引言:视觉智能的两大支柱
计算机视觉的实现可以看作一个多层次的处理管道 ,底层是图像处理,上层是计算机视觉核心任务。这两者并非相互独立,而是相辅相成的技术体系:
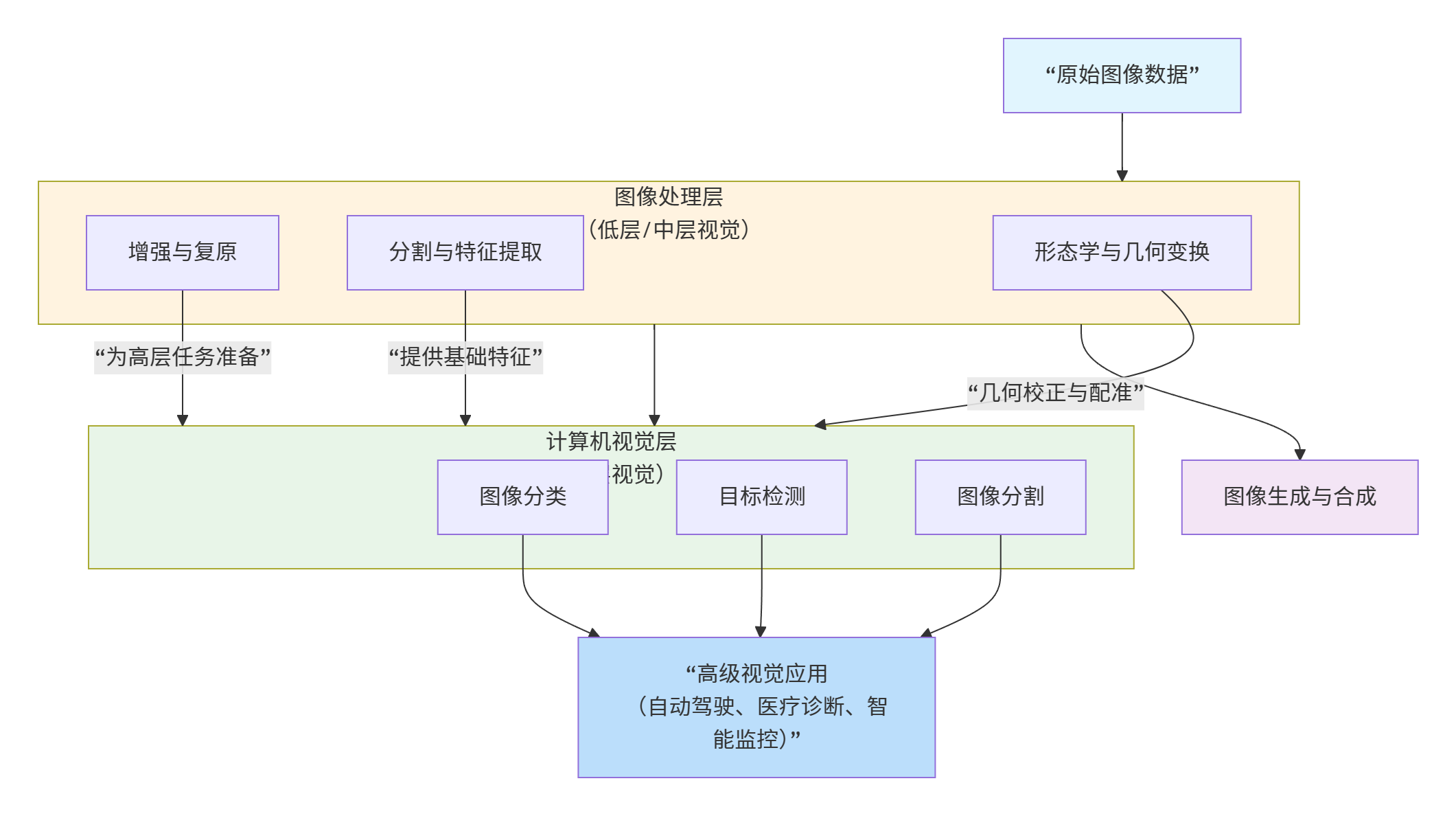
工具箱思维在这两个层面都有体现:
- 图像处理:选择正确的"工具"来处理像素、提取特征
- 计算机视觉:选择正确的"模型"来理解语义、完成任务
掌握这两个层面工具的选择与组合能力,是成为视觉领域专家的关键。
第一部分:图像处理基础工具箱
1.1 图像增强与复原:改善"视觉输入质量"
-
核心任务:改善图像的视觉效果,从降质图像中恢复信息
-
工具分类:
- 对比度增强:直方图均衡化、伽马校正
- 平滑去噪:高斯滤波(抑制高斯噪声)、中值滤波(去除椒盐噪声)
- 锐化增强:拉普拉斯算子、Sobel 算子
- 图像复原:维纳滤波、盲去卷积
1.2 图像分割:划定"兴趣区域"
-
核心任务:将图像划分为具有相似属性的若干区域
-
工具分类:
- 阈值分割:Otsu 方法、自适应阈值
- 边缘检测:Canny 算子、Sobel 算子
- 区域分割:区域生长、分水岭算法
- 聚类分割:K-means、均值漂移
1.3 特征提取与描述:捕捉"关键信息"
-
核心任务:提取稳定、可区分的局部或全局特征
-
工具分类:
- 局部特征:SIFT(尺度不变)、SURF(加速版)、ORB(实时应用)
- 角点特征:Harris 角点检测、Shi-Tomasi 角点
- 全局特征:颜色直方图、纹理特征(LBP、Gabor)
1.4 形态学操作:处理"形状与结构"
-
核心任务:基于形状处理二值图像,用于去噪、连接、分离
-
工具分类:
- 基本操作:膨胀、腐蚀
- 组合操作:开运算(去噪)、闭运算(填充)
- 高级应用:形态学梯度、顶帽/黑帽变换
1.5 几何变换与图像配准:实现"对齐与校正"
-
核心任务:对图像进行空间变换,实现图像间的对齐
-
工具分类:
- 几何变换:仿射变换、投影变换
- 图像配准:特征匹配 + RANSAC 算法
图像处理工具箱小结 :这些工具主要处理图像的低层特征 (像素、边缘、纹理)和中层特征(区域、形状),是后续高级视觉任务的基础。
第二部分:计算机视觉核心任务工具箱
2.1 图像分类:识别"是什么"
-
核心任务:为整张图像分配语义标签
-
工具演进:
- 传统方法:SIFT/HOG 特征 + SVM/随机森林
- 深度学习:CNN(ResNet、EfficientNet)、Transformer(ViT、Swin Transformer)
-
评估指标:Top-1/Top-5 准确率
2.2 目标检测:定位"在哪里,是什么"
-
核心任务:识别目标并用边界框标出位置和类别
-
工具演进:
- 两阶段检测:R-CNN 系列(Faster R-CNN、Mask R-CNN)
- 单阶段检测:YOLO 系列、SSD、RetinaNet
- Transformer 检测:DETR、Deformable DETR
-
评估指标:mAP(平均精度均值)、IoU(交并比)
2.3 语义分割:理解"每个像素属于什么"
-
核心任务:为每个像素分配语义类别标签
-
工具演进:
- 编码器-解码器:FCN、U-Net、SegNet
- 空间金字塔:DeepLab 系列、PSPNet
- Transformer 架构:SETR、SegFormer
-
评估指标:mIoU(平均交并比)、像素准确率
2.4 实例分割:区分"每个独立个体"
-
核心任务:在语义分割基础上区分同一类别的不同实例
-
工具演进:
- 基于检测:Mask R-CNN、Cascade Mask R-CNN
- 单阶段:SOLO、YOLACT
- Transformer:Mask2Former、QueryInst
-
评估指标:mAP(基于掩码)
2.5 图像生成与合成:从"理解"到"创造"
-
核心任务:生成新的、逼真的图像
-
工具演进:
- 生成对抗网络:GAN、StyleGAN、CycleGAN
- 变分自编码器:VAE
- 扩散模型:DDPM、Stable Diffusion、DALL-E
-
评估指标:FID、IS 分数、人类评估
计算机视觉工具箱小结 :这些工具处理图像的高层语义(对象、场景、概念),实现从感知到理解的跨越。
第三部分:整合工具箱------从预处理到高层理解的完整流水线
真正的视觉系统往往是多层次工具的组合。以下是典型的工作流程:
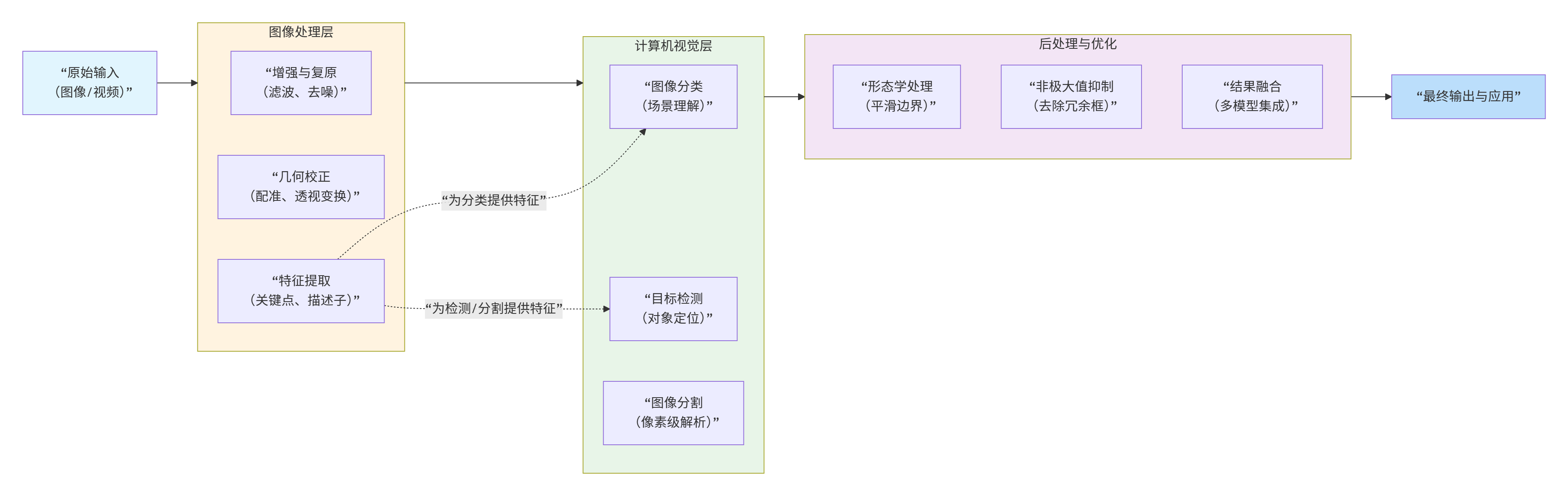
3.1 实际案例:智能监控系统流水线
1. 图像采集
↓
2. 图像预处理
├── 去噪:中值滤波(去除传感器噪声)
├── 增强:直方图均衡化(改善低光照)
└── 校正:透视变换(校正摄像头畸变)
↓
3. 目标检测(YOLOv8)
├── 检测人、车、异常物体
└── 输出边界框和置信度
↓
4. 目标跟踪(DeepSORT)
├── 关联连续帧中的同一目标
└── 分配唯一ID,计算运动轨迹
↓
5. 行为分析
├── 基于轨迹分析异常行为(徘徊、奔跑)
└── 基于目标交互分析群体行为
↓
6. 结果后处理
├── 形态学操作:平滑检测框
├── 非极大值抑制:去除重叠框
└── 时间一致性滤波:平滑跟踪结果
↓
7. 报警与可视化3.2 实际案例:医学影像分析流水线
1. 医学图像输入(CT/MRI)
↓
2. 预处理
├── 标准化:窗宽窗位调整
├── 去噪:各向异性扩散滤波
└── 增强:对比度受限自适应直方图均衡化
↓
3. 器官/病灶分割(U-Net)
├── 语义分割:分割肿瘤、器官
└── 实例分割:区分不同病灶实例
↓
4. 特征提取
├── 传统特征:形状、纹理、灰度特征
├── 深度学习特征:CNN中间层特征
└── 影像组学特征:高通量定量特征
↓
5. 分类/诊断
├── 分类模型:判断良恶性
└── 生存预测:预测患者预后
↓
6. 可视化与报告
├── 3D重建:器官/病灶三维可视化
└── 量化报告:自动生成诊断报告第四部分:算法选择指南与决策流程
面对一个视觉问题,如何选择正确的工具组合?遵循以下决策框架:
开始 → 明确视觉问题
└─ 这是低层处理问题还是高层理解问题?
├─ 低层处理 → 图像处理任务
│ └─ 具体需求?
│ ├─ 改善图像质量
│ │ └─ 增强与复原
│ │ └─ "高斯/中值滤波、直方图均衡化"
│ ├─ 提取兴趣区域
│ │ └─ 图像分割
│ │ └─ "Otsu阈值/Canny边缘、区域生长/分水岭"
│ ├─ 检测关键点/边缘
│ │ └─ 特征提取
│ │ └─ "SIFT/ORB特征、Harris角点检测"
│ ├─ 处理形状/结构
│ │ └─ 形态学操作
│ │ └─ "膨胀/腐蚀、开/闭运算"
│ └─ 对齐/变换图像
│ └─ 几何变换与配准
│ └─ "仿射/投影变换、特征匹配+RANSAC"
└─ 高层理解 → 计算机视觉任务
└─ 需要什么层次理解?
├─ 识别图片内容
│ └─ 图像分类
│ └─ "ResNet/EfficientNet、ViT/Swin Transformer"
├─ 定位并识别多个物体
│ └─ 目标检测
│ └─ "YOLO系列(实时)、Faster R-CNN(高精度)"
├─ 分析每个像素类别
│ └─ 语义分割
│ └─ "U-Net(医学)、DeepLab(通用)"
├─ 区分同类别不同个体
│ └─ 实例分割
│ └─ "Mask R-CNN(两阶段)、SOLO(单阶段)"
└─ 创造新图像
└─ 图像生成
└─ "扩散模型(高质量)、GAN(快速生成)"
└─ 考虑实际约束?
├─ 数据量少
│ └─ "使用预训练模型、数据增强、迁移学习"
├─ 实时性要求高
│ └─ "选择轻量模型、模型量化/剪枝、边缘部署优化"
├─ 精度要求高
│ └─ "使用更大模型、集成学习、更精细调参"
├─ 硬件资源有限
│ └─ "模型轻量化、知识蒸馏、选择效率高模型"
└─ 构建处理流水线,实验验证
└─ 部署与迭代优化4.1 工具选择的"黄金三角"权衡
精度 (Accuracy)
/\
/ \
/ \
/ \
/ \
速度 (Speed) ------ 资源 (Resource)- 精度优先:选择更大、更深的模型(如 ResNet-152、YOLOv8-X、Swin-Large)
- 速度优先:选择轻量级模型(如 MobileNet、YOLOv5s、NanoDet)
- 资源受限:考虑模型量化、知识蒸馏、边缘优化版本
4.2 数据驱动的工具选择策略
| 数据情况 | 推荐策略 | 可用工具 |
|---|---|---|
| 大量标注数据 | 从头训练大型模型 | ResNet、ViT、YOLO、U-Net 等完整训练 |
| 少量标注数据 | 迁移学习 + 微调 | 使用 ImageNet 预训练模型,在目标数据上微调 |
| 无标注数据 | 自监督学习/无监督学习 | SimCLR、MoCo(自监督);GAN、扩散模型(无监督生成) |
| 类别不平衡 | 重采样/重加权损失 | Focal Loss、Class-balanced 采样 |
| 多域数据 | 域适应/域泛化 | DANN、ADDA 等域适应方法 |
4.3 部署环境考量
| 部署平台 | 推荐工具链 | 优化策略 |
|---|---|---|
| 云端服务器 | PyTorch/TensorFlow → ONNX → TensorRT | 模型并行、批处理优化、动态批处理 |
| 移动端 | TensorFlow Lite、PyTorch Mobile、NCNN | 模型量化、操作融合、内存优化 |
| 嵌入式设备 | TensorRT、OpenVINO、TVM | 算子级优化、内存复用、低精度推理 |
| 浏览器端 | TensorFlow.js、ONNX.js、WebNN | 模型压缩、WebGL 加速、WASM 优化 |
| 边缘计算 | NVIDIA Jetson、RKNN、MediaPipe | 硬件感知优化、流水线并行、零拷贝传输 |
第五部分:技术演进全景与未来趋势
5.1 图像处理与计算机视觉技术演进时间线
演化主线:手工设计 → 机器学习 → 深度学习 → 大模型/多模态
· 1960s-1990s: 传统图像处理时代
- 基础算子:中值滤波(1971), Canny边缘检测(1986)
- 数学形态学、多尺度分析理论发展
· 1990s-2000s: 手工特征时代
- 局部特征:SIFT(1999), SURF(2006)
- 目标检测:Viola-Jones(2001), HOG(2005)
· 2012-2015: 深度学习革命初期
- 里程碑:AlexNet赢得ImageNet(2012)
- 架构创新:VGG(2014), GoogLeNet(2014)
- 任务拓展:R-CNN(检测, 2014), FCN(分割, 2015)
· 2016-2018: 深度学习成熟期
- 深度突破:ResNet(2016), DenseNet(2017)
- 实时检测:YOLO(2016), SSD(2016)
- 生成模型:GANs爆发(2014-2018)
- 实例分割:Mask R-CNN(2017)
· 2019-2021: 效率与Transformer时代
- 模型轻量化:MobileNet系列, EfficientNet
- Transformer进入CV:ViT(2020), DETR(2020)
- 自监督学习:MoCo, SimCLR
- 扩散模型兴起:DDPM(2020)
· 2022至今: 大模型与多模态时代
- 扩散模型爆发:Stable Diffusion(2022), DALL-E 2
- 视觉基础模型:SAM(分割一切, 2023)
- 多模态大模型:CLIP, BLIP, LLaVA
- 视频生成:Sora(2024)5.2 当前技术范式对比
| 技术范式 | 代表技术 | 核心思想 | 优势 | 局限 |
|---|---|---|---|---|
| 传统图像处理 | 滤波、边缘检测、形态学 | 基于数学模型和手工设计 | 可解释性强、计算高效、无需训练数据 | 泛化能力有限、需专业知识设计 |
| 经典机器学习 + 特征工程 | SIFT+HOG+SVM | 手工特征 + 传统分类器 | 小数据有效、特征可解释 | 特征设计复杂、性能瓶颈明显 |
| 深度学习(监督) | CNN、Transformer | 数据驱动、端到端学习 | 性能强大、自动特征学习 | 需要大量标注数据、计算资源大 |
| 自监督学习 | MoCo、MAE | 从无标注数据学习通用表示 | 减少标注依赖、学习通用特征 | 预训练计算成本高、下游任务仍需微调 |
| 生成模型 | GAN、扩散模型 | 学习数据分布并生成 | 创造新内容、数据增强 | 训练不稳定、评估困难、计算量大 |
| 多模态大模型 | CLIP、LLaVA | 跨模态联合学习 | 零样本/少样本能力强、通用性好 | 模型巨大、计算资源要求极高 |
5.3 未来趋势与工具箱演进
-
基础模型(Foundation Models)普及
- 视觉基础模型(如 SAM)将成为标准工具
- 通过提示(Prompting)适应各种下游任务
- 减少对任务特定模型的需求
-
多模态融合成为标配
- 视觉-语言-音频多模态统一表示
- 多任务统一模型架构
- 跨模态理解和生成能力
-
边缘智能与实时处理
- 轻量级基础模型
- 设备端学习与自适应
- 低功耗、高能效视觉芯片
-
神经渲染与 3D 视觉
- 神经辐射场(NeRF)技术成熟
- 3D 生成与理解
- 虚实融合的视觉系统
-
可信与可解释视觉
- 模型可解释性工具
- 公平性、鲁棒性保障
- 隐私保护的视觉计算
结语:构建面向未来的视觉智能工具箱
图像处理与计算机视觉的发展,从简单的手工算子到复杂的深度学习模型,再到如今的多模态基础模型,展现了一条清晰的技术演进路径。工具箱思维的核心价值在于:
- 系统性思考:理解视觉问题的层次性,从像素处理到语义理解
- 精准匹配:根据问题特性、数据条件、资源约束选择最合适的工具
- 灵活组合:将不同层次的工具组合成高效的处理流水线
- 持续进化:跟踪技术发展,不断更新和丰富自己的工具箱
未来的视觉智能系统将更加多层次、自适应、可解释:
- 多层次:从低层信号处理到高层语义理解的深度融合
- 自适应:能够根据环境、任务、数据自动调整处理策略
- 可解释:不仅给出结果,还能解释决策过程和依据
在这个快速发展的领域中,最宝贵的不是掌握某个具体工具,而是建立系统化的工具箱思维框架。这个框架能够帮助你在技术浪潮中保持方向感,在面对新问题时快速找到解决路径,在不断变化的技术环境中持续创造价值。
记住:真正的专家不是工具最多的人,而是最懂得为特定问题选择和组合工具的人。