Dropout 层是深度学习、神经网络和人工智能模型训练中非常常见的一种正则化层。它用来描述一种在训练过程中随机"关闭"部分神经元输出的技术。换句话说,Dropout 层是在回答:模型训练时,怎样避免过度依赖某些神经元,从而降低过拟合风险。
如果说全连接层、卷积层主要负责学习特征,归一化层主要负责稳定特征分布,那么 Dropout 层更强调"打破依赖"和"增强泛化"。它不会直接提取新特征,而是在训练阶段随机丢弃部分神经元输出,迫使模型不能只依赖少数特征路径,而要学习更加稳健的表示。
因此,Dropout 层常用于多层感知机、卷积神经网络、循环神经网络、Transformer 和各种深度学习模型中,是理解神经网络正则化和防止过拟合的重要基础。
一、基本概念:什么是 Dropout 层
Dropout 层是一种在训练阶段随机将部分神经元输出置为 0 的正则化方法。
假设某一层的输出向量为:
Dropout 会随机生成一个掩码向量:
其中每个 mᵢ 只可能取 0 或 1。
• mᵢ = 1 表示保留第 i 个神经元输出
• mᵢ = 0 表示丢弃第 i 个神经元输出
经过 Dropout 后,输出可以写为:
其中:
• h 表示原始隐藏层输出
• m 表示随机生成的 Dropout 掩码
• ⊙ 表示逐元素相乘
• h̃ 表示经过 Dropout 后的输出
从通俗角度看,Dropout 就像在训练时随机让一部分神经元"暂时休息"。每次训练时,被关闭的神经元都可能不同,因此模型不能总是依赖固定的几个神经元完成任务。
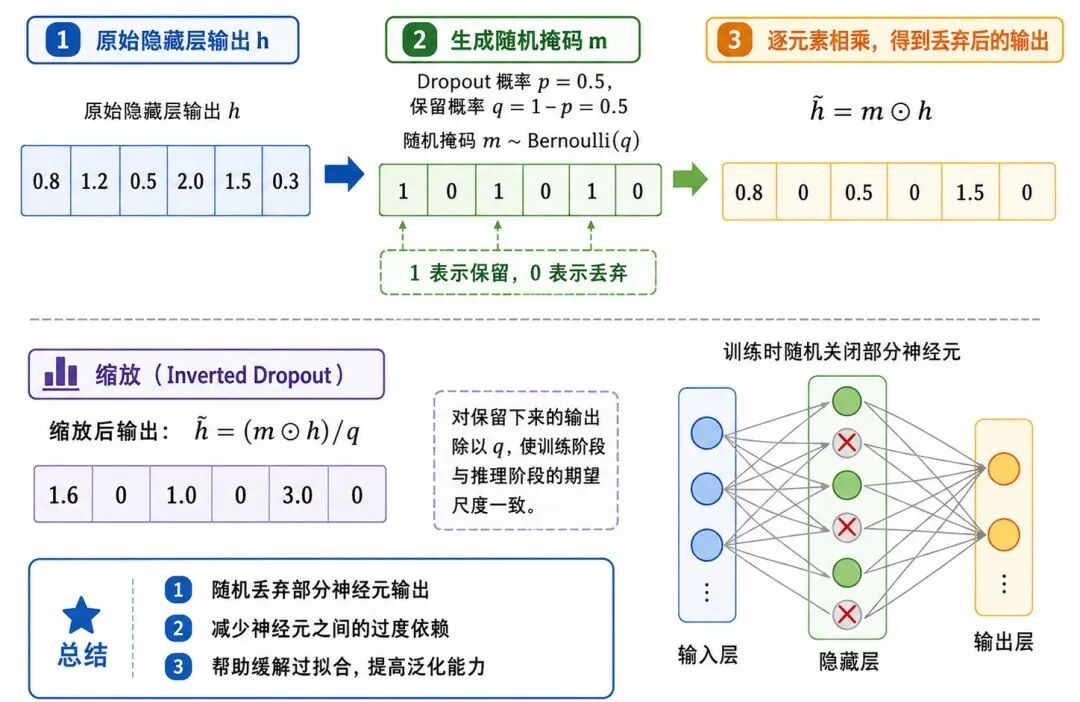
图 1:Dropout 层的随机丢弃机制
例如,原本某一层输出为:
cs
[0.8, 1.2, 0.5, 2.0]如果 Dropout 随机关闭第 2 和第 4 个位置,输出就可能变成:
cs
[0.8, 0, 0.5, 0]这样做的目的不是破坏模型,而是让模型学会在部分信息缺失的情况下仍然完成任务。
二、为什么需要 Dropout 层
Dropout 层之所以重要,是因为深度神经网络很容易出现过拟合。
所谓过拟合,是指模型在训练集上表现很好,但在新数据上表现较差。它往往说明模型没有学到真正稳定的一般规律,而是记住了训练数据中的细节、噪声或偶然模式。
在神经网络中,过拟合可能来自:
• 参数数量过多
• 训练数据不足
• 模型结构过于复杂
• 某些神经元之间形成过强依赖
• 训练轮数过多
Dropout 的作用,就是在训练过程中人为制造一定随机性,打破神经元之间过强的协同依赖。
从通俗角度看:如果每次训练都让所有神经元一起工作,模型可能会形成固定套路;如果每次随机关闭一部分神经元,模型就必须学会更灵活、更稳健的判断方式。
例如,在图像分类中,如果模型过度依赖某个局部纹理判断类别,一旦新图片中这个纹理稍有变化,模型就可能出错。Dropout 会迫使模型不能只依赖单一线索,而要综合更多特征。
因此,Dropout 是一种典型的正则化方法。它的核心目标是:
• 降低过拟合风险
• 提高模型泛化能力
• 减少神经元之间的过度依赖
• 让模型学习更加稳健的特征表示
三、Dropout 层的核心计算过程
Dropout 的核心计算可以分成三步:
生成随机掩码 → 丢弃部分输出 → 调整输出尺度
1、生成随机掩码
设 Dropout 概率为 p,表示每个神经元输出被丢弃的概率。
那么保留概率为:
其中:
• p 表示丢弃概率
• q 表示保留概率
对每个神经元,Dropout 会随机决定是否保留:
其中:
• mᵢ 表示第 i 个位置的随机掩码
• Bernoulli(q) 表示以概率 q 取 1、以概率 1 − q 取 0 的伯努利分布
2、丢弃部分输出
生成掩码后,Dropout 会进行逐元素相乘:
如果 mᵢ = 1,则 hᵢ 被保留;如果 mᵢ = 0,则 hᵢ 被置为 0。
从通俗角度看:这一步就是随机关闭一部分神经元输出。
3、调整输出尺度
如果直接丢弃一部分神经元,输出整体数值会变小。
例如,如果 p = 0.5,平均只有一半神经元被保留,那么输出总强度大致也会下降一半。
为了保持训练和推理时的数值尺度一致,现代框架通常使用 inverted dropout,也就是在训练时对保留下来的输出除以 q:
其中 q = 1 − p。
这样做的好处是:训练阶段已经完成尺度调整,推理阶段就不需要再额外缩放。
从通俗角度看:Dropout 不只是"随机清零",还会把保留下来的信号适当放大,使整体输出规模保持稳定。
四、训练阶段与推理阶段的区别
Dropout 有一个非常重要的特点:训练阶段和推理阶段行为不同。
1、训练阶段
训练时,Dropout 会随机丢弃部分神经元输出。
例如,某一层有 100 个神经元,如果 Dropout 概率 p = 0.5,那么每次训练大约会随机关闭 50 个神经元。
但需要注意:每次前向传播被关闭的神经元通常都不同。
从通俗角度看:训练阶段的 Dropout 像是在不断制造不同的"临时子网络"。模型每次都不能依赖完整网络,而要在随机缺失部分神经元的情况下完成预测。
这种机制可以降低模型对某些固定神经元组合的依赖。
2、推理阶段
推理阶段通常不再使用随机丢弃。
也就是说,模型在预测新样本时,会使用完整网络。
在 PyTorch 中,如果模型处于训练模式:
go
model.train()Dropout 会生效。
如果模型处于推理模式:
javascript
model.eval()Dropout 会关闭随机丢弃行为。
这一点非常重要。
如果推理时忘记调用 model.eval(),模型每次预测都可能随机关闭不同神经元,导致输出不稳定。
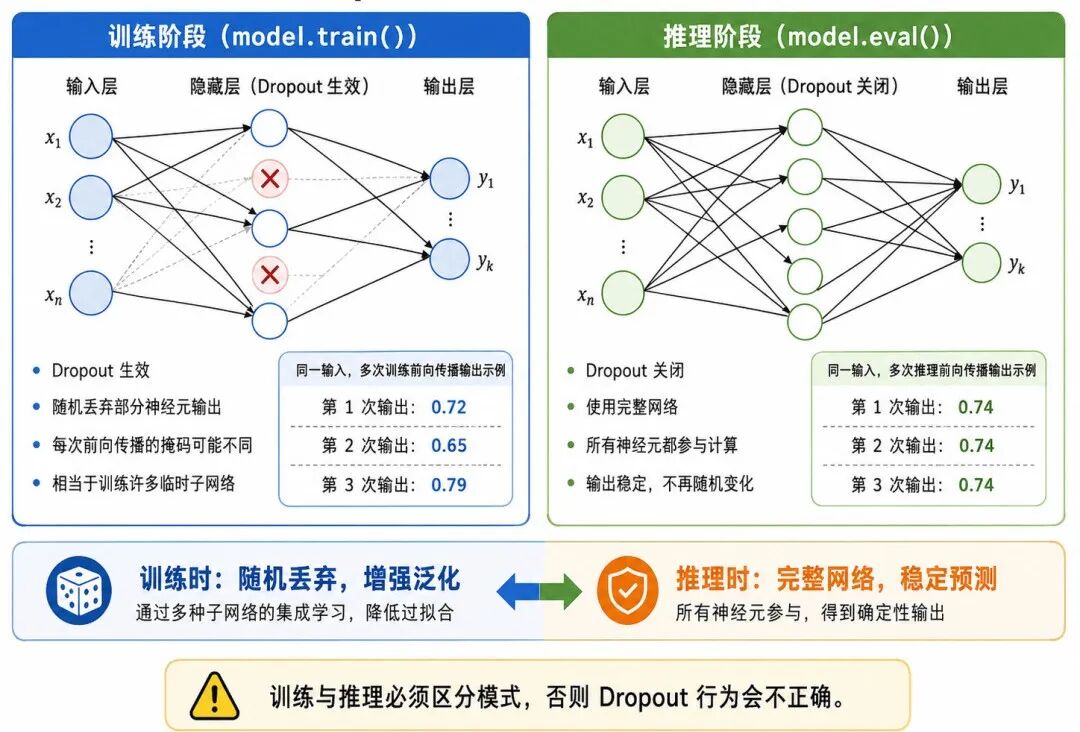
图 2:Dropout 层在训练阶段与推理阶段的区别
从通俗角度看:
• 训练时:随机关闭部分神经元,增强鲁棒性
• 推理时:使用完整网络,得到稳定预测结果
五、Dropout 为什么能缓解过拟合
Dropout 能缓解过拟合,主要有三个原因。
1、减少神经元之间的过度依赖
在没有 Dropout 的情况下,某些神经元可能会形成固定组合。
例如,一个神经元总是假设另一个神经元已经检测到了某个特征,于是自己只负责补充一小部分信息。
这种强依赖在训练集上可能有效,但面对新数据时可能不稳定。
Dropout 会随机关闭部分神经元,使这种固定依赖关系被打破。
从通俗角度看:Dropout 迫使每个神经元不能总是依赖"队友",而要学习更有独立价值的特征。
2、相当于训练多个子网络
每次使用 Dropout 时,网络中被保留的神经元组合都不同。
因此,同一个大网络在训练时会产生许多不同的子网络。
从直观上看,这有点像同时训练许多不同结构的模型,然后在推理时使用完整网络进行综合。
这种思想与集成学习有相似之处。
从通俗角度看:Dropout 让模型在训练过程中见过许多"缺胳膊少腿"的版本,因此完整模型在推理时往往更加稳健。
3、引入训练噪声,提高泛化能力
Dropout 在隐藏表示中引入随机噪声。
适度噪声可以让模型不容易记住训练集中的偶然细节,而更倾向于学习稳定模式。
这类似于数据增强、权重衰减等正则化思想:通过限制或扰动模型,让它不要过度适应训练集。
不过,Dropout 不是越强越好。
如果丢弃概率过大,模型每次训练时可用信息太少,可能导致欠拟合或收敛困难。
六、Dropout 层在网络中的常见位置
Dropout 可以放在不同网络结构中,但不同位置的使用方式有所不同。
1、多层感知机中的 Dropout
在多层感知机中,Dropout 常放在隐藏层之后:
全连接层 → 激活函数 → Dropout → 下一层
例如:
Linear → ReLU → Dropout → Linear
从通俗角度看:先让隐藏层产生特征表示,再随机丢弃一部分表示,迫使后续层不能过度依赖某些固定特征。
Dropout 在全连接网络中非常常见,因为全连接层参数较多,容易过拟合。
2、卷积神经网络中的 Dropout
在卷积神经网络中,Dropout 可以用于卷积层之后,也可以用于全连接分类头中。
早期 CNN 中,Dropout 常用于靠近输出端的全连接层,例如:
卷积特征 → 展平 → 全连接层 → Dropout → 输出层
这是因为 CNN 前面的卷积层已经通过局部连接和参数共享降低了参数量,而后面的全连接层更容易过拟合。
此外,也有专门用于特征图的 Dropout 变体,例如 Spatial Dropout。它不是随机丢弃单个元素,而是可能按通道丢弃整张特征图的一部分。
3、Transformer 中的 Dropout
在 Transformer 中,Dropout 通常出现在多个位置,例如:
• 注意力权重之后
• 前馈网络中
• 残差连接附近
• embedding 表示之后
从通俗角度看:Transformer 参数多、表达能力强,适当使用 Dropout 可以减少过拟合,尤其是在数据规模相对有限时。
不过,在大规模预训练模型中,Dropout 的使用方式会因模型规模、数据量和训练策略而变化。
七、Dropout 概率如何选择
Dropout 概率 p 是一个重要超参数。
它表示神经元输出被丢弃的概率。
常见经验是:
• p = 0.1:轻度 Dropout
• p = 0.2~0.3:中等 Dropout
• p = 0.5:较强 Dropout,早期全连接网络中较常见
但这些只是经验值,不是固定规则。
如果 p 太小,正则化效果可能不明显。
如果 p 太大,模型可用信息过少,可能出现欠拟合。
从通俗角度看:Dropout 概率越大,训练时"关掉"的神经元越多,模型受到的约束越强。
选择 Dropout 概率时,需要结合:
• 数据规模
• 模型大小
• 过拟合程度
• 训练集与验证集差距
• 网络结构
• 其他正则化方法
例如:
• 如果训练集准确率很高,但验证集准确率明显较低,可以适当增大 Dropout
• 如果训练集和验证集表现都不好,说明模型可能欠拟合,此时继续增大 Dropout 可能会更糟
• 如果模型已经使用较强的数据增强和权重衰减,Dropout 不一定需要很大
从实践角度看,Dropout 应该通过验证集表现来调整,而不是机械设置。
八、Dropout 的优势、局限与使用注意事项
1、Dropout 的主要优势
Dropout 最大的优势是降低过拟合风险。
它通过随机丢弃神经元输出,减少模型对局部特征路径的过度依赖。
其次,Dropout 实现简单,使用方便。
在深度学习框架中,只需要添加一层 Dropout,就可以在训练阶段自动生效,在推理阶段自动关闭。
再次,Dropout 具有较好的通用性。
它可以用于全连接网络、CNN、RNN、Transformer 等多种结构中。
从通俗角度看,Dropout 的优势在于:它让模型在训练时不能总是依赖完整信息,从而学习更加稳健的特征。
2、Dropout 的主要局限
Dropout 也有局限。
首先,它可能降低训练速度。
由于每次训练只使用部分神经元,模型可能需要更多迭代才能收敛。
其次,Dropout 概率过大可能导致欠拟合。
如果丢弃太多信息,模型会变得难以学习有效规律。
再次,Dropout 不一定适合所有位置。
例如,在某些卷积层、归一化层附近或大规模预训练模型中,Dropout 的效果可能需要具体实验判断。
此外,Dropout 不能替代数据质量、合理模型结构和适当训练策略。
它只是正则化工具之一,而不是解决过拟合的唯一方法。
3、使用 Dropout 时需要注意的问题
使用 Dropout 时,需要注意:
• Dropout 主要在训练阶段生效
• 推理阶段应切换到 model.eval()
• Dropout 概率 p 不是越大越好
• 全连接层中常见 Dropout,卷积层中要谨慎选择位置
• 已使用强数据增强或强权重衰减时,Dropout 可适当减小
• 如果模型欠拟合,不应盲目增加 Dropout
• Dropout 会引入随机性,训练结果可能略有波动
• 在 PyTorch 中,nn.Dropout(p) 中的 p 表示丢弃概率,不是保留概率
最后一点尤其容易混淆。
例如:
apache
nn.Dropout(p=0.5)表示训练时每个元素有 50% 的概率被置为 0,而不是 50% 的概率被保留。
九、Python 示例
下面给出几个简单示例,用来帮助理解 Dropout 层的基本使用。
示例 1:观察 Dropout 的随机丢弃效果
apache
import torchimport torch.nn as nn
# 固定随机种子,方便观察结果torch.manual_seed(0)
# 构造一个简单输入:10个1x = torch.ones(10)
# p=0.5 表示每个元素有50%的概率被置为0(保留比例1-p=0.5)dropout = nn.Dropout(p=0.5)
# 训练模式下,Dropout随机置零,并缩放保留元素(除以保留概率)dropout.train()y_train = dropout(x)
# 推理模式下,Dropout不生效,输出等于输入dropout.eval()y_eval = dropout(x)
print("原始输入:", x)print("训练模式输出:", y_train) # 约一半元素为0,其余为2.0(1/0.5)print("推理模式输出:", y_eval) # 全为1.0这个例子中:
• 训练模式下,部分元素会被随机置为 0
• 保留下来的元素会被放大,以保持期望尺度稳定
• 推理模式下,Dropout 不再随机丢弃,输出与输入一致
从通俗角度看:训练时 Dropout 会制造随机缺失;推理时模型使用完整信息。
示例 2:在多层感知机中使用 Dropout
python
import torchimport torch.nn as nn
# 构建一个带Dropout的前馈网络(输入20维,输出2类logits)model = nn.Sequential( nn.Linear(20, 64), # 全连接层:20→64 nn.ReLU(), # ReLU激活 nn.Dropout(p=0.5), # 随机丢弃50%的神经元(仅训练时) nn.Linear(64, 32), # 全连接层:64→32 nn.ReLU(), nn.Dropout(p=0.3), # 随机丢弃30%的神经元 nn.Linear(32, 2) # 输出层:32→2(类别logits))
# 一批输入:8个样本,每个20个特征x = torch.randn(8, 20)
# 训练模式:Dropout生效,随机失活并缩放model.train()logits_train = model(x)
# 推理模式:Dropout关闭,所有神经元均参与计算model.eval()logits_eval = model(x)
print("训练模式输出形状:", logits_train.shape) # (8,2)print("推理模式输出形状:", logits_eval.shape) # (8,2)这个例子中:
• nn.Dropout(p=0.5) 表示丢弃概率为 0.5
• Dropout 放在 ReLU 之后,用于随机丢弃隐藏表示
• 训练模式和推理模式都会输出 8 × 2 的 logits
• 但训练模式下的中间计算包含随机丢弃
从结构上看,Dropout 常作为隐藏层之后的正则化模块。
示例 3:比较 Dropout 在训练模式和推理模式下的差异
python
import torchimport torch.nn as nn
torch.manual_seed(42) # 固定随机种子,使结果可复现
dropout = nn.Dropout(p=0.5) # Dropout层,丢弃概率50%x = torch.ones(5) # 输入:全1向量
# 训练模式:每次前向传播随机置零不同元素,并缩放保留元素dropout.train()print("训练模式第 1 次:", dropout(x))print("训练模式第 2 次:", dropout(x))print("训练模式第 3 次:", dropout(x))
# 推理模式:Dropout关闭,输出等于输入dropout.eval()print("推理模式第 1 次:", dropout(x))print("推理模式第 2 次:", dropout(x))print("推理模式第 3 次:", dropout(x))这个例子可以看到:
• 训练模式下,每次 Dropout 的随机掩码可能不同
• 推理模式下,Dropout 不再随机丢弃
• 因此推理时必须切换到 eval() 模式
这也是 Dropout 和 BatchNorm 一样,需要区分训练模式与推理模式的重要原因。
示例 4:在 CNN 分类头中使用 Dropout
python
import torchimport torch.nn as nn
# CNN模型,在全连接部分加入Dropout防止过拟合class SimpleCNNWithDropout(nn.Module): def __init__(self): super().__init__()
# 卷积特征提取:两层卷积+池化 self.features = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, padding=1), # 3→16通道 nn.ReLU(), nn.MaxPool2d(kernel_size=2), # 32→16
nn.Conv2d(16, 32, kernel_size=3, padding=1), # 16→32通道 nn.ReLU(), nn.MaxPool2d(kernel_size=2) # 16→8 )
# 分类器:展平 → 全连接 → ReLU → Dropout → 输出10类 self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(32 * 8 * 8, 128), nn.ReLU(), nn.Dropout(p=0.5), # 随机丢弃50%神经元 nn.Linear(128, 10) # 输出10类logits )
def forward(self, x): x = self.features(x) x = self.classifier(x) return x
model = SimpleCNNWithDropout()
# 一批8张32x32的RGB图像x = torch.randn(8, 3, 32, 32)
logits = model(x)
print("输出 logits 形状:", logits.shape) # (8,10)这个例子中:
• 卷积层负责提取图像局部特征
• 全连接分类头负责综合特征并输出 logits
• Dropout 放在分类头中,用于降低过拟合风险
输出形状为 8 × 10,表示 8 个样本,每个样本对应 10 个类别的原始分数。
📘 小结
Dropout 层是一种用于缓解过拟合的正则化层。它在训练阶段随机将部分神经元输出置为 0,迫使模型减少对固定神经元组合的依赖,从而学习更稳健的特征。推理阶段 Dropout 通常关闭,模型使用完整网络进行预测。对初学者而言,可以把 Dropout 理解为:训练时随机让部分神经元"休息",让模型不要死记训练集,而是学会更可靠的判断方式。

"点赞有美意,赞赏是鼓励"