从单体智能到群体智慧:多智能体框架 AutoGen, MetaGPT, ChatDev 原理解析
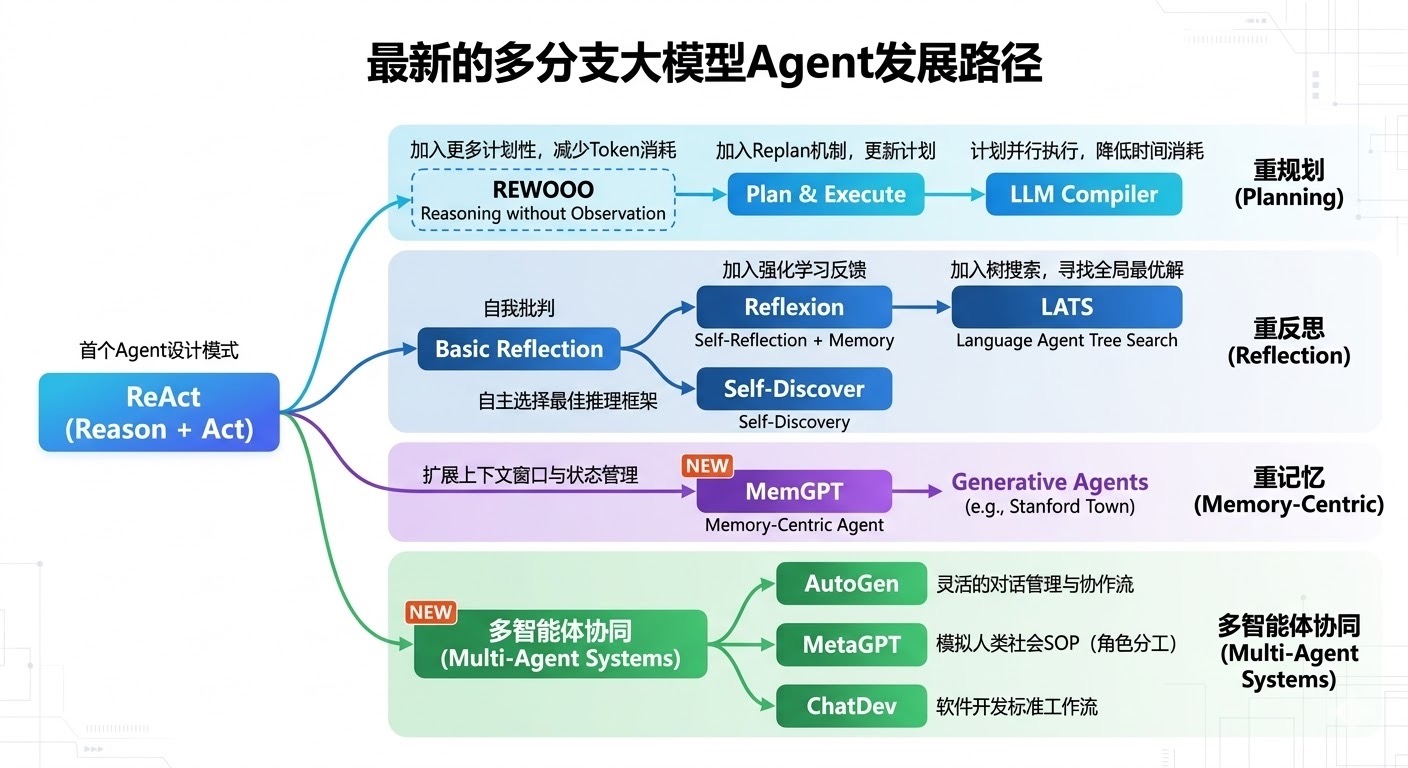
在LLM时代的早期,我们见证了AutoGPT、BabyAGI等单体Agent 的爆发。单体Agent通过"思考-行动-观察"(如ReAct框架)的范式,确实展现了惊人的自动化潜力。然而,大厂在实际落地工业级应用时发现,单体Agent面临着 上下文遗忘、长期规划能力弱、容易陷入死循环(幻觉叠加) 等致命问题。
为了解决这些痛点,学术界和工业界逐渐将目光转向了多智能体系统(Multi-Agent Systems, MAS)。其核心思想来源于人类社会的"分工协作"------通过让多个具有特定System Prompt(角色设定)的Agent相互交互、辩论或协作,来降低单一模型的任务复杂度,利用交叉验证减少幻觉。
本文将深入解析多智能体领域最具代表性的三大框架:AutoGen、MetaGPT、ChatDev。
一、 AutoGen:灵活的对话驱动型多智能体拓扑
1.1 发展来龙去脉
微软提出AutoGen的初衷,是为了解决Agent之间的交互拓扑结构僵化 的问题。在它出现之前,很多多智能体系统都是硬编码(Hard-code)的流水线。AutoGen提出了一种以 对话(Conversation) 为一等公民的编程范式,使得Agent之间可以自由组网(P2P、层级、群聊)。
1.2 底层原理解析
AutoGen的底层核心基类是 ConversableAgent。所有Agent(包括代表人类的 UserProxyAgent 和大模型驱动的 AssistantAgent)都继承自这个类。
核心机制:消息传递(Message Passing)
AutoGen的状态机完全由消息流驱动。其生成响应的数学表达可以抽象为:
Rt+1=LLM(SystemPrompt,M≤t,Ctask)R_{t+1} = \text{LLM}(\text{SystemPrompt}, \mathcal{M}{\le t}, C{task})Rt+1=LLM(SystemPrompt,M≤t,Ctask)
其中 M≤t={m1,m2,...,mt}\mathcal{M}{\le t} = \{m_1, m_2, ..., m_t\}M≤t={m1,m2,...,mt} 表示直到 ttt 时刻的对话历史,CtaskC{task}Ctask 是当前任务上下文。
群聊管理器(GroupChatManager)
当存在超过两个Agent时,AutoGen 引入了 GroupChatManager。在底层,Manager本身也是一个Agent,它通过一个调度算法(可以是LLM决策、轮询或随机)来决定下一个发言者(Speaker Selection):
Next_Speaker=Select(A,M,Rules)\text{Next\_Speaker} = \text{Select}(\mathcal{A}, \mathcal{M}, \text{Rules})Next_Speaker=Select(A,M,Rules)
其中 A\mathcal{A}A 是候选Agent集合。思考:LLM作为调度器的不稳定性问题怎么解决?
1.3 适用场景与优缺点
- 适用场景:需要频繁人机交互、动态角色调整、开放性辩论的任务(如代码编写与测试验证对弈)。
- 优点 :高度灵活,
UserProxyAgent使得"人类在环(Human-in-the-loop)"变得异常简单。支持无缝的代码执行环境集成。 - 缺点:缺乏严格的业务流程控制(SOP),在群聊模式下极易发散,导致Token消耗剧增且无法收敛。
1.4 🚀 常见疑难杂症
- Q: AutoGen中多Agent群聊时,如何防止"发散"和"死循环"?
- 底层剖析 :AutoGen默认的
autospeaker selection 依赖LLM的Next token prediction来决定下一个发言人,这在复杂任务中极易产生幻觉,导致两个Agent互相恭维或陷入重复报错的死循环。 - 解决方案 :(1) 引入基于状态机(FSM)的严格路由转移图(Transition Graph),限制Agent的发话流向;(2) 在Manager中注入特定的Critic Agent,一旦检测到循环相似度超过阈值(如通过TF-IDF或Embedding相似度),立即触发打断(Interrupt)机制;(3) 设置严格的
max_consecutive_auto_reply。
二、 MetaGPT:引入标准化作业程序(SOP)的流水线架构
2.1 发展来龙去脉
如果说AutoGen像是一个"自由讨论的会议室",那么2023年深度赋智(DeepWisdom)开源的MetaGPT就是一个"等级森严、纪律严明的现代企业"。单靠自由对话在解决严谨的软件工程落地时往往会失败。MetaGPT的提出,就是为了将人类社会成熟的 SOP(Standard Operating Procedure) 机制注入到多智能体系统中。
2.2 底层原理解析
MetaGPT 架构的底层核心可以用两个词概括:Role(角色) 和 Environment(环境)。
SOP与动作空间(Action Space)
在MetaGPT中,每个角色不再只是一个简单的Prompt,而是绑定了一组具体的动作(Action)。角色的运行逻辑遵循:
Statet+1,Actiont+1=Role.think(Environment.Memory),Role.act()\text{State}{t+1}, \text{Action}{t+1} = \text{Role.think}(\text{Environment.Memory}), \text{Role.act}()Statet+1,Actiont+1=Role.think(Environment.Memory),Role.act()
这里的 think 阶段通常不是直接生成文本,而是选择下一个要执行的原子Action。
共享消息池与发布-订阅机制(Pub-Sub)
这是MetaGPT最精华的底层设计。与AutoGen的点对点直接发送消息不同,MetaGPT引入了全局的 Environment。
- 发布:Agent完成动作后,将结构化产物(如需求文档、代码、PRD)以Message形式发布到环境中的共享内存。
- 订阅 :每个Agent只监听(Subscribe)与自己当前状态相关的特定类型消息(例如,测试工程师Agent只订阅开发工程师Agent发布的
Code类型消息,而忽略产品经理的PRD)。
通过这种方式,信息的信噪比被极大提高:
Magent_i={m∈Env.Memory∣m.type∈Subscriptionsi}\mathcal{M}_{agent\_i} = \{ m \in \text{Env.Memory} \mid \text{m.type} \in \text{Subscriptions}_i \}Magent_i={m∈Env.Memory∣m.type∈Subscriptionsi}
2.3 适用场景与优缺点
- 适用场景:软件开发、研报生成、长链路数据分析等具有明确阶段和交付物的瀑布流型任务。
- 优点:稳定性极高,通过SOP和强制的结构化输出(JSON/Markdown),极大缓解了Agent的幻觉问题。长上下文管理优秀。
- 缺点:不够灵活。如果要将其应用于一个新的行业(如医疗诊断),必须人工重写一整套SOP和Action。
2.4 🚀 常见疑难杂症
- Q: MetaGPT 的全局共享内存(Shared Memory)在长时间运行后会导致Context Window溢出,如何解决?
- 底层剖析:虽然订阅机制减少了无关消息,但随着任务推进,相关消息(如长代码文件)依然会撑爆上下文。
- 解决方案 :(1) 长期/短期记忆分层 :将早期阶段的交付物(如PRD)利用Vector DB(如Milvus、Faiss)进行向量化存储,仅在当前Action需要时通过RAG检索;(2) 状态压缩(Context Summarization):引入一个专门的Summary Agent,当历史Message长度达到阈值时,对旧消息进行摘要降维;(3) 仅传递指针/文件路径,而非文件全量文本。
三、 ChatDev:基于沟通链(ChatChain)的软件作坊
3.1 发展来龙去脉
ChatDev由清华大学团队提出,它的核心思想是将软件开发生命周期(瀑布模型)直接映射为多智能体的对话链。它与MetaGPT有相似之处(都关注软件开发),但侧重点不同:MetaGPT强调SOP和发布/订阅,而ChatDev更强调阶段性的微观对话和确认机制。
3.2 底层原理解析
ChatDev的核心架构是 ChatChain(沟通链),这是一个基于状态机(Finite State Machine)的配置图。
阶段(Phase)与原子对话(Atomic Chat)
整个开发过程被拆解为设计、编码、测试、文档四个主阶段(Phase)。每个Phase又由多个原子对话(Atomic Chat)组成。
例如在"编码"阶段,存在一个"Coding"的原子对话,由程序员和CTO参与。其底层是通过轮流Prompting实现的:
Instructioncoder=SystemPromptcoder+History+Task\text{Instruction}{coder} = \text{SystemPrompt}{coder} + \text{History} + \text{Task}Instructioncoder=SystemPromptcoder+History+Task
FeedbackCTO=Critic(Codegenerated)\text{Feedback}{CTO} = \text{Critic}(\text{Code}{generated})FeedbackCTO=Critic(Codegenerated)
思维反刍(Thought Fallback / Self-Reflection)
ChatDev在每个Phase结束时,经常会加入一个内部反馈机制,利用LLM自我反思:
Quality_Score=Evaluator(Artifact)\text{Quality\_Score} = \text{Evaluator}(\text{Artifact})Quality_Score=Evaluator(Artifact). 如果分数不达标,状态机回滚,要求重新对话。
3.3 适用场景与优缺点
- 适用场景:轻量级软件原型生成、游戏Demo开发、学习展示。
- 优点 :配置非常直观,修改
ChatChainConfig.json即可定义新的工作流。其微观的"两人对辩"模式在纠错方面有一定奇效。 - 缺点:过度依赖LLM的自身能力,且缺乏像MetaGPT那样细粒度的基于AST(抽象语法树)等外部工具的硬性规则校验,往往只能产出玩具级别的代码(Toy level)。
3.4 🚀 常见疑难杂症
- Q: ChatDev中的角色容易在对话中忘记自己是"专家",出现复读机现象(如程序员复读产品经理的话),如何从底层机制上解决?
- 底层剖析:这是典型的"角色漂移(Role Drift)"问题。因为在多轮Transformer的注意力机制计算中,System Prompt的注意力权重随着Context变长而被稀释(Attention Dilution)。
- 解决方案 :(1) 系统提示词强化(System Prompt Reinforcement) :在每一次输入给LLM的最后一句(即User Prompt)强制拼接当前角色的核心指令("Remember you are a Senior Coder...");(2) 约束解码(Constrained Decoding):利用如Guidance或Outlines等库,限制模型输出的语法树格式,切断其寒暄或复读的可能;(3) 设计独立的评审者(Reviewer),通过评分制过滤无效回复。
四、 核心对比总结
| 维度 | AutoGen (微软) | MetaGPT (开源社区/深度赋智) | ChatDev (清华) | 知识点 |
|---|---|---|---|---|
| 拓扑结构 | 动态图、群聊 (Dynamic Graph) | 严格流水线 (SOP Pipeline) | 链式状态机 (ChatChain) | 针对不同业务线(客服 vs 研发),你会选哪个? |
| 消息路由 | LLM自身决策 (基于Manager) | 全局环境、发布-订阅 (Pub/Sub) | 硬编码的流程图配置文件 | 面对高并发任务,谁的Token利用率最高?(答: MetaGPT) |
| 抗幻觉能力 | 较弱(易发散) | 极强(SOP+结构化强制要求) | 中等(靠双人对辩) | 如何设计多Agent的共识机制(Consensus)? |
| 核心创新点 | 统一的对话范式,人类在环 | 环境抽象,角色的动作空间 | 微观两人结对编程,瀑布模型映射 | 你能手写一个简易的Pub-Sub消息分发中心吗? |
🚀 总结
多Agent绝不是Agent数量越多越好(边际效用递减,且错误率根据乘法原理 Psuccess=p1×p2⋯×pnP_{success} = p_1 \times p_2 \dots \times p_nPsuccess=p1×p2⋯×pn 会急剧下降)。
能用传统代码逻辑(如Python的if-else、正则表达式、AST解析)解决的步骤,坚决不用LLM的Agent去生成;Agent只应该被部署在需要泛化和模糊决策的节点上。 这叫做 Neuro-Symbolic(神经符号) 结合的多智能体架构!
如果以LLM问答消耗作为基线1,那么Agent与多- Agent的token消耗量大约是4倍与10-15倍,而多智能体大量的token被浪费在不同智能体之间的协调同步上了!
牢记多智能体三用三不用场景 :
该用场景:1. 上下文污染时用独立子Agent隔离;2. 任务可并行探索时用多Agent分发;3. 管理20+工具时按领域拆分专业化Agent。不该用:1. 多数编码任务;2. 简单查询等低价值任务;3. 拟人化角色分工。