
一,transformer接口调用
python
from transformers import AutoModel, AutoTokenizer
import torch
mllm_path = "your/path/to/InternVL2-2B"
device = torch.device('cuda:0')
model = AutoModel.from_pretrained(
mllm_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
).eval()
tokenizer = AutoTokenizer.from_pretrained(mllm_path, trust_remote_code=True, use_fast=False)
model = model.to(device)
generation_config = dict(max_new_tokens=1024, do_sample=False)其中generation_config是大模型参数配置,常见的有
|--------------------|------------------------------------------------------------------------------------------------------|
| 参数字段 | 含义 |
| max_new_tokens=512 | 最多生成多少 新 token |
| min_new_tokens=10 | 至少生成多少 token 才允许停止。 |
| do_sample=True | 决定是否随机采样 token。 False的时候每次选取概率最大 token True的时候每次按概率分布随机采样,导致每次结果不一样 |
| temperature=0.7 | 控制概率分布平滑度 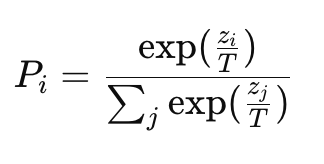 小 → 更确定,大 → 更随机 |
小 → 更确定,大 → 更随机 |
| output_scores=True | 返回每一步 token 概率。 |
视觉侧导入视频:
python
pixel_values, num_patches_list = get_pixel_values(vr)
def get_pixel_values(vr, input_size=448, max_num=1):
# 定义函数:从视频读取所有帧并转换为模型输入的像素张量
transform = build_transform(input_size=input_size)
# 构建图像预处理函数(resize、normalize等)
pixel_values_list = [] # 存储每一帧处理后的tensor
num_patches_list = [] # 记录每一帧被切成多少tile(patch)
for i in range(len(vr)): # 遍历视频中的所有帧
img = Image.fromarray(vr[i].asnumpy()).convert('RGB')
# 从video reader取出第i帧,并转成PIL RGB图像
img = dynamic_preprocess( # 对图像进行动态预处理(可能会切成多个tile)
img,
image_size=input_size, # 每个tile最终尺寸
use_thumbnail=True, # 是否使用缩略图
max_num=max_num # 最多切多少个tile
)
# 如果把max_num设为1,就表示不切分,直接resize成input_size
# img是一个list,每个元素是(448,448)的PIL.Image
pixel_values = [transform(tile) for tile in img]
# 对每个tile做transform(tensor化、归一化)
# pixel_values是一个list,每个元素是(3,448,448)的tensor
pixel_values = torch.stack(pixel_values)
# 把tile列表堆叠成tensor:[当前这一帧被切成的 tile 数, 3, 448, 448]
num_patches_list.append(pixel_values.shape[0])
# 记录每个帧被切成多少个tile
pixel_values_list.append(pixel_values)
# 保存当前帧的tile tensor
pixel_values = torch.cat(pixel_values_list)
# 把所有帧的tile拼接:[视频里所有帧被切成的 tile 数, 3, H, W]
return pixel_values, num_patches_list
# 返回所有tile和每帧tile数量预处理图像函数:
python
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
# 使用ImageNet数据集的均值和方差用于归一化
def build_transform(input_size):
# 构建图像预处理流程
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([ # 将多个图像处理操作按顺序组合
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
# 如果图像不是RGB模式,就转换成RGB
T.Resize((input_size, input_size),
interpolation=InterpolationMode.BICUBIC),
# 将图像resize到指定大小,例如448×448,使用双三次插值
T.ToTensor(),
# 将PIL图像转换为PyTorch tensor
# 同时把像素值从 [0,255] 变成 [0,1]
# 输出形状: [3, H, W]
T.Normalize(mean=MEAN, std=STD)
# 使用ImageNet均值和标准差做归一化
# (x - mean) / std
])
return transform # 返回构建好的transform图像切分patch函数:根据图像的长宽比,把一张图动态切成多个 448×448 的块(tiles),供视觉模型输入。因为vit需要固定输入尺寸448*448,但是输入不一定是多大。internvl会自动计算一个合适的切块网格,比如1920*1080 原始比例是16:9,算法找到一个合适的最接近切块网格是3*2,也就是把原图切成3*2共6个448*448的patch,所以需要先resize成1344*896,再切分。
python
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
# 动态预处理图像:按长宽比切分成若干块
orig_width, orig_height = image.size # 读取原始图像的宽和高
aspect_ratio = orig_width / orig_height # 计算原图长宽比
target_ratios = set( # 枚举所有可能的切分网格比例 (i, j)
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
# 只保留块数在[min_num, max_num]之间的网格
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# 按总块数从小到大排序
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
# 根据原图长宽比,选最接近的目标网格比例
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
# 目标总宽度 = 每块尺寸 × 列数
target_height = image_size * target_aspect_ratio[1]
# 目标总高度 = 每块尺寸 × 行数
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# 总块数 = 列数 × 行数
# resize the image
resized_img = image.resize((target_width, target_height))
# 先把整张图resize到目标尺寸
processed_images = [] # 用来保存切分后的所有子图
for i in range(blocks): # 遍历每一个块
box = ( # 计算第i个块对应的裁剪区域 (left, upper, right, lower)
(i % (target_width // image_size)) * image_size,
# 左边界:当前列 × 块宽
(i // (target_width // image_size)) * image_size,
# 上边界:当前行 × 块高
((i % (target_width // image_size)) + 1) * image_size,
# 右边界:左边界 + 块宽
((i // (target_width // image_size)) + 1) * image_size
# 下边界:上边界 + 块高
)
# split the image
split_img = resized_img.crop(box)
# 从resize后的大图中裁出当前子图
processed_images.append(split_img)
# 保存当前子图
assert len(processed_images) == blocks
# 确保切出来的子图数量正确
if use_thumbnail and len(processed_images) != 1:
# 如果启用缩略图,并且当前不止一块
thumbnail_img = image.resize((image_size, image_size))
# 额外生成一张整图缩略图
processed_images.append(thumbnail_img)
# 把缩略图也加入输出
return processed_images # 返回所有切分后的子图(以及可选缩略图)文本侧:
python
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + prompt规定输入几个图片要告诉大模型,输入几帧,就要输入几个Frame1: <image>
最后和prompt拼起来,形如:
python
'Frame1: <image>\nFrame2: <image>\nFrame3:
<image>\nFrame4: <image>\nFrame5: <image>\nFrame6:
<image>\nFrame7: <image>\nFrame8: <image>\nFrame9:
<image>\nFrame10: <image>\nFrame11: <image>\nFrame12:
<image>\nCould you specify the anomaly events present in the video?'视频侧提取出的pixel_values 和文本侧的prompt,配置,一同输入大模型
python
response, history = model.chat(
tokenizer,
pixel_values, question,
generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
二,InternVL内部forward解析
进入chat函数后即进入到internvl的内部。
python
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
verbose=False):
template = get_conv_template(self.template)
# 获取对话模板(例如 system / user / assistant 的格式)
template.system_message = self.system_message
# 设置系统提示词
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep.strip())
# 获取对话分隔符对应的token id,作为生成停止标志
history = [] if history is None else history
# 如果没有历史对话,则初始化为空列表
for (old_question, old_answer) in history:
# 遍历历史对话
template.append_message(template.roles[0], old_question)
# 加入历史用户问题
template.append_message(template.roles[1], old_answer)
# 加入历史模型回答
template.append_message(template.roles[0], question)
# 添加当前用户问题
template.append_message(template.roles[1], None)
# 添加待生成的 assistant 回复占位
query = template.get_prompt()
# 将模板中的对话拼接成完整 prompt
for num_patches in num_patches_list:
# 遍历每张图像(或每一帧)的tile数量
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
# 构造图像token:
# <img> + (IMG_CONTEXT * 每个patch对应token数 * patch数量) + </img>
query = query.replace('<image>', image_tokens, 1)
# 将prompt中的 <image> 占位符替换为真正的图像token序列(每次替换一个)
model_inputs = tokenizer(query, return_tensors='pt')
# 对完整prompt进行tokenize,转成tensor
input_ids = model_inputs['input_ids'].to(self.device)
# token id序列,送入GPU
attention_mask = model_inputs['attention_mask'].to(self.device)
# attention mask,标识有效token (表示是不是padding的)
generation_config['eos_token_id'] = eos_token_id # 设置生成停止token
generation_output = self.generate( # 调用模型生成函数
pixel_values=pixel_values, # 输入视觉tensor(ViT输入)
input_ids=input_ids, # 文本token id
attention_mask=attention_mask, # attention mask
**generation_config # 生成参数(如max_new_tokens等)
)进入self.generate 函数
python
def generate(
self,
pixel_values: Optional[torch.FloatTensor] = None, # 输入图像tensor
input_ids: Optional[torch.FloatTensor] = None, # 文本token id
attention_mask: Optional[torch.LongTensor] = None, # attention mask
visual_features: Optional[torch.FloatTensor] = None, # 已经计算好的视觉特征(可选)
generation_config: Optional[GenerationConfig] = None, # 文本生成配置
output_hidden_states: Optional[bool] = None, # 是否输出hidden states
**generate_kwargs,
) -> torch.LongTensor:
if pixel_values is not None: # 如果输入包含图像
if visual_features is not None:
vit_embeds = visual_features
# 如果已经提供视觉特征,直接使用
else:
vit_embeds = self.extract_feature(pixel_values)
# 否则用ViT从pixel_values提取视觉特征
input_embeds = self.language_model.get_input_embeddings()(input_ids)
# 将文本token id转换成embedding向量
B, N, C = input_embeds.shape
# B: batch size
# N: token序列长度
# C: embedding维度
input_embeds = input_embeds.reshape(B * N, C)
# 展平成二维tensor方便替换
input_ids = input_ids.reshape(B * N)
# 同样把token id展平成一维
selected = (input_ids == self.img_context_token_id)
# 找到所有 <IMG_CONTEXT> token 的位置
assert selected.sum() != 0
# 确保确实存在视觉token占位
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
# 用ViT提取的视觉embedding替换这些位置
input_embeds = input_embeds.reshape(B, N, C)
# 再恢复成原来的 [B, N, C] 结构
else:
input_embeds = self.language_model.get_input_embeddings()(input_ids)
# 如果没有图像输入,只使用文本embedding
outputs = self.language_model.generate(
inputs_embeds=input_embeds, # 使用已经融合视觉token的embedding
attention_mask=attention_mask, # attention mask
generation_config=generation_config, # 生成参数
output_hidden_states=output_hidden_states,
use_cache=True, # 启用KV cache加速生成
**generate_kwargs,
)
return outputs # 返回生成的token id序列2.1 视觉侧ViT
2.1.1 视觉侧概览
- ViT把输入的RGB特征 视频帧数,3,448,448 变成 自ViT encoding后的特征
视频帧数, 1025,1024
-
为了节省算力,压缩到每个图片占256个token,每个token 4096维 视频帧数, 256, 4096
-
用一个MLP对齐到LLM的语言空间 视频帧数, 256, 2048
整体表达为extract_feature函数,函数如下:
python
def extract_feature(self, pixel_values):
# 从图像pixel_values中提取视觉特征,最终得到可以送入LLM的视觉embedding
if self.select_layer == -1:
# 如果select_layer = -1,表示使用ViT最后一层的输出特征
vit_embeds = self.vision_model(
pixel_values=pixel_values, # 输入图像tensor [N,3,H,W]
output_hidden_states=False, # 不返回所有层hidden states
return_dict=True # 返回dict结构
).last_hidden_state # 取最后一层输出 [N, tokens, C]
# 从输入的[视频帧数,3,448,448] 变成 [视频帧数, 1025,1024]
# 每个frame被ViT分成1024个patch,额外加上一个CLS标识,一共1025个patch,每个patch1024维。
else:
vit_embeds = self.vision_model(
pixel_values=pixel_values,
output_hidden_states=True, # 返回所有层hidden states
return_dict=True
).hidden_states[self.select_layer]
# 取指定层的特征
vit_embeds = vit_embeds[:, 1:, :]
# 去掉CLS token
# 原shape: [视频帧数, 1025, 1024]
# 变成: [视频帧数, 1024, 1024]
h = w = int(vit_embeds.shape[1] ** 0.5)
# patch token数量开平方得到二维网格尺寸
# 例如 1024 tokens → 32×32
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
# 将一维token序列恢复成二维patch grid
# [视频帧数, 1024, 1024] → [视频帧数,32,32,1024] 还原成每个长宽位置的1024向量
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
# 对patch grid做空间重排/下采样
# 减少视觉token数量,但增加每个patch的维度。
# 从 [视频帧数,32,32,1024] → [视频帧数,16,16,4096]
# 降低LLM输入token规模, 因为大模型的复杂度是O(n^2) 32->16 大幅减小token运算复杂度
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
# 再次展平成token序列
# [视频帧数,16,16,4096] → [视频帧数, 256, 4096]
vit_embeds = self.mlp1(vit_embeds)
# 用MLP把ViT特征投影到LLM embedding空间
# [视频帧数,256,4096] → [视频帧数, 256, 2048]
return vit_embeds
# 返回视觉token embedding [N, visual_tokens, LLM_dim]2.1.2 ViT encoder 内部定义
定义在huggingface/modules/transformers_modules/InternVL2-2B/modeling_intern_vit.py
step1:embedding 视频帧数,3,448,448 -> 视频帧数,1025,1024
python
hidden_states = self.embeddings(pixel_values)
# [视频帧数,3,448,448] -> [视频帧数,1025,1024]
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
patch_embeds = self.patch_embedding(pixel_values)
# 用patch embedding层对图像做patch划分和线性投影
# 实际上是一个Conv2d(kernel=patch_size, stride=patch_size)
# 输入: [视频帧数,3,448,448]
# 输出: [视频帧数, 1024, 32, 32]
# 一张图分成32*32 每个patch 1024维
batch_size, _, height, width = patch_embeds.shape
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
# flatten空间维度
# [视频帧数, 1024, 32, 32] → [视频帧数, 1024, 1024]
# 把一张图分成1024个patch,每个patch是一个token,1024维
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
# 构造CLS token embedding
# shape: [B, 1, C]
# expand只是复制batch维度
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
# 把CLS token拼到patch tokens前面
# [B, 1, C] + [B, H*W, C]
# → [B, 1 + H*W, C]
position_embedding = torch.cat([
self.position_embedding[:, :1, :],
# CLS token对应的位置编码
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
# patch tokens的位置编码
# 如果输入尺寸变化,这里会插值位置编码
], dim=1)
embeddings = embeddings + position_embedding.to(target_dtype)
# 给每个token加上位置编码,本质上就是一堆nn.Parameters()
# 让Transformer知道patch在图像中的空间位置
return embeddings
# 返回ViT输入token序列
# shape: [12, 1 + 1024, 1024]step2: ViT encoder
过24个经典Transformer Encoder Block,每个如下:
python
class InternVisionEncoderLayer(nn.Module):
def forward(
self,
hidden_states: torch.Tensor,
) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor], Optional[Tuple[torch.FloatTensor]]]:
hidden_states = hidden_states + self.drop_path1(self.attn(self.norm1(hidden_states).to(hidden_states.dtype)) * self.ls1)
# 第一条残差分支: Attention Block
# self.norm1 归一化 -> self.attn(...) 自注意力
# -> * self.ls1 层归一化 -> hidden_states 残差连接
hidden_states = hidden_states + self.drop_path2(self.mlp(self.norm2(hidden_states).to(hidden_states.dtype)) * self.ls2)
# 接下来,self.norm2归一化 -> self.mlp 全连接层
# -> * self.ls2 层归一化-> hidden_states 残差连接
return hidden_states返回结果:
|-------------------|----------------------------------------------------------------|
| 输出字段 | 含义 |
| last_hidden_state | 最后一层的特征 视频帧数,1025,1024 |
| pooler_output | last_hidden_state:, 0, : CLS的特征,表示整个图的全局表示 视频帧数,1,1024 |
2.2 文本侧
python
input_embeds = self.language_model.get_input_embeddings()(input_ids)
# 把文本id [1,文本token长度] -> [1, 文本token长度, 2048]
# 得到每个词的词向量
selected = (input_ids == self.img_context_token_id)
# 找到是图像的token
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
# 我们有多少个图像token,就应该有多少个图片占位符
# 依次填充进去,完成图片和文本模态对齐得到图片和文字prompt融合后的,输入MLLM的输入:
python
outputs = self.language_model.generate(
inputs_embeds=input_embeds,
attention_mask=attention_mask,
generation_config=generation_config,
output_hidden_states=output_hidden_states,
use_cache=True,
**generate_kwargs,
)一次MLLM前向传播:
位于lib/python3.9/site-packages/transformers/generation/utils.py
默认是greedy,每次next token选择概率最高的token作为输出
python
return self.greedy_search(
input_ids,
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
synced_gpus=synced_gpus,
streamer=streamer,
**model_kwargs,
)他是生成模型的主循环:
2.2.1 next token 概览
python
while True:
# prepare model inputs
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
# 最核心函数:预测每个token的next token。
next_token_logits = outputs.logits[:, -1, :]
# 但是我们只需要最后一个,因为现在是在推理阶段
# argmax 选取最大的logit的token作为输出
next_tokens = torch.argmax(next_tokens_scores, dim=-1)
# 拼接到input_ids,即当前的输出序列
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
) # 更新kv cache
# 如果 eos_token 出现了,结束循环
if eos_token_id_tensor is not None:
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
# stop when each sentence is finished
if unfinished_sequences.max() == 0:
this_peer_finished = True
# 如果生成序列超出长度,结束循环
if stopping_criteria(input_ids, scores):
this_peer_finished = True
if this_peer_finished and not synced_gpus:
break2.2.2 next token forward 内部定义
python
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)主体就是这个self.model() ,也就是24个 decoder Transformer,如下:
python
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPast]:
# 获取输入序列
if input_ids is not None and inputs_embeds is not None:
raise ValueError('You cannot specify both input_ids and inputs_embeds at the same time')
elif input_ids is not None: # 除了第一次,都走这个分支
batch_size, seq_length = input_ids.shape[:2]
elif inputs_embeds is not None:
# 第一次没有生成任何答案呢,inputsids是None,走这里
batch_size, seq_length = inputs_embeds.shape[:2]
else:
raise ValueError('You have to specify either input_ids or inputs_embeds')
seq_length_with_past = seq_length
decoder循环
.cache/huggingface/modules/transformers_modules/InternVL2-2B/modeling_internlm2.py
- RMS归一化
python
# decoder循环
residual = hidden_states # 保存残差
hidden_states = self.attention_norm(hidden_states) # RMS 归一化- 自注意力
python
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
qkv_states = self.wqkv(hidden_states) # 三个linear 生成qkv
qkv_states = rearrange(
qkv_states,
'b q (h gs d) -> b q h gs d',
gs=2 + self.num_key_value_groups,
d=self.head_dim,
)
# [1, 文本长度,8, 4, 128] 共8*4个头,每个头128维
query_states = qkv_states[..., : self.num_key_value_groups, :]
# [1, 文本长度,8, 2, 128]
query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
# [1, 文本长度,16, 128] 16个query heads
key_states = qkv_states[..., -2, :]
# [1, 文本长度,8, 128]
value_states = qkv_states[..., -1, :]
# [1, 文本长度,8, 128]
query_states = query_states.transpose(1, 2)
key_states = key_states.transpose(1, 2)
value_states = value_states.transpose(1, 2)
kv_seq_len = key_states.shape[-2]
# RoPE 位置编码增强q和k
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# 和16个q对齐,把kv也复制到16个
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attention_mask is not None:
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
attn_output = self.wo(attn_output)
# 全连接层
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value- 残差连接
python
hidden_states = residual + hidden_states- 全连接层
python
residual = hidden_states
hidden_states = self.ffn_norm(hidden_states)
hidden_states = self.feed_forward(hidden_states)
hidden_states = residual + hidden_states2.3 生成结果decode回自然语言
python
response = tokenizer.batch_decode(generation_output,
skip_special_tokens=True)[0]三,总结
-
Visual encoder 是一个ViT,24层Transformer Encoder组成
-
InternVL特有的MLP层也位于Visual encoder
-
Text encoder 是一个24层Transformer Decoder组成