注:本文章为华为HCIA-Datacom学习指南的整理,作者为王达老师,感兴趣的朋友可以去看看
2.1 IPv4数据包格式
来自IP的上层协议的报文均需要经过IP的封装,形成IP数据包(也称为"IP分组",或者统称"IP报文")。本章仅介绍IPv4数据包。
经过IPv4封装的上层协议报文所形成的IPv4数据包,由IPv4数据包头部和数据两部分组成,如图2 - 1所示。数据包头部中包括固定为20个字节的一些必选字段以及可选且长度可变的"选项""填充"字段,但可变长字段的总长度不超过40个字节,即总的IPv4数据包头部长度最小为20个字节,最长为60个字节。各字段的说明见表2 - 1。
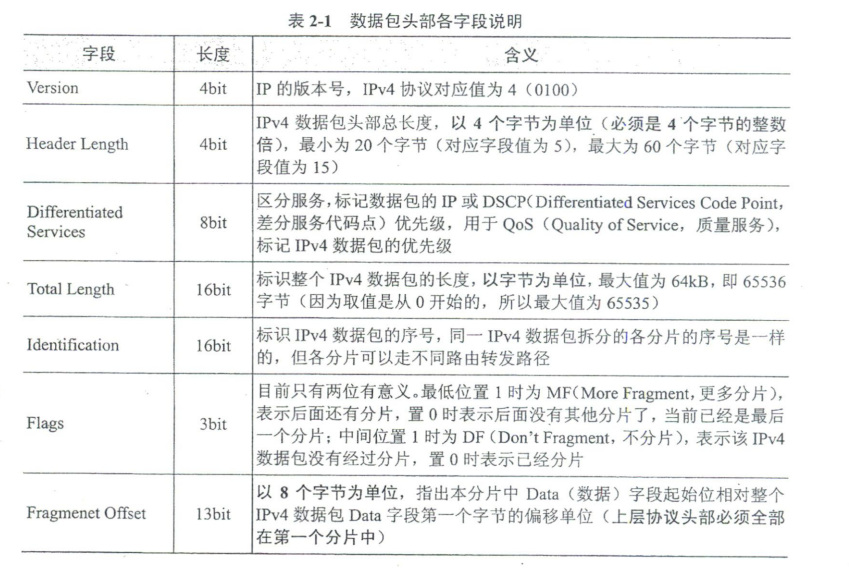
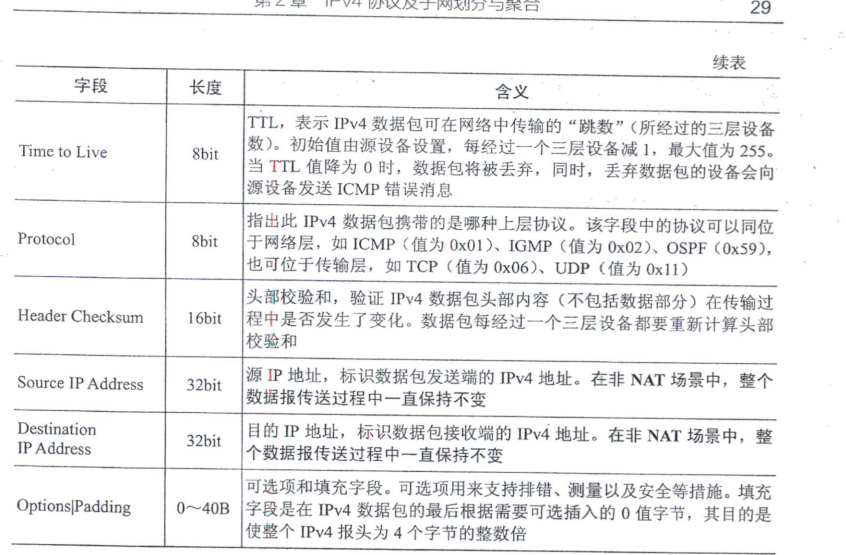
IPv4数据包头部字段比较多,特别要注意IPv4数据包头部长度(Header Length)、整个IPv4数据包长度(Total Length)、分片偏移(Fragment Offset)这几个字段中的长度单位是不一样的。另外,要着重理解区分服务(Differentiated Services)、标志(Flags)、TTL(Time to Live)这几个字段的用途,记住源IP地址(Source IP Address)和目的IP地址(Destination IP Address)两字段的值在非NAT场景数据传输过程中一直保持不变,因为它们本身就是代表不同网络(一个IP网段代表一个计算机网络)的。而数据帧的MAC地址(包括源MAC地址和目的MAC地址),每经过一个网络都需要重新封装,也就是每经过一个网络时,链路上传输的数据帧的MAC地址都是不一样的,但在同一网络内部传输时,帧中的MAC地址是不变的。
2.2 IPv4数据包分片与重组
不同链路有不同的MTU(Maximum Transmission Unit,最大传输单元),这些链路对来自上层协议的数据包的最大限制也不同,超过限制后数据包就会被丢弃,因为数据链路层没有分片功能。如以太网、PPP链路的MTU值均为1500个字节,X.25链路的MTU值只有576个字节。
当一台三层设备发送或者转发的IPv4报文长度超过了出接口所使用链路的MTU限制时,发送端就要对该IPv4数据包进行拆分,分成一个个小的数据包分片,然后才能向数据链路层进行下发。各分片到了最终的目的端后重新组合在一起,还原为大的IPv4数据包,再向上层传输。中间设备不会进行数据包分片重组,因为分片时仅对数
据包的数据部分进行拆分,IPv4数据包头部是不会拆分的,它们都具有相同的目的IP地址。
IPv4数据包头部格式中的Flags和Fragment Offset两字段就是用于IPv4数据包分片和重组功能的,同时还会利用Identification(标识)字段。
2.2.1 IPv4数据包分片
IPv4数据包分片可以在主机、三层交换机或者路由器上发生,因为IPv4数据包在传输过程中,可能要经过多段MTU值不一样的链路,在一些更小的MTU链路上还要对已经经过了分片的IPv4数据包再次进行分片。
如图2-2所示,主机A发往主机B的1500个字节的IPv4数据包,中间需要经过两次分片:首先要在路由器1上进行第一次分片,因为路由器1连接路由器2的链路的MTU值小于1500个字节;然后在路由器2向路由器3转发时,又要对第一个IPv4数据包分片进行第二次分片,因为路由器2连接路由器3的链路的MTU小于1496个字节。
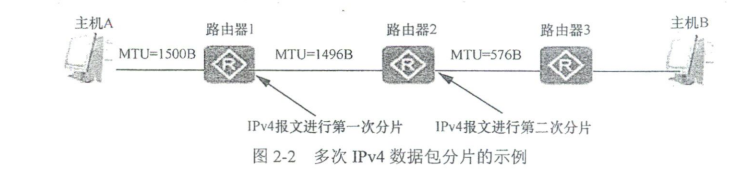
由同一个IPv4数据包或数据包分片拆分的每个IPv4数据包分片都要重新进行IPv4协议封装,加装与原始IPv4数据包相同(不同分片的部分字段值不一样)的数据包头部,且它们均有相同的Identification字段值(即有相同的数据包序列号)。但每个分片可以单独路由,且可走不同的路由路径。
虽然由同一个IPv4数据包拆分的分片的头部字段值是相同的,但不同分片中的Flags字段和Fragment Offset字段值不相同,也不是固定的,需要根据以下情形做适当的调整。每个分片Data字段长度必须是8字节的整数倍,且原IPv4数据包的上层协议头必须全部包括在第一分片的Data字段中。
① 除最后一个分片,其他分片的Flags字段的最低位置1(表示后面还有分片),中间位置0(表示数据包已分片),即Flags字段值为001;
② 最后一个分片的Flags字段的最低位置0(表示这是最后一个分片,后面没有分片了),中间位置0,即Flags字段值为000。
Fragment Offset字段以8个字节为单位,第一个分片的值为0,第二个分片的分片偏移值表示第二个分片中Data字段的第一个字节相比原IPv4数据包或数据包分片中Data字段第一个字节的偏移值(要除以8),以此类推。假设一个4000个字节数据的IPv4数据包被分成3个分片,3个分片的Data字段的字节范围分别为0~1399B,1400~2799B,2800~3999B,则这3个分片的分片偏移值分别为0、1400/8=175、2800/8=350。
【说明】IPv4数据包分片后即使只丢失一个分片数据也要重传整个数据包,因为IPv4协议本身没有超时重传的机制,没有办法只重传数据包中的一个数据包分片。
2.2.2 IPv4数据包分片重组
IPv4数据包分片重组仅在目的端进行,重组时选择分片的依据就是各IPv4数据包分片中的Identification字段值,相同的即重组在一起,因为由同一个IPv4数据包拆分的各分片的Identification字段值是相同的。但又不是直接把具有相同Identification字段值的各分片随便组合起来,还需进行如下处理。
① 根据各IPv4数据包分片的Fragment Offset字段值大小,按由小到大的顺序进行排列(第一个分片的Fragment Offset字段值为0,最小)。
② 除第一个分片外,其余各分片均去掉IPv4数据包包头部,然后把各分片的Data字段部分按照前面的排列顺序拼接起来。
③ 修改第一个分片IPv4数据包包头部信息,Flags字段的最低两位分别设为1(表示数据包没有分片)、0(表示后面没有分片),Fragment Offset字段值设为0。
2.3 IPv4地址
IPv4地址是用来标识网络设备IP地址的,也表示设备所连接的IP网络。源IPv4地址和目的IPv4地址分别用于标识IPv4数据包的发送方和接收方。根据IPv4数据包中的这两个IPv4地址可以判断目的端是否与源端在同一IP网段。如果不在同一IP网段,则需要采用路由机制来进行跨网段转发,否则可以直接在局域网内部依据二层交换方式转发。
2.3.1 IPv4地址基本格式
IPv4地址在计算机内部是以二进制形式表示的,每个地址都有32位(4个字节),由数字0或1构成。在IPv4地址的32位二进制数字中,每连续8位(1个字节)为一段(假设分别用W、X、Y、Z表示,如图2-3所示)。在计算机内部,这4段之间并没有用来分隔各段的一个小圆点,只是我们为了方便分辨,在每个字节间用一个小圆点分隔。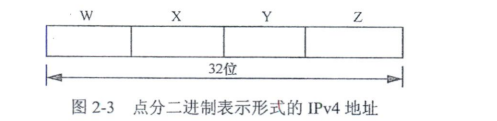
32位二进制IPv4地址被分成了两部分,一部分用来表示此IPv4地址所属于的网段(一个有类网络或子网),被称为"网络ID"(Network ID);另一部分用来表示具体主机或节点的IPv4地址,被称为"主机ID"(Host ID),如图2 - 4所示。
仅凭借IPv4地址,不能反映任何有关主机位置的网络信息,只能通过Network ID判断出主机属于哪个网络。同理,对于IPv4地址中Network ID相同的设备,无论实际所处的物理位置如何,它们都是处在同一个网络中。当然,如果多个IP段相同的网络被其他网络分隔,这时即使IP地址在同一IP网段的主机也是不能直接通信的,这属于重叠网络情形,可以用ARP代理或者NAT(Network Address Translation,网络地址转换)方案来实现互联。
由于整个IPv4地址有32位,无论是书写,还是记忆都不方便,于是我们在日常的IPv4地址使用中就把这4段二进制数转换成对应的十进制数,同样在每个字节间用小圆点分隔。这样IPv4地址中的每段最多只需用3个十进制数(8位二进制数所能表示最大十进制数为255=2⁸ - 1)表示,这样就简单、明了了许多。
2.3.2 子网掩码、网络地址和广播地址
通过一个IPv4地址,我们可以同时定义该主机所在的网络标识及自身的标识,具体网络ID和主机ID各占多少位是由对应网络的子网掩码决定的。
子网掩码用于确定一个IPv4地址属于哪个网络。子网掩码与IPv4地址一样,也是32位二进制数,是将与IPv4地址对应的Network ID部分所有比特位置1,与IPv4地址对应的Host ID部分所有比特位置0得到的。反过来,也就是在子网掩码中置1部分所对应的IPv4地址比特位是Network ID,子网掩码中置0部分对应的IPv4地址比特位是Host ID。这样一来,一个IPv4地址,如果知道其对应的子网掩码,就知道其32位二进制数码中哪些位属于Network ID,哪些位属于Host ID。但子网掩码中的1必须从最高位起连续,且不能中间有0。
如一个子网掩码为255.255.255.0,则该网络的IPv4地址中高3个字节(共24位)属于Network ID,只有最后一个字节(8位)属于Host ID,因为高3个字节的十进制数为255,转换为二进制后即每位均为1。
单个IPv4地址无法确定其所属网络,需要与其子网掩码共同决定,此时可以直接以二进制或十进制各自写出IPv4地址和子网掩码,但通常是采用十进制方法表示。子网掩码通常是采用前缀表示方式,即在IPv4地址后加上"/",然后带上子网掩码中连续1的位数,即该IPv4地址中Network ID部分的位数,也就是通常所说的"子网掩码前缀长度"。如192.168.1.0/25中的"25"就代表子网掩码中最高的25位为1,由此我们可以直接算出它的十进制子网掩码值为255.255.255.128。
另外,每一个网络有两个特殊的IPv4地址:一个是代表对应网络本身的网络地址,对应网络中第一个,也是最小的IPv4地址,此时Network ID部分的值保持不变,Host ID部分所有比特位为0;另一个是代表对应网络的地址范围,是向对应网络进行广播通信的IPv4地址,即广播地址,对应网络中最后一个,也是最大的IPv4地址,此时Network ID部分的值保持不变,Host ID部分所有比特位为1。网络地址和广播地址均不能分配给主机使用。
如在一个C类192.168.1.0/24网络中,其网络地址是192.168.1.0/24,广播地址是192.168.1.255/24。
2.3.3 4种主要的进制及相互转换方法
计算机网络中的数据可以采用二进制、八进制、十进制或十六进制,如前面介绍的IPv4地址可以是二进制表示形式,但更常采用十进制,这就需要把二进制的IPv4地址转换成十进制形式。本书后面将要介绍的IPv6地址通常是以十六进制表示,这就涉及二进制与十六进制之间的转换。下面先介绍常用的4种进制,然后再介绍常用的二进制、十进制和十六进制之间的转换方法。
- 4种主要的进制
(1)二进制
二进制是计算机运算时所采用的数制,基数是2,也就是说它只有两个数码,即0和1。在计算机程序中运行的都是二进制数码,我们称之为机器码。计算机或网络设备只能识别机器码,所以本书后面介绍的编程语言中,高级编程语言(如C++、Python和Java等)生成的源码并不是机器码,就需要经过汇编,最终转换成机器码。
在给定的一个数的表示形式中,如果除0和1外还有其他数(例如1061),那它绝不是一个二进制数。二进制数的标志为B,如(1001010)B,也可用下标"2"来表示,如(1001010)₂。
(2)八进制
八进制的基数是8,也就是说它有8个数码,即0、1、2、3、4、5、6、7。对比十进制可以看出,比十进制少了"8"和"9"两个数码,这样当一个数的表示形式中出现"8"和(或)"9"时(如23459),那它绝不是八进制数。
八进制数的标志为O或Q(它特别一些,可以有两种标志),如(4603)O(注意是字母O,不是数字0)、(4603)Q,也可用下标"8"来表示,如(4603)₈。在C、C++这类语言中规定,一个数如果要指明它采用八进制,必须在它前面加上一个0(注意是数字0,不是字母O),如:123是十进制,但0123则表示采用八进制。
(3)十进制
十进制是日常生活中常用的数制类型,基数是10,也就是它有10个数码,即0、1、2、3、4、5、6、7、8、9。十进制数的标志为D,如(1250)D,也可用下标"10"来表示,如(1250)₁₀。其实也可以不加标志的,因为默认就是十进制。
(4)十六进制
十六进制数我们平时用得比较少,但在计算机中却用得比较多,如MAC地址、IPv6地址、Windows系统中的注册表,以及磁盘数据存储中都是采用十六进制。
十六进制的基数是16,也就是说它有16个数码,除了十进制中的0~9这10个数码可用外,还使用了A~F这6个英文字母(分别代表10、11、12、13、14、15),这样一来,十六进制的这16个数码依次是0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F(不区分大小写)。对比前面其他几种数制的介绍可以看出,如果一个数的表示形式中出现了字母,如63AB,则它只能是十六进制了。
十六进制数的标志为H,如(4603)H,也可用下标"16"来表示,如(4603)₁₆。十六进制数也常常用前缀0x来表示(注意是数字0,而不是字母O)。在C、C++这类编程语言中也规定,十六进制数必须以0x开头。比如0x10表示一个十六进制数,而不是八进制或者十进制的10。
表2-2是二进制、十进制、八进制和十六进制4种常在计算机中使用的数的对应关系。注意,八进制没有8和9两个数码,八进制数10对应的是十进制数8,八进制数11对应的是十进制数9。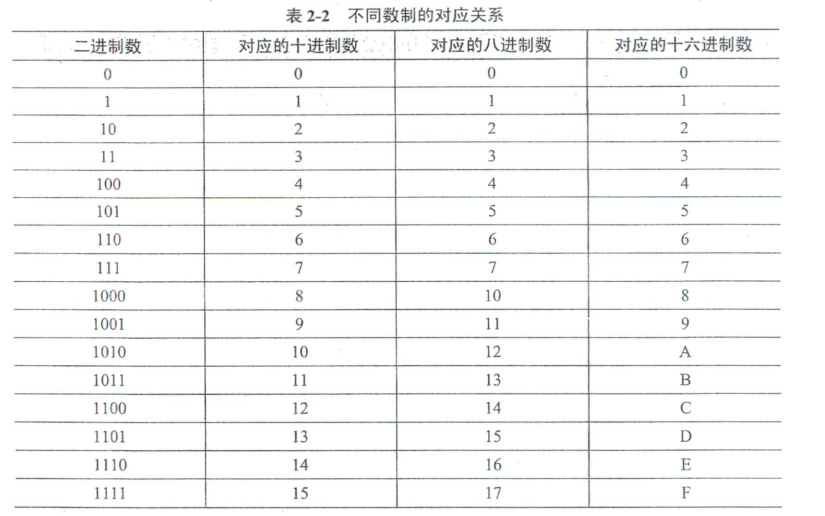
- 二进制与十进制、十六进制的相互转换
(1)二进制转换为十进制的方法
二进制转换成十进制时,只需按它的权值展开即可。"权值"是指对应数值位的进制幂次方数,如二进制整数中第0位(最低位,也就是整数最右边的那位)的权值是2的0次方,第1位的权值是2的1次方......同理在八进制整数中第0位的权值是8的0次方,第1位的权值是8的1次方......以此类推。展开的方式是把二进制数首先写成加权系数展开格式,然后按十进制加法规则求和。这种做法称为"按权相加法"。
二进制数的一般表现形式为:b_{n - 1}\\cdots b_{1}b_{0}(共n位),按权相加展开后的格式为(注意,展开式中从左往右各项的幂次是降低的,最高位的幂次为n - 1,最低位的幂次为0):b_{n - 1}\\times2\^{n - 1}+b_{n - 2}\\times2\^{n - 2}+\\cdots +b_{1}\\times2\^{1}+b_{0}\\times2\^{0}。如二进制数(11010)_2,共5位二进制数码,所以最高位幂次为5 - 1 = 4,最低位幂次为0,按权相加展开格式为:1\\times2\^{4}+1\\times2\^{3}+0\\times2\^{2}+1\\times2\^{1}+0\\times2\^{0},然后把各值按十进制数相加,即可得到16 + 8 + 0 + 2 + 0 = 26。
(2)十进制转换为二进制的方法
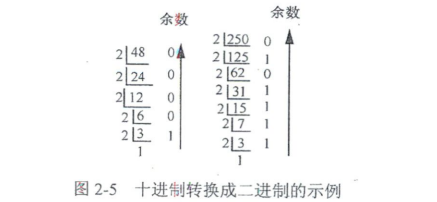
十进制转换为二进制的方法是采用"除2逆序取余法"。先将十进制数除以2,得到一个商数和余数;然后再将商数除以2,又得到一个商数和余数;以此类推,直到商数为小于2的数为止。从最后一步得到的小于2的商开始将其他各步所得的余数(也都是小于2的0或1)排列起来(俗称"逆序排列")就得到了对应的二进制数。
图2-5左图所示的是十进制数48转换成二进制数时依次除以2的过程。图中每步的最右边显示的是各步商数除以2所得到的余数,最后一步的商数为1,因为它小于2,所以不能再除了。然后从最后得到的商数(1)开始依次向上把其他各步除以2得到的余数排列起来,就得到48转换成二进制数的结果为(110000)₂。同理,图2-5右图所示的是十进制数250转换成二进制数的结果就为(11111010)₂。
(3)二进制转换为十六进制的方法
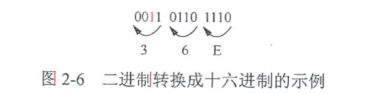
二进制数转换成十六进制数的方法是:由低位向高位,每4位二进制数分成一组,不足4位则用0补足4位;然后将每一组二进制数直接用相应的1位十六进制数表示即可。
如一个二进制数为1101101110,转换成十六进制数时,则把该二进制数码从低(右)到高(左)每4位二进制数码分成一组,最后一组只有2位------11,在其左面补上两个0,然后把各组的4位二进制数码参照表2 - 2得出其对应的十六进制数,即可计算出转换后的十六进制数为36E,如图2 - 6所示。
(4)十六进制转换为十进制的方法
十六进制转换成十进制的方法与二进制转换成十进制的方法一样,也是采用"按权相加法",只是这里的权值是16的相应幂次方。如十六进制数的格式为b_{n - 1}b_{n - 2}\\cdots b_{1}b_{0},则按权相加展开后的格式就是(从左往右幂次依次是降低的,最低位的幂次为0):b_{n - 1}\\times16\^{n - 1}+b_{n - 2}\\times16\^{n - 2}+\\cdots +b_{1}\\times16\^{1}+b_{0}\\times16\^{0},然后把各项相加即可。
如十六进制数为(26345)_{16},共5位十六进制数码,所以最高位幂次为5 - 1 = 4,最低位幂次为0,按权相加展开后的格式为:2\\times16\^{4}+6\\times16\^{3}+3\\times16\^{2}+4\\times16\^{1}+5\\times16\^{0},把各项相加,即可得到131072 + 24576 + 768 + 64 + 5 = 156485。
2.3.4 IPv4地址分类
IPv4地址总体上分为有类地址和无类地址两大类,所谓"有类地址"是指IPv4地址被固定地划分到某一类中,每一类IPv4地址的子网掩码是固定的,也就是子网掩码长度固定,即一个IPv4地址是固定属于某类网络的。"无类地址"是IPv4地址没有固定划分到某一类中,是针对有类地址中的单播地址进行划分,其子网掩码长度不固定。
在有类地址中,IPv4地址又分为5小类,分别用A、B、C、D和E表示。其中A、B、C这3类是单播通信地址类型,D是组播通信地址类型,E是保留地址类型。
- A类IPv4地址
A类IPv4地址是专门为网络规模比较大的网络而设计的IPv4单播地址,因为它的Network ID部分所占的位数最少,所以用于标识主机的Host ID位数是最多的。在A类IPv4地址结构中,用来标识网络的Network ID部分只占IPv4地址中的最高1个字节,Host ID部分占用了剩余的全部3个字节,如图2 - 7所示。

另外,规定A类IPv4地址中Network ID的最高位固定为0,只有其余7位是可变的。这样一来,A类网络的总数从256(2⁸)个减少到128(2⁷)个。但实际上可用的只有126个,即整个IPv4地址中可构建126个A类网络,因为Network ID为0和127的A类网络是不可用的。Network ID全为0的地址用于保留,不能被分配;而Network ID为01111111(相当于十进制的127)的地址是专用本地环路测试(也就是通常所说的环回地址),也是不能被分配的。也就是凡是以0,或者127开头的地址是不能分配给节点使用的。
因为A类IPv4地址中Host ID有24位,所以可用的Host ID数,也就是每个A类网络中拥有的IPv4地址数为16777216(2²⁴)。但Host ID全为0的地址为"网络地址",而Host ID全为1的地址为"广播地址",均不能分配给主机使用,所以实际上可用的地址数为16777214(16777216 - 2)。由此可知,A类IPv4地址包含的网络数是最少的,但每个A类网络中拥有的IPv4地址数是最多的,可以构建的网络规模最大,适用于大型企业和运营商。
我们再根据"子网掩码"的定义,可以很容易得出A类IPv4地址的子网掩码为固定的255.0.0.0,因为子网掩码就是由Network ID部分全置1,Host ID部分全置0得到的,而A类地址中Network ID部分就是最高的那个字节,其余3个字节均为Host ID部分。
- B类IPv4地址
相比于A类IPv4地址是针对大型网络设计的而言,B类IPv4地址是针对中型网络而设计的。在B类IPv4地址中,Network ID占用最高的两个字节,而Host ID则占用剩余的低两个字节,如图2 - 8所示。

另外,规定B类IPv4地址Network ID的最高两位固定为1、0,只有其余的14位可变。由此可知B类网络的总数从65536(2¹⁶,也可写成256×256)减少到16384(2¹⁴,64×256)个。B类IPv4地址中Host ID为16位,所以可用的Host ID数,也就是每个B类网络拥有的IPv4地址数为65536(2¹⁶)个。同样因为Host ID全为0的地址为网络地址,而Host ID全为1的地址为广播地址,均不能分配给主机使用,所以实际上可用的地址数为65534(65536 - 2)。
我们再根据"子网掩码"的定义,可以很容易得出B类IPv4地址的子网掩码为固定的255.255.0.0,因为B类地址中Network ID部分是最高的两个字节,每个字节均为8个连续的1,转换成十进制后每个字节就是255了。
- C类IPv4地址
C类IPv4地址是针对小型网络而设计的,其Network ID占用最高的前3个字节,而Host ID只占用最后的一个字节,如图2 - 9所示。从中可以得出,采用C类IPv4地址的网络数最多,而每个C类IPv4网络中可使用的IPv4地址数又是最少的,这正好符合中小型企业占大多数,而每个中小型企业网络中的用户数又不多的特点。
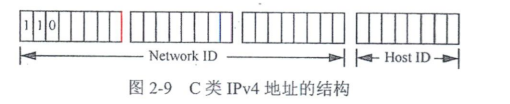
另外,规定C类IPv4地址Network ID的最高3位固定为1、1、0,只有后面的21位可变。由此得知C类网络总数从16777216(2²⁴,也可写成256×256×256)个减少到2097152(2²¹,32×256×256)个。C类IPv4地址中Host ID仅为8位,所以可用的Host ID数,也就是每个C类网络拥有的IPv4地址数为256(2⁸)个。同样,因为Host ID全为0的地址为网络地址,而"主机ID"全为1的地址为广播地址,不能分配给主机使用,所以实际上可用的地址数为254(256 - 2)。
我们同样根据子网掩码的定义可以很容易得出,C类IPv4地址的子网掩码为固定的255.255.255.0,因为C类地址中Network ID部分是最高的前3个字节,每个字节均为8个连续的1,转换成十进制后每个字节就是255了。
表2 - 3总结了A、B和C 3类IPv4单播地址的主要特征,其实可以直接从第一个字节w的取值得出某个IPv4地址是属于哪类网络中的地址。

- D类IPv4地址
前面介绍的A、B、C类IPv4地址均是应用于单播通信的IPv4单播地址,此处介绍的D类IPv4地址是应用于组播通信的,是IPv4组播地址。通过组播IPv4地址,组播源(配置的IP地址仍是IPv4单播地址)只需发送一份数据,对应组播组(以D类组播地址标识)的所有用户就均可收到。IPv4组播地址不能分配给主机或设备接口使用。
组播地址是不分Network ID和Host ID的,也没有子网掩码,只是规定在最高字节中高4位固定为1、1、1、0的IPv4地址属于D类组播地址,如图2 - 10所示,D类组播地址段范围为224.0.0.0~239.255.255.255。

- E类IPv4地址
E类IPv4地址是属于IANA保留使用,当初规定不分配给用户使用的IPv4地址,其实目前也已分配完了。E类地址的地址段范围为240.0.0.0~247.255.255.255,其特征是最高5位分别是1、1、1、1、0,如图2 - 11所示,也就是有27位是可变的。

2.3.5 公网/私网 IPv4 地址
在使用 IPv4 地址时经常听到"公网 IPv4 地址"和"私网 IPv4 地址",到底哪些是公网 IPv4 地址,哪些是私网 IPv4 地址呢?其实这主要是针对 2.3.4 节所介绍的 A、B、C 这 3 类 IPv4 单播地址(包括划分后的子网地址)而言的,尽管 D 类组播地址也有公用与私用之分。
为了提高 IPv4 地址的重复利用率,我们设计 IPv4 地址时就在 A、B、C 这 3 类 IPv4 地址中各自划分了一段专用于各组织局域网内部的地址段,这就是前面所说的"私网 IPv4 地址",或者"局域网专用 IPv4 地址"。私网 IPv4 地址在不同公司内部的局域网中可以重复使用,且无须向 IP 地址管理机构申请、注册和购买。
A、B、C 类地址各自划分的局域网专用地址段(由这些网段划分的子网同样专用于局域网)如下。
(1)10.0.0.0/8(10.0.0.0,255.0.0.0)
这是 A 类 IPv4 地址中划分出的私网地址段,范围为 10.0.0.0~10.255.255.255。如果用地址前缀表示地址范围,则可表示为 10.0.0.0/8。在这样一个地址空间中有 24 个 Host ID 位,相当于最多可以有 2²⁴(16777216)个 IP 地址(包括了网络地址和广播地址),满足了大多数大型局域网的 IP 地址需求。
(2)172.16.0.0/12(172.16.0.0,255.240.0.0)
这是 B 类 IPv4 地址中划分出的私网地址段,范围为 172.16.0.0~172.31.255.255。如果用地址前缀表示地址范围,则可表示为 172.16.0.0/12。但这里的"12"不能理解为子网掩码前缀长度,仅是用于指定一个 IPv4 地址段范围。具体的网络中仍是 B 类网络中所限制的 16 位 Host ID 个数,相当于最多可有 2¹⁶(65536)个 IP 地址(包括网络地址和广播地址),从而满足大多数中型局域网的 IP 地址需求。
(3)192.168.0.0/16(192.168.0.0,255.255.0.0)
这是 C 类 IPv4 地址中划分出的私网地址段,范围为 192.168.0.0~192.168.255.255。如果用地址前缀表示地址范围,则可表示为 192.168.0.0/16。这里的"16"也不能理解为子网掩码前缀长度,仅是用于指定一个 IPv4 地址段范围。具体的网络中仍是 C 类网络中所限制的 8 位 Host ID 个数,相当于最多可有 2⁸(256)个 IP 地址(包括网络地址和广播地址),从而满足大多数小型局域网的 IP 地址需求。
2.4 IPv4子网划分与聚合
前面介绍的都是基于分类的A、B和C类的IPv4地址划分方式,但随着计算机网络
的普及和互联网应用的高速发展,这种原始划分方式下的公网IPv4地址明显不足。基于此,诞生了两种非常重要的技术,那就是VLSM(Variable Length Subnet Mask,可变长子网掩码)和CIDR(Classless Inter - Domain Routing,无类别域间路由),把传统有类IPv4网络进一步变成一个更为高效、更为实用的无类网络。
VLSM是把有类网络中的固定子网掩码进一步划分成为可变长子网掩码,用于IPv4子网的划分,把一个大的网络划分成多个小的子网;而CIDR则用于IPv4子网的聚合,把多个子网汇总成一个更大的子网或者对应的有类网络,甚至超网,这样可以在实现各子网间路由的基础上又大大减少路由器中的路由条目,提高路由表查找效率。
2.4.1 VLSM子网划分的基本思想
VLSM实现子网划分的基本思想很简单,就是把原来的有类网络IPv4地址中的Network ID部分向Host ID部分借位,把原属于Host ID的一部分变成Network ID的一部分,我们通常称之为Sub - Network ID(子网ID),如图2 - 12所示。
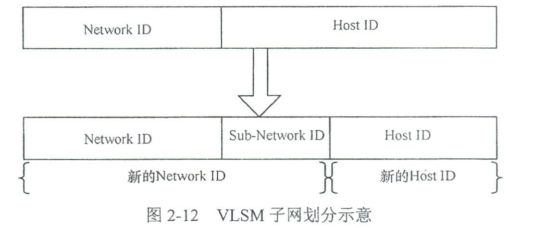
这样一来,新的Network ID就等于"原来的Network ID"+"Sub - Network ID",新的Host ID等于"原来的Host ID"-"Sub - Network ID"。Sub - Network ID长度决定了可以划分子网的数量,该数量等于2ⁿ,n为Sub - Network ID的长度,即所划分的子网只能是2的n次幂,且每增加一位,所划分的子网是原来的2倍。如向"主机ID"借1位可划分成2个子网,借2位则可划分成4个子网,借3位则可以划分成8个子网,以此类推。
因为由同一个网络划分出来的每个子网的Sub - Network ID长度一样,各子网新的Network ID和新的Host ID长度也都一样,所以各子网的子网掩码和所包括的IPv4地址数都一样,即各子网的IPv4地址数是原网络中的IPv4地址数除以所划分的子网数。如一个C类网络,向Host ID借3位后就划分了8个子网,因为每个C类网络只有256个IPv4地址,所以划分后的每个子网的IPv4地址数为256÷8 = 32。其实也可以简单地计算各子网的IPv4地址数,那就是2的新Host ID位数次方。如前面的示例中,向C类网络的Host ID借3位后,则新的Host ID为8 - 3 = 5位,这样很快就算出各子网的IPv4地址数是2⁵ = 32。
通过VLSM可以非常灵活地依据实际所需的地址数来调整所划分的子网大小。如一家公司中有6个部门,每个部门的人数不超过30人,现在想为每个部门分别配置一个子网。如果没有VLSM,则需要用6个C类网络,而有了VLSM后,仅用一个C类网络就可以划分出所需的6个子网(向Host ID借3位,共划分8个子网,每个子网有30个可用的主机 IPv4 地址),而且每个子网中可用的 IPv4 地址更贴近各部门的实际需求,这样就大大提高了 IPv4 的利用率。
【经验之谈】VLSM 只能划分相同大小的子网,也就是一个网络划分了子网后,各子网的 IPv4 地址数是相同的。要想使各子网大小不一样,必须同时结合后面将要介绍的 CIDR 技术,把其中一些子网再聚合成一些稍大些的子网。另外,子网还可以进一步被划分成更小的子网,这就是多级子网划分。
2.4.2 广播地址的分类
因为广播地址中涉及子网的广播地址,所以这部分在"子网划分与聚合"部分介绍。
本来广播地址只有一种,就是每个有类网络中所说的最后那个 IPv4 地址,它可以在整个有类网络内进行广播。但自从有了无类网络,并进行子网划分后,根据其广播范围的大小,IPv4 广播地址又分成了以下几种。
(1)网络广播地址
"网络广播地址"是传统意义上的有类网络的广播地址。网络广播地址可以将数据包广播发送到本地有类网络内部所有节点上。IPv4 路由器不转发目的 IP 地址为网络广播地址的广播数据包,也就是网络广播数据包只能在一个本地有类网络(包括其所划分的所有子网)内部广播,而不能被路由到其他网络中。
网络广播地址是将有类 IPv4 地址(A、B、C 3 类)中的所有 Host ID 部分全部置为 1 得到的,也就是每个 Host ID 的 8 位组均为 255。例如,假设 151.110.0.0 是一个有类的 B 类地址,则其网络广播地址为 151.110.255.255。
(2)子网广播地址
"子网广播地址"针对的是具体子网的广播地址。它仅可以将数据包发送到相应无类子网内部的所有节点上。IPv4 路由器也不转发目的 IP 地址为子网广播地址的广播数据包,也就是子网广播数据包只能在一个子网内部广播,而不能被路由到其他子网中。
子网广播地址是通过无类地址的 Host ID 部分全部设置为 1 得到的,因为在包含 Host ID 的 8 位组中还可能包括 Network ID(严格地讲是 Sub - Network ID)中的一些位,所以此时的广播地址中 Host ID 所对应的 8 位组值不一定是 255 了。如 192.168.1.0/26 这个子网的广播地址是 192.168.1.63,而不是 192.168.1.255。
(3)有限广播地址
"有限广播地址"是通过 IPv4 地址的 32 位全部设置为 1(255.255.255.255)而形成的。在本地 Network ID 未知的情况下(如采用 DHCP 服务自动分配 IP 地址的客户端),可以使用有限广播地址来进行本地网络或子网内部所有节点的传送。路由器接收到目的 IP 地址为有限广播地址的 IP 报文后,会停止对该报文的转发。
2.4.3 IPv4 子网划分方法及示例
在进行子网划分时,往往有以下两种情形,下面介绍各自的计算方法。
情形一:已知对某网络划分的子网数,或同时给出了子网的最大主机地址数,求子网掩码、子网地址范围、网络地址和广播地址。
在这种情况下,子网划分的计算步骤如下。
① 由已知子网掩码前缀或子网掩码确定子网掩码中非0/非255的字节的地址块大小n。
方法是对子网掩码中各值为非255的字节用"256 - 对应字节值",或者用256除以通过子网ID位数得到划分的子网数,均可得出地址块大小(值为0的字节的地址块大小为256)。
② 用划分子网后的子网掩码中非0/非255字节的值除以地址块大小n,确定划分的子网数m、每个子网的地址范围、网络地址和广播地址。
【示例3】求172.16.1.0/18子网中最大主机IPv4地址。
① 由172.16.1.0/18可知其子网掩码前缀为18,得出其子网掩码为255.255.192.0(前18位全为1,后14位全为0)。
② 子网掩码中仅第3个字节值为非0且非255的字节,用256 - 192,或者通过子网ID 位为 2,用 256 除以 4(2²),均可得出该字节的地址块大小为 64。由此可得出 4 个子网的地址范围为:
172.16.0.0~172.16.63.255
172.16.64.0~172.16.127.255
172.16.128.0~172.16.191.255
172.16.192.0~172.16.255.255
显然 172.16.1.0/18 子网是属于第一个子网,最大可用的主机 IPv4 地址为 172.16.63.254。
2.4.4 CIDR 子网聚合的基本思想
这里所说的"子网聚合"不是在物理上把原来划分后的子网又重新聚合成一个大的网络,而是计算一条同时用于划分后各子网数据转发的聚合路由(或称"汇总路由"),以便减少设备上的路由表项数量,提高路由表查找效率。
这对于当前一些大型企业,或者 ISP(Internet Service Provider,互联网服务提供商)骨干网核心路由器设备是非常必要的,因为这些核心设备连接的网络非常多,如果每一个子网都以具体的明细路由来体现的话,设备中的路由表项数量将非常多,转发用户数据时,路由表的查找效率会大大降低。
子网聚合所使用的技术是前面提到的 CIDR。通过它可以计算出通过 VLSM 划分后的各子网的聚合路由。聚合路由的计算关键是要计算出聚合后的 Network ID 长度,方法很简单,我们可以简单地理解为前面介绍的 VLSM 的逆过程。具体做法是把原来子网中的 Host ID 向 Network ID 部分借位(所借位数为聚合 ID,等于所聚合子网数 2ⁿ 表示形式中的 n),实现 Host ID 扩展(可容纳的主机数增多),Network ID 部分缩小,最终达到聚合子网路由,精减路由表项的目的。但聚合网络的 Network ID 位数不能小于 8。其基本示意图如图 2 - 13 所示。
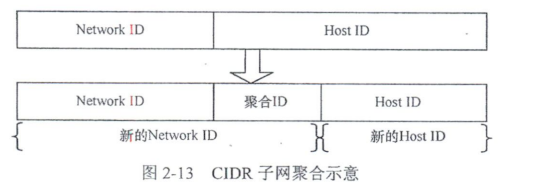
通过CIDR进行子网聚合时要注意以下几项原则。
①与VLSM划分中向Host ID借n位(n大于等于1)可划分出2ⁿ个子网对应,通过CIDR向Network ID借n位时则可聚合2ⁿ个子网。
也就是Network ID每减少1位,所聚合的子网数就是前面所聚合的子网数的2倍。如向Network ID借1位时聚合了2个子网,借2位时则能聚合4个(2×2)子网,借3位时则能聚合8个(2×4)子网,以此类推。
②与VLSM只可以划分出2ⁿ个(如2、4、8、16等)子网,不能划分出非2ⁿ个(如3、5、6、7、9、10等)子网一样,子网聚合也只能聚合2ⁿ个子网,不能聚合非2ⁿ个子网。
例如,你只想聚合192.168.1.64/26、192.168.1.128.0/26、192.168.1.192/26这3个子网,但最终聚合的肯定不会只针对这3个子网,而是把192.168.1.0/26这个子网包括进去了,也就是聚合的路由会同样适用于192.168.1.0/26这个子网。
③ 被聚合的最后一个子网必须是原网络划分出的第2ᵐ个子网,如第0、2、4、8、16等个子网,如果不是则最终被聚合的子网是向后延续到最近一个第2ᵐ个子网,且必须连续,同时要满足前面所说的被聚合子网数必须是2ⁿ个。
如对192.168.1.0/24这个有类网络划分了8个子网,则从第1个到第8个子网的网络地址分别为:192.168.1.0/27、192.168.1.32/27、192.168.1.64/27、192.168.1.96/27、192.168.1.128/27、192.168.1.160/27、192.168.1.192/27、192.168.1.224/27。根据以上介绍的原则可知,192.168.1.0/27、192.168.1.32/27这两个子网可以聚合,192.168.1.0/27、192.168.1.32/27、192.168.1.64/27、192.168.1.96/27这4个子网可以聚合,192.168.1.128/27、192.168.1.160/27、192.168.1.192/27、192.168.1.224/27这4个子网也可以聚合,当然全部8个子网更可以聚合。
不能仅对192.168.1.32/27、192.168.1.64/27这两个子网进行聚合,因为最后一个被聚合的子网192.168.1.64/27是属于原有类网络划分出的第3个子网(不是2ᵐ),不符合本条原则规定。这两个子网最终聚合的结果肯定还会包括192.168.1.96/27这个子网,同时还包括最前面的192.168.1.0/27子网,因为最终被聚合的子网数要符合2ⁿ个。也不能仅对192.168.1.32/27、192.168.1.64/27、192.168.1.96/27、192.168.1.128/27这4个子网进行聚合,因为最后一个被聚合的子网192.168.1.128/27是原有类网络划分的第5个子网(也不是2ᵐ),也不符合本条规定。这4个子网聚合的最后一个子网是192.168.1.224/27,同时为了满足被聚合的子网必须是2ⁿ个,所以最前面的192.168.1.0/27子网也将同时被聚合。
同样的道理,也不能仅对192.168.1.0/27、192.168.1.32/27、192.168.1.64/27、192.168.1.96/27、192.168.1.128/27,或者192.168.1.32/27、192.168.1.64/27、192.168.1.96/27、192.168.1.128/27、192.168.1.160/27,或者192.168.1.64/27、192.168.1.96/27、192.168.1.128/27、192.168.1.160/27、192.168.1.192/27,或者192.168.1.96/27、192.168.1.128/27、192.168.1.160/27、192.168.1.192/27、192.168.1.224/27这些子网进行聚合,因为被聚合子网数不是2ⁿ个。这些子网聚合的最终结果是什么大家可以根据前面的规则进行分析。
2.4.5 子网聚合方法及示例
子网聚合的计算方法有两种。
方法一:直接看最终被聚合的子网数得出,聚合2个子网,Network ID长度减1,聚合4个子网,Network ID长度减2,聚合8个子网,Network ID长度减3,以此类推。但最终被聚合的子网数只能是2ⁿ,且最后一个被聚合子网必须为第2ᵐ个。
方法二:求各被聚合子网中Network ID中相同部分的位数,就是把各子网的网络地址用二进制形式表示,然后把连续完全相同部分作为聚合后的Network ID。
下面通过几个示例进行具体介绍。
【示例1】求192.168.1.0/27、192.168.1.32/27、192.168.1.64/27、192.168.1.96/27 4个连续子网聚合后的网络地址和子网掩码。
(1)方法一
先用方法一来求解。从题中的已知条件很容易看出,这里被聚合的4个子网是连续的,符合被聚合子网必须为2ⁿ个的要求。同时最后一个被聚合的子网192.168.1.96/27为原网络192.168.1.0/24划分后的第4个子网,也符合最后一个被聚合子网为第2ⁿ个。
方法二:求各被聚合子网中Network ID中相同部分的位数,就是把各子网的网络地址用二进制形式表示,然后把连续完全相同部分作为聚合后的Network ID。
下面通过几个示例进行具体介绍。
【示例1】求192.168.1.0/27、192.168.1.32/27、192.168.1.64/27、192.168.1.96/27 4个连续子网聚合后的网络地址和子网掩码。
(1)方法一
先用方法一来求解。从题中的已知条件很容易看出,这里被聚合的4个子网是连续的,符合被聚合子网数必须为2ⁿ个的要求。同时最后一个被聚合的子网192.168.1.96/27为原网络192.168.1.0/24划分后的第4个子网,也符合最后一个被聚合子网为第2ᵐ个的
要求。所以直接可以得出,聚合后的Network ID长度为原来的27减2,等于25,网络地址的计算可随便把其中一个子网的网络地址中的前25位保持不变,后面7位全部置0得到,最终的网络地址为192.168.0.0/25,子网掩码为255.255.255.128.0
(2)方法二
下面通过方法二也可验证通过方法一得出的结果是否正确。把示例中的4个连续子网的网络地址用二进制形式表示如下:
11000000.10101000.00000000.00000000
11000000.10101000.00010000.00000000
11000000.10101000.00100000.00000000
11000000.10101000.00110000.00000000
然后把这4个子网的Network ID中相同的部分(即11000000.10101000.0部分保持不变,其余各位均置0),即得出聚合后的网络地址为192.168.0.0/25。这里聚合的是4个子网,即2²,所以最终的子网掩码长度比原来子网的子网掩码长度27短2,得到聚合后网络的子网掩码长度为25;最后把前面25位全部置1,后面7位全部置0,就得到聚合网络的子网掩码为:255.255.128.0。
通过方法二的计算验证了方法一计算的结果是正确的。
【示例2】求192.168.4.0/24、192.168.5.0/24、192.168.6.0/24、192.168.7.0/24这4个有类网络聚合后的网络地址和子网掩码。
下面同样按以上两种方法来计算。
(1)方法一
这是4个有类网络的聚合,因为这里被聚合的最后一个网络是192.168.7.0/24,其也可被看成是192.168.0.0/21网络划分出的其中4个子网(一共向Network ID借了3位,划分出了8个子网)。但这里最后一个被聚合的子网是192.168.7.0/24,恰好是第8个子网(第一个子网可以看作为192.168.0.0/24),符合最后一个被聚合子网为第2ᵐ个的要求,所以最终聚合的结果是可以仅针对示例中这4个给出的网络进行聚合的。
根据前面得出的规律,4个子网聚合,就只需要向Network ID部分借2位,相当于是被聚合子网中原来的Network ID减2,即24 - 2,等于22。然后把示例中的任意一个子网的Network ID前22位保持不变,后面10位全置0,就得到聚合后的网络地址为192.168.1.0/22,聚合后网络的子网掩码为255.255.252.0。
(2)方法二
同样按照前面介绍的第二种方法来计算,验证方法一的计算结果的正确性。我们把示例中的4个有类网络的网络地址转换成如下二进制形式:
11000000.10101000.00000100.00000000
11000000.10101000.00000101.00000000
11000000.10101000.00000110.00000000
11000000.10101000.00000111.00000000
结果得出相同部分共有22位,我们把余下的10位全部置0就得出聚合后的网络地址为192.168.1.0/22;然后把最高22位全部置1,后面10位全部置0,就得出聚合后网络的子网掩码为255.255.252.0。方法二与前面方法一计算的结果完全一样。
这里假设示例中要求只聚合192.168.4.0/24、192.168.5.0/24、192.168.6.0/24这3个有类网络,大家计算一下,其结果仍是与上面一样,因为最后一个被聚合的有类网络不是原网络划分出的第2^m个,所以不能作为最后一个被聚合的网络,最终聚合的结果仍将包括192.168.7.0/24这个网络。
2.4.6 网络地址、广播地址和主机地址的注意事项
因为有了无类网络,所以不能按有类网络来区分网络地址、广播地址和主机IPv4地址了,因为在无类网络中,Network ID和Host ID可能不是连续的完整字节,而是其中有一个字节既包括了Network ID,又包括了Host ID。而且经过子网划分后,原来整个地址段被分成了多段,而每个子网都有一个网络地址和广播地址,所以子网的网络地址可能不再是原来有类网络中的第一个IPv4地址,广播地址也可能不是原来有类网络中最后一个IPv4地址。但无类网络与有类网络有一点是相同的,就是网络地址是子网的第一个IPv4地址,广播地址是子网的最后一个IPv4地址。
总的来说要注意以下几个方面。
(1)最后一个字节为0的IPv4地址不一定是网络地址
如172.16.2.0/18就不是网络地址,它是172.16.0.0/18这个子网中的一个中间IPv4地址,既不是第一个,也不是最后一个。因为172.16.0.0/18这个子网的地址范围是172.16.0.0~172.16.3.255,它的网络地址是172.16.0.0/18。
(2)最后一个字节为255的IPv4地址不一定是广播地址
如172.16.2.255/18就不是广播地址,它也是172.16.0.0/18这个子网中的一个中间IPv4地址,既不是第一个,也不是最后一个。因为172.16.0.0/18这个子网的地址范围是172.16.0.0~172.16.3.255,它的广播地址是172.16.3.255/18。
(3)最后一个字节为0或者255的也可能是主机IPv4地址
在有类网络中最后一个字节为0或255的肯定分别是网络地址或广播地址,其不能作为主机IPv4地址。但在无类网络中,这个是可能的。如前面说的172.16.2.0/18、172.16.2.255/18都是172.16.0.0/18这个子网可用的主机IPv4地址,其实还有172.16.1.0/18、172.16.3.0/18、172.16.0.255/18、172.16.1.255/18也是这个子网可用的主机IPv4地址。
(4)网络地址的最后一个字节不一定为0
在有类网络中,网络地址的最后一个字节肯定为0,但在无类网络中,网络地址最后一个字节可能不是0。如192.168.1.0/24这个有类网络通过向Host ID借2位划分4个子网,分别为192.168.1.0/26、192.168.1.64/26、192.168.1.128/26、192.168.1.192/26。后面3个子网的网络地址的最后一个字节都不为0。
(5)广播地址的最后一个字节不一定为255
如192.168.1.0/24这个有类网络划分4个子网后,除最后一个子网192.168.1.192/26的广播地址最后一个字节为255外,前面3个子网的广播地址分别为192.168.1.63/26、192.168.1.127/26、192.168.1.191/26。
2.5 IPv4网络的3种数据包传输方式
IPv4协议定义了3种IPv4数据包的传输方式:单播、广播和组播。
2.5.1 单播传输方式
单播传输用于发送数据包到单个目的地,且每发送一份单播数据包都使用一个单播IPv4地址作为目的地址。这是最常见的IPv4数据包传输方式,是一种点对点传输方式,对应单播通信。采用单播方式时,系统为每个需求该数据的用户单独建立一条数据传送通路,并为该用户发送一份独立的副本数据。
如图2 - 14所示,假设Host C需要从数据源(Source)获取数据,则数据源必须与Host C设备建立单独的传输通道。
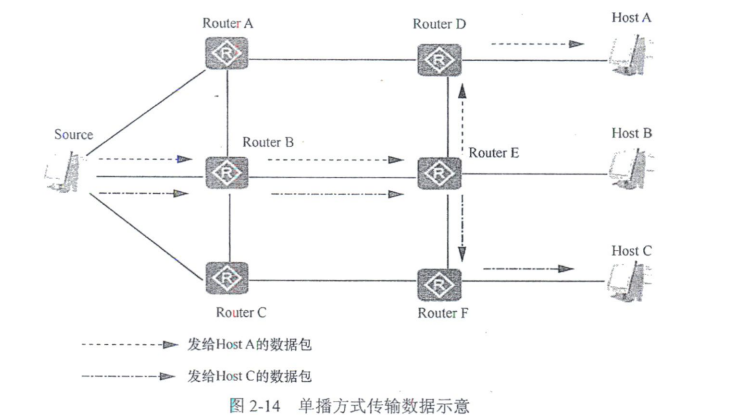
由于网络中传输的数据量和要求接收该数据的用户量成正比,因此当需要相同数据的用户数量很庞大时,数据源主机就必须将多份内容相同的数据发送给这些目的用户。这样一来,网络带宽将可能成为数据传输中的瓶颈,不利于数据规模化发送。
2.5.2 广播传输方式
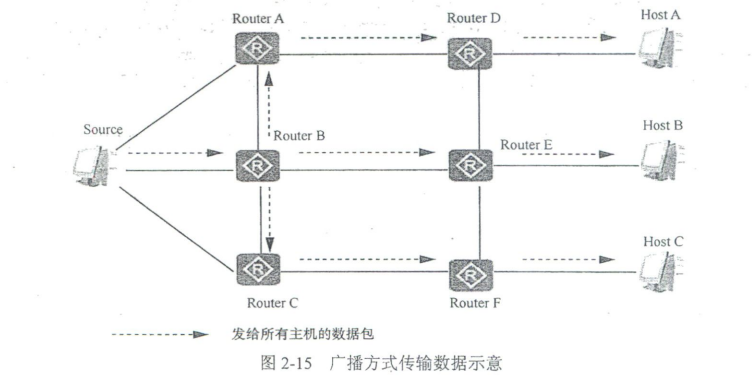
广播传输是指发送数据包到同一广播域或子网内的所有设备的一种数据传输方式,对应广播通信。在广播传输方式中,IPv4数据包中的目的IP地址对应网段的广播IPv4地址,是一种点对多点传输方式。如果采用广播方式,系统会为网络中所有用户各传送一个数据副本,不管它们是否需要。当然最终可能只有一个或多个,也可能没有节点接收该广播数据包。
如图2 - 15所示,假设Host A、Host C需要从数据源获取数据,则数据源通过路由器广播该数据,但这时网络中本来不需要接收该数据的Host B也同样接收到该数据,这样不仅信息的安全性得不到保障,而且会造成同一网段中信息泛滥。由此可见,这种传输方式不利于与特定对象进行数据交互,并且浪费了大量的带宽,带来了数据泄露的安全性隐患。
2.5.3 组播传输方式
通过前面的介绍可以看出,传统的单播和广播通信方式不能有效地解决单点发送、多点接收的问题。IPv4组播技术的出现及时解决了这些问题,它也是一种点对多点传输方式,对应组播通信。当网络中的某些用户需要特定数据时,组播数据发送者(即组播源)仅发送一次数据,借助组播路由协议为组播数据包建立组播分发树,被传递的数据到达距离用户端尽可能近的节点后才开始复制和分发。
在组播传输方式中,IPv4数据包中的目的IPv4地址是D类的组播IP地址。如图2 - 16所示,假设Host A、Host C需要从数据源获取数据,为了将数据顺利地传输给真正需要该数据的用户,Host A、Host C组成一个接收者集合(就是组播组),网络中各路由器根据该集合中各接收者的分布情况进行数据的转发和复制,最后准确地传输给实际需要的接收者,如Host A和Host C(Host B接收不到)。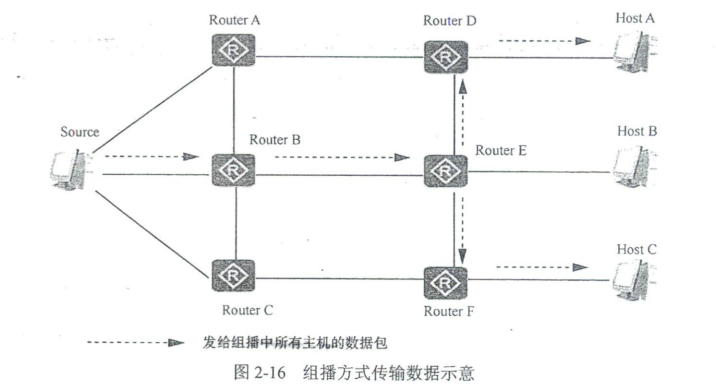
综上所述,相比单播传输方式,组播传输方式由于被传递的信息在距信息源尽可能远的网络节点才开始被复制和分发,所以用户的增加不会导致信息源负载的加重以及网络资源消耗的显著增加。相比广播传输方式,组播传输方式由于被传递的信息只会发送给需要该信息的接收者,所以不会造成网络资源的浪费,并能提高信息传输的安全性。