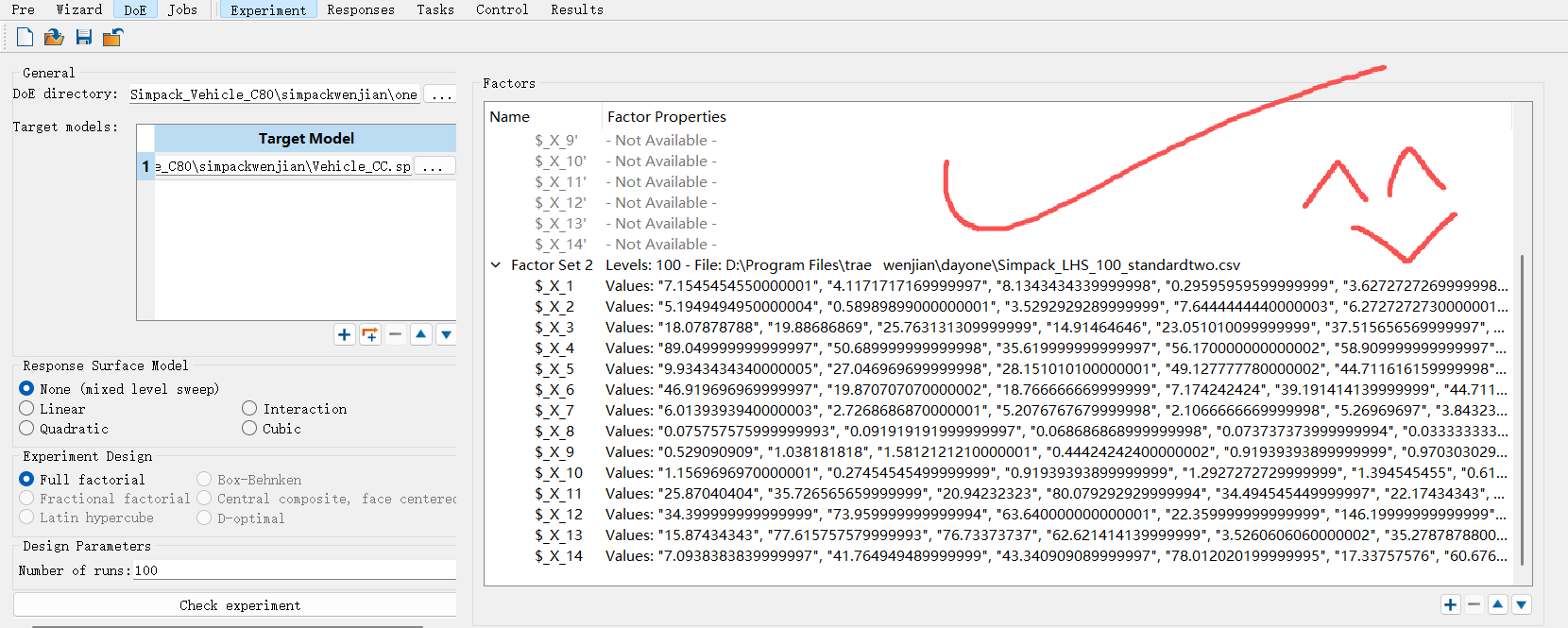
记录磕磕绊绊学simpack的全过程:
打开simpack软件:打开相应的文件到这个页面
打开DOE
第一步导入这个文件
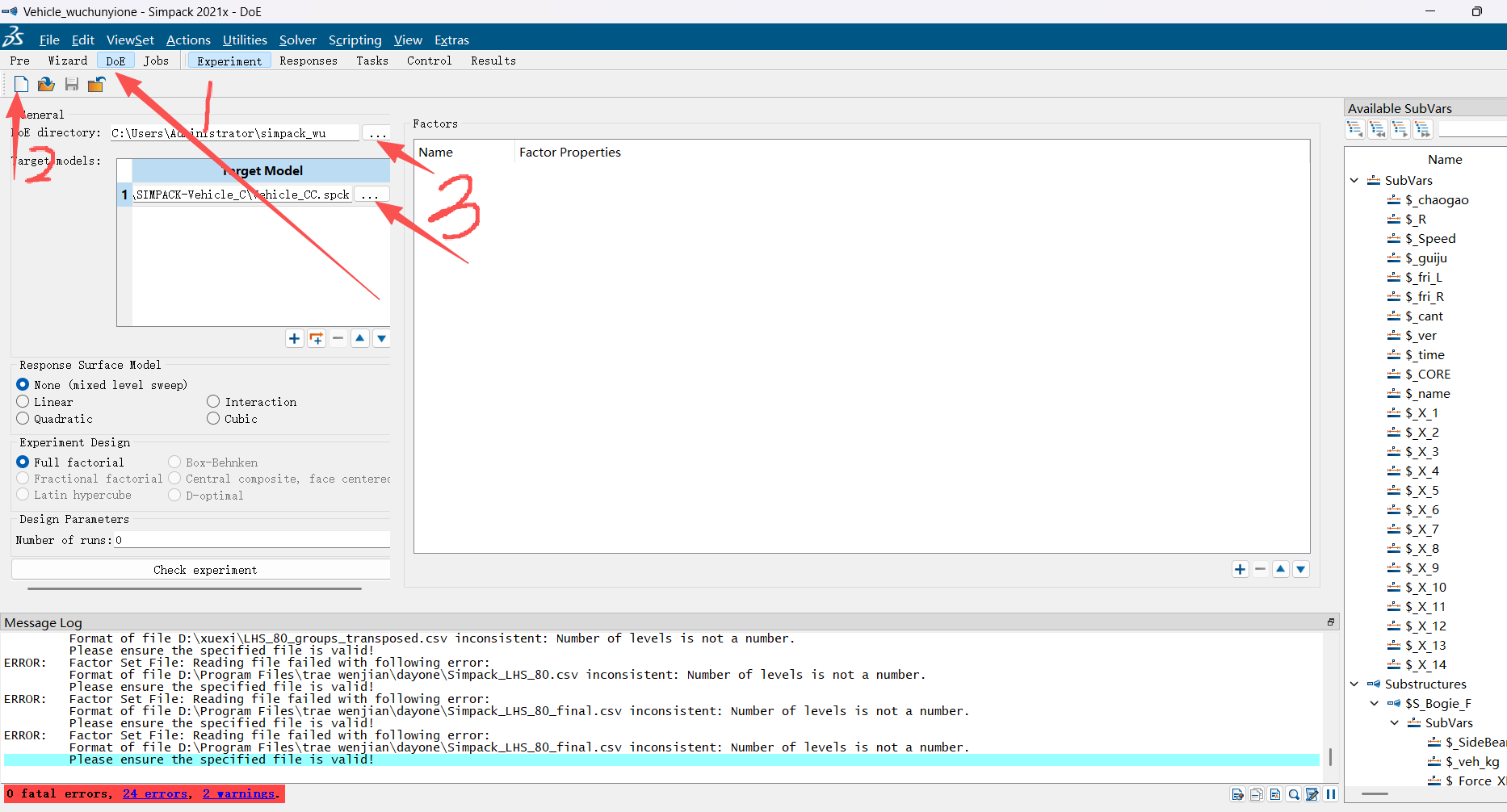
如果遇到这个界面,是配置文件位置有问题:文件位置都要不一样,第一个是DOE配置文件,第二个是需要做DOE的模型,第三个是DOE结果文件存储 的路径。
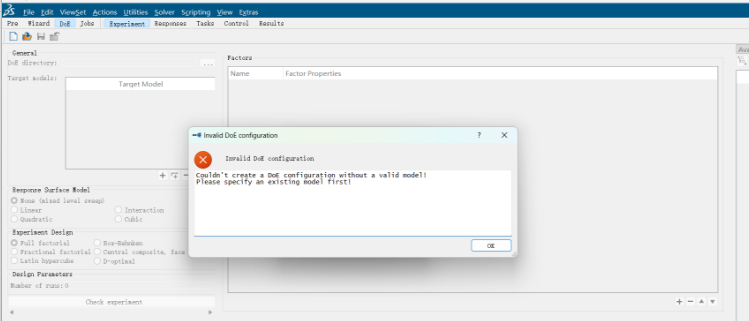
第二步:(如果不会生成csv文件)可看
1.先是生成你需要的数据,你要取那些,取的这些范围自己设,知网上查或者官网上有
2.打开trae或者其他AI软件,把你需要的这个直接截图发给AI,告诉它你要用什么模型,去抽样数据,得到csv文件
3.下面的文件只能参考,不全,要跟据你自己需要的设,AI会生成的
python
import numpy as np
import random
import pandas as pd
'''
该文件目的是:
1.接收到一组变量范围numpy矩阵以及样本需求个数,shape = (m,2),输出样本numpy矩阵
执行ParameterArray函数即可
'''
def Partition(number_of_sample,
limit_array):
"""
为各变量的变量区间按样本数量进行划分,返回划分后的各变量区间矩阵
:param number_of_sample: 需要输出的 样本数量
:param limit_array: 所有变量范围组成的矩阵,为(m, 2)矩阵,m为变量个数,2代表上限和下限
:return: 返回划分后的个变量区间矩阵(三维矩阵),三维矩阵每层对应于1个变量
"""
coefficient_lower = np.zeros((number_of_sample, 2))
coefficient_upper = np.zeros((number_of_sample, 2))
for i in range(number_of_sample):
coefficient_lower[i, 0] = 1 - i / number_of_sample
coefficient_lower[i, 1] = i / number_of_sample
for i in range(number_of_sample):
coefficient_upper[i, 0] = 1 - (i + 1) / number_of_sample
coefficient_upper[i, 1] = (i + 1) / number_of_sample
partition_lower = coefficient_lower @ limit_array.T # 变量区间下限
partition_upper = coefficient_upper @ limit_array.T # 变量区间上限
partition_range = np.dstack((partition_lower.T, partition_upper.T)) # 得到各变量的区间划分,三维矩阵每层对应于1个变量
return partition_range # 返回区间划分上下限
def Representative(partition_range):
"""
计算单个随机代表数的函数
:param partition_range: 一个shape为 (m,N,2) 的三维矩阵,m为变量个数、n为样本个数、2代表区间上下限的两列
:return: 返回由各变量分区后区间随机代表数组成的矩阵,每列代表一个变量
"""
number_of_value = partition_range.shape[0] # 获得变量个数
numbers_of_row = partition_range.shape[1] # 获得区间/分层个数
coefficient_random = np.zeros((number_of_value, numbers_of_row, 2)) # 创建随机系数矩阵
representative_random = np.zeros((numbers_of_row, number_of_value))
for m in range(number_of_value):
for i in range(numbers_of_row):
y = random.random()
coefficient_random[m, i, 0] = 1 - y
coefficient_random[m, i, 1] = y
temp_arr = partition_range * coefficient_random # 利用*乘实现公式计算(对应位置进行乘积计算),计算结果保存于临时矩阵 temp_arr 中
for j in range(number_of_value): # 计算每个变量各区间内的随机代表数,行数为样本个数n,列数为变量个数m
temp_random = temp_arr[j, :, 0] + temp_arr[j, :, 1]
representative_random[:, j] = temp_random
return representative_random # 返回代表数向量
def Rearrange(arr_random):
"""
打乱矩阵各列内的数据
:param arr_random: 一个N行, m列的矩阵
:return: 每列打乱后的矩阵
"""
for i in range(arr_random.shape[1]):
np.random.shuffle(arr_random[:, i])
return arr_random第三步:打开CSV文件
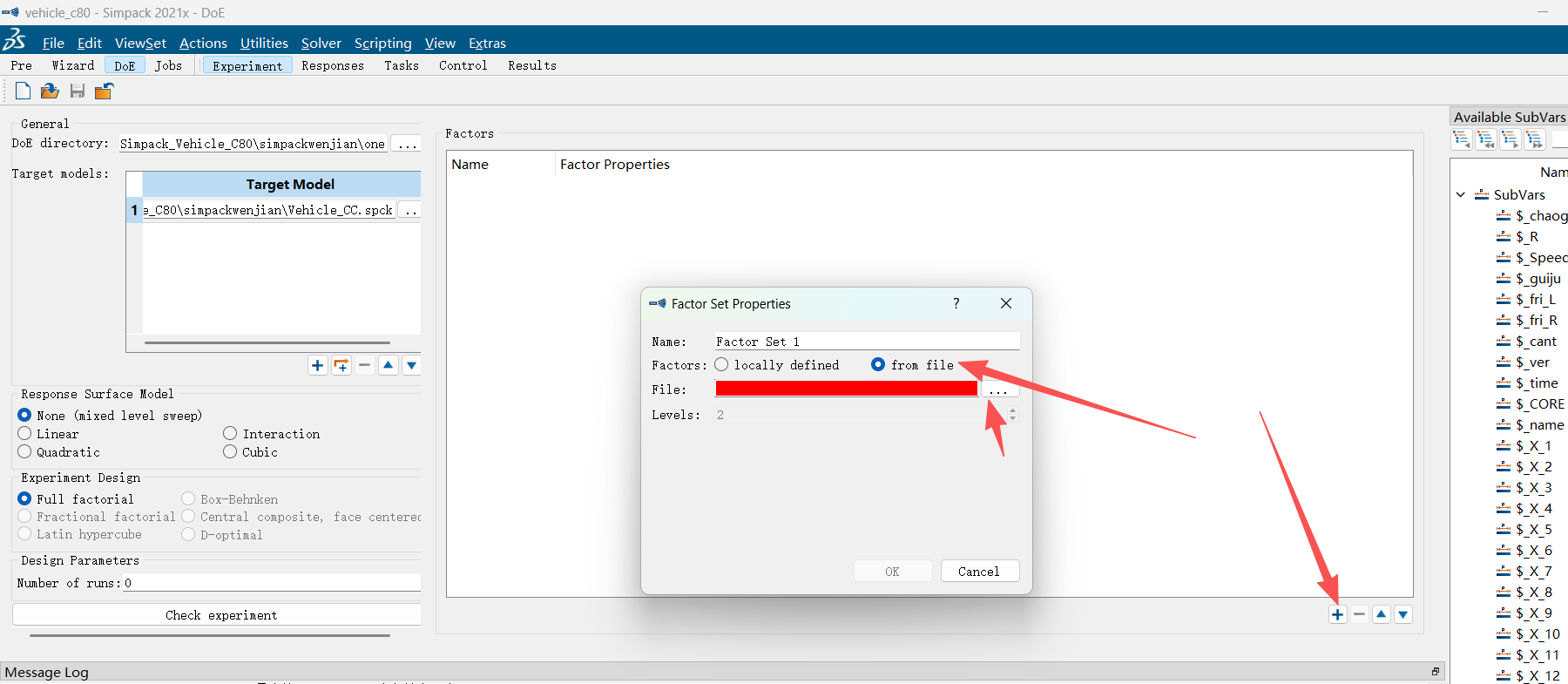
可以查看帮助文档:需要一定的版本,可能有的版本打不开
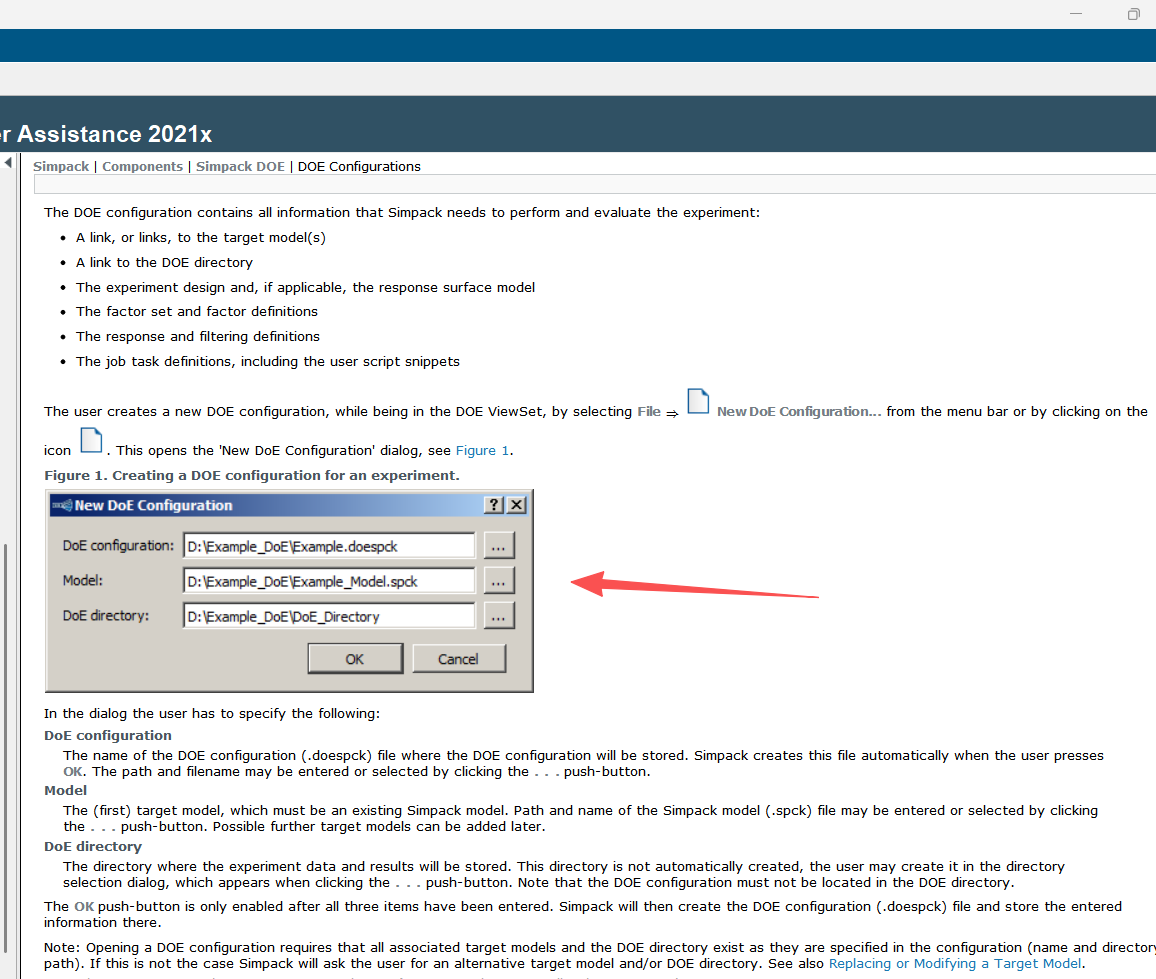
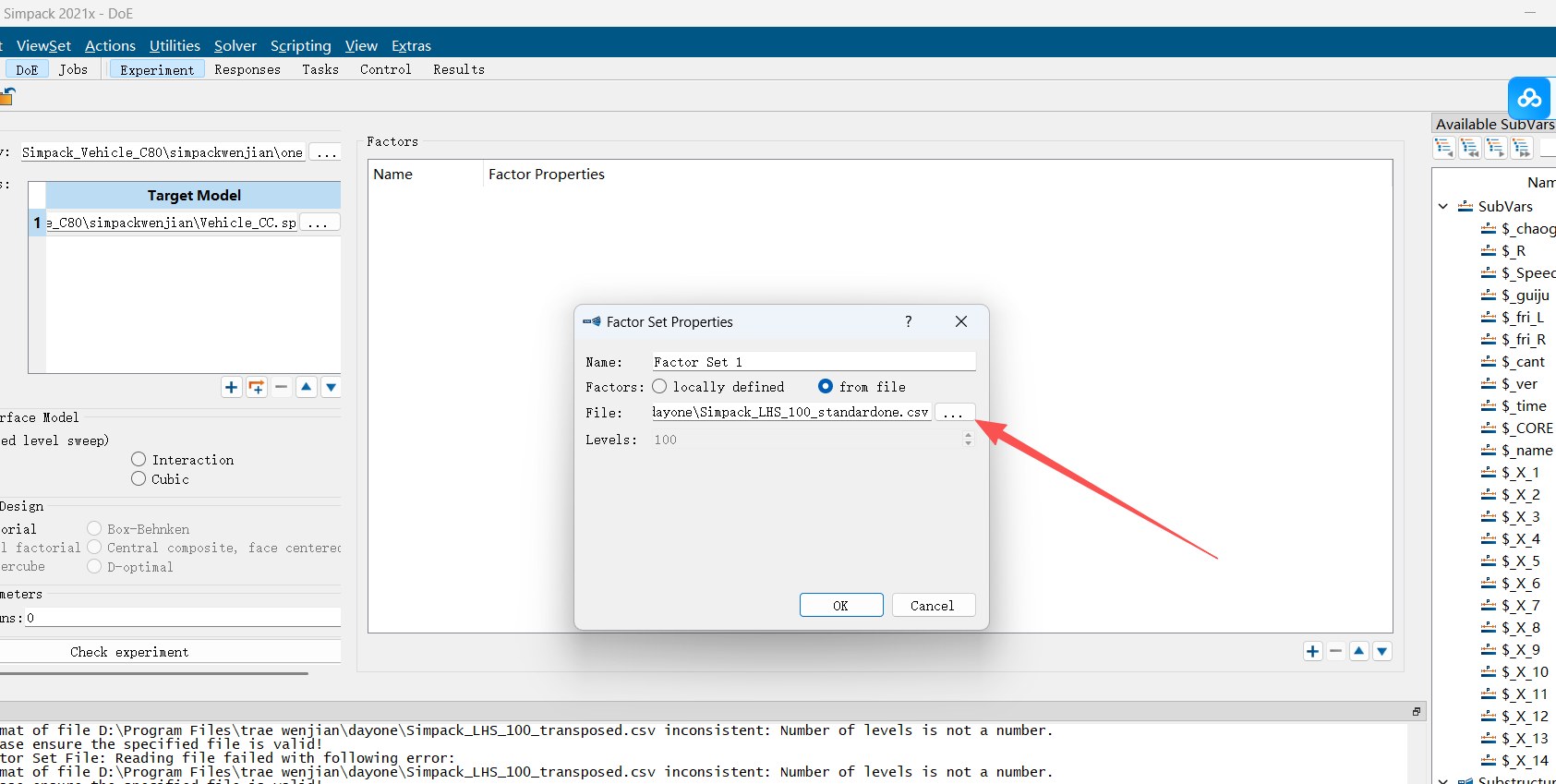
遇到问题:显示文件导入不进去,打开你的CSV文件用记事本打开,看看格式对不对,或者你文件的命名对不对,不能有空格,中文
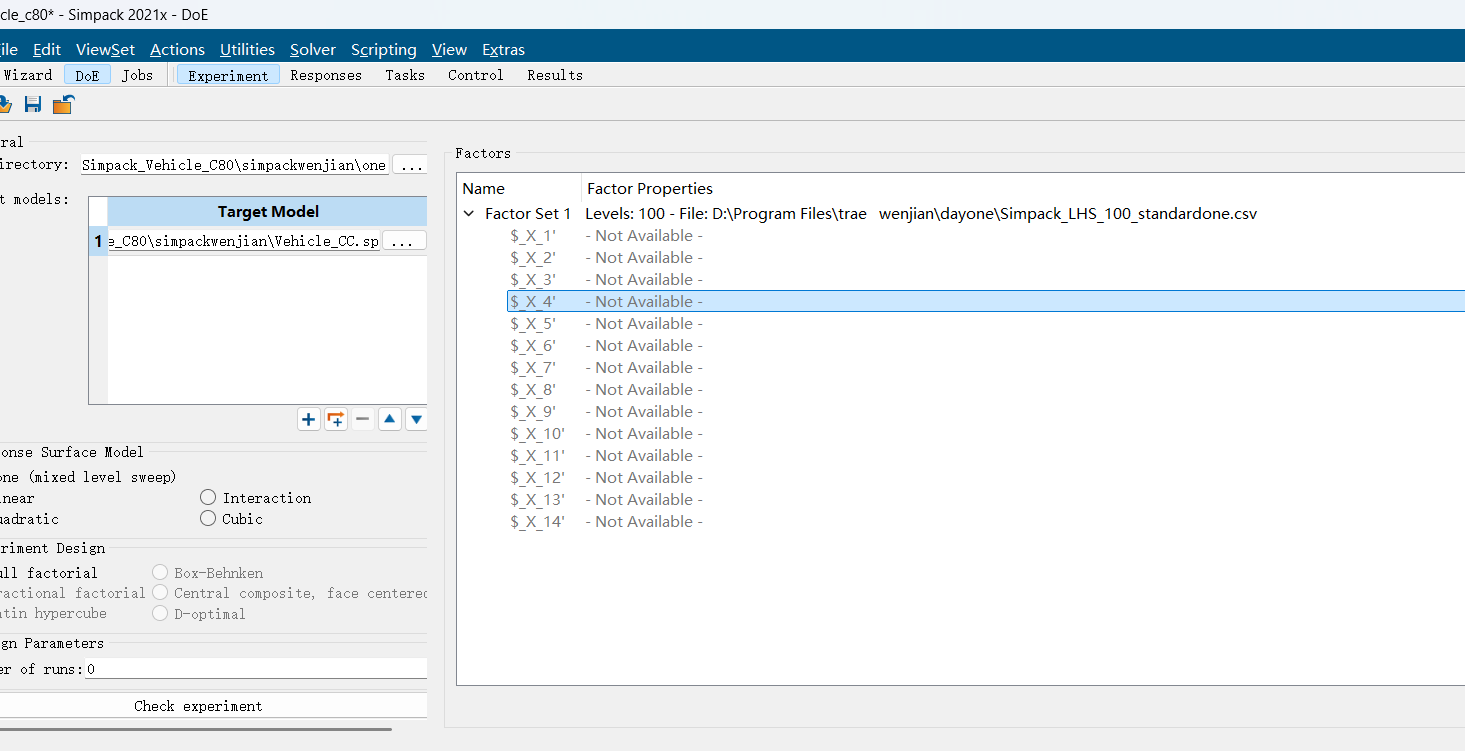
这个界面是文字命名的问题,要跟你设置的系数是完全对的上的
改文件的标点符号,有的一个可能没显示出来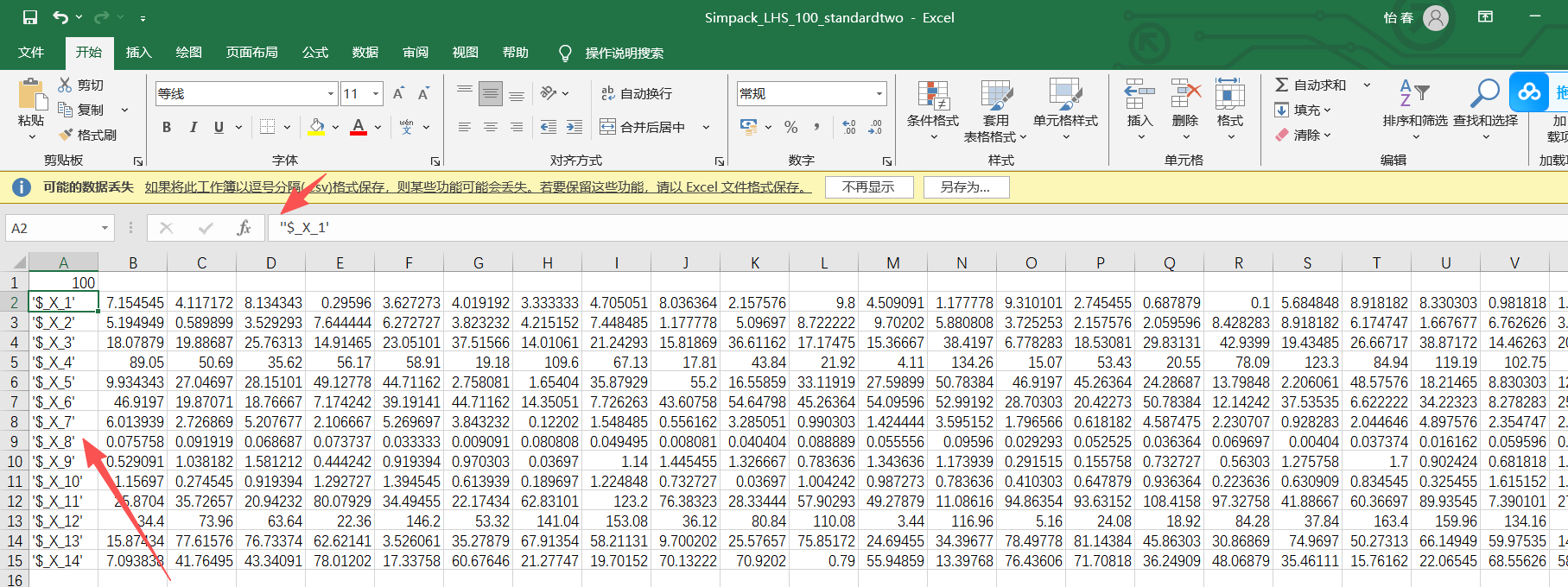
真的问题很多,每个问题都是我自己踩的坑,但坚持,一定有办法解决的