前言:
在漫长的开发岁月中,我们寻寻觅觅、跌跌撞撞一直在寻找制胜的法门。就像博主在之前开发点云相关算法的过程中,发现传统的 PCL 库仅能完成基础的点云分割与分类任务,且某些分割规则完全依赖于开发者的主观定义,这无疑增加了开发的难度和时间成本。于是我思索,有没有一种框架就像我们常见的yolo一样可以对点云做识别和分割,嘿...你猜怎么着,让我找到了这个------pointNet/pointNet++,那么就让我们一起去探寻下这个算法的奇妙吧,博主主要是针对ubuntu下的开发,windos平台教程类似。
正文:
一、简介:
关于pointNet和pointNet++呢其实我还是不喜欢来说什么定义啊、发展啊什么的,但是为了简单了解他们,还是有必要讲一下的。
PointNet和PointNet++是深度学习处理3D点云数据的两个里程碑式的工作。简单来说,PointNet开创性地实现了直接处理无序点云的思路,而PointNet++则通过引入层级结构,解决了PointNet无法捕获局部上下文信息的问题。下面我们来详细了解它们各自的原理。
💡 背景:点云数据的挑战
在PointNet出现之前,处理点云通常需要将其转换成规则的3D体素或2D视图,但这会导致计算量大和信息丢失。点云数据本身有三个核心挑战需要解决
-
无序性:点云是一个点的集合,点的顺序不影响它所代表的物体。
-
点间相互作用:相邻的点往往形成一个有意义的局部结构(如桌面、椅子腿)。
-
变换不变性:对点云进行整体的旋转或平移,不应改变其分类结果。
🧱 PointNet:点云深度学习的开山之作
PointNet的核心思想非常巧妙:它使用一个对称函数来聚合所有点的信息,从而保证模型对输入顺序不敏感。
其核心设计包含三个关键部分:
-
对称函数(Max Pooling) :这是PointNet的灵魂。网络首先通过共享权重的多层感知机(MLP)对每个点独立 地提取特征,然后使用最大池化(Max Pooling) 层,从所有点中选出每个特征维度上的最大值,组合成一个全局特征向量。由于最大池化是对集合进行操作,无论点的顺序如何,最终得到的全局特征都是一样的,完美解决了无序性问题。
-
T-Net(空间变换网络) :为了让网络对点云的旋转、平移具有变换不变性,PointNet引入了T-Net。它是一个微型的PointNet,可以学习一个变换矩阵(如旋转矩阵),并对输入点云或中间特征进行"对齐",让后续的处理更加容易。
-
局部与全局特征融合(用于分割) :对于分割任务,需要同时知道"全局是什么物体"和"这个点在哪里"。PointNet将经过最大池化得到的全局特征 ,与之前每个点的局部特征进行拼接,使得每个点都能"看到"整体和局部信息,从而完成逐点分类。
尽管PointNet很巧妙,但它对每个点独立处理,最后只用一个全局特征代表整个点云,严重缺少对局部结构的捕获能力。
⛓️ PointNet++:迈向层次化的局部特征学习
为了解决PointNet的局限性,其作者提出了PointNet++。它借鉴了卷积神经网络(CNN)中"由局部到整体"的层次化思想。
PointNet++的核心是引入了Set Abstraction(集合抽象) 模块,通过三个步骤逐层提取特征:
-
采样层(Sampling Layer) :从输入点云中选取一些点作为局部区域的中心。这里使用的是最远点采样(FPS) 算法,它能更好地覆盖整个点云空间,而不是随机采样。
-
分组层(Grouping Layer) :以上一步选取的中心点为中心,寻找其周围的邻近点,构成一个个局部区域。常用的方法是球查询(Ball Query),即以固定半径画一个球,将球内的点归为一个区域。这保证了局部区域的空间尺度。
-
PointNet层 :在每个局部区域内部,使用一个mini-PointNet来提取该区域的特征。就这样,原始的单个点被抽象成了代表局部区域的"点",点云数量变少,但每个点蕴含的信息更丰富了。
通过堆叠多个Set Abstraction模块,网络就能逐层扩大感受野,捕获从局部几何到整体形状的各级特征。
应对密度不均的挑战:多尺度分组
点云数据经常存在密度不均的问题(如激光雷达近处密、远处疏)。PointNet++提出了两种策略来保证鲁棒性:
- 多尺度分组(MSG, Multi-Scale Grouping):在同一个中心点,使用多个不同半径进行球查询,分别用PointNet提取特征后拼接在一起,从而获得多尺度的信息。
- 多分辨率分组(MRG, Multi-Resolution Grouping):将上一层提取的抽象特征与本层直接从原始点提取的特征相结合,这样在点云稀疏时,可以直接依赖更可靠的原始点特征。
上面的内容由AI生成🦐🦐🦐
可以参考链接https://hub.baai.ac.cn/view/13446![]() https://hub.baai.ac.cn/view/13446和https://cloud.tencent.com/developer/article/2009432
https://hub.baai.ac.cn/view/13446和https://cloud.tencent.com/developer/article/2009432![]() https://cloud.tencent.com/developer/article/2009432
https://cloud.tencent.com/developer/article/2009432
二、配置:
可以直接访问https://github.com/fxia22/pointnet.pytorch通过README来配置相关配置的流程,如果缺少包,安装就ok了,主要是 torch、torchvision、torchaudio这三个,当然你也可以建立自己的虚拟环境来做开发这样更加稳妥,具体的一些操作可以访问下面这篇博客:https://blog.csdn.net/weixin_43798721/article/details/144425949![]() https://blog.csdn.net/weixin_43798721/article/details/144425949上面这篇博客的内容已经写的很详细了,通过该博主的介绍可以很好的实现pointNet的demo的复现。我就不再赘述了,我们主要是讲一下对自己模型的训练和使用。
https://blog.csdn.net/weixin_43798721/article/details/144425949上面这篇博客的内容已经写的很详细了,通过该博主的介绍可以很好的实现pointNet的demo的复现。我就不再赘述了,我们主要是讲一下对自己模型的训练和使用。
三、模型训练:
和yolo类似,我们需要对点云打标签来做数据集的处理,当然在上面的demo中标签其实已经做好了,不过现在我们需要做自己的点云和需求的话,那么我们就需要自己来做标签。
1、下载cloudcompare
cloudcompare是一款点云编辑处理的软件,可以对点云做裁减和标注以及合并、导出,所以这是我们的点云处理的首选。
官网:
https://www.cloudcompare.org/![]() https://www.cloudcompare.org/参考安装教程:https://blog.csdn.net/qq_60088512/article/details/134517373
https://www.cloudcompare.org/参考安装教程:https://blog.csdn.net/qq_60088512/article/details/134517373![]() https://blog.csdn.net/qq_60088512/article/details/134517373
https://blog.csdn.net/qq_60088512/article/details/134517373
2、标注数据
我们下载好cloudcompare后,就可以打开软件开始标注了,不过你要准备好自己的数据集,我这里用pointNet的demo中椅子的数据集为例。
创建目录文件
创建data文件夹,在data下面创建points(存放点云<Nx3>)、points_label(存放每一个点的标签<Nx1>)和points_merge(cloudcompare标注好后需要保存的位置<Nx4>)文件夹。
注意: 由于cloudcompare软件后面保存数据时他把点云信息和标签信息放到了一个文件中(每一行就是一个点的 x y z label),我认为这样不好,所以建立了三个文件夹,points和points_label就是对points_merge的拆分。
bash
mkdir -p data/points data/points_label data/points_merge加载文件
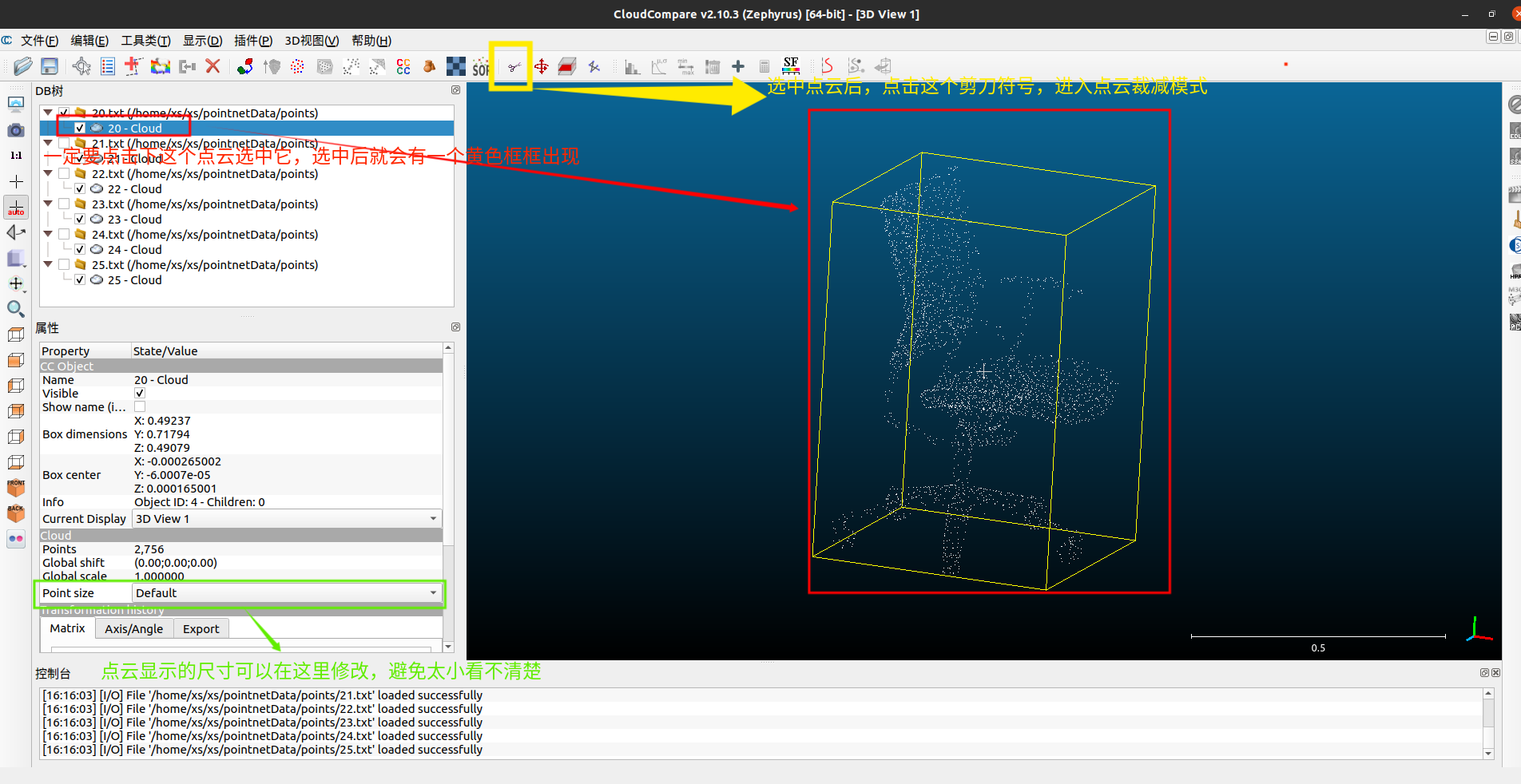
打开cloudcompare,将我们要编辑的点云拖入软件或者左上角的文件------》打开来打开文件,文件可以支持拖入和打开多个,需要注意的是左边这个框的勾选,只留需要编辑的一个点云就可以了。
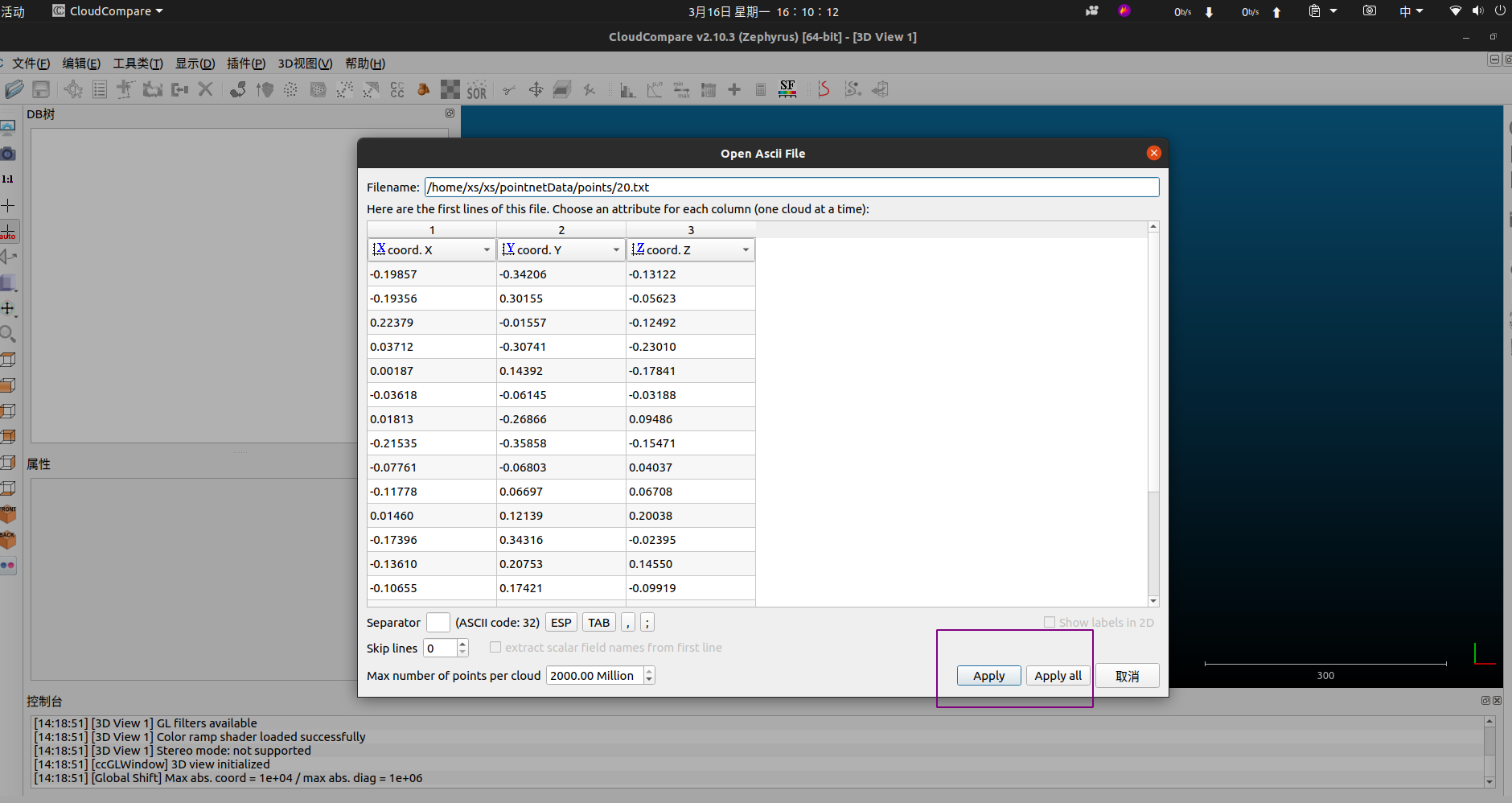
如上图,我拖入了5个文件,然后点击Apply或者Apply all都可以,那么就会有下面的这种结构出现。
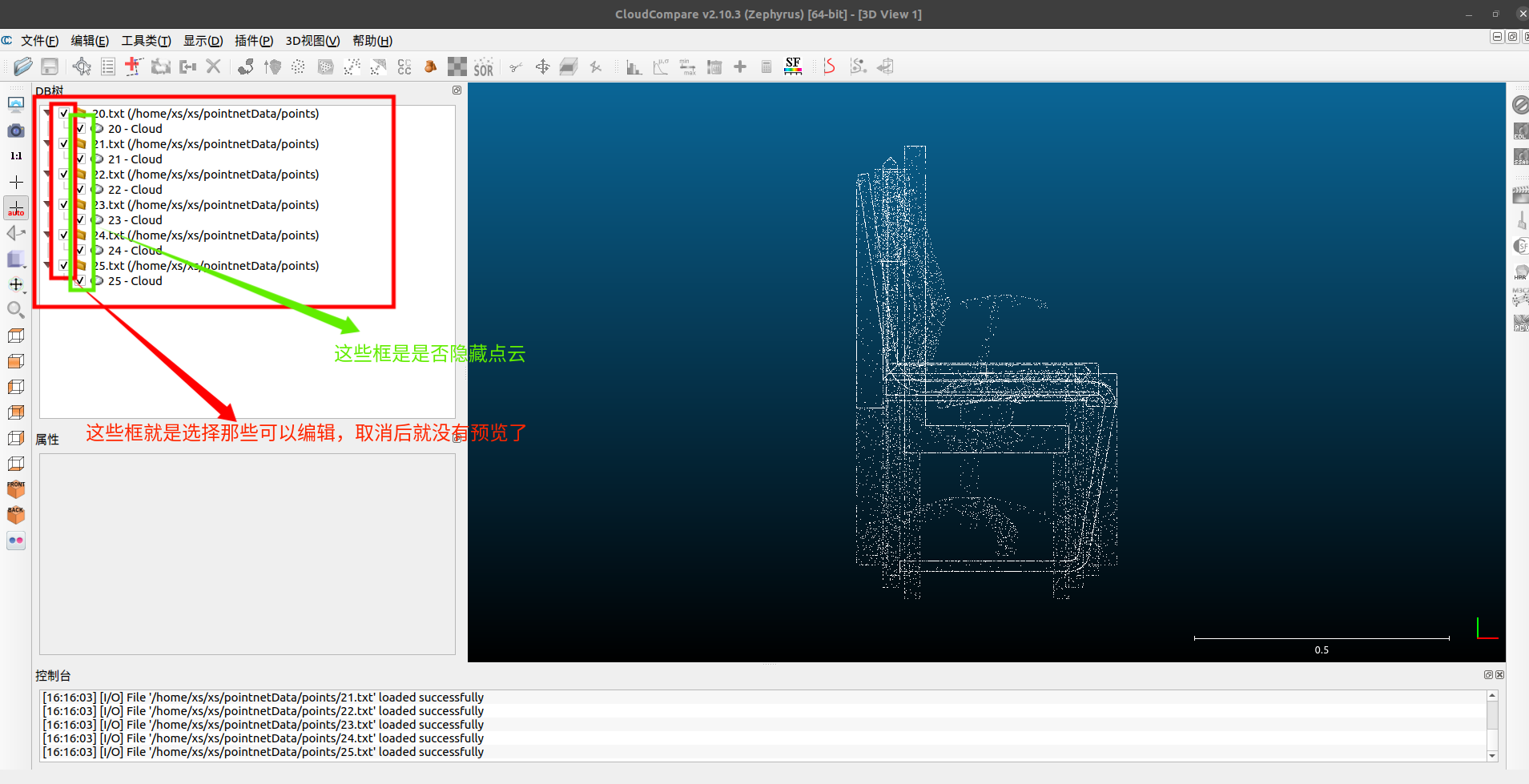
我们可以取消除了需要标注点云的其他点云,如:我这里先只留20.txt点云
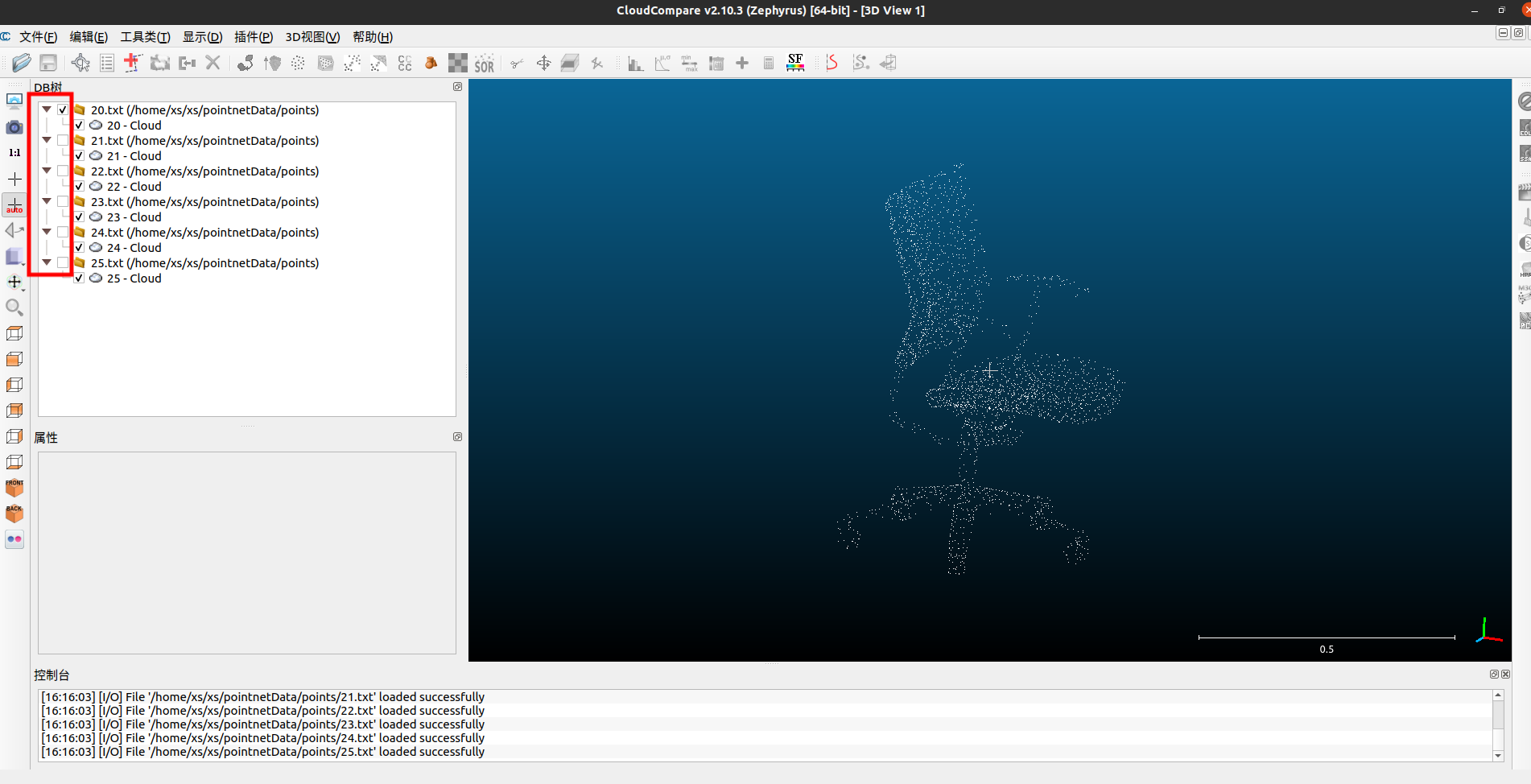
分割点云
我们首先需要对点云做人为的分割处理,然后才能打标签;具体的操作参考下面的图片。
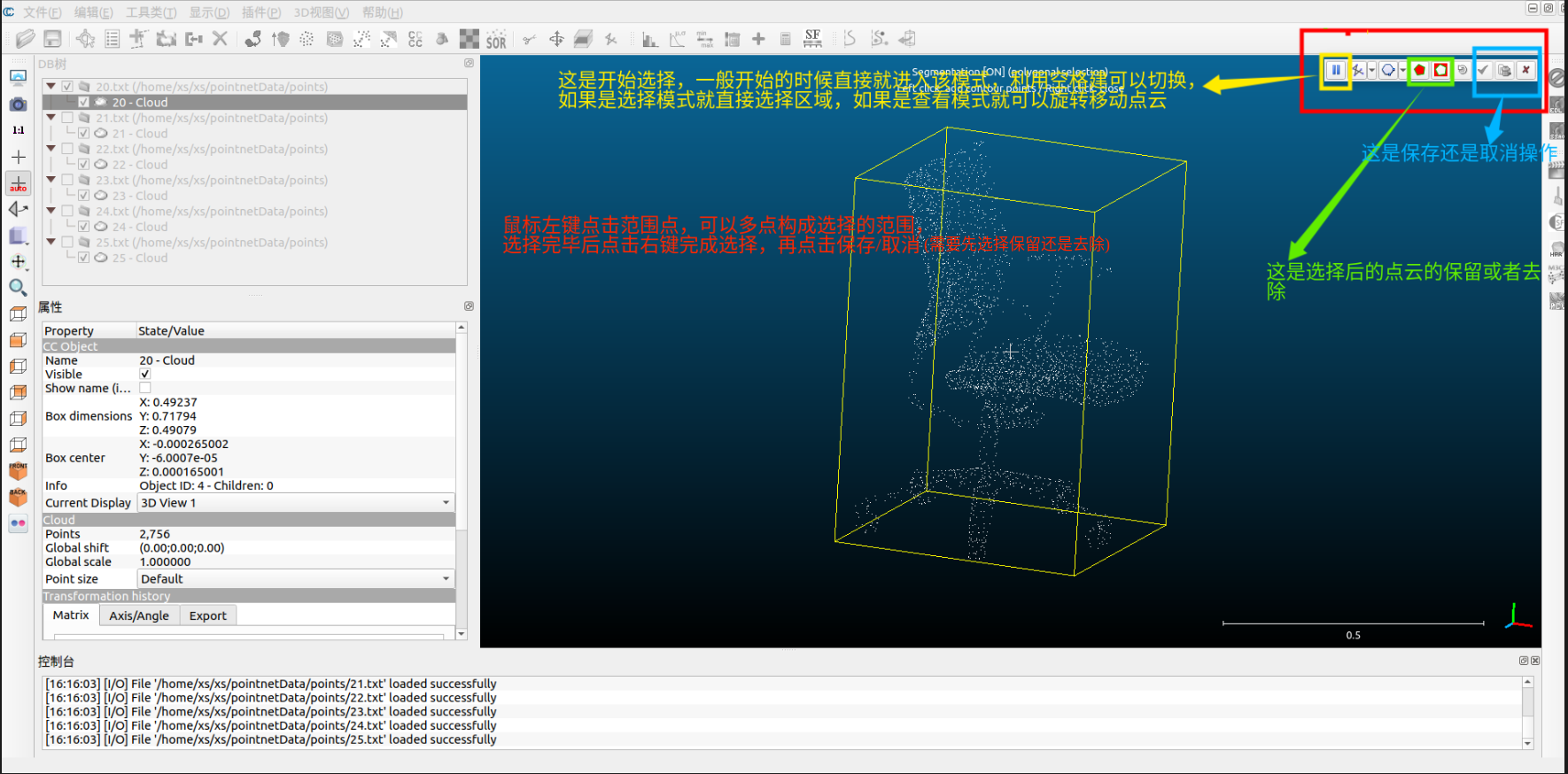
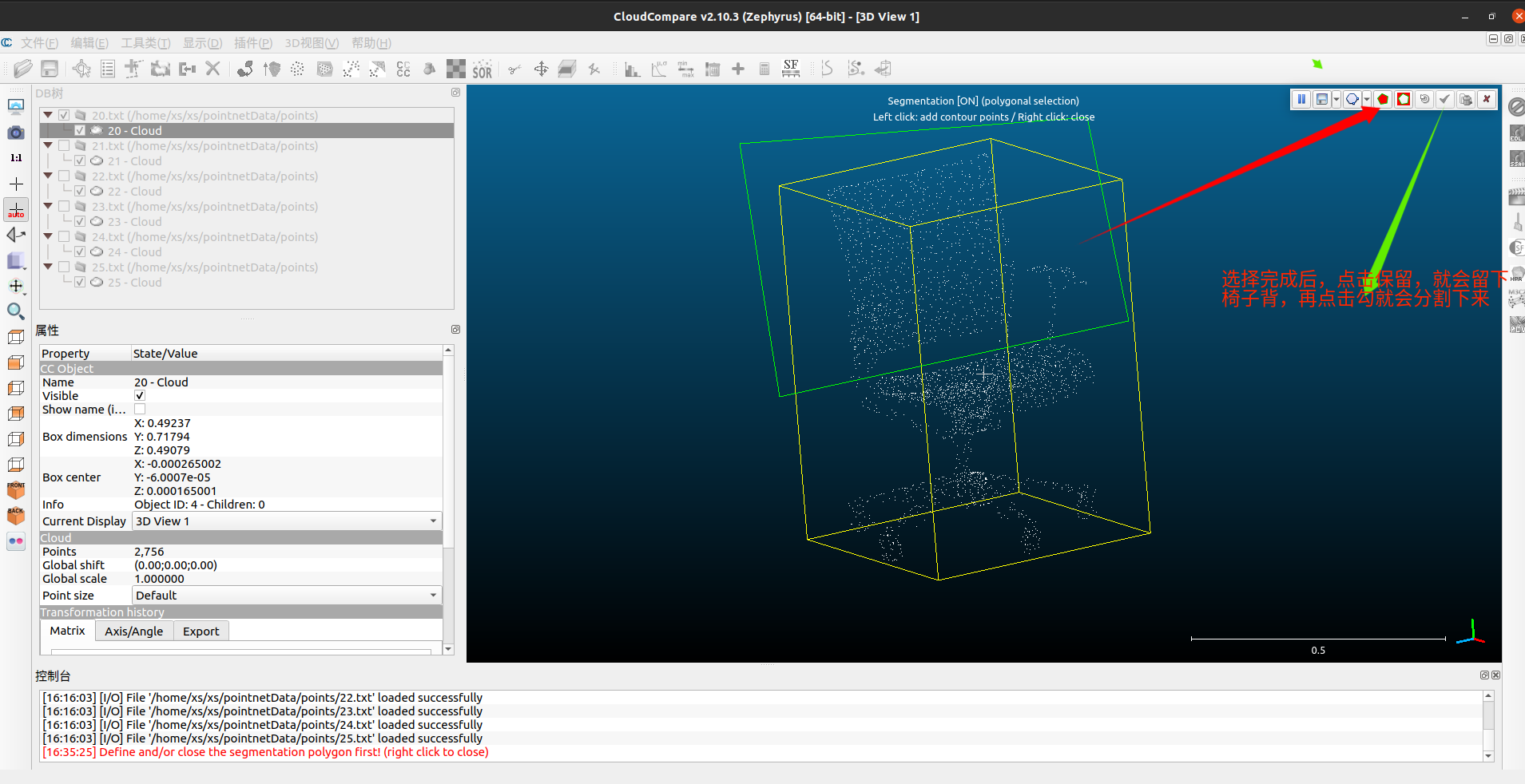
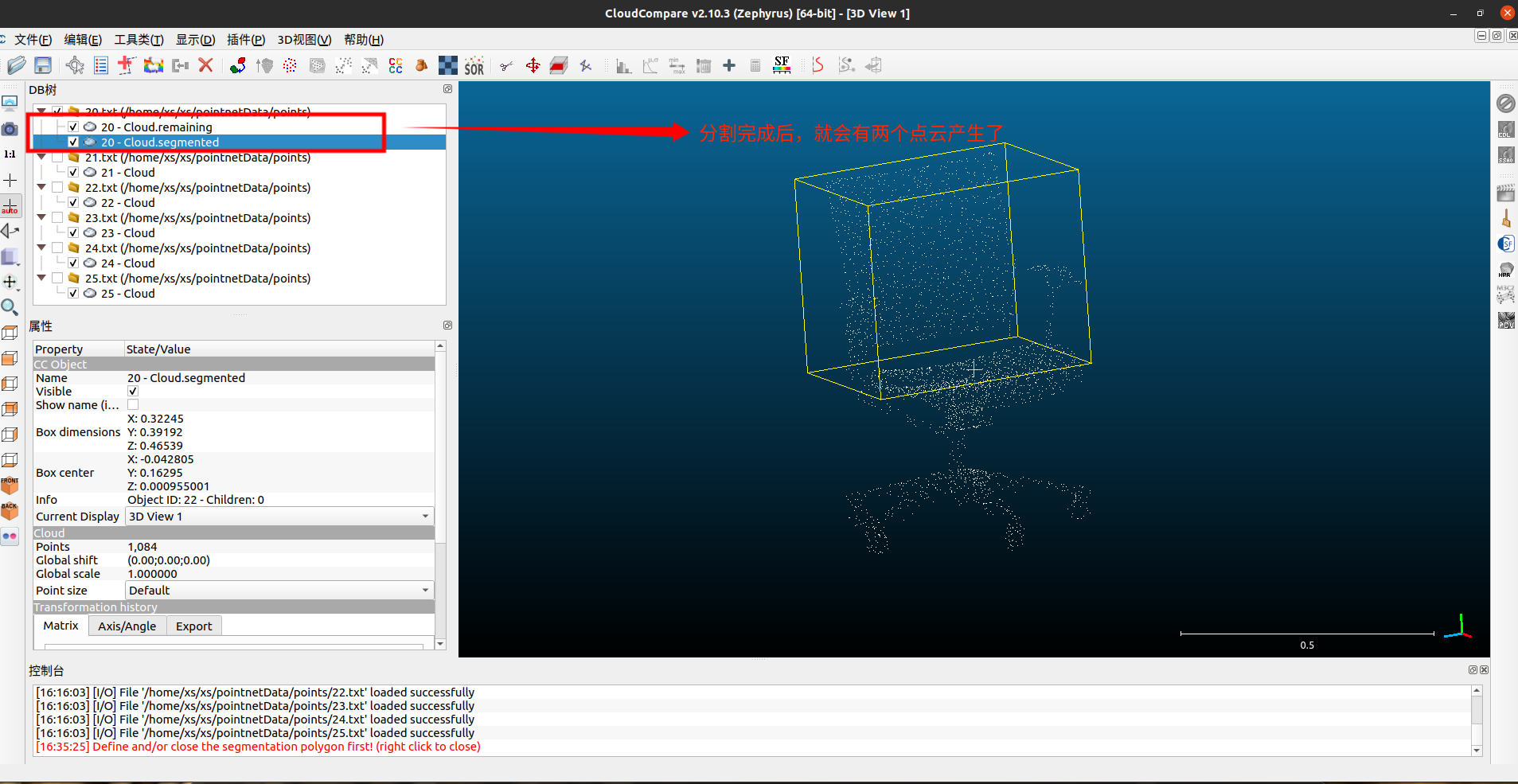
如果,你绝得自己分割的还不够好,你可以选择你分割出来的点云继续上面的操作,也可以在上面点击保留后先不要点击绿色的勾,再做一次选择(此时就需要空格键切换模式了),点击保留/去除后再点绿色的勾。
标注点云
我这里要做的是二分,所以就只做标注0、1就够了,具体的工作需要看你的需求。
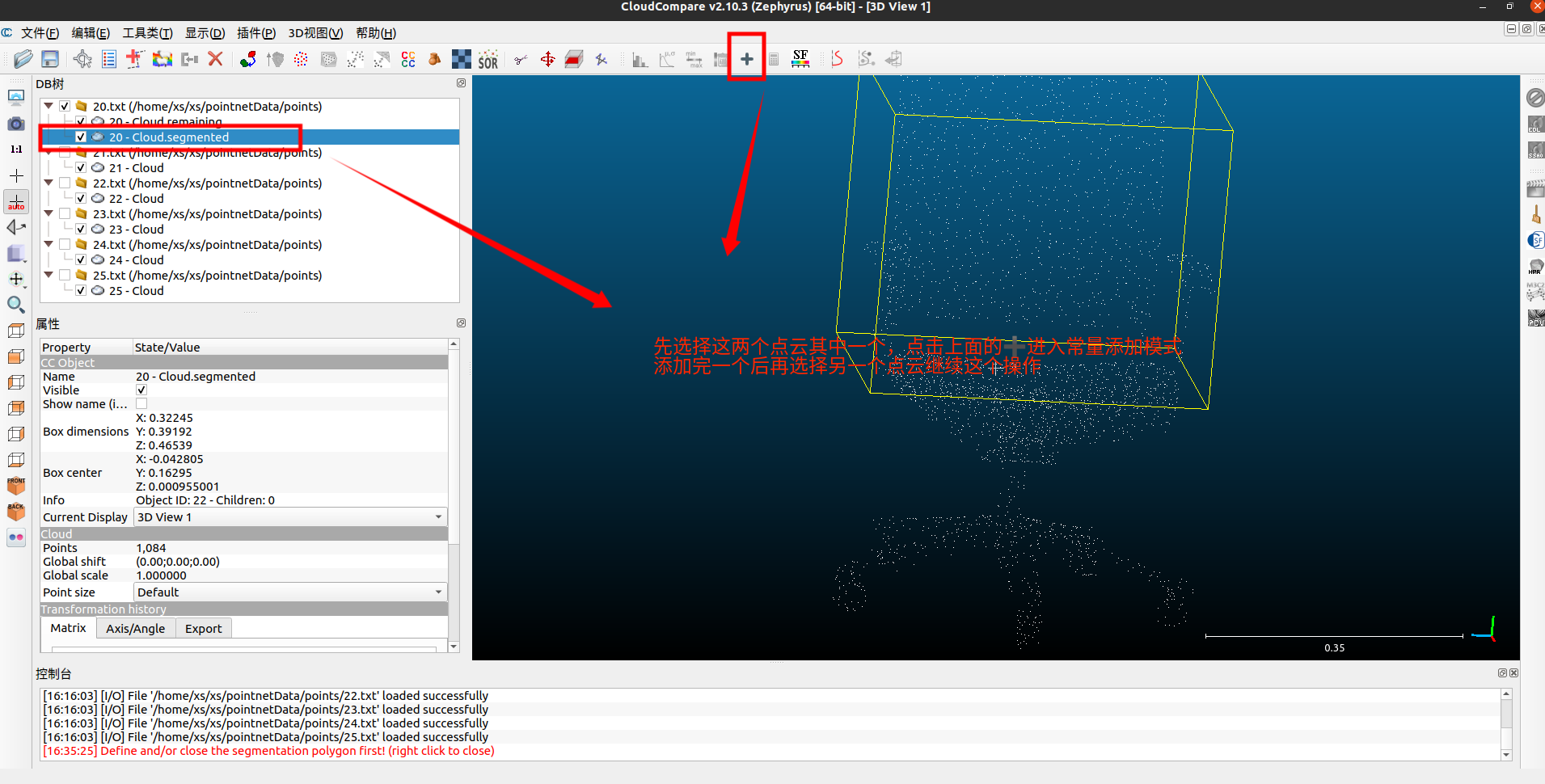
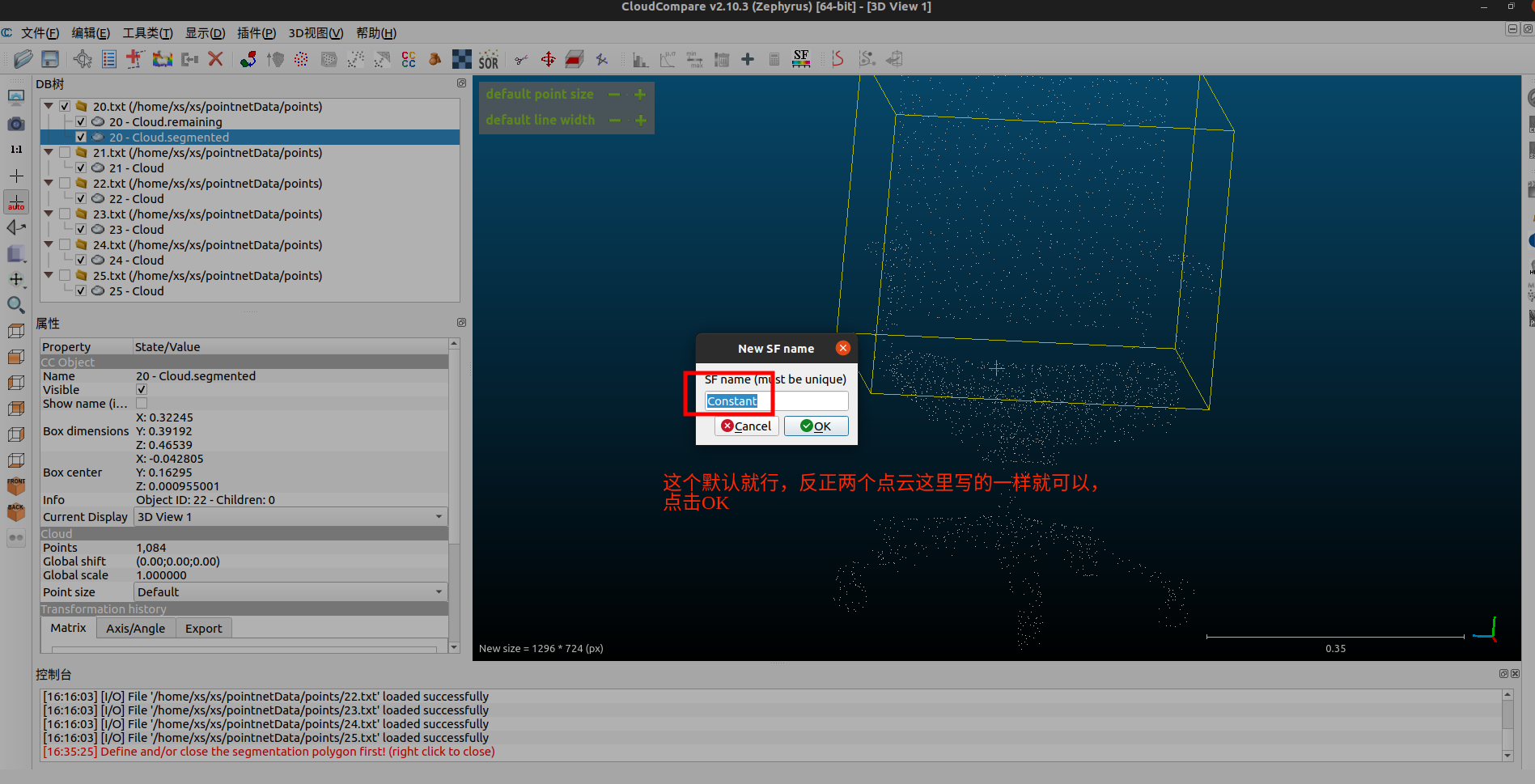
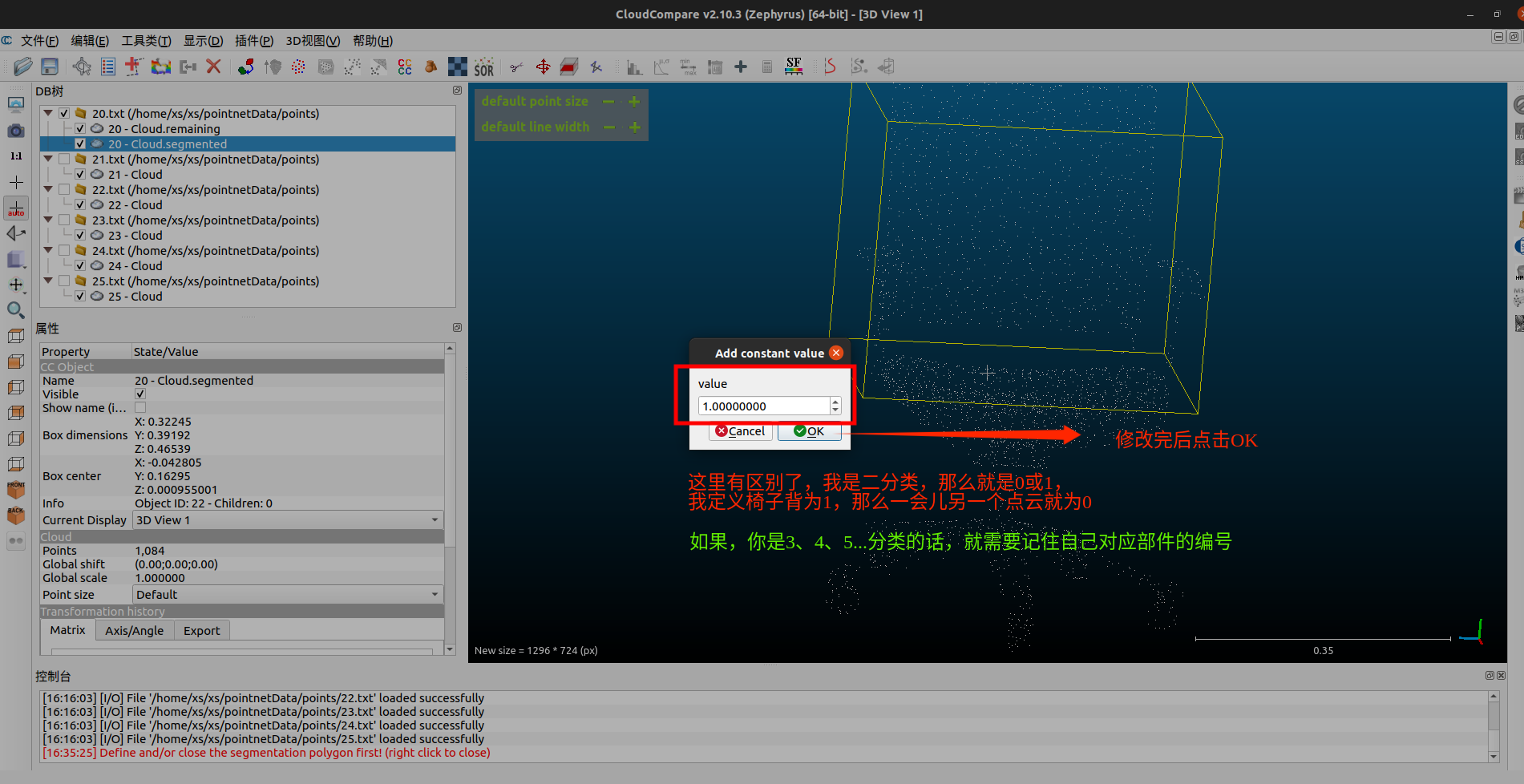
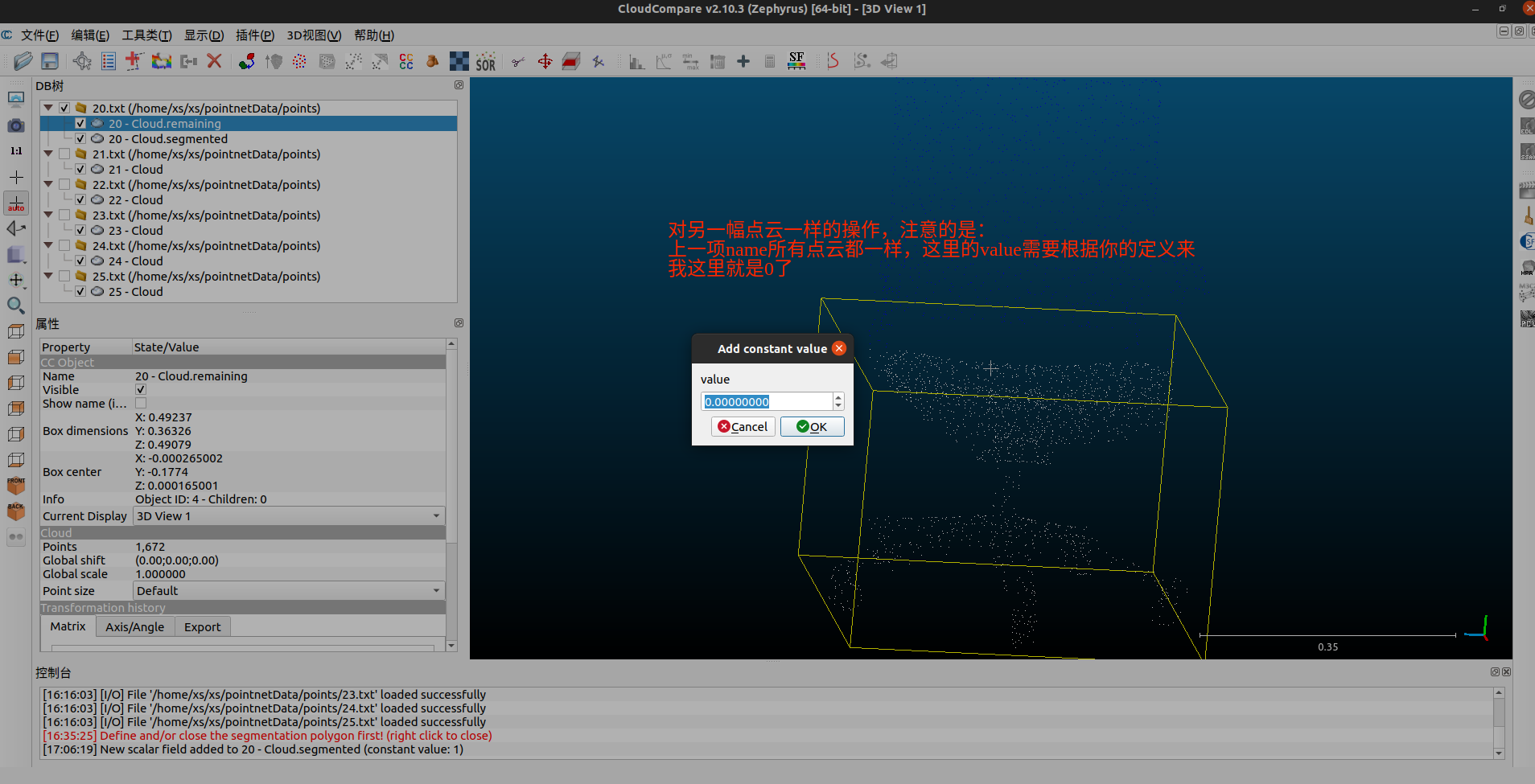
合并点云
标注完成后,我们就需要对上面我们分割的点云做合并处理。
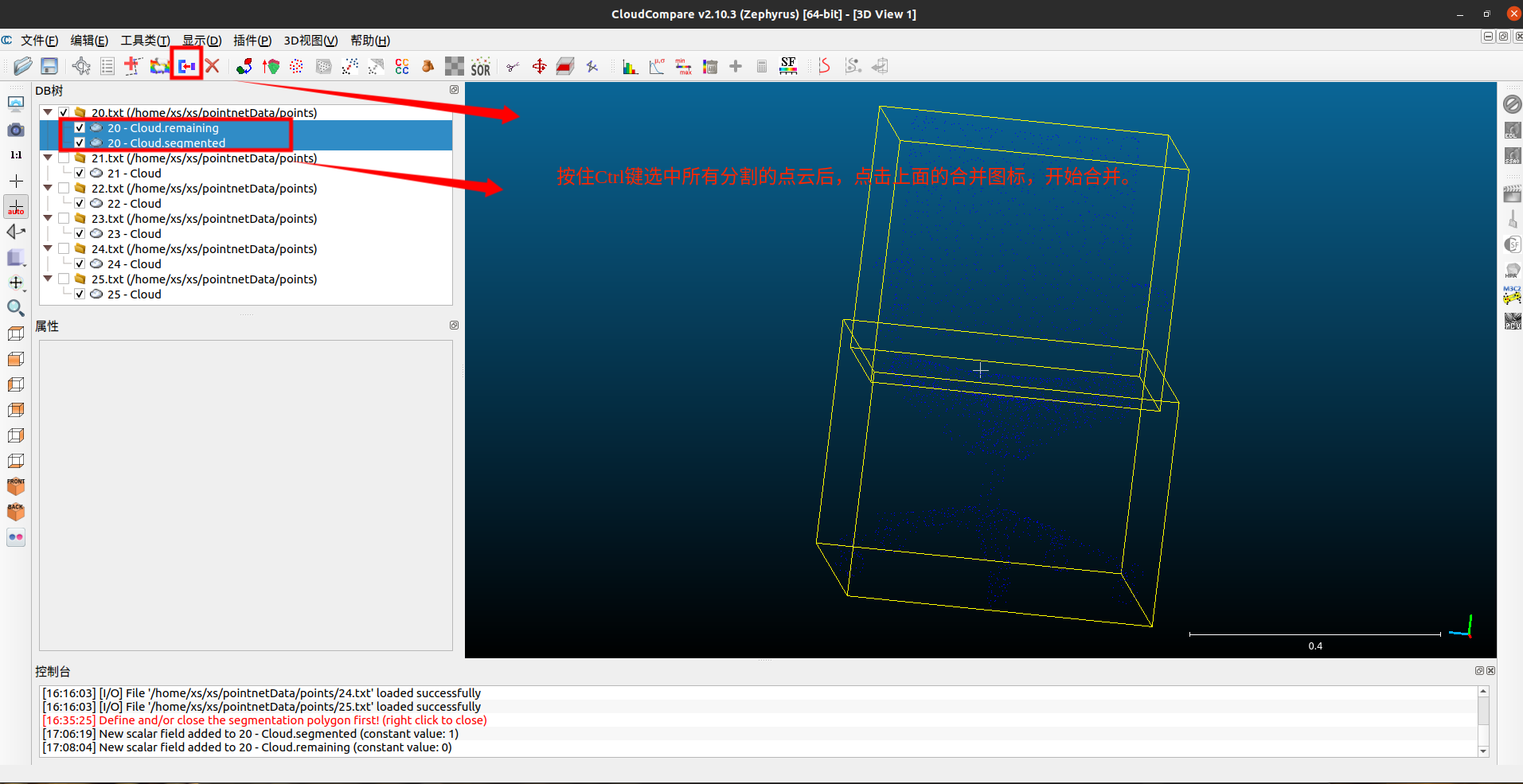 注意这个选择
注意这个选择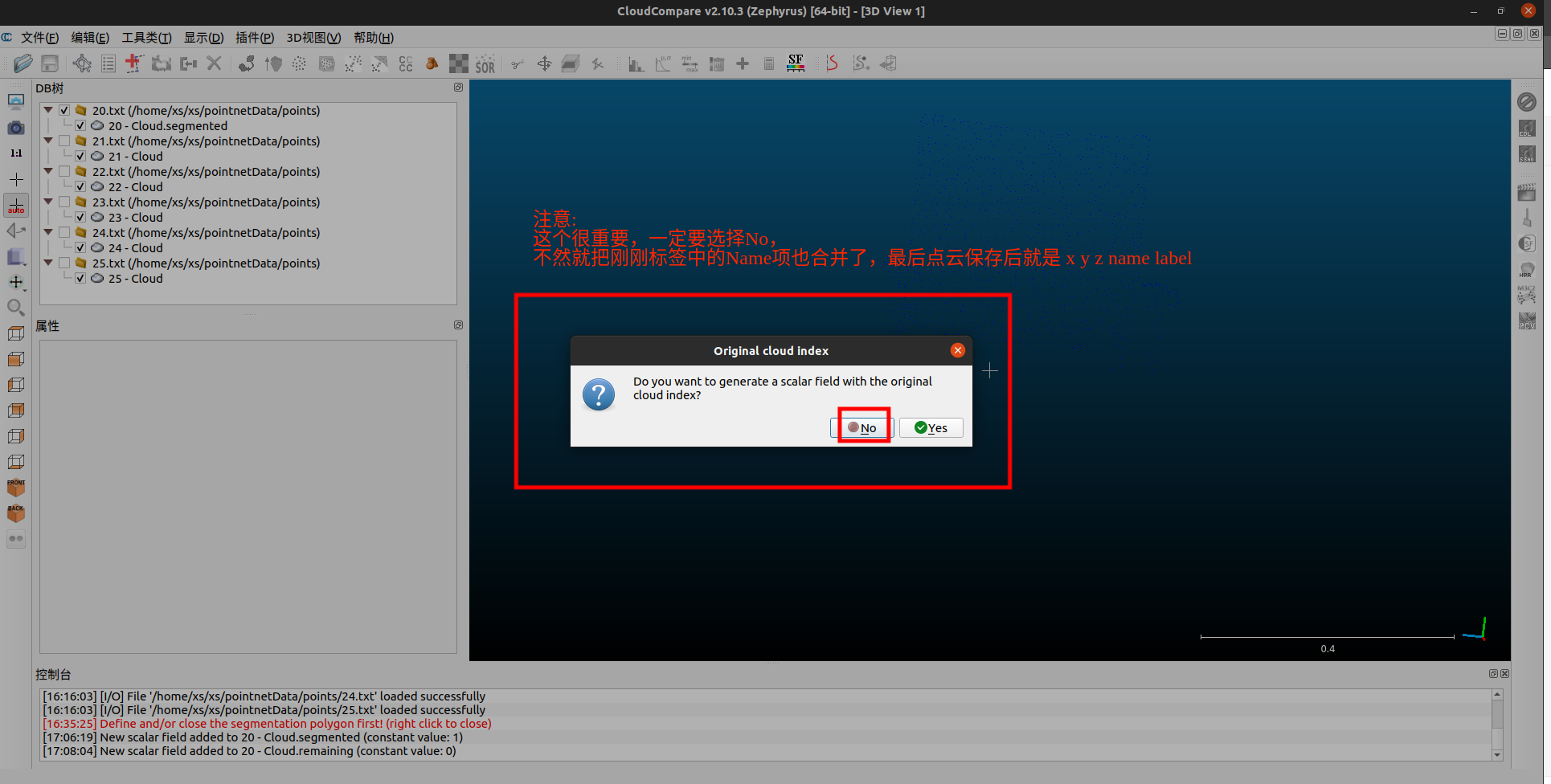
合并完成后,就可以看到下面的这个情况了(我改变了显示的尺寸)
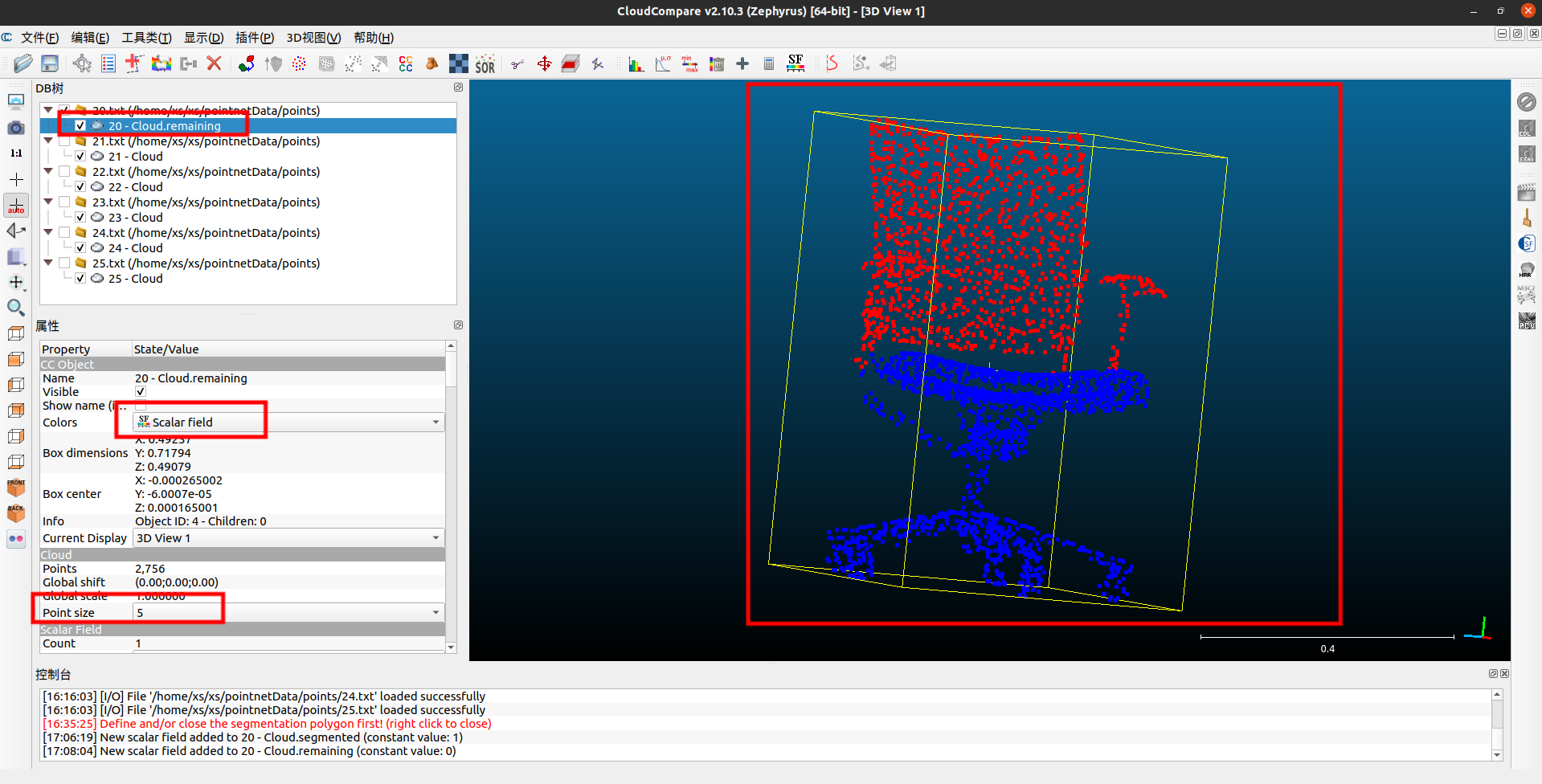
保存点云
这个点云,到此就标注完成,然后就是保存到你建立的data/points_merge下去了。
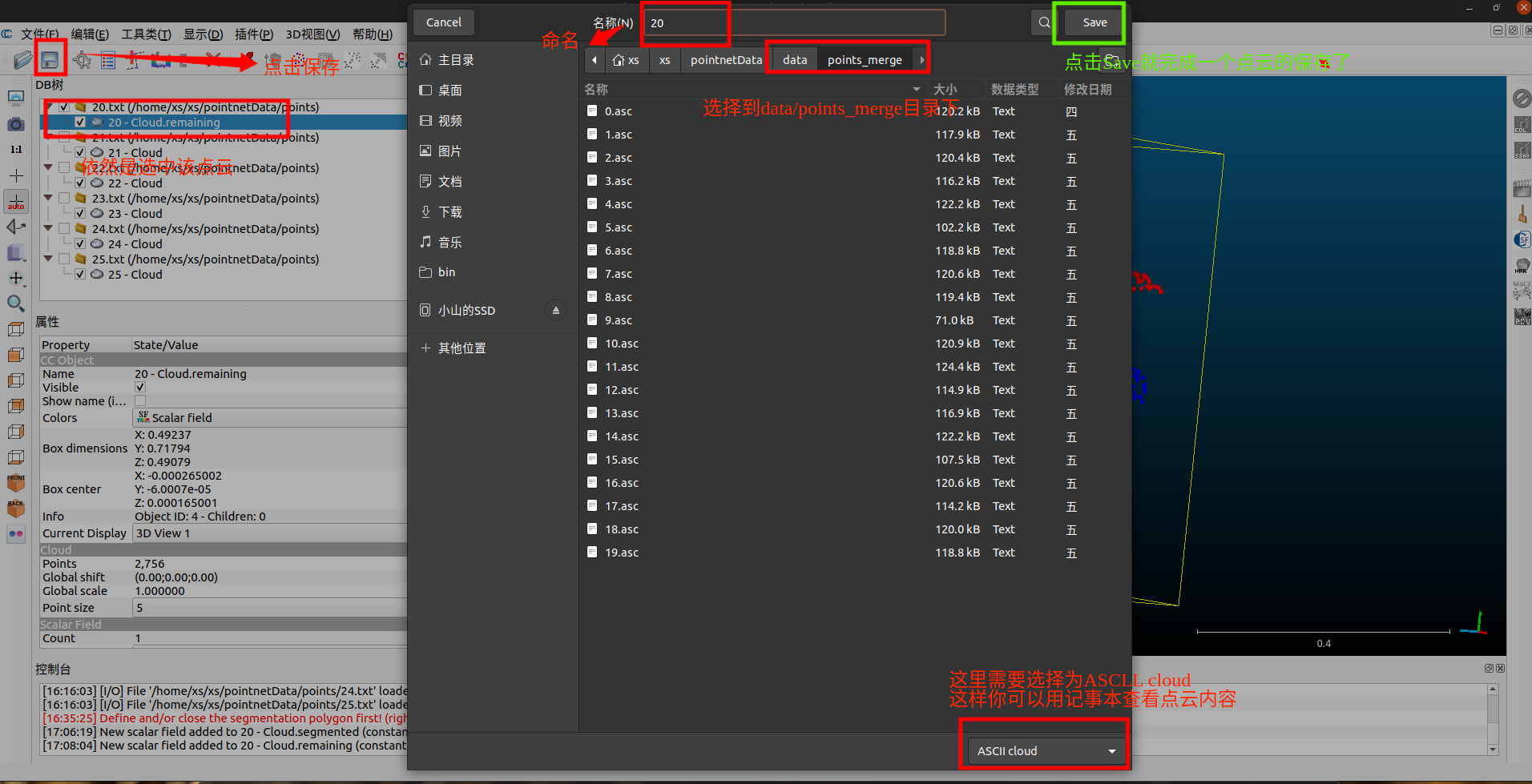
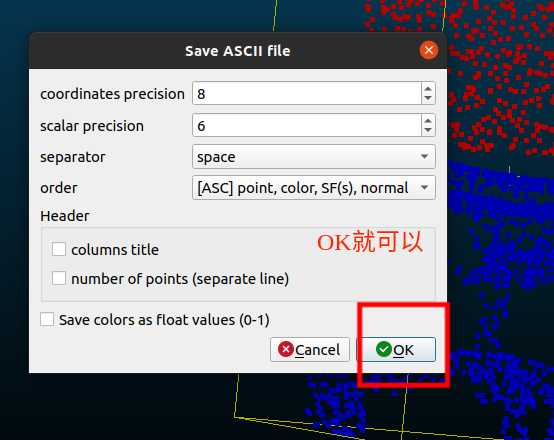
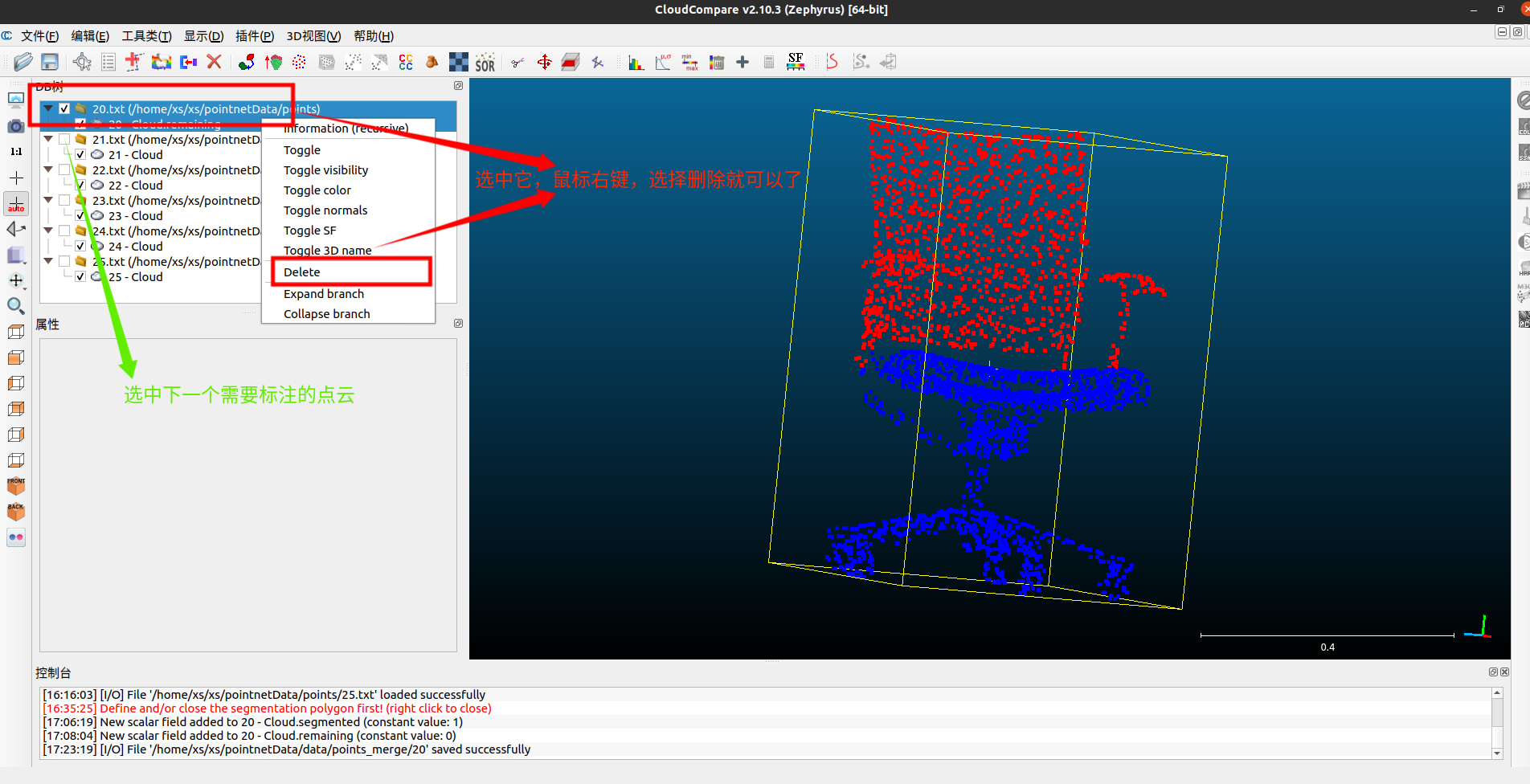
到此,就标注并保存好一组数据了,你可以选择刚刚标注完的原始点云删除掉,再选中下一个需要标注的点云开始重复上面的操作了。
3、分割数据
写一个脚本放到我们的points_merge同级目录下,方便我们对点云标签的分割。
如:
脚本内容:
python
import os
BASE_DIR = "."
POINTS_MERGE_DIR = os.path.join(BASE_DIR, "points_merge") # 原始合并文件目录
POINTS_DIR = os.path.join(BASE_DIR, "points") # 输出坐标目录
LABELS_DIR = os.path.join(BASE_DIR, "points_label") # 输出标签目录
def convert_merge_to_pts_seg():
if not os.path.exists(POINTS_MERGE_DIR):
print(f"错误:目录 {POINTS_MERGE_DIR} 不存在!")
return
# 创建输出目录
os.makedirs(POINTS_DIR, exist_ok=True)
os.makedirs(LABELS_DIR, exist_ok=True)
# 获取所有文件(忽略子目录)
files = [f for f in os.listdir(POINTS_MERGE_DIR)
if os.path.isfile(os.path.join(POINTS_MERGE_DIR, f))]
if not files:
print(f"警告:{POINTS_MERGE_DIR} 中没有文件。")
return
converted_count = 0
for file_name in files:
base_name = os.path.splitext(file_name)[0]
merge_path = os.path.join(POINTS_MERGE_DIR, file_name)
pts_path = os.path.join(POINTS_DIR, base_name + '.pts')
seg_path = os.path.join(LABELS_DIR, base_name + '.seg')
# 如果目标文件已存在,跳过(可根据需要修改为覆盖)
if os.path.exists(pts_path) and os.path.exists(seg_path):
print(f"跳过已存在: {base_name}")
converted_count += 1
continue
# 读取合并文件,每行格式: x y z label
try:
with open(merge_path, 'r') as f:
lines = f.readlines()
except Exception as e:
print(f"读取文件 {file_name} 失败: {e}")
continue
coords = []
labels = []
valid_file = True
for line_num, line in enumerate(lines, start=1):
parts = line.strip().split()
if len(parts) < 4:
continue # 忽略无效行
x, y, z, label_str = parts[0], parts[1], parts[2], parts[3]
# 强制将标签转换为整数(支持 "1" 或 "1.0" 等形式)
try:
label_int = int(float(label_str))
except ValueError:
print(f"文件 {file_name} 第 {line_num} 行标签 '{label_str}' 不是有效的数字,跳过该文件。")
valid_file = False
break
coords.append(f"{x} {y} {z}")
labels.append(str(label_int))
if not valid_file:
continue
if not coords:
print(f"文件 {file_name} 中没有有效点,跳过。")
continue
# 写入 .pts 和 .seg
with open(pts_path, 'w') as f_pts:
f_pts.write("\n".join(coords))
with open(seg_path, 'w') as f_seg:
f_seg.write("\n".join(labels))
converted_count += 1
print(f"已转换: {base_name}")
print(f"处理完成!共转换 {converted_count} 个文件。")
def main():
convert_merge_to_pts_seg()
if __name__ == "__main__":
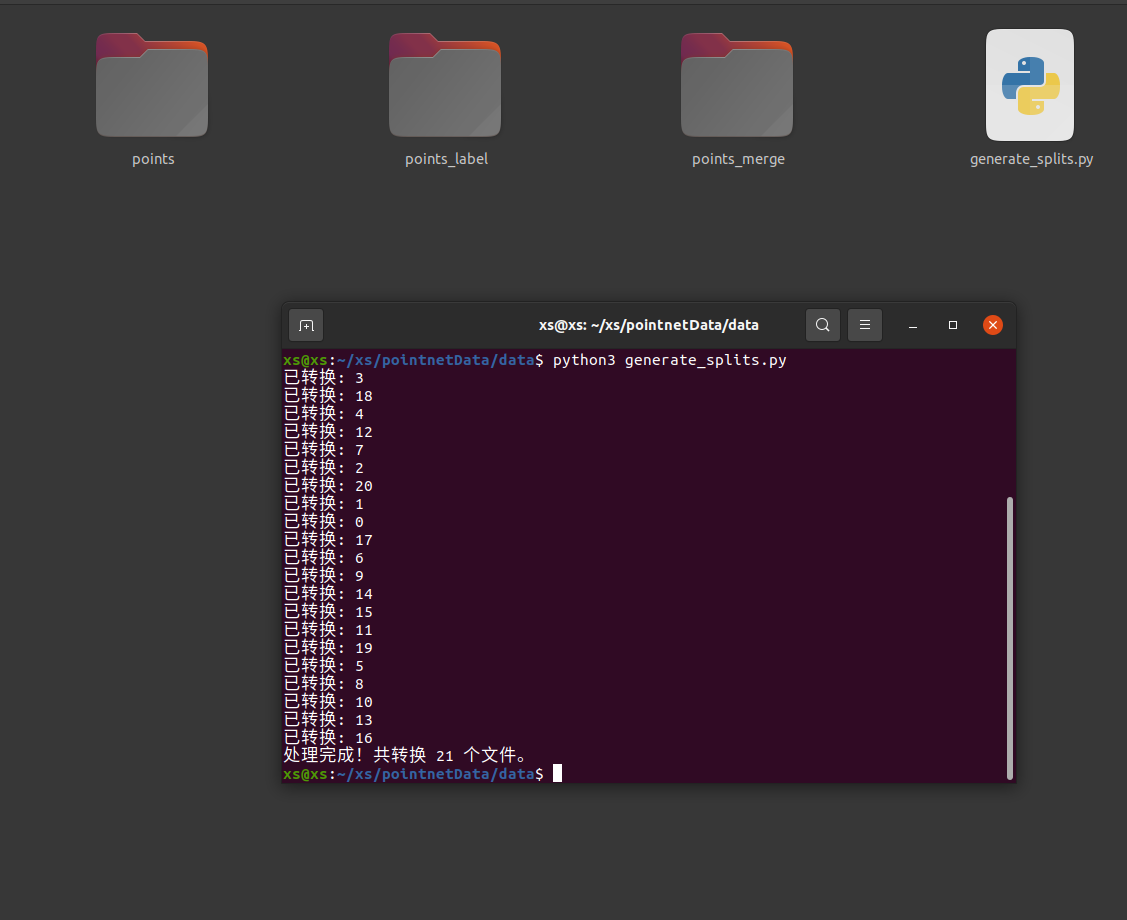
main()在目录下打开终端运行该脚本
bash
python3 generate_splits.py最后生成points和points_merge文件 并且把点位数据和标签数据分割开了
4、模型训练
完成上面的事后,我们就进入了我们自己的模型训练,首先创建我们的训练脚本train.py文件,并切换到你自己的虚拟(pointnet)环境。
我的环境名是叫pointnet:
bash
conda activate pointnet添加train.py内容如下:
python
import argparse
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
import json
from pointnet.model import PointNetDenseCls, feature_transform_regularizer
# -------------------- 自定义数据集类 --------------------
class PointCloudDataset(Dataset):
def __init__(self, root, split='train', split_ratio=0.7, random_seed=42, num_points=2500):
"""
root: 数据根目录,包含 points/ 和 points_label/ 子文件夹
split: 'train' 或 'val'
split_ratio: 训练集比例
num_points: 每个点云固定点数(随机采样/重复)
"""
self.root = root
self.num_points = num_points
self.points_dir = os.path.join(root, 'points')
self.labels_dir = os.path.join(root, 'points_label')
# 获取所有样本的 basename(不含扩展名)
self.basenames = [f.split('.')[0] for f in os.listdir(self.points_dir) if f.endswith('.pts')]
self.basenames.sort()
# 划分训练/验证集
random.seed(random_seed)
random.shuffle(self.basenames)
split_idx = int(len(self.basenames) * split_ratio)
if split == 'train':
self.basenames = self.basenames[:split_idx]
elif split == 'val':
self.basenames = self.basenames[split_idx:]
else:
raise ValueError("split must be 'train' or 'val'")
# 构建标签到连续索引的映射(基于所有样本的标签)
self.label_to_idx, self.idx_to_label = self._build_label_mapping()
self.num_classes = len(self.label_to_idx)
print(f"数据集 {split}: 共 {len(self.basenames)} 个样本,标签类别数: {self.num_classes}")
def _build_label_mapping(self):
"""扫描所有样本的标签,建立原始标签到连续0..N-1的映射"""
all_labels = set()
for name in self.basenames:
seg_path = os.path.join(self.labels_dir, name + '.seg')
with open(seg_path, 'r') as f:
for line in f:
line = line.strip()
if line:
# 处理可能的小数点格式,如 '1.000000'
try:
val = int(float(line)) # 先转float再转int,安全处理
except ValueError:
# 如果转换失败(如空行),跳过
continue
all_labels.add(val)
sorted_labels = sorted(all_labels)
label_to_idx = {l: i for i, l in enumerate(sorted_labels)}
idx_to_label = {i: l for i, l in enumerate(sorted_labels)}
return label_to_idx, idx_to_label
def __len__(self):
return len(self.basenames)
def __getitem__(self, idx):
name = self.basenames[idx]
pts_path = os.path.join(self.points_dir, name + '.pts')
seg_path = os.path.join(self.labels_dir, name + '.seg')
# 读取点云 (N, 3)
points = np.loadtxt(pts_path, dtype=np.float32)
# 读取标签:先以浮点数读取,再转为整数,兼容 '1.000000' 格式
seg_float = np.loadtxt(seg_path, dtype=np.float32) # (N,)
seg = seg_float.astype(np.int64) # 转为整数
# 确保点数一致:随机采样到固定点数
n = points.shape[0]
if n > self.num_points:
choice = np.random.choice(n, self.num_points, replace=False)
elif n < self.num_points:
choice = np.random.choice(n, self.num_points, replace=True)
else:
choice = np.arange(n)
points = points[choice, :]
seg = seg[choice]
# 归一化点云:去中心化并缩放到单位球
centroid = np.mean(points, axis=0)
points = points - centroid
m = np.max(np.sqrt(np.sum(points ** 2, axis=1)))
if m > 0:
points = points / m
# 将原始标签映射到连续索引
seg = np.array([self.label_to_idx[l] for l in seg])
# 转换为 torch tensor
points = torch.from_numpy(points).float() # (N, 3)
seg = torch.from_numpy(seg).long() # (N,)
return points, seg
# -------------------- 训练函数 --------------------
def train(args):
# 设置随机种子
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
# 设备选择
device = torch.device("cuda" if args.cuda and torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 数据集
train_dataset = PointCloudDataset(args.data_root, split='train', split_ratio=args.train_ratio,
random_seed=args.seed, num_points=args.num_points)
val_dataset = PointCloudDataset(args.data_root, split='val', split_ratio=args.train_ratio,
random_seed=args.seed, num_points=args.num_points)
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, drop_last=False)
num_classes = train_dataset.num_classes
print(f"类别数: {num_classes}")
# 模型
model = PointNetDenseCls(k=num_classes, feature_transform=args.feature_transform).to(device)
if args.model_path:
state_dict = torch.load(args.model_path, map_location=device)
model.load_state_dict(state_dict)
print(f"已加载预训练模型: {args.model_path}")
# 优化器
optimizer = optim.Adam(model.parameters(), lr=args.lr, betas=(0.9, 0.999))
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=args.lr_step, gamma=args.lr_gamma)
# 损失函数
criterion = nn.NLLLoss()
best_acc = 0.0
os.makedirs(args.out_dir, exist_ok=True)
for epoch in range(args.epochs):
# 训练
model.train()
train_loss = 0.0
train_correct = 0
total_points = 0
for points, seg in tqdm(train_loader, desc=f'Epoch {epoch} Train'):
points = points.transpose(2, 1).to(device) # (B, 3, N)
seg = seg.to(device) # (B, N)
optimizer.zero_grad()
pred, trans, trans_feat = model(points) # pred: (B, N, num_classes)
pred = pred.view(-1, num_classes) # (B*N, num_classes)
seg = seg.view(-1) # (B*N)
loss = criterion(pred, seg)
if args.feature_transform:
loss += feature_transform_regularizer(trans_feat) * 0.001
loss.backward()
optimizer.step()
pred_choice = pred.max(1)[1]
correct = pred_choice.eq(seg).sum().item()
train_correct += correct
total_points += seg.size(0)
train_loss += loss.item() * seg.size(0)
train_acc = train_correct / total_points
train_loss = train_loss / total_points
print(f'Epoch {epoch:2d} | Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.4f}')
# 验证
model.eval()
val_loss = 0.0
val_correct = 0
total_points_val = 0
with torch.no_grad():
for points, seg in val_loader:
points = points.transpose(2, 1).to(device)
seg = seg.to(device)
pred, _, _ = model(points)
pred = pred.view(-1, num_classes)
seg = seg.view(-1)
loss = criterion(pred, seg)
pred_choice = pred.max(1)[1]
correct = pred_choice.eq(seg).sum().item()
val_correct += correct
total_points_val += seg.size(0)
val_loss += loss.item() * seg.size(0)
val_acc = val_correct / total_points_val
val_loss = val_loss / total_points_val
print(f'Epoch {epoch:2d} | Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}')
# 调整学习率
scheduler.step()
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), os.path.join(args.out_dir, 'best_model.pth'))
print(f'保存最佳模型,验证准确率: {best_acc:.4f}')
# 同时保存标签映射,供预测时使用
mapping = {
'label_to_idx': train_dataset.label_to_idx,
'idx_to_label': train_dataset.idx_to_label,
'num_classes': num_classes
}
with open(os.path.join(args.out_dir, 'label_mapping.json'), 'w') as f:
json.dump(mapping, f, indent=2)
print(f"训练完成,最佳验证准确率: {best_acc:.4f}")
# -------------------- 主函数 --------------------
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_root', type=str, required=True, help='数据根目录(包含points/和points_label/)')
parser.add_argument('--out_dir', type=str, default='./output', help='模型和日志输出目录')
parser.add_argument('--batch_size', type=int, default=4, help='batch size')
parser.add_argument('--epochs', type=int, default=200, help='训练轮数')
parser.add_argument('--num_points', type=int, default=2500, help='每个点云采样点数')
parser.add_argument('--train_ratio', type=float, default=0.7, help='训练集比例')
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
parser.add_argument('--lr_step', type=int, default=20, help='学习率衰减步长')
parser.add_argument('--lr_gamma', type=float, default=0.5, help='学习率衰减因子')
parser.add_argument('--workers', type=int, default=0, help='数据加载线程数(小数据集设为0)')
parser.add_argument('--seed', type=int, default=42, help='随机种子')
parser.add_argument('--feature_transform', action='store_true', help='启用特征变换正则化')
parser.add_argument('--model_path', type=str, default='', help='预训练模型路径(可选)')
parser.add_argument('--cuda', action='store_true', help='使用GPU进行训练(如果可用)')
args = parser.parse_args()
train(args)在pointnet的环境下运行代码:
bash
python3 train.py --data_root '你的data目录路径' --cuda最后,得到模型文件位于 output下。
5、使用模型
训练完成后,可以创建使用代码predict.py
python
import argparse
import os
import json
import numpy as np
import torch
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from pointnet.model import PointNetDenseCls
def normalize_point_cloud(points):
"""去中心化并缩放到单位球"""
centroid = np.mean(points, axis=0)
points = points - centroid
m = np.max(np.sqrt(np.sum(points ** 2, axis=1)))
if m > 0:
points = points / m
return points
def load_point_cloud(file_path):
"""从文件加载点云,支持 .pts 或 .txt 格式(每行 x y z)"""
return np.loadtxt(file_path, dtype=np.float32)
def plot_pointcloud_matplotlib(points, colors, title="Segmentation", save_path=None, point_size=10):
"""
使用 matplotlib 绘制点云,风格:黑色背景、大点、无坐标轴。
points: (N, 3) 点云坐标
colors: (N, 3) RGB 颜色值(0-1 范围)
point_size: 点的大小(像素)
"""
fig = plt.figure(figsize=(10, 8), facecolor='black')
ax = fig.add_subplot(111, projection='3d', facecolor='black')
ax.scatter(points[:, 0], points[:, 1], points[:, 2],
c=colors, s=point_size, alpha=1.0, edgecolors='none')
# 隐藏坐标轴和背景网格
ax.set_axis_off()
ax.grid(False)
# 设置轴范围,使物体居中
max_range = np.max(np.abs(points)) * 1.1
ax.set_xlim(-max_range, max_range)
ax.set_ylim(-max_range, max_range)
ax.set_zlim(-max_range, max_range)
# 添加标题(白色字体)
ax.text2D(0.5, 0.95, title, transform=ax.transAxes, color='white', fontsize=16, ha='center')
plt.tight_layout()
if save_path:
plt.savefig(save_path, facecolor='black', bbox_inches='tight', dpi=150)
print(f"图像已保存到 {save_path}")
plt.show()
def predict(args):
device = torch.device("cuda" if args.cuda and torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载标签映射
with open(args.mapping, 'r') as f:
mapping = json.load(f)
idx_to_label = {int(k): v for k, v in mapping['idx_to_label'].items()}
num_classes = mapping['num_classes']
print(f"标签映射: {idx_to_label}")
# 为每个类别分配鲜艳颜色(0-1 浮点数)
# 这里定义一组高饱和颜色,按类别索引分配
color_list = [
[1,0,0], # 红
[0,1,0], # 绿
[0,0,1], # 蓝
[1,1,0], # 黄
[1,0,1], # 紫
[0,1,1], # 青
[1,0.5,0], # 橙
[0.5,0,1], # 紫蓝
[0,1,0.5], # 青绿
[1,0,0.5], # 粉红
]
# 如果类别数超过颜色列表长度,循环重复
while len(color_list) < num_classes:
color_list.extend(color_list) # 简单重复
# 加载模型
model = PointNetDenseCls(k=num_classes, feature_transform=False)
state_dict = torch.load(args.model, map_location=device)
model.load_state_dict(state_dict)
model.to(device)
model.eval()
# 加载点云
points = load_point_cloud(args.input)
print(f"点云加载完成,共 {points.shape[0]} 个点")
# 预处理:归一化 + 采样到固定点数
points_norm = normalize_point_cloud(points.copy())
n = points_norm.shape[0]
num_points = args.num_points
if n > num_points:
choice = np.random.choice(n, num_points, replace=False)
elif n < num_points:
choice = np.random.choice(n, num_points, replace=True)
else:
choice = np.arange(n)
points_sampled = points_norm[choice] # (num_points, 3)
# 转换为 tensor 并添加 batch 维度
input_tensor = torch.from_numpy(points_sampled).float().unsqueeze(0) # (1, num_points, 3)
input_tensor = input_tensor.transpose(2, 1).to(device) # (1, 3, num_points)
# 推理
with torch.no_grad():
pred, _, _ = model(input_tensor)
pred = pred.squeeze(0) # (num_points, num_classes)
pred_choice = pred.max(1)[1].cpu().numpy() # (num_points,)
# 如果需要映射回原始标签(但颜色仍按连续索引分配,不影响显示)
if args.map_back:
pred_labels = np.array([idx_to_label[i] for i in pred_choice])
print("预测标签(原始值):", np.unique(pred_labels))
else:
pred_labels = pred_choice
print("预测标签(索引):", np.unique(pred_labels))
# 生成颜色数组 (N, 3),按预测的类别索引分配颜色
pred_colors = np.array([color_list[idx] for idx in pred_choice])
# 可视化
plot_pointcloud_matplotlib(points_sampled, pred_colors,
title=f"Prediction: {os.path.basename(args.input)}",
save_path=args.output_img,
point_size=args.point_size)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, required=True, help='训练好的模型文件 (.pth)')
parser.add_argument('--mapping', type=str, required=True, help='标签映射文件 (label_mapping.json)')
parser.add_argument('--input', type=str, required=True, help='输入点云文件 (.pts 或 .txt)')
parser.add_argument('--output_img', type=str, default='', help='输出图像路径(可选)')
parser.add_argument('--num_points', type=int, default=2500, help='模型输入的点数,必须与训练一致')
parser.add_argument('--point_size', type=int, default=10, help='点的大小(像素)')
parser.add_argument('--map_back', action='store_true', help='将预测索引映射回原始标签值(仅打印,不影响颜色)')
parser.add_argument('--cuda', action='store_true', help='使用GPU进行推理')
args = parser.parse_args()
predict(args)运行使用模型的代码
python
python3 predict.py --model '你的pth文件位置' --mapping '你的json文件位置' --input '你的需要分割的点云位置支持pts和txt点云' --cuda6、实现效果:
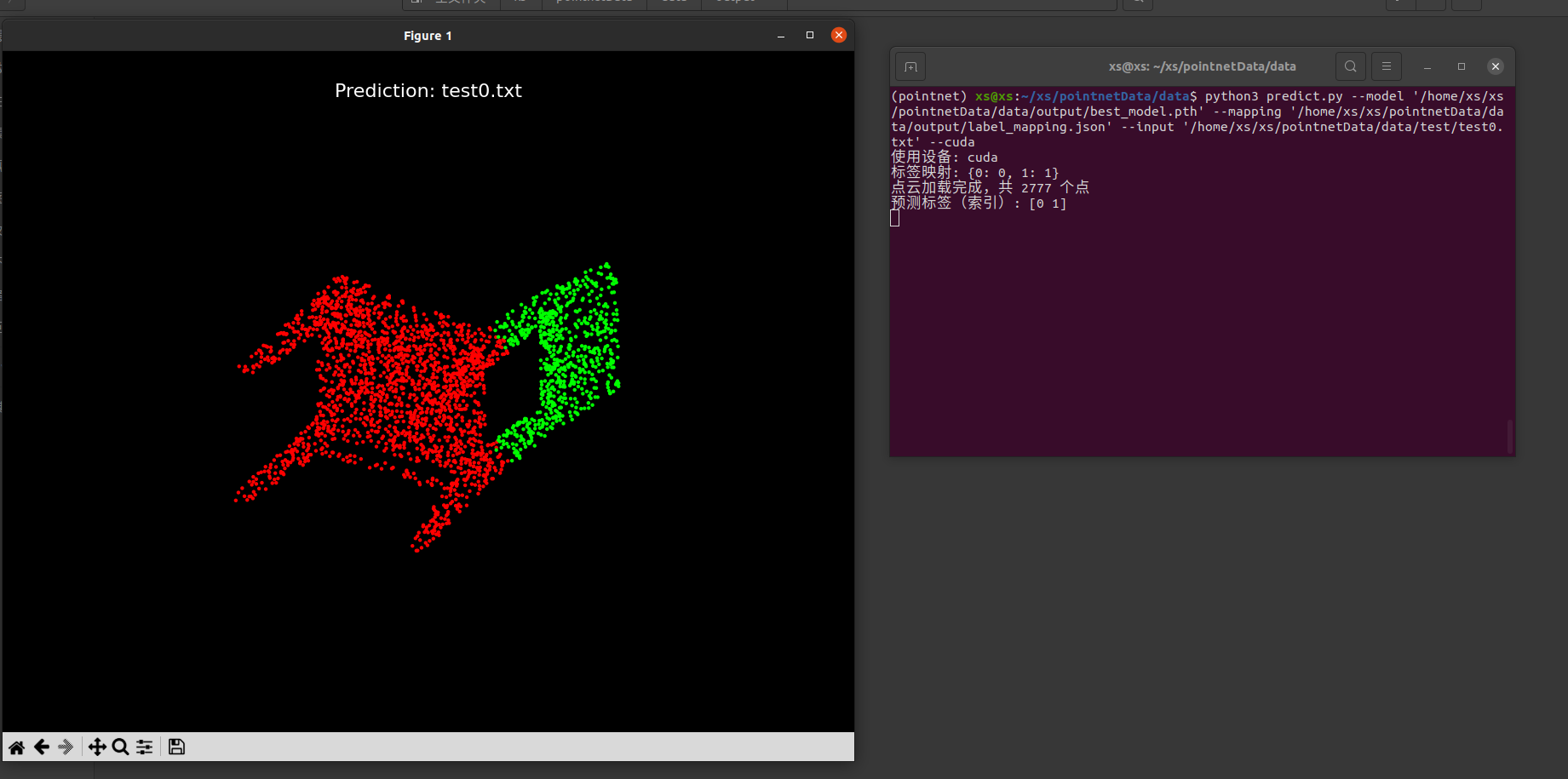
结语:
历经无数个深夜的调试,终于把PointNet从配置到训练完整跑通了。回望来路,最折腾的不是网络结构本身,而是那些藏在水面下的环境依赖------CUDA版本、PCL兼容性、Python库的相爱相杀......每一次报错都是一次"劝退"警告,但咬牙坚持下来,才发现官方源码其实是最诚实的老师,只是需要我们多几分耐心去读懂它的脾气。当第一个epoch的loss开始下降,当可视化窗口中点云被准确着色分类,那一刻的喜悦足以抵消此前所有抓狂。
PointNet作为点云深度学习的奠基之作,其设计之简洁、思想之深刻,确实令人叹服。它证明了无需复杂结构,只要抓住点云的置换不变性,就能直击三维理解的核心。如今跑通它,不仅是为后续研究铺路,更是向经典致敬。
接下来,我计划把它部署到自己的机器人上,让算法真正落地,也期待在点云的世界里探索更多可能。开发之路漫漫,bug与惊喜常伴,愿我们都能保持这份死磕到底的劲头,在一次次迭代中逼近自己的理想状态。共勉!