一、为什么需要学习率调度?
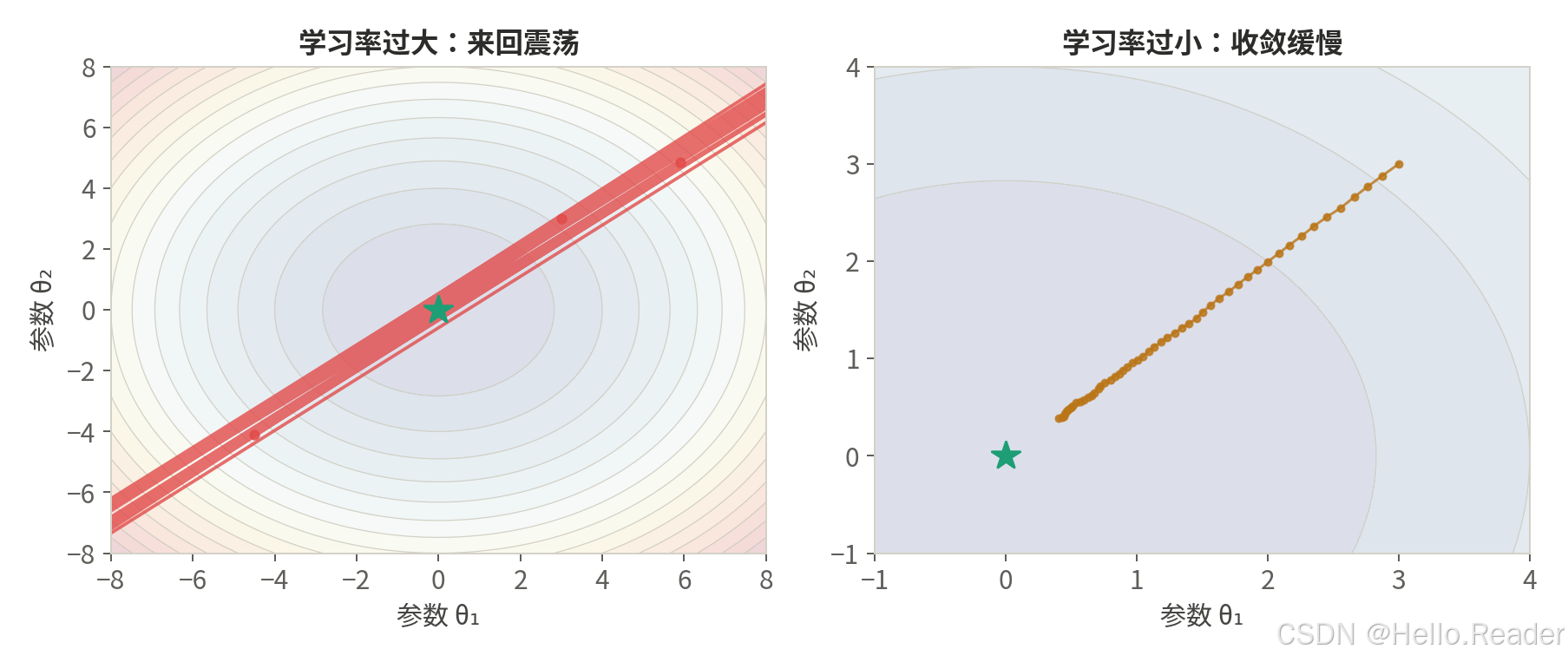
学习率控制着参数更新的步长。如果把模型训练比作下山:
- 学习率过大:步子迈得太大,在山谷里来回跳跃,甚至越跳越远(发散)。
- 学习率过小:步子太小,下山极慢,还容易卡在半山腰的小坑里(局部最优)。
- 理想策略:开始大步走(快速接近山谷),越接近谷底步子越小(精细搜索最优点)。
学习率调度器(LR Scheduler)就是自动实现这个"由大到小"或"动态调整"过程的工具。
训练循环中的调度器用法
在 PyTorch 中,调度器的使用模式非常统一:
python
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(num_epochs):
train(model, optimizer)
val_loss = validate(model)
scheduler.step() # 每个 epoch 结束后调用注意 scheduler.step() 应在 optimizer.step() 之后、每个 epoch 结束时调用(PyTorch 1.1+ 的约定)。
二、八大调度器详解
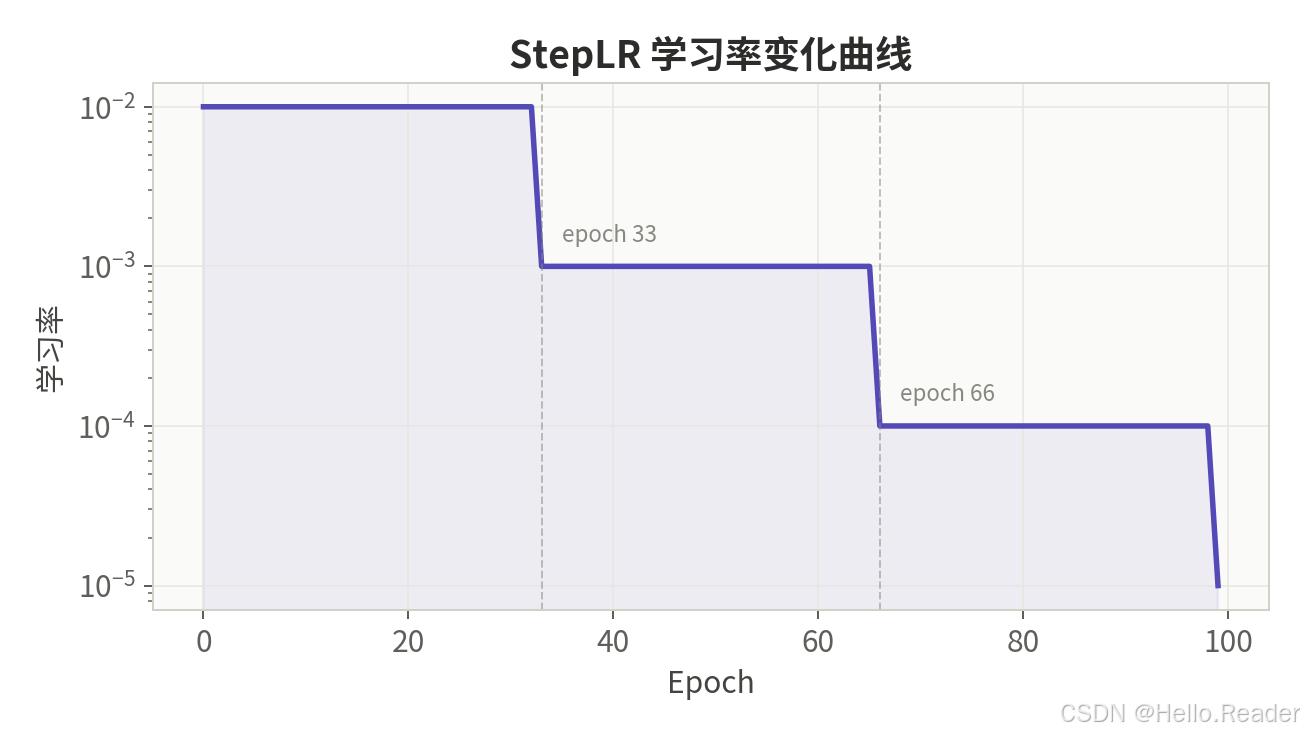
2.1 StepLR ------ 阶梯衰减
核心思想:每隔固定步数(step_size),将学习率乘以衰减因子 gamma。
数学公式:
lr epoch = lr init × γ ⌊ epoch / step_size ⌋ \text{lr}{\text{epoch}} = \text{lr}{\text{init}} \times \gamma^{\lfloor \text{epoch} / \text{step\_size} \rfloor} lrepoch=lrinit×γ⌊epoch/step_size⌋
其中 γ \gamma γ 通常取 0.1,step_size 通常为总 epoch 数的 1/3。
PyTorch 实现:
python
scheduler = optim.lr_scheduler.StepLR(
optimizer,
step_size=30, # 每 30 个 epoch 衰减一次
gamma=0.1 # 每次乘以 0.1
)适用场景:CNN 图像分类(ResNet 原论文即采用此策略)。
优点:实现简单,行为可预测,易于调试。
缺点:阶梯式跳变可能导致训练不稳定;衰减时机固定,缺乏自适应能力。
2.2 MultiStepLR ------ 多阶梯衰减
StepLR 的灵活版本,允许在指定的 epoch 列表处进行衰减。
数学公式:
lr epoch = lr init × γ ∣ { m ∈ milestones : m ≤ epoch } ∣ \text{lr}{\text{epoch}} = \text{lr}{\text{init}} \times \gamma^{|\{m \in \text{milestones} : m \leq \text{epoch}\}|} lrepoch=lrinit×γ∣{m∈milestones:m≤epoch}∣
PyTorch 实现:
python
scheduler = optim.lr_scheduler.MultiStepLR(
optimizer,
milestones=[60, 80, 90], # 在第 60、80、90 epoch 衰减
gamma=0.1
)适用场景:当你通过实验观察到 loss 在某些特定 epoch 出现平台期时,可以手动指定衰减点。
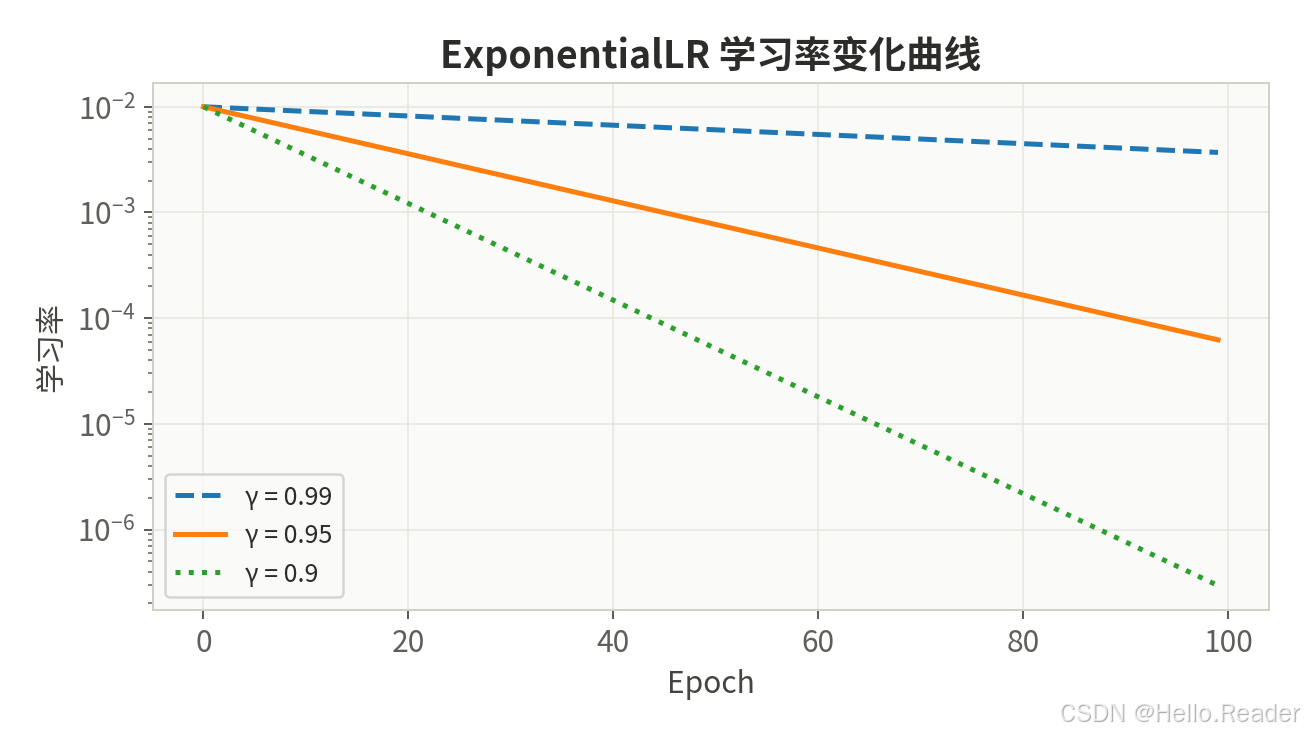
2.3 ExponentialLR ------ 指数衰减
核心思想:每个 epoch 将学习率乘以 gamma(略小于 1),实现连续平滑的指数下降。
数学公式:
lr epoch = lr init × γ epoch \text{lr}{\text{epoch}} = \text{lr}{\text{init}} \times \gamma^{\text{epoch}} lrepoch=lrinit×γepoch
gamma 通常取 0.9 ~ 0.99。
PyTorch 实现:
python
scheduler = optim.lr_scheduler.ExponentialLR(
optimizer, gamma=0.95
)
# gamma=0.95 → 100 个 epoch 后 lr 降为初始值的 0.6%
# gamma=0.99 → 100 个 epoch 后 lr 降为初始值的 36.6%适用场景:RNN、语音识别等需要持续细化的任务。
优点:曲线平滑无突变,只有一个超参。
缺点:后期学习率可能衰减到极小值导致训练停滞;gamma 选择比较敏感。
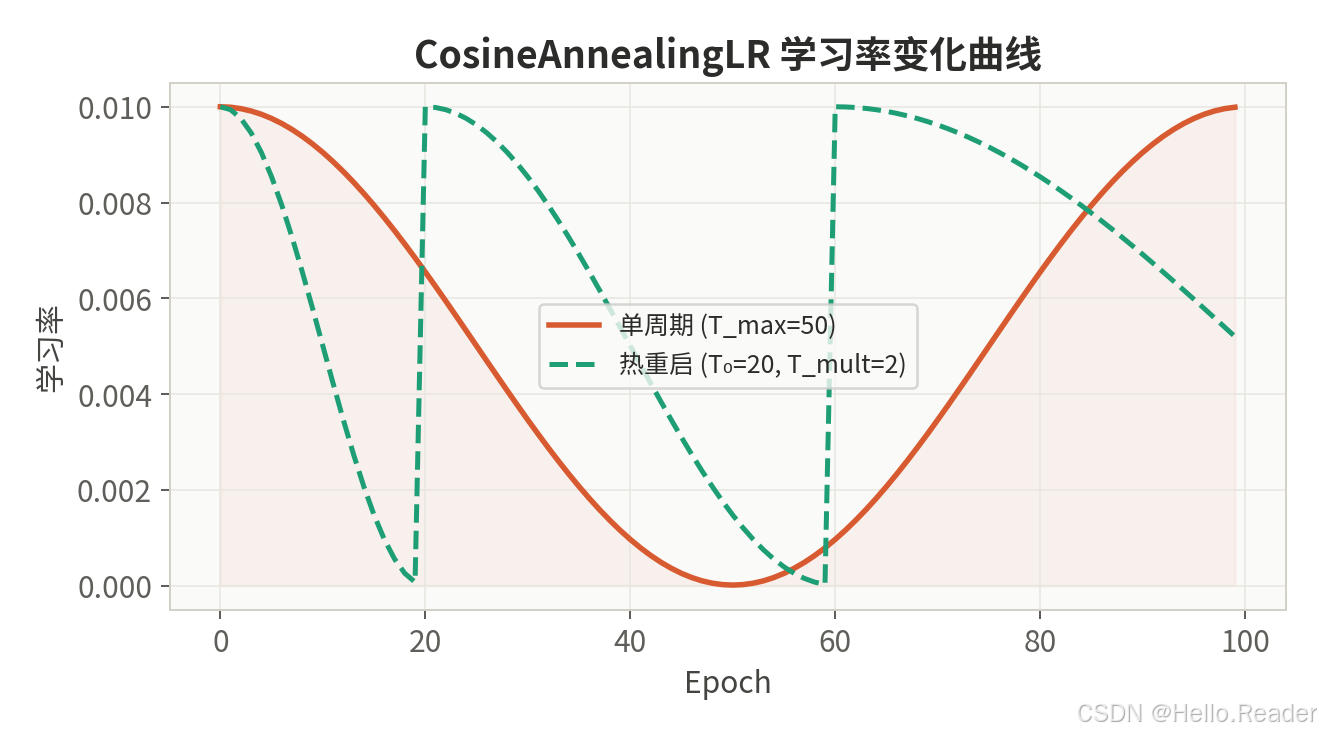
2.4 CosineAnnealingLR ------ 余弦退火
核心思想:学习率按余弦函数从初始值平滑下降到最小值。SGDR(Stochastic Gradient Descent with Warm Restarts)论文推广了带热重启的版本。
数学公式:
lr t = η min + 1 2 ( η max − η min ) ( 1 + cos ( t T max π ) ) \text{lr}t = \eta{\min} + \frac{1}{2}(\eta_{\max} - \eta_{\min})\left(1 + \cos\left(\frac{t}{T_{\max}} \pi\right)\right) lrt=ηmin+21(ηmax−ηmin)(1+cos(Tmaxtπ))
其中 T max T_{\max} Tmax 是半周期长度, η min \eta_{\min} ηmin 是最小学习率。
PyTorch 实现:
python
# 单周期余弦退火
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=50, # 半周期长度
eta_min=1e-5 # 最小学习率
)
# 带热重启的版本(SGDR)
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=10, # 初始周期长度
T_mult=2 # 每次重启后周期翻倍
)适用场景:ImageNet 训练、各类视觉任务。
优点:曲线平滑,理论上优于阶梯衰减;热重启版本可逃离局部最优。
缺点:需要提前知道总训练长度;周期设置不当效果下降明显。
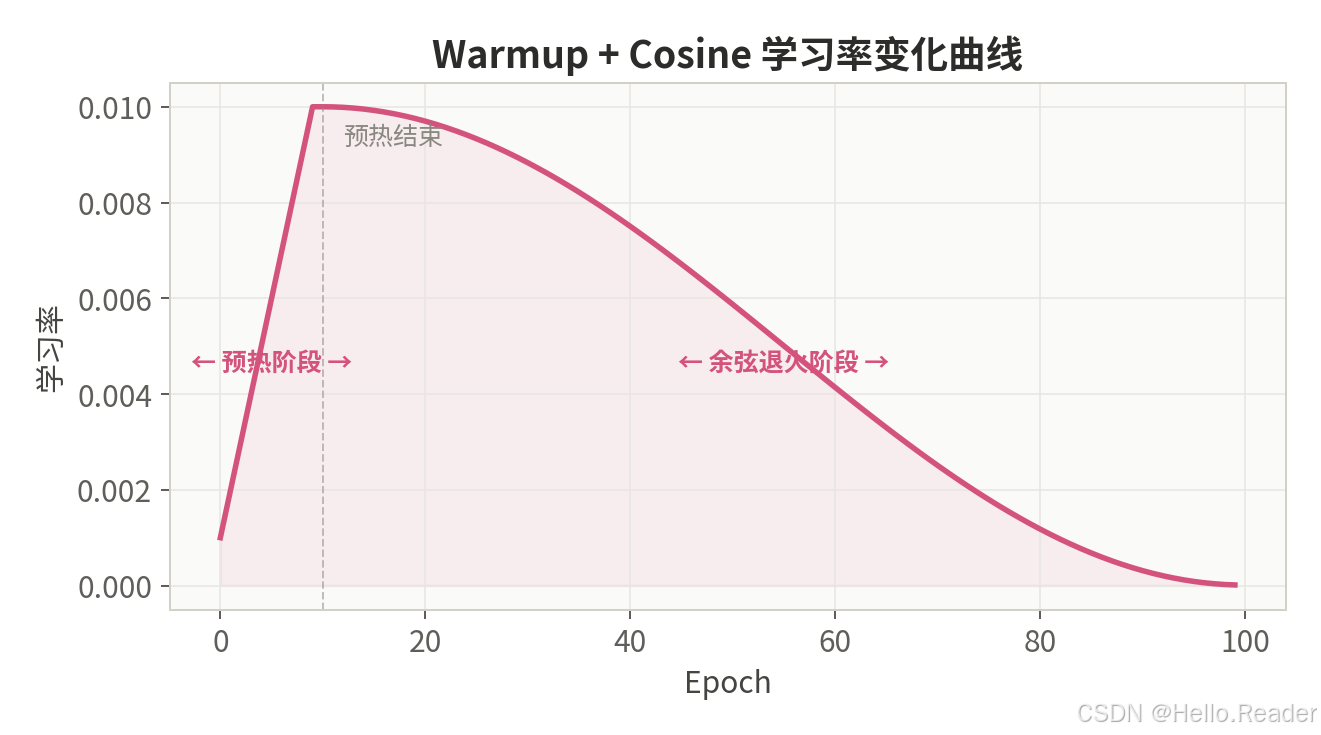
2.5 Warmup + Cosine ------ 预热 + 余弦退火
核心思想:分两阶段------先线性预热,学习率从接近 0 增长到目标值;再切换为余弦退火逐渐降低。预热阶段让参数先稳定下来,避免初始梯度过大导致训练崩溃。
这是几乎所有 Transformer 模型(BERT、GPT、ViT、LLaMA 等)的标配策略。
数学公式:
预热阶段( t < T warmup t < T_{\text{warmup}} t<Twarmup):
lr t = lr init × t + 1 T warmup \text{lr}t = \text{lr}{\text{init}} \times \frac{t + 1}{T_{\text{warmup}}} lrt=lrinit×Twarmupt+1
余弦阶段( t ≥ T warmup t \geq T_{\text{warmup}} t≥Twarmup):
lr t = η min + 1 2 ( lr init − η min ) ( 1 + cos ( π ⋅ t − T warmup T total − T warmup ) ) \text{lr}t = \eta{\min} + \frac{1}{2}(\text{lr}{\text{init}} - \eta{\min})\left(1 + \cos\left(\pi \cdot \frac{t - T_{\text{warmup}}}{T_{\text{total}} - T_{\text{warmup}}}\right)\right) lrt=ηmin+21(lrinit−ηmin)(1+cos(π⋅Ttotal−Twarmupt−Twarmup))
PyTorch 实现:
python
# 方法 1:LambdaLR 自定义
import math
def lr_lambda(epoch):
warmup_epochs = 10
total_epochs = 100
if epoch < warmup_epochs:
return (epoch + 1) / warmup_epochs
progress = (epoch - warmup_epochs) / (total_epochs - warmup_epochs)
return 0.5 * (1 + math.cos(math.pi * progress))
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
# 方法 2:Hugging Face transformers 库(推荐)
from transformers import get_cosine_schedule_with_warmup
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=1000,
num_training_steps=10000
)适用场景:Transformer 训练(NLP、CV 均适用),几乎是现代大模型训练的事实标准。
优点:避免初期梯度爆炸,兼顾训练稳定性与最终精度。
缺点:需要设置预热步数,实现稍复杂。
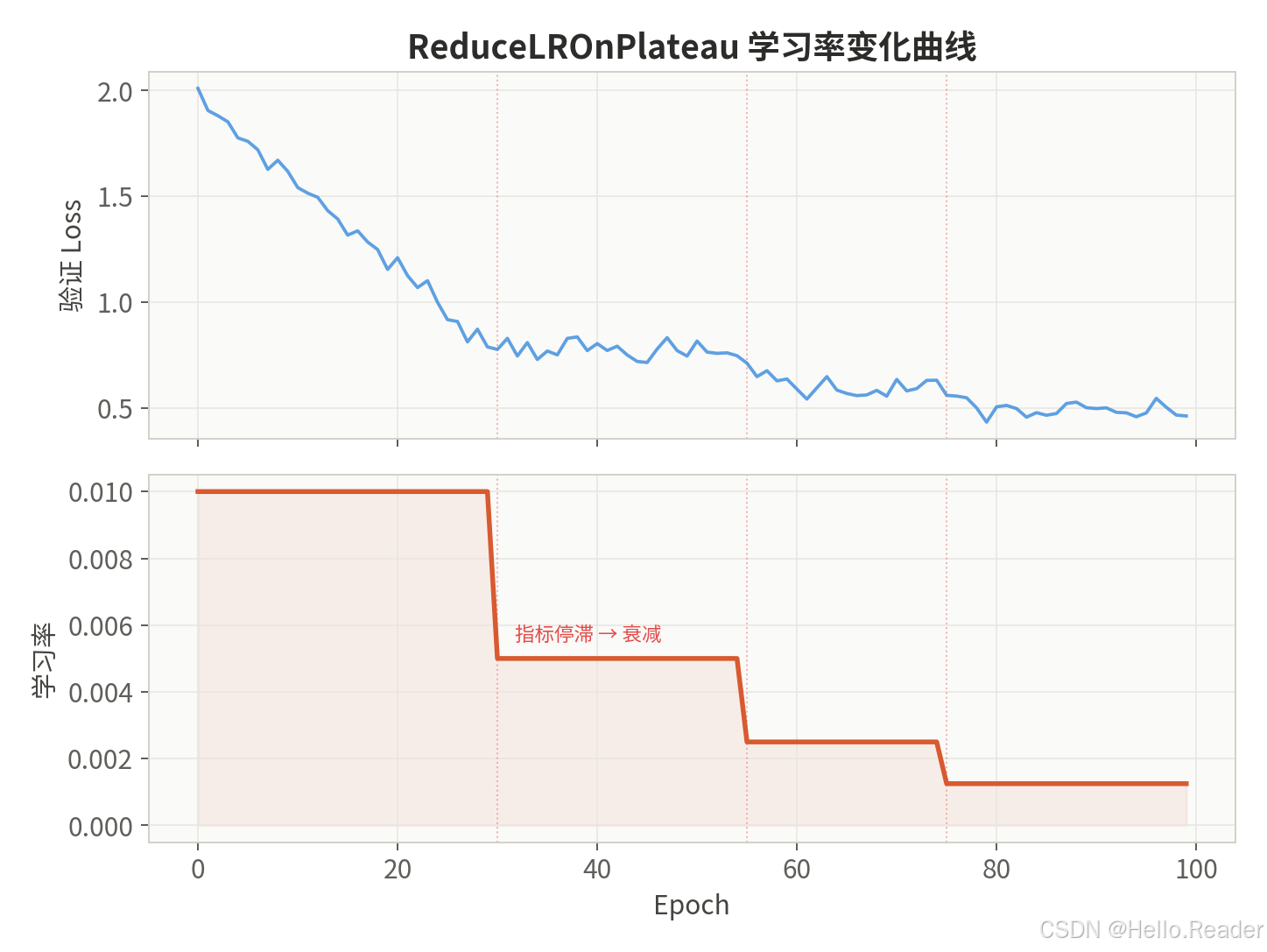
2.6 ReduceLROnPlateau ------ 自适应衰减
核心思想:监控验证集指标(loss 或 accuracy),当连续 patience 个 epoch 没有改善时,自动将学习率乘以 factor。这是唯一一种"响应式"策略。
衰减规则:
若连续 patience 个 epoch 指标未改善: lr new = lr current × factor \text{若连续 patience 个 epoch 指标未改善:} \quad \text{lr}{\text{new}} = \text{lr}{\text{current}} \times \text{factor} 若连续 patience 个 epoch 指标未改善:lrnew=lrcurrent×factor
PyTorch 实现:
python
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 'min' 监控 loss,'max' 监控 accuracy
factor=0.5, # 每次衰减为原来的 50%
patience=10, # 容忍 10 个 epoch 无改善
min_lr=1e-6, # 学习率下限
verbose=True # 打印衰减日志
)
for epoch in range(num_epochs):
train(model, optimizer)
val_loss = validate(model)
scheduler.step(val_loss) # 注意:必须传入监控指标适用场景:微调预训练模型、训练长度不确定的探索性实验。
优点:完全自适应,无需预设衰减时间表。
缺点:依赖验证集指标的可靠性;patience 设置需要经验。
注意 :与其他调度器不同,ReduceLROnPlateau 的
step()方法需要传入监控指标(如val_loss)。
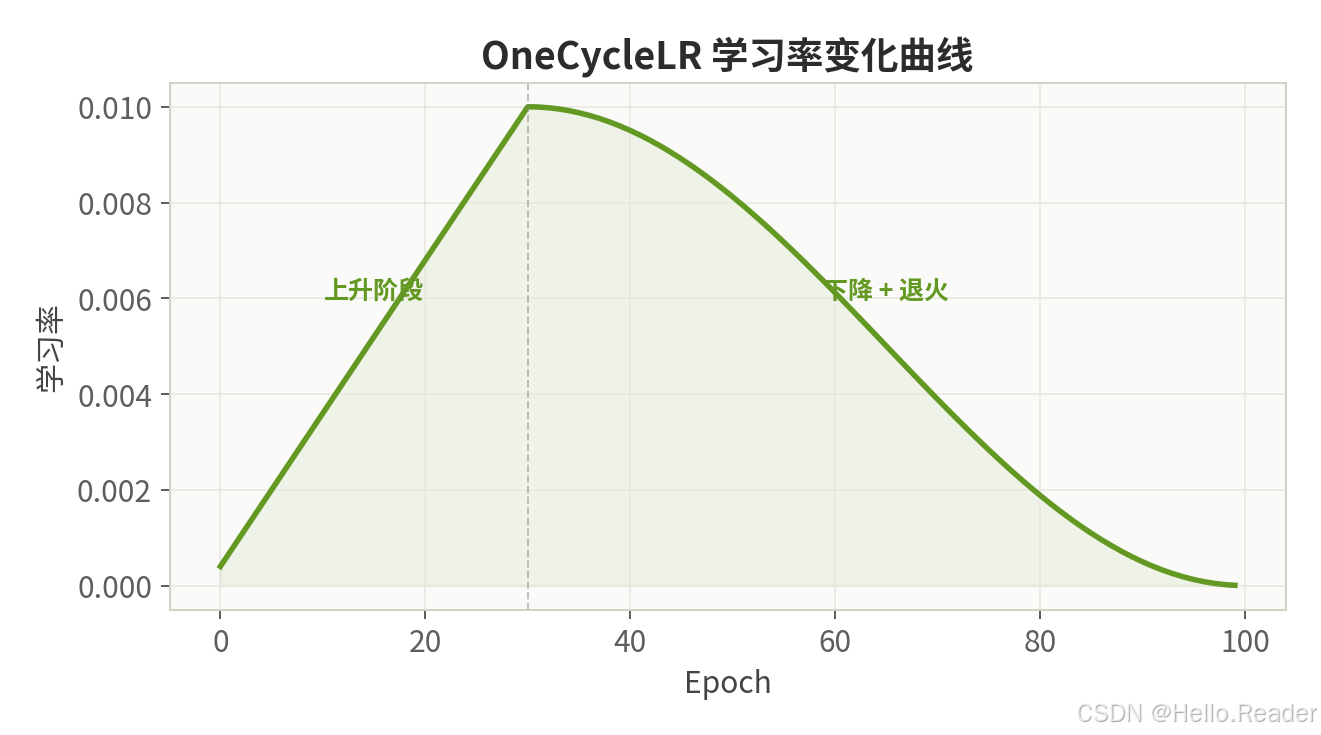
2.7 OneCycleLR ------ 超级收敛
核心思想:由 Leslie Smith 在"Super-Convergence"论文中提出。训练分为三段:
- 上升阶段 (约占 30%):学习率从
max_lr / div_factor线性上升到max_lr。 - 下降阶段 (约占 70%):学习率从
max_lr余弦下降到初始值。 - 退火尾声 :学习率继续降到极小值
max_lr / (div_factor × final_div_factor)。
PyTorch 实现:
python
scheduler = optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=0.01,
total_steps=100,
pct_start=0.3, # 上升阶段占 30%
div_factor=25, # 初始 lr = max_lr / 25
final_div_factor=1e4, # 最终 lr = max_lr / (25 × 1e4)
anneal_strategy='cos' # 下降阶段用余弦退火
)
# 注意:OneCycleLR 是按 step(batch)更新,不是按 epoch
for epoch in range(num_epochs):
for batch in train_loader:
train_step(model, optimizer, batch)
scheduler.step() # 每个 batch 后调用适用场景:ResNet 快速训练、配合大 batch size 使用。
优点:能实现"超级收敛",大幅减少所需训练 epoch。
缺点:需预先确定总步数,对 max_lr 选择敏感。
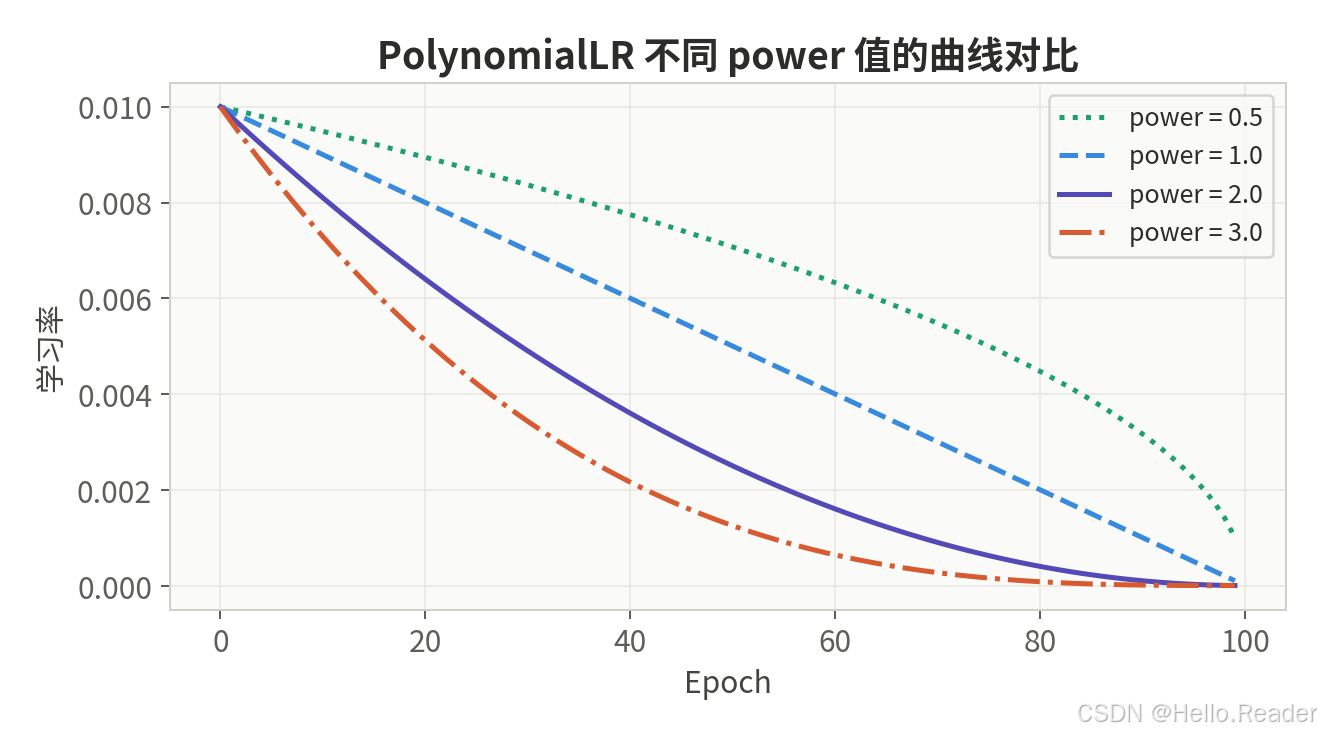
2.8 PolynomialLR ------ 多项式衰减
核心思想:学习率按多项式函数衰减,power 参数控制衰减曲线的形状。
数学公式:
lr epoch = ( lr init − lr end ) × ( 1 − epoch T total ) power + lr end \text{lr}{\text{epoch}} = (\text{lr}{\text{init}} - \text{lr}{\text{end}}) \times \left(1 - \frac{\text{epoch}}{T{\text{total}}}\right)^{\text{power}} + \text{lr}_{\text{end}} lrepoch=(lrinit−lrend)×(1−Ttotalepoch)power+lrend
power = 1:线性衰减power > 1:前期衰减慢,后期加速(如 power=2 为二次衰减)power < 1:前期衰减快,后期趋于平缓
PyTorch 实现:
python
# PyTorch 1.13+ 内置
scheduler = optim.lr_scheduler.PolynomialLR(
optimizer,
total_iters=100,
power=2.0 # 二次衰减
)
# 旧版本手动实现
def poly_lr_lambda(epoch):
total_epochs = 100
power = 0.9
return (1 - epoch / total_epochs) ** power
scheduler = optim.lr_scheduler.LambdaLR(optimizer, poly_lr_lambda)适用场景:语义分割(DeepLab 系列)、目标检测。
优点:衰减形状灵活可调,power=1 时就是线性衰减。
缺点:需要预知总训练步数,power 最佳值依赖任务。
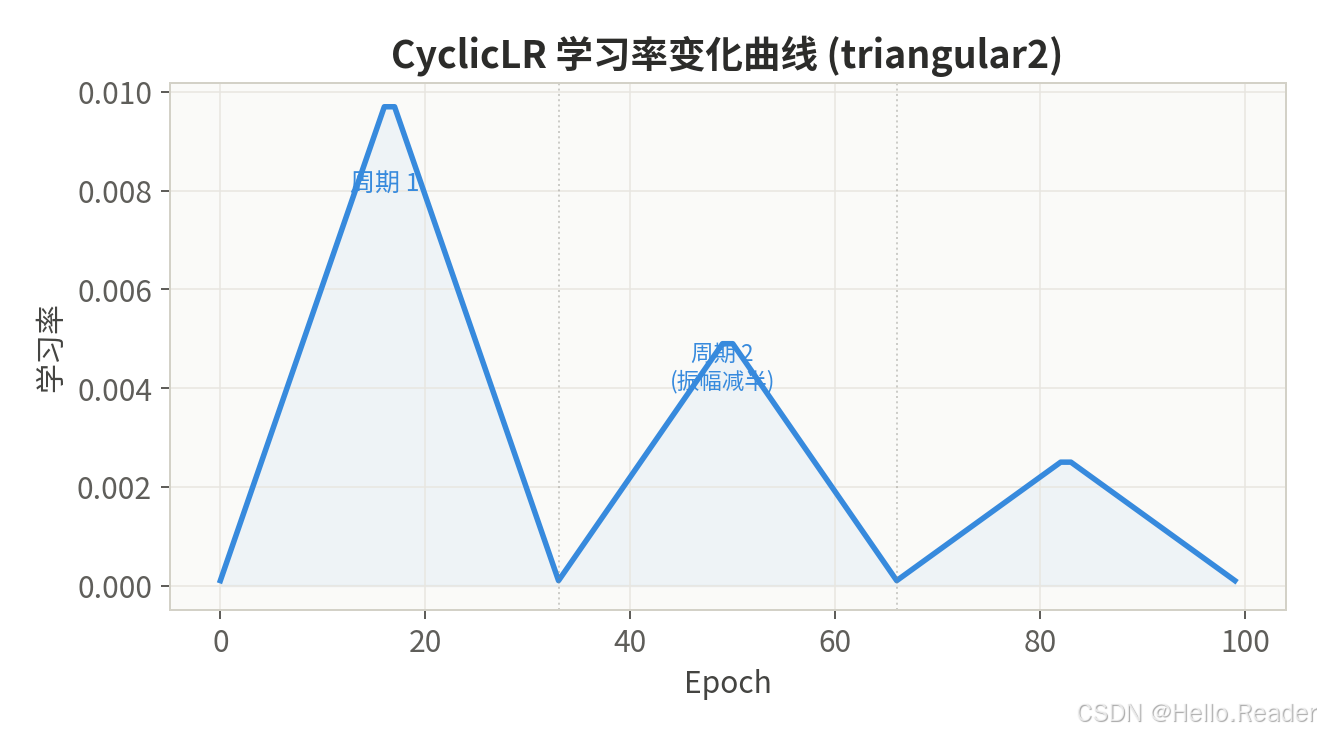
2.9 CyclicLR ------ 周期性学习率
核心思想 :学习率在 base_lr 和 max_lr 之间周期性波动。triangular2 模式下每个周期的振幅减半。理论依据是周期性提高学习率有助于跳过尖锐的局部最小值,倾向于收敛到更平坦、泛化更好的区域。
数学公式(triangular2 模式):
cycle = ⌊ epoch / ( 2 × step_size ) ⌋ \text{cycle} = \lfloor \text{epoch} / (2 \times \text{step\_size}) \rfloor cycle=⌊epoch/(2×step_size)⌋
x = ∣ epoch step_size − 2 × cycle − 1 ∣ x = \left| \frac{\text{epoch}}{\text{step\_size}} - 2 \times \text{cycle} - 1 \right| x= step_sizeepoch−2×cycle−1
lr = base_lr + ( max_lr − base_lr ) × max ( 0 , 1 − x ) × 1 2 cycle \text{lr} = \text{base\_lr} + (\text{max\_lr} - \text{base\_lr}) \times \max(0, 1 - x) \times \frac{1}{2^{\text{cycle}}} lr=base_lr+(max_lr−base_lr)×max(0,1−x)×2cycle1
PyTorch 实现:
python
scheduler = optim.lr_scheduler.CyclicLR(
optimizer,
base_lr=1e-4, # 下界
max_lr=0.01, # 上界
step_size_up=2000, # 上升半周期(以 batch 为单位)
mode='triangular2', # 振幅逐周期减半
cycle_momentum=False # 搭配 Adam 时设为 False
)适用场景:小数据集、快速实验、学习率范围探索。
优点:无需精确设置总训练长度,能跳出尖锐局部最优。
缺点:波动可能导致训练不稳定,上下界设置需要经验。
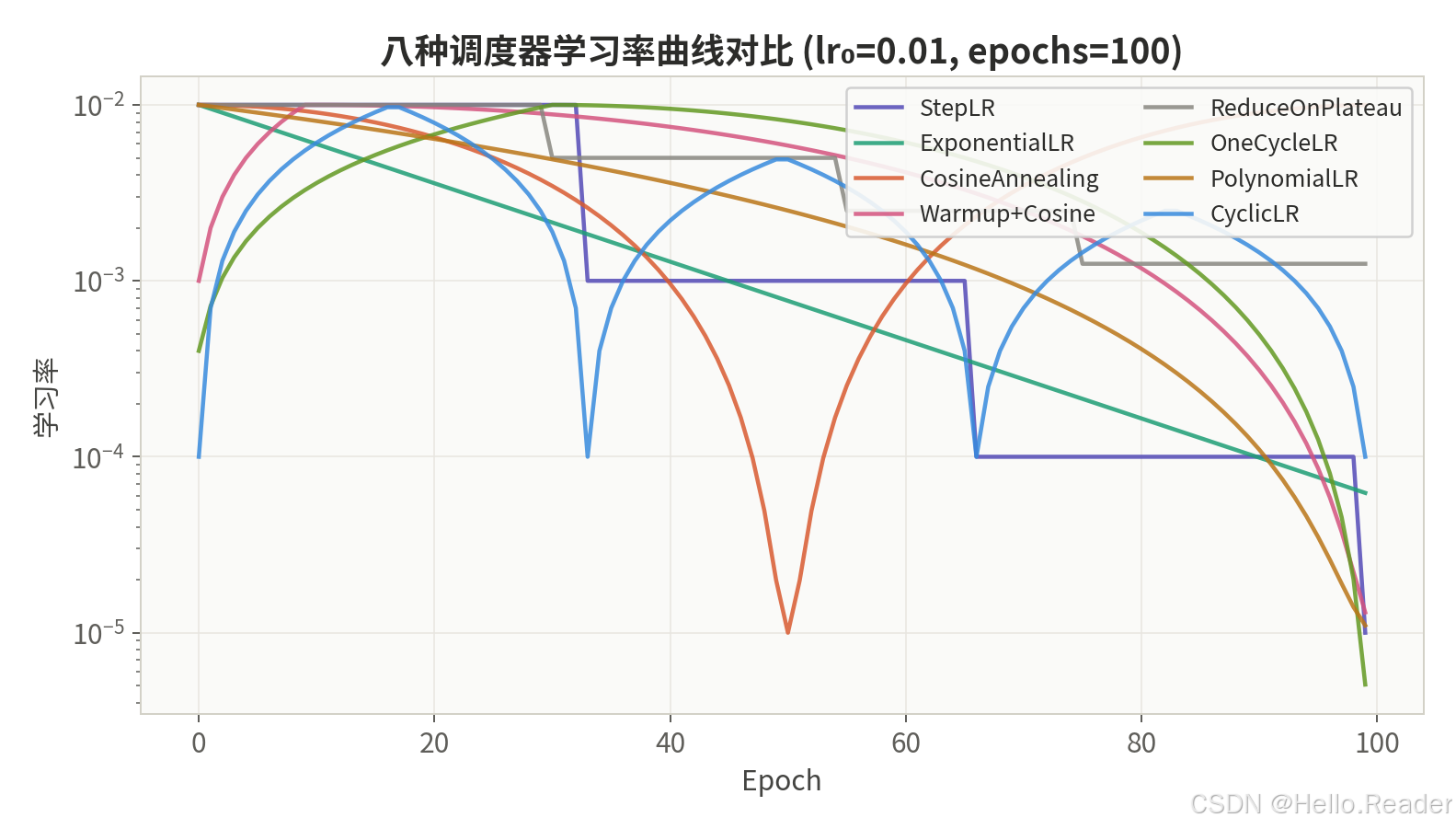
三、全部调度器对比
下图展示了在相同初始学习率(0.01)和总 epoch(100)下,8 种调度器的学习率变化曲线对比。
对比总结表
| 调度器 | 衰减方式 | 需要预设总步数 | 自适应 | 典型场景 |
|---|---|---|---|---|
| StepLR | 阶梯式 | 否 | 否 | CNN 分类 |
| MultiStepLR | 多阶梯 | 否 | 否 | 自定义衰减节点 |
| ExponentialLR | 指数平滑 | 否 | 否 | RNN / 语音 |
| CosineAnnealingLR | 余弦曲线 | 是 | 否 | ImageNet 训练 |
| Warmup + Cosine | 预热 + 余弦 | 是 | 否 | Transformer 全系列 |
| ReduceLROnPlateau | 响应式 | 否 | 是 | 微调 / 探索性实验 |
| OneCycleLR | 升 → 降 → 退火 | 是 | 否 | 快速训练 / 大 batch |
| PolynomialLR | 多项式 | 是 | 否 | 语义分割 |
| CyclicLR | 周期波动 | 否 | 否 | 小数据 / 快速实验 |
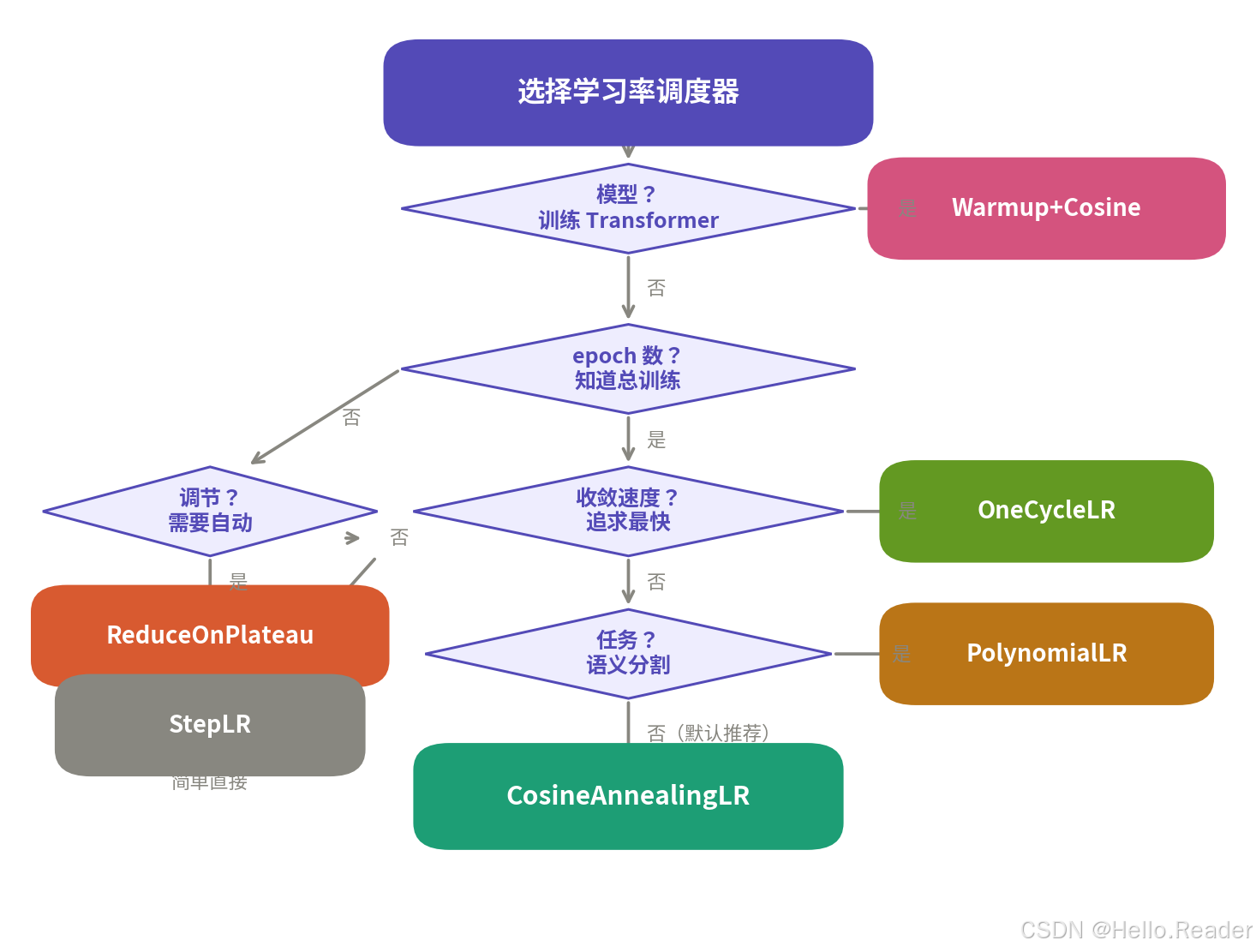
四、如何选择调度器?
按任务类型选
- CNN 图像分类(ResNet、EfficientNet)→ StepLR 或 CosineAnnealingLR
- Transformer 模型(BERT、GPT、ViT、LLaMA)→ Warmup + Cosine(几乎是唯一选择)
- 语义分割(DeepLab、SegFormer)→ PolynomialLR(power=0.9)
- 目标检测(YOLO、Faster R-CNN)→ StepLR、MultiStepLR 或 CosineAnnealingLR
- 微调预训练模型(不确定训练多久)→ ReduceLROnPlateau
- 快速训练 / 大 batch→ OneCycleLR
按经验法则选
- 不知道选什么? 用 CosineAnnealingLR,它在绝大多数场景都有不错的表现。
- 训练 Transformer? 用 Warmup + Cosine,不用犹豫。
- 不确定总 epoch 数? 用 ReduceLROnPlateau,让训练动态自己决定。
- 想要最快收敛? 试试 OneCycleLR + 大 batch size。
- 任务简单 / 赶时间? StepLR 足够了。
五、进阶技巧
5.1 组合调度器(ChainedScheduler / SequentialLR)
PyTorch 支持将多个调度器串联:
python
scheduler1 = optim.lr_scheduler.LinearLR(
optimizer, start_factor=0.01, total_iters=10
)
scheduler2 = optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=90
)
scheduler = optim.lr_scheduler.SequentialLR(
optimizer,
schedulers=[scheduler1, scheduler2],
milestones=[10] # 第 10 epoch 从 scheduler1 切换到 scheduler2
)5.2 学习率查找器(LR Finder)
在正式训练前,用 LR Range Test 找到最佳学习率范围:
python
# 使用 torch-lr-finder 库
from torch_lr_finder import LRFinder
finder = LRFinder(model, optimizer, criterion)
finder.range_test(train_loader, end_lr=10, num_iter=100)
finder.plot() # 选择 loss 下降最快的区间
finder.reset()找到的最佳学习率可以直接用作 OneCycleLR 的 max_lr 或 CyclicLR 的 max_lr。
5.3 不同参数组使用不同学习率
微调预训练模型时,通常对骨干网络和新增层使用不同的学习率:
python
optimizer = optim.Adam([
{'params': model.backbone.parameters(), 'lr': 1e-5}, # 骨干:小学习率
{'params': model.head.parameters(), 'lr': 1e-3} # 新增层:大学习率
])
# 调度器会同时作用于所有参数组
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)5.4 监控学习率变化
训练时记录学习率有助于调试:
python
# 方法 1:获取当前学习率
current_lr = optimizer.param_groups[0]['lr']
# 方法 2:配合 TensorBoard
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
for epoch in range(num_epochs):
train(model, optimizer)
scheduler.step()
writer.add_scalar('lr', optimizer.param_groups[0]['lr'], epoch)六、常见误区
-
在
optimizer.step()之前调用scheduler.step():PyTorch 1.1+ 要求先执行优化器更新,再执行调度器更新,否则第一个 epoch 的学习率会被跳过。 -
ReduceLROnPlateau 忘记传入指标 :这个调度器的
step()方法需要传入验证指标(如val_loss),不能像其他调度器一样直接scheduler.step()。 -
OneCycleLR 按 epoch 更新:OneCycleLR 设计上是按 batch(step)更新的,如果按 epoch 更新会导致学习率变化过慢。
-
混淆 T_max 和 total_epochs :CosineAnnealingLR 的
T_max是半周期长度。如果你的总训练长度是 100 epoch 且只想做一个完整周期,应设T_max=100。 -
Warmup 步数设置过大:预热阶段通常只占总训练的 5%~10%。过长的预热会浪费训练时间,过短则可能达不到稳定效果。
七、总结
学习率调度是深度学习训练中不可或缺的技术。核心要点:
- 没有"万能"的调度器,选择取决于任务、模型架构和训练预算。
- Warmup + Cosine 已成为现代深度学习(尤其是 Transformer)的事实标准。
- CosineAnnealingLR 是最通用的选择,适合大多数场景。
- ReduceLROnPlateau 是最"省心"的选择,适合不确定训练长度的场景。
- 善用 LR Finder 可以大幅减少超参调优的时间。
- 训练时务必监控和记录学习率变化曲线,它是排查训练问题的重要线索。