文章目录
- 缓冲区
- 磁盘
-
- 磁盘基本结构
- 为什么操作系统使用逻辑块
- 局部性原理
- [I/O 到磁盘的完整流程](#I/O 到磁盘的完整流程)
- [Linux 文件系统与 inode 机制](#Linux 文件系统与 inode 机制)
-
- Inode
-
- inode简介
- [inode 的多级索引结构](#inode 的多级索引结构)
-
- [inode 的数据块指针](#inode 的数据块指针)
- [直接块(Direct Block)](#直接块(Direct Block))
- 一级间接块
- 二级间接块
- 三级间接块
- [inode 索引结构总结](#inode 索引结构总结)
- [EXT4 文件系统结构](#EXT4 文件系统结构)
- SuperBlock(超级块)
- [Block Bitmap](#Block Bitmap)
- [inode Bitmap](#inode Bitmap)
- [inode Table](#inode Table)
- [Data Block](#Data Block)
- [EXT4 文件系统整体结构](#EXT4 文件系统整体结构)
- 文件
-
- 文件创建过程
- 文件读取流程
- [Linux 文件系统整体流程](#Linux 文件系统整体流程)
- Linux文件系统思想
- 粘滞位:
- 软硬链接
-
- [硬链接(Hard Link)](#硬链接(Hard Link))
- [软链接(Symbolic Link)](#软链接(Symbolic Link))
- 软硬链接对比
- Linux的三个时间
缓冲区
缓冲区问题
在 Linux 编程中,经常会遇到一个经典问题:
c
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char *fputsString = "hello fputs\n";
fputs(fputsString,stdout);
const char *wstring = "hello write\n";
write(1,wstring,strlen(wstring));
fork();
return 0;//C语言接口打印两次,缓冲区问题
}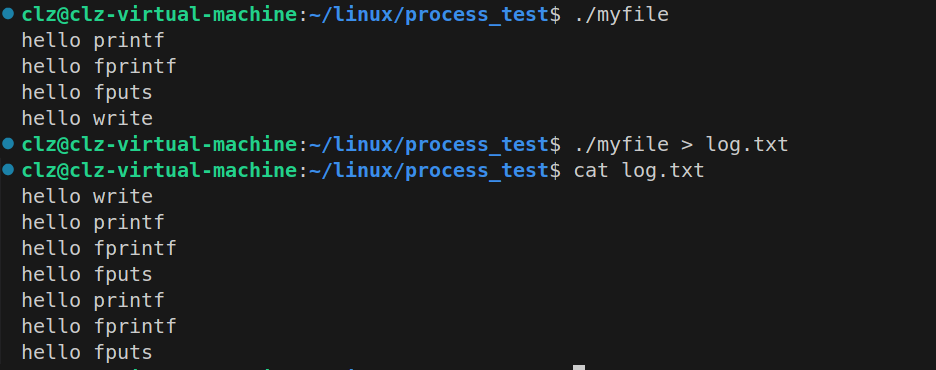
可以看到:
printf、fprintf、fputs 输出 两次
write 输出 一次
产生这个现象的核心原因是:I/O 缓冲区机制。
缓冲区概念
缓冲区本质上是 内存中的一块临时存储区域,用于在程序和外设之间暂存数据。
它的主要作用是:
减少慢速 I/O 设备带来的性能损耗,提高程序执行效率。
原因很简单:
| 设备 | 速度 |
|---|---|
| CPU / 内存 | 纳秒级 |
| 磁盘 / 终端 | 毫秒级 |
因此系统采用 缓冲区机制:
应用程序
↓
用户态缓冲区(stdio)
↓
系统调用 write()
↓
内核缓冲区
↓
设备(磁盘 / 终端)I/O区分
标准I/O缓冲区与系统调用I/O区别
Linux I/O 分为两层:
| 层级 | 接口示例 | 缓冲策略 | 属于谁 |
|---|---|---|---|
| 用户层缓冲 I/O | printf(), fprintf(), fputs() |
使用 FILE* 缓冲区(stdio 缓冲) |
C 库 |
| 内核层系统调用 I/O | write(), read() |
直接与内核交互,无用户态缓冲 | 内核 |
标准IO
C标准库I/O(printf、fprintf 、fputs)
这三个函数都属于标准库层
最终都会间接调用到系统调用(如write),但中间有一层缓冲机制
| 函数 | 所属层级 | 缓冲类型 | 说明 |
|---|---|---|---|
printf() |
标准输出 | 行缓冲 | 写到终端时,遇到换行符 \n 或 fflush() 才真正写出 |
fprintf(stdout, ...) |
标准输出 | 同上 | 只是显式指定 stdout |
fputs() |
标准输出 | 同上 | 不自动加 \n,但仍在缓冲区中 |
这些函数在用户态维护一个FILE缓冲区例如4KB 数据先写道缓冲区,再由标准库统一调用系统调用write()一次性写入内核,提高性能 |
|||
| 系统调用I/O |
c
write(1, wstring, strlen(wstring));这是真正的系统调用接口,直接陷入内核执行:
1->文件描述符,对应stdoutwstring->用户缓冲区地址strlen(wstring)->要写的字节数
执行流程:
- CPU通过系统调用号(
_NR_write)进入内核态 - 内核根据
fd(此处为1,即标准输出)找到对应的文件对象 - 调用底层驱动的
.write()实现(终端设备驱动) - 数据直接写入内核缓冲区或设备,不经用户态缓冲
- 没有缓冲机制,每次
write()都是一次系统调用
| 项目 | 标准库 I/O(printf 等) | 系统调用 I/O(write) |
|---|---|---|
| 层级 | 用户态 stdio 库 | 内核态 syscall |
| 缓冲 | 有(全缓冲 / 行缓冲) | 无缓冲 |
| 效率 | 高(合并多次写) | 低(每次陷入内核) |
| 控制粒度 | 由标准库控制 | 由程序员控制 |
| 文件描述符 | 隐藏(封装在 FILE*) | 显式(int fd) |
| 所以总体过程为 |
用户程序
↓
C 标准库(libc)
↓
系统调用接口(sys_write)
↓
内核文件系统 & 驱动
fwrite->将数据从进程拷贝到缓冲区中系统调用 I/O
例如:
write(fd, buf, size);特点:
没有 stdio 缓冲
直接进入内核
执行流程:
用户程序
↓
write()
↓
进入内核
↓
设备驱动
↓
输出设备因此:
write() 每调用一次,就会触发一次系统调用。
为什么会存在printf不立即输出的问题?
printf()并不会立即调用write()
它先把数据写入用户态缓冲区(由libc)管理,只有以下情况才会刷新到内核:
- 缓冲区满
- 输出流遇到换行符(行缓冲)
- 显式调用
fflush - 程序正常退出(自动刷新)
举例:
c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// C接口
printf("hello printf\n");
fprintf(stdout, "hellp fprintf\n");
const char *fputsString = "hello fputs\n";
fputs(fputsString, stdout);
// 系统接口
const char *wstring = "hello write\n";
write(1, wstring, strlen(wstring));
//代码结束之前,进行创建子进程
//1. 如果我们没有进行>,看到了4条消息
// stdout 默认使用的是行刷新,在进程fork之前,三条C函数已经将数据进行打印输出到显示器上(外设),你的FILE内部,进程内部不存在对应的数据啦
//2. 如果我们进行了>, 写入文件不再是显示器,而是普通文件,采用的刷新策略是全缓冲,之前的3条c显示函数,虽然带了\n,但是不足以stdout缓冲区写满!数据并没有被刷新!!!
//执行fork的时候,stdout属于父进程,创建子进程时, 紧接着就是进程退出!谁先退出,一定要进行缓冲区刷新(就是修改)
//写时拷贝!!数据最终会显示两份
//3. write为什么没有呢?上面的过程都和wirte无关,wirte没有FILE,而用的是fd,就没有C提供的缓冲区
fork(); // fork
return 0;
}示例分析:
printf
c
printf("hello printf\n");
流程:
printf() 被调用
↓
格式化字符串内容(如 %d, %s 等处理)
↓
将生成的字符串写入 stdout 的缓冲区(FILE* 结构体内的缓冲区)
↓
发现字符串中包含换行符 \n(且输出目标是终端)
→ 触发 行缓冲刷新
↓
调用 write(1, buf, len)(真正的系统调用)
↓
内核根据文件描述符 1(stdout)找到对应终端设备
↓
将数据交给终端驱动程序显示在屏幕上fprintf
c
fprintf(stdout, "hellp fprintf\n");
流程几乎相同,只是显式指定输出流:
fprintf(stdout, ...)
↓
数据写入 stdout 的缓冲区
↓
检查是否该刷新(含 \n 或调用 fflush())
↓
若刷新 → 调用 write(1, buf, len)
↓
内核写入终端设备
区别:
fprintf() 允许你选择输出流,比如 stderr、文件等,不限于标准输出。fputs
c
fputs("hello fputs\n", stdout);
流程:
将字符串直接拷贝进 stdout 缓冲区(不会自动加 \n)
↓
若输出流为终端并且字符串中含 \n → 行缓冲触发刷新
↓
调用 write(1, buf, len)
↓
内核写入终端设备
注意:
fputs() 不会自动在结尾加换行符,不加 \n 时数据可能仍停留在用户缓冲区中。write
c
write(1, "hello write\n", 12);
流程(系统调用路径):
用户调用 write()
↓
进入内核(系统调用号 __NR_write)
↓
内核函数:
c
sys_write(fd, buf, count)
{
struct file *file = current->files->fd[fd];
return file->f_op->write(file, buf, count, &file->f_pos);
}↓
根据文件描述符 1 找到文件对象(终端)
↓
调用终端驱动的 .write() 函数
↓
设备驱动将数据送到显示缓冲区,终端显示内容
特点:
直接进入内核,无任何用户态缓冲;
写完立即生效。fwrite
c
fwrite(buf, 1, len, fp);fwrite()的作用是:把数据从用户进程拷贝到内核缓冲区
真正写入磁盘的操作:
- 缓冲区满
- 程序调用
fflush() - 文件关闭
fclose() - 系统周期性刷新时
缓冲区的意义:
缓冲区的核心作用:节省时间,提高效率
| 术语 | 含义 |
|---|---|
| 缓冲区(Buffer) | 位于内存中的一块暂存区,用于存放等待输入或输出的数据 |
| 缓冲I/O(Buffered I/O) | 程序与设备之间通过缓冲区进行间接通信的I/O模式 |
| 非缓冲I/O(Unbuffered I/O) | 程序直接与设备交互,不经过缓冲区,速度慢但及时 |
fwrite() |
将数据从用户空间拷贝到内核缓冲区 |
fflush() |
强制把缓冲区的数据写入磁盘 |
fread() |
从内核缓冲区读取数据到用户内存 |
write() 系统调用 |
直接进入内核态执行I/O(不经过C库缓冲) |
| 缓冲区的存在是为了在快的内存和慢的外设之间架起桥梁 | |
| 它让CPU不必一直等待慢速磁盘的回应,提高程序的执行效率 |
缓冲区刷新策略:
外设的I/O速度远慢于内存
一次I/O调用的"等待时间"通常比"传输时间"长的多
所以:
- 一次性写大块数据(批量)比多次写小块数据效率高的多
- 因此缓冲区会"攒一攒",等积累到一定量再一次性写入磁盘
两种特殊刷新时机:
- 手动刷新
- 程序员主动调用
fflush(fp)
- 程序员主动调用
- 系统触发刷新
- 程序正常关闭(
fclose(fp)) - 程序异常结束(可能丢失未刷数据)
- 缓冲区被新数据填满
缓冲区刷新策略的三种主要类型:
- 程序正常关闭(
| 策略名称 | 类比(顺丰故事) | 行为描述 | 应用场景 |
|---|---|---|---|
| 无缓冲(Unbuffered I/O) | 顺丰为你一个键盘开飞机 | 每次 fwrite() 都立刻写入外设 |
系统级日志、关键安全数据 |
| 行缓冲(Line Buffered) | 顺丰每装满一箱(或每行)就发 | 以"行结束符"(\n)为界触发刷新 |
终端输入输出(如 stdout) |
| 全缓冲(Fully Buffered) | 顺丰装满整车货才发 | 缓冲区满时才写入外设 | 普通文件写入(FILE* fp 默认) |
| 无缓冲: | |||
| 数据一旦写入缓冲,就会立即输出到外设,不经过任何延迟或积累 | |||
| 特点: |
- 几乎实时刷新
- 开销较大(频繁I/O调用)
- 通常用于用户交互类设备
标准错误流stderr默认是无缓冲的,希望错误信息立即显示
行缓冲
当输出数据遇到换行符\n,或者缓冲被填满时,系统才将缓冲区的数据刷新到设备
特点: - 兼顾性能与交互体验
- 适合"面向人阅读"的输出设备(如显示器)
- 用户可手动调用
fflush(stdout)进行强制刷新
在实现进度条时,如果 printf 语句没有带换行符,则输出不会立即显示,除非显式调用:
c
fflush(stdout);这说明标准输出设备(stdout)通常采用行缓冲策略。
全缓冲策略:
只有当缓冲区被完全填满时,系统才会将数据一次性写入外设
特点:
- 效率最高:仅在缓冲区满时执行一次 I/O
- 适合非交互式设备,如磁盘文件、网络套接字
- 适合批量数据写入场景
c
FILE *fp = fopen("data.txt", "w");
fprintf(fp, "Hello, world!");
// 数据暂存在缓冲区,未必立即写入磁盘
fclose(fp); // 或 fflush(fp) 后,数据才真正写入文件总体逻辑图:
应用层数据
↓
缓冲区
↓
刷新策略决定何时写入外设
↓
外设(显示器 / 文件 / 网络)语言级缓冲区:
- 由C语言标准I/O库提供,用于暂存应用程序输出数据,提高I/O效率
属于用户态内存空间,由库函数自行管理 - 系统级缓冲区
属于操作系统内核,负责在设备驱动层次进一步缓存数据
FILE结构体
FILE结构体详解
C标准库缓冲区的真正位置
在C标准库中,所有通过标准I/O接口(如printf,fprintf())等进行的操作,实际是通过一个名为FILE的结构体对象完成的
FILE结构体的定义
c
typedef struct _IO_FILE {
int _fileno; // 文件描述符,对应内核级文件
char *_IO_buf_base; // 缓冲区起始地址
char *_IO_buf_end; // 缓冲区结束地址
char *_IO_write_ptr; // 当前写指针
char *_IO_read_ptr; // 当前读指针
// ... 其他标志位与状态信息
} FILE;说明:
FILE结构体封装了底层的文件描述符(fd)以及一块用户态缓冲区- 这块缓冲区正是缓冲区刷新策略所作用的区域
- 对应
FILE指针(例如stdout,stdin,stderr)即是指向这些结构体的指针
缓冲区的刷新和管理策略:
C语言库会根据设备类型自动选择缓冲策略(即setvbuf的默认策略)
| 设备类型 | 默认缓冲模式 | 说明 |
|---|---|---|
| 标准输入(键盘) | 行缓冲 | 输入每行结束刷新 |
| 标准输出(显示器) | 行缓冲 | 输出带换行符或缓冲满时刷新 |
| 标准错误(stderr) | 无缓冲 | 错误信息即时输出 |
| 文件(磁盘) | 全缓冲 | 缓冲区写满或关闭文件时刷新 |
| 刷新行为出发的典型情况包括: |
- 缓冲区满
- 输出遇到换行符(行缓冲)
- 调用`fflush(FILE *stream)
- 调用
fclose(FILE *stream)(会隐式调用fflush) - 程序正常结束(运行时库会清空所有缓冲区)
特殊情况:
- 用户强制刷新
c
fflush(stdout)即为用户强制刷新缓冲区,此时不论缓冲策略为何,数据都会被立即送入内核
- 程序或进程退出时刷新
当进程正常结束时,C 语言运行时会自动调用清理函数,将所有仍在缓冲区中的数据刷新到目标设备。
fork()导致输出重复问题
若程序在 printf 输出后但尚未 fflush 时执行 fork(),子进程会复制父进程的用户态缓冲区。于是父子进程都持有相同的缓冲数据,且各自执行 fflush 或进程退出时都会输出一次,从而造成输出重复。
结论:
此现象证明缓冲区位于用户态内存中(即进程私有空间),若缓冲区在内核中,fork 后不会被复制,也不会导致重复输出。
FILE与缓冲区的联系
所有标准I/O操作都必须通过FILE指针进行,因为:
- FILE 结构体中包含了缓冲区的指针;
- 只有通过 FILE*,库函数才能定位到对应缓冲区;
- 当执行
fflush(FILE *fp)或fclose(FILE *fp)时,系统才能正确刷新对应的缓冲区内容。
c
FILE *fp = fopen("data.txt", "w");
fprintf(fp, "Buffered Output\n");
fflush(fp); // 强制刷新
fclose(fp); // 关闭文件并刷新缓冲区缓冲区位置与层次图
┌────────────────────────────┐
│ 用户空间 (User Space
│ ┌──────────────────────────┐
│ │ C 标准库 FILE 结构体缓冲区
│ │ (语言级缓冲区)
│ └──────────────┬───────────┘
│ │ write()/read() 调用
└────────────────┼────────────────────
▼
┌────────────────────────────┐
│ 内核空间 (Kernel Space)
│ ┌──────────────────────────┐
│ │ 内核 I/O 缓冲区(页缓存、设备队列)
│ └──────────────────────────┘
└────────────────────────────┘!\[Pasted image 20251116212126.png]
如果一个文件没有被打开->在磁盘上放着->磁盘上有大量的文件,也必须被静态管理,方便我们随时打开->文件系统
磁盘
磁盘基本结构
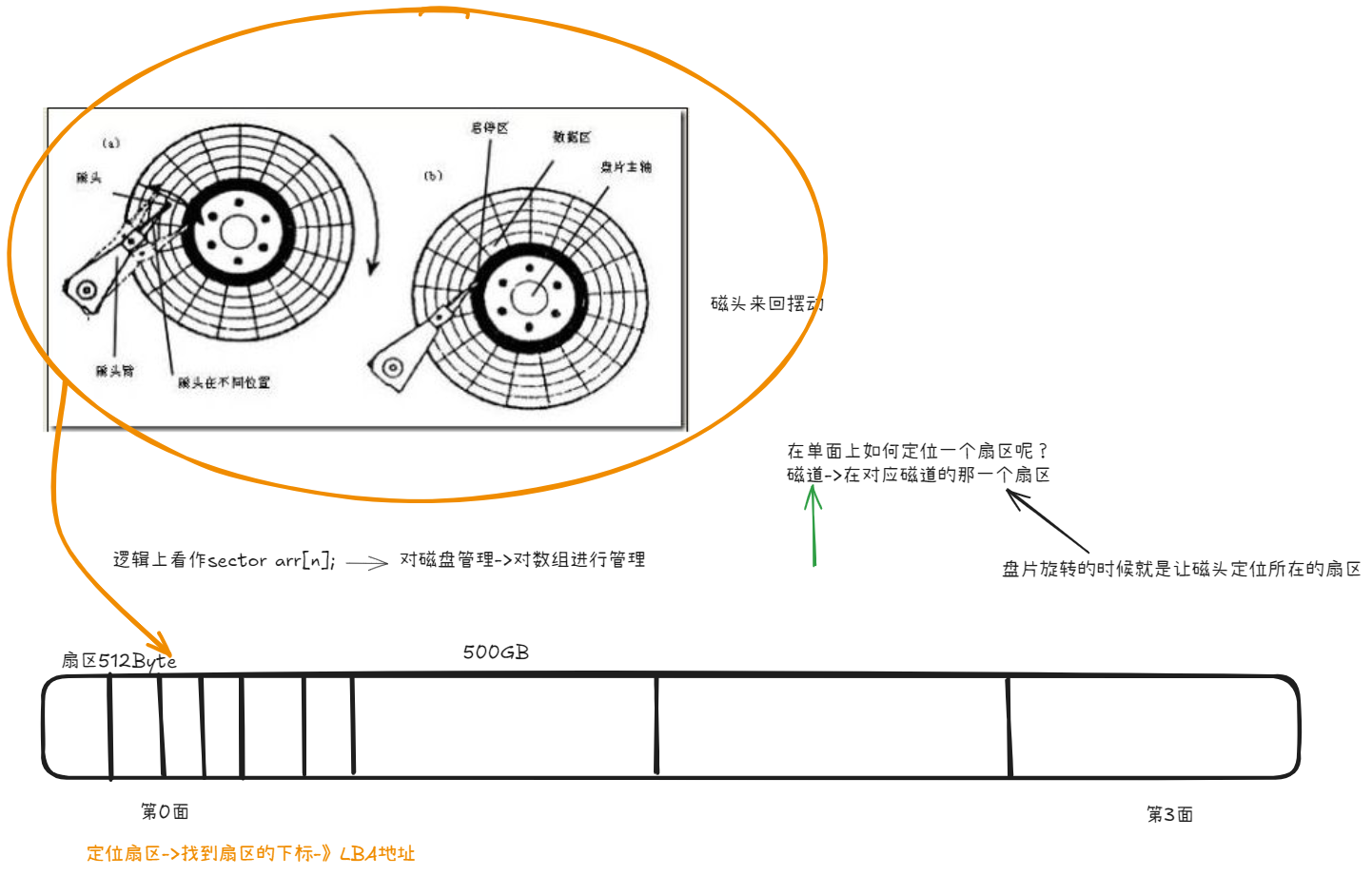
盘面:4
磁道/面:10
扇区/磁道:100
扇区:521Byte
4*10*100*512==总容量
4*10*100=下标范围
10*100=1000扇区 每一面
LBA:123号位置
123/1000 = 0--0号盘面
123/100=1 --1号磁道
123%100 = 23--23号扇区
为什么操作系统使用逻辑块
虽然磁盘最小单位是:
512B
但操作系统通常使用:
4KB block
原因:
- 提高 I/O 效率
- 减少磁盘寻址
- 利用局部性原理
- 便于管理
- 不想让os的代码和硬件强耦合
因此文件系统读写通常是:
4KB
虽然对应的磁盘访问的基本单位是512字节,但是依旧很小->OS内的文件系统定制的多个扇区的读写->1KB,2KB,4KB为基本单位,哪怕指向读取或修改bit,也必须将4KBload内存,进行读取或者修改,如果必要再写回磁盘
局部性原理
(4GB)内存是被划分成了4KB大小的空间 - 页框
磁盘中的文件尤其是可执行文件-按照4KB大小划分好的块--页帧
分组
I/O 到磁盘的完整流程
整个过程如下:
用户程序
↓
printf
↓
stdio buffer
↓
write()
↓
内核 page cache
↓
文件系统
↓
inode
↓
data block
↓
磁盘Linux 文件系统与 inode 机制
当程序执行 write() 时,数据并不是直接写入磁盘,而是交给 文件系统 管理。
Linux 文件由两部分组成:
文件 = 文件属性 + 文件内容
在 Linux 文件系统中:
| 部分 | 存储位置 |
|---|---|
| 文件属性 | inode |
| 文件数据 | data block |
Inode
inode简介
inode(index node) 是文件的元数据结构。
每个文件都有一个 inode。
inode 保存:
- 文件大小
- 文件权限
- 所有者
- 时间戳
- 数据块指针
例如:
bash
ls -i file.txt输出:
bash
23456 file.txt其中 123456 就是 inode 号。
inode 的多级索引结构
文件 = inode + data block
inode 记录文件属性,同时保存 数据块的位置 。
但是一个问题出现了:
如果文件很大,一个 inode 如何记录大量数据块?
Linux 采用 多级索引结构。
inode 的数据块指针
在 Linux(EXT 系列文件系统)中,一个 inode 内通常包含 15 个指针:
inode
│
├── 12 个直接块指针
├── 1 个一级间接块
├── 1 个二级间接块
└── 1 个三级间接块示意:
node
│
├─ direct[0]
├─ direct[1]
├─ direct[2]
...
├─ direct[11]
│
├─ single indirect
│
├─ double indirect
│
└─ triple indirect直接块(Direct Block)
前 12 个指针直接指向数据块:
inode
├── block0
├── block1
├── block2
...
└── block11如果每个 block 是:
4KB
那么:
12 × 4KB = 48KB
小文件可以直接访问,非常快。
一级间接块
如果文件超过 48KB,就会使用 一级间接块。
inode
│
└── single indirect
│
├── block
├── block
├── block一级间接块本身是一个 数据块 ,里面存放 大量数据块地址 。
假设:
block = 4KB
地址大小 = 4B
一个块可以存:
4096 / 4 = 1024 个地址
因此一级间接块可以管理:
1024 × 4KB ≈ 4MB
二级间接块
如果文件继续变大:
inode
│
└── double indirect
│
├── 一级索引块
│ ├── 数据块
│
├── 一级索引块容量:
1024 × 1024 × 4KB
≈ 4GB
三级间接块
最后是三级索引:
inode
│
└── triple indirect
│
└── 二级索引块
│
└── 一级索引块
│
└── 数据块容量:
1024 × 1024 × 1024 × 4KB
≈ 4TB
inode 索引结构总结
| 类型 | 容量 |
|---|---|
| 12直接块 | 48KB |
| 一级间接块 | 4MB |
| 二级间接块 | 4GB |
| 三级间接块 | 4TB |
这样 Linux 就能 同时兼顾小文件效率和大文件扩展能力。
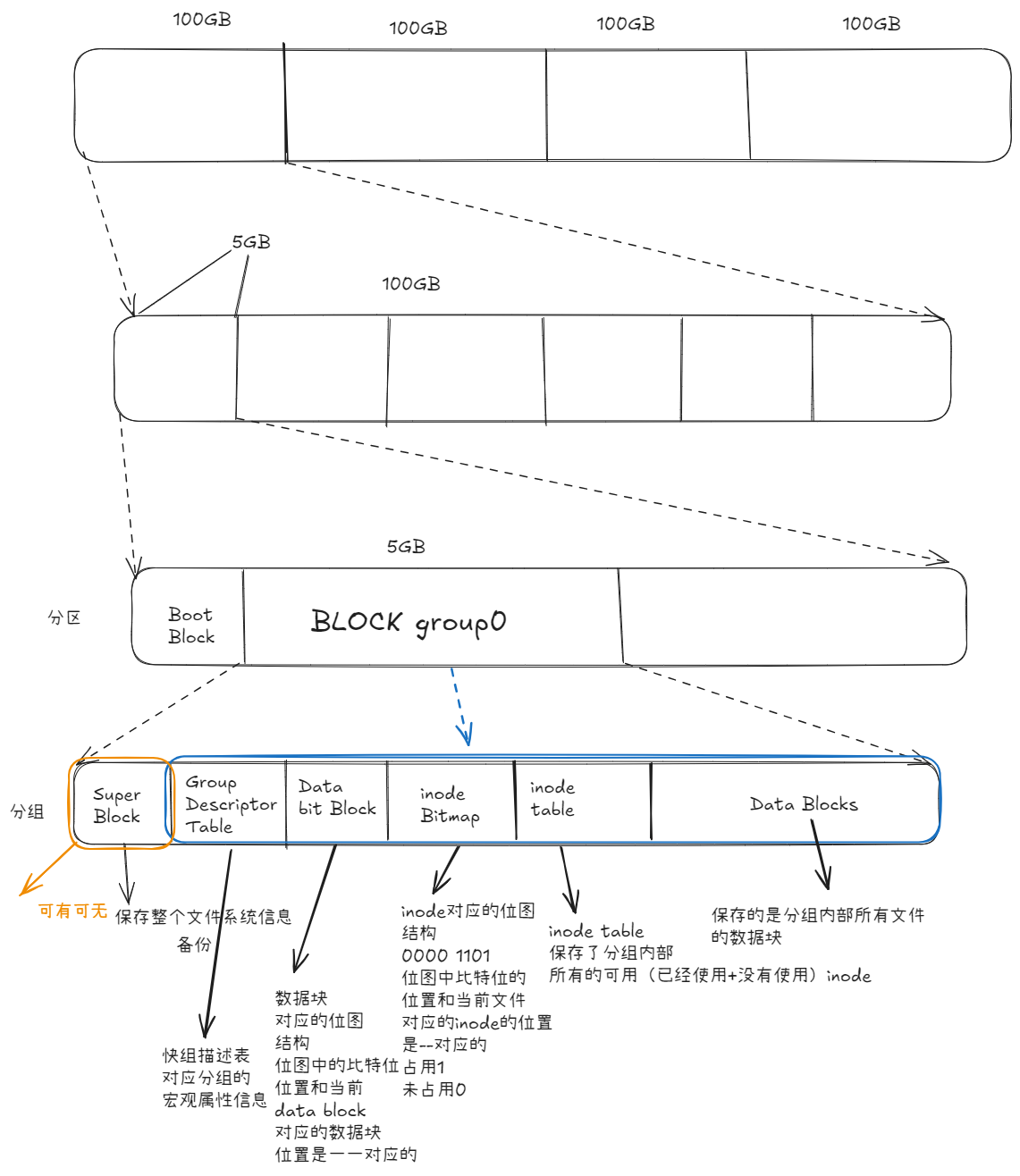
EXT4 文件系统结构
当磁盘被格式化为 Linux 文件系统(如 EXT4)时,会被组织成如下结构:
磁盘
│
├── Super Block
├── Group Descriptor
├── Block Bitmap
├── inode Bitmap
├── inode Table
└── Data BlocksSuperBlock(超级块)
超级块是文件系统最重要的结构。
它保存:
- 文件系统大小
- block 大小
- inode 数量
- 空闲块数量
- 挂载信息
可以查看:
bash
dumpe2fs /dev/sda1Block Bitmap
Block Bitmap 用来管理 哪些数据块被使用 。
例如:
1 = 已使用
0 = 空闲
示例:
Block Bitmap
1 1 1 0 0 0 1 1表示:
block3
block4
block5
可用
inode Bitmap
inode 也需要管理:
inode Bitmap
例如:
inode1 已使用
inode2 已使用
inode3 空闲
inode Table
inode Table 存放 所有 inode 结构体:
inode table
inode1
inode2
inode3 每个 inode 对应一个文件。
Data Block
数据块存放:
文件内容
例如:
data block
Hello Linux
EXT4 文件系统整体结构
完整结构:
磁盘
│
├── SuperBlock
│
├── Block Bitmap
│
├── inode Bitmap
│
├── inode Table
│
└── Data Blocks示意:
+-------------------+
| Super Block |
+-------------------+
| Block Bitmap |
+-------------------+
| inode Bitmap |
+-------------------+
| inode Table |
+-------------------+
| Data Blocks |
+-------------------+文件
文件=文件+属性
Linux的文件属性和文件内容是分批存储的
文件属性:Inode是固定大小
一个文件一个Inode-》文件几乎所有的属性
文件名不在Inode中存储
文件内容:data block
随着应用类型变化-》大小在变化
inode为了区分彼此,每一个inode都有自己的id
目录创建文件:
很多人误以为文件名存在 inode 中。
实际上:
文件名存储在目录中,而不是 inode 中。
目录本质是一个特殊文件。
目录内容:
文件名 → inode号
示例:
bash
file.txt → inode 123456因此:
路径解析
↓
找到 inode
↓
读取数据块文件创建过程
当执行:
bash
touch file.txtLinux 实际做了以下事情:
-
分配 inode
-
更新 inode bitmap
-
在目录中添加
-
文件名 → inode
流程:目录
│
└── file.txt → inode123
文件读取流程
当程序读取文件:
bash
open("file.txt")执行流程:
路径解析
↓
找到 inode
↓
读取 inode
↓
找到 data block
↓
读取数据完整流程:
程序
↓
VFS
↓
inode
↓
data block
↓
磁盘Linux 文件系统整体流程
最终我们可以把整个链路串起来:
程序
↓
printf
↓
stdio buffer
↓
write
↓
VFS
↓
inode
↓
data block
↓
磁盘扇区Linux 文件系统设计遵循三个核心思想:
-
抽象
磁盘被抽象为:文件 -
分离
文件被拆分为:
inode(属性)
data block(数据) -
引用计数
删除文件机制:clink count类似:
C++ shared_ptr
Linux文件系统思想
Linux 文件系统可以用一句话总结:
文件名只是 inode 的映射,真正的数据存储在 data block 中。
完整流程:
程序
↓
stdio
↓
write
↓
文件系统
↓
inode
↓
data block
↓
磁盘粘滞位:
在所有人都可共享的文件夹
在一个目录删除文件->跟这个文件目录是否具有写权限有关
粘滞位:是所有可以自由的写入文件目录,而限制人的删除权限
软硬链接
Linux 支持两种链接:
硬链接
软链接
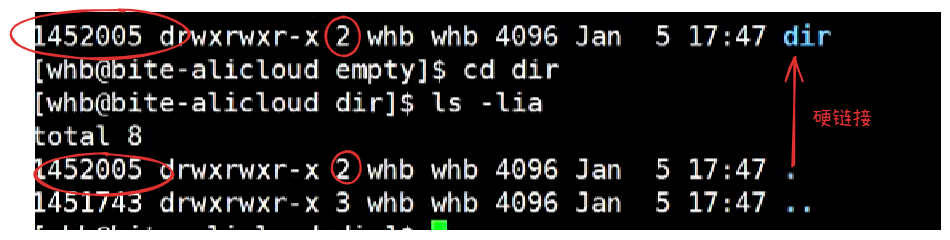
硬链接(Hard Link)
硬链接的理解
硬链接没有独立的inode-如何理解硬链接
建立一个硬链接具体做了什么?
建立硬链接根本没有创建文件,因为没有给硬链接分配独立的inode
没有创建文件-》无属性和内容集合-》别人的inode和内容
因此硬链接本质就是:在指定的文件路径下新增文件名和inode编号的映射关系
inode引用计数->硬链接数->只有有一个链接到inode->引用计数-1->shared_ptr
创建硬链接:
bash
ln file.txt file2.txt此时:
bash
file.txt → inode123
file2.txt → inode123两者 共享同一个 inode 。
示意:
file.txt
\
→ inode
/
file2.txt特点:
- 没有新 inode
- 只是新增目录映射
- 数据完全共享
硬链接删除原理
什么时候一个文件算被真正的删除呢?
当一个文件的硬链接数变成0的时候->才算被真正删除
!\[Pasted image 20251212203855.png]
删除文件时:
bash
rm file.txt实际上只是:
inode 引用计数 -1
只有当:
link count = 0文件才真正删除。
这类似于:
C++ shared_ptr
为什么目录不能创建硬链接
Linux 禁止普通用户给目录创建硬链接。
原因是:
防止目录结构出现循环。
例如:
dirA
└── dirB如果允许:
bash
ln dirA dirA/sub会变成:
dirA
└── sub → dirA形成无限循环:
dirA/sub/sub/sub/sub...这会破坏文件系统。

Linux 禁止对目录创建硬链接,就是为了防止用户把目录硬链接到它的父目录或更上层,从而造成循环结构,破坏整个文件系统的稳定性。
为什么创建的普通文件的硬链接数为1呢?
一个普通关系,本身有一个文件和自己的inode具有一个映射关系
创建一个空目录,为什么目录的硬链接数为2?
目录建立目录-》引用计数增加的根本原因
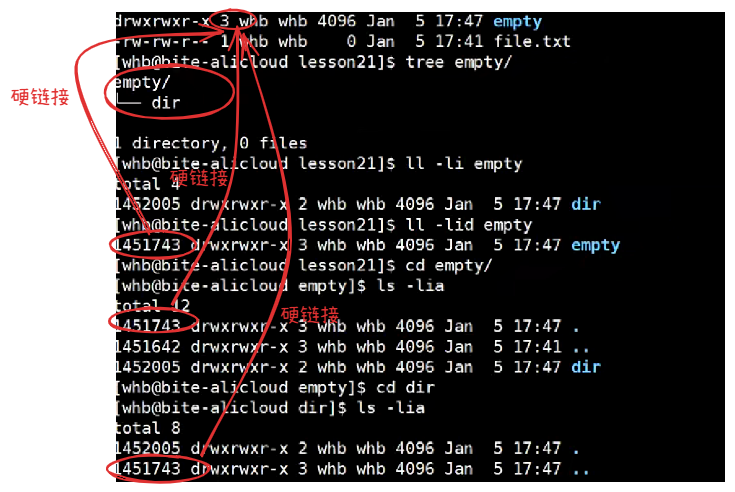
软链接(Symbolic Link)
软链接的理解
软链接本质是它的数据块保存它所指向的目标文件的路径,他是独立文件独立inode
相当于windows的快捷方式
创建软链接:
bash
ln -s file.txt link.txt此时:
link.txt → inode456
inode456 内部存储:file.txt 的路径
示意:
link.txt
↓
"file.txt"
↓
inode123软链接类似于:
Windows 快捷方式
特点:
- 有独立 inode
- 存储目标路径
- 可以跨文件系统
软硬链接对比
| 特性 | 硬链接 | 软链接 |
|---|---|---|
| inode | 共享 | 独立 |
| 跨文件系统 | 不支持 | 支持 |
| 删除原文件 | 仍可访问 | 失效 |
| 本质 | inode映射 | 路径引用 |
| 软硬链接的区别:是否具有独立的inode | ||
| 软链接具有独立的inode-可以被当作独立文件看待 |
Linux的三个时间
change time:文件属性修改的最近时间
modify time:文件内容改变的时间-》会引起chang time改变
access time:文件内容最近被访问的时间-》只有时间到一定时间刷新-》才会更改