
本文作者:小夏,TRAE 技术专家
你让 AI 帮你干活,它却老是选错工具、传错参数、返回一堆没用的信息?问题可能不在 AI 模型本身,而在于你给它的"工具说明书"没写好。本文从 6 个方法出发,手把手教你:怎么给工具起名 AI 才看得懂、怎么设计参数才不容易传错、怎么让报错信息帮 AI 自己改正、怎么控制工具数量避免 AI "选择困难"。
同时带你理解 Skills 按需加载模式,去解决工具太多撑爆上下文的问题。
简单来说就是:你不是在写接口,而是在教 AI 怎么跟世界打交道。
原理介绍见上篇:如何让你的 Agent 更准确:MCP 工具设计技巧(上)

输入设计:降低出错概率
输入设计的核心目标是:让 Agent 更容易传对参数,更难传错参数。
合理的默认值:开箱即用
用户(和 Agent)应该能够在最少配置的情况下开始使用工具,每个可选参数都应该有合理的默认值:
python
def search_issues(
query: str,
repo: str = None, # 默认搜索所有仓库
state: str = "open", # 默认只搜索 open 状态
sort: str = "relevance", # 默认按相关性排序
limit: int = 20 # 默认返回 20 条
) -> str:
"""
搜索 GitHub Issues。
参数:
- query: 搜索关键词(必填)
- repo: 限定仓库,格式 owner/repo(可选,默认搜索所有可访问仓库)
- state: Issue 状态,可选 'open'|'closed'|'all'(可选,默认 'open')
- sort: 排序方式,可选 'relevance'|'created'|'updated'(可选,默认 'relevance')
- limit: 返回数量上限(可选,默认 20,最大 100)
"""
pass关键点:
-
必填参数应该尽量少,只有真正无法提供默认值的才设为必填
-
默认值要在描述中明确说明
-
默认值应该是最常用的选项,而非最安全的选项
Schema 验证:用类型系统约束输入
利用 JSON Schema 的特性来约束输入,减少 Agent 传错参数的可能性:
使用枚举限制可选值
json
{
"state": {
"type": "string",
"enum": ["open", "closed", "all"],
"description": "Issue 状态过滤"
}
}使用 pattern 约束格式
json
{
"repo": {
"type": "string",
"pattern": "^[a-zA-Z0-9_-]+/[a-zA-Z0-9_.-]+$",
"description": "仓库名,格式为 owner/repo"
}
}使用 minimum/maximum 约束范围
json
{
"limit": {
"type": "integer",
"minimum": 1,
"maximum": 100,
"default": 20,
"description": "返回结果数量上限"
}
}宽松解析:严格定义,宽容执行
这是一个重要的实践原则:在 Schema 中定义严格的规范,但在实际执行时宽容地处理变体。
python
def get_file_content(file_path: str) -> str:
"""
获取文件内容。
参数:
- file_path: 文件路径(支持绝对路径或相对于项目根目录的相对路径)
"""
# Schema 定义的是 file_path,但也接受常见变体
# Agent 可能会传 path、filepath、file 等
# 宽松解析示例(在实际代码中处理)
normalized_path = normalize_path(file_path)
# 自动处理路径格式
if not normalized_path.startswith('/'):
normalized_path = os.path.join(project_root, normalized_path)
return read_file(normalized_path)为什么这样做?
-
Agent 可能不会完全按照你定义的参数名传递
-
严格的 Schema 帮助 Agent 理解「正确」的方式
-
宽松的执行提高了工具的容错能力
分页参数的设计
对于可能返回大量数据的工具,分页是必要的:
python
def list_commits(
repo: str,
branch: str = "main",
page: int = 1,
per_page: int = 30
) -> str:
"""
列出仓库的提交历史。
参数:
- repo: 仓库名,格式 owner/repo
- branch: 分支名(默认 'main')
- page: 页码,从 1 开始(默认 1)
- per_page: 每页数量(默认 30,最大 100)
返回包含分页信息的结果:
{
"commits": [...],
"pagination": {
"page": 1,
"per_page": 30,
"total_count": 150,
"has_next": true
}
}
"""
pass分页设计要点:
-
页码从 1 开始(更符合人类直觉,Agent 也更容易理解)
-
提供明确的 has_next 或 has_more 字段
-
返回 total_count 帮助 Agent 判断是否需要继续获取
参数分组与嵌套
对于参数较多的工具,合理的分组可以提高可理解性:
json
{
"type": "object",
"properties": {
"query": { "type": "string", "description": "搜索关键词" },
"filters": {
"type": "object",
"description": "过滤条件(均为可选)",
"properties": {
"author": { "type": "string" },
"labels": { "type": "array", "items": { "type": "string" } },
"created_after": { "type": "string", "format": "date" }
}
},
"options": {
"type": "object",
"description": "查询选项(均为可选)",
"properties": {
"sort": { "type": "string", "enum": ["relevance", "created", "updated"] },
"limit": { "type": "integer", "default": 20 }
}
}
},
"required": ["query"]
}但要注意:嵌套不宜过深。 前面提到,某些 LLM 对复杂嵌套结构的支持有限,一般建议嵌套不超过 2 层,否则会大大增加返回非法 JSON 对象的概率。
针对 LLM 特性的 Schema 技巧
除了常规的 JSON Schema 设计原则外,还有一些针对 LLM 生成特性的高级技巧,可以提高工具调用的稳定性。
复杂数组展开为独立参数
当工具参数中包含复杂对象的数组时,LLM 生成正确 JSON 数组的稳定性往往不如预期。这是因为数组需要 LLM 正确处理多个嵌套层级的括号匹配、逗号分隔等语法细节。
一个实用的解决方案是:将数组展开为带编号的独立参数。 LLM 会识别 item_1 、item_2 、item_3 这种模式,并用更稳定的 JSON 对象方式来表达原本的数组语义。
json
// ❌ 不稳定:复杂对象数组
// LLM 可能在括号匹配、逗号分隔等处出错
{
"type": "object",
"properties": {
"changes": {
"type": "array",
"items": {
"type": "object",
"properties": {
"file_path": { "type": "string" },
"old_content": { "type": "string" },
"new_content": { "type": "string" }
}
},
"description": "要执行的文件修改列表"
}
}
}
// ✅ 更稳定:展开为独立参数
{
"type": "object",
"properties": {
"change_1": {
"type": "object",
"properties": {
"file_path": { "type": "string" },
"old_content": { "type": "string" },
"new_content": { "type": "string" }
},
"description": "第 1 个文件修改(必填)"
},
"change_2": {
"type": "object",
"properties": {
"file_path": { "type": "string" },
"old_content": { "type": "string" },
"new_content": { "type": "string" }
},
"description": "第 2 个文件修改(可选,如不需要则留空)"
},
"change_3": {
"type": "object",
"properties": {
"file_path": { "type": "string" },
"old_content": { "type": "string" },
"new_content": { "type": "string" }
},
"description": "第 3 个文件修改(可选,如不需要则留空)"
}
},
"required": ["change_1"]
}为什么这样更稳定?
-
扁平结构: 避免了数组嵌套,LLM 只需要处理对象的 key-value 结构
-
模式识别: LLM 很容易识别 change_1 、change_2 、change_3 的编号规律
-
独立验证: 每个参数可以独立验证,一个出错不会影响其他
-
灵活数量: 不需要的参数可以留空或不传,无需处理动态长度数组
适用场景:
-
批量文件操作(多文件编辑、重命名)
-
多条消息发送
-
多个资源的创建或更新
-
任何需要传递「复杂对象列表」的场景
注意事项:
-
预设的参数数量应该覆盖大多数使用场景(通常 3-5 个足够)
-
如果确实需要处理更多项目,可以在描述中说明分批调用
-
在工具实现中,需要将展开的参数重新组装为数组处理
静态参数作为行为提醒(Reminder Pattern)
这是一个巧妙的技巧:设计一个静态参数,它的值永远是固定的,但在描述中包含重要的行为提醒。当 LLM 按顺序生成工具调用参数时,它必须「输出」这个固定值,相当于在执行前进行了一次自我确认。
css
{
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "要写入的文件路径"
},
"content": {
"type": "string",
"description": "要写入的文件内容"
},
"CONFIRM_OVERWRITE": {
"type": "string",
"enum": ["I confirm this will overwrite existing content"],
"description": "确认提醒:此参数的值必须是 'I confirm this will overwrite existing content'。在输出此参数前,请确认:1) 你已经读取过原文件内容 2) 你确定要覆盖而非追加 3) 用户明确要求了此操作"
}
},
"required": ["file_path", "content", "CONFIRM_OVERWRITE"]
}工作原理:
LLM 在生成工具调用时会按顺序输出每个参数。当它输出到 CONFIRM_OVERWRITE 参数时:
-
它必须输出固定值 "I confirm this will overwrite existing co ntent"
-
在「决定」输出这个值的过程中,描述中的提醒会被「重新处理」一遍
-
这相当于在关键操作前设置了一个「检查点」
更多应用示例:
json
// 删除操作的安全提醒
{
"resource_id": {
"type": "string",
"description": "要删除的资源 ID"
},
"SAFETY_CHECK": {
"type": "string",
"enum": ["CONFIRMED_PERMANENT_DELETE"],
"description": "安全检查:此参数必须填写 'CONFIRMED_PERMANENT_DELETE'。在填写前请确认:1) 这是不可逆操作 2) 已告知用户删除后果 3) 用户明确确认要删除"
}
}
// 发送消息的内容检查
{
"recipient": { "type": "string" },
"message": { "type": "string" },
"TONE_CHECK": {
"type": "string",
"enum": ["professional_tone_verified"],
"description": "语气检查:此参数必须填写 'professional_tone_verified'。在填写前请检查消息内容:1) 语气是否专业友好 2) 是否有拼写错误 3) 是否包含敏感信息"
}
}
// 代码执行的环境确认
{
"code": { "type": "string" },
"ENVIRONMENT_CHECK": {
"type": "string",
"enum": ["sandbox_environment_confirmed"],
"description": "环境确认:此参数必须填写 'sandbox_environment_confirmed'。请确认代码将在沙箱环境执行,不会影响生产数据"
}
}为什么这个技巧有效?
-
强制「思考」: LLM 必须处理描述文本才能确定输出什么值
-
打断自动化倾向: 防止 LLM 「惯性」地快速生成工具调用而忽略重要细节
-
可审计: 工具调用日志中会包含这个确认参数,便于追溯
-
零实现成本: 工具实现端只需要验证参数值是否正确即可
使用建议:
-
将此类参数放在参数列表的最后,让 LLM 在填完所有实际参数后再进行确认
-
使用 enum 限制值域,确保 LLM 必须输出完全正确的值
-
参数名使用大写(如 CONFIRM_XXX 、SAFETY_CHECK),使其在视觉上突出
-
不要滥用此技巧,只用于真正需要谨慎处理的关键操作

输出设计:给 Agent 可操作的信息
工具的输出是 Agent 做出下一步决策的依据。好的输出设计应该让 Agent 能够快速理解结果、提取关键信息、决定后续行动。
JSON vs Markdown:什么时候用什么
结构化数据 → JSON
当输出是需要被 Agent 解析和处理的数据时,使用 JSON:
python
# ✅ 适合 JSON 的场景
def get_user_profile(user_id: str) -> str:
return json.dumps({
"id": "usr_123",
"name": "Alice",
"email": "alice@example.com",
"role": "admin",
"created_at": "2024-01-15T10:30:00Z"
})
def list_issues(repo: str) -> str:
return json.dumps({
"issues": [
{"number": 1, "title": "Bug report", "state": "open"},
{"number": 2, "title": "Feature request", "state": "closed"}
],
"total_count": 2
})面向展示的内容 → Markdown
当输出主要是给用户阅读的内容时,Markdown 更合适:
python
# ✅ 适合 Markdown 的场景
def generate_report(data: dict) -> str:
return """
# 月度报告
## 概要
- 总用户数:1,234
- 活跃用户:567
- 新增用户:89
## 详细分析
...
"""
def explain_error(error_code: str) -> str:
return """
## 错误说明
**错误代码**: AUTH_001
**含义**: 认证令牌已过期
**解决方案**:
1. 检查令牌是否在有效期内
2. 使用 refresh_token 获取新令牌
3. 重新进行认证
"""混合场景 → 用 JSON 包装 Markdown
有时候你需要同时提供结构化数据和可读内容:
python
def analyze_code(file_path: str) -> str:
return json.dumps({
"status": "completed",
"metrics": {
"lines": 150,
"complexity": 12,
"issues_count": 3
},
"summary": """
## 代码分析结果
发现 3 个潜在问题:
1. 函数 `processData` 复杂度过高
2. 缺少错误处理
3. 变量命名不规范
""",
"issues": [
{"line": 45, "type": "complexity", "message": "..."},
{"line": 67, "type": "error_handling", "message": "..."},
{"line": 89, "type": "naming", "message": "..."}
]
})输出控制:避免干扰 MCP 通信
MCP 使用 stdio 进行通信,工具在正常运行时不应该向 stdout 输出任何内容,否则可能干扰 MCP Client 的解析。
python
# ❌ 不好:直接 print 会干扰 MCP 通信
def process_data(data: str) -> str:
print("Processing...") # 这会破坏 MCP 协议
result = do_processing(data)
print("Done!") # 这也会
return result
# ✅ 好:使用文件日志
import logging
logger = logging.getLogger(__name__)
logger.addHandler(logging.FileHandler('/tmp/mcp-tool.log'))
def process_data(data: str) -> str:
logger.info("Processing...")
result = do_processing(data)
logger.info("Done!")
return json.dumps({"result": result})返回有意义的上下文,避免暴露底层技术细节
工具返回应该优先考虑上下文相关性而非灵活性,避免返回底层技术细节相关的标识符。
python
# ❌ 不好:返回低级技术细节
def get_user(user_id: str) -> str:
return json.dumps({
"uuid": "550e8400-e29b-41d4-a716-446655440000", # 难以理解
"256px_image_url": "https://...", # 过于具体
"mime_type": "image/jpeg", # Agent 通常不需要
"created_at_epoch": 1704067200 # 需要转换
})
# ✅ 好:返回语义化、可理解的信息
def get_user(user_id: str) -> str:
return json.dumps({
"name": "Alice Chen", # 可直接使用
"image_url": "https://...", # 简化字段名
"file_type": "jpeg", # 更直观
"created_at": "2024-01-01T00:00:00Z" # 标准格式
})关键原则:
-
使用 name 、image_url 、file_type 这样的字段,而非 uuid 、256px_image_url 、mime_type
-
将任意的字母数字 UUID 解析为更有语义意义和可解释的名称(甚至简单的 0 索引 ID 方案),可以显著提高 Agent 在检索任务中的精确度,减少幻觉
使用 response_format 控制输出详细程度
有时 Agent 需要灵活地获取简洁或详细的回复(例如 search_user(name='jane' ) → send_message(id=12345) )。你可以通过暴露一个简单的 response_format 枚举参数来实现:
python
from enum import Enum
class ResponseFormat(Enum):
DETAILED = "detailed" # 完整信息,适合需要所有字段时
CONCISE = "concise" # 精简信息,适合后续调用时
def search_users(query: str, response_format: str = "concise") -> str:
users = db.search(query)
if response_format == "detailed":
# 206 tokens - 完整信息
return json.dumps({
"users": [{
"id": u.id,
"name": u.name,
"email": u.email,
"department": u.department,
"role": u.role,
"created_at": u.created_at.isoformat(),
"last_active": u.last_active.isoformat(),
"avatar_url": u.avatar_url
} for u in users]
})
else:
# 72 tokens - 精简信息
return json.dumps({
"users": [{
"id": u.id,
"name": u.name
} for u in users]
})这种模式类似于 GraphQL,让 Agent 可以选择只接收需要的信息片段。你可以添加更多格式以获得更大的灵活性。
回复格式的选择
工具回复的结构格式(XML、JSON 或 Markdown)也会影响评估性能:没有万能的解决方案。
这是因为 LLM 是基于下一个 token 预测训练的,往往对与其训练数据匹配的格式表现更好。最佳的回复结构会因任务和 Agent 而异。我们建议你根据自己的评估选择最佳的回复结构。
包含足够的上下文
工具输出应该包含足够的上下文,让 Agent 不需要额外调用就能理解结果:
python
# ❌ 不好:缺少上下文
def create_issue(repo: str, title: str) -> str:
issue = github.create_issue(repo, title)
return str(issue.number) # 只返回 issue 编号
# ✅ 好:包含完整上下文
def create_issue(repo: str, title: str) -> str:
issue = github.create_issue(repo, title)
return json.dumps({
"status": "success",
"issue": {
"number": issue.number,
"title": issue.title,
"url": issue.html_url, # Agent 可以直接分享给用户
"state": issue.state,
"created_at": issue.created_at.isoformat()
},
"message": f"Issue #{issue.number} created successfully"
})分页元数据
对于分页结果,元数据应该清晰完整:
python
def list_commits(repo: str, page: int = 1, per_page: int = 30) -> str:
commits, total = github.get_commits(repo, page, per_page)
return json.dumps({
"commits": [
{
"sha": c.sha[:7],
"message": c.message.split('\n')[0], # 只取第一行
"author": c.author.login,
"date": c.date.isoformat()
}
for c in commits
],
"pagination": {
"page": page,
"per_page": per_page,
"total_count": total,
"total_pages": (total + per_page - 1) // per_page,
"has_previous": page > 1,
"has_next": page * per_page < total
}
})控制输出大小:Token 效率优化
优化上下文的质量 很重要,但优化返回给 Agent 的上下文数量同样重要。
大量输出会占用上下文窗口,影响 Agent 的后续推理。例如,一些主流 coding agent 会限制工具回复长度。 我们预计 Agent 的有效上下文长度会随时间增长,但对上下文高效工具的需求将持续存在。
应该主动控制输出大小:
python
def read_file(file_path: str, max_lines: int = 500) -> str:
content = read_file_content(file_path)
lines = content.split('\n')
if len(lines) > max_lines:
# 截断并提供明确的引导指令
truncated = '\n'.join(lines[:max_lines])
return json.dumps({
"content": truncated,
"truncated": True,
"total_lines": len(lines),
"shown_lines": max_lines,
"message": f"File has {len(lines)} lines, showing first {max_lines}. Use read_file_range() to read specific sections.",
"suggestion": "Consider using search_in_file() for targeted lookups instead of reading the entire file."
})
return json.dumps({
"content": content,
"truncated": False,
"total_lines": len(lines)
})
# 引导 Agent 采用更高效的策略
def search_documents(query: str, max_results: int = 20) -> str:
"""
搜索文档内容。
💡 提示:对于知识检索任务,建议进行多次小范围、有针对性的搜索,
而非一次大范围搜索。这样可以获得更精确的结果,同时节省上下文空间。
"""
results = db.search(query, limit=max_results)
return json.dumps({
"results": results,
"count": len(results),
"tip": "For better results, try more specific queries rather than broad searches."
})
错误处理:帮助 Agent 自我纠正
错误处理是 Agent 工具设计中最容易被忽视,却又最能体现「为 Agent 设计」思维的环节。
错误是输入,不是终点
传统编程中,我们习惯在错误时抛出异常,让程序「快速失败」。但对于 Agent 来说,这种方式代价太高了。
想象一下:Agent 执行一个复杂任务,可能需要 5 分钟、调用 20 次工具、花费 $0.50 的 token。如果在第 15 步因为一个参数格式错误就让整个流程崩溃,用户体验会非常糟糕。
核心转变: 对于 Agent 工具,错误不是「终点」,而是「输入」,是给 Agent 的另一种反馈,帮助它调整策略继续前进。
python
# ❌ 传统方式:抛出异常
def get_user(user_id: str):
user = db.find(user_id)
if not user:
raise UserNotFoundError(f"User {user_id} not found")
return user
# ✅ Agent 友好:返回描述性错误
def get_user(user_id: str) -> str:
"""
返回:
- 成功时返回用户信息的 JSON 字符串
- 失败时返回错误描述,包含修正建议
"""
user = db.find(user_id)
if not user:
return f"""User not found: {user_id}.
Possible reasons:
1. ID format incorrect - should be 'usr_' followed by 8 characters (e.g., 'usr_a1b2c3d4')
2. User may have been deleted
Try: Use find_user_by_email() if you have the user's email address."""
return json.dumps(user)错误信息要有「可操作性」
一个好的错误信息应该回答三个问题:
1. 出了什么问题?( What)
sql
User not found: usr_invalid1232. 为什么会出这个问题?( Why)
csharp
The ID format is incorrect - expected 'usr_' prefix followed by 8 alphanumeric characters.3. 应该怎么修正?( How)
csharp
Please verify the ID format or try searching by email using find_user_by_email().完整示例:
python
def create_github_issue(repo: str, title: str, body: str = "") -> str:
# 验证 repo 格式
if "/" not in repo:
return f"""Invalid repository format: '{repo}'
Expected format: 'owner/repo' (e.g., 'facebook/react')
You provided: '{repo}'
Please correct the format and try again."""
# 检查仓库是否存在
if not github.repo_exists(repo):
return f"""Repository not found: '{repo}'
Possible reasons:
1. The repository doesn't exist
2. The repository is private and you don't have access
3. Typo in owner or repo name
Try: Use github_search_repos(query="{repo.split('/')[-1]}") to find similar repositories."""
# 检查权限
if not github.has_write_access(repo):
return f"""Permission denied for repository: '{repo}'
You don't have write access to create issues in this repository.
Contact the repository owner to request access."""
# 创建 issue
issue = github.create_issue(repo, title, body)
return json.dumps({
"status": "success",
"issue_number": issue.number,
"url": issue.html_url
})提供替代方案
当一种方式失败时,告诉 Agent 还有什么其他选择:
sql
def get_user_by_id(user_id: str) -> str:
user = db.find_by_id(user_id)
if not user:
return f"""User not found with ID: {user_id}
Alternative approaches:
1. Search by email: find_user_by_email(email="user@example.com")
2. Search by username: find_user_by_username(username="john_doe")
3. List all users: list_users(limit=100) to browse available users"""
return json.dumps(user)区分可恢复错误和不可恢复错误
不是所有错误都需要 Agent 去「修复」。有些错误是可以重试或调整参数的,有些则需要人工介入:
python
# 可恢复错误:Agent 可以尝试修正
def api_call_with_retry_hint(params):
if rate_limited:
return "Rate limited. Please wait 60 seconds and retry."
if invalid_params:
return f"Invalid parameter 'date': expected YYYY-MM-DD format, got '{params['date']}'"
# 不可恢复错误:需要人工介入
def sensitive_operation(params):
if not_authorized:
return """Permission denied. This operation requires admin privileges.
⚠️ This cannot be resolved automatically. Please ask the user to:
1. Contact their administrator to request access, or
2. Use a different account with appropriate permissions"""错误信息的格式
对于复杂的错误信息,结构化格式比纯文本更容易被 Agent 解析和处理:
python
# 返回结构化的错误信息
def structured_error_response(error_type, message, suggestions):
return json.dumps({
"status": "error",
"error_type": error_type,
"message": message,
"suggestions": suggestions,
"recoverable": True
})
# 使用示例
return structured_error_response(
error_type="VALIDATION_ERROR",
message="Invalid email format",
suggestions=[
"Check if the email contains '@' symbol",
"Verify there are no spaces in the email",
"Use find_user_by_id() if you have the user ID instead"
]
)配置错误的优雅处理
配置错误(如环境变量缺失、路径错误)不应该让工具崩溃。相反,应该在工具被调用时提供有用的诊断信息:
python
def github_create_issue(repo: str, title: str) -> str:
# 检查必要的配置
github_token = os.environ.get('GITHUB_TOKEN')
if not github_token:
return json.dumps({
"status": "configuration_error",
"error": "GitHub token not configured",
"message": """
GITHUB_TOKEN environment variable is not set.
To fix this:
1. Create a GitHub Personal Access Token at https://github.com/settings/tokens
2. Set the environment variable:
- In your shell: export GITHUB_TOKEN=your_token_here
- In MCP config: add "env": {"GITHUB_TOKEN": "your_token_here"}
Required scopes: repo, read:org
""",
"recoverable": False,
"requires_user_action": True
})
# 正常执行...关键点:
-
配置错误不是 Agent 能自己修复的,需要明确标记 requires_user_action
-
提供具体的修复步骤,而非简单的错误消息
-
不要让工具在启动时就崩溃,等到实际被调用时再报告问题

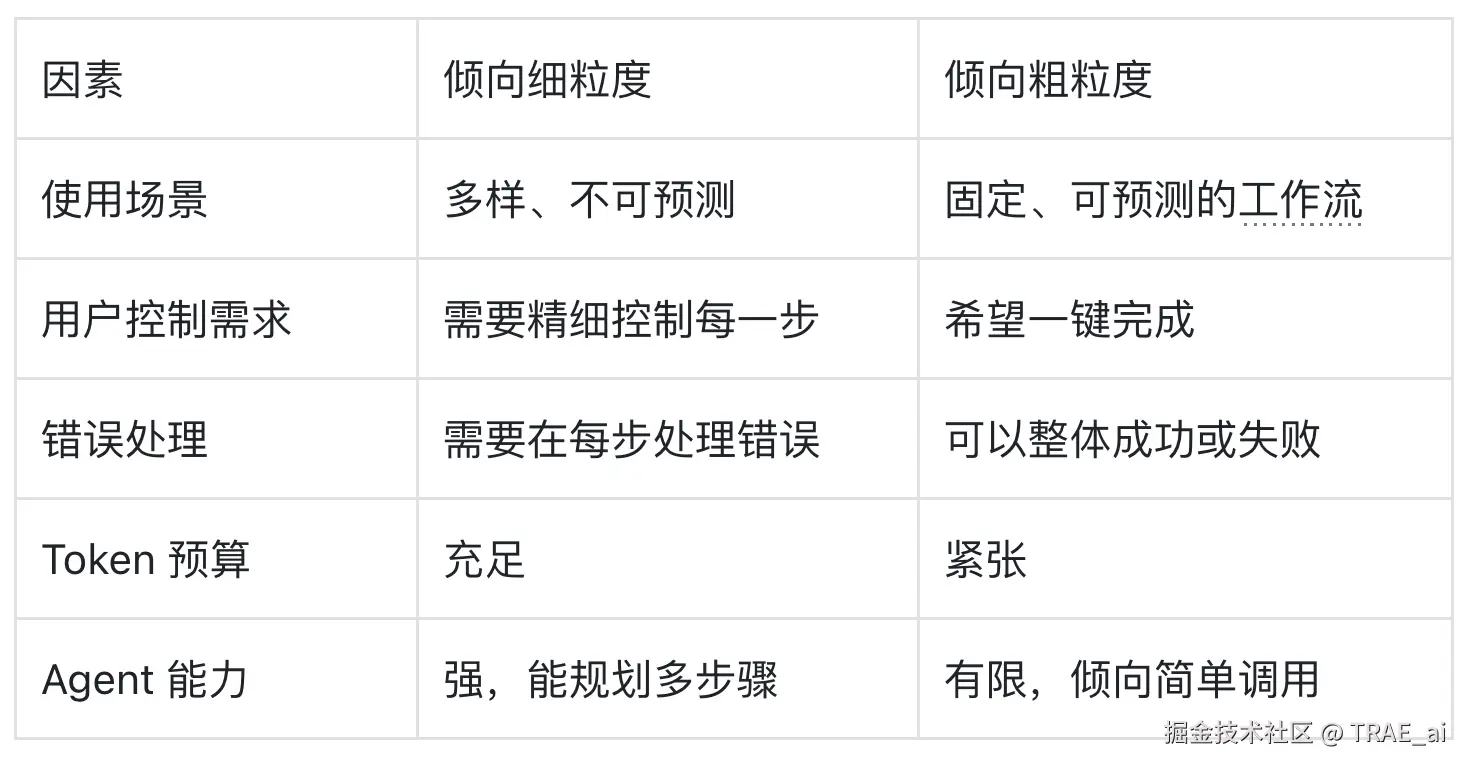
工具粒度的权衡
设计 MCP 工具时,一个关键决策是:工具应该多「大」?是提供细粒度的原子操作,还是粗粒度的组合工作流?
为什么不能直接把 API 包装成工具?
一个常见的错误是直接把现有的 REST API 端点或函数封装成 MCP 工具,「反正功能都实现了,包一层不就行了?」但这忽略了一个关键问题:Agent 和传统软件有着完全不同的「可供性」(Affordances)。
LLM Agent 的上下文窗口(context window)是稀缺资源,而计算机内存是廉价且充裕的。这个根本差异决定了工具设计的方向。
让我们用一个简单的例子来说明:在通讯录中搜索联系人。
传统软件可以高效地存储和处理整个联系人列表,逐个检查每条记录。但如果让 LLM Agent 使用一个返回「所有联系人」的工具,然后逐个 token 地阅读每一条......它就是在用最宝贵的上下文空间处理大量无关信息。
想象一下:你会通过从头到尾逐页阅读来在通讯录中找人吗?当然不会,你会直接翻到按字母排序的相关页面。Agent 也应该如此。
ini
# ❌ 不好:直接暴露底层能力,让 Agent 自己处理
list_contacts() # 返回所有联系人,Agent 需要逐个筛选
get_contact(id) # Agent 需要知道 ID 才能调用
# ✅ 好:针对 Agent 的认知模式设计
search_contacts(name="张") # 直接返回匹配结果
message_contact(name="张三") # 内部处理搜索和发送核心洞察: 好的 Agent 工具应该匹配 Agent(和人类)解决问题的自然方式,而不是底层系统的数据结构。
两个极端的问题
太细粒度:多次调用,浪费 token
scss
# ❌ 每个字段一个工具,需要多次调用
get_user_name(user_id) # 第 1 次调用
get_user_email(user_id) # 第 2 次调用
get_user_address(user_id) # 第 3 次调用
get_user_phone(user_id) # 第 4 次调用问题:
-
每次调用都消耗 token(包括工具选择、参数生成、结果解析)
-
Agent 需要多次「思考」该调用什么
-
增加出错的机会点
太粗粒度:返回大量无关信息,填满上下文
bash
# ❌ 一个工具返回所有信息
get_user_all_data(user_id) # 返回 50 个字段,包含完整的历史记录、偏好设置、活动日志...问题:
-
大量无关信息占用上下文窗口
-
Agent 需要从海量数据中提取有用信息
-
增加 token 消耗和处理延迟
实践案例:订单追踪
让我们通过一个具体的例子来理解粒度选择的影响。
假设你要构建一个帮助用户追踪订单的 Agent。作为人类开发者,你可能会这样使用 API:先调用 GET /users 获取用户信息,再调用 GET /orders 获取订单列表,最后调用 GET /shipments 获取物流状态。你读过文档,写好脚本,调试通过,部署上线。
如果直接把这三个 API 暴露为 MCP 工具:
scss
# ❌ 差的设计:直接暴露底层 API
get_user_by_email(email) # 第 1 次调用
list_orders(user_id) # 第 2 次调用
get_order_status(order_id) # 第 3 次调用Agent 需要:
-
加载三个工具的完整定义到上下文
-
进行三次往返调用
-
在对话历史中存储所有中间结果
-
自己组织信息生成最终回复
更好的设计:
python
# ✅ 好的设计:围绕用户目标设计
def track_order(email: str) -> str:
"""
追踪用户的最新订单状态。
内部会自动查询用户信息、订单列表和物流状态,
返回格式化的订单追踪结果。
"""
# 内部调用三个 API,组装结果
return "Order #12345 shipped via FedEx, arriving Thursday."同样的结果,一次调用,围绕用户目标设计。
核心原则:把编排逻辑放在你的代码里,而不是放在 LLM 的上下文窗口里。
确保每个工具都有清晰、独特的目的。 工具应该让 Agent 能够像人类一样分解和解决任务,在获得相同底层资源访问权限的情况下,同时减少中间输出本应占用的上下文空间。
过多的工具或功能重叠的工具也会分散 Agent 的注意力,使其偏离高效策略。仔细、有选择性地规划你要构建(或不构建)的工具,真的很值得。
找到合适的粒度
原则:按使用场景聚合,而非按数据结构拆分
工具可以合并功能,在底层处理多个离散操作(或 API 调用)。例如,工具可以用相关元数据丰富回复内容,或者在单次工具调用中处理经常串联的多步骤任务。以下是一些实用的例子:
ini
# ❌ 不好:直接暴露底层 API,需要多次调用
list_users() # 第 1 次调用
list_events() # 第 2 次调用
create_event(...) # 第 3 次调用
# ✅ 好:合并为面向目标的工具
schedule_event(
participants=["alice@example.com", "bob@example.com"],
title="项目讨论",
duration_minutes=30
)
# 内部自动:查找用户 → 检查空闲时间 → 创建事件
ini
# ❌ 不好:原始日志读取
read_logs(file="/var/log/app.log") # 返回大量无关日志
# ✅ 好:智能日志搜索
search_logs(
keyword="error",
time_range="last_1h",
context_lines=3
)
# 只返回相关日志行及其上下文
scss
# ❌ 不好:需要多次调用才能获取完整信息
get_customer_by_id(customer_id) # 基本信息
list_transactions(customer_id) # 交易记录
list_notes(customer_id) # 服务备注
# ✅ 好:一次性获取客户完整上下文
get_customer_context(customer_id)
# 返回客户基本信息 + 最近交易 + 重要备注的整合视图
ini
# ✅ 合适的粒度:按场景组织
get_user_profile(user_id) # 返回姓名、邮箱、头像,展示用
get_user_billing_info(user_id) # 返回支付方式、账单地址,需要时才调
get_user_activity_summary(user_id, days=7) # 返回近 7 天活动摘要启发式方法:如果 Agent 在 90% 的情况下调用 A 后都会调用 B,考虑合并它们。
ini
# 观察到的调用模式:
# 1. get_issue(id)
# 2. get_issue_comments(id) <-- 几乎总是紧跟着调用
# ✅ 考虑合并
get_issue_with_comments(issue_id, include_comments=True)提供便利函数,保留底层能力
有时候你需要同时提供「简单但有限」和「复杂但完整」的工具。关键是在描述中明确指导 Agent 的选择:
python
# 便利函数:覆盖 80% 的使用场景
def search_issues(query: str, repo: str = None) -> str:
"""
搜索 GitHub Issues(推荐首选)。
这是最常用的搜索方式,自动处理分页和格式化。
大多数情况下应该优先使用这个函数。
参数:
- query: 搜索关键词
- repo: 可选,限定在特定仓库搜索
返回前 20 条最相关的结果。
"""
pass
# 底层能力:处理复杂场景
def search_issues_advanced(
query: str,
filters: dict,
sort: str = "relevance",
per_page: int = 30,
page: int = 1
) -> str:
"""
高级 Issue 搜索,支持复杂过滤条件。
⚠️ 只有当 search_issues 无法满足需求时才使用:
- 需要精确控制过滤条件(作者、标签、日期范围等)
- 需要自定义排序方式
- 需要分页获取大量结果
filters 支持的字段:
- author: 作者用户名
- labels: 标签列表
- state: 'open' | 'closed' | 'all'
- created_after: ISO 日期字符串
- created_before: ISO 日期字符串
"""
pass组合工具 vs 原子工具
对于复杂的工作流,可以考虑提供「组合工具」:
python
# 原子工具:灵活但需要多步
create_branch(repo, branch_name, from_branch)
commit_changes(repo, branch, files, message)
create_pull_request(repo, branch, title, body)
# 组合工具:一步完成常见工作流
def quick_fix_and_pr(
repo: str,
file_path: str,
changes: str,
description: str
) -> str:
"""
快速修复并创建 PR(一步完成)。
自动执行以下步骤:
1. 创建新分支 (fix/auto-{timestamp})
2. 应用更改并提交
3. 创建 Pull Request
适用于简单的单文件修复。
对于复杂的多文件更改,请使用 create_branch + commit_changes + create_pull_request。
"""
pass粒度决策的考量因素
严格控制工具数量
工具数量是影响 Agent 效果的关键因素,一个拥有 4 个精心构造工具的 Agent,效果一定会优于拥有 40 个粗制滥造工具的 Agent。需要记住,用户可能同时连接多个 MCP Server,加上 Agent 自带的工具,总数很容易超标。保守估计每个 Server 的工具数量,给其他 Server 留出空间。
一个 Server,一个职责
不要试图构建一个「全能」的 MCP Server。就像微服务架构一样,每个 Server 应该专注于一个领域:
diff
✅ 好的拆分:
- github-server: GitHub 相关操作
- slack-server: Slack 消息和频道管理
- calendar-server: 日历和事件管理
❌ 不好的设计:
- productivity-suite-server: 包含 GitHub + Slack + Calendar + Email + Notes + ...避免工具重叠和冗余
功能相似的工具是 Agent 混淆的主要来源。当你有 edit_tool_v1 、edit_tool_v2 、replace_line_with_regex 这样的工具时,模型会在它们之间反复犹豫。如前所述,有工程师观察到 Agent 尝试了 18 个编辑相关工具后才放弃。
scss
# ❌ 不好:多个重叠的编辑工具
edit_file_v1(path, content)
edit_file_v2(path, changes)
replace_line(path, line_number, new_content)
replace_regex(path, pattern, replacement)
patch_file(path, diff)
# ✅ 好:一个通用的编辑工具
edit_file(path, changes, mode="replace") # mode: replace | patch | regex删除未使用的工具
如果一个工具在过去 30 天内从未被调用,请考虑移除它,因为未使用的工具仍然会:
-
占用上下文窗口
-
增加 Agent 的选择负担
-
可能与其他工具产生混淆
按角色拆分(Admin vs User)
如果某些工具只有特定角色才能使用,考虑将它们拆分到不同的 Server:
diff
- github-server: 常规操作(create_issue, list_repos, search_code)
- github-admin-server: 管理操作(delete_repo, manage_permissions, billing)这样普通用户的 Agent 不会被管理功能干扰,管理员也能在需要时显式启用高权限工具。
定期统计工具使用
工具设计不是一次性的,随着使用数据积累,你应该定期统计:
-
哪些工具从未被使用? 考虑移除或合并
-
哪些工具总是一起被调用? 考虑提供组合版本
-
哪些工具经常调用失败? 可能需要改进设计或文档
-
哪些工具的参数经常传错? ****可能需要简化或提供更好的默认值
提供诊断工具:info 命令模式
一个实用的最佳实践是提供一个 info 或 status 工具,用于诊断 MCP Server 的状态:
python
def server_info() -> str:
"""
获取 MCP Server 的状态和配置信息。
用于诊断问题或验证配置是否正确。
返回版本信息、依赖状态、配置检查结果。
"""
return json.dumps({
"version": "1.2.3", # 动态读取,不要硬编码
"status": "healthy",
"dependencies": {
"github_api": {"status": "ok", "authenticated": True},
"database": {"status": "ok", "connection": "active"}
},
"configuration": {
"GITHUB_TOKEN": "configured" if os.environ.get('GITHUB_TOKEN') else "missing",
"LOG_LEVEL": os.environ.get('LOG_LEVEL', 'info'),
"MAX_RESULTS": os.environ.get('MAX_RESULTS', '100')
},
"issues": [
# 列出检测到的配置问题
]
})这个模式的好处:
-
便于调试: 当工具行为异常时,Agent 或用户可以先调用 info 检查状态
-
自我文档化: 显示当前生效的配置,避免「我明明配置了为什么不生效」的困惑
-
版本一致性: 确保用户知道自己运行的是哪个版本

可移植的脚本执行:跨环境一致性
无论是 MCP Server 还是 Skills 中的工具,脚本都需要在不同环境中可靠运行,你的本地机器、远程 Agent 环境、或者分享给其他人使用。传统的包管理方式会带来可移植性问题:依赖特定路径的解释器、需要预先创建虚拟环境、依赖隐式存在的全局包......这些不一致性会导致脚本在环境迁移时失败。
核心原则:永远不要依赖周围环境中隐式存在的包。完整且显式的依赖声明应该统一适用于代码运行的所有环境。
Python:使用 UV 实现零配置执行
UV 是现代 Python 包管理器,提供两个关键能力:
-
解释器管理: 自动运行(必要时安装)正确版本的 Python
-
实时包安装: 运行脚本时自动获取、安装和缓存依赖
使用 PEP 723 内联元数据,将依赖声明嵌入脚本本身:
python
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "requests==2.32.5",
# "markdown==3.10",
# ]
# ///
import requests
import markdown
def fetch_and_convert(url: str) -> str:
response = requests.get(url)
return markdown.markdown(response.text)运行方式:
bash
uv run script.py # 自动安装依赖并执行
uvx some-cli-tool # 直接从 PyPI 运行命令行工具无需创建虚拟环境、无需永久安装、无需 shell 配置。依赖规格随脚本一起移动,新用户 checkout 后立即可运行。
在 MCP 配置中使用 UV 启动 Server:
json
{
"mcpServers": {
"my-python-server": {
"command": "uv",
"args": ["run", "server.py"],
"cwd": "/path/to/server"
}
}
}类似的,你在 SKILL.md 中也可以指定使用 UV:
perl
## 执行脚本
运行分析脚本:
```bash
uv run scripts/analyze.py --input data.json
```Node.js:使用 npx 实现即时执行
Node.js 生态中,npx(npm 自带)提供类似能力:
perl
# 无需全局安装,直接运行包中的命令
npx cowsay "Hello MCP"
# 指定版本运行
npx typescript@5.0 --version
# 运行本地 package.json 中的脚本
npx tsx script.ts对于需要依赖的脚本,使用 package.json 声明依赖,配合 npx 或直接运行:
json
{
"type": "module",
"dependencies": {
"node-fetch": "^3.3.0",
"marked": "^12.0.0"
}
}
bash
# 安装依赖并运行(首次会自动 npm install)
npm start
# 或使用 npx 运行特定脚本
npx tsx src/main.tsBun:更快的 JavaScript 运行时
Bun 是高性能 JavaScript 运行时,内置包管理器:
arduino
# bunx 类似 npx,但更快
bunx cowsay "Hello from Bun"
# 直接运行 TypeScript,无需编译
bun run script.ts
# Bun 自动读取 package.json 依赖
bun install && bun run startBun 的优势:
-
启动速度极快(比 Node.js 快 4x)
-
原生支持 TypeScript
-
内置测试运行器和打包器
编译为独立可执行文件: Bun 支持将 TypeScript/JavaScript 代码、所有依赖和运行时打包成单个可执行文件,实现真正的零依赖分发:
css
# 编译为当前平台的可执行文件
bun build ./server.ts --compile --outfile my-mcp-server
# 交叉编译到其他平台
bun build ./server.ts --compile --target=bun-linux-x64 --outfile my-mcp-server-linux
bun build ./server.ts --compile --target=bun-darwin-arm64 --outfile my-mcp-server-mac
bun build ./server.ts --compile --target=bun-windows-x64 --outfile my-mcp-server.exe编译后的可执行文件:
-
包含 Bun 运行时 + 代码 + 所有 node_modules 依赖
-
无需目标机器安装 Node.js、Bun 或任何依赖
-
单文件分发,简化 MCP Server 的部署和共享
Deno:安全优先的运行时
Deno 采用不同的方式,可以直接从 URL 导入依赖:
javascript
// deps.ts - 集中管理依赖
export { serve } from "https://deno.land/std@0.220.0/http/server.ts";
export { parse } from "https://deno.land/std@0.220.0/flags/mod.ts";
// main.ts
import { serve, parse } from "./deps.ts";
const args = parse(Deno.args);
serve((req) => new Response("Hello MCP"));运行方式:
css
# 显式授予权限
deno run --allow-net --allow-read main.ts
# 或使用配置文件
deno task startDeno 的优势:
-
默认安全(需显式授权网络、文件等权限)
-
无需 node_modules,依赖缓存在全局
-
原生支持 TypeScript
跨语言最佳实践总结

关于编译型语言: 当然也可以选择 Rust、Go 等编译型语言开发 MCP Server,编译后的二进制文件同样是零依赖、单文件分发。但缺点也很明显:需要为每个目标平台(Linux/macOS/Windows × x64/arm64)单独编译和分发,增加了构建和发布的复杂度。相比之下,上述脚本语言方案只需分发源码,由运行时处理跨平台兼容性。
配置 Agent 使用正确的运行时:
在 Agent 配置或 SKILL.md 中明确指定:
markdown
## 运行时要求
- Python 脚本:使用 `uv run` 执行
- TypeScript 脚本:使用 `bun run` 或 `npx tsx` 执行
- 不要使用全局安装的包,始终通过包管理器运行这确保脚本在任何环境中都能获得一致的行为和性能。

高级模式:Skills 与 MCP 的互补
当工具数量增长到一定程度,MCP 的「会话开始时加载所有工具」模式会遇到瓶颈。这时,一种互补的方案是 Skills(或类似的渐进式披露机制)。
问题回顾:工具数量爆炸
MCP 的设计是在会话开始时,Agent 通过协议获取所有可用工具的定义,并将它们注入到 system prompt 中。这意味着:
-
上下文占用固定: 无论用户这次会话是否需要,所有工具定义都会占用 token
-
选择负担恒定: Agent 每次决策都要在完整的工具列表中选择
-
难以扩展: 随着功能增加,工具数量只增不减
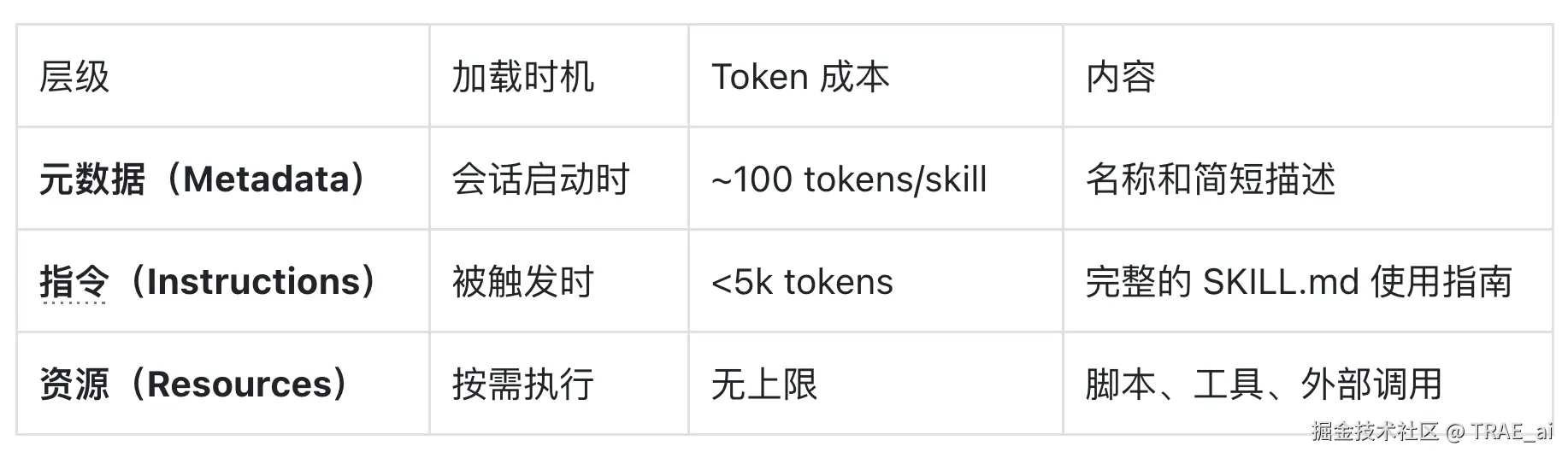
Skills 的渐进式披露模型
Skills 提供了一种不同的思路:按需加载。Skills 通常采用三层披露结构:
这种设计的优势:
-
启动成本低: 只加载元数据,几十个 Skills 可能只占用几百 token
-
按需深入: 只有当 Agent 判断某个 Skill 相关时,才读取完整指令
-
丰富的上下文: Skill 文档可以包含详细的使用说明、示例、最佳实践,这些在 MCP 工具的简短 description 中很难容纳
-
降低试错成本: Skill 中可以描述工具调用的最佳实践、推荐的参数组合、常见陷阱的规避方法。Agent 读取 Skill 后能直接采用正确的使用方式,而不是通过反复尝试来学习,这在调用有副作用的工具(如创建资源、发送消息)时尤其重要
MCP 与 Skills 的对比
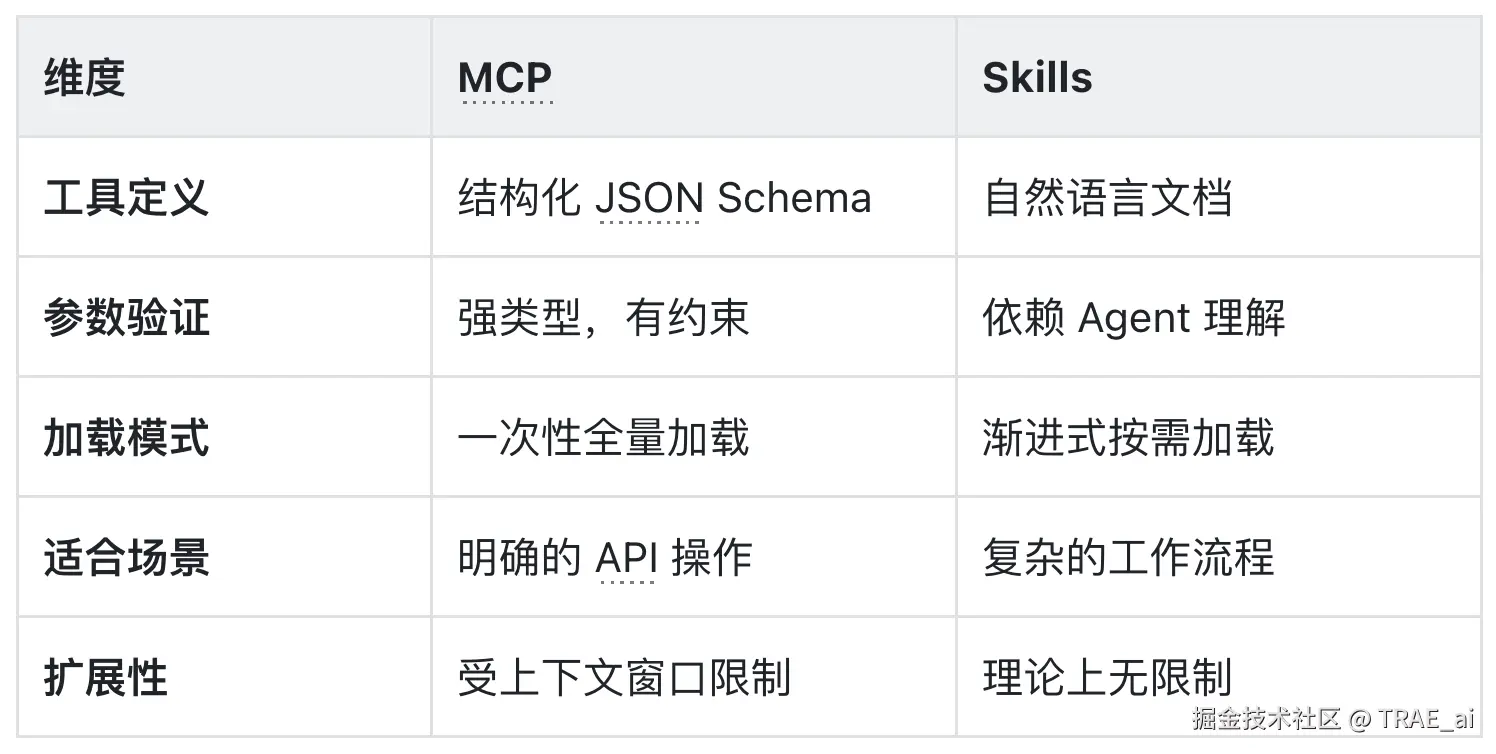
上下文占用的具体对比
Skills 采用了一种不同的方式:保持入口点小巧,只在需要时加载详细内容。

关键差异: MCP 工具定义在每一轮对话都消耗 token,无论该轮是否使用该工具;而 Skills 的详细内容只在被调用时读取。如果你的工作涉及长代码 diff、日志或策略文档,这个差异直接决定了有多少「真正有用的内容」能放入上下文。
两者如何互补
MCP 和 Skills 不是非此即彼的关系,而是可以互补使用:
MCP 适合:
-
需要精确参数验证的 API 调用
-
高频使用的核心工具
-
需要跨 Agent 共享的标准化接口
Skills 适合:
-
需要丰富上下文说明的复杂工作流
-
低频但重要的专业操作
-
包含多个步骤的组合任务
组合模式:将 MCP 工具封装为 Skills 的一部分
markdown
# SKILL.md: GitHub PR Review
## 描述
帮助进行 GitHub Pull Request 代码审查。
## 使用场景
当用户要求审查 PR、查看 PR 变更、或对 PR 提出评论时使用。
## 工具
此 Skill 使用以下 MCP 工具(需确保 github-server 已连接):
- `github_get_pull_request`: 获取 PR 详情
- `github_list_pr_files`: 列出变更文件
- `github_create_review`: 提交审查意见
## 工作流程
1. 首先使用 `github_get_pull_request` 获取 PR 基本信息
2. 使用 `github_list_pr_files` 查看变更的文件列表
3. 对于需要详细审查的文件,读取具体内容
4. 分析代码变更,识别潜在问题
5. 使用 `github_create_review` 提交审查意见
## 最佳实践
- 关注代码逻辑而非格式问题(格式问题应由 linter 处理)
- 对于大型 PR,优先审查核心逻辑文件
- 提出建设性的改进建议,而非简单指出问题通过这种方式,Skills 提供了丰富的上下文和工作流指导,而 MCP 工具提供了精确的执行能力。Agent 可以:
-
根据 Skill 的元数据判断是否相关
-
读取完整的 SKILL.md 理解工作流程
-
调用底层的 MCP 工具执行具体操作
使用 MCPorter 将 MCP 转换为 CLI 工具
Skills 原生支持调用 CLI 命令,但直接调用 MCP Server 需要处理协议握手、连接管理、OAuth 认证等复杂逻辑。MCPorter 提供了一个优雅的解决方案:将任意 MCP Server 转换为独立的 CLI 工具,让 Skills 可以像调用普通命令行工具一样使用 MCP 能力。
生成 CLI 工具:
bash
# 从 HTTP MCP Server 生成 CLI
npx mcporter generate-cli --command https://mcp.linear.app/mcp
# 从 stdio MCP Server 生成 CLI
npx mcporter generate-cli --command "npx -y chrome-devtools-mcp@latest"
# 生成并编译为独立可执行文件
npx mcporter generate-cli linear --compile --output dist/linear生成的 CLI 工具可以直接在 SKILL.md 中使用:
ini
## 工具
使用 Linear CLI 进行 Issue 操作:
```bash
# 搜索 Issues
linear search_issues query="bug" state=open
# 创建 Issue
linear create_issue title="Fix login bug" team=ENG
\`\`\`为什么需要 MCPorter 而非直接调用 MCP?
-
Daemon 进程复用连接: MCPorter 维护一个后台 daemon 进程,保持与 MCP Server 的长连接。对于 chrome-devtools 、mobile-mcp 等有状态的 Server,这意味着 Chrome 标签页和设备会话在多次调用之间保持活跃,无需每次重新建立连接。
-
自动处理 OAuth 认证: 许多托管 MCP Server(如 Vercel、Linear、Supabase)需要 OAuth 认证。MCPorter 自动缓存 token、处理刷新,避免 Skill 执行时弹出浏览器登录窗口。
-
统一的调用接口: 无论底层是 HTTP 还是 stdio 传输,生成的 CLI 提供一致的调用体验。Skill 作者无需关心 MCP 协议细节。
-
零配置发现: MCPorter 自动合并常见 AI 客户端的 MCP 配置,无需重复配置 Server 连接信息。
Daemon 管理:
bash
# 查看 daemon 状态
mcporter daemon status
# 预热 daemon(提前启动连接)
mcporter daemon start
# 重启 daemon(配置变更后)
mcporter daemon restart通过 MCPorter,你可以在 Skills 中充分利用 MCP 生态的丰富工具,同时保持 Skill 定义的简洁性,只需编写 CLI 调用指令,复杂的协议处理交给 MCPorter。
进阶用法:生成 TypeScript API 进行脚本编排
MCPorter 还支持将 MCP Server 转换为带类型的 TypeScript API,这为「脚本化工具编排」打开了新的可能:
bash
# 生成类型定义
npx mcporter emit-ts linear --out types/linear.d.ts
# 生成完整的客户端包装器
npx mcporter emit-ts linear --mode client --out clients/linear.ts生成的 TypeScript 客户端可以直接在脚本中使用:
ini
import { createRuntime, createServerProxy } from "mcporter";
const runtime = await createRuntime();
const linear = createServerProxy(runtime, "linear");
// 强类型调用
const issues = await linear.searchIssues({ query: "bug", state: "open" });
const issue = await linear.createIssue({ title: "Fix login", team: "ENG" });
await runtime.close();为什么这很重要? 当 Agent 直接调用 MCP 工具时,每次调用的参数、返回值都会进入对话上下文,多步骤任务会快速消耗上下文窗口。而让 Agent 生成一个 TypeScript 脚本来编排多个工具调用:
-
上下文压力大幅降低: 只有脚本代码和最终执行结果进入上下文,中间的 API 调用细节被封装在脚本内部
-
执行更可靠: 脚本一次性执行,避免多轮对话中的状态丢失和理解偏差
-
可复用和可审计: 生成的脚本可以保存、修改、重复执行
这种「Agent 写脚本 → 脚本调用工具」的模式,是 Anthropic 在 Code Execution with MCP 中推荐的高级用法。MCPorter 让这一模式变得开箱即用。

总结:从 MCP 到更广泛的 Agent Tool Interface 设计
我们从一个核心洞察出发:MCP 是 AI Agent 的用户界面,不是已有 REST API 的封装。 围绕这一理念,我们系统地探讨了 Agent 工具设计的方方面面。
核心原则回顾
理解 Agent 的认知特性
Agent 只能通过工具的名称、描述和参数 Schema 来「理解」工具。它不会阅读文档,不会从上下文推断隐含信息,每次调用都需要从头理解工具的用途。设计工具的本质,是在设计 Agent 的认知体验:减少认知负担,让 Agent 更容易用对、更难用错。
设计的六个维度

工具数量的克制
工具数量直接影响 Agent 的决策质量。每个 MCP Server 建议控制在 5-15 个工具,避免功能重叠,定期清理未使用的工具。
超越 MCP:更广泛的适用性
这些原则不仅适用于 MCP,也适用于任何 Agent Tool Interface 设计:无论是 OpenAI 的 Function Calling、Anthropic 的 Tool Use,还是其他 Agent 框架。核心思维是一致的:
-
换位思考: 站在 Agent(LLM)的角度设计,而非人类开发者的角度
-
显式优于隐式: 所有重要信息都应该在工具定义中明确表达
-
上下文是稀缺资源: 每个 token 都有成本,精简而完整是永恒的追求
持续演进
Agent 工具设计是一个持续迭代的过程。随着 LLM 能力的提升、MCP 生态的成熟、以及 Skills 等新范式的出现,最佳实践也会不断演进。但核心理念不会改变:你不是在写 API,你是在教会一个智能体如何与这个世界交互。
希望本文能为你的 MCP Server 开发和 Agent 工具设计提供一个系统的思考框架。好的工具设计,让 Agent 更可靠、更高效,最终让用户获得更好的体验。
延伸阅读
如何评测 MCP Server
本文聚焦于 MCP Server 的设计原则,但并未涉及如何系统性地评测 MCP Server 的效果。如果你想了解这方面的实践,推荐阅读 GitHub 官方博客的这篇文章:Measuring what matters: How offline evaluation of GitHub MCP Server works (github.blog/ai-and-ml/g...
这篇文章详细介绍了 GitHub MCP Server 团队如何构建自动化离线评测管道,确保每次迭代都能提升质量而非引入回归。文章的核心内容包括:
-
评测流程: 执行(Fulfillment)→ 评估(Evaluation)→ 汇总(Summarization)三阶段管道
-
工具选择评测: 使用准确率、精确率、召回率、F1 分数等分类指标,衡量模型是否选对了工具
-
参数正确性评测: 检测参数幻觉、必填参数缺失、值匹配等问题
-
混淆矩阵分析: 识别哪些工具容易被混淆(如 list_issues 与 search_issues),从而针对性地优化工具描述
通过离线评测,团队可以在用户感知之前发现问题,并将「感觉变好了」转化为可量化的改进。
用 Agent 为 Agent 编写工具
Anthropic 工程团队也发布了一篇关于 Agent 工具设计的深度文章:Writing effective tools for AI agents --- with agents (www.anthropic.com/engineering...
这篇文章从实践角度出发,介绍了如何通过「评测驱动」的方式迭代优化工具设计,并分享了他们在优化内部 Slack、Asana 等 MCP Server 过程中提炼的核心原则,文章的亮点包括:
-
与 Agent 协作优化工具: 使用 Claude Code 分析评测日志,自动发现工具描述的问题并进行重构。实验表明,Claude 优化后的工具在测试集上的表现甚至超过了人类专家手写的版本
-
选择正确的工具: 强调「Agent 的可供性(Affordances)与传统软件不同」------上下文窗口是稀缺资源,不应简单地把 API 包装成工具,而要围绕高价值工作流设计
-
返回有意义的上下文: 避免返回底层技术标识符(如 UUID),优先使用语义化的字段名;提供 response_format 参数让 Agent 灵活选择详细或精简的输出
-
Token 效率优化: 实现分页、过滤、截断等机制,并在截断时提供清晰的引导指令
-
工具描述的 Prompt Engineering: 即使是微小的描述调整也能带来显著的性能提升------Claude Sonnet 3.5 在 SWE-bench 上的 SOTA 表现就得益于对工具描述的精准优化
这篇文章提供了更多来自 Anthropic 内部实践的具体案例和数据支撑,值得深入阅读。
更多精品内容欢迎进入 TRAE 官方社区了解:🔗 forum.trae.cn/