视觉Transformer实战 | Cross-Attention Multi-Scale Vision Transformer(CrossViT)
-
- [0. 前言](#0. 前言)
- [1. CrossViT 核心思想](#1. CrossViT 核心思想)
-
- [1.1 ViT 局限性](#1.1 ViT 局限性)
- [1.2 CrossViT 原理](#1.2 CrossViT 原理)
- [2. CrossViT 模型架构](#2. CrossViT 模型架构)
-
- [2.1 双分支结构](#2.1 双分支结构)
- [2.2 多尺度特征融合策略](#2.2 多尺度特征融合策略)
- [2.3 预测机制](#2.3 预测机制)
- [3. 实现 CrossViT](#3. 实现 CrossViT)
-
- [3.1 数据集加载](#3.1 数据集加载)
- [3.2 模型构建](#3.2 模型构建)
- [3.3 模型训练](#3.3 模型训练)
- 相关链接
0. 前言
Vision Transformer (ViT)在计算机视觉领域取得了巨大成功,但标准 ViT 结构在处理不同尺度的视觉特征时存在局限性。双分支 ViT (Cross-Attention Multi-Scale Vision Transformer, CrossViT) 通过引入双分支结构来解决这一问题,能够同时捕获局部和全局视觉特征。本文将详细介绍 CrossViT 的技术原理,并使用 PyTorch 从零开始实现 CrossViT 模型。
1. CrossViT 核心思想
1.1 ViT 局限性
ViT 的性能受 patch 大小的显著影响:小尺寸 patch (如 16×16 )可捕获细粒度特征,提升精度(如比 32×32 patch 高 6%),但计算量激增( FLOPs 增加 4 倍)。同时,单一尺度特征难以适应多尺度物体识别,而卷积神经网络 (Cable News Network, CNN) 中多尺度融合(如特征金字塔)能够显著增加模型多尺度检测性能,但在 Transformer 中尚未充分探索。
1.2 CrossViT 原理
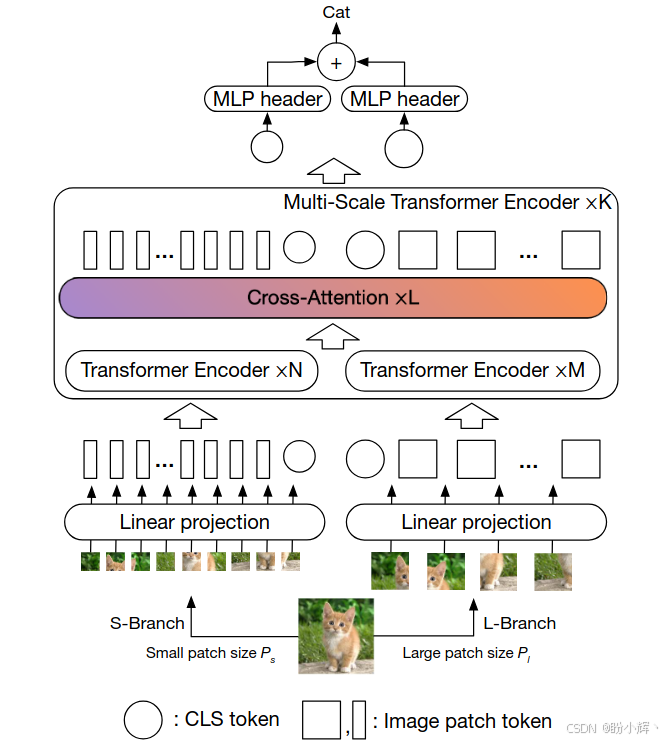
为了解决标准 ViT 在处理不同尺度特征时存在的局限性,CrossViT 设计了双分支架构(如下图所示),分别处理不同粒度的 patch,并通过高效的跨分支信息融合平衡计算与精度:
L-Branch(大分支):处理粗粒度patch(如32×32),使用更深的Transformer编码器和更大的嵌入维度S-Branch(小分支):处理细粒度patch(如16×16),使用较浅的编码器和更小的嵌入维度,轻量化设计避免计算爆炸
2. CrossViT 模型架构
2.1 双分支结构
| 分支 | Patch尺寸 | Transformer层数 | Embedding维度 | 作用 |
|---|---|---|---|---|
| L-Branch | 大(如 32×32 ) | 较多(如 12 层) | 较高(如 768 维) | 主特征提取 |
| S-Branch | 小(如 16×16 ) | 较少(如 4 层) | 较低(如 384 维) | 补充细粒度信息 |
每个分支独立进行 Patch 嵌入,并添加可学习的位置编码。分支间通过多尺度 Transformer 编码器交互,每个编码器包含:
- 分支内自注意力 (
Self-Attention) - 分支间交叉注意力 (
Cross-Attention) 融合模块
2.2 多尺度特征融合策略
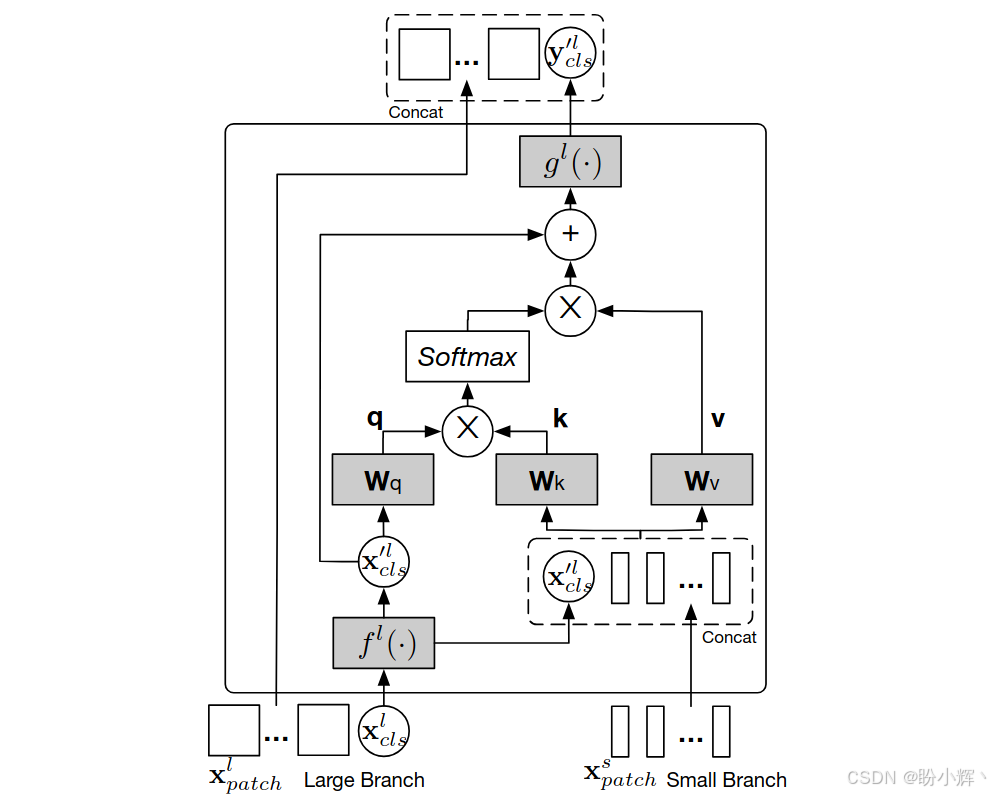
有效的特征融合是学习多尺度特征表示的关键。CrossViT 探索了四种融合方式,最终选择 Cross-Attention Fusion:

All-Attention Fusion:拼接所有Token后通过自注意力融合,计算复杂度高 ( O ( N 2 ) O(N^2) O(N2))Class Token Fusion:仅融合两分支的Class Token,忽略空间信息Pairwise Fusion:对齐空间位置后逐点融合,因为两个分支处理的patch大小不同,token的数量也不同,需插值操作引入噪声,然后再进行融合Cross-Attention Fusion(选定方案):其中一个分支的Class token与另一个分支的所有Patch token进行融合,具体而言,以Class Token为代理,将分支A的Class Token作为查询 (Query),与分支B的Patch Token计算注意力,信息交换流程:Class token A与Patch Token B交互 → 获取B分支的细粒度信息,由于Class token已经从自己分支的所有Patch token中学习到了抽象信息,因此与另一个分支的Patch token进行交互有助于融入不同尺度的信息- 更新后的
Class token A通过自注意力将信息传递给Patch Token A,将从其它分支学习到的信息传递给自己分支的Patch Token从而丰富每个Patch Token的特征表示
2.3 预测机制
最终融合特征由两个分支的 Class Token 拼接后线性分类,保留双分支全局信息,避免单一 Class Token 的信息损失:
y p r e d = L i n e a r ( C L S L ; C L S S ) y_{pred}=Linear(CLS_L;CLS_S) ypred=Linear(CLSL;CLSS)
3. 实现 CrossViT
3.1 数据集加载
为了训练 CrossViT,本节使用 Oxford-IIIT Pet Dataset 数据集,该数据集是一个广泛应用于计算机视觉研究的宠物图像数据集,包含 37 种宠物类别的数据集,其中包含 12 种猫的类别和 25 种狗的类别,每个类别大约有 200 张图像,总计约 7349 张图像。首先下载数据集images.tar.gz,下载完成后解压缩,图像样本如下所示:
(1) 首先,加载所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import numpy as np
from PIL import Image
import os
import matplotlib.pyplot as plt
from tqdm import tqdm
import re
from sklearn.model_selection import train_test_split(2) 定义数据集类 CustomDataset,用于读取图像,并根据文件名为图像分配标签(图片文件名以"类别名_序号"构成):
python
class CustomDataset(Dataset):
def __init__(self, root_dir, transform=None, train=True, test_size=0.1):
self.root_dir = root_dir
self.transform = transform
self.train = train
# 获取所有图像和对应的标签
self.image_paths = []
self.labels = []
# 从文件名中提取类别
all_files = os.listdir(root_dir)
pattern = re.compile(r'^(.+?)_\d+\.(jpg|jpeg|png)$', re.IGNORECASE)
# 收集所有类别
classes = set()
for filename in all_files:
match = pattern.match(filename)
if match:
classes.add(match.group(1))
self.classes = sorted(classes)
self.class_to_idx = {cls: idx for idx, cls in enumerate(self.classes)}
# 收集所有有效图像
for filename in all_files:
match = pattern.match(filename)
if match:
cls = match.group(1)
self.image_paths.append(os.path.join(root_dir, filename))
self.labels.append(self.class_to_idx[cls])
# 划分训练集和验证集
train_paths, test_paths, train_labels, test_labels = train_test_split(
self.image_paths, self.labels, test_size=test_size, stratify=self.labels
)
if train:
self.image_paths = train_paths
self.labels = train_labels
else:
self.image_paths = test_paths
self.labels = test_labels
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert('RGB')
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label(3) 创建数据集和数据加载器:
python
# 数据增强和归一化
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 0.2))
], p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 创建数据集和数据加载器
batch_size = 16
train_dataset = CustomDataset(root_dir='data/images', transform=train_transform, train=True)
test_dataset = CustomDataset(root_dir='data/images', transform=test_transform, train=False)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4, pin_memory=True)
# 获取类别数量
num_classes = len(train_dataset.classes)
print(f"数据集包含 {num_classes} 个类别: {train_dataset.classes}")3.2 模型构建
(1) 将图像分割为 patch 并嵌入到向量空间:
python
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
# 使用卷积层实现patch embedding
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
x = self.proj(x) # (B, embed_dim, n_patches_h, n_patches_w)
x = x.flatten(2) # (B, embed_dim, n_patches)
x = x.transpose(1, 2) # (B, n_patches, embed_dim)
return x(2) 定义多头注意力机制:
python
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim=768, num_heads=8, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim必须能被num_heads整除"
# 定义Q,K,V投影层
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
self.attn_dropout = nn.Dropout(dropout)
self.proj = nn.Linear(embed_dim, embed_dim)
self.proj_dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
B, N, C = x.shape
# 生成Q,K,V
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = attn.softmax(dim=-1)
attn = self.attn_dropout(attn)
# 应用注意力权重到V上
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_dropout(x)
return x(3) 定义 Transformer 编码器块:
python
class TransformerBlock(nn.Module):
def __init__(self, embed_dim=768, num_heads=8, mlp_ratio=4.0, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = MultiHeadSelfAttention(embed_dim, num_heads, dropout)
self.norm2 = nn.LayerNorm(embed_dim)
# MLP层
mlp_hidden_dim = int(embed_dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, mlp_hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
# 残差连接和层归一化
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x(4) 定义交叉注意力模块,用于两个分支间的信息交换:
python
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim, num_heads=8, dropout=0.1):
super().__init__()
self.query_dim = query_dim
self.context_dim = context_dim
self.num_heads = num_heads
self.head_dim = query_dim // num_heads
assert self.head_dim * num_heads == query_dim, "query_dim必须能被num_heads整除"
# 查询投影 (query_dim -> query_dim)
self.q = nn.Linear(query_dim, query_dim)
# 键值投影 (context_dim -> 2 * query_dim)
self.kv = nn.Linear(context_dim, 2 * query_dim)
self.attn_dropout = nn.Dropout(dropout)
self.proj = nn.Linear(query_dim, query_dim)
self.proj_dropout = nn.Dropout(dropout)
def forward(self, x, context):
B, N, _ = x.shape
_, M, _ = context.shape
# 生成Q (来自查询分支)
q = self.q(x).reshape(B, N, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# 生成K,V (来自上下文分支)
kv = self.kv(context).reshape(B, M, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = attn.softmax(dim=-1)
attn = self.attn_dropout(attn)
# 应用注意力权重到V上
x = (attn @ v).transpose(1, 2).reshape(B, N, self.query_dim)
x = self.proj(x)
x = self.proj_dropout(x)
return x(5) 定义完整的 CrossViT 模型:
python
class CrossViT(nn.Module):
def __init__(self, img_size=224, in_channels=3, num_classes=10,
small_patch_size=8, small_embed_dim=192, small_depth=4, small_num_heads=6,
large_patch_size=16, large_embed_dim=384, large_depth=4, large_num_heads=12,
cross_depth=2, dropout=0.1):
"""
参数:
img_size (int): 输入图像大小
in_channels (int): 输入通道数
num_classes (int): 分类类别数
small_patch_size (int): 小分支的patch大小
small_embed_dim (int): 小分支的嵌入维度
small_depth (int): 小分支的Transformer块数
small_num_heads (int): 小分支的注意力头数
large_patch_size (int): 大分支的patch大小
large_embed_dim (int): 大分支的嵌入维度
large_depth (int): 大分支的Transformer块数
large_num_heads (int): 大分支的注意力头数
cross_depth (int): 交叉注意力块数
dropout (float): dropout概率
"""
super().__init__()
# 小分支(处理小patch)
self.small_patch_embed = PatchEmbedding(img_size, small_patch_size, in_channels, small_embed_dim)
self.small_cls_token = nn.Parameter(torch.zeros(1, 1, small_embed_dim))
self.small_pos_embed = nn.Parameter(torch.zeros(1, self.small_patch_embed.n_patches + 1, small_embed_dim))
# 大分支(处理大patch)
self.large_patch_embed = PatchEmbedding(img_size, large_patch_size, in_channels, large_embed_dim)
self.large_cls_token = nn.Parameter(torch.zeros(1, 1, large_embed_dim))
self.large_pos_embed = nn.Parameter(torch.zeros(1, self.large_patch_embed.n_patches + 1, large_embed_dim))
# Dropout
self.pos_dropout = nn.Dropout(dropout)
# 小分支Transformer编码器
self.small_blocks = nn.ModuleList([
TransformerBlock(small_embed_dim, small_num_heads, 4.0, dropout)
for _ in range(small_depth)
])
# 大分支Transformer编码器
self.large_blocks = nn.ModuleList([
TransformerBlock(large_embed_dim, large_num_heads, 4.0, dropout)
for _ in range(large_depth)
])
# 交叉注意力模块
self.cross_blocks = nn.ModuleList()
for _ in range(cross_depth):
# 小分支到大分支的交叉注意力
self.cross_blocks.append(nn.ModuleList([
CrossAttention(query_dim=small_embed_dim, context_dim=large_embed_dim,
num_heads=small_num_heads, dropout=dropout),
CrossAttention(query_dim=large_embed_dim, context_dim=small_embed_dim,
num_heads=large_num_heads, dropout=dropout)
]))
# 分类头
self.norm_small = nn.LayerNorm(small_embed_dim)
self.norm_large = nn.LayerNorm(large_embed_dim)
self.head = nn.Linear(small_embed_dim + large_embed_dim, num_classes)
# 初始化权重
nn.init.trunc_normal_(self.small_cls_token, std=0.02)
nn.init.trunc_normal_(self.large_cls_token, std=0.02)
nn.init.trunc_normal_(self.small_pos_embed, std=0.02)
nn.init.trunc_normal_(self.large_pos_embed, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
"""
前向传播
参数:
x (torch.Tensor): 输入图像,形状为(B, C, H, W)
返回:
torch.Tensor: 分类logits,形状为(B, num_classes)
"""
B = x.shape[0]
# 小分支前向传播
small_patch_embeddings = self.small_patch_embed(x) # (B, n_patches, small_embed_dim)
small_cls_tokens = self.small_cls_token.expand(B, -1, -1) # (B, 1, small_embed_dim)
small_embeddings = torch.cat([small_cls_tokens, small_patch_embeddings], dim=1) # (B, n_patches+1, small_embed_dim)
small_embeddings = small_embeddings + self.small_pos_embed
small_embeddings = self.pos_dropout(small_embeddings)
# 大分支前向传播
large_patch_embeddings = self.large_patch_embed(x) # (B, n_patches, large_embed_dim)
large_cls_tokens = self.large_cls_token.expand(B, -1, -1) # (B, 1, large_embed_dim)
large_embeddings = torch.cat([large_cls_tokens, large_patch_embeddings], dim=1) # (B, n_patches+1, large_embed_dim)
large_embeddings = large_embeddings + self.large_pos_embed
large_embeddings = self.pos_dropout(large_embeddings)
# 分别通过各自的Transformer编码器
for blk in self.small_blocks:
small_embeddings = blk(small_embeddings)
for blk in self.large_blocks:
large_embeddings = blk(large_embeddings)
# 交叉注意力
for small_cross_attn, large_cross_attn in self.cross_blocks:
# 小分支到大分支的交叉注意力
small_cls = small_embeddings[:, 0:1, :] # 只取CLS token
large_cls = large_embeddings[:, 0:1, :]
# 交叉注意力
small_cls = small_cls + small_cross_attn(small_cls, large_embeddings)
large_cls = large_cls + large_cross_attn(large_cls, small_embeddings)
# 更新CLS token
small_embeddings = torch.cat([small_cls, small_embeddings[:, 1:, :]], dim=1)
large_embeddings = torch.cat([large_cls, large_embeddings[:, 1:, :]], dim=1)
# 归一化
small_embeddings = self.norm_small(small_embeddings)
large_embeddings = self.norm_large(large_embeddings)
# 提取CLS token
small_cls = small_embeddings[:, 0]
large_cls = large_embeddings[:, 0]
# 拼接两个分支的CLS token作为最终特征
combined_cls = torch.cat([small_cls, large_cls], dim=1)
# 分类头
logits = self.head(combined_cls)
return logits3.3 模型训练
(1) 定义模型训练和评估函数:
python
from matplotlib import pyplot as plt
def train_model(model, train_loader, test_loader, criterion, optimizer, num_epochs=10, device='cuda'):
model = model.to(device)
best_acc = 0.0
history = {'train_loss': [], 'train_acc': [], 'test_loss': [], 'test_acc': []}
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
# 训练阶段
pbar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs} [Training]')
for images, labels in pbar:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计信息
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
pbar.set_postfix({'loss': running_loss/(pbar.n+1), 'acc': 100.*correct/total})
train_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
# 测试阶段
test_loss, test_acc = evaluate_model(model, test_loader, criterion, device)
# 打印结果
print(f'Epoch {epoch+1}/{num_epochs}: '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | '
f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')
history['train_acc'].append(train_acc)
history['train_loss'].append(train_loss)
history['test_acc'].append(test_acc)
history['test_loss'].append(test_loss)
# 保存最佳模型
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), 'best_crossvit.pth')
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['test_loss'], label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['test_acc'], label='Test Acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()
print(f'Training complete. Best test accuracy: {best_acc:.2f}%')
def evaluate_model(model, test_loader, criterion, device='cuda'):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 统计信息
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_loss = running_loss / len(test_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy(2) 初始化模型、损失函数和优化器:
python
num_classes = len(train_dataset.classes)
model = CrossViT(
img_size=224,
in_channels=3,
num_classes=num_classes,
small_patch_size=8,
small_embed_dim=192,
small_depth=4,
small_num_heads=6,
large_patch_size=16,
large_embed_dim=384,
large_depth=4,
large_num_heads=12,
cross_depth=2,
dropout=0.1
)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=0.01)(4) 训练模型:
python
device = 'cuda' if torch.cuda.is_available() else 'cpu'
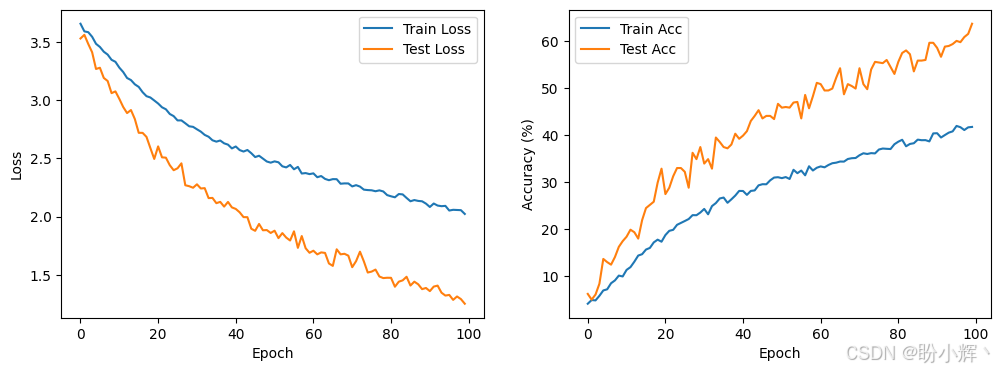
train_model(model, train_loader, test_loader, criterion, optimizer, num_epochs=100, device=device)模型训练过程,损失和模型性能变化情况如下所示:
相关链接
视觉Transformer实战 | Transformer详解与实现
视觉Transformer实战 | Vision Transformer(ViT)详解与实现
视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现
视觉Transformer实战 | Pooling-based Vision Transformer(PiT)详解与实现
视觉Transformer实战 | Data-efficient image Transformer(DeiT)详解与实现