通过本文可快速学习kafka的基础知识,主题和分区,简单的集群操作
目录
[1. 有broker](#1. 有broker)
[9. 查看消费组的详细信息](#9. 查看消费组的详细信息)
同一个消费组内:负载均衡,消息均分!(每条消息发到不同的分区)
⼀、为什么使⽤消息队列
1.使⽤同步的通信⽅式来解决多个服务之间的通信
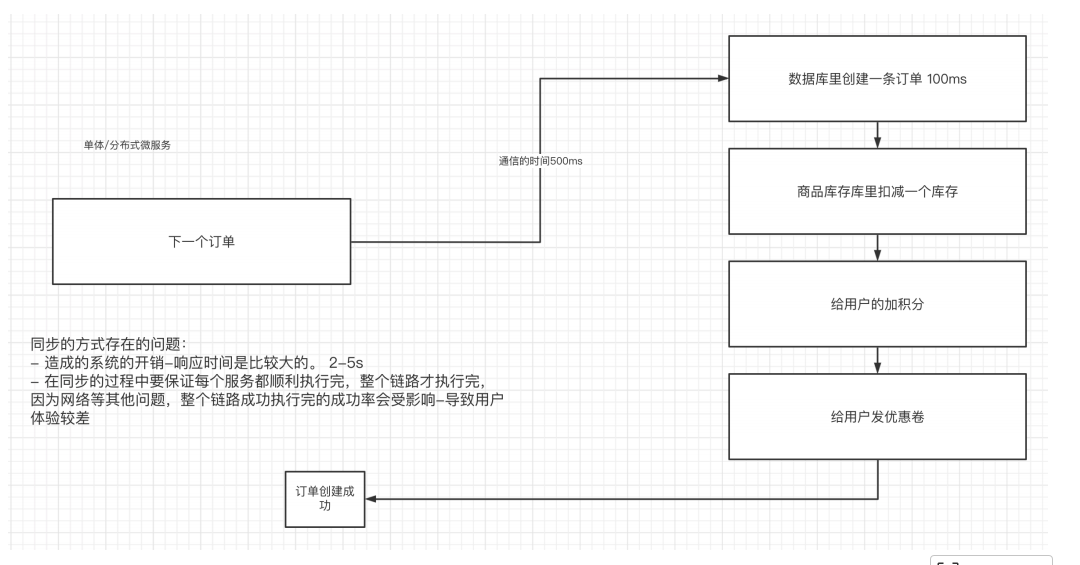
同步的通信⽅式会存在性能和稳定性的问题。
2.使⽤异步的通信⽅式
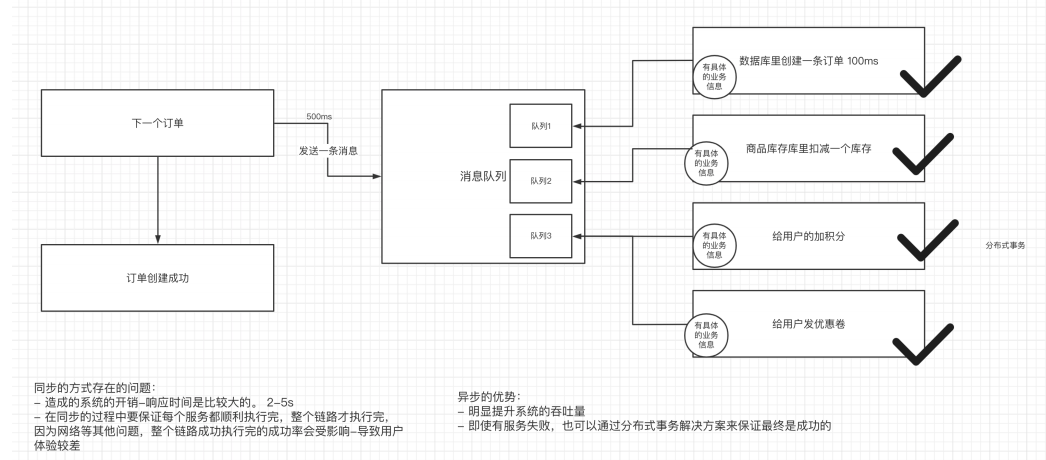
针对于同步的通信⽅式来说,异步的⽅式,可以让上游快速成功,极⼤提⾼了系统的吞吐
量。⽽且在分布式系统中,通过下游多个服务的分布式事务的保障,也能保障业务执⾏之后
的最终⼀致性。
⼆、 消息队列 的流派
⽬前消息队列的中间件选型有很多种:
rabbitMQ:内部的可玩性(功能性)是⾮常强的
rocketMQ: 阿⾥内部⼀个⼤神,根据kafka的内部执⾏原理,⼿写的⼀个消息队列中间
件。性能是与Kafka相⽐肩,除此之外,在功能上封装了更多的功能。
kafka:全球消息处理性能最快的⼀款MQ
zeroMQ
这些消息队列中间件有什么区别?
1. 有broker
重topic:Kafka、RocketMQ、ActiveMQ
整个broker,依据topic来进⾏消息的中转。在重topic的消息队列⾥必然需要topic的存在
轻topic:RabbitMQ
topic只是⼀种中转模式。
2.⽆broker
在⽣产者和消费者之间没有使⽤broker,例如zeroMQ,直接使⽤socket进⾏通信。
三、 Kafka 的基本知识
1. Kafka 的安装
-
部署⼀台zookeeper服务器
-
安装jdk
-
下载kafka的安装包:http://kafka.apache.org/downloads
-
上传到kafka服务器上: /usr/local/kafka
-
解压缩压缩包
-
进⼊到config⽬录内,修改server.properties
#broker.id属性在kafka集群中必须要是唯⼀
broker.id=0
#kafka部署的机器ip和提供服务的端⼝号
listeners=PLAINTEXT://192.168.200.140:9092
#kafka的消息存储⽂件
log.dir=/usr/local/kafka/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect=192.168.200.140:2181 -
进⼊到bin⽬录内,执⾏以下命令来启动kafka服务器(带着配置⽂件)
./kafka-server-start.sh -daemon ../config/server.properties
-
校验kafka是否启动成功:
进⼊到zk内查看是否有kafka的节点: /brokers/ids/0
2. kafka 中的⼀些基本概念
kafka中有这么些复杂的概念
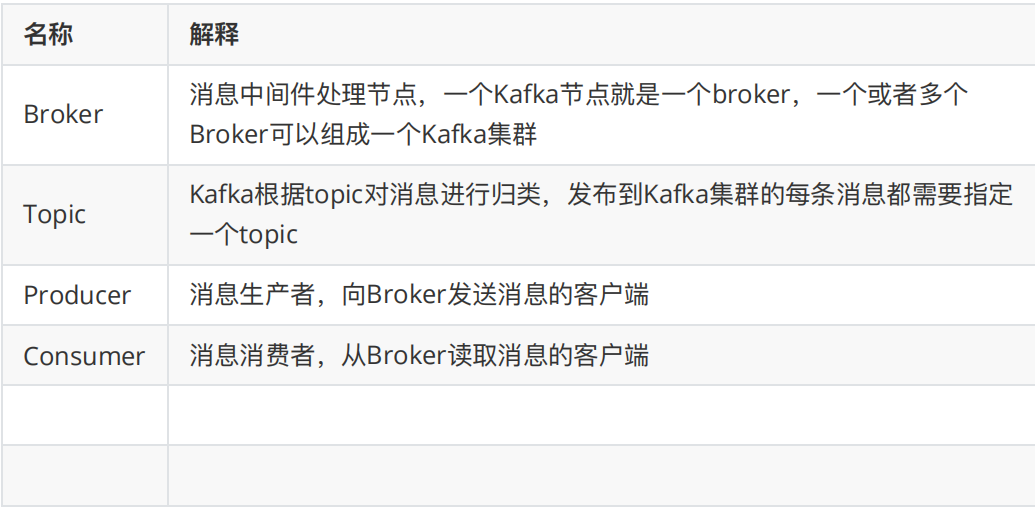
3.创建topic
执⾏以下命令创建名为"test"的topic,这个topic只有⼀个partition,并且备份因⼦也设置为
1:
./kafka-topics.sh --create --zookeeper 192.168.200.140:2181 --replication-factor 1 --partitions 1 --topic test查看当前kafka内有哪些topic
./kafka-topics.sh --list --zookeeper 192.168.200.140:2181Kafka 创建的topic 是放到zookeeper里的
4.发送消息
把消息发送给broker中的某个topic,打开⼀个kafka发送消息的客户端,然后开始⽤客户端向
kafka服务器发送消息
./kafka-console-producer.sh --bootstrap-server 192.168.200.140:9092 --topic test5.消费消息
打开⼀个消费消息的客户端,向kafka服务器的某个主题消费消息
⽅式⼀:从当前主题中的最后⼀条消息的offset(偏移量位置)+1开始消费
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092 --topic test⽅式⼆:从当前主题中的第⼀条消息开始消费
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092 --from-beginning --topic test6.关于消息的细节
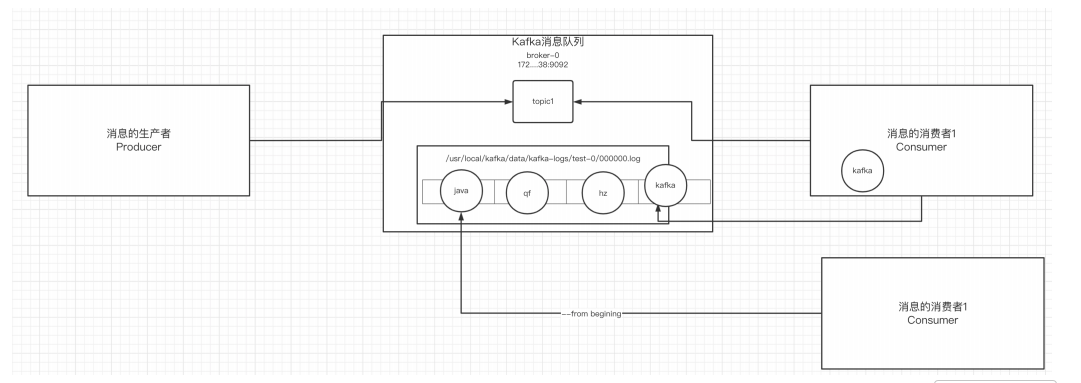
-
⽣产者将消息发送给broker,broker会将消息保存在本地的⽇志⽂件中
/usr/local/kafka/data/kafka-logs/主题-分区/00000000.log
-
消息的保存是有序的,通过offset偏移量来描述消息的有序性
-
消费者消费消息时也是通过offset来描述当前要消费 的那条消息的位置
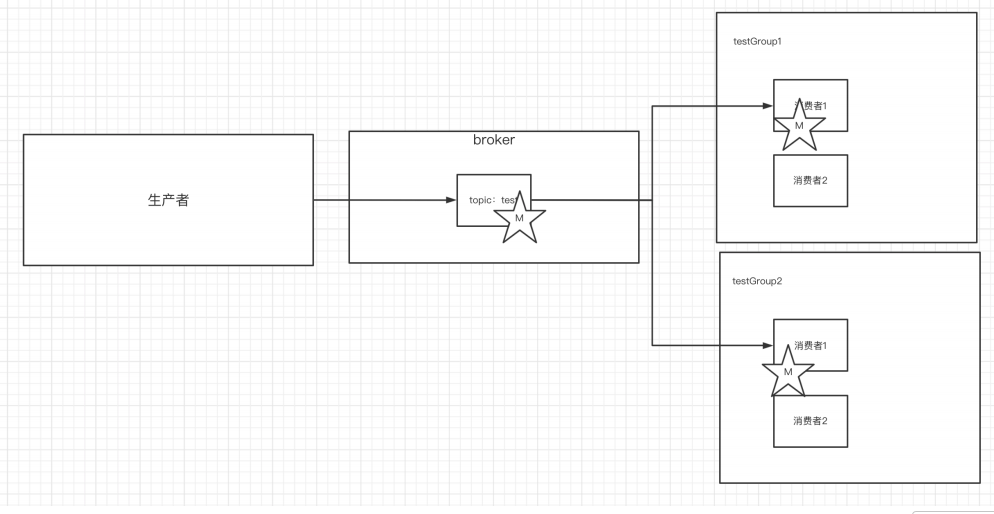
7.单播消息
在⼀个kafka的topic中,启动两个消费者,⼀个⽣产者,问:⽣产者发送消息,这条消息是否同时会被两个消费者消费?
如果多个消费者在同⼀个消费组 ,那么只有⼀个消费者可以收到订阅的topic中的消息。换言之,同⼀个消费组中只能有⼀个消费者收到⼀个topic中的消息。
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092 --consumer-property group.id=testGroup --topic test8. 多播 消息
不同的消费组订阅同⼀个topic ,那么不同的消费组中只有⼀个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同⼀个消息。
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092 --consumer-property group.id=testGroup2 --topic test下图就是描述多播和单播消息的区别
9. 查看消费组的详细信息
查看当前有多少个消费组
./kafka-consumer-groups.sh --bootstrap-server 192.168.200.140:9092 --list通过以下命令可以查看到消费组的相信信息:
./kafka-consumer-groups.sh --bootstrap-server 192.168.200.140:9092 --describe --group testGroup
重点关注以下⼏个信息:
- current-offset: 最后被消费的消息的偏移量
- Log-end-offset: 消息总量(最后⼀条消息的偏移量)
- Lag:积压了多少条消息
四、 Kafka 中主题和分区的概念
1.主题Topic
主题-topic在kafka中是⼀个逻辑的概念,kafka通过topic将消息进⾏分类。不同的topic会被
订阅该topic的消费者消费。
但是有⼀个问题,如果说这个topic中的消息⾮常⾮常多,多到需要⼏T来存,因为消息是会被
保存到log⽇志⽂件中的。为了解决这个⽂件过⼤的问题,kafka提出了Partition分区的概念
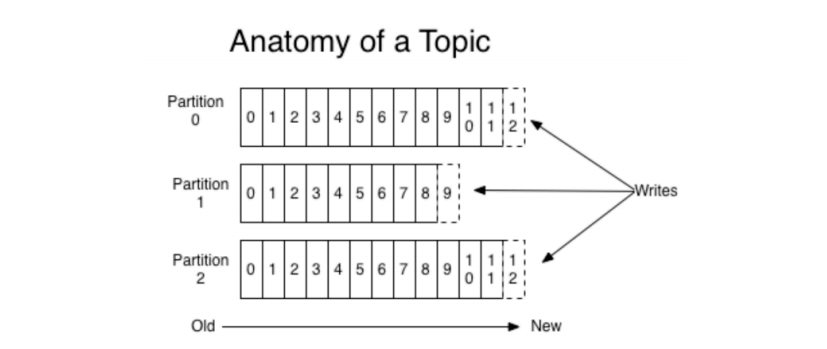
2.分区Partition
1)分区的概念
通过partition将⼀个topic中的消息分区来存储。这样的好处有多个:
- 分区存储,可以解决统⼀存储⽂件过⼤的问题
- 提供了读写的吞吐量:读和写可以同时在多个分区中进⾏
2)创建多分区的主题
./kafka-topics.sh --create --zookeeper 192.168.200.140:2181 --replication-factor 1 --partitions 2 --topic test1可以通过这样的命令查看topic的分区信息
./kafka-topics.sh --describe --zookeeper 192.168.200.140:2181 --topic test13. kafka 中消息⽇志⽂件中保存的内容
- 00000.log: 这个⽂件中保存的就是消息
- __consumer_offsets-49:
kafka内部⾃⼰创建了__consumer_offsets主题包含了50个分区。这个主题⽤来存放消费者消费某个主题的偏移量。因为每个消费者都会⾃⼰维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量⾃主上报给kafka中的默认主题: consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区。
- 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets主题的分区数
- 提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前offset的值
- ⽂件中保存的消息,默认保存7天。七天到后消息会被删除。
五、 Kafka 集群操作
1.搭建 kafka 集群(三个broker)
-
创建三个server.properties⽂件
0 1 2
broker.id=2
// 9092 9093 9094
listeners=PLAINTEXT://192.168.65.60:9094
//kafka-logs kafka-logs-1 kafka-logs-2
log.dir=/usr/local/data/kafka-logs-2 -
通过命令来启动三台broker
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
校验是否启动成功
进⼊到zk中查看/brokers/ids中过是否有三个znode(0,1,2)
2.副本的概念
在创建主题时,除了指明了主题的分区数以外,还指明了副本数,那么副本是⼀个什么概念
呢?
./kafka-topics.sh --create --zookeeper 192.168.200.140:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic副本是为了为主题中的分区创建多个备份,多个副本在kafka集群的多个broker中,会有⼀个
副本作为leader,其他是follower。
查看topic情况:
# 查看topic情况
./kafka-topics.sh --describe --zookeeper 192.168.200.140:2181 --topic my-replicated-topic
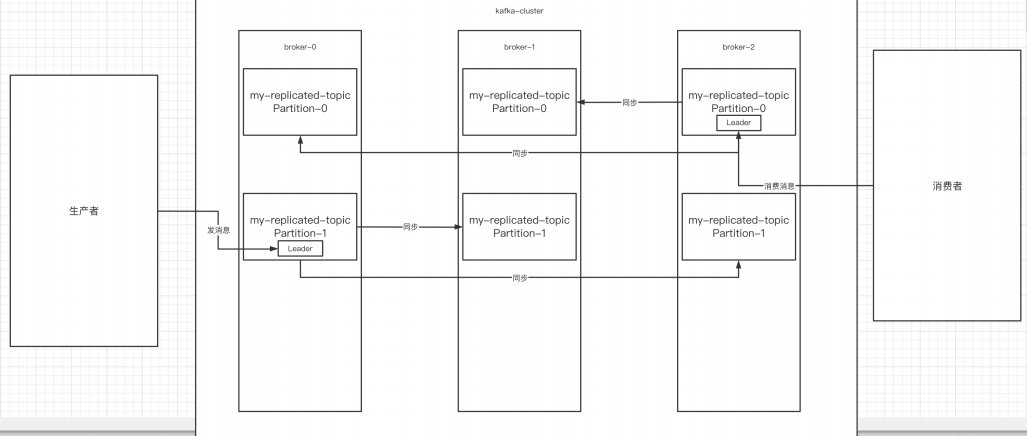
- leader: kafka的写和读的操作,都发⽣在leader上。leader负责把数据同步给follower。当leader挂
了,经过主从选举,从多个follower中选举产⽣⼀个新的leader
- follower :接收leader的同步的数据
- isr: :可以同步和已同步的节点会被存⼊到isr集合中。这⾥有⼀个细节:如果isr中的节点性能
较差,会被提出isr集合。
一个分区 = 多个一模一样的副本
副本实际上就是复制了一份分区,存入broker中,实际上还是分区
此时,broker、主题、分区、副本 这些概念就全部展现了
⼤家需要把这些概念梳理清楚:
集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存
储),可以为分区创建多个副本,不同的副本存放在不同的broker⾥。
3.关于集群消费
1)向集群发送消息:
./kafka-console-producer.sh --broker-list 192.168.200.140:9092,192.168.200.140:9093,192.168.200.140:9094 --topic my-replicated-topic2)从集群中消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092,192.168.200.140:9093,192.168.200.140:9094 --from-beginning --topic my-replicated-topic3)指定消费组来消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.200.140:9092,192.168.200.140:9093,192.168.200.140:9094 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic4)分区分消费组的集群消费中的细节
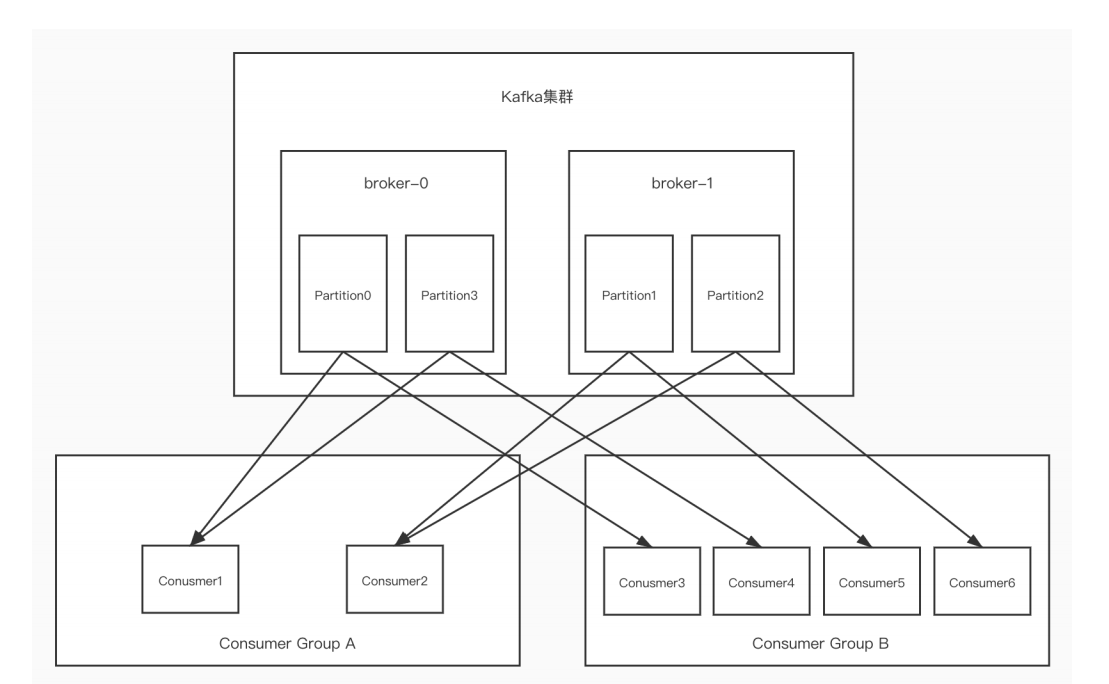
- ⼀个partition只能被⼀个消费组中的⼀个消费者消费,⽬的是为了保证消费的顺序性,但 是多个partion的多个消费者消费的总的顺序性是得不到保证的,那怎么做到消费的总顺序性呢?
- partition的数量决定了消费组中消费者的数量,建议同⼀个消费组中消费者的数量不要超过partition的数量,否则多的消费者消费不到消息
- 如果消费者挂了,那么会触发rebalance机制(后⾯介绍),会让其他消费者来消费该分区
同一个消费组 = 单播模式(负载均衡实现单播)
不同消费组 = 广播模式
同一个消费组内: 负载均衡 ,消息均分!(每条消息发到不同的分区)
- 同一个组里开 2 个消费者
- 消息会被分摊 ,一条消息只会被组内一个消费者消费
- 用于提高消费速度