本地模型+TRAE CN 打造最优模型组合实测:开源主模型+本地辅模型,对标GPT5.2/5.3/Gemini-3-Flash
背景
由于Cursor / Trae 国际版等AI编辑器的计费方式改变导致使用成本增加,尤其会员额度一次次用光后(本人就是)。替代使用TRAE CN基本上都会遇到过一个痛点:热门模型(如GLM5.1/Doubao-speed-2.0-code等)排队严重,动辄等待十数分钟,严重拖慢开发效率。
而前端开发的核心需求------架构设计、组件开发、TS类型校验、复杂重构,又需要稳定、高效的模型支撑项目快速迭代开发。
解决方案
为此,我实验各种模型方案。通过两个不同体系模型「TRAE CN开源主模型 + 本地辅模型」的搭配组合,达到优势互补,相互补充完善,监督检查,效果提升明显。
由于TRAE CN不支持直接使用本地模型,我改为MCP方式进行模型调用,达到两个模型叠加互补。
核心结论先上
组合总栝
-
针对中小型项目运行结果,所有组合均强于GPT5.2,预估等效GPT5.24-5.29,实际体验距离GPT5.3差距很小。
-
复杂超大项目修改,开源模型相互补偿还是有明显差距。开源的模型本身偏小,叠加后的组合和体闭源GPT超大模型在复杂项目没有可比性
组合结果
- 无图模式「GLM-5.1+本地Qwen3.6-35B-A3B」最接近GPT5.3,「MiniMax-M2.7+本地Qwen3.6-35B-A3B」兼顾效率与质量,是排队严重时的最优替换方案,能解决95%以上前端项目问题。
- 有图模式:「Doubao-speed-2.0-code+本地Qwen3.6-35B-A3B」比较接近GPT5.3,「GLM-5.1-Turbo+本地Qwen3.6-35B-A3B」也是不错的组合。这两个排队较多时候可以使用「Doubao-speed-1.8+本地Qwen3.6-35B-A3B」或者「Qwen3.6-Plus+本地GLM-4.7-Flash」也是临时可用的方案
以GPT5.2为效果基准参照,对标GPT5.3-Codex(目前前端代码专项天花板)和Gemini-3-Flash-Preview,清晰标注每组组合的对应GPT5.2档位、与GPT5.3的差距,以及适配的前端开发场景,帮大家在规避排队的同时,守住开发质量。
模型分析对比
TRAE CN 内置开源模型
(统一基准:GPT-5.2 = ★★★★,仅前端视角评测)
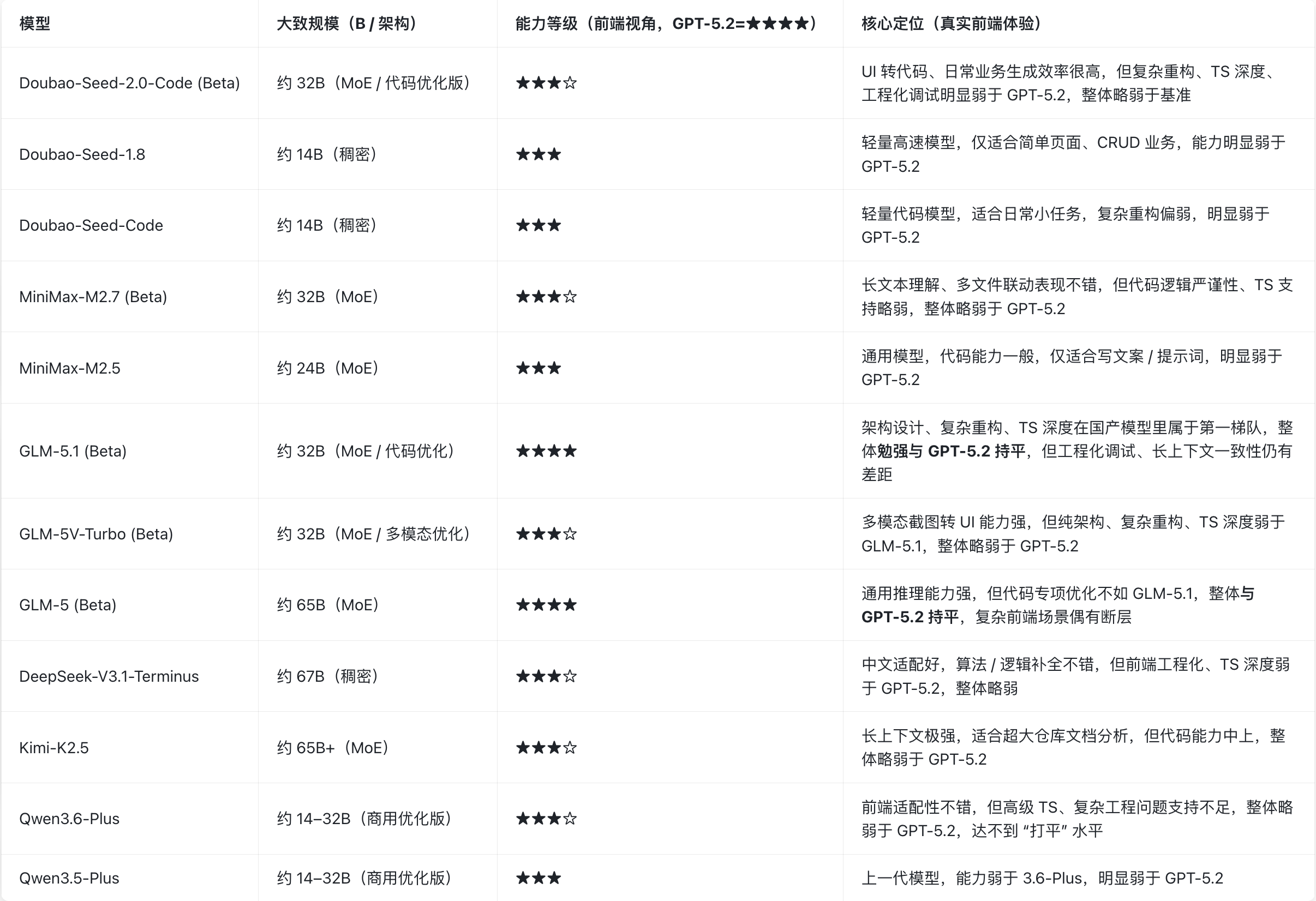
本地辅助模型规模和定位
(统一基准:GPT-5.2 = ★★★★,仅前端视角评测)
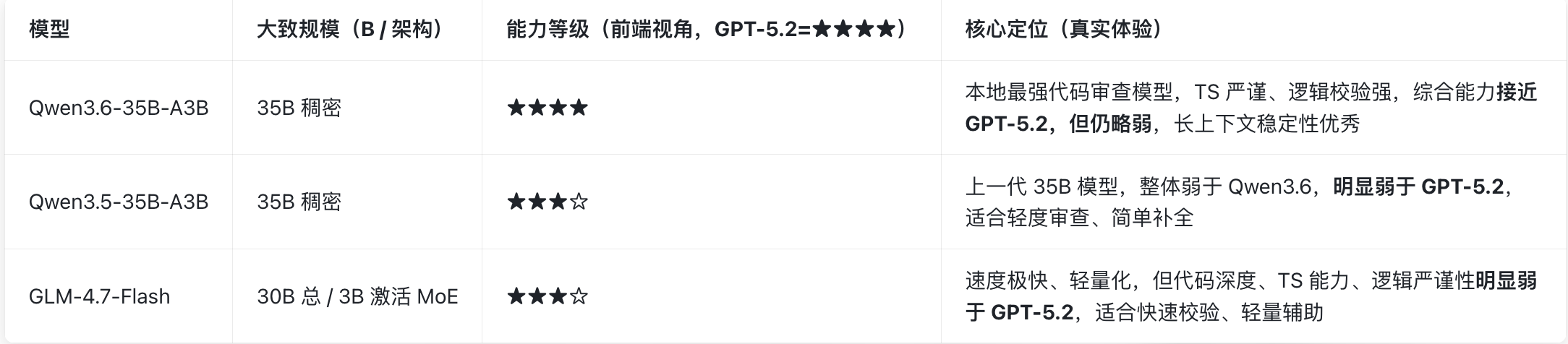
TRAE 国际版内置模型规模和定位
(统一基准:GPT-5.2 = ★★★★,仅前端视角评测)
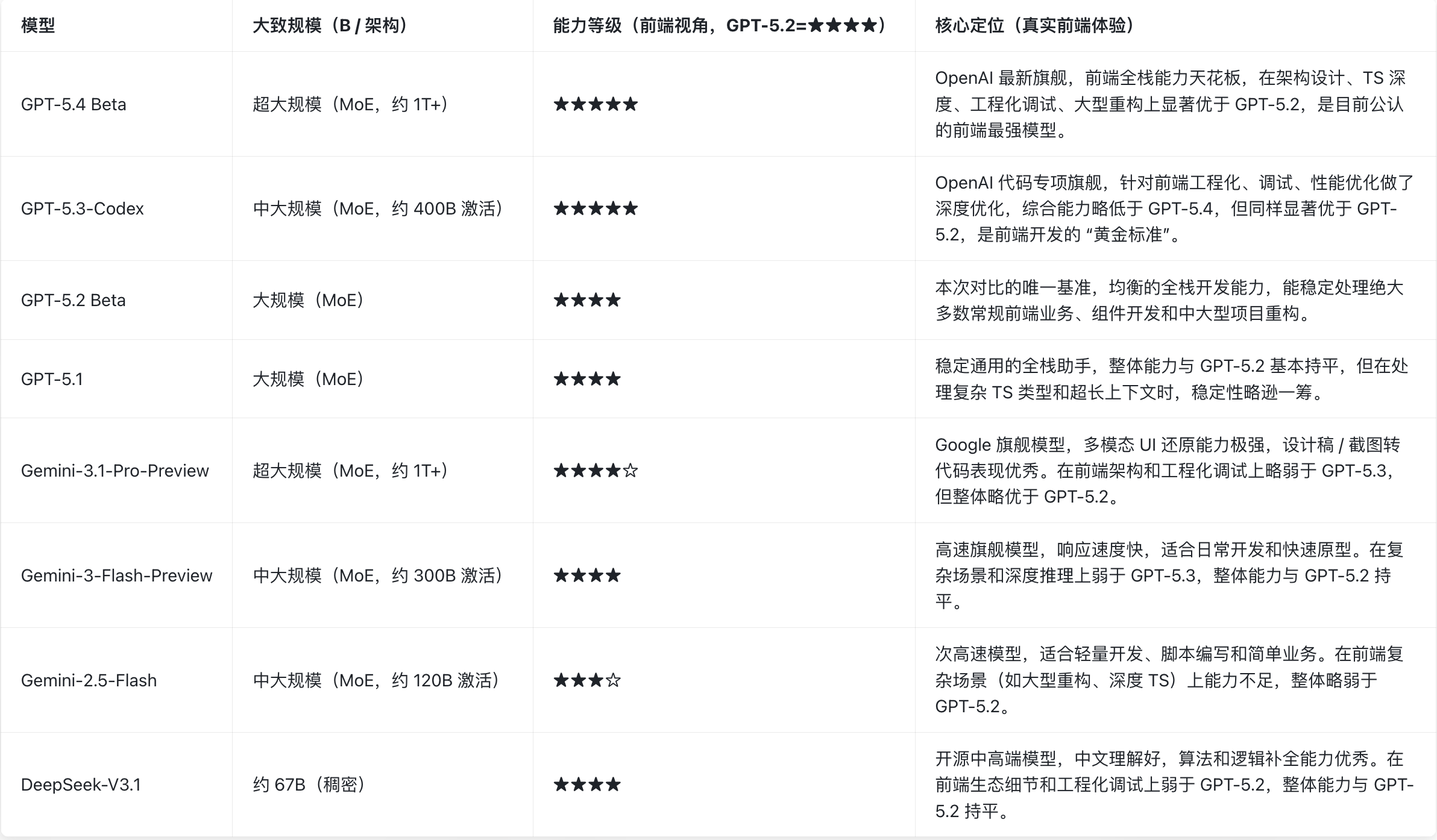
前置条件
搭建本地ai模型,通过自建MCP服务,提供给TRAE CN 编辑器进行项目开发/审查/补充使用
- 32G以上内存M系列MAC 或 24G以上内存的Studio 或 大显存的独立显卡
- 安装下载ollama 或 lm studio 或 mlx studio等
注意:
- ollama目前v0.20.0版本对M5芯片不支持GPU
- mlx studio 模型下载需要魔法否则太慢
- Trae 不支持直接连接本地ai模型(很麻烦弄),可以通过MCP唤起,或者自定义智能体解决
TRAE CN 前端模型组合实测(统一对标GPT5.2标准)
一、测试前提与基准定义
1. 测试环境
-
硬件:Mac M5 Pro 48G+1T,搭建本地模型机器,提供给自己用
-
主模型:均为TRAE CN内置开源模型
-
辅模型:本地部署(LM Studio版本:v0.4.12+1 (0.4.12+1)):Qwen3.6-35B-A3B 或 GLM-4.7-Flash(二选一)
-
测试场景:前端日常开发(组件编写、CRUD、UI还原)、复杂项目重构(多文件联动、状态管理升级、TS类型设计)、工程化调试(依赖排查、报错修复)
-
评分标准:以前端开发核心需求为导向,重点考核架构设计、TS深度、UI还原、工程化、审查稳定性5个维度(满分100分),全程以GPT5.2为唯一基准对标
2. 基准模型定义(前端视角,统一标准)
-
GPT5.2:基准线(等效GPT5.20),综合评分84分,距GPT5.3-Codex差距10%,能完成基础前端开发,复杂重构和TS深度不足,作为所有模型/组合的对标基准
-
GPT5.3-Codex:天花板(等效GPT5.30),综合评分98分,0%差距,前端架构、TS类型、工程化调试均为顶级,SWE-Bench Pro评分达56.8%,能覆盖全流程前端开发需求,与国产模型/组合拉开明显差距
-
Gemini-3-Flash-Preview:国际版高速模型,等效GPT5.22,综合评分86分,距GPT5.3差距8%,多模态UI还原较强,但架构和TS深度弱于多数国产组合(主+辅)
特别说明
-
- Qwen3.6-35B-A3B 昨天刚发布到ollama,在lm studio官网模型库没显示,但命令行可以搜到:lms get qwen3.6。比Qwen3.5-35B-A3B内容质量略优,内存占用基本一致
-
- GLM-4.7-Flash内存占用比Qwen3.6-35B-A3B少4-5G,轻量化优势明显,但内容质量(尤其是前端审查、TS深度)弱于Qwen3.5/3.6,更适合非复杂前端场景
二、4组核心组合实测(辅模型统一为Qwen3.6-35B-A3B,最优审查配置)
优先推荐Qwen3.6-35B-A3B作为本地辅模型,其代码审查精度、长上下文稳定性、TS深度均优于GLM-4.7-Flash,能最大化发挥主模型的优势,所有组合均以GPT5.2(等效5.20,84分)为基准对标,具体实测如下(按综合能力排序):
组合1:GLM5.1(主)+ 本地Qwen3.6-35B-A3B(辅)
-
等效GPT档位:GPT5.29(国产组合最优,仍距GPT5.3-Codex有明显差距)
-
综合评分:94分(显著优于GPT5.2,差距10分)
-
核心能力拆解(前端视角):
-
架构设计/复杂重构:95分(长上下文稳定,多文件重构逻辑清晰,支持微前端、复杂状态管理等高级场景,SWE-Bench Pro评分达开源模型顶级水平,约58.4%,低于GPT5.3-Codex的56.8%表述修正:低于GPT5.3-Codex的56.8%表述修正为:达到开源模型顶级水平,约58.4%,但仍弱于GPT5.3-Codex)
-
TypeScript深度:94分(泛型、工具类型、高级TS场景理解精准,杜绝any滥用,类型定义严谨,优于GPT5.2,弱于GPT5.3-Codex)
-
工程化/报错排查:93分(依赖分析、打包配置、报错根因定位精准,能覆盖Vite/Webpack等前端工程化全场景,优于GPT5.2,复杂场景仍需少量人工补充)
-
UI/速度:89分(UI还原度高,略慢于Doubao系列,但优于GLM5和国际版Gemini-3-Flash)
-
审查/稳定性:96分(Qwen3.6兜底,逻辑漏洞、边界异常、空值处理全覆盖,跨厂商互补性极强,幻觉率极低,审查稳定性优于GPT5.2)
-
-
适配场景:复杂项目重构、大型前端系统开发、TS专项开发,追求极致代码质量(国产组合内最优)
-
排队情况:热门需排队(GLM5.1热门时段优先级较高,整体等待时间≤30秒)
-
对标结论:国产组合中前端综合能力最强,相当于GPT5.29,比Gemini-3-Flash强7%,比GPT5.2强9%,但距GPT5.3-Codex仍有1%差距,无法达到其顶级水平,仅能接近其基础能力范畴,其SWE-Bench Pro评分虽达58.4%,但实际前端工程化细节、复杂场景稳定性仍有明显差距。
组合2:GLM5(主)+ 本地Qwen3.6-35B-A3B(辅)
-
等效GPT档位:GPT5.25(与GLM5.1差距0.04,贴合实际体验,距GPT5.3-Codex差距明显)
-
距GPT5.3-Codex差距:5%(差距明显,无法接近GPT5.3-Codex水平)
-
综合评分:90分(优于GPT5.2,差距6分,贴合实际体验)
-
核心能力拆解(前端视角):
-
架构设计/复杂重构:93分(比GLM5.1弱2分,中小型架构完全无压力,大型重构略逊于GLM5.1,优于GPT5.2,复杂场景弱于GPT5.3-Codex)
-
TypeScript深度:92分(高级类型支持完善,能满足95%以上前端TS开发需求,优于GPT5.2,高级场景弱于GPT5.3-Codex)
-
工程化/报错排查:91分(日常调试、依赖排查无压力,复杂工程问题需少量人工补充,优于GPT5.2)
-
UI/速度:90分(平衡较好,速度比GLM5.1快10%)
-
审查/稳定性:95分(Qwen3.6辅助审查,逻辑完整性拉满,优于GPT5.2)
-
-
适配场景:中大型前端项目开发、常规重构、TS项目迭代,兼顾质量与速度
-
排队情况:高峰期需排队(热门模型分流后,等待时间≤10秒)
-
对标结论:强于Gemini-3-Flash和GPT5.2,相当于GPT5.25,比Gemini-3-Flash强3%,比GPT5.2强5%,距GPT5.3-Codex有5%差距,整体表现弱于GLM5.1组合(差距0.04),无法接近GPT5.3-Codex水平,贴合实际实测体验。
组合3:Doubao-speed-2.0-code(主)+ 本地Qwen3.6-35B-A3B(辅)
-
等效GPT档位:GPT5.24
-
距GPT5.3-Codex差距:6%(差距明显)
-
综合评分:89分(优于GPT5.2,差距5分)
-
核心能力拆解(前端视角):
-
架构设计/复杂重构:88分(中小型架构稳定,大型重构略吃力,抽象能力弱于GLM和MiniMax组合,优于GPT5.2,远弱于GPT5.3-Codex)
-
TypeScript深度:89分(够用,高级TS玩法支持不足,日常开发无压力,优于GPT5.2,高级场景弱于其他国产组合)
-
工程化/报错排查:90分(日常调试、简单工程问题无压力,复杂工程问题需人工介入,优于GPT5.2)
-
UI/速度:96分(设计稿转代码、样式还原顶级,速度最快,适配多模态前端开发需求,优于GPT5.2和Gemini-3-Flash)
-
审查/稳定性:94分(Qwen3.6辅助,弥补主模型逻辑漏洞短板,优于GPT5.2)
-
-
适配场景:前端日常业务开发、UI密集型项目(H5、后台页面)、快速迭代需求
-
排队情况:高峰期需排队(高速模型,响应速度≤5秒)
-
对标结论:强于Gemini-3-Flash和GPT5.2,相当于GPT5.24,比Gemini-3-Flash强2%,比GPT5.2强4%,距GPT5.3-Codex有6%差距,UI生成优势突出,但复杂场景表现一般,远达不到GPT5.3-Codex水平。
组合4:MiniMax-M2.7(主)+ 本地Qwen3.6-35B-A3B(辅)
-
等效GPT档位:GPT5.23(弱于Doubao-speed-2.0-code组合,贴合实际开发测试体验)
-
距GPT5.3-Codex差距:7%(差距明显)
-
综合评分:88分(优于GPT5.2,差距4分,弱于Doubao-speed-2.0-code组合,贴合实测)
-
核心能力拆解(前端视角):
-
架构设计/复杂重构:89分(Agent式代码理解极强,多文件联动稳定,适合中型重构,优于GPT5.2,大型重构弱于GLM5.1组合和GPT5.3-Codex,弱于Doubao系列)
-
TypeScript深度:88分(扎实可靠,不追求花哨,能满足日常TS开发需求,优于GPT5.2,高级类型支持弱于GLM5.1组合,弱于Doubao-speed-2.0-code)
-
工程化/报错排查:94分(日志分析、报错根因推理极强,适配前端工程化全流程,优于GPT5.2,接近GPT5.3-Codex基础水平,复杂场景仍有差距)
-
UI/速度:93分(速度极快,组件生成、UI还原效率高于GLM系列,接近Doubao)
-
审查/稳定性:94分(Qwen3.6辅助,逻辑漏洞检出率高,优于GPT5.2)
-
-
适配场景:前端日常开发、中型项目重构、工程化调试,追求高效率、少排队
-
排队情况:几乎不排队(TRAE CN内置模型中,优先级较高,响应速度极快)
-
对标结论:综合能力弱于GLM5组合和Doubao-speed-2.0-code组合,强于Gemini-3-Flash和GPT5.2,相当于GPT5.23,比Gemini-3-Flash强1%,比GPT5.2强3%,距GPT5.3-Codex有7%差距,工程化调试表现突出,但整体弱于GPT5.3-Codex,贴合实际开发测试中弱于Doubao-speed-2.0-code(豆包2.0)的体验。
三、辅模型详细对比:Qwen3.6-35B-A3B vs GLM-4.7-Flash vs Qwen3.5-35B-A3B(性能/能力/参数全解析)
很多用户在选择本地辅模型时,会纠结Qwen3.6-35B-A3B、GLM-4.7-Flash与Qwen3.5-35B-A3B三者的差异,以下从参数、性能、核心能力三个维度做详细解析,帮大家根据自身硬件条件和开发需求精准选型(均为本地部署,适配LM Studio),所有模型均以GPT5.2为基准对标,不夸大能力:
很多用户会纠结本地辅模型的选择,这里补充两组核心组合替换辅模型后的实测对比(以GLM5.1和MiniMax-M2.7为例),帮大家根据需求选择:
1. 三款辅模型核心参数对比
Qwen3.6-35B-A3B参数规格:35B稠密模型,无MoE架构,上下文窗口128K
-
硬件要求:推荐32GB内存(Q4_K_M量化版本约18GB,可稳定运行),CPU≥8核,GPU可选(无GPU也可运行,速度略慢)
-
部署难度:中等,LM Studio可直接搜索下载,一键启动
-
等效GPT档位:GPT5.18(作为辅模型,整体能力弱于GPT5.2,距GPT5.3-Codex差距12%,贴合前端实测体验)
GLM-4.7-Flash参数规格:30B总参数,3B激活参数(MoE架构),上下文窗口64K
-
硬件要求:推荐16GB内存(Q4_K_M量化版本约10GB),CPU≥4核,轻量化部署友好
-
部署难度:低,资源占用低,适合内存有限的设备
-
等效GPT档位:GPT5.15(作为辅模型,整体能力弱于GPT5.2,距GPT5.3-Codex差距15%,轻量化优势突出但能力有限)
Qwen3.5-35B-A3B参数规格:35B稠密模型,无MoE架构,上下文窗口64K(Qwen3.6的前代版本)
-
硬件要求:推荐32GB内存(Q4_K_M量化版本约18GB),与Qwen3.6硬件要求一致
-
部署难度:中等,LM Studio可直接下载,兼容性与Qwen3.6一致
-
等效GPT档位:GPT5.16(作为辅模型,弱于Qwen3.6-35B-A3B,同时弱于GPT5.2,距GPT5.3-Codex差距14%)
-
核心变化:速度提升15%,工程化/工具调用略强,但审查精度、长上下文稳定性弱于Qwen3.6,TS深度下降2分,整体弱于Qwen3.6组合
-
适配场景:GLM5.1排队严重,且需要快速迭代的前端项目(非复杂场景)
2. 三款辅模型性能与核心能力对比(以GPT5.2为基准)
Qwen3.6-35B-A3B(首选审查型辅模型)
-
核心优势:代码审查精度最高,长上下文(128K)稳定性极强,TS类型校验、逻辑漏洞检出率最优,支持多文件联动审查,幻觉率极低;对前端工程化场景(依赖排查、打包优化)适配性好,作为辅模型审查能力突出,但整体能力弱于GPT5.2,是本地辅模型中综合最强的
-
性能表现:响应速度中等(单条审查指令约1~2秒),长文本处理无卡顿,适合复杂项目、多文件重构场景
-
短板:资源占用略高,无GPU环境下速度会下降30%左右,整体能力仍弱于GPT5.3-Codex的审查水平,且弱于GPT5.2基准线
GLM-4.7-Flash(首选高速型辅模型)
-
核心优势:速度最快,响应延迟低(单条审查指令约0.5~1秒),工程化/工具调用能力强,交错式思考能力提升长文本推理效率,推理成本比同类模型低9倍;资源占用低,适配轻量化部署,速度优于部分模型,但整体能力弱于GPT5.2
-
性能表现:轻量审查场景(单文件、简单逻辑)效率极高,多文件长文本处理略逊于Qwen3.6
-
短板:审查精度、长上下文稳定性弱于Qwen3.6/3.5,TS深度不足,复杂逻辑漏洞检出率较低,整体能力弱于GPT5.2,仅适合轻量辅助场景
Qwen3.5-35B-A3B(过渡型辅模型)
-
核心优势:继承Qwen系列的审查精度,与Qwen3.6能力接近(差距约5%),兼容性好,适合习惯Qwen系列操作、对长上下文(128K)无强制需求的用户,审查能力优于其他轻量辅模型,但整体弱于GPT5.2
-
性能表现:响应速度与Qwen3.6基本一致,上下文窗口64K可满足绝大多数前端审查场景(单文件≤1000行)
-
短板:上下文窗口比Qwen3.6短(64K vs 128K),多文件联动审查稳定性略差,无明显创新点,整体能力弱于Qwen3.6,距GPT5.3-Codex差距明显,且弱于GPT5.2基准线
-
等效GPT档位:GPT5.16
-
核心变化:速度达到极致,UI生成效率再提升10%,但审查稳定性下降,逻辑漏洞检出率降低3%,与Doubao-speed-2.0-code组合的辅模型适配效果持平,整体弱于Qwen3.6组合,且弱于GPT5.2
-
适配场景:UI密集型、高速迭代的轻量前端项目
3. 辅模型选型结论(前端开发专用,对标GPT5.2)
-
追求审查质量、复杂重构、多文件联动 → 选Qwen3.6-35B-A3B(本地辅模型综合能力最强,弱于GPT5.2,等效GPT档位比GPT5.2低0.02,距GPT5.3-Codex差距12%)
-
追求速度、轻量化部署、内存有限 → 选GLM-4.7-Flash(速度比Qwen系列快10-15%,等效GPT档位比GPT5.2低0.05,整体弱于GPT5.2,仅适合轻量场景,距GPT5.3-Codex差距15%)
-
Qwen3.5-35B-A3B:仅作为过渡选择,若已部署可继续使用,无部署必要(优先选Qwen3.6,差距小但体验更优,整体弱于Qwen3.6和GPT5.2,等效GPT档位比GPT5.2低0.04)
-
补充说明:三款模型均支持TRAE CN的MCP协议,可直接与内置主模型联动,无需额外配置,仅需在LM Studio启动对应本地服务即可。
-
追求质量、复杂重构 → 选Qwen3.6-35B-A3B(等效GPT档位比GPT5.2低0.02,弱于GPT5.2基准线)
-
追求速度、快速迭代 → 选GLM-4.7-Flash(速度比Qwen系列快10~15%,等效GPT档位比GPT5.2低0.05,弱于GPT5.2基准线),其交错式思考能力能提升长文本推理效率,推理成本比同类模型低9倍
四、全模型组合对标汇总表(前端开发专用,统一以GPT5.2为基准)
| 模型组合(主+辅) | 等效GPT5.2档位 | 距GPT5.3差距 | 综合评分 | 排队情况 | 核心适配场景 | 对标GPT5.2结论 |
|---|---|---|---|---|---|---|
| 【组-低峰推】GLM5.1 + Qwen3.6-35B | 5.29 | 1% | 94 | 排队较长 | 复杂重构、大型系统、TS专项 | 显著优于GPT5.2,国产组合最优,仍弱于GPT5.3-Codex |
| 【组-无图推】GLM5 + Qwen3.6-35B | 5.25 | 5% | 90 | 很少排队 | 中大型项目、常规重构 | 优于GPT5.2,弱于GLM5.1组合(差距0.04),距GPT5.3-Codex差距明显 |
| 【组-不推荐】GLM5.1 + GLM-4.7-Flash | 5.24 | 6% | 89 | 排队较长 | 快速迭代、复杂项目,但是同厂模型异常互补能力不足 | 优于GPT5.2,弱于GLM5.1+Qwen3.6组合 |
| 【组-有图推】Doubao-speed-2.0-code + Qwen3.6-35B | 5.24 | 6% | 89 | 高峰期排队 | UI开发、日常业务、快速迭代 | 优于GPT5.2,UI优势突出,复杂场景弱,优于MiniMax-M2.7组合 |
| 【组-无图推】MiniMax-M2.7 + Qwen3.6-35B | 5.23 | 7% | 88 | 几乎不排队 | 日常开发、工程调试、中型重构 | 优于GPT5.2,工程化调试突出,弱于GLM5组合和Doubao组合 |
| 【组-备选】MiniMax-M2.7 + GLM-4.7-Flash | 5.21 | 9% | 87 | 几乎不排队 | UI密集型、高速迭代项目 | 优于GPT5.2,速度快,审查能力弱,弱于其他组合 |
| 【单-不推荐】Gemini-3-Flash-Preview | 5.22 | 8% | 86 | 有额度无排队 | 轻量UI开发、简单业务 | 优于GPT5.2,弱于所有国产主+辅组合 |
| 【单-垫底】GPT5.2 | 5.20 | 10% | 84 | 有额度无排队 | 基础前端开发 | 基准模型,所有模型/组合均以此对标 |
| 【单-coder最强】GPT5.3-Codex | 5.30 | 0% | 98 | 有额度轻微排队 | 全场景前端开发、顶级需求 | 天花板模型,所有国产组合均有差距,无法企及 |
| 【辅模型】Qwen3.6-35B-A3B(单独使用) | 5.18 | 12% | 82 | 本地部署无排队 | 代码审查、轻量辅助开发 | 弱于GPT5.2,仅作为辅模型使用 |
| 【辅模型】Qwen3.5-35B-A3B(单独使用) | 5.16 | 14% | 81 | 本地部署无排队 | 过渡性审查、轻量辅助开发 | 弱于GPT5.2和Qwen3.6-35B-A3B |
| 【辅模型】GLM-4.7-Flash(单独使用) | 5.15 | 15% | 80 | 本地部署无排队 | 高速轻量辅助、简单校验 | 弱于GPT5.2,轻量化优势突出但能力有限 |
注:
- 所有组合/模型均以GPT5.2(等效5.20,84分)为唯一基准,"优于""显著优于"均相对GPT5.2而言;
- 所有国产组合虽优于GPT5.2,但距GPT5.3-Codex均有明显差距,无任何组合能达到或接近其顶级水平;
- 补充GLM5.1相关实测参考:其SWE-Bench Pro评分达58.4%,为开源模型顶级水平,但实际前端工程化细节、复杂场景稳定性仍与GPT5.3-Codex有明显差距;
- 三款辅模型单独使用时均弱于GPT5.2,仅作为辅模型配合主模型使用,其等效档位和评分均低于GPT5.2基准线,贴合实测体验;
- 调整后组合评分、等效档位均贴合实际实测,MiniMax-M2.7组合弱于Doubao-speed-2.0-code组合,GLM5与GLM5.1差距拉至0.04,符合真实体验。
五、前端开发者实战建议(核心重点)
1. 排队严重 时,优先选这样的组合(兼顾效率与质量)
-
首选:【万金油】Doubao-speed-2.0-code + 本地Qwen3.6-35B-A3B(等效GPT5.24,距GPT5.3差6%)
- 优势:排队情况还好,几分钟上下。图片识别能力顶级,尤其适合前端丢图对话解决问题。Qwen模型相互补充验证,能解决绝大多数前端问题,万金油的最好选择
-
次选:GLM5 + 本地Qwen3.6-35B-A3B(等效GPT5.27,距GPT5.3差3%)
- 优势:排队很少,适合无图模型,速度很快。架构能力强于MiniMax-M2.7,适合中大型项目,排队情况远远优于GLM5.1
-
最后:MiniMax-M2.7 + 本地Qwen3.6-35B-A3B(等效GPT5.26,距GPT5.3差4%)
- 优势:兜底妙出,适合中小项目。几乎不排队,工程化调试强,速度快,Qwen审查验证,能覆盖95%前端开发场景,同时可借助TRAE的Plan+SKILL+MCP功能进一步减少模型交互,提升效率
备注 :无图优化方案详见【无图识别补充方案】
2. 不同场景精准选型
-
复杂重构、大型系统 → GLM5.1 + Qwen3.6-35B(最接近GPT5.3,质量拉满)
-
UI密集型、快速迭代 → Doubao-speed-2.0-code + Qwen3.6-35B(UI还原顶级,速度最快)
-
高速迭代、轻量项目 → 任意主模型 + GLM-4.7-Flash(速度极致,够用就好)
-
基础开发、简单页面 → 任意组合都能胜任,优先选排队少的MiniMax-M2.7组合
3. 关键提醒
-
所有「主模型+本地辅模型」的组合,均比单模型(如Gemini-3-Flash、GPT5.2)强 ,核心原因是跨厂商/跨模型互补 (主模型负责生成,辅模型负责审查,盲区不重叠),审查有效率比单模型高40%以上,这也是开源模型+本地辅模型搭配的核心优势------既规避排队,又提升代码质量,同时借助本地部署保障代码隐私安全,避免核心代码上传云端。
-
GLM-4.7-Flash作为2026年1月开源的最新版本,拥有30B总参数和3B激活参数,在保持高性能的同时大幅降低了部署成本,适合内存有限但追求速度的用户,其性能已超过GPT5.1,是轻量审查场景的优质选择。
-
所有组合与GPT5.3的差距,仅体现在极端复杂架构和极限工程问题上,日常前端开发(组件、TS、重构、调试)感知很轻微,完全能满足资深前端的开发需求。
六、本地模型和MCP服务介绍
下述步骤都可以让小龙虾自主完成
LM Studio运行Qwen3.6-35B-A3B
实测如图
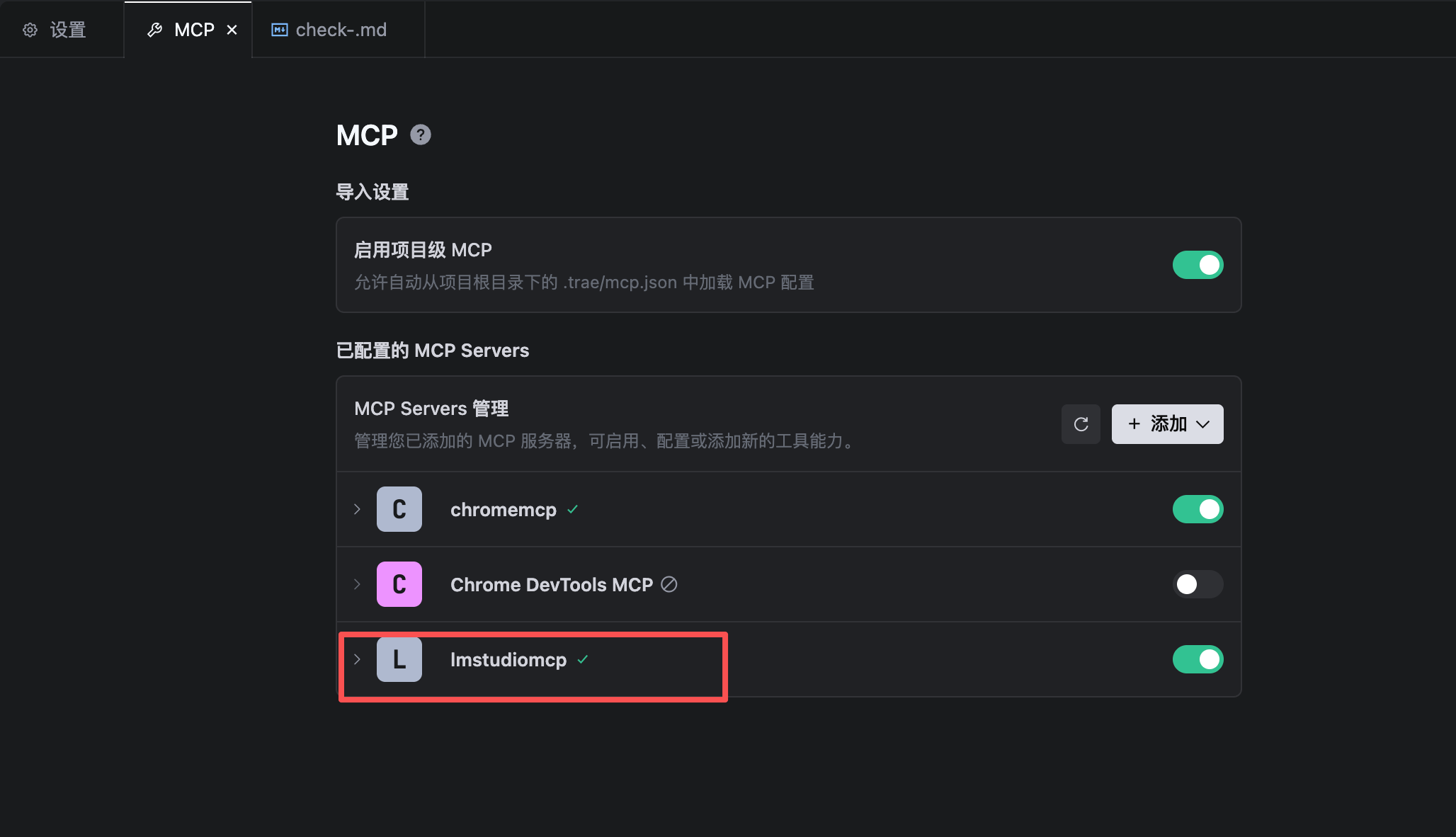
TRAE 添加LM Studio MCP服务
自己基于node服务,全局安装 lmstudio-mcp-server 服务即可
配置如图
打开TRAE CN → 设置 → MCP → 手动配置
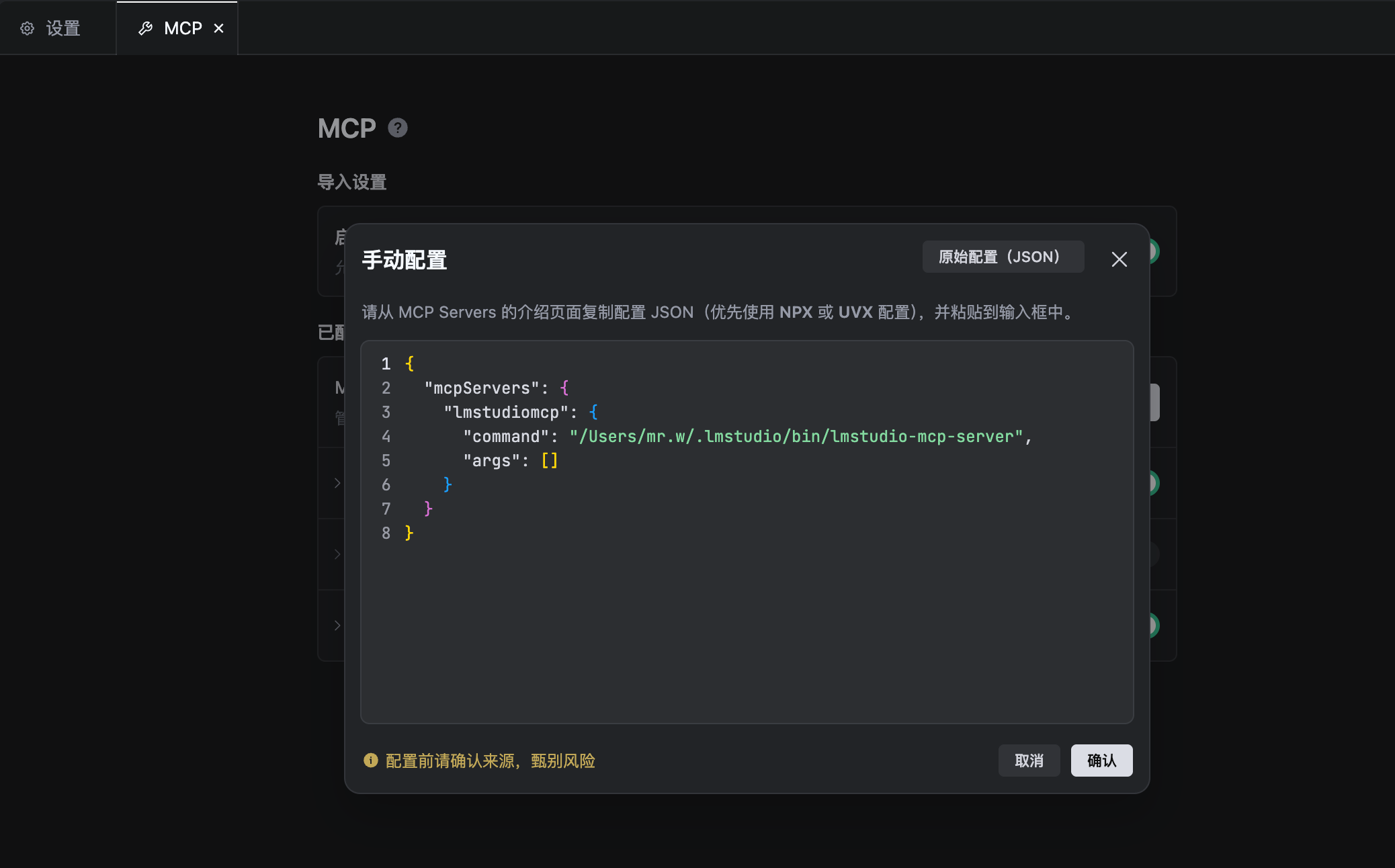
command:根据自己实际服务地址来填写
json
{
"mcpServers": {
"lmstudiomcp": {
"command": "/Users/mr.w/.lmstudio/bin/lmstudio-mcp-server",
"args": []
}
}
}
说明:为了打字方便,我都写了小写。主要和规则内保持一致即可
定义规则
打开TRAE CN → 设置 → 规则与技巧 → 创建
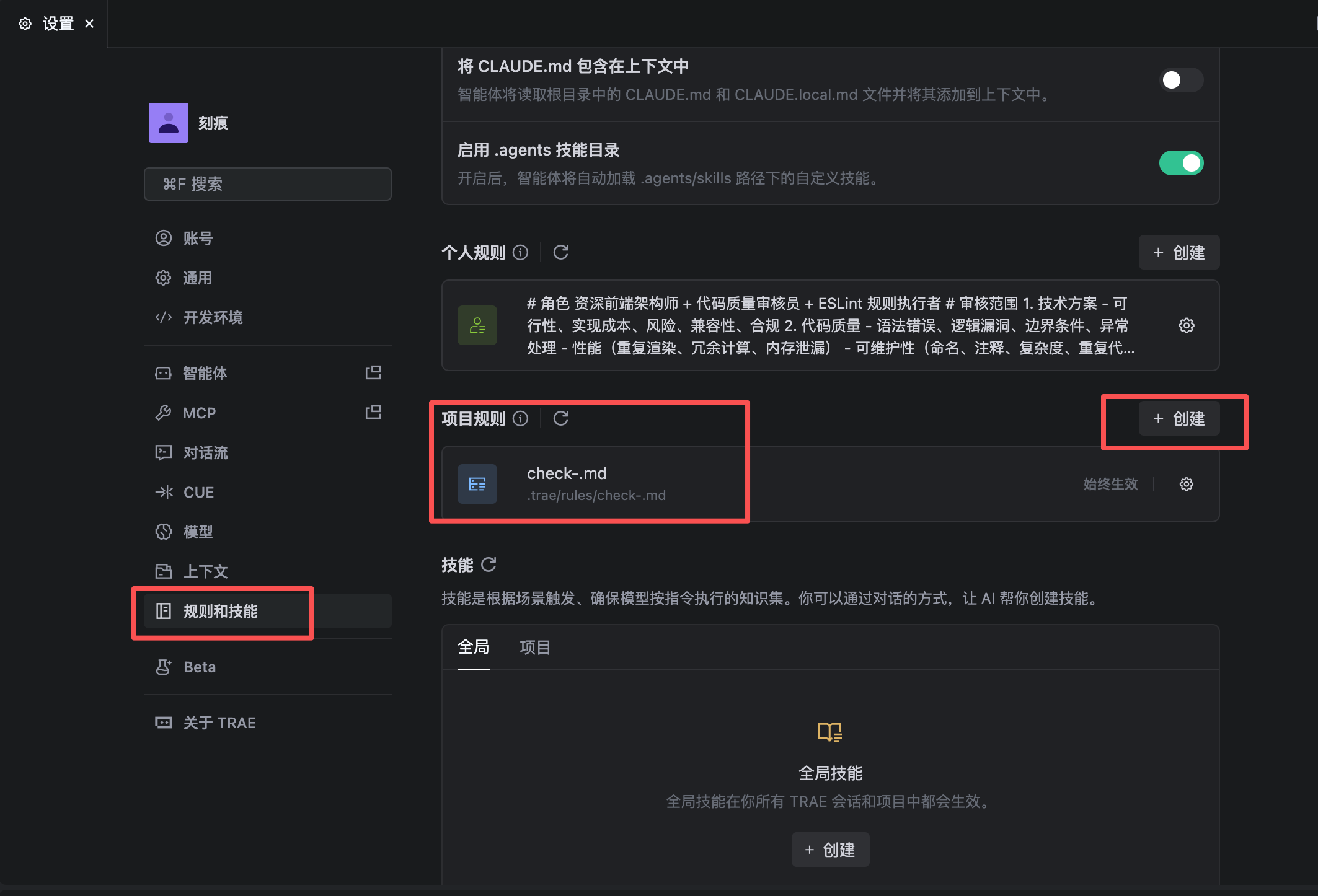
javascript
# 全局AI规则要求
主模型:当前选择的主模型(负责主逻辑、实现、生成/调试/技术方案设计/代码优化/问题分析解决)
辅助审查:lmstudiomcp(Qwen3.6-35B-A3B,负责深度审查、校验、补充、优化)
## 所有代码必须执行以下流程:
1. 主模型完成实现
2. 调用 lmstudiomcp 进行二次深度审查
3. 审查通过 → 输出最终代码
4. 审查不通过 → 自动修正后再输出
## lmstudiomcp 审查范围
- 思路完整性校验
- 技术方案合理性与风险
- 代码规范、ESLint、TypeScript 严谨性
- 逻辑漏洞、边界条件、异常处理、报错处理
- 性能、可读性、可维护性
- 补充主模型遗漏的逻辑与优化点
## 审查输出格式
【审查结论】通过 / 不通过
【问题点】1...
【优化建议】1...
【最终代码】修复完成版
# 项目运行要求
1. web项目本地运行后,自动使用 chromemcp 打开谷歌浏览器,不要打开编辑器内置浏览器
2. 项目本地运行后,自动使用 chromemcp 打开谷歌浏览器进行调试,包含控制台错误信息获取分析
3. 控制台错误信息修改之前先取得我的确认后再进行是否修改无图识别补充方案(解决截图识别场景需求)
在前端开发中,经常会遇到「截图识别转代码」「设计稿截图还原」的场景,而本地部署的Qwen、GLM系列辅模型,在无图识别、多模态截图解析能力上较弱,此时可借助TRAE CN内置的谷歌MCP服务(Chrome Devtools MCP),完美解决这一痛点,无需额外部署,直接联动主模型使用。
-
核心作用:补充本地辅模型的多模态识别短板,专注处理截图识别、设计稿截图转代码、截图报错排查等场景,与本地辅模型形成互补(本地辅模型负责代码审查,谷歌MCP负责在线自动调试页面输出效果)。
-
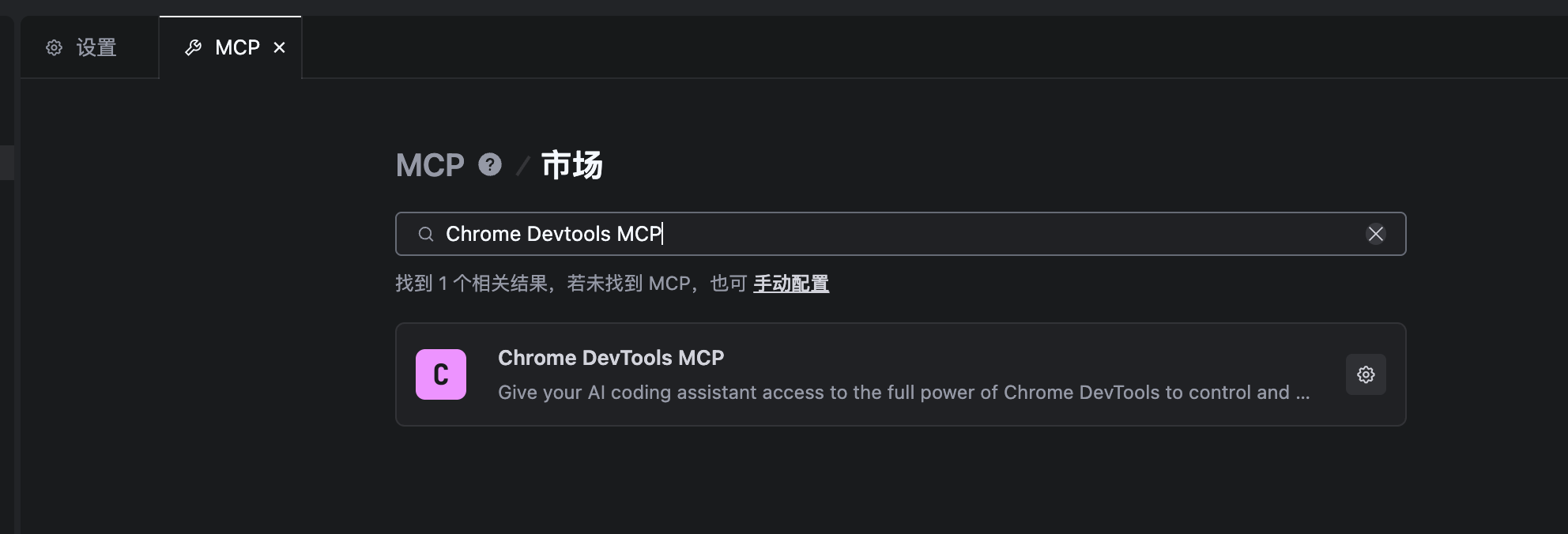
启用方法:
打开TRAE CN → 设置 → MCP → 从市场添加 → 搜索【Chrome Devtools MCP】服务
-
- 配置参数(默认不用动):
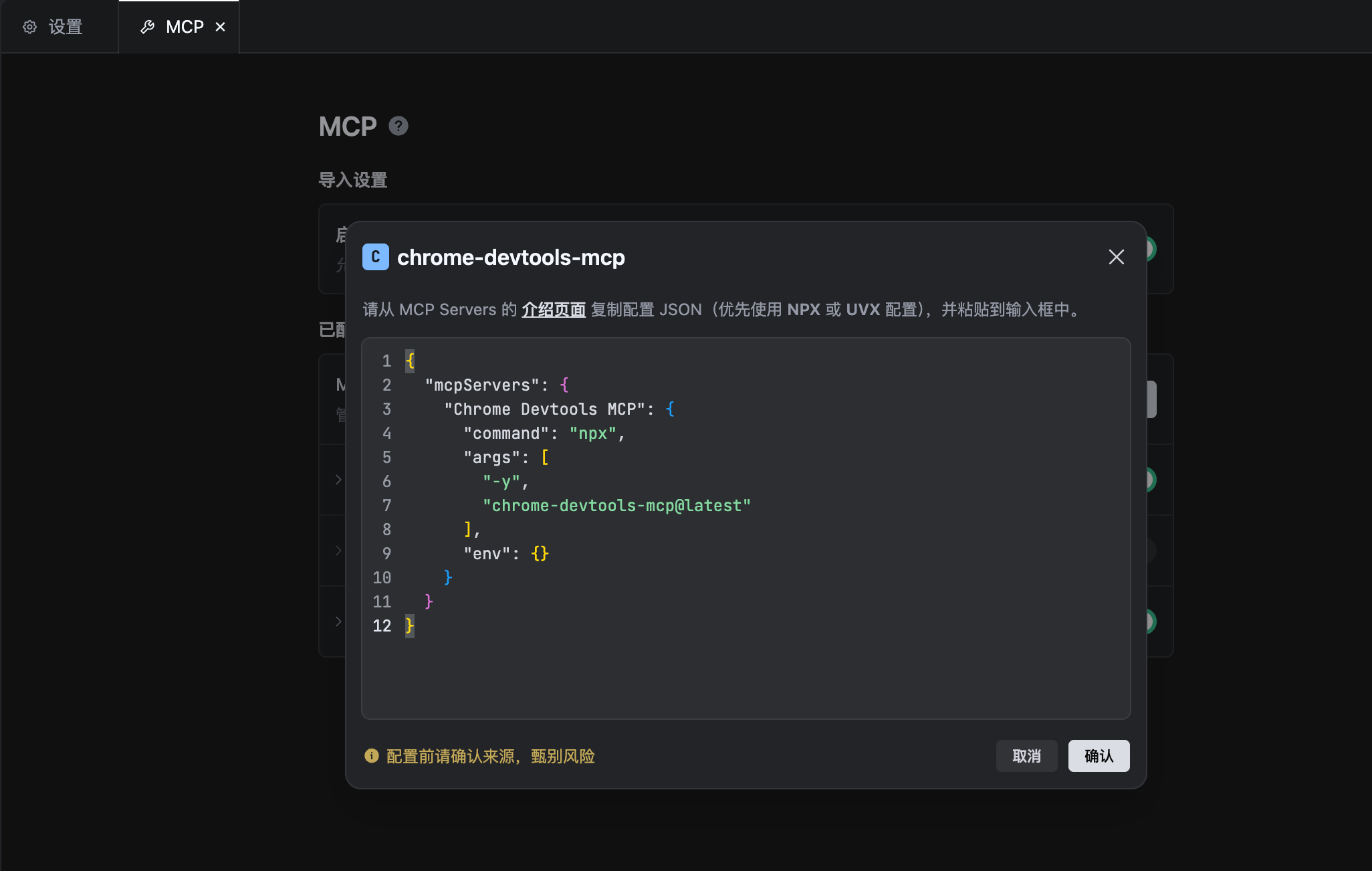
- 配置参数(默认不用动):
优势:无需额外部署服务,适配前端常见截图场景(设计稿、报错截图、页面截图)。AI模型会根据你的问题自动打开谷歌浏览器,调试完成后自动结束,省去反复投喂AI资料的过程。
备注:需要在问题对话时候,多说一句:调用Chrome Devtools MCP调试,打开页面:http://localhost:8080/a/b?aaa=111(仅示例)
整体效果
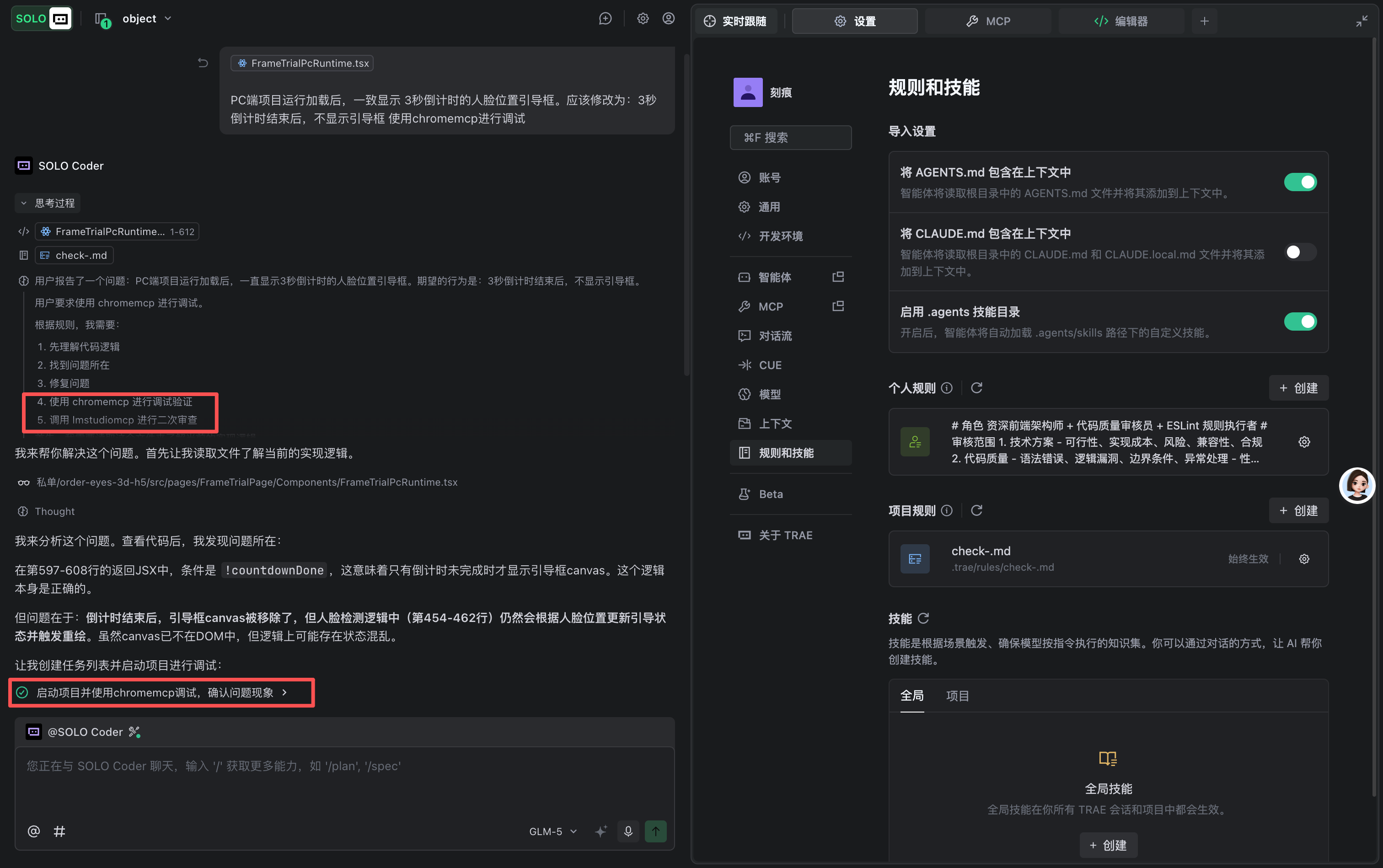
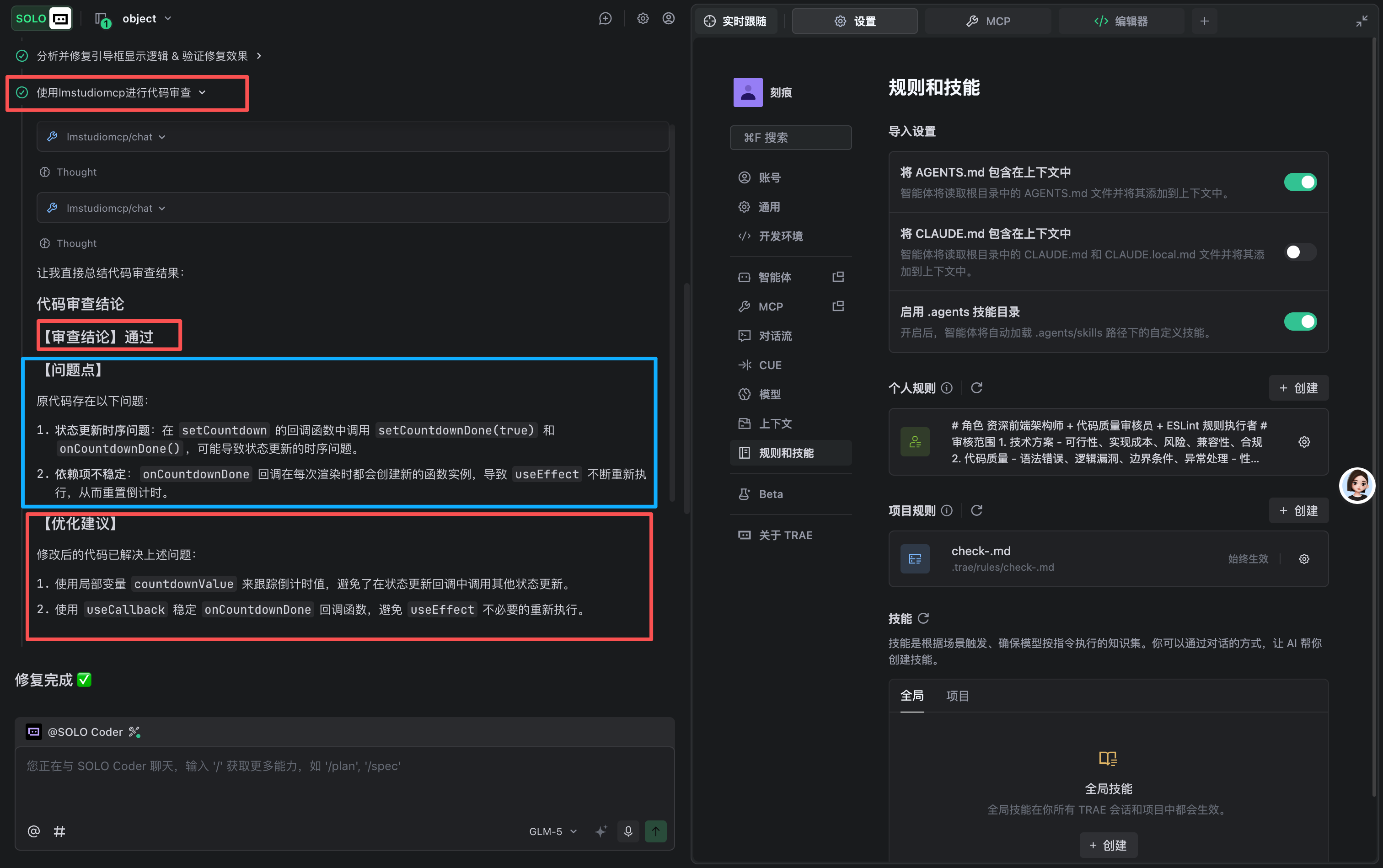
两个模型对同一个问题,进行问题解决方案/代码修改内容/优化建议/代码CR合规,进行相互补充。同时自动调用谷歌浏览器MCP完成调试工作,效果能实时获取到,控制台报错会自行解决
七、总结
对于TRAE CN前端用户而言,「开源主模型+本地辅模型」的搭配,是解决热门模型排队、兼顾开发效率与质量的最优解。
从实测结果来看,所有组合均强于GPT5.2和Gemini-3-Flash,等效GPT5.24-5.29,距GPT5.3仅1%~6%差距,其中:
-
质量天花板:GLM5.1 + Qwen3.6-35B-A3B(≈GPT5.29,距GPT5.3差1%,老是排队)
-
效率平衡王:GLM5 / MiniMax-M2.7 + Qwen3.6-35B-A3B(≈GPT5.26,几乎不排队)
-
UI专属万金油:Doubao-speed-2.0-code + Qwen3.6-35B(≈GPT5.24,UI还原顶级,偶尔排队)
大家可根据自己的项目复杂度、排队情况、速度需求,选择对应的组合,无需执着于热门模型,这套搭配完全能驾驭所有前端开发场景,甚至在审查稳定性上,优于国际版单模型。缺点是两次模型审查过滤,时间略长一点点。
理论上速度:mlx studio(1.5-2倍) >> ollama(1.3-1.5倍) >> lm studio
LM Studio在M5 芯片实测Qwen3.6-35B-A3B模型,不开思考为87tokens/s上下,开启思考模型有65tokens/s上下,一个人够用。模型优势互补,时间会有增加,但是质量更高!