations = 48
num_privileged_obs = None # if not None a priviledge_obs_buf will be returned by step() (critic obs for assymetric training). None is returned otherwise
num_actions = 12
env_spacing = 3. # not used with heightfields/trimeshes
send_timeouts = True # send time out information to the algorithm
episode_length_s = 20 # episode length in seconds
test = False
class terrain:
mesh_type = 'plane' # "heightfield" # none, plane, heightfield or trimesh
horizontal_scale = 0.1 # [m]
vertical_scale = 0.005 # [m]
border_size = 25 # [m]
curriculum = True
static_friction = 1.0
dynamic_friction = 1.0
restitution = 0.
# rough terrain only:
measure_heights = True
measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] # 1mx1.6m rectangle (without center line)
measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
selected = False # select a unique terrain type and pass all arguments
terrain_kwargs = None # Dict of arguments for selected terrain
max_init_terrain_level = 5 # starting curriculum state
terrain_length = 8.
terrain_width = 8.
num_rows= 10 # number of terrain rows (levels)
num_cols = 20 # number of terrain cols (types)
# terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
# trimesh only:
slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfaces
class commands:
curriculum = False
max_curriculum = 1.
num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
resampling_time = 10. # time before command are changed[s]
heading_command = True # if true: compute ang vel command from heading error
class ranges:
lin_vel_x = [-1.0, 1.0] # min max [m/s]
lin_vel_y = [-1.0, 1.0] # min max [m/s]
ang_vel_yaw = [-1, 1] # min max [rad/s]
heading = [-3.14, 3.14]
class init_state:
pos = [0.0, 0.0, 1.] # x,y,z [m]
rot = [0.0, 0.0, 0.0, 1.0] # x,y,z,w [quat]
lin_vel = [0.0, 0.0, 0.0] # x,y,z [m/s]
ang_vel = [0.0, 0.0, 0.0] # x,y,z [rad/s]
default_joint_angles = { # target angles when action = 0.0
"joint_a": 0.,
"joint_b": 0.}
class control:
control_type = 'P' # P: position, V: velocity, T: torques
# PD Drive parameters:
stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
# action scale: target angle = actionScale * action + defaultAngle
action_scale = 0.5
# decimation: Number of control action updates @ sim DT per policy DT
decimation = 4
class asset:
file = ""
name = "legged_robot" # actor name
foot_name = "None" # name of the feet bodies, used to index body state and contact force tensors
penalize_contacts_on = []
terminate_after_contacts_on = []
disable_gravity = False
collapse_fixed_joints = True # merge bodies connected by fixed joints. Specific fixed joints can be kept by adding " <... dont_collapse="true">
fix_base_link = False # fixe the base of the robot
default_dof_drive_mode = 3 # see GymDofDriveModeFlags (0 is none, 1 is pos tgt, 2 is vel tgt, 3 effort)
self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter
replace_cylinder_with_capsule = True # replace collision cylinders with capsules, leads to faster/more stable simulation
flip_visual_attachments = True # Some .obj meshes must be flipped from y-up to z-up
density = 0.001
angular_damping = 0.
linear_damping = 0.
max_angular_velocity = 1000.
max_linear_velocity = 1000.
armature = 0.
thickness = 0.01
class domain_rand:
randomize_friction = True
friction_range = [0.5, 1.25]
randomize_base_mass = False
added_mass_range = [-1., 1.]
push_robots = True
push_interval_s = 15
max_push_vel_xy = 1.
class rewards:
class scales:
termination = -0.0
tracking_lin_vel = 1.0
tracking_ang_vel = 0.5
lin_vel_z = -2.0
ang_vel_xy = -0.05
orientation = -0.
torques = -0.00001
dof_vel = -0.
dof_acc = -2.5e-7
base_height = -0.
feet_air_time = 1.0
collision = -1.
feet_stumble = -0.0
action_rate = -0.01
stand_still = -0.
only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
soft_dof_vel_limit = 1.
soft_torque_limit = 1.
base_height_target = 1.
max_contact_force = 100. # forces above this value are penalized
class normalization:
class obs_scales:
lin_vel = 2.0
ang_vel = 0.25
dof_pos = 1.0
dof_vel = 0.05
height_measurements = 5.0
clip_observations = 100.
clip_actions = 100.
class noise:
add_noise = True
noise_level = 1.0 # scales other values
class noise_scales:
dof_pos = 0.01
dof_vel = 1.5
lin_vel = 0.1
ang_vel = 0.2
gravity = 0.05
height_measurements = 0.1
# viewer camera:
class viewer:
ref_env = 0
pos = [10, 0, 6] # [m]
lookat = [11., 5, 3.] # [m]
class sim:
dt = 0.005
substeps = 1
gravity = [0., 0. ,-9.81] # [m/s^2]
up_axis = 1 # 0 is y, 1 is z
class physx:
num_threads = 10
solver_type = 1 # 0: pgs, 1: tgs
num_position_iterations = 4
num_velocity_iterations = 0
contact_offset = 0.01 # [m]
rest_offset = 0.0 # [m]
bounce_threshold_velocity = 0.5 #0.5 [m/s]
max_depenetration_velocity = 1.0
max_gpu_contact_pairs = 2**23 #2**24 -> needed for 8000 envs and more
default_buffer_size_multiplier = 5
contact_collection = 2 # 0: never, 1: last sub-step, 2: all sub-steps (default=2)
class LeggedRobotCfgPPO(BaseConfig):
seed = 1
runner_class_name = 'OnPolicyRunner'
class policy:
init_noise_std = 1.0
actor_hidden_dims = [512, 256, 128]
critic_hidden_dims = [512, 256, 128]
activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
# only for 'ActorCriticRecurrent':
# rnn_type = 'lstm'
# rnn_hidden_size = 512
# rnn_num_layers = 1
class algorithm:
# training params
value_loss_coef = 1.0
use_clipped_value_loss = True
clip_param = 0.2
entropy_coef = 0.01
num_learning_epochs = 5
num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
learning_rate = 1.e-3 #5.e-4
schedule = 'adaptive' # could be adaptive, fixed
gamma = 0.99
lam = 0.95
desired_kl = 0.01
max_grad_norm = 1.
class runner:
policy_class_name = 'ActorCritic'
algorithm_class_name = 'PPO'
num_steps_per_env = 24 # per iteration
max_iterations = 1500 # number of policy updates
# logging
save_interval = 50 # check for potential saves every this many iterations
experiment_name = 'test'
run_name = ''
# load and resume
resume = False
load_run = -1 # -1 = last run
checkpoint = -1 # -1 = last saved model
resume_path = None # updated from load_run and chkpt- 可以看到这其中包含了很多参数,我们一个个来看。
3-2 env环境参数
- 环境配置
python
class env:
num_envs = 4096
num_observations = 48
num_privileged_obs = None # if not None a priviledge_obs_buf will be returned by step() (critic obs for assymetric training). None is returned otherwise
num_actions = 12
env_spacing = 3. # not used with heightfields/trimeshes
send_timeouts = True # send time out information to the algorithm
episode_length_s = 20 # episode length in seconds
test = Falsenum_envs:同时并行运行的机器人环境数量num_observations:策略网络输入的观测维度num_privileged_obs:这个参数用于 asymmetric actor-critic,上一期我们也讲过,如果设置为None则不使用特权观测维度num_actions:动作空间维度,4 条腿 × 3 个关节 = 12env_spacing:多个机器人环境之间的间距,这个参数不会生效,因为地形已经统一生成。send_timeouts:是否把 episode timeout 信息发送给算法episode_length_s:每个 episode 持续时间(秒)test:训练模式还是测试模式- 下图为设置
num_envs=1的情况下,可以看到整个环境里头就只有一只机械狗

3-3 terrain地形参数
- 用于配置地形
python
class terrain:
mesh_type = 'plane' # "heightfield" # none, plane, heightfield or trimesh
horizontal_scale = 0.1 # [m]
vertical_scale = 0.005 # [m]
border_size = 25 # [m]
curriculum = True
static_friction = 1.0
dynamic_friction = 1.0
restitution = 0.
# rough terrain only:
measure_heights = True
measured_points_x = [-0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] # 1mx1.6m rectangle (without center line)
measured_points_y = [-0.5, -0.4, -0.3, -0.2, -0.1, 0., 0.1, 0.2, 0.3, 0.4, 0.5]
selected = False # select a unique terrain type and pass all arguments
terrain_kwargs = None # Dict of arguments for selected terrain
max_init_terrain_level = 5 # starting curriculum state
terrain_length = 8.
terrain_width = 8.
num_rows= 10 # number of terrain rows (levels)
num_cols = 20 # number of terrain cols (types)
# terrain types: [smooth slope, rough slope, stairs up, stairs down, discrete]
terrain_proportions = [0.1, 0.1, 0.35, 0.25, 0.2]
# trimesh only:
slope_treshold = 0.75 # slopes above this threshold will be corrected to vertical surfacesmesh_type:环境的地形配置none:无地面(不常用)plane:平地,最简单的训练环境heightfield:高度场,生成凹凸不平的连续地面trimesh:三角网格,自定义复杂地形(可导入CAD模型)- 注:这里修改不会发生变化依旧是平地,我们下面3-1-1讲。
- 地图缩放:
horizontal_scale:网格在水平轴的缩放,越小网格越细。vertical_scale:网格高度缩放,用于放大凹凸效果。
border_size:地形边界大小。- 课程训练
curriculum:开启地形难度渐进策略。max_init_terrain_level:训练初期的最大难度级别,越高地形越复杂。
- 摩擦力系数
static_friction:环境的地形配置dynamic_friction:环境的地形配置restitution:环境的地形配置
- Rough terrain 高度测量
measure_heights:是否对粗糙地形采样高度。measured_points_x/y:在机器人底盘下采样点,通常生成 局部高度观测,供 RL 网络计算奖励或控制。
- 选择固定地形
selected = True:固定选择一种地形类型训练,不随机生成。terrain_kwargs:可传入自定义参数覆盖默认地形设置。
- 地形尺寸和网格
terrain_length/width:地形实际尺寸(米)num_rows/num_cols:地形网格划分行列,用于随机生成不同类型地形
terrain_proportions:控制不同地形类型出现的比例:smooth slope(平滑坡)rough slope(粗糙坡)stairs up(上坡台阶)stairs down(下坡台阶)discrete(离散凹凸)
slope_treshold:对三角网格地形有效,超过阈值的坡度会被修正为垂直面,避免机器人"滑下坡"或掉落
3-1-1 地形仍为平地问题
- 这是因为在
legged_gym/envs/base/legged_robot.py中
python
def create_sim(self):
""" Creates simulation, terrain and evironments
"""
self.up_axis_idx = 2 # 2 for z, 1 for y -> adapt gravity accordingly
self.sim = self.gym.create_sim(self.sim_device_id, self.graphics_device_id, self.physics_engine, self.sim_params)
self._create_ground_plane()
self._create_envs()
def _get_env_origins(self):
""" Sets environment origins. On rough terrain the origins are defined by the terrain platforms.
Otherwise create a grid.
"""
self.custom_origins = False
self.env_origins = torch.zeros(self.num_envs, 3, device=self.device, requires_grad=False)
# create a grid of robots
num_cols = np.floor(np.sqrt(self.num_envs))
num_rows = np.ceil(self.num_envs / num_cols)
xx, yy = torch.meshgrid(torch.arange(num_rows), torch.arange(num_cols))
spacing = self.cfg.env.env_spacing
self.env_origins[:, 0] = spacing * xx.flatten()[:self.num_envs]
self.env_origins[:, 1] = spacing * yy.flatten()[:self.num_envs]
self.env_origins[:, 2] = 0.- 可以看到并没有解析地形参数,而是直接生成平底了。
- 如果需要使用特殊地形,我们需要补上代码并修改生成地形和初始化机器人位姿的代码
- 感兴趣的朋友们可以参考# 修改环境训练不生效 #66自行补上代码
- 感兴趣的朋友们可以参考# 修改环境训练不生效 #66自行补上代码
3-4 commands接收命令参数
python
class commands:
curriculum = False
max_curriculum = 1.
num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
resampling_time = 10. # time before command are changed[s]
heading_command = True # if true: compute ang vel command from heading error
class ranges:
lin_vel_x = [-1.0, 1.0] # min max [m/s]
lin_vel_y = [-1.0, 1.0] # min max [m/s]
ang_vel_yaw = [-1, 1] # min max [rad/s]
heading = [-3.14, 3.14]curriculum:是否开启课程学习(Curriculum Learning),训练过程中机器人的指令难度会随着训练进程逐渐增加。max_curriculum:课程学习的最大难度系数。num_commands:机器人每个时间步接收到的指令维度。默认 4 表示四种控制信号:lin_vel_x:前后方向的线速度(m/s)lin_vel_y:左右方向的线速度(m/s)ang_vel_yaw:绕 z 轴的角速度(rad/s)heading:机器人目标朝向(rad)
resampling_time:每条指令保持多久才重新采样新的目标指令。heading_command:是否启用"朝向命令模式"。如果是算法会使用heading来计算绕 z 轴旋转角速度ang_vel_yaw,通过 PID 或差值控制机器人朝向目标方向。ranges:定义每个指令的范围,用于随机采样训练指令
3-5 init_state初始位姿
python
class init_state:
pos = [0.0, 0.0, 1.] # x,y,z [m]
rot = [0.0, 0.0, 0.0, 1.0] # x,y,z,w [quat]
lin_vel = [0.0, 0.0, 0.0] # x,y,z [m/s]
ang_vel = [0.0, 0.0, 0.0] # x,y,z [rad/s]
default_joint_angles = { # target angles when action = 0.0
"joint_a": 0.,
"joint_b": 0.}- 顾名思义
3-6 control关节控制器参数
python
class control:
control_type = 'P' # P: position, V: velocity, T: torques
# PD Drive parameters:
stiffness = {'joint_a': 10.0, 'joint_b': 15.} # [N*m/rad]
damping = {'joint_a': 1.0, 'joint_b': 1.5} # [N*m*s/rad]
# action scale: target angle = actionScale * action + defaultAngle
action_scale = 0.5
# decimation: Number of control action updates @ sim DT per policy DT
decimation = 4control_type控制模式类型'P'→ 位置控制(Position Control):策略输出目标关节角度'V'→ 速度控制(Velocity Control):策略输出目标关节速度'T'→ 力矩控制(Torque Control):策略直接输出关节力矩
stiffness:(刚度)关节偏离目标角度时产生的回复力矩大小,数值越大 → 关节越"硬",动作越快响应damping:(阻尼)关节运动速度的阻力,防止振荡,运动越平滑,但响应稍慢- 这两个参数结合形成 PD 控制器 : τ = K p ( θ target − θ ) − K d θ ˙ \tau = K_p (\theta_\text{target} - \theta) - K_d \dot{\theta} τ=Kp(θtarget−θ)−Kdθ˙
action_scale:策略输出动作与关节实际目标角度的缩放比例,公式: t a r g e t a n g l e = a c t i o n S c a l e ∗ a c t i o n + d e f a u l t A n g l e target angle = actionScale * action + defaultAngle targetangle=actionScale∗action+defaultAngledecimation:动作更新频率降低因子,每隔decimation个仿真步,更新一次控制动作
3-7 asset模型(资产)的物理、碰撞和几何属性
python
class asset:
file = ""
name = "legged_robot" # actor name
foot_name = "None" # name of the feet bodies, used to index body state and contact force tensors
penalize_contacts_on = []
terminate_after_contacts_on = []
disable_gravity = False
collapse_fixed_joints = True # merge bodies connected by fixed joints. Specific fixed joints can be kept by adding " <... dont_collapse="true">
fix_base_link = False # fixe the base of the robot
default_dof_drive_mode = 3 # see GymDofDriveModeFlags (0 is none, 1 is pos tgt, 2 is vel tgt, 3 effort)
self_collisions = 0 # 1 to disable, 0 to enable...bitwise filter
replace_cylinder_with_capsule = True # replace collision cylinders with capsules, leads to faster/more stable simulation
flip_visual_attachments = True # Some .obj meshes must be flipped from y-up to z-up
density = 0.001
angular_damping = 0.
linear_damping = 0.
max_angular_velocity = 1000.
max_linear_velocity = 1000.
armature = 0.
thickness = 0.01penalize_contacts_on:哪些刚体接触会产生惩罚(Reward 减分)terminate_after_contacts_on:哪些刚体接触会直接终止仿真disable_gravity:是否禁用重力collapse_fixed_joints:将由固定关节连接的刚体合并为一个刚体fix_base_link:是否固定机器人底座default_dof_drive_mode:默认关节驱动模式,对应 GymDofDriveModeFlags :- 0 → 无控制
- 1 → 位置目标
- 2 → 速度目标
- 3 → 力矩(effort)控制
self_collisions:是否禁用自碰撞replace_cylinder_with_capsule:将碰撞体的圆柱(Cylinder)替换为胶囊(Capsule)flip_visual_attachments:翻转模型可视网格的坐标系density:刚体密度(kg/m³)angular_damping&linear_damping:刚体旋转与线性运动的阻尼max_angular_velocity&max_linear_velocity:刚体角速度和线速度的上限armature:附加惯量,通常用于关节模拟thickness:碰撞网格厚度
3-8 domain_rand领域随机化(Domain Randomization)参数
python
class domain_rand:
randomize_friction = True
friction_range = [0.5, 1.25]
randomize_base_mass = False
added_mass_range = [-1., 1.]
push_robots = True
push_interval_s = 15
max_push_vel_xy = 1.randomize_friction:是否随机化摩擦系数friction_range:摩擦系数随机范围[min, max]randomize_base_mass:是否随机化机器人底座质量added_mass_range:随机化的额外质量范围[min, max](kg)push_robots:是否给机器人施加随机推力push_interval_s:每隔多少秒施加一次推力(s)max_push_vel_xy:推力产生的最大速度扰动(m/s)
3-9 核心参数rewards
python
class rewards:
class scales:
termination = -0.0
tracking_lin_vel = 1.0
tracking_ang_vel = 0.5
lin_vel_z = -2.0
ang_vel_xy = -0.05
orientation = -0.
torques = -0.00001
dof_vel = -0.
dof_acc = -2.5e-7
base_height = -0.
feet_air_time = 1.0
collision = -1.
feet_stumble = -0.0
action_rate = -0.01
stand_still = -0.
only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
soft_dof_vel_limit = 1.
soft_torque_limit = 1.
base_height_target = 1.
max_contact_force = 100. # forces above this value are penalized- scales 子类:各项奖励/惩罚的权重
termination:终止惩罚,通常在机器人摔倒或碰撞时触发tracking_lin_vel:线速度跟踪奖励,机器人朝目标速度运动获得正奖励tracking_ang_vel:角速度跟踪奖励,机器人旋转符合目标角速度获得奖励lin_vel_z:垂直速度惩罚,控制机器人不随意跳跃或下落ang_vel_xy:横向角速度惩罚,限制机器人倾斜或翻滚orientation:朝向奖励/惩罚,可控制机器人姿态torques:电机力矩惩罚,用于鼓励低能耗动作dof_vel:关节速度惩罚dof_acc:关节加速度惩罚,鼓励平滑动作base_height:底座高度惩罚,维持机器人高度feet_air_time:抬脚时间奖励,适用于步态学习collision:碰撞惩罚,避免碰撞障碍feet_stumble:绊倒惩罚action_rate:动作变化速率惩罚,鼓励平滑动作stand_still:静止奖励/惩罚,可鼓励保持不动- 注:数值越大(正或负)代表该项对总奖励影响越显著。
only_positive_rewards:如果为True,总奖励会被裁剪为非负数(即总奖励不低于 0)tracking_sigma:用于速度跟踪的高斯奖励公式 r e w a r d = exp ( − ( e r r o r ) 2 σ 2 ) reward = \exp\left(-\frac{(error)^2}{\sigma^2}\right) reward=exp(−σ2(error)2)- 作用:误差越小奖励越高,σ 控制"容忍度"
soft_dof_pos_limit / soft_dof_vel_limit / soft_torque_limit:关节位置、速度和力矩超过 URDF 限制比例时给予惩罚base_height_target:机器人底座的目标高度(m),奖励会引导机器人保持此高度max_contact_force:接触力阈值,超过这个力会被惩罚
3-10 normalization观测归一化
python
class normalization:
class obs_scales:
lin_vel = 2.0
ang_vel = 0.25
dof_pos = 1.0
dof_vel = 0.05
height_measurements = 5.0
clip_observations = 100.
clip_actions = 100.normalization.obs_scales:各类观测的归一化缩放因子lin_vel:线速度缩放,除以 2.0,使观测值在合理范围ang_vel:角速度缩放,除以 0.25dof_pos:关节位置缩放,除以 1.0(保持原值)dof_vel:关节速度缩放,除以 0.05height_measurements:高度观测缩放,除以 5.0
clip_observations:观测值裁剪阈值,超过 ±100 的值会被截断,防止异常值干扰训练clip_actions:动作值裁剪阈值,超过 ±100 的动作会被截断
3-11 noise噪声
python
class noise:
add_noise = True
noise_level = 1.0 # scales other values
class noise_scales:
dof_pos = 0.01
dof_vel = 1.5
lin_vel = 0.1
ang_vel = 0.2
gravity = 0.05
height_measurements = 0.1noise.add_noise:是否在观测中添加噪声
noise.noise_level:整体噪声缩放因子,控制噪声强度noise.noise_scales:针对每类观测的噪声标准差dof_pos:关节位置噪声dof_vel:关节速度噪声lin_vel:线速度噪声ang_vel:角速度噪声gravity:重力观测噪声height_measurements:高度测量噪声
3-12 方针和可视化
python
# viewer camera:
class viewer:
ref_env = 0
pos = [10, 0, 6] # [m]
lookat = [11., 5, 3.] # [m]
class sim:
dt = 0.005
substeps = 1
gravity = [0., 0. ,-9.81] # [m/s^2]
up_axis = 1 # 0 is y, 1 is z
class physx:
num_threads = 10
solver_type = 1 # 0: pgs, 1: tgs
num_position_iterations = 4
num_velocity_iterations = 0
contact_offset = 0.01 # [m]
rest_offset = 0.0 # [m]
bounce_threshold_velocity = 0.5 #0.5 [m/s]
max_depenetration_velocity = 1.0
max_gpu_contact_pairs = 2**23 #2**24 -> needed for 8000 envs and more
default_buffer_size_multiplier = 5
contact_collection = 2 # 0: never, 1: last sub-step, 2: all sub-steps (default=2)viewer:用于渲染观察的摄像机参数ref_env:参考环境索引,用于多环境渲染pos:摄像机在世界坐标系中的位置lookat:摄像机注视点
sim:物理仿真核心参数dt:每次仿真更新的时间间隔,影响仿真精度和速度substeps:在一个仿真步内细分的子步数,提高碰撞和力学稳定性gravity:重力向量up_axis:指定世界坐标系中的上方向
physx:NVIDIA PhysX 仿真引擎参数num_threads:CPU物理线程数solver_type:物理求解器类型num_position_iterations / num_velocity_iterations:迭代次数,控制稳定性与精度contact_offset / rest_offset:碰撞检测和接触缓冲bounce_threshold_velocity:低速碰撞是否触发弹跳max_depenetration_velocity:碰撞分离速度上限max_gpu_contact_pairs:GPU同时处理的接触对上限default_buffer_size_multiplier:缓冲区扩容系数contact_collection:碰撞数据收集模式,决定仿真中是否保留接触信息
4 LeggedRobotCfgPPO
4-1 完整代码一栏
python
class LeggedRobotCfgPPO(BaseConfig):
seed = 1
runner_class_name = 'OnPolicyRunner'
class policy:
init_noise_std = 1.0
actor_hidden_dims = [512, 256, 128]
critic_hidden_dims = [512, 256, 128]
activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
# only for 'ActorCriticRecurrent':
# rnn_type = 'lstm'
# rnn_hidden_size = 512
# rnn_num_layers = 1
class algorithm:
# training params
value_loss_coef = 1.0
use_clipped_value_loss = True
clip_param = 0.2
entropy_coef = 0.01
num_learning_epochs = 5
num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
learning_rate = 1.e-3 #5.e-4
schedule = 'adaptive' # could be adaptive, fixed
gamma = 0.99
lam = 0.95
desired_kl = 0.01
max_grad_norm = 1.
class runner:
policy_class_name = 'ActorCritic'
algorithm_class_name = 'PPO'
num_steps_per_env = 24 # per iteration
max_iterations = 1500 # number of policy updates
# logging
save_interval = 50 # check for potential saves every this many iterations
experiment_name = 'test'
run_name = ''
# load and resume
resume = False
load_run = -1 # -1 = last run
checkpoint = -1 # -1 = last saved model
resume_path = None # updated from load_run and chkptLeggedRobotCfgPPO:强化学习训练核心配置seed:随机种子,保证实验可复现runner_class_name:训练器类型,这里使用"OnPolicyRunner",也就是我们上一期讲过的【宇树机器人强化学习】(三):OnPolicyRunner和VecEnv以及RolloutStorage的python实现与解析
4-2 policy策略
python
class policy:
init_noise_std = 1.0
actor_hidden_dims = [512, 256, 128]
critic_hidden_dims = [512, 256, 128]
activation = 'elu' # can be elu, relu, selu, crelu, lrelu, tanh, sigmoid
# only for 'ActorCriticRecurrent':
# rnn_type = 'lstm'
# rnn_hidden_size = 512
# rnn_num_layers = 1init_noise_std:初始化动作噪声标准差,用于探索actor_hidden_dims:Actor网络隐藏层维度critic_hidden_dims:Critic网络隐藏层维度activation:激活函数类型(如elu、relu、tanh等)rnn_type / rnn_hidden_size / rnn_num_layers:仅对循环策略网络(ActorCriticRecurrent)生效
4-3 algorithm PPO算法参数
python
class algorithm:
# training params
value_loss_coef = 1.0
use_clipped_value_loss = True
clip_param = 0.2
entropy_coef = 0.01
num_learning_epochs = 5
num_mini_batches = 4 # mini batch size = num_envs*nsteps / nminibatches
learning_rate = 1.e-3 #5.e-4
schedule = 'adaptive' # could be adaptive, fixed
gamma = 0.99
lam = 0.95
desired_kl = 0.01
max_grad_norm = 1.value_loss_coef:Critic损失权重use_clipped_value_loss:是否使用截断值函数损失clip_param:PPO截断范围entropy_coef:策略熵正则化权重,鼓励探索num_learning_epochs:每次采样的训练轮数num_mini_batches:小批量数量 = num_envs * nsteps / num_mini_batcheslearning_rate:学习率schedule:学习率调度方式,可选adaptive或fixedgamma:折扣因子lam:GAE优势估计参数desired_kl:期望KL散度,用于自适应学习率max_grad_norm:梯度裁剪上限
4-4 runner训练循环参数
python
class runner:
policy_class_name = 'ActorCritic'
algorithm_class_name = 'PPO'
num_steps_per_env = 24 # per iteration
max_iterations = 1500 # number of policy updates
# logging
save_interval = 50 # check for potential saves every this many iterations
experiment_name = 'test'
run_name = ''
# load and resume
resume = False
load_run = -1 # -1 = last run
checkpoint = -1 # -1 = last saved model
resume_path = None # updated from load_run and chkptpolicy_class_name:策略网络类名称algorithm_class_name:算法类型num_steps_per_env:每个环境每轮采样步数max_iterations:最大训练轮数 / 策略更新次数save_interval:每多少轮检查是否保存模型experiment_name:实验名称run_name:运行名称resume:是否从已有模型恢复训练load_run:-1 表示加载最后一次运行checkpoint:-1 表示加载最后保存的模型resume_path:恢复训练的路径,由load_run和checkpoint决定
5 train训练输出解析
5-1 实例
-
我们设置
num_envs = 40,其他参数保存默认,我们来看一下训练过程中会输出什么:################################################################################
Learning iteration 300/1500Computation: 1504 steps/s (collection: 0.576s, learning 0.062s) Value function loss: 0.0001 Surrogate loss: -0.0234 Mean action noise std: 1.04 Mean reward: 0.06 Mean episode length: 367.28 Mean episode rew_action_rate: -0.0882 Mean episode rew_ang_vel_xy: -0.1622 Mean episode rew_collision: -0.0200 Mean episode rew_dof_acc: -0.0849 Mean episode rew_dof_pos_limits: -0.0121 Mean episode rew_feet_air_time: -0.0244 Mean episode rew_lin_vel_z: -0.0413 Mean episode rew_torques: -0.0305Mean episode rew_tracking_ang_vel: 0.0340
Mean episode rew_tracking_lin_vel: 0.0328
5-2 训练时间
Learning iteration 300/1500:当前是第 300 次策略更新,总共计划更新 1500 次。Computation: 1504 steps/s (collection: 0.576s, learning 0.062s):1504 steps/s:每秒采集和训练的总步数collection: 0.576s:采集数据所用时间learning 0.062s:训练更新所用时间
5-3 损失函数
Value function loss: 0.0001:Critic(值函数)损失,非常低,说明值函数预测较准确。Surrogate loss: -0.0234:PPO的 surrogate loss,负值也常见,表示策略在当前迭代下微调。
5-4 策略探索
Mean action noise std: 1.04:动作噪声标准差,表示策略在探索动作空间时的随机性。- 越大 → 探索越激进
- 越小 → 策略更稳定
5-5 奖励指标
Mean reward: 0.06:本轮平均总奖励,正数表示策略略微学到了一些动作。Mean episode rew_action_rate: -0.0882→ 动作变化速率惩罚,动作变化过快Mean episode rew_ang_vel_xy: -0.1622→ 横向角速度惩罚,机器人可能有轻微翻滚/倾斜Mean episode rew_collision: -0.0200→ 碰撞惩罚,说明偶尔有碰撞Mean episode rew_dof_acc: -0.0849→ 关节加速度惩罚,动作不够平滑Mean episode rew_dof_pos_limits: -0.0121→ 关节位置软限制惩罚,很小Mean episode rew_feet_air_time: -0.0244→ 抬脚时间奖励偏低Mean episode rew_lin_vel_z: -0.0413→ 垂直速度惩罚,控制跳跃/下落Mean episode rew_torques: -0.0305→ 力矩惩罚,动作能耗Mean episode rew_tracking_ang_vel: 0.0340→ 角速度跟踪奖励,策略在旋转方向略有改善Mean episode rew_tracking_lin_vel: 0.0328→ 线速度跟踪奖励,机器人前进方向学习中
5-6 其他
Mean episode length: 367.28:平均每回合长度,回合未提前终止太多,训练环境较稳定。

小结
- 本期我们梳理了
unitree_rl_gym的训练流程,从train.py的入口到TaskRegistry的环境与算法创建,再到LeggedRobotCfg的环境和训练参数配置,全面了解了并行环境、地形设置、动作观测维度、奖励设计和仿真参数,为后续解析 Go2 机器人环境及 PPO 训练闭环打下了基础。 - 下一期我们
legged_gym/envs/base/legged_robot.py从奖励函数的实现开始。 - 如有错误,欢迎指出!感谢观看