论文总结
1、作者提出了表格分支、图像分支和融合分支三个分支的神经网络模型,**能够在模态缺失情况下也进行推理,**该结构在推理时支持模态缺失(如图像或表格缺失),仍可依靠其他分支进行分类。
2、作者针对多模态分类任务中标签不一致的问题,提出了标签掩蔽和最大似然选择方法解决。这两种方法分别适用于不同训练阶段(预训练 vs. 从零训练)。标签掩蔽方法仅在图像和表格标签一致时训练融合分支。最大似然选择方法选择图像中概率最高的24张切片作为输入,以减少标签不一致。
3、对于PE数据集 ,图像模型使用的是 PENet (基于3D CNN),表格模型使用的是 Tabular Transformer 。对于NACC数据集 ,图像模型使用的是 3D CNN + Transformer ,表格模型依然是 Tabular Transformer。
4、没有找到开源代码;作者对比实验做的很完善,把所提出来的方法各个组件和现有方法做了对比,例如MMTM、concatenation、Tokenfusion和CM attention等。以及对比了单模态、多模态和集成学习的方法。
摘要
本文提出了一种三分支神经融合(TNF)方法,旨在分类多模态医学图像和表格数据。它还提出了两种解决方案,以解决多模态分类中标签不一致的问题。传统的多模态医学数据分类方法通常依赖单标签方法,通常将两种不同输入方式的特征合并。当特征互斥或不同模态标签不同时,这会带来问题,导致准确性降低。为克服这一问题,我们的TNF方法实现了三分支框架,管理三个独立输出:一个用于图像模态,另一个用于表格模态,第三个混合输出融合图像和表格数据 。**最终决策通过整合三大分支的似然方法做出。**我们通过大量实验验证了TNF的有效性,展示了其在多种卷积神经网络和基于变换器架构中的传统融合和集成方法的优越性。
引言
在过去几十年里,医疗数据分类被广泛研究,并成为医疗数据处理中的关键组成部分。医学数据分类有助于准确确定患者病灶位置,减轻医生在治疗过程中的工作负担Wang和Zuo,2022。大多数医学数据分类模型都是针对单一模态创建的,如图像数据Singh等,2020、视频数据Funke等,2019和文本数据Pagad等,2022。另一方面,多模态学习在视觉和语言学习等领域取得了显著进展 Wang 等,2022;Uppal 等,2021,视频学习 Panda 等,2021和自动驾驶 Xiao 等,2020。多模态学习也应用于生物医学数据Acosta等,2022。因此,将多模态学习应用于多模态医学数据分析是近期趋势Amal 等,2022;Shaik等,2023年;Taleb 等,2021;Yao等,2017。
在诊断某些疾病如阿尔茨海默病时,临床医生结合诊断工具、病史及其他信息,包括神经学检查、认知和功能评估、医学影像(MRI、CT、超声波)以及脑脊液或血液检测,以做出准确诊断协会,2023。上述过程将生成两种医学数据模式:一种是包括MRI、CT或超声在内的医学图像数据;另一种是包含患者信息的医疗表格数据,如性别、年龄和诊断结果。基于医学图像和表格数据自动诊断,需要采用多模态医学数据分类方法。分类方法以医学影像和表格数据为输入,输出为诊断结果。在多模态分类中,通常有两种不同的方法。第一种是集成 Rokach, 2010;Kumar 等,2016,该方法训练多个模型以适应不同模态,并在推理阶段对多个模型的输出进行汇聚,以获得最终的分类结果。第二种方法是融合法,它提取不同模态的特征,然后融合这些特征并输出最终分类结果Zhang 等,2021。集成模式的稳健性更高,但在准确性和可解释性方面不如融合模式。融合可能更准确,但更容易出现过拟合,且灵活性较低(要求所有模态在训练和推断时间均可用)。需要提出一种能够克服合奏和融合各自不足的方法。本文提出了三分支神经融合(TNF)用于多模态数据分类,如图1所示。
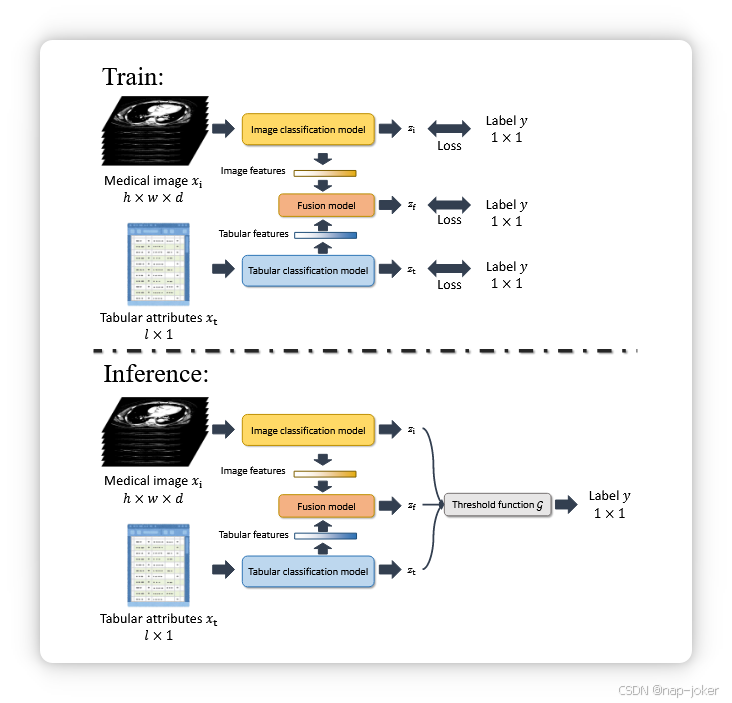
图1:TNF的整体结构。输入是医学图像习及对应的表格属性xt。分别将 习 和 xt 输入到图像分类模型和表格分类模型中,以获得似然 zi 和 zt。图像特征和表格特征被输入到融合模型中以获得似然 zf。Zi、Zt 和 ZF 通过阈值函数 G 处理,得到分类结果 yˆ。
我们的方法同时利用了集成和融合。医学图像分类模型通过对医学图像进行分类以获得概率zi。医学表格分类模型通过对医学表格进行分类,以获得似然zt。同时,我们将医学图像分类模型的特征和医学表格分类模型的特征融合,得到似然 zf 。我们将似然 zi、zt 和 zf 进行集成以得到分类结果。我们的TNF不依赖特定的网络结构。在实验中,我们通过使用多种纯卷积神经网络(CNN)结构和CNN+TransformerVaswani 等,2017混合结构验证了我们的方法。我们还在两个图像表多模态数据集上验证了该方法:肺栓塞(PE)数据集Zhou 等,2021,包含肺栓塞CT扫描和临床记录;以及认知障碍水平分类数据集Beekly等,2004,该数据集包含脑MRI扫描和问卷表。我们的方法比集成法和融合法更优,ACC、MCC Chicco 等, 2021、AUROC 及其他指标提升了1%至5%。我们还观察到,借助TNF的微调过程,图像分支和表格分支的效果优于单模态分支。此外,在推断阶段,即使缺少一种模态(图像或表格)也可发挥作用。这显示了TNF相较于传统多模聚变方法的灵活性,后者需要各种类型的数据才能进行预测。
本文的贡献可总结为:
• 我们提出了三分支神经融合(TNF),这是一种高性能分类结构,结合融合与集成,用于多模态医疗数据分类。
• 我们还提出了两种方法,分别是标签掩蔽和最大似然选择,以解决多模态分类任务中的标签不一致问题。这两种方法在基于TNF的模型上取得了令人满意的结果。
• 在各种Transformer和卷积神经网络上进行充分实验,结果证明TNF优于单个融合或集成。多个数据集上的实验证明了TNF的普遍性。
相关工作
医疗数据处理中的多模态
模态是一种特定的模式,其中某物存在、被体验或表达 Pei 等,2023。例如,在两种不同情况下收集的两个数据集的数据,可以被视为两种模态Baltrusˇaitis等,2018。在医疗数据机器学习领域,已有努力模拟临床专家决策的多模态特性,以提升预测准确性Su 等,2020。多模态医疗数据处理主要侧重于分类、预测和分段。关于分类,MRI和表格数据结合使用用于乳腺癌分类Holste等,2021。值得注意的是,本研究的数据仅来自单一机构。另一项研究采用多种影像方式进行皮肤病变分类Yap等,2018。然而,其相较基线的准确率提升被发现有限。关于预测,组织学病理图像和基因组信息结合以预测生存 Mobadersany 等,2018。然而,本研究所用数据集相对较小。此外,脑损伤模式和用户定义的临床测量也用于预测转为多发性硬化症Yoo等,2019。该方法需要用户自定义的MRI测量,因此需要与临床医生的协作。值得注意的是,上述方法存在三个共同局限性。首先,它们主要专注于增强特定网络结构,这些结构可能缺乏跨不同机器学习架构的灵活性(例如无法将为CNN设计的改进应用到Transformer模型中)。其次,标签在不同模态之间可能有所不同。然而,这些方法要求不同模态的标签在训练过程中保持一致。第三,这些方法要求在训练和推理阶段都提供多模输入。如果推理阶段缺少任何模态,这些方法将无法使用。我们的创新方法有效克服了这三个局限。
多模分类中的集成与融合技术
集成和融合是多模态数据分类中两种常见策略。集成方法结合多个基分类器的输出,增强了鲁棒性和准确性。该技术已被证明在RGB自然图像分类Beluch等,2018和医学图像分类Zhou等,2021中有效。相比之下,融合通过整合来自不同层次的多个来源或模态的数据,以提升分类性能。它已被广泛应用于基于深度学习的分类。在CNN的背景下,多模态传输模块(MMTM)Joze等,2020实现了卷积层内特征模态的融合,且空间维度范围变化。加权特征融合 Dong 等, 2022 将图关注网络和卷积神经网络中的特征合并,用于高光谱图像分类。辅助监督Holste等,2023在训练过程中生成额外源,以提升小数据集上的聚变。关于基于Transformer的融合,跨模态注意力Li 和 Li, 2020促进了对两个不同序列或特征集的同时关注。TokenFusion Wang 等,2022 识别无信息性标记,并在多模态分类任务中用投影和聚合的模态间特征替代它们。
方法
方法概论
给定以习表示的医学图像和一组表状属性xt,我们的方法会产生三个不同的输出:zi、zt和zf,均源自深度学习模型,记为F(·)。这里,zi 和 zt 分别源自医学图像和表格属性,zf 对应于医学图像和表格属性的融合特征。这种关系可以描述如下:zi, zt, zf = F (xi, xt), (1)
在训练阶段,模型 F(·) 通过损失函数 L 进行优化,定义为:L = λ1Lc(zi, yi) + λ2Lc(zt, yt) + λ3Lc(zf, yf),(2)
其中 λ1, λ2 和 λ3 为加权系数,yi, yt 和 yf 是图像、表格和融合分支的标签, Lc(·)表示交叉熵损失。在推断阶段,分类结果由以下方式确定:
yˆ = G zi + zt + zf 3 , (3),其中 G(·) 是由阈值 θ 定义的阈值函数。对于二元分类场景,该函数表达为:如果α ≥θ,G(z) = 1,(4) G(z) = 0,如果α <θ,(5),通常为θ = 0.5。该方法的完整框架如图1所示。
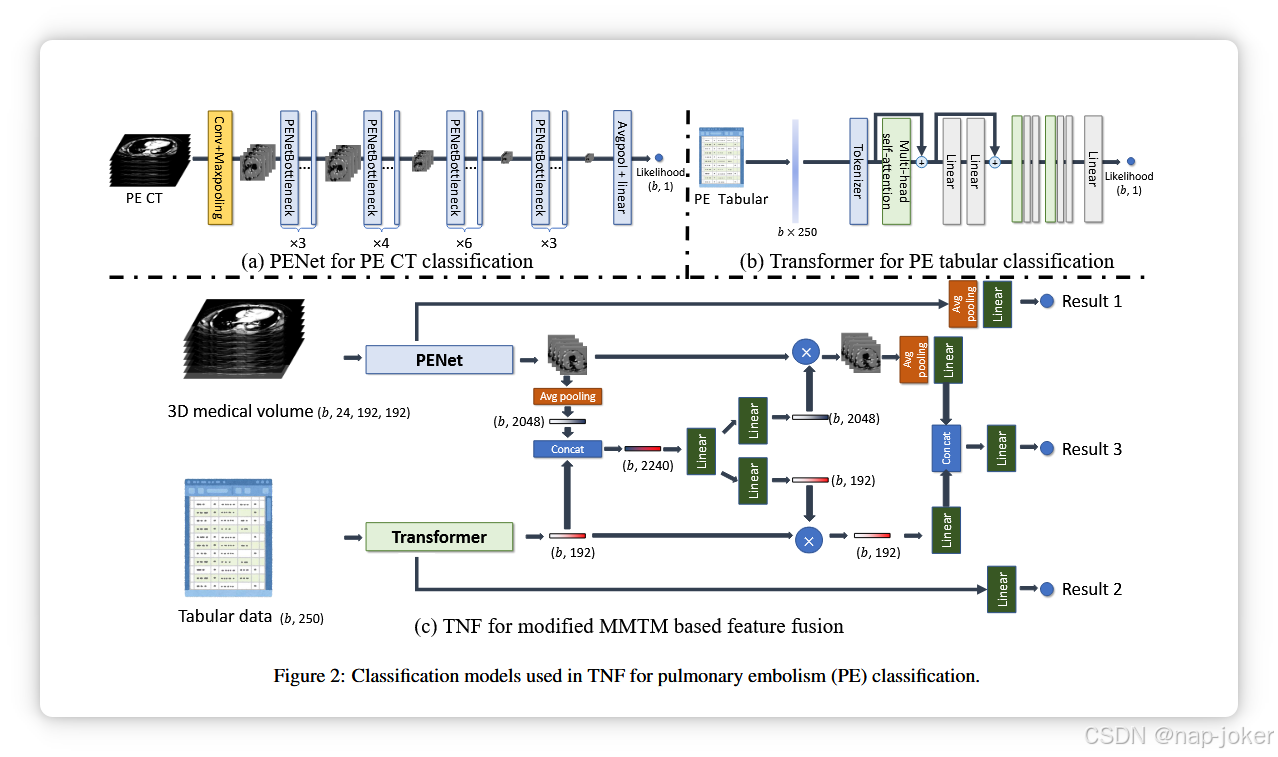
肺栓塞(PE)的TNF分类
我们采用了斯坦福AIMI的肺栓塞(PE)数据集Zhou等,2021作为研究的首个数据集。该数据集包括计算机断层扫描(CT)扫描及从同一患者的电子健康记录(EHR)中提取的相应临床数据。我们选择了基准架构:用于CT扫描的分类采用PENet架构Huang等,2020,EHR数据分类采用了Tabular TransformerGorishniy等,2021。这些方法在我们框架中的整合如图2所示。
解决标签不一致问题在多模分类中至关重要。在PE数据集中,每个CT切片都有自己的标签。例如,大小为256×256×100的CT体积可产生100个单独的切片标签。然而,相应的电子健康记录系统数据只被赋予一个标签,无论是正例还是反例。先前的研究Huang等,2020建立了PE数据集图像数据分类的基准,将CT体积划分为多个连续的24个切片。如果任意24个连续切片中有任意4个片被识别为正,则整个体积标记为正。这种方法在融合电子健康记录和CT体积数据时并不能完全解决标签不一致的问题,因为电子健康记录标签可能与图像不一致。详情请参阅附录A。为解决这一差异,我们提出了两种方法:1)标签掩蔽,2)最大似然选择。
标签掩蔽
标签掩蔽的实现可以描述为: L = λ1Lc(zi, yi) + λ2Lc(zt, yt) + λ3Lc(zf, yi),如果yi = yt, λ1Lc(zi, yi) + λ2Lc(zt, yt),否则,(6),其中yi和yt分别是图像标签和表格标签。只有当 yi = yt 时,聚变分支的权重才会被优化。使用标签掩蔽时,如果标签不一致,则无法进行聚变分支的训练。
最大似然选择
我们在以往研究中使用预训练的PENetZhou等,2021,提取每个体积中概率最高的24个切片,并以此作为输入来训练基于TNF的模型。如果整个体积都是正的,那么这24个切片也是正的,否则它们是负的。该过程可以描述为,j′ = argmax j (Fi(xj i )), j ∈� {1, . . . . , N }, zi, zt, zf = F (xj′ i , xt), (7),其中N表示CT体积内24切片群的总数。例如,如果一个CT体积包含100个切片,N = 100/24向上取整 = 5。这意味着有五个组别,第1到第4组各包含24个切片,第5组仅包含4个切片。我们通过填充第5组空气的CT值(-1000)来填充填充,从4片扩展到24片。Fi是图2(a)中的PENet。通过只选择具有最高正似然的切片,最大似然选择解决了图像标签与表格标签之间的不一致问题。
基于TNF的PE分类模型
我们验证了多个基于TNF的PE分类模型。
基于MMTM的特征融合
首先,我们基于TNF进行了基于MMTM特征融合的实验。MMTM Joze 等,2020 是一种广泛使用的特征融合方法,用于融合多种模态的知识,如
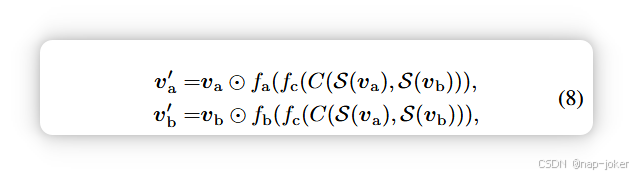
其中 S 是挤压多维特征 va 的"挤压"函数,∈ Rb×c×m1,...,mK 映射为 Rb×c。fa(·) 和 fb(·) 和 fc(·) 分别是线性层。C(·) 是通道连接。按信道而言,⊙乘法。在我们的语境中,特征vi∈Rb×c×h×w×d来自三维医疗体积,而特征vt∈Rb×l则来自表格变换器。由于这些特征的尺寸不同,而来自表格变换器的vt仅有两个维度,因此被认为没有必要挤压vt。因此,我们将MMTM方法调整为融合vi和vt,如图2(c)所示。改良后的聚变过程定义为:
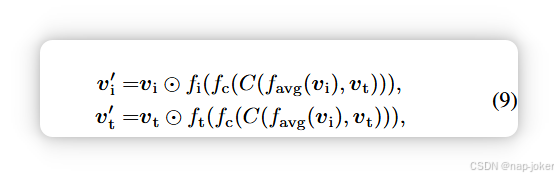
其中 favg 是平均池函数。随后,融合输出通过平均池化、串接和线性层的应用获得,如图2(c)所示。
基于串接的变压器特征融合
TNF在变压器结构上的有效性也进行了评估。对于图像特征vi∈Rb×c×h×w×d,我们应用三维卷积和重塑函数将其转换为v′ i ∈Rb×h×w×d×c′。这些特征随后与表格变换器输出按通道串接。概率计算方式如下:
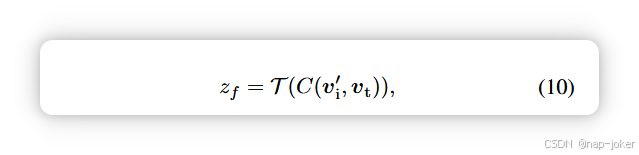
其中 T 代表类嵌入块和 Transformer 块。详见附录B了解网络结构。
基于TokenFusion的变换器特征融合
TNF还通过TokenFusionWang 等,2022和跨模态注意力Li和Li, 2020在变换器特征融合中展现了有效性。我们使用 TokenFusion 将图像和表格模态的特征融合:

其中MLP是一个多层感知器,SA是一个自注意力机制,f(·)是一个线性函数。之后,将 v′ i 和 v′t 融合以得到分类结果。TokenFusion 为每个token分配权重,选择性地强调或减少某些标记。
基于注意力的跨模态变换器特征融合
另一方面,跨模态注意力促进了对两个不同特征源的同时关注:
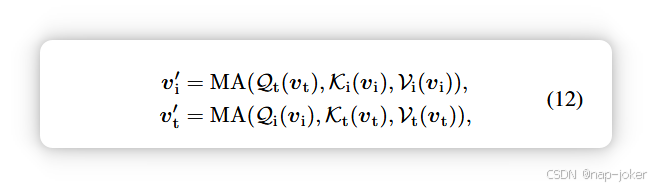
其中MA代表多头注意力机制,而Q、K和V表示查询、键和值操作。
认知障碍水平分类的TNF表示
TNF还被用于一项涉及认知障碍级别分类的多类别分类任务,使用NACC Beekly等,2004数据集。认知障碍等级分为三个阶段:0(正常)、1(轻度认知障碍)和2(严重认知障碍)。NACC数据集包含两种模式:脑MRI体积(图像数据)和问卷表(表格数据)。我们基于TNF开发了两个用于分类NACC数据的模型。
基于串接的特征融合
第一个模型如图3(a)所示,采用CNN对大脑MRI体积进行分类,并使用表格变换器处理表格数据。我们将脑MRI体积(形状为(b, 5760)与来自表格变换器(形状为(b, 768)的特征串接在一起。这得到一个形状为(b, 6528)的组合特征矢量,然后输入线性层以推导出融合标签。
基于Transformer架构的特征融合
第二个模型如图3(b)所示,涉及通过三维卷积层处理大脑MRI体积的特征、重塑操作和变压器块。该过程得到形状为 (b, 36, 768) 的特征向量。表格变换器中间层的特征(b, 99, 768)与该向量串接形成新的形状向量(b, 135, 768)。该合并向量随后被输入到变压器层中,以获得聚变标签。
实验和结果
预处理
PE数据集的预处理
PE数据集表包含1505个属性,如年龄、性别、脉冲等。我们去除了两个与PE直接相关的属性("肺循环疾病:频率"和"肺循环疾病:存在"),因为我们发现如果这两个属性不是0,PE必定为正。我们使用 SHAP Shrikumar 等, 2017 来筛选 PE 分类中最重要的 250 个属性。我们还将PE数据集的图像从256×256调整为224×224,并中心裁剪为192×192。我们将图像强度归一化为范围-1, 1。
NACC数据集预处理
• 病例选择与图像预处理 NACC数据集包含9,812例具有T1、T2和FLAIR模态的脑MRI病例。我们选择具有T1模态的薄片病例,并使用FreeSurfer Fischl, 2012进行骨头切除、调整大小和强度归一化。经过预处理后,仍有1,252个体素大小为182×218×182的案例。我们将体积强度归一化为范围-8, 8。• 表格预处理 我们通过零填充、特征选择和归一化对NACC表格数据进行预处理。经过预处理后,表格数据保留了99项特征,包括认知问卷信息、性别、年龄等。
训练和推理
PE数据集
我们遵循PE数据集的实验设置Zhou等,2021。共有1,837例,其中1,454例用于培训,190例用于验证,193例用于测试。我们加载了先前研究提供的最佳预训练PENetHuang等,2020。为确定预训练重量的饱和度,我们从预训练重量开始运行额外训练历程,确认无进一步性能提升;我们将自己训练好的预训练表变换器加载到基于TNF的模型中进行训练。学习率为10-4,余弦衰减降至10-5。训练轮数为1000,优化器为AdamW Loshchilov 和 Hutter, 2018。正则化参数设置为 λ1 = 0.1,λ2 = 0.1,λ3 = 0.8。验证数据集中采用最佳模型进行测试。
NACC数据集
在1252个NACC数据集中,我们随机选择了752个用于训练,249个用于验证,251个用于测试。我们预训练了一个与以往研究中Qiu等,2022结构一致的4块CNN模型,如图3所示,用于图像分类;以及图2(b)中结构相同、用于表格分类的表变换器模型。预训练后,我们训练图3(a)(b)所示基于TNF的模型。学习率为10⁻³,训练轮数为100,优化器为Adam。
结果
PE数据集
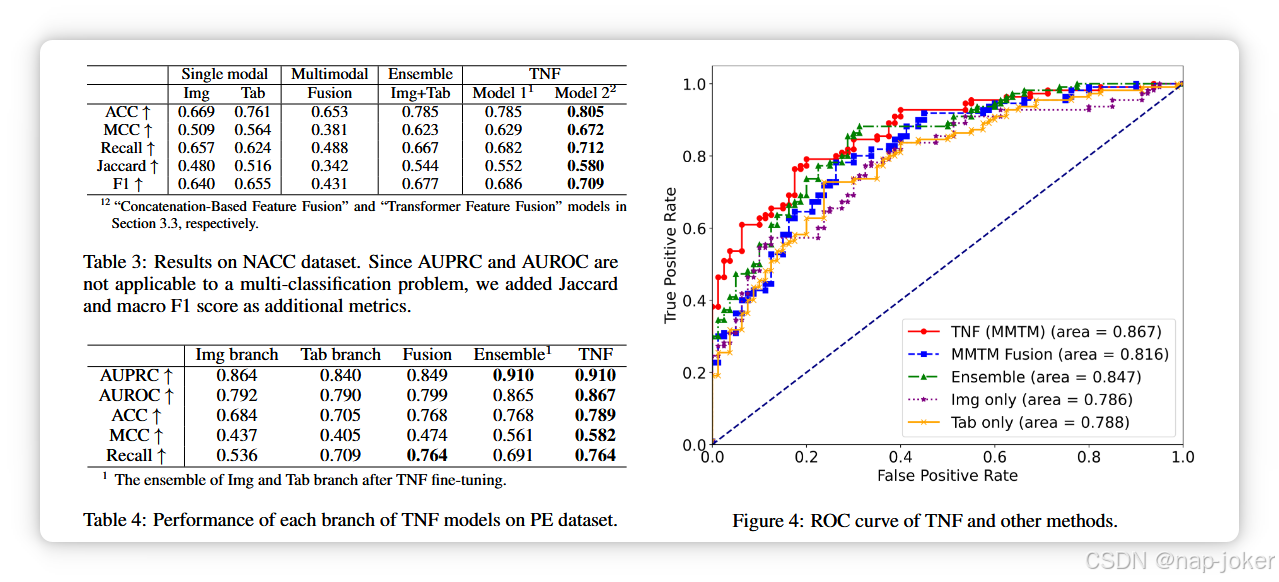
首先,我们评估了PE数据集上的两种方法:使用最大似然选择对标签掩蔽进行不一致标签训练,以及从零开始训练与预训练进行比较。对于从零开始训练,只有PENet在Kinetics-600数据集上进行了预训练 Carreira 等,2018。在预训练的情况下,PENet和Tabular Transformer均在PE数据集上进行预训练。这些比较的结果见表1。我们发现,最大似然选择与预训练的结合在大多数指标上表现最佳。因此,我们选择它进行以下实验。PE数据集的结果详见表2,ROC曲线见图4。我们比较了基于TNF的模型与单模态、多模态融合和集成方法。我们尝试了两种融合模型:1)MMTM融合,其结构与图2(c)中的模型等价;图4:TNF的ROC曲线及其他方法。 只输出聚变结果。2)夹子融合,基于Hager等,2023的研究(详见附录C)。TNF方法不仅超越了单模态分类(无论是图像还是表格),在大多数指标上也优于多模态融合和 集成**。值得注意的是,融合方法的准确率低于** 集成方法,表明传统多模聚变对某些数据集可能无效。
NACC数据集
NACC数据集的定量结果见表3。作为对比,多模聚变模型与仅包含融合分支的模型相同,如图3左侧所示。我们基于TNF的两种模型,即基于简单连接的特征融合和Transformer特征融合模型,表现优于其他方法。
基于3D Grad-CAM的关键区域分析
为了可视化模型预测的关键区域,我们设计了一个3D Grad-CAM模型,并将其适配到TNF模型中。Grad-CAM Selvaraju 等,2017 能够为CNN所做的决策提供视觉解释。我们修改了Grad-CAM技术,使其能够应用于多个输入和多个输出,并能处理3D医学图像。我们一次反向传播一个输出,以获得它的GradCAM热图。
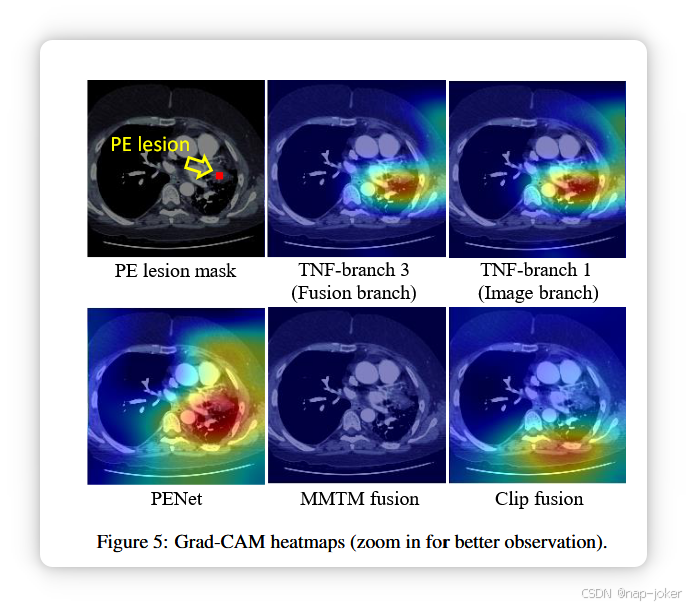
我们比较了五种类型的Grad-CAM热图:1)TNF的融合分支。模型如图2(c)所示;2)TNF的图像分支;3)PENet;4)MMTM聚变模型;模型结构等价于图2(c)中的模型,仅输出聚变结果;5)夹剪融合模型。Grad-CAM热图与临床医生标记的PE病灶面罩进行比较,如图5所示示例。TNF的Grad-CAM热力图突出显示了病变区域。另一方面,PENet的热力图显示了更大的区域。MMTM融合和夹子融合未能突出病灶。一般来说,TNF的热图最接近病灶掩码。
各个分支的性能对比
我们还对TNF模型的各个分支进行了性能比较,见表4。注意,我们的TNF模型有三个分支:1)图像分支;2)表格分支;以及3)聚变分支。我们展示了每个分支的结果、前两个分支的集成以及TNF。TNF在量化上取得了最佳结果,除了召回问题。
讨论
标签掩蔽与最大似然选择的比较
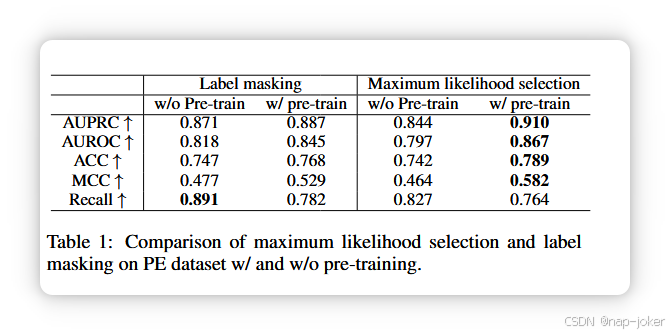
为解决多模态处理中标签不一致的挑战,我们引入了两种方法:标签掩蔽和最大似然选择。根据表1的结果,当网络进行预训练时,最大似然选择相比标签掩蔽获得更高的AUPRC(0.910对0.887)。然而,如果没有预训练,情况会相反(0.844对0.871)。这表明,最大似然选择在微调预训练网络时更有效,因为它不会添加新的标签信息,而这些信息在训练阶段可能存在冗余。相反,标签掩蔽更适合从零开始训练,因为它引入了更多的训练数据。
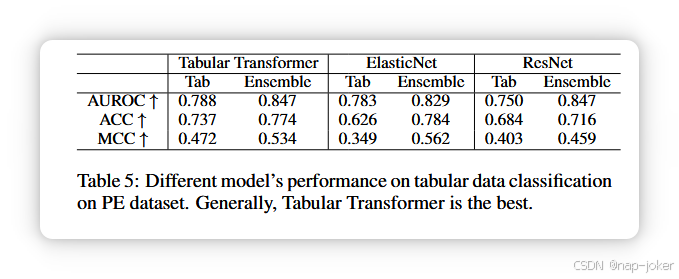
表格分类的模型选择
ElasticNet Zou 和 Hastie, 2005 曾用于 PE 数据集中的表格数据分类。我们还研究了ResNetJian等,2016和Tabular TransformerGorishniy等,2021,以评估其疗效。表5显示,Tabular Transformer的性能优于其他型号。因此,我们选择了Tabular Transformer作为基线模型。
TNF增强单模态分类
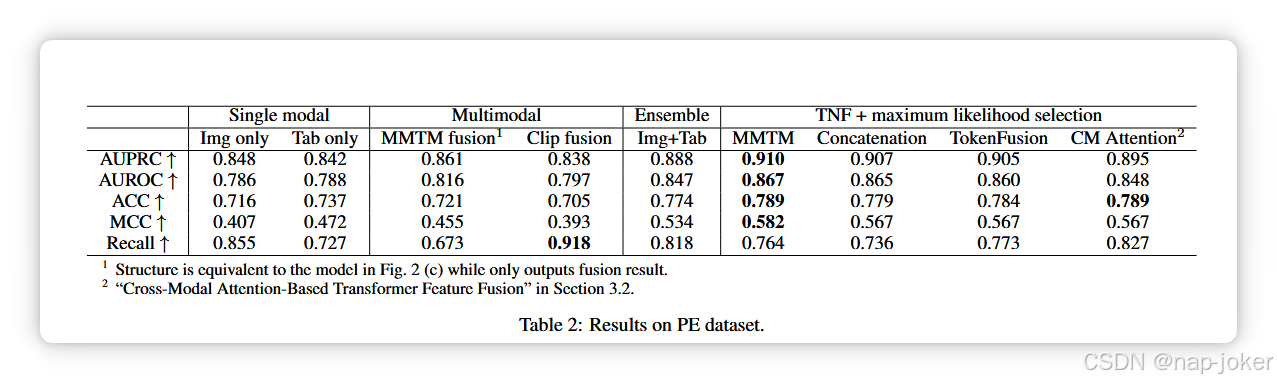
表4中的"Img分支"栏和表2中的"仅图像"栏显示图像分类结果。经过与TNF的微调,图像分类的性能指标有了明显提升。AUPRC从0.848上升至0.864,MCC从0.407上升至0.437。我们将这一提升归功于融合过程中表模态特征的整合。TNF使PENet能够更有效地提取对准确分类至关重要的共同特征。
TNF相较于多模聚变的优势
当不同模态的信息相互冲突时,采用融合方法反而会降低准确率。如表2和表3所示,多模融合无法超越集成。部分原因是如果融合部分被优化,特征提取部分可能优化不佳。TNF通过提取模态间的共同特征,同时保持特征提取部分的优化,解决了这一问题。TNF相较于聚变的另一个优势是,即使缺少一种模态,也能推断结果。例如,如果缺少表格数据,我们仍可通过图像分支推断结果。另一方面,多模态融合模型无法在某一模态数据缺失时推断结果。
总结
我们提出了三分支神经融合(TNF)模型用于多模态数据分类。我们还提出了标签掩蔽和最大似然选择,以解决标签不一致的挑战。我们在两种多模态医学数据集上验证了多种CNN和基于变革的融合算法,均优于多模态集成和融合结果。与多模聚变相比,TNF在缺失某一模态时仍能推断分类结果。相较于集成,TNF在定量上取得了更好的结果。基于研究生CAM的可解释性研究进一步证明,TNF可以使模型聚焦病灶,从而展示其在辅助诊断方面的潜力。未来,我们计划探索多种融合方式的案例,并将基于TNF的模型引入临床实践,为临床医生提供支持。