技术栈
爬虫,如何查找一个网页的header请求头?
洛兮银儿
2026-03-18 8:51
以下以某网页为例子
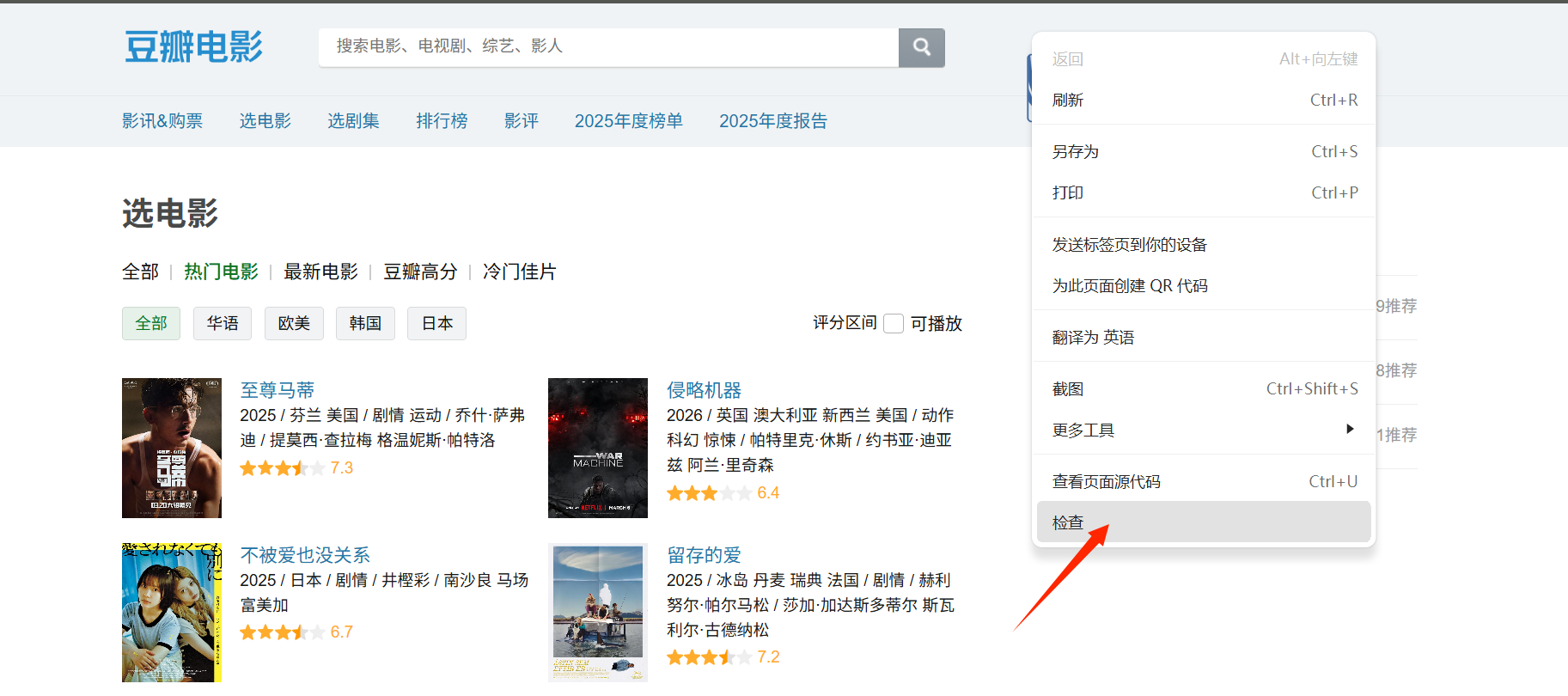
在网页右键,点击检查
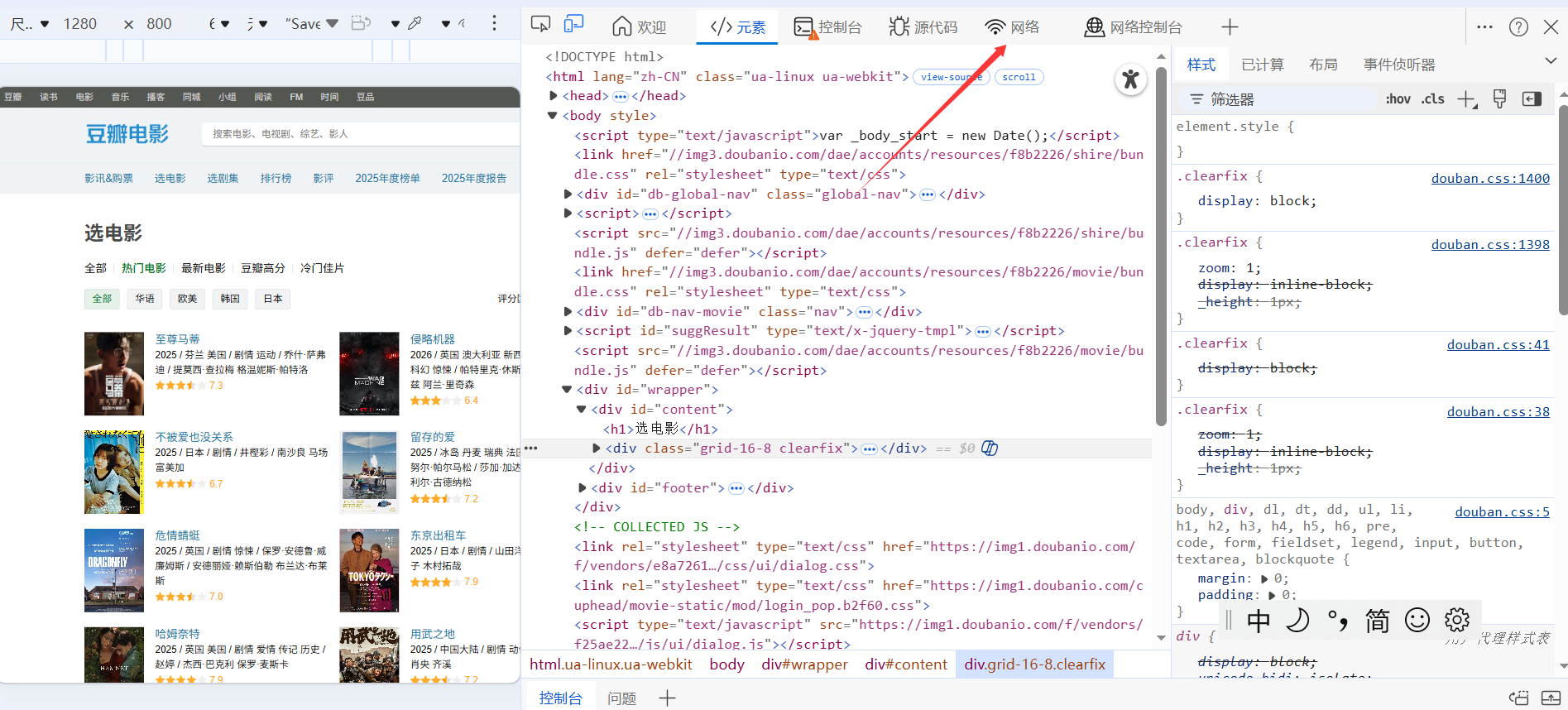
进入检查页面,找到网络,也叫network。
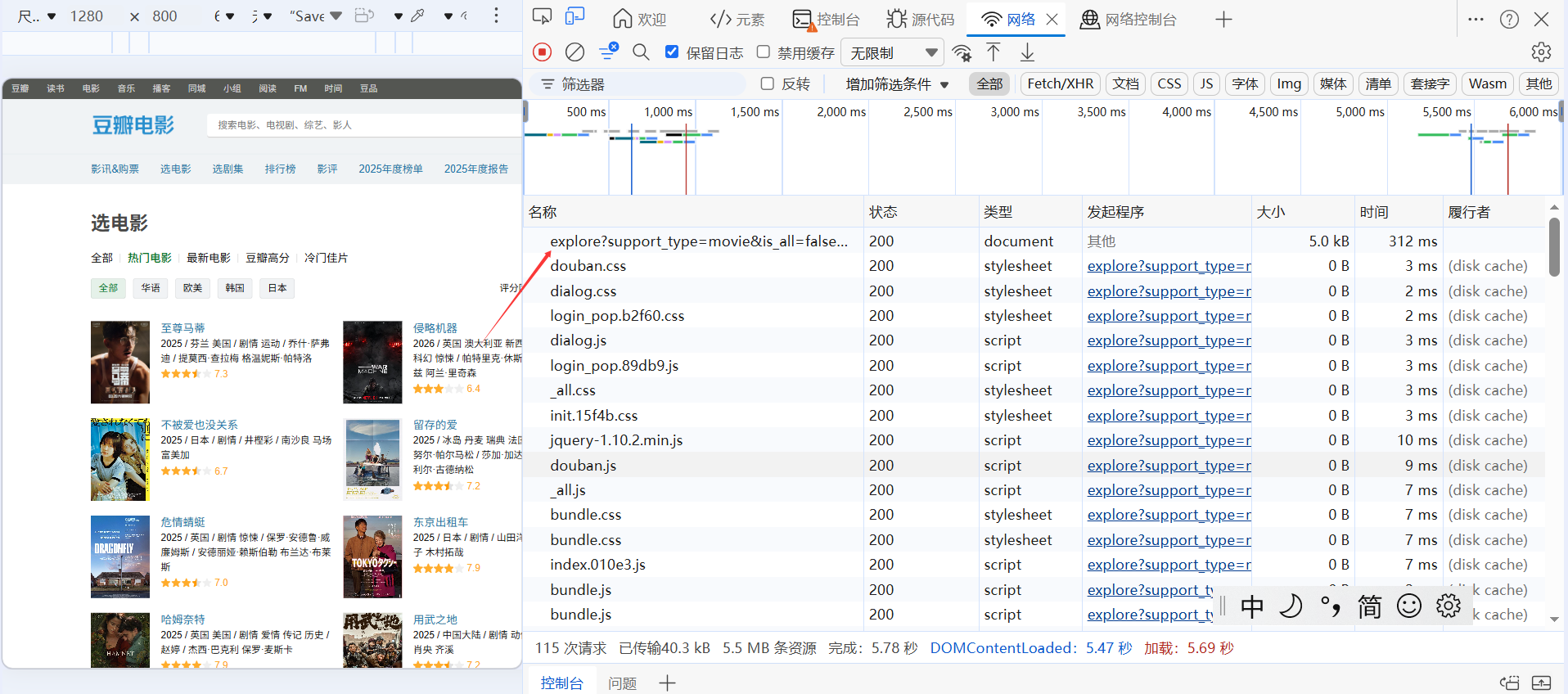
点击网络以后,键盘敲打ctrl+R,进入一个页面
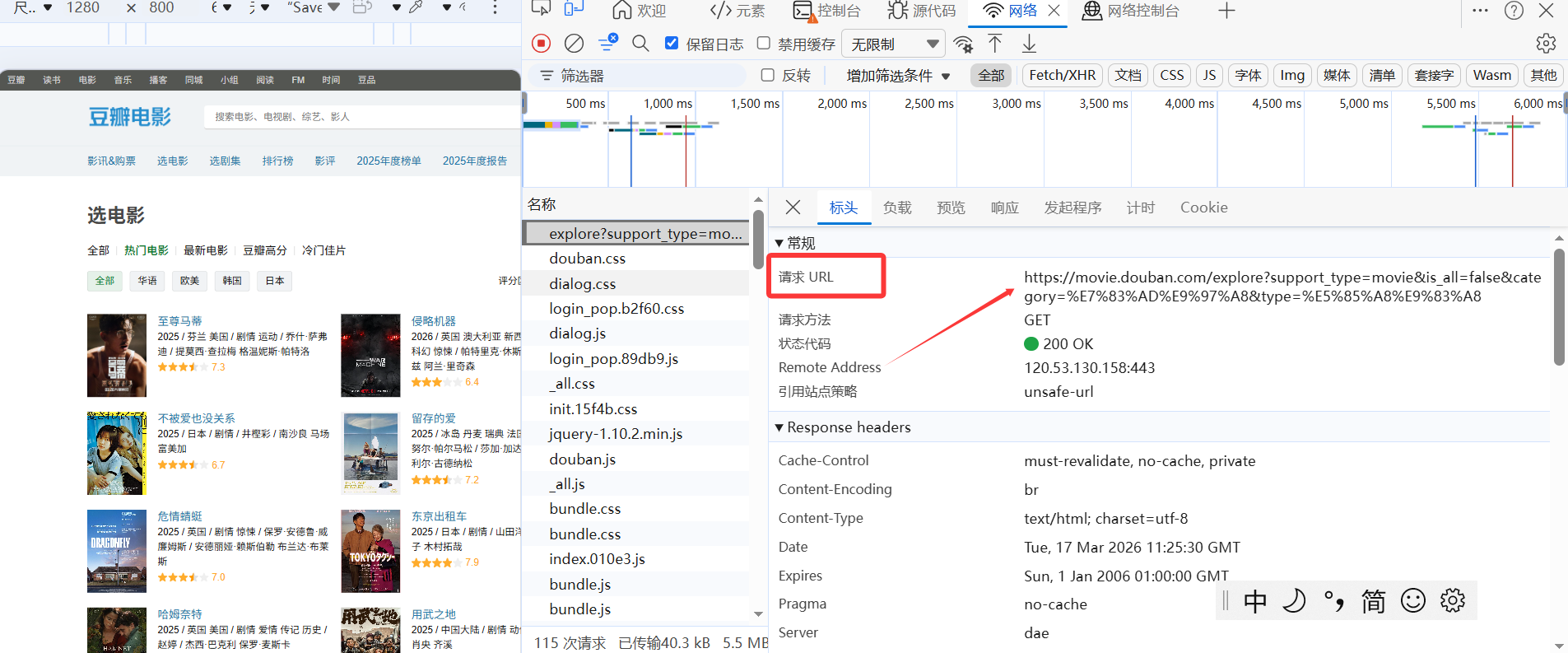
进入后会显示很多名称,一直往上滑,找到第一个名称,点击它,就会显示请求头URL了。
python
上一篇:
像摩尔线程和 沐曦科技怎么解决 nccl 通信问题
下一篇:
WaitableEvent 跨线程等待的死锁陷阱
相关推荐
小大宇
20 分钟前
python flask框架 SSE流式返回、跨域、报错
开发语言
·
python
·
flask
像风一样的男人@
33 分钟前
python --fastapi推流AI推理
人工智能
·
python
·
fastapi
2601_95631988
1 小时前
最新量化开发卡住,先查规则和流程是否完整
人工智能
·
python
小小代码狗
1 小时前
SQLi-Labs 基础注入实战教程(Less-1 ~ Less-5and Less-9)
服务器
·
python
·
php
nanawinona
2 小时前
2026年下半年量化学习,不同基础要查不同缺口
人工智能
·
python
CTA量化套保
2 小时前
最新量化表达入门,从概念规则到简单实现
人工智能
·
python
吃饱了得干活
3 小时前
别再手动解析 LLM 输出了!LangChain 四种结构化输出方案对比
后端
·
python
·
langchain
ikun_文
3 小时前
Python进阶—函数编程
python
·
pycharm
MC皮蛋侠客
3 小时前
uv 系列(三):依赖、锁文件与环境同步——可重复构建的核心
python
·
uv
热门推荐
01
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
02
GitHub 镜像站点
03
如何新建文件夹? 电脑新建文件夹的4种方法
04
AI科技热点日报 | 2026年07月01日
05
幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南
06
国内可直接用、免费额度/永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)
07
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
08
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
09
2026 年 AI 大模型 & AI 编程工具实战全总结
10
【解构】DeepSeek V4 发布:技术报告深度解读 + 横向对比六大开源模型,我们的判断是……