文章目录
- 一、概述
-
- [1.1 语义分割](#1.1 语义分割)
- [1.2 SETR](#1.2 SETR)
- 二、结构
-
- [2.1 输入预处理](#2.1 输入预处理)
- [2.2 Encoder结构](#2.2 Encoder结构)
- [2.2 Decoder(解码器)](#2.2 Decoder(解码器))
-
- [2.2.1 基础上采样(Naive Upsampling)](#2.2.1 基础上采样(Naive Upsampling))
- [2.2.2 渐进式上采样(Progressive Upsampling)](#2.2.2 渐进式上采样(Progressive Upsampling))
- [2.2.3 多层次特征聚合(Multi-Level Feature Aggregation)](#2.2.3 多层次特征聚合(Multi-Level Feature Aggregation))
- [2.3 输出](#2.3 输出)
- 三、总结
一、概述
1.1 语义分割
图像分类和语义分割:
图像分类:输入一张图片,输出一个或多个类别。只关心整张图的主体是什么,不关心位置、形状、边界。模型关心全局语义、整体特征,不需要空间细节,不需要位置信息。- CNN:ResNet、VGG、MobileNet
- Transformer:ViT
输入:一张猫的照片。输出:cat
语义分割:给每一个像素分类:这个像素是:人?车?路?天空?猫?狗?背景?模型关心每个像素的类别、物体边缘、形状、位置、多尺度信息(大物体 + 小物体都要识别)。- CNN:FCN、U-Net、DeepLab
- Transformer:SETR、SegFormer、Mask2Former
输入:城市街景图。输出:和原图一样大的彩色掩码图,每个颜色代表一类

| 维度 | 图像分类 | 语义分割 |
|---|---|---|
| 输出粒度 | 图像级别(1 个标签) | 像素级别(H×W 个标签) |
| 是否需要空间结构 | 不需要 | 必须要 |
| 是否需要边缘 / 形状 | 不需要 | 非常需要 |
| 输出形状 | 类别数C | H×W×C |
| 典型模型 | ViT | SETR |
| 特征使用 | 只取全局特征 | 保留所有空间特征 |
| 损失函数 | 交叉熵(单标签) | 逐像素交叉熵 |
1.2 SETR
SETR 是首个纯 Transformer 做语义分割的主流模型,把语义分割看作序列到序列(Seq2Seq)任务,用纯 Transformer 编码器替代传统 CNN 编码器。
论文标题:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
论文链接:https://arxiv.org/abs/2012.15840
官方代码:https://github.com/fudan-zvg/SETR
二、结构
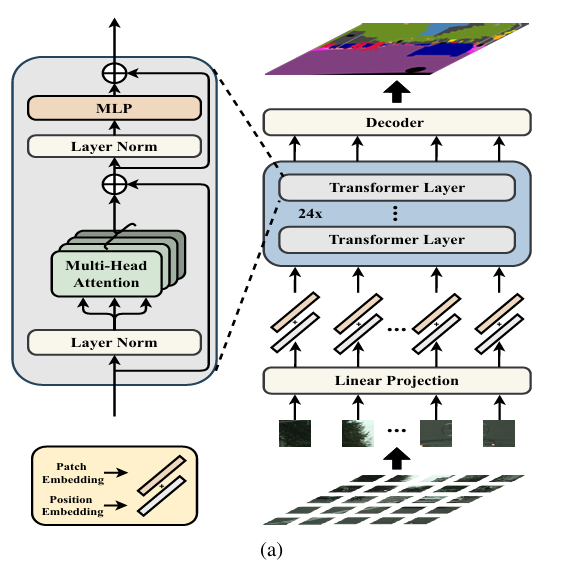
对于SETR,本质是VIT+Decoder结构,其中Decoder主要由三种设计。
2.1 输入预处理
输入:将图像张量 (H,W,3) 转换为嵌入序列 (L,C),为 Transformer 输入做准备。
X ∈ R H × W × C (高度 H )(宽度 W )(通道数 C , R G B 为 3 ) \mathbf{X} \in \mathbb{R}^{H \times W \times C} (高度H)(宽度W)(通道数C,RGB 为 3) X∈RH×W×C(高度H)(宽度W)(通道数C,RGB为3)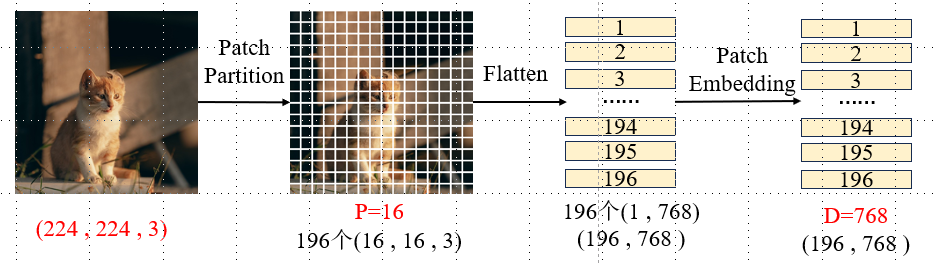
Patch划分:将图像均匀划分为固定大小的 Patch(默认 16×16)Patch展平:将每个 Patch 展平为向量。
分块数量: N u m p a t c h e s = H P × W P 。每个块为: X p ∈ R ( P × P × C ) 分块数量:Num_{patches} = \frac{H}{P} \times \frac{W}{P}。每个块为:\mathbf{X_p} \in \mathbb{R}^{(P \times P \times C)} 分块数量:Numpatches=PH×PW。每个块为:Xp∈R(P×P×C)线性映射:通过线性投影层(Linear Projection)映射为 C 维的特征嵌入。(论文中C=1024)
X 0 ∈ R N × C ( N 个 P a t c h ,每个 C 维) X_0∈\mathbb{R}^{N×C} (N个 Patch,每个C维) X0∈RN×C(N个Patch,每个C维)位置编码:Transformer 本身无序,需为每个位置学习可训练的位置嵌入,与向量逐元素相加,得到最终输入序列,保留空间位置信息。
X = X 0 + P E ∈ R N × C X=X_0+PE∈\mathbb{R}^{N×C} X=X0+PE∈RN×C
| 处理 | 步骤 | ViT | SETR | 结论 |
|---|---|---|---|---|
| 1 | Patch 切分 | 将图像切成固定大小的非重叠 Patch(如 16×16) | Patch 尺寸可选更多(如 16×16/8×8),且支持更大输入分辨率(如 512×512) | 逻辑一致,SETR 为适配分割的高分辨率需求,放宽了 Patch 尺寸 / 输入分辨率限制 |
| 2 | Patch 展平 | 每个 Patch(16×16×3)展平为一维向量(768 维) | 完全一致 | 无差异 |
| 3 | 线性映射 | 展平后的向量经线性层映射为固定维度 Token(如 768 维) | 完全一致 | 无差异 |
| 4 | 位置编码 | ①可学习的位置编码,维度与 Token 一致 ②固定尺寸:训练用 224×224 对应的 PE,推理时输入分辨率必须和训练一致 | ①可学习的位置编码,维度与 Token 一致(和 ViT 相同) ②可插值的 PE:训练用固定尺寸 PE,推理时若输入分辨率不同,对 PE 做 bilinear 插值,适配新的 Token 数量 | 框架一致,SETR 对 PE 做了插值适配改造 |
| 5 | Class Token | 分类任务需要,在 Token 序列开头添加一个可学习的Class Token | 分割任务不需要全局分类 Token,不添加Class Token | 任务目标差异,但不影响核心输入结构 |
2.2 Encoder结构
Encoder:编码器由多个完全相同的 Transformer 层堆叠而成,每层包含核心组件:
层归一化(Layer Norm):对输入序列做归一化,稳定训练;多头自注意力(MSA, Multi-Head Self-Attention):为每个位置生成查询(Query)、键(Key)、值(Value)向量(均来自同一输入);计算各位置与所有位置的注意力权重,实现全局感受野,建模长距离依赖;多头机制并行学习不同子空间的注意力模式,提升特征表达能力。残差连接(Residual Connection):将 MSA 输出与输入相加,缓解梯度消失;层归一化(Layer Norm):对序列做归一化,稳定训练;多层感知机(MLP):包含两层线性变换 + 中间 GELU 激活,进一步增强特征非线性表达,同样搭配残差连接与 Layer Norm。残差连接(Residual Connection):缓解梯度消失;
输出:
- Naive/PUP Decoder仅用最后一层特征;
- MLA Decoder用多层特征(如 L = 24 L=24 L=24时选 Z 6 , Z 12 , Z 18 , Z 24 Z_6,Z_{12},Z_{18},Z_{24} Z6,Z12,Z18,Z24)
Z = X L ∈ R N × C Z=X_L∈\mathbb{R}^{N×C} Z=XL∈RN×C
论文提供两种编码器变体,适配不同算力与性能需求:
| 配置 | 嵌入维度C | 编码器的层数 | 注意力头数 | 参数规模 |
|---|---|---|---|---|
| T-Base | 768 | 12 | 12 | ~87M |
| T-Large | 1024 | 24 | 16 | ~305M |
ViT 和 SETR 都复用上述这套结构,SETR 本质是基于 ViT 改造的语义分割模型。差异不在【单层怎么做】,而在【多层怎么用】。
| 差异维度 | ViT(分类) | SETR(分割) | 差异原因 |
|---|---|---|---|
| 特征输出方式 | ① 仅保留最后一层的输出; ② 只取Class Token或对所有Token全局池化; ③ 输出:Batch, 1, Dim(全局特征) | ① 保留所有层的输出,至少抽取关键层6/12/18/24; ② 保留所有 Token 的空间对应关系,不丢弃任何 Token; ③ 输出:Batch, Num_Tokens, Dim(多层空间特征) | ViT 只需全局语义 SETR 需要像素级特征 |
| 层数与参数量选择 | ① 标准配置:12/16/24 层; ② 输入分辨率固定(224×224) ③ Token 数少(196),计算量可控 | ① 优先用24 层大模型; ② 支持更高分辨率输入(如 512×512), ③ Token 数多(1024),但通过抽取多层而非全部层控制计算量 | 分割需要更强语义,需高分辨率保证精度 |
| 特征维度(Dim)适配 | 固定维度,仅服务于分类头 | 维度与 ViT 一致,但后续会将 Batch, N, D 转为 Batch, D, H, W,维度作为通道数,适配卷积解码器 | 分割需空间结构 |
| 训练策略 / 正则化 | ① 用 ImageNet 预训练,优化分类损失; ② 常用 Dropout、权重衰减 | ① 先复用 ViT 的 ImageNet 预训练权重,再在分割数据集(如 Cityscapes)微调; ② 增加随机裁剪、翻转等数据增强; ③ 损失函数是逐像素交叉熵,而非图像级交叉熵 | 分割数据集标注成本高,预训练 + 微调是必选; 像素级任务需要更强的数据增强防止过拟合 |
| 自注意力计算 | 全局自注意力,所有Token 两两计算注意力),Token 数少,计算压力小 | 同样是全局自注意力,但 Token 数多,单注意力头计算量是 ViT 的27 倍;SETR 未改注意力机制,而是靠解码器渐进上采样缓解整体计算量 | 这是 Transformer 做分割的固有问题,SETR 选择不改 Encoder 注意力,改解码器的折中方案 |
2.2 Decoder(解码器)
将 Transformer 输出的序列 (N,L,C) 恢复为 2D 特征图 (N,H/16,W/16,C),再逐步上采样至输入分辨率 (N,H,W,K)(K 为类别数),输出像素级分割结果。
-
特征重塑:Encoder 阶段的Flatten就像把一张完整的风景照片,按从左到右、从上到下的顺序卷成一根长条,这个过程是为了用 Transformer 高效建模全局特征。现在需要将 Encoder 输出的序列特征恢复为特征图,把这根长条重新展开,变回一张特征照片,为 Decoder 的空间上采样做准备。 Z ∈ R N × C ------ > Z 2 D = R e s h a p e ( Z ) ∈ R H P × W P × C Z∈\mathbb{R}^{N×C}------>Z_{2D}=Reshape(Z)∈\mathbb{R}^{\frac{H}{P} \times \frac{W}{P}×C} Z∈RN×C------>Z2D=Reshape(Z)∈RPH×PW×C -
上采样:Decoder 的核心是将【H/16,W/16】的低分辨率特征图恢复为【H,W】的像素级分割。
Z 2 D ∈ R H P × W P × C ------ > Y ∈ R H × W × K Z_{2D}∈\mathbb{R}^{\frac{H}{P} \times \frac{W}{P}×C}------>Y∈\mathbb{R}^{{H} \times{W}×K} Z2D∈RPH×PW×C------>Y∈RH×W×K
2.2.1 基础上采样(Naive Upsampling)
两步卷积降通道 + 一步 16 倍上采样。
- 步骤1:两次1*1卷积映射通道。(C--->K)
- 1×1 卷积的核心作用:仅改变通道数,空间尺寸(高 / 宽)完全不变。
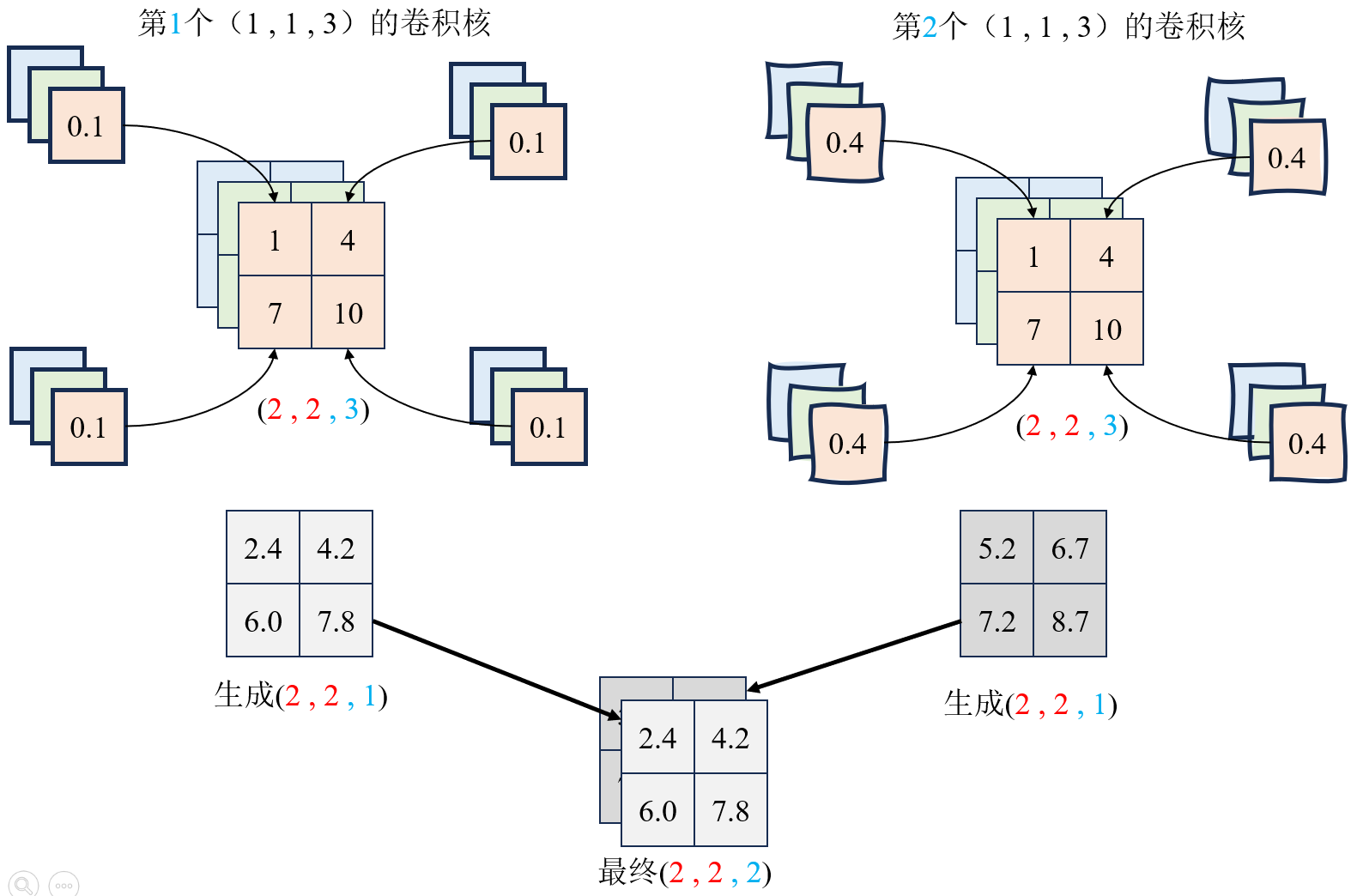

- 1×1 卷积的核心作用:仅改变通道数,空间尺寸(高 / 宽)完全不变。
Z c o n v = C o n v 1 × 1 ( C o n v 1 × 1 ( Z 2 D ) ) ∈ R H P × W P × K Z_{conv}=Conv_{1\times1}(Conv_{1\times1}(Z_{2D}))∈\mathbb{R}^{\frac{H}{P} \times \frac{W}{P}×K} Zconv=Conv1×1(Conv1×1(Z2D))∈RPH×PW×K
- 步骤2:双线性上采样16倍,恢复原图尺寸,通道数不变
- 双线性上采样不会凭空创造信息,而是对小特征图的每个像素,按 16 倍比例扩散,空缺的像素用周围 4 个像素的加权平均填充。
- 先把 32×32 的特征图 铺 到 512×512 的画布上:
- 小图的 (0,0) 像素 → 大图的 (0,0) 位置;
- 小图的 (0,1) 像素 → 大图的 (0,16) 位置;
- 小图的 (1,0) 像素 → 大图的 (16,0) 位置;
- 以此类推,小图每个像素对应大图间隔 16 个像素的位置。
- 填充空缺像素:
- 比如大图 (0,1)~(0,15) 这些空缺位置,用小图 (0,0) 和 (0,1) 两个像素的 "距离加权平均" 计算值;
- 再比如大图 (1,1) 位置,用小图 (0,0)、(0,1)、(1,0)、(1,1) 四个像素的加权平均计算值(这就是 "双线性" 的由来)。
Y N a i v e = U p s a m p l e ( s c a l e = 16 ) ( Z c o n v ) ∈ R H × W × K Y_{Naive}=Upsample_{(scale=16)}(Z_{conv})∈\mathbb{R}^{H\times W\times K} YNaive=Upsample(scale=16)(Zconv)∈RH×W×K
2.2.2 渐进式上采样(Progressive Upsampling)
4 次 2× 渐进上采样 + 卷积降通道
- 步骤1:4 次【2× 上采样】(累计 16×)+ 每次上采样前卷积细化。
- 一次性 16 倍上采样:小特征图(如 32×32)直接放大到 512×512,插值填充的像素太多,容易丢失细节;
- 4 次 2 倍分步上采样:32×32 → 64×64 → 128×128 → 256×256 → 512×512(每次只放大 2 倍),每次放大前用卷积 细化特征,让小尺寸特征先优化,再放大,细节更准确。
Z i = U p s a m p l e ( s c a l e = 2 ) ( C o n v 3 × 3 ( Z i − 1 ) ) Z_i=Upsample_{(scale=2)}(Conv_{3\times 3}(Z_{i-1})) Zi=Upsample(scale=2)(Conv3×3(Zi−1)) - i = 1 : R H 8 × W 8 × C i=1:\mathbb{R}^{\frac{H}{8}\times \frac{W}{8}\times C} i=1:R8H×8W×C
- i = 2 : R H 4 × W 4 × C i=2:\mathbb{R}^{\frac{H}{4}\times \frac{W}{4}\times C} i=2:R4H×4W×C
- i = 3 : R H 2 × W 2 × C i=3:\mathbb{R}^{\frac{H}{2}\times \frac{W}{2}\times C} i=3:R2H×2W×C
- i = 4 : R H × W × C i=4:\mathbb{R}^{{H}\times {W}\times C} i=4:RH×W×C
- 步骤2:最终1*1卷积映射类别(C--->K)
Y P U P = C o n v 1 × 1 ( Z 4 ) ∈ R H × W × K Y_{PUP}=Conv_{1\times1}(Z_4)∈\mathbb{R}^{H\times W\times K} YPUP=Conv1×1(Z4)∈RH×W×K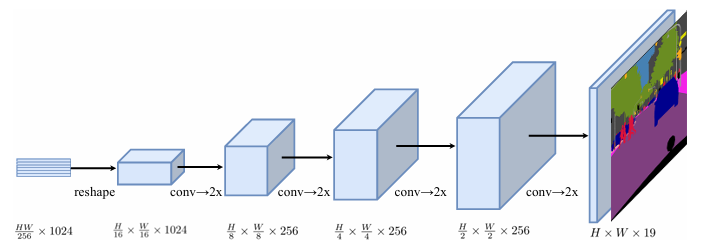
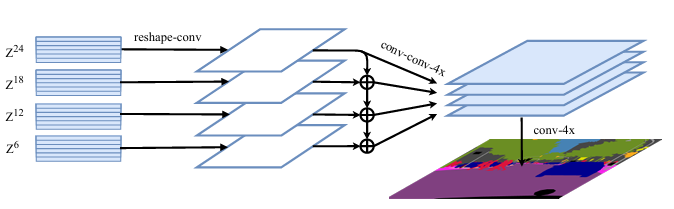
2.2.3 多层次特征聚合(Multi-Level Feature Aggregation)
单流卷积降通道 + 单独上采样(4×)+ 多层特征融合 + 融合后(4×)
假设抽取 M = 4 层 E n c o d e r 特征( Z 6 , Z 12 , Z 18 , Z 24 ) M=4层Encoder 特征(Z_6,Z_{12},Z_{18},Z_{24}) M=4层Encoder特征(Z6,Z12,Z18,Z24),每层均为 R N × C \mathbb{R}^{N\times C} RN×C。
- 步骤 1:单流特征处理(4 个流并行)
- 卷积降通道:Conv1×1(1024→512)→Conv3×3(512→512)→Conv3×3(512→256)
- 输出: R 256 × H 16 × W 16 \mathbb{R}^{{256}\times \frac{H}{16}\times \frac{W}{16}} R256×16H×16W
- 4× 上采样: R 256 × H 4 × W 4 \mathbb{R}^{{256}\times \frac{H}{4}\times \frac{W}{4}} R256×4H×4W
- 步骤 2:自上而下融合(跨层交互):从第 2 个流开始,将当前流特征与上一流特征逐元素相加。
- F l ′ = F l + C o n v 3 × 3 ( F l − 1 ′ ) F_l^′=F_l+Conv_{3×3}(F_{l−1}^′) Fl′=Fl+Conv3×3(Fl−1′)
- 融合后每个流仍为 R 256 × H 4 × W 4 \mathbb{R}^{{256}\times \frac{H}{4}\times \frac{W}{4}} R256×4H×4W
- 步骤 3:拼接与最终上采样
- 将 4 个流的 F l ′ F_l^′ Fl′拼接,维度 R 4 × 256 × H 4 × W 4 \mathbb{R}^{{4}\times{256}\times \frac{H}{4}\times \frac{W}{4}} R4×256×4H×4W
- 4× 上采样:维度 R 1024 × H 4 × W 4 \mathbb{R}^{1024\times \frac{H}{4}\times \frac{W}{4}} R1024×4H×4W
- 1×1 卷积映射类别
Y M L A = C o n v 1 × 1 ( F ) ∈ R H × W × K Y_{MLA}=Conv_{1\times1}(F)∈\mathbb{R}^{H\times W\times K} YMLA=Conv1×1(F)∈RH×W×K
2.3 输出
将 Decoder 输出的高维特征图映射为【像素级类别概率分布】,并通过损失函数完成模型训练。
三、总结
关键创新点:
- 纯 Transformer 分割范式:首次证明 Transformer 可独立完成语义分割任务,打破 CNN 在分割领域的垄断
- 序列→空间的适配设计:通过【Patch Embedding 序列化】和【Reshape 反序列化】,解决 Transformer 序列特征与分割任务 2D 空间特征的适配问题
- 多策略解码方案:提出 Naive/PUP/MLA 三种 Decoder,兼顾不同场景
- 全局注意力优势:相比 CNN 的局部感受野,Transformer 的全局自注意力能更好捕捉图像长距离语义关联(如道路、建筑的全局布局),提升复杂场景分割精度。