文章目录
- 摘要
- abstract
- [一、综述论文Multilingual Vision-Language Models, A Survey-多语言视觉-语言模型综述](#一、综述论文Multilingual Vision-Language Models, A Survey-多语言视觉-语言模型综述)
-
- 1.1从专用编码器向统一生成式架构的范式转移
- [1.2评估困境:基于翻译的基准 vs. 文化根基的基准](#1.2评估困境:基于翻译的基准 vs. 文化根基的基准)
- 1.3未来多语言视觉-语言模型的发展
- 二、实验
- 总结
摘要
多语言视觉-语言模型的核心矛盾------语言中立性与文化感知的张力。技术演进经历了从融合编码器、双编码器到多模态大语言模型的范式转移。评估体系正从基于翻译的基准向文化根基基准转型。未来发展方向聚焦于三大层面:数据层面构建文化数据引擎,模型层面采用可插拔文化适配器,评估层面建立多维文化素养基准。实验方面,成功部署服务器环境并跑通基线代码,为后续设计验证奠定基础。
abstract
The core contradiction of multilingual visual-language models lies in the tension between language neutrality and cultural perception. Technological evolution has undergone a paradigm shift from fusion encoders and dual encoders to multimodal large language models. Evaluation systems are transitioning from translation-based benchmarks to culturally rooted benchmarks. Future development focuses on three key areas: building a cultural data engine at the data level, employing pluggable cultural adapters at the model level, and establishing multidimensional cultural literacy benchmarks at the evaluation level. In terms of experimentation, a server environment was successfully deployed and baseline code ran, laying the foundation for subsequent design verification.
一、综述论文Multilingual Vision-Language Models, A Survey-多语言视觉-语言模型综述
语言中立性与文化感知的根本张力:当前多语言视觉-语言模型发展的核心瓶颈,并非单纯的技术能力不足,而在于一个深层次的、往往未被明说的目标冲突:追求语言中立性与实现"文化感知"之间的矛盾。
图 1 说明:来自 M5-VGR 数据集的视觉-语言推理示例。原始德语描述为:"Auf dem ersten Bild ist der Kleiderschrank weiß und übersichtlich, auf dem zweiten Bild ist er blau",翻译为:"在第一张图片中,衣柜是白色且整洁的,在第二张图片中它是蓝色的"。答案为"错误"(false)。

语言中立性(跨语言对齐)的追求:从工程和实践角度看,为了高效实现跨语言迁移(即用英语数据训练,让模型能处理 Hindi 或 Swahili 语),研究者们致力于让模型在不同语言中学习到对齐的表示。
背后的假设是,存在一种独立于语言之外的客观世界(例如,一张猫的图片,无论用哪种语言描述,其核心语义"猫"是不变的)。
对比学习通过拉近匹配图文对(如图像与英文描述、图像与中文描述)的距离,强制模型忽略语言差异,聚焦于共享的视觉语义。这种方法催生了mCLIP 和 NLLB-CLIP 这样的模型,它们在事实性检索和零样本跨语言任务上表现优异。
文化感知的必然要求:语言并非透明的符号系统,它根植于特定的文化和语境中。语言中立性在面对文化特定概念时显得捉襟见肘。例如,当询问"典型的早餐"时,英语使用者期望的是培根和鸡蛋,而日本使用者则期望味噌汤和米饭。一张"婚礼"的图片,在西方语境下可能是教堂和白纱,在印度语境下则可能是鲜艳的纱丽和复杂的仪式。
如果模型强行追求中立,实际上是在用单一的(通常是西方的)文化视角去"覆盖"所有其他文化,这不仅会导致输出不符合用户预期,甚至加剧文化霸权和刻板印象。
矛盾的伦理根源:这两个目标都源于对公平的追求。中立性旨在通过平等对待所有语言来提供一致的信息(形式平等),而文化感知则旨在通过尊重文化差异来提供有意义的体验(实质平等)。当前的模型和基准大多偏向于前者,因为这更容易量化和实现。未来的挑战在于如何设计能够在这两者之间取得平衡的模型------既能处理跨文化的普适概念,又能感知并适应特定文化的细微差别。
1.1从专用编码器向统一生成式架构的范式转移
多语言视觉-语言模型的架构设计经历了从专用拼接到统一生成的根本性范式转移,这直接借鉴了且受益于大语言模型(LLMs)的发展。
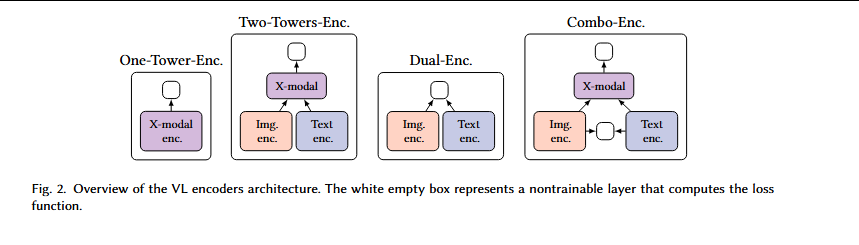
第一代:融合型编码器:早期的多模态模型(如 LXMERT、UNITER、M3P)主要基于 Transformer 编码器架构。它们的设计思路是将预训练的图像特征(如 Faster R-CNN 提取的区域特征)和文本特征进行深度融合(通过交叉注意力机制),以学习联合表示。这类模型在视觉问答(VQA)、自然语言视觉推理(NLVR2)等理解性任务上表现卓越。然而,它们结构复杂、计算量大,且天生不具备生成能力(如图像描述),更重要的是,它们严重依赖多语言的预训练编码器(如 XLM-R),在扩展新语言时成本较高。
视觉-语言编码器架构概览。白色空框表示计算损失函数的不可训练层。
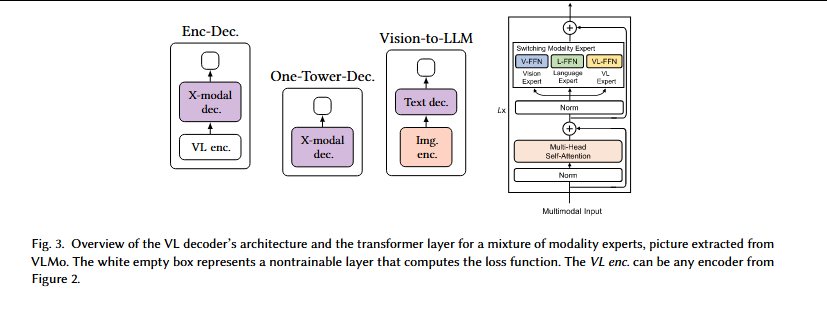
视觉-语言解码器架构及混合模态专家(mixture of modality experts)的 Transformer 层概览,图片摘自 VLMo。白色空框表示计算损失函数的不可训练层。VL enc. 可以是图 2 中的任何编码器。
第二代:双编码器与对比学习:以 CLIP 和 ALIGN 为代表的模型开辟了一条新路径。它们采用独立的图像编码器和文本编码器,通过对比学习在大规模噪声图文对上进行训练。这种设计的最大优势在于效率和可扩展性。文本和图像可以被独立编码并建立索引,从而实现高效的跨模态检索。
然而,其浅层的交互方式(仅在最后通过点积计算相似度),在复杂的跨模态推理任务上表现不佳。这种架构在多语言领域的扩展就是像 mCLIP 这样的模型,它们直接在多语言文本上训练,实现了跨语言的检索能力。
第三代:多模态大语言模型:这是当前最前沿的范式。它直接将"视觉"作为"外语"接入到强大的大语言模型中。代表模型如 MAGMA、Flamingo、mBLIP 和 LLaVA。其核心思想是训练一个视觉适配器,将视觉编码器(如 ViT)的输出特征映射到大语言模型的词嵌入空间。这样一来,大语言模型就可以将图像"看作"是一串特殊的标记(Tokens),并利用其强大的文本生成和推理能力来处理多模态任务。
优势:这种范式完美继承了大语言模型的所有优点:上下文学习、指令遵循、强大的推理和生成能力。对于多语言场景,这意味着模型理论上可以利用大语言模型本身的多语言能力,无需为每种语言重新训练视觉部分。
挑战:视觉信息可能会在映射到文本空间的过程中丢失,导致"幻觉"问题(模型"看到"了不存在的物体);同时,大语言模型固有的语言偏见(如英语数据主导)会直接传递到多模态版本中。
1.2评估困境:基于翻译的基准 vs. 文化根基的基准
评估方法在很大程度上决定了研究的方向。当前多语言视觉-语言模型的评估体系正面临着从以翻译为中心向以文化为中心的转型。
第一类:基于翻译的基准:这是目前的主流方法(约占综述中提及基准的 2/3)。其构建方式简单直接:选取一个现有的英文视觉-语言数据集(如图像和英文描述/问题),然后通过人工或机器翻译将其翻译成目标语言。最具代表性的例子包括 XNLI(跨语言自然语言推理)的视觉版本,以及 IGLUE 基准。
优点:保证了数据在不同语言间的平行性。图像是固定的,文本内容在语义上是等价的。这使得跨语言性能的比较变得直接和公平(例如,可以精确计算模型在英语和汉语上的准确率差异),完美契合了"语言中立性"的评估需求。
缺陷:这种基准评估的是模型的"翻译鲁棒性"和"跨语言对齐能力",而非真正的"跨文化理解能力"。由于图像本身源自英文数据集(如 Flickr30k、COCO),其内容天然带有英语文化圈的视角(如典型的西方家庭场景、节日、食物)。一个模型可能通过翻译测试,但仍然对印度或非洲文化中的特定视觉概念一无所知。这种评估方式无形中强化了英语和西方文化的中心地位。
第二类:文化根基的基准:为弥补上述缺陷,开始构建更具文化多样性的数据集。基准通常从源头就考虑文化的多样性,例如 MARVL,要求标注者为来自不同地理区域的图像提供符合本地文化语境的描述;或者 XM3600,它收集了全球 36 个地区、3600 种不同视觉概念的图像,并配有本地语言的描述。
挑战:这类基准的构建成本极高,需要全球范围内的标注者协作。评估变得复杂。由于不同语言的描述不再是对同一图像的直译,传统的自动评估指标(如 BLEU、CIDEr)变得不再适用,因为这些指标依赖于参考文本的重合度。如何为不同文化语境下的生成文本设计公平且有效的自动评估指标,是一个亟待解决的开放问题(目前多依赖人工评估)。这导致了模型在"中立性"和"感知性"上的表现难以在同一把尺子上衡量。
1.3未来多语言视觉-语言模型的发展
未来将聚焦于构建平衡且公平的多模态智能系统。
在数据层面,需打造文化数据引擎,通过挖掘非英语内容、人机协作和生成式模型,构建文化多样化的数据集,打破英语中心主义。
在模型层面,采用可插拔文化适配器架构,让基础模型学习跨文化通用表示,再通过轻量级适配器注入特定文化知识,实现动态文化视角调整。
在评估层面,建立多维文化素养基准,综合衡量事实对齐性、文化知识深度、敏感性与公平性,超越传统准确率指标。最终,模型将从静态图像扩展到视频、音频等多感官信号,并与具身智能结合,在与真实世界的互动中实现对文化的深层理解。
二、实验
上星期代码实验方面:先在谷歌colab上运行的jupyter形式的代码,经常断,后在服务器上新建了一个clmm形式虚拟环境,将jupyter形式论文进行划分为8个模块,第二天看着有点乱,合成一个python代码。跑amazon_eletronics数据集的BPR和lightGCN基线代码。
数据方面:
一些结果:
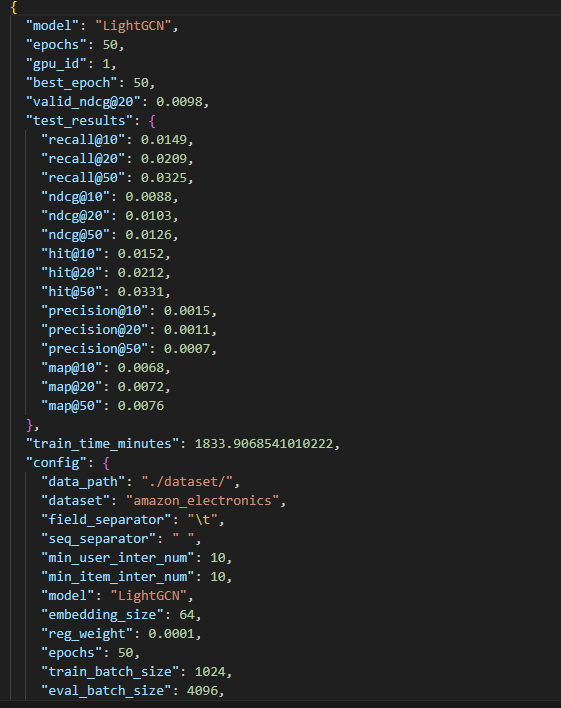
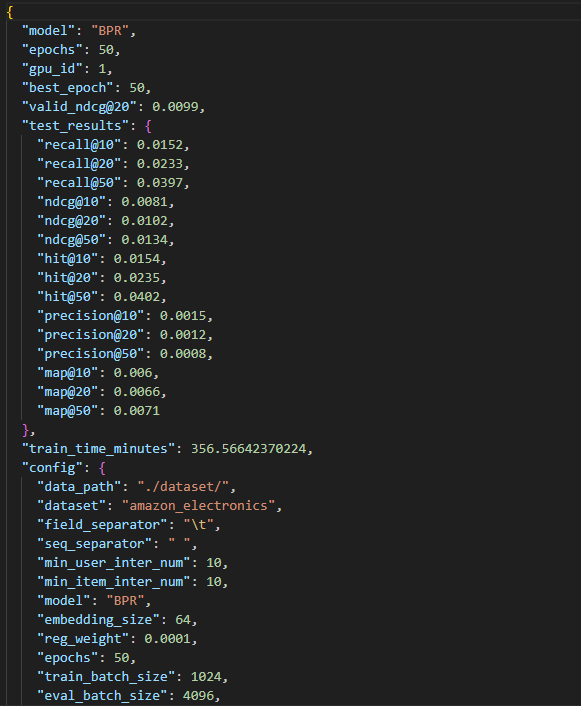
结果方面出现了问题,大概率是筛选数据出现了错误,导致不符合一般BPR和lightGCN的结果。
上学期做的跑基线测试。因为数据问题和模型设计方面,只跑了BPR,lightGCN等一些相关模型,数据选择方面有点问题,不适合,舍弃了。
总结
为了找出设计模型的一些点,搜索看了一篇综述论文,略读了几篇里面写的几篇的论文,没有找到合适的,但数据和代码设计很有启发。
在实验方面,下载了一些大的数据集合,同时跑通两个基线模型方便验证。