开篇介绍:
hello 大家,这篇博客我们将继续介绍Linux系统的基础指令,话不多说,我们开始。
rmdir指令 和 rm指令:
rmdir指令:
rmdir 是 Linux 中专门用于删除空目录 的命令,与创建目录的 mkdir 功能对应,语法简单且核心功能明确:
一、核心功能与语法
- 功能:仅删除空目录(目录内无任何文件或子目录,仅含
.和..隐藏引用),若目录非空则报错。 - 语法:
rmdir [-p] [dirName]dirName:指定要删除的目录(可填绝对路径或相对路径)。- 无选项时,仅删除单个空目录。
二、常用选项 -p:递归删除空父目录
- 作用 :删除指定空目录后,若其父目录也变为空目录,则自动连带删除该父目录,依次向上递归。
- 示例 :
- 先创建多级空目录:
mkdir -p a/b/c(a 包含 b,b 包含 c,均为空); - 直接删 c:
rmdir a/b/c→ 仅删除 c,a/b 仍为空目录; - 用
-p删 c:rmdir -p a/b/c→ 先删 c,发现 b 变空则删 b,再发现 a 变空则删 a,最终 a、b、c 均被删除。
- 先创建多级空目录:
三、注意事项
- 无法删除非空目录:若目录内有文件或子目录,执行
rmdir会提示 "目录非空",需先清空目录内容(用rm命令)再删除。 - 需权限:删除目录需具备该目录及其父目录的 "执行 + 写入" 权限,否则提示权限不足。
rmdir 适合精准删除空目录,尤其 -p 选项在清理多级空目录时很高效,避免手动逐级删除的繁琐。这个其实用的比较少,我们一般是用rm指令。
rm指令:
rm 是 Linux 系统中用于删除文件或目录的核心命令,功能强大rmdir更灵活(rmdir仅能删除空目录),可直接处理文件和非空目录,是日常操作和脚本编写中高频使用的工具。以下从功能、选项、示例及注意事项展开详细说明:
一、核心功能与语法
- 核心功能:删除指定的文件或目录(包括非空目录,需配合选项)。
- 语法:
rm [-f -i -r -v] [目标文件/目录][目标文件/目录]:可指定单个或多个文件 / 目录(用空格分隔),支持绝对路径、相对路径或通配符(如*.txt删除所有 txt 文件)。
二、常用选项及实战示例
1. 基础用法:删除文件
不添加选项时,rm 可直接删除普通文件,但对只读文件(权限为 -r--r--r--)会提示确认,对目录则报错(需配合 -r 选项),即不能直接使用rm去删除目录,哪怕是空目录。
下面是我们要直接使用rm去删除music这个空目录: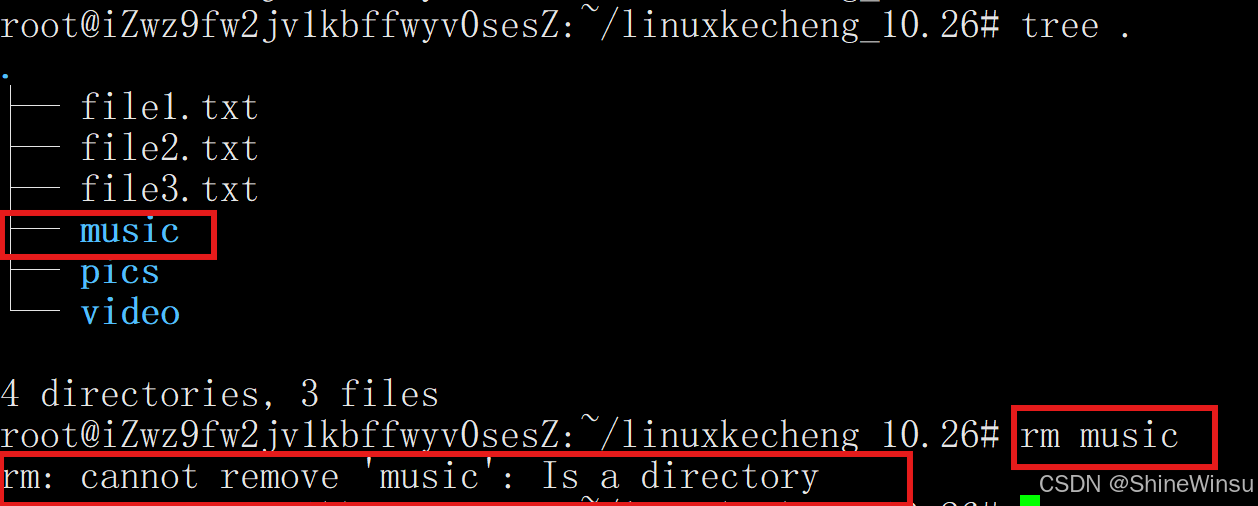 可以看到,是不行的
可以看到,是不行的
# 删除单个文件
rm file.txt
# 删除多个文件(用空格分隔)
rm note1.txt note2.pdf image.png
# 用通配符删除一类文件(如所有.log文件)
rm *.log 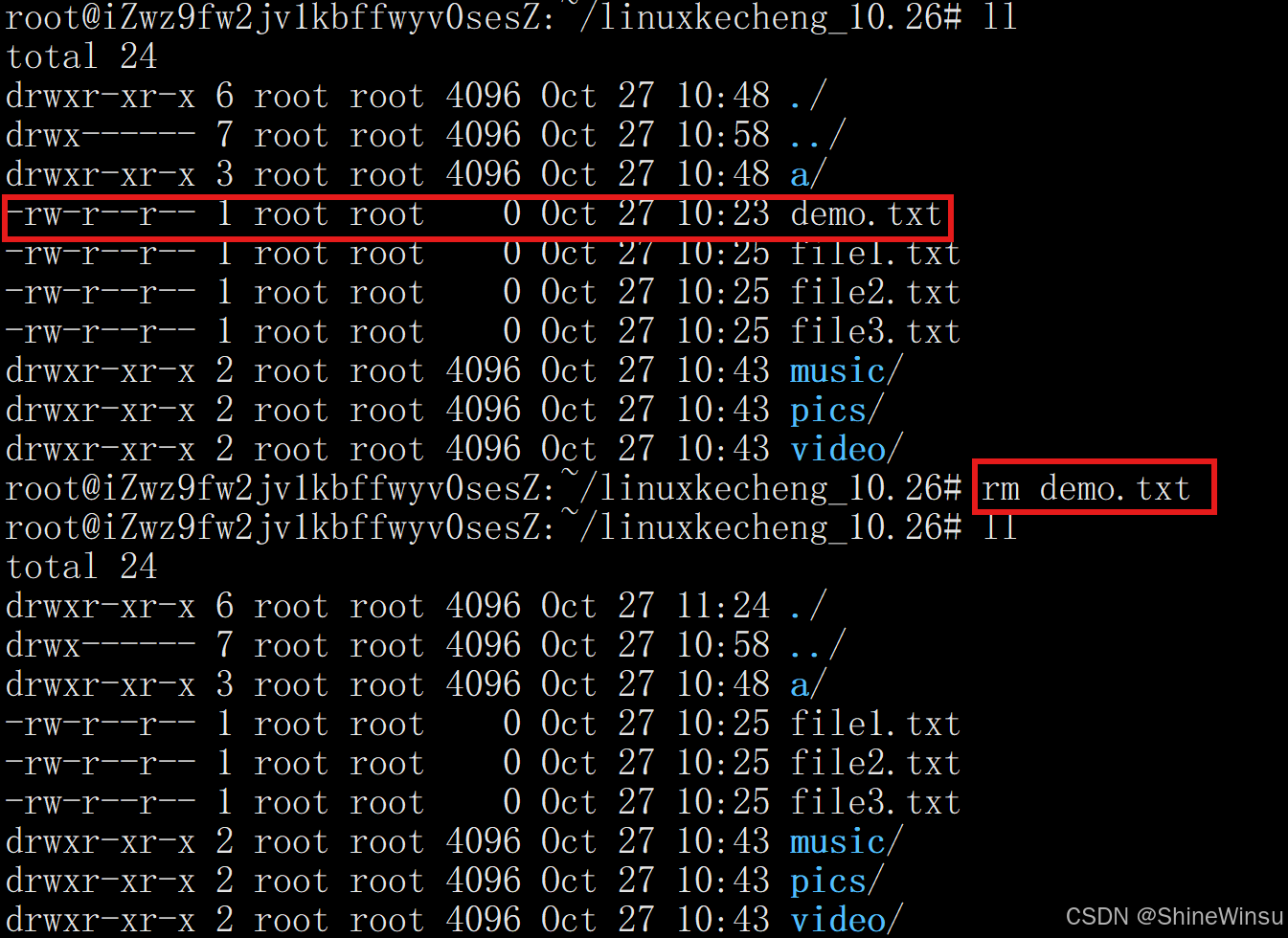
2. 关键选项详解
(1)-f:强制删除,忽略提示
-
作用:直接删除文件 / 目录,不询问确认(即使文件是只读的),也不提示 "文件不存在" 的错误(静默删除)
-
适用场景:脚本自动化删除(无需人工干预)、确认要删除且无需提示时。
强制删除只读文件(不会提示确认)
rm -f read_only_file.txt
强制删除不存在的文件(不报错,静默执行)
rm -f no_such_file.txt
(2)-i:删除前逐一询问确认
-
作用 :删除每个文件 / 目录前都会提示
是否删除?(y/n),输入y确认删除,n取消,避免误删。 -
适用场景 :删除重要文件时,通过交互确认降低风险(系统默认对
rm配置别名rm -i的场景下,直接执行rm也会触发询问)。删除前询问(如删除file.txt时会提示:rm: 是否删除普通文件 'file.txt'?)
rm -i file.txt
删除多个文件时,逐个询问
rm -i *.docx
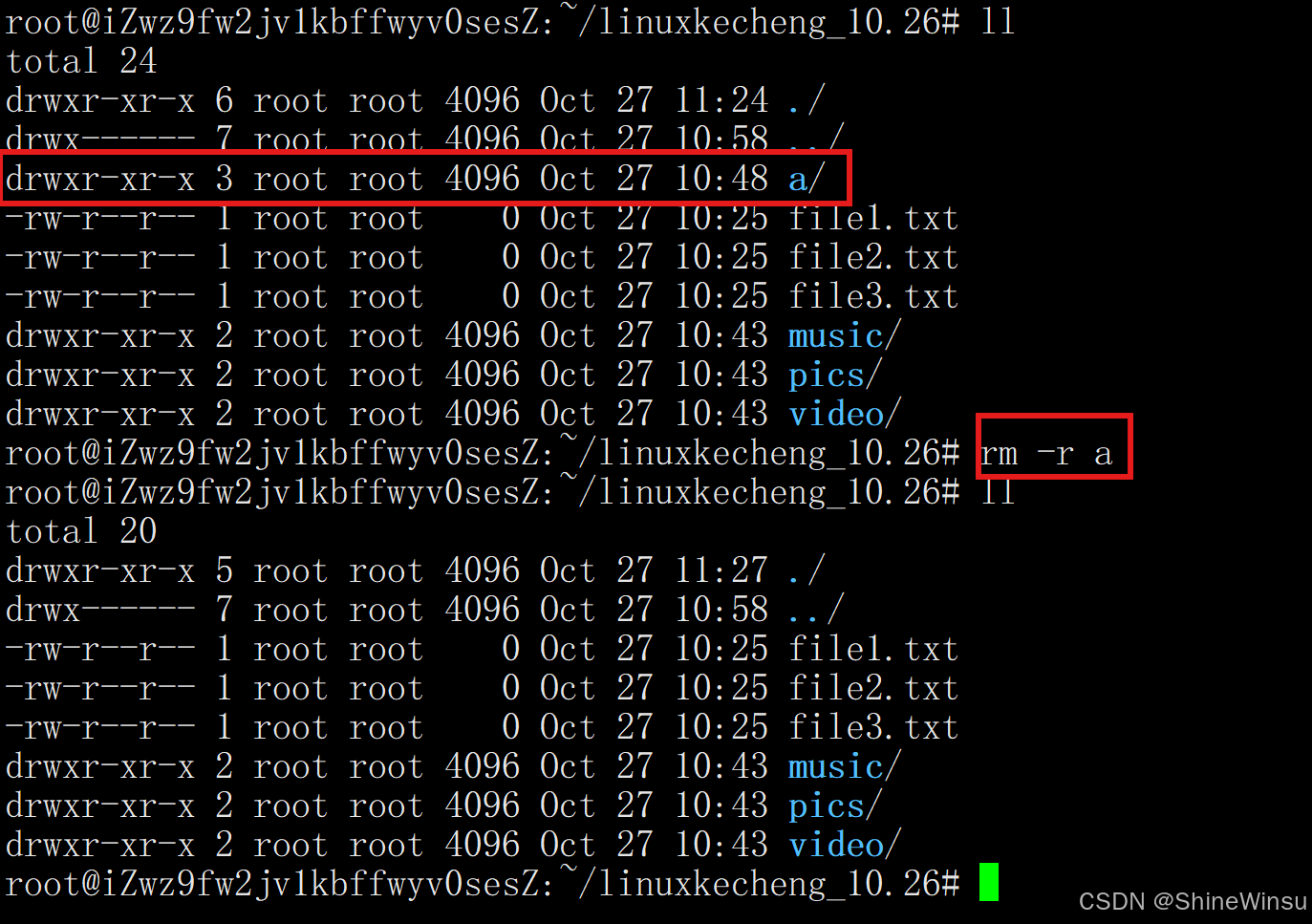
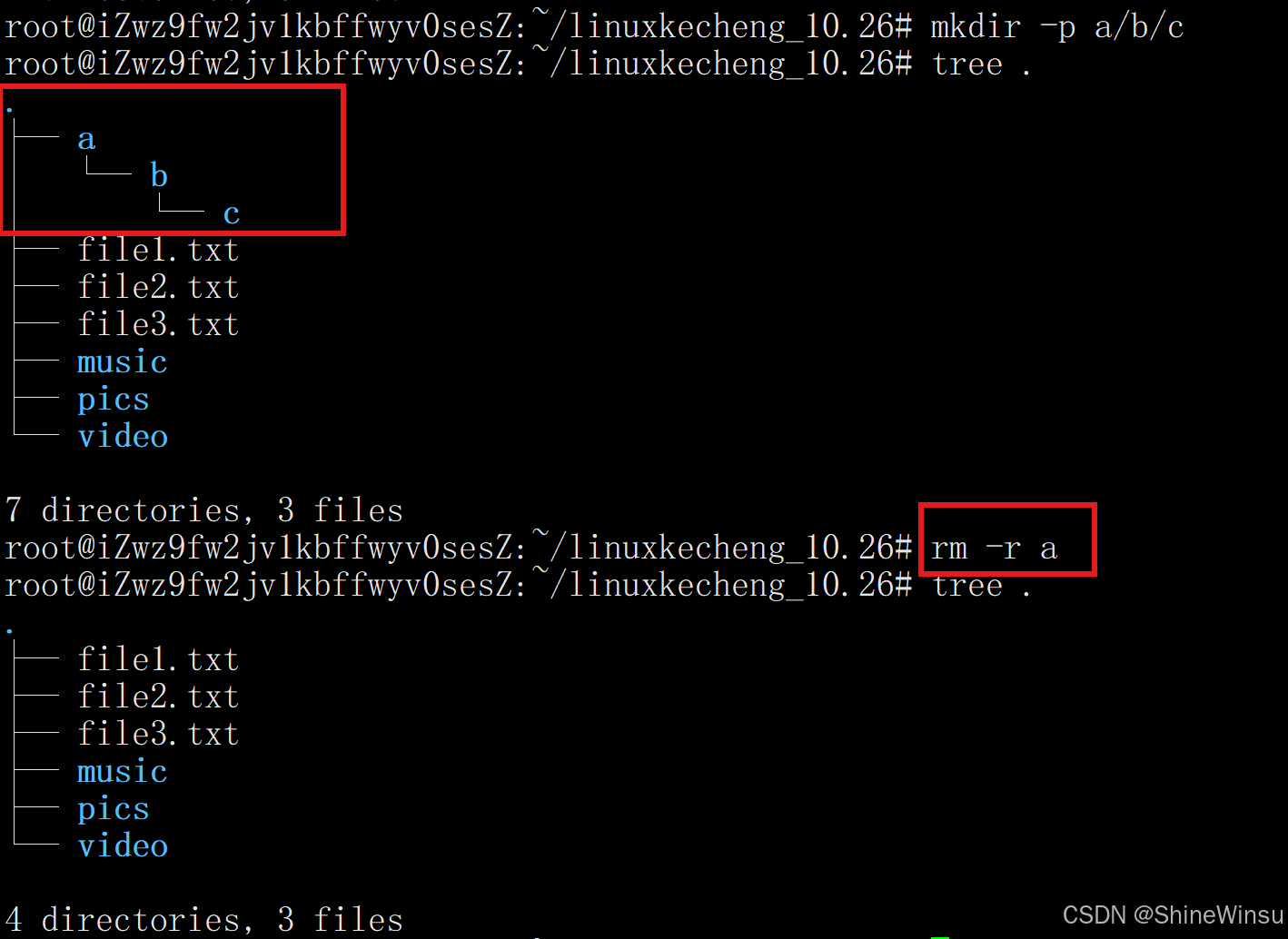
(3)-r:递归删除目录及内容
-
作用:删除目录时必须使用的选项,会递归删除该目录下的所有文件、子目录及子目录内的内容(无论是否为空,即哪怕该目录下文件有内容,或者目录下还有目录,都是直接删除的),即我们想要使用rm去删除目录的话,就得加 -r选项,这个是一个比较关键的点,希望大家注意。
-
注意 :
-r可小写(-r)或大写(-R),功能一致。删除非空目录(含所有子文件和子目录)
rm -r docs/ # docs目录下有文件或子目录时,需用-r
递归删除多个目录
rm -r dir1/ dir2/
 (4)
(4)-v:显示删除过程(verbose,详细模式)
-
作用:删除时输出每个被删除的文件 / 目录名称,清晰展示操作过程。
显示删除文件的详细过程
rm -v *.tmp
输出示例:removed 'a.tmp'、removed 'b.tmp'
递归删除目录并显示过程
rm -rv old_data/
输出示例:removed directory 'old_data/logs'、removed 'old_data/report.txt' 等
3. 选项组合:高效删除场景
(1)-rf:强制递归删除目录(慎用!)
-
功能 :结合
-r(递归删目录)和-f(强制不提示),直接删除目录及所有内容,无任何确认步骤。 -
风险提示 :这是 Linux 中最危险的命令之一,若误操作(如
rm -rf /或rm -rf ~/*),可能删除系统文件或个人数据,且无法恢复! -
正确用法:确认目录无需保留时使用,例如清理临时目录:
强制删除临时目录及其所有内容(确保路径正确!)
rm -rf /tmp/old_cache/
(2)-ri:递归删除前逐一确认
-
功能:删除目录时,对每个文件和子目录都询问确认,适合删除包含重要内容的目录,最大限度避免误删。
递归删除目录,每个文件/子目录都需确认
rm -ri project_backup/
会提示:rm: 是否进入目录 'project_backup/'?(y/n),确认后逐个询问删除内容
三、注意事项
- 删除不可逆 :Linux 中
rm删除的文件 / 目录不会进入 "回收站",一旦删除无法直接恢复(除非借助专业数据恢复工具,且成功率低),操作前务必确认目标。 - 权限要求 :删除文件需对文件所在目录有 "写入" 权限;删除目录需对其父目录有 "写入" 权限,否则提示
Permission denied(需用sudo获取权限)。 - 通配符使用谨慎 :例如
rm *.txt会删除当前目录所有 txt 文件,若误写为rm *txt(少一个点),可能删除无关文件。 - 区分文件与目录 :删除目录必须加
-r选项,否则报错rm: 无法删除'dir/': 是一个目录;删除文件时无需-r,加了也不影响(但多余)。
rm 命令的强大之处在于其灵活性(兼顾文件和目录),但也因 "不可逆删除" 的特性要求使用者格外谨慎。记住:删除前先用 ls 或 ll 确认目标路径和内容,重要数据务必提前备份,这是避免操作失误的关键!
通配符:
在 Linux 命令行中,通配符 是用于模糊匹配文件或目录名称的特殊字符,能大幅提升文件操作的效率。它通过 "模式匹配" 快速定位一类文件,避免逐个输入文件名的繁琐。以下是常见通配符的详细说明:
一、核心通配符类型
| 通配符 | 功能描述 | 示例 |
|---|---|---|
* |
匹配任意长度的任意字符(包括空字符) | *.txt 匹配所有以.txt结尾的文件;file* 匹配以file开头的所有文件(如file1、fileabc) |
? |
匹配单个任意字符 | f?le.txt 匹配file.txt、f1le.txt等(中间单个字符任意);?.txt 匹配a.txt、1.txt等单字符开头的 txt 文件 |
[] |
匹配方括号内的任意一个字符 | [a-z].txt 匹配a.txt、b.txt...z.txt;[0-9]_file 匹配1_file、2_file...9_file;[abc].sh 匹配a.sh、b.sh、c.sh |
[^] 或 [!] |
匹配方括号内以外的任意一个字符 | [^0-9].txt 匹配非数字开头的 txt 文件(如a.txt、x.txt);[!abc].sh 匹配除a.sh、b.sh、c.sh外的.sh文件 |
{} |
匹配花括号内的任意一个字符串 (需结合bash的扩展功能,执行前需确认shopt -s braceexpand已开启) |
{file1,file2,file3}.txt 匹配file1.txt、file2.txt、file3.txt;{doc,pdf,mp3} 匹配doc、pdf、mp3三个目录 |
二、典型使用场景
1. 批量删除文件
rm *.log # 删除当前目录所有以.log结尾的文件
rm ?.txt # 删除所有单字符开头的txt文件(如a.txt、1.txt)2. 批量移动 / 复制文件
mv [a-c].jpg pics/ # 将a.jpg、b.jpg、c.jpg移动到pics目录
cp {report,summary}.pdf docs/ # 复制report.pdf和summary.pdf到docs目录3. 批量查看文件内容
cat *.conf # 查看所有.conf配置文件的内容
grep "error" [0-9]*.log # 在数字开头的log文件中搜索"error"4. 模糊匹配目录
ls /home/user/{docs,downloads} # 列出docs和downloads目录的内容
rmdir empty_* # 删除所有以empty_开头的空目录(需目录为空)三、通配符的匹配顺序
通配符会由 Shell(如 Bash)在命令执行前 自动解析,将匹配到的文件 / 目录列表替换到命令中。例如执行ls *.txt时,Shell 会先找到所有符合*.txt的文件,再将这些文件名作为参数传给ls命令。
四、注意事项
- 通配符不匹配隐藏文件 :以
.开头的隐藏文件(如.bashrc)不会被*、?等通配符匹配,需显式指定(如ls .*)。 - 空匹配的处理 :若通配符未匹配到任何文件,部分命令会直接报错(如
rm *.nonexist会提示 "无此文件或目录"),可结合nullglob选项(shopt -s nullglob)让 Shell 自动忽略空匹配。 - 与正则表达式的区别 :通配符是简单的模式匹配 ,语法和功能远少于正则表达式(如正则的
+、*、()在通配符中无意义),切勿混淆。
man指令:
man 命令是 Linux 系统中查询命令、函数、配置文件等帮助信息的 "百科全书",全称为 manual(manual)。它将系统中所有可查询的帮助文档按 "章节" 分类,通过简洁的语法快速定位所需信息,是解决 "记不住命令参数" 问题的核心工具。以下是详细介绍:
一、核心功能与基本语法
- 核心功能:查阅命令、系统调用、库函数、配置文件格式等的详细说明(包括语法、选项、参数、示例等)。
- 基本语法:
man [选项] 目标目标:可以是命令(如ls)、系统调用(如open)、库函数(如printf)、配置文件(如passwd)等。- 若不指定选项,默认从第 1 章开始搜索,找到第一个匹配结果后显示,即自动往后找,哪一章有出现第一个匹配结果,就进行显示。
二、man 手册的 9 大章节(核心分类)
man 手册按内容类型分为 9 个章节(不同发行版可能微调,但核心一致),章节号代表内容类别,查询时可指定章节精准定位:
| 章节号 | 内容类型 | 典型示例 |
|---|---|---|
| 1 | 普通用户命令 (如 ls、cd、rm 等终端命令) |
man 1 ls 查看 ls 命令的用法 |
| 2 | 系统调用 (内核提供的函数接口,如 open、write,需编程时调用) |
man 2 open 查看 open 函数的参数、返回值及所需头文件 |
| 3 | 库函数 (用户态库中的函数,如 C 库的 printf、fread) |
man 3 printf 查看 printf 函数的格式与用法 |
| 4 | 特殊文件 (/dev 目录下的设备文件,如 /dev/sda、/dev/null) |
man 4 null 了解 /dev/null 设备的作用 |
| 5 | 文件格式 / 配置文件 (如 /etc/passwd、/etc/fstab 的格式说明) |
man 5 passwd 查看 /etc/passwd 每个字段的含义 |
| 6 | 游戏相关(系统预装小游戏的帮助,较少用到) | man 6 fortune 查看 fortune 游戏的玩法 |
| 7 | 杂项 (包括环境变量、协议、宏定义等,如 environ 全局变量) |
man 7 ascii 查看 ASCII 码表 |
| 8 | 系统管理命令 (仅 root 可用,如 ifconfig、useradd) |
man 8 useradd 查看创建用户的管理员命令参数 |
| 9 | 内核相关(内核函数、模块等,主要供内核开发者参考) | man 9 schedule 查看内核调度函数(需特殊权限) |
三、常用选项及实战示例
1. 基础用法:直接查询命令
man ls # 查看 ls 命令的帮助(默认第1章,普通命令)
man passwd # 不指定章节时,默认显示第1章(passwd 命令);若想查 /etc/passwd 文件格式,需指定第5章 2. 选项
2. 选项 -k:按关键字搜索所有相关帮助
-
作用:模糊搜索包含关键字的所有手册条目(类似 "全局搜索"),适合记不清具体命令名时使用。
man -k "list directory" # 搜索包含"list directory"的所有命令,结果会显示 ls 等相关命令及章节
man -k "file format" # 搜索与"文件格式"相关的手册(如第5章的配置文件说明)
3. 选项 num:指定章节查询
-
作用 :精准定位某一章节的内容,避免同名称不同类型的条目混淆(如
passwd既是命令又是文件)。man 5 passwd # 查看 /etc/passwd 文件的格式说明(第5章)
man 1 passwd # 查看 passwd 命令(修改密码)的用法(第1章)
man 2 write # 查看系统调用 write 函数的用法(第2章,编程用)
4. 选项 -a:显示所有章节的匹配结果
-
作用 :当一个目标在多个章节有手册时,
-a会在退出当前章节后自动显示下一个章节的内容,直到所有匹配章节显示完毕。man -a printf # 先显示第1章(printf 命令),按 q 退出后,自动显示第3章(printf 库函数)
四、man 手册的阅读技巧
在 man 手册页面中,可通过以下快捷键操作(类似 Vim):
- 翻页 :
Space(下一页)、b(上一页)、Enter(下一行)、k(上一行)。 - 搜索 :
/关键词(向下搜索)、?关键词(向上搜索),按n跳至下一个结果,N跳至上一个。 - 退出:按
q退出手册页面。 - 查看目录 :部分手册支持按
h显示帮助,或按=查看当前章节结构。
五、注意事项
- 手册的完整性 :部分精简系统可能未安装完整手册,需通过
sudo apt install manpages(Debian/Ubuntu)或sudo yum install man(CentOS)补充安装。 - 中英文手册 :默认通常为英文,可安装中文手册包(如
manpages-zh)切换语言。 - 与
--help的区别 :命令 --help显示简洁的参数摘要,适合快速回忆;man 命令提供完整的详细说明,适合深入学习。
man 命令是 Linux 学习者的 "随身导师",无论是日常命令参数遗忘,还是编程时需要系统调用 / 库函数的细节,都能通过它高效解决。养成 "查手册" 的习惯,是学好 Linux 的关键一步!
大家要熟练使用man指令哦,Linux中的那个男人。
cp指令:
这是一个比较重要的指令。
cp(copy)是 Linux 系统中用于复制文件或目录的核心命令,功能灵活且高频使用,支持单文件、多文件、目录(含递归复制)等多种场景,配合选项可精准控制复制行为。以下从功能、选项、实战示例及注意事项展开详细说明:
一、核心功能与语法逻辑
- 核心功能:将 "源文件 / 目录" 的内容复制到 "目标文件 / 目录",可保留文件属性、递归复制目录、批量复制多个文件等。
- 语法 :
cp [选项] 源文件/目录 目标文件/目录语法逻辑分 3 种核心场景:- 源是单个文件 ,目标是文件:复制源文件并命名为目标文件(若目标文件存在,默认覆盖或按选项提示);
- 源是单个文件 ,目标是目录:复制源文件到该目录下,文件名不变;
- 源是多个文件 / 目录 ,目标必须是已存在的目录:将所有源文件 / 目录批量复制到该目录下;
- 源是目录 :必须配合
-r选项,否则报错(目录复制需递归处理子内容)。
二、常用选项及实战示例
1. 基础用法:复制单个文件
不添加选项时,默认复制单个文件, 复制源文件并命名为目标文件(若目标文件存在,默认覆盖或按选项提示),目标可是 "新文件名" 或 "现有目录"
# 场景1:复制 file.txt 到当前目录,并重命名为 file_copy.txt
cp file.txt file_copy.txt
# 场景2:复制 file.txt 到 ../docs 目录(目标目录需已存在),文件名仍为 file.txt
cp file.txt ../docs/
# 场景3:复制 /etc/passwd(绝对路径源文件)到当前目录
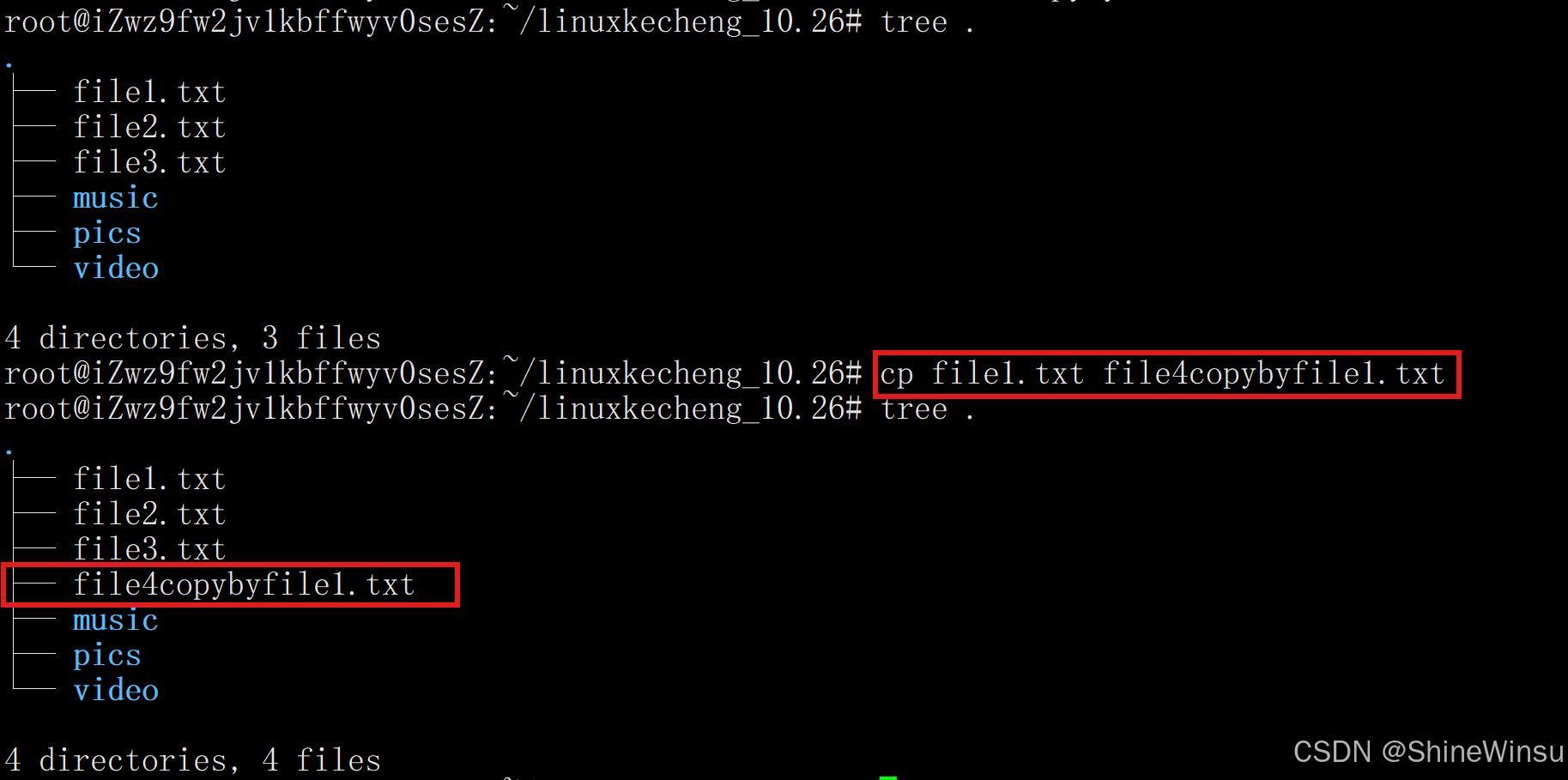
cp /etc/passwd ./复制 file1.txt 到当前目录,并重命名为 file4copybyfile1.txt:
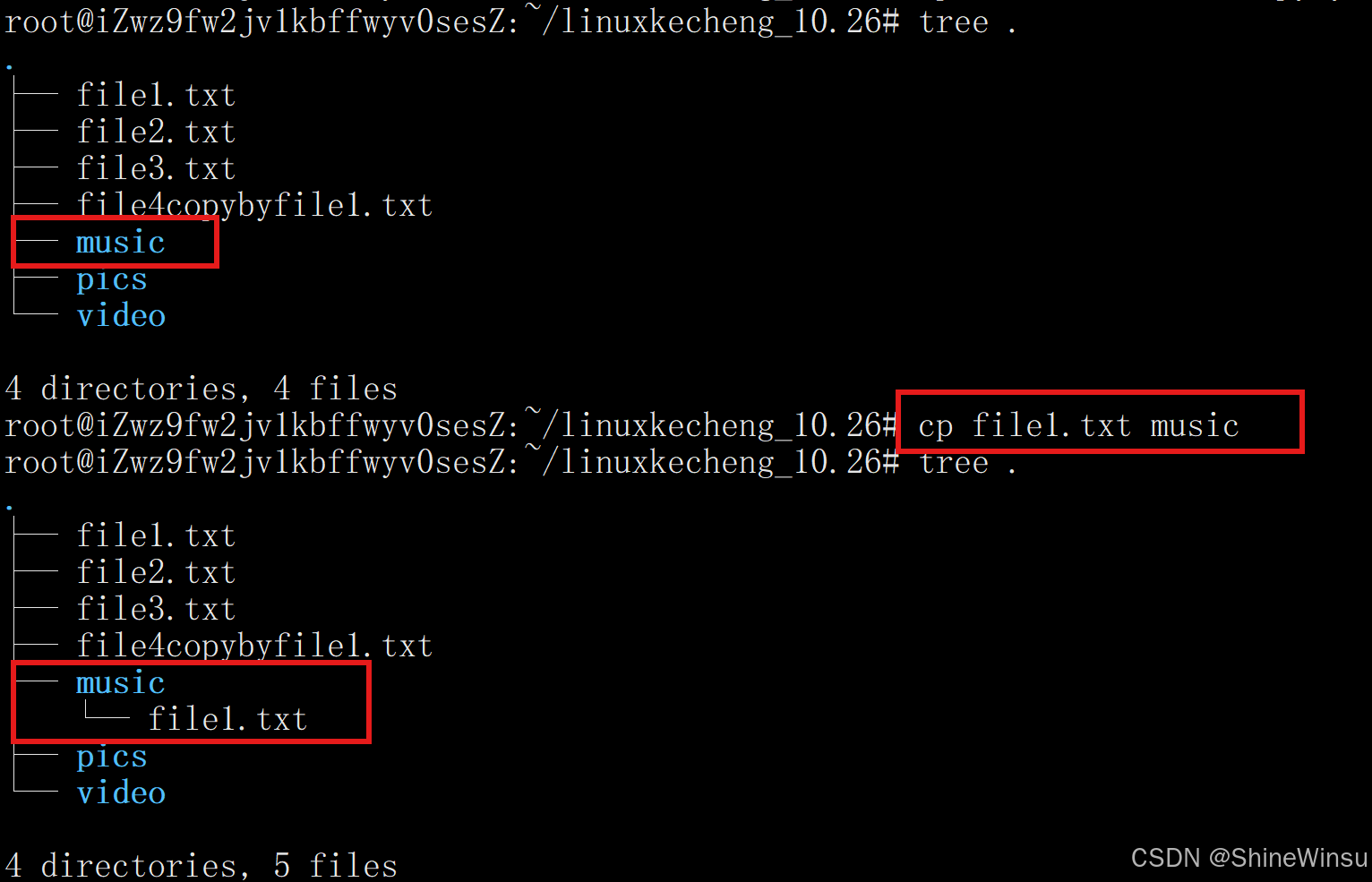
将file1.txt文件复制到已存在的music目录中:
2. 关键选项详解
(1)-f:强制复制,忽略覆盖提示
-
作用:当目标文件 / 目录已存在时,直接覆盖,不询问用户(即使目标是只读文件);若目标目录非空,也会强制覆盖其中同名文件,即哪怕是已经存在的文件,也直接给覆盖了,管你三七二十一的,霸道总裁一枚
-
适用场景 :脚本自动化复制(无需人工干预)、确认覆盖无风险时。
# 强制覆盖目标文件(即使 target.txt 已存在且只读) cp -f source.txt target.txt # 强制复制文件到目录,覆盖目录中同名文件 cp -f report.pdf docs/
把file1.txt文件强制复制给file2.txt文件: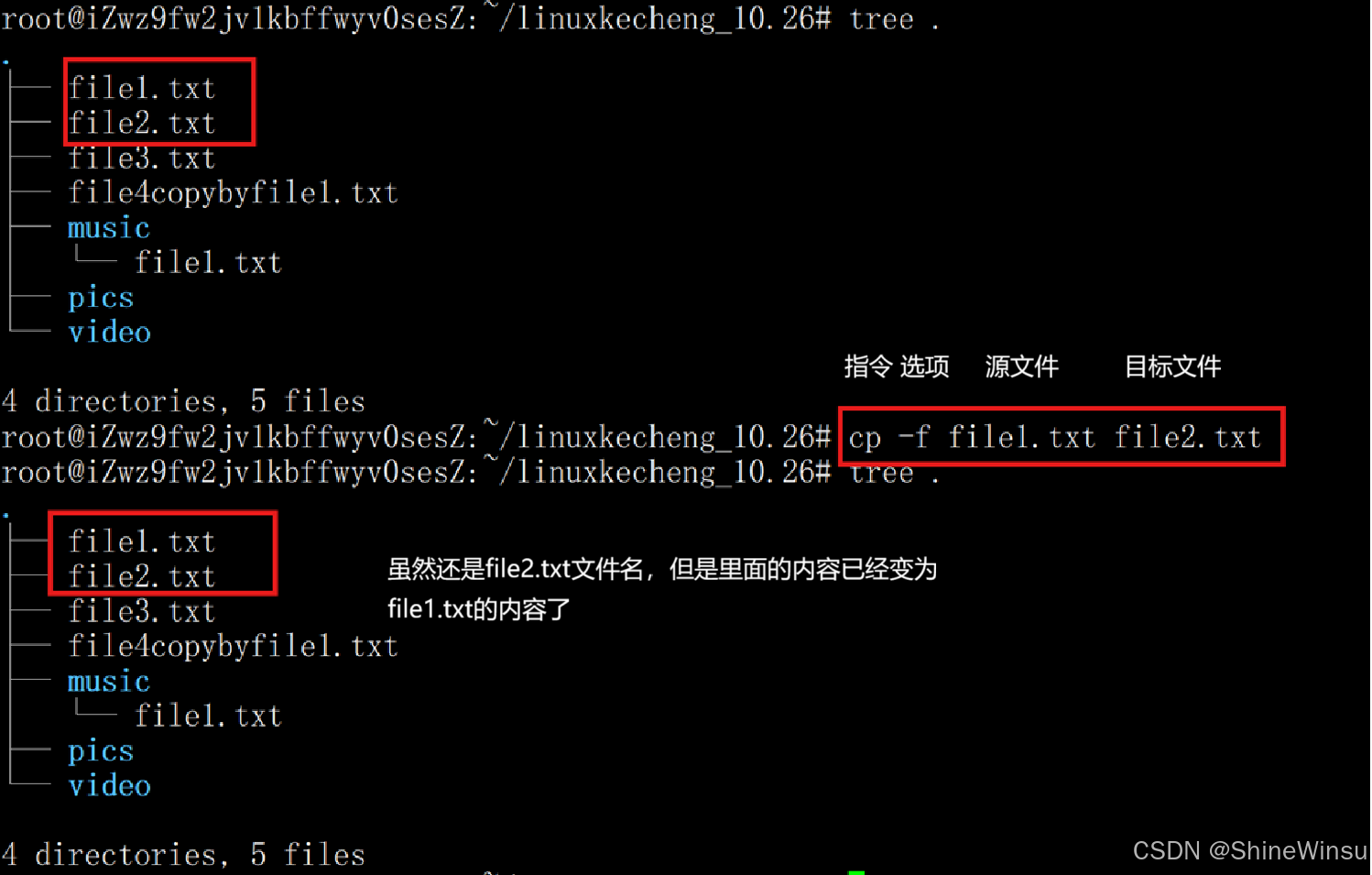
复制当前目录下文件给另一个目录下的同名文件,直接覆盖:
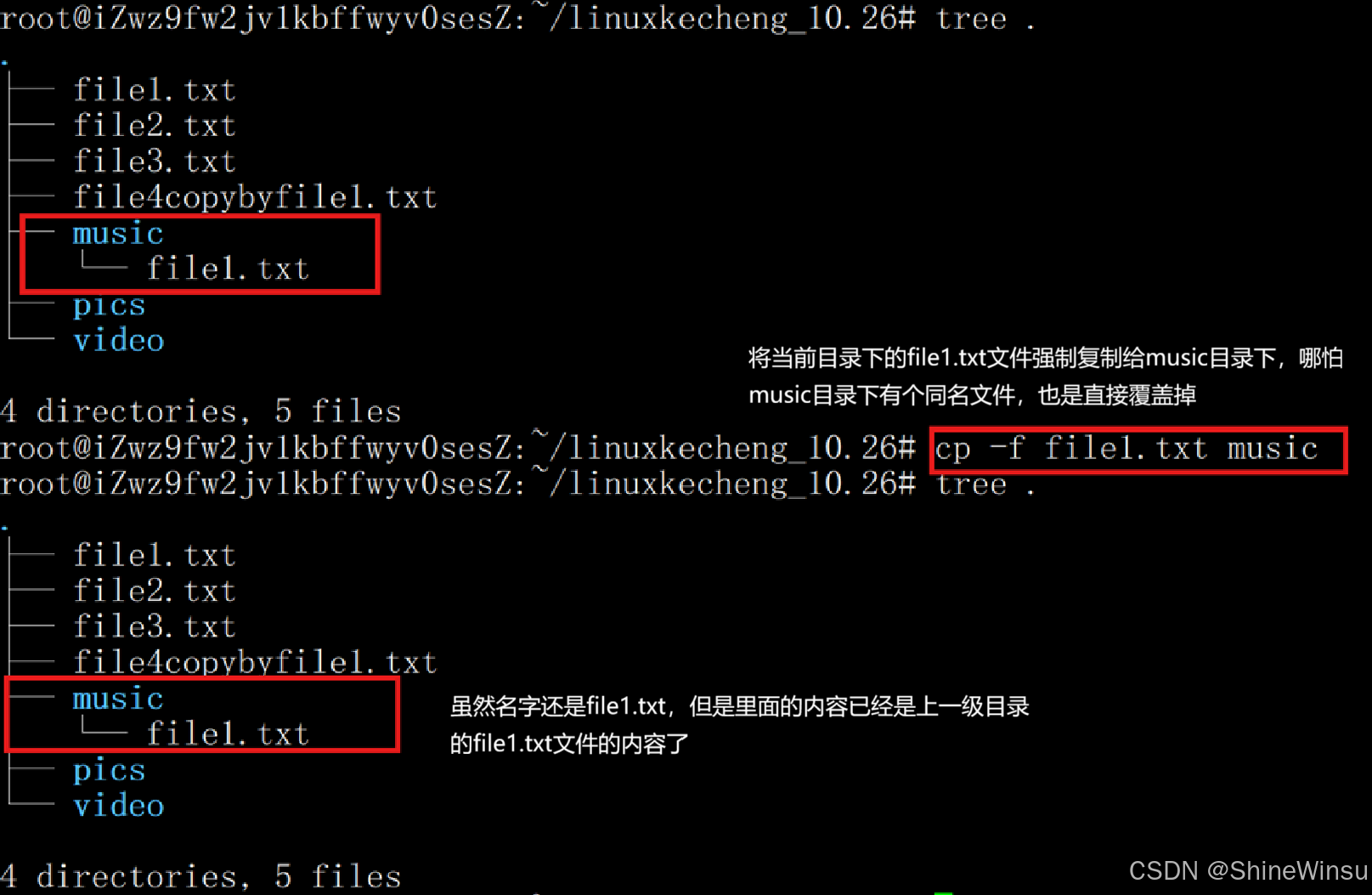
(2)-i:覆盖前询问确认
-
作用 :若目标文件 / 目录已存在,会提示
是否覆盖目标文件?(y/n),输入y确认覆盖,n取消,避免误覆盖重要文件。 -
注意 :部分系统(如 CentOS)默认给
cp配置别名cp -i,直接执行cp也会触发询问。复制时询问覆盖(若 target.txt 已存在,会提示确认)
cp -i source.txt target.txt
批量复制多个文件到目录,若目录中有同名文件,逐个询问
cp -i *.txt docs/
(3)-r:递归复制目录及所有内容
-
作用:复制目录时必须使用的选项,会递归复制该目录下的所有文件、子目录及子目录内的内容(无论目录是否为空),即我们想要复制目录的话,就得加上-r选项
-
说明:
-r可小写(-r)或大写(-R),功能完全一致。递归复制 docs 目录(含所有子文件/子目录)到 ../backup 目录下
cp -r docs/ ../backup/
复制多个目录到 target_dir 目录(target_dir 需已存在)
cp -r dir1/ dir2/ target_dir/
强制递归复制(覆盖目标目录中同名文件/目录,不提示)
cp -rf old_project/ new_project/
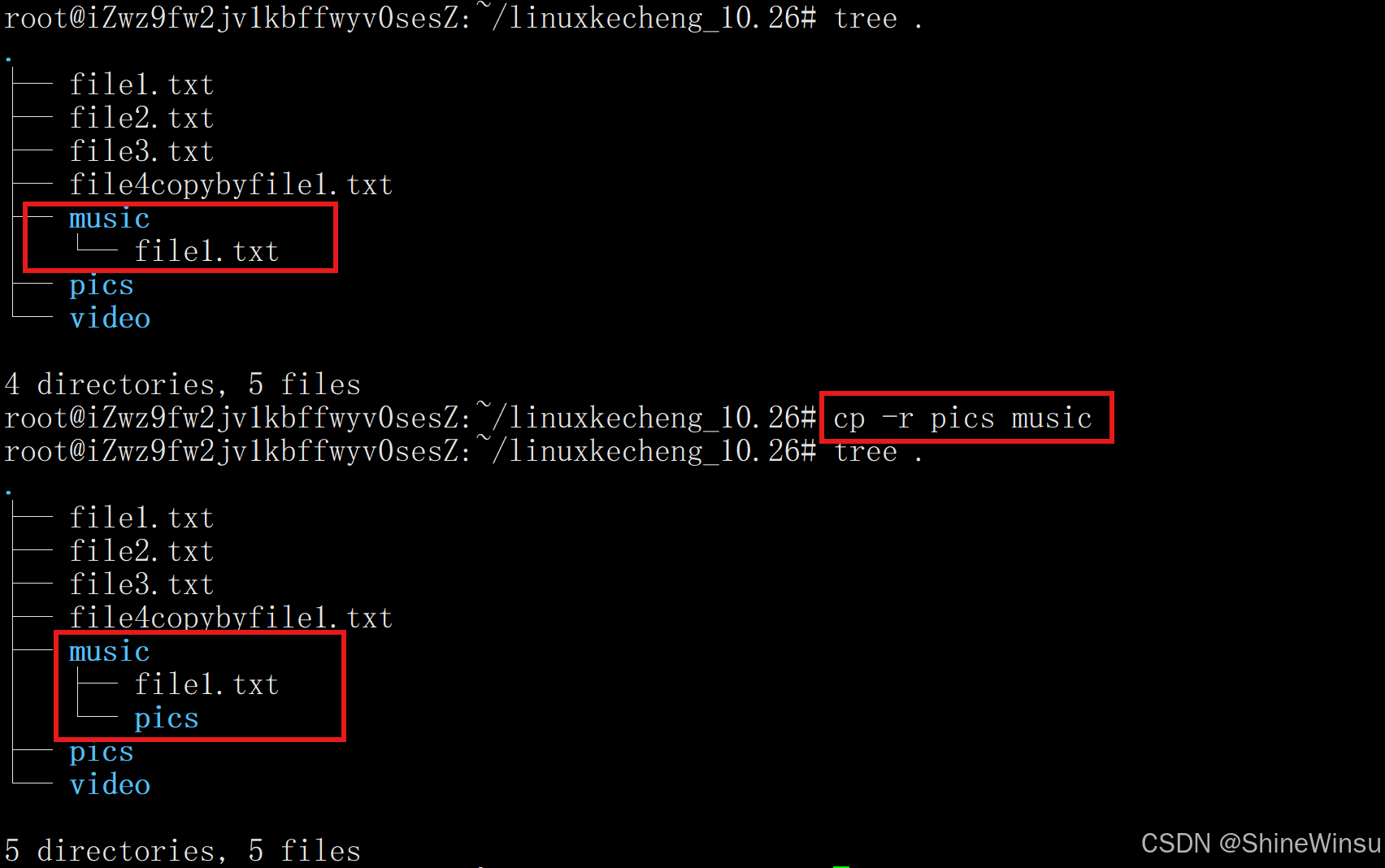
可以看到,我们成功的把当前目录的pics目录复制到music目录下,当然大家也可以使用绝对路径来指定,我这里是用的相对路径,自动省略.
(4)扩展实用选项(补充高频场景)
-
-p:保留文件属性 :复制时保留源文件的权限、所有者、所属组、修改时间等属性(默认复制后属性会变为当前用户和当前时间)。# 复制文件并保留其权限、修改时间等属性 cp -p config.conf backup/ -
-v:显示复制过程 :输出每个文件的复制详情(如 "已复制'source.txt' -> 'target.txt'"),清晰跟踪复制进度。# 递归复制目录并显示过程 cp -rv docs/ ../backup/
3. 高频组合场景
(1)批量复制多个文件到目录
将多个文件(或通过通配符匹配的一类文件)复制到指定目录,目标目录必须已存在。
# 复制 file1.txt、file2.pdf 到 docs 目录
cp file1.txt file2.pdf docs/
# 用通配符复制所有 .log 文件到 logs 目录
cp *.log logs/
# 复制当前目录下所有文件(含隐藏文件)到 ../all_files 目录
cp -r ./* ../all_files/ # 注意 ./* 包含所有非隐藏文件,若需隐藏文件可加 .*(2)复制目录并改名
若目标目录不存在,cp -r 会创建该目标目录,并将源目录的内容复制进去(等价于 "复制 + 改名")。
# 源目录 docs,目标目录 docs_backup 不存在
cp -r docs docs_backup # 会创建 docs_backup目录,并复制 docs目录到其中把video这个目录复制到testcp-r这个目录,由于没有testcp-r这个目录,所以直接创建一个出来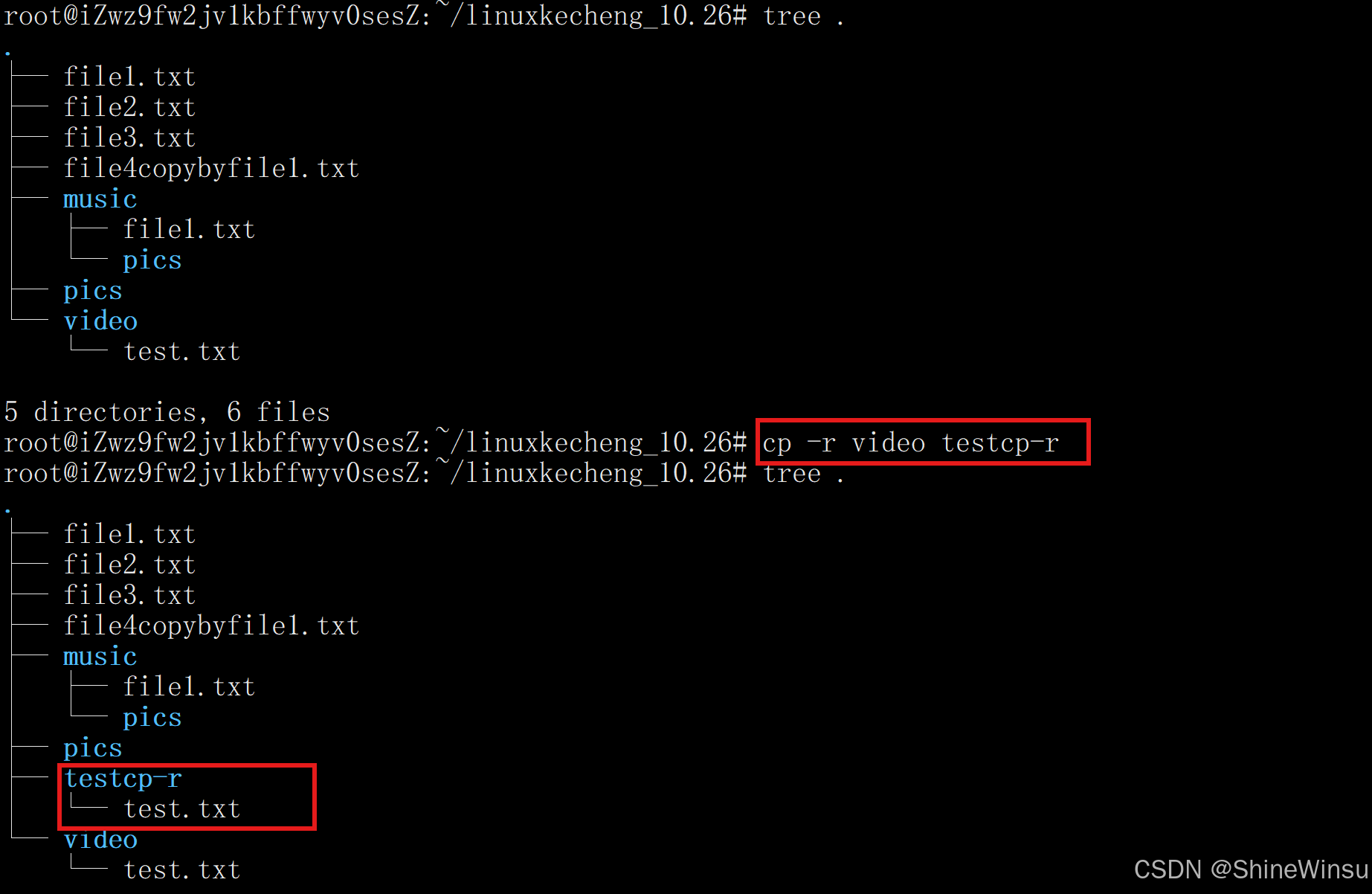
但是大家可以看到,诶,怎么是把video目录里面的test.txt文件复制到testcp-r这个目录里呢?我用了-r是想把video这个目录复制到testcp-r这个目录里呀,这是怎么回事,其实这与Linux发行版本有关,在Ubuntu中,我们是不能在没有存在目标目录时,用-r把一个目录复制到目标目录里面,虽然会自动创建原本不存在的那一个目录,但是只会把我们的源目录的里面的内容(包括子目录和文件)复制到新创建的那一个目录里面,并不会直接把源目录复制到新创建的目标目录中,所以我们想要把目录放进一个原本不存在的目录里面的话,就得先创建那个原本不存在的目录,然后再使用cp -r把源目录放进那个新创建的目录。这一点需要注意。
(3)安全复制(避免误覆盖)
结合 -i 和 -r,递归复制目录时,对每个同名文件都询问确认,适合复制包含重要内容的目录。
# 递归复制目录,覆盖前逐一询问
cp -ri old_docs/ new_docs/三、注意事项
-
目录复制的关键区别:
- 若目标目录已存在 :
cp -r 源目录/ 目标目录/会将源目录的内容复制到目标目录下; - 若目标目录不存在 :
cp -r 源目录/ 目标目录/会创建目标目录,并将源目录的内容复制进去(而非复制源目录本身); - 若想复制源目录本身 到目标目录下,需写成:
cp -r 源目录 目标目录/(源目录后不加/)。
- 若目标目录已存在 :
-
权限要求:
- 复制源文件 / 目录:需对源文件 / 目录有 "读" 权限;
- 复制到目标目录:需对目标目录有 "写 + 执行" 权限,否则提示
Permission denied(需用sudo获取权限)。
-
符号链接的复制:
- 默认情况下,
cp会复制符号链接指向的原文件,而非链接本身; - 若需复制符号链接本身(保留链接属性),需加
-d选项:cp -d link.txt target_dir/。
- 默认情况下,
-
避免误操作 :复制前建议用
ls查看源文件 / 目录和目标路径,确认无误后再执行;重要文件复制前可先备份。
cp 命令的核心价值在于 "灵活与高效"------ 既能处理单个文件的简单复制,也能通过 -r 递归复制复杂目录,配合 -f/-i 控制覆盖行为,满足日常操作和脚本自动化的多种需求。熟练掌握这些用法,能大幅提升文件管理效率!所以大家还是要高度掌握cp指令的。
mv指令:
mv(move)是 Linux 系统中用于移动文件 / 目录 或重命名文件 / 目录的核心命令,功能灵活活且高频使用,既 "剪切" 的特性(移动后源文件 / 目录会消失),也能快速重命名,是文件管理的重要工具。以下从功能、选项、实战场景及注意事项展开说明:
一、核心功能与语法逻辑
mv 的核心功能分为两类类:移动 (改变文件 / 目录的位置)和重命名 (改变文件 / 目录的名称),具体行为由 "目标参数的类型" 决定:
语法:mv [选项] 源文件/目录 目标文件/目录
-
场景 1:目标是 "文件" (不存在或已存在)功能:将源文件 / 目录重命名 为目标文件。限制:源只能有 1 个(多个源会报错)。
-
场景 2:目标是 "已存在的目录" 功能:将所有源文件 / 目录移动 到该目录下(文件名 / 目录名不变)。特点:源可以有多个(用空格分隔)。
二、常用选项及作用
| 选项 | 功能说明 | 适用场景 |
|---|---|---|
-f |
强制操作:若目标文件 / 目录已存在,直接覆盖,不询问 | 脚本自动化、确认覆盖无风险时 |
-i |
交互提示:若目标已存在,会询问 "是否覆盖?(y/n)",需手动确认 | 避免误覆盖重要文件(部分系统默认 mv -i) |
三、实战示例
1. 基础用法:重命名文件 / 目录
-
重命名文件:
bashmv old.txt new.txt # 将文件 old.txt 改名为 new.txt(目标不存在) mv report.pdf doc.pdf # 若 doc.pdf 已存在,不加选项会直接覆盖(或按系统默认提示)将本目录的file2.txt文件重命名为newfile2.txt:
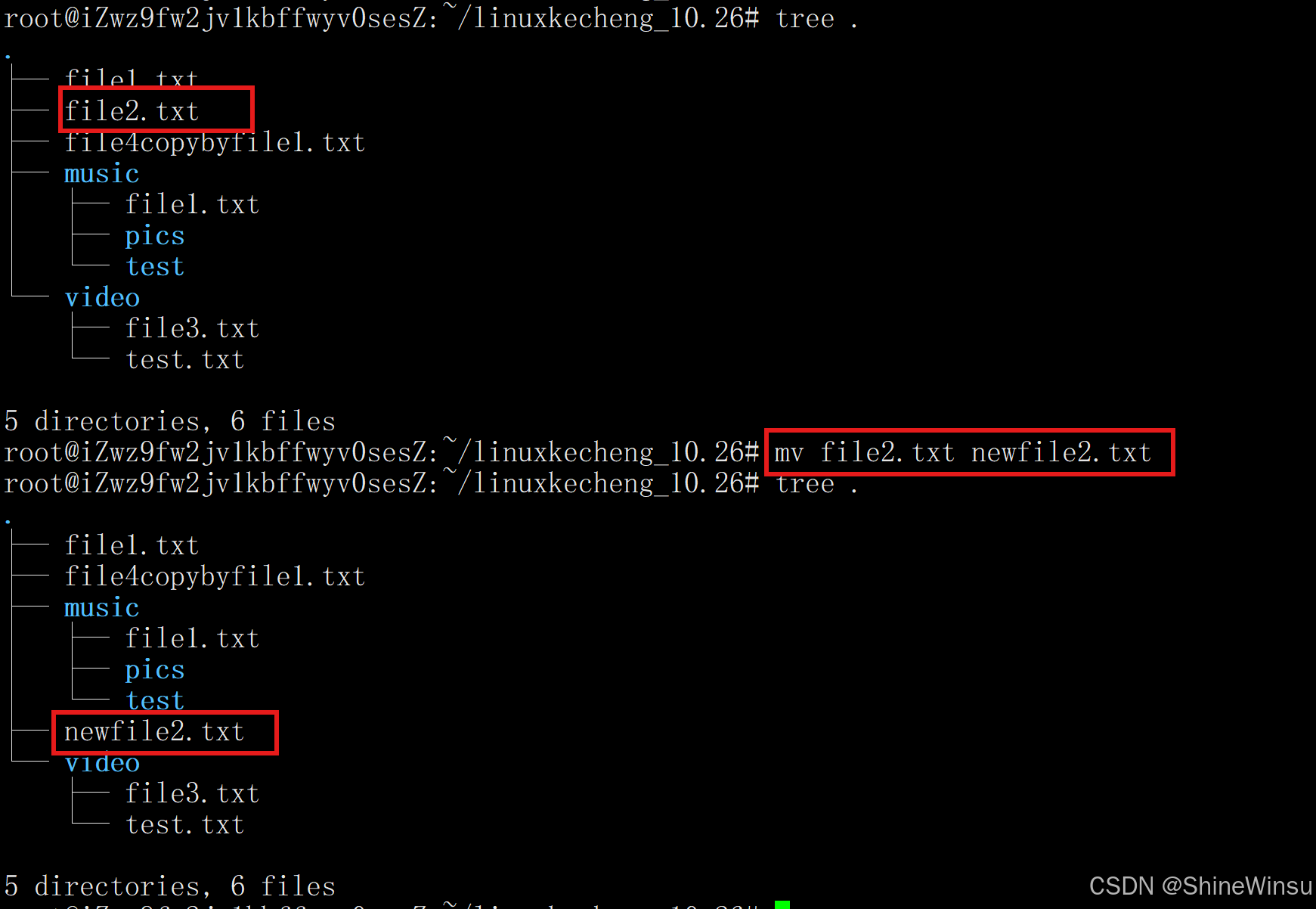
-
重命名目录:
mv docs/ documents/ # 将目录 docs 改名为 documents(目标目录不存在)
将本目录下的video目录重命名为newvideo: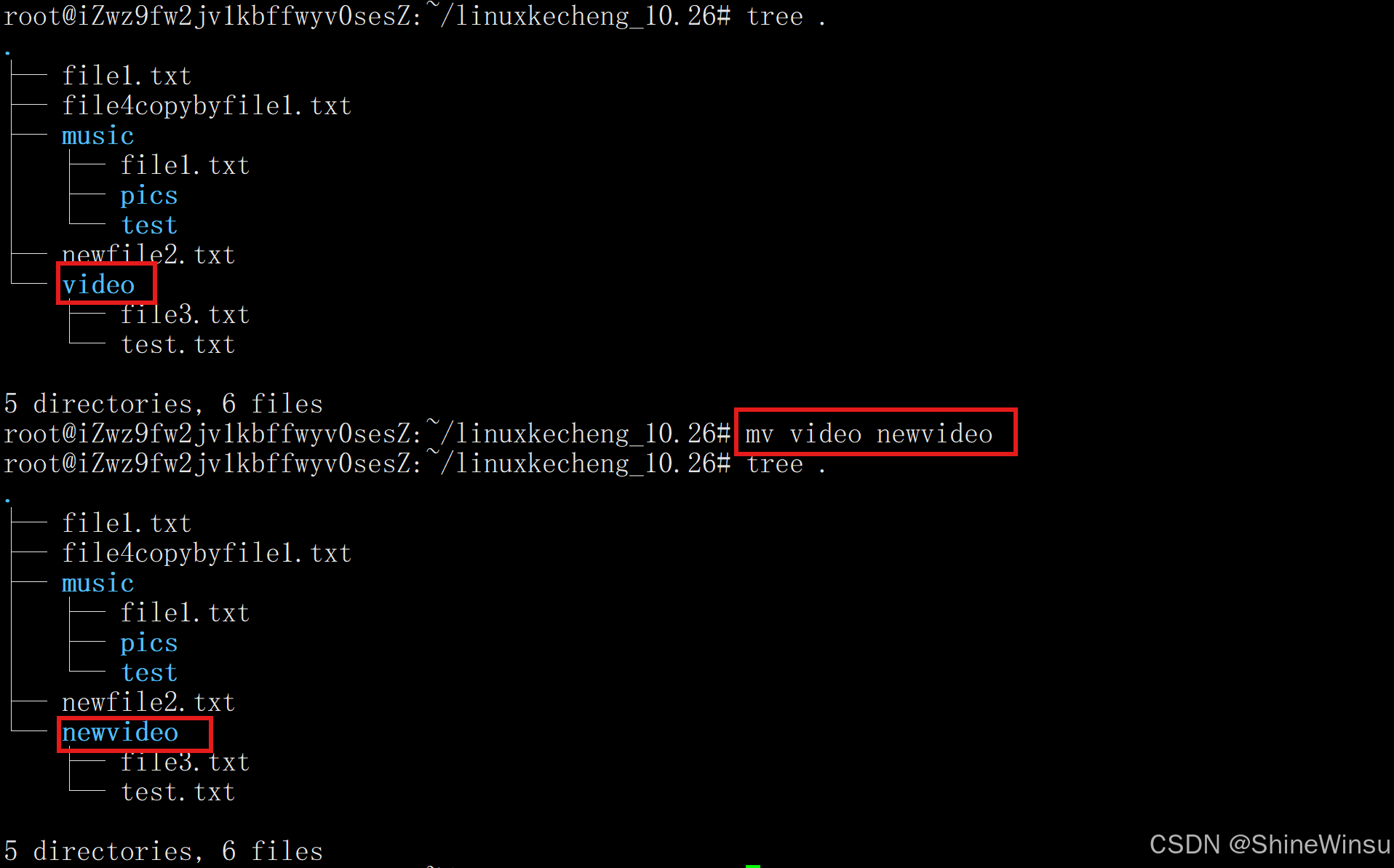
2. 移动文件 / 目录到目标目录
- 移动单个文件到目录:
bash
mv note.txt ./docs/ # 将 note.txt 移动到当前目录的 docs 子目录中
mv /tmp/logs/*.log ./backup/ # 将 /tmp/logs 下的所有 .log 文件移动到当前 backup 目录将本目录下的file3.txt文件剪切到已存在的video目录下: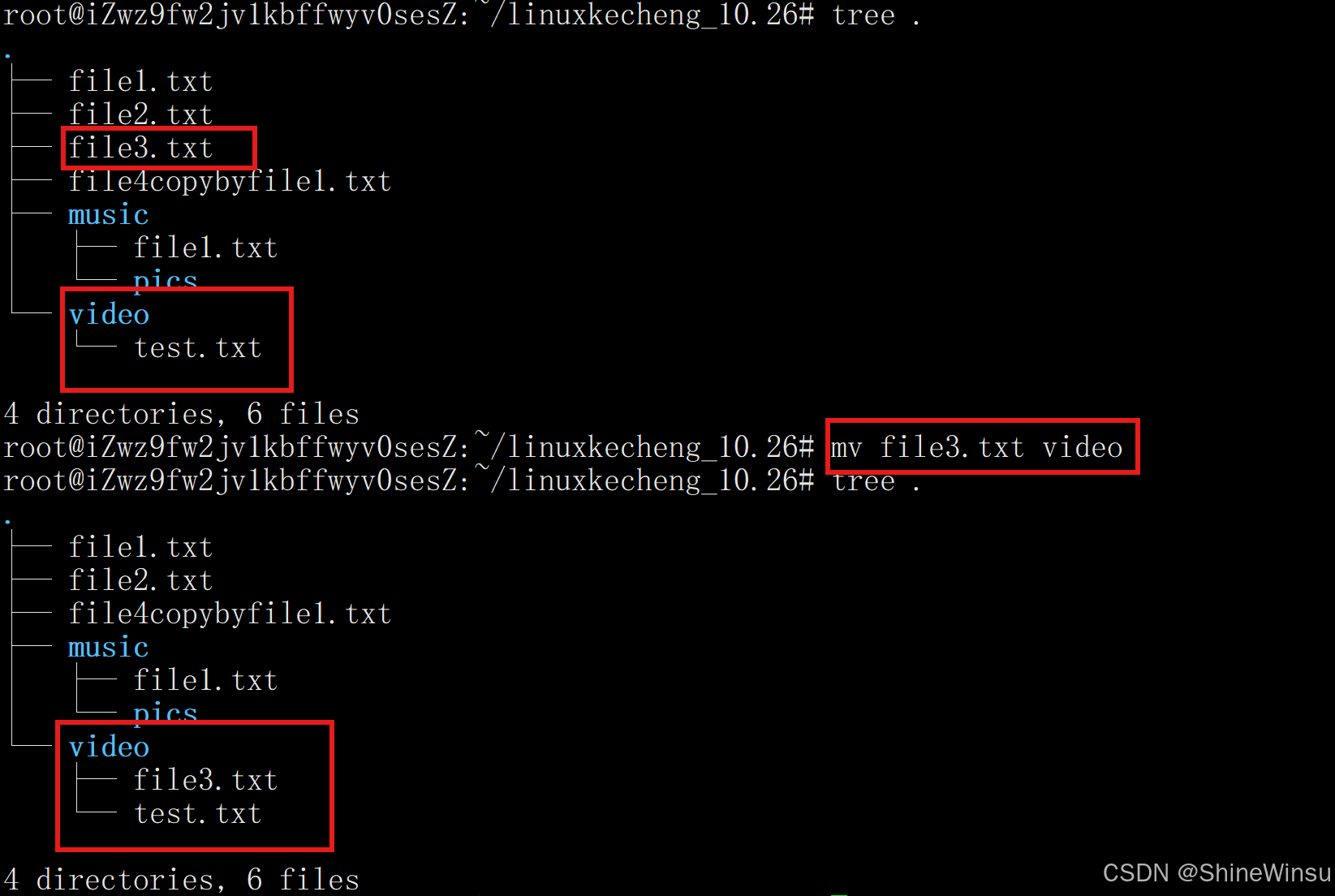
-
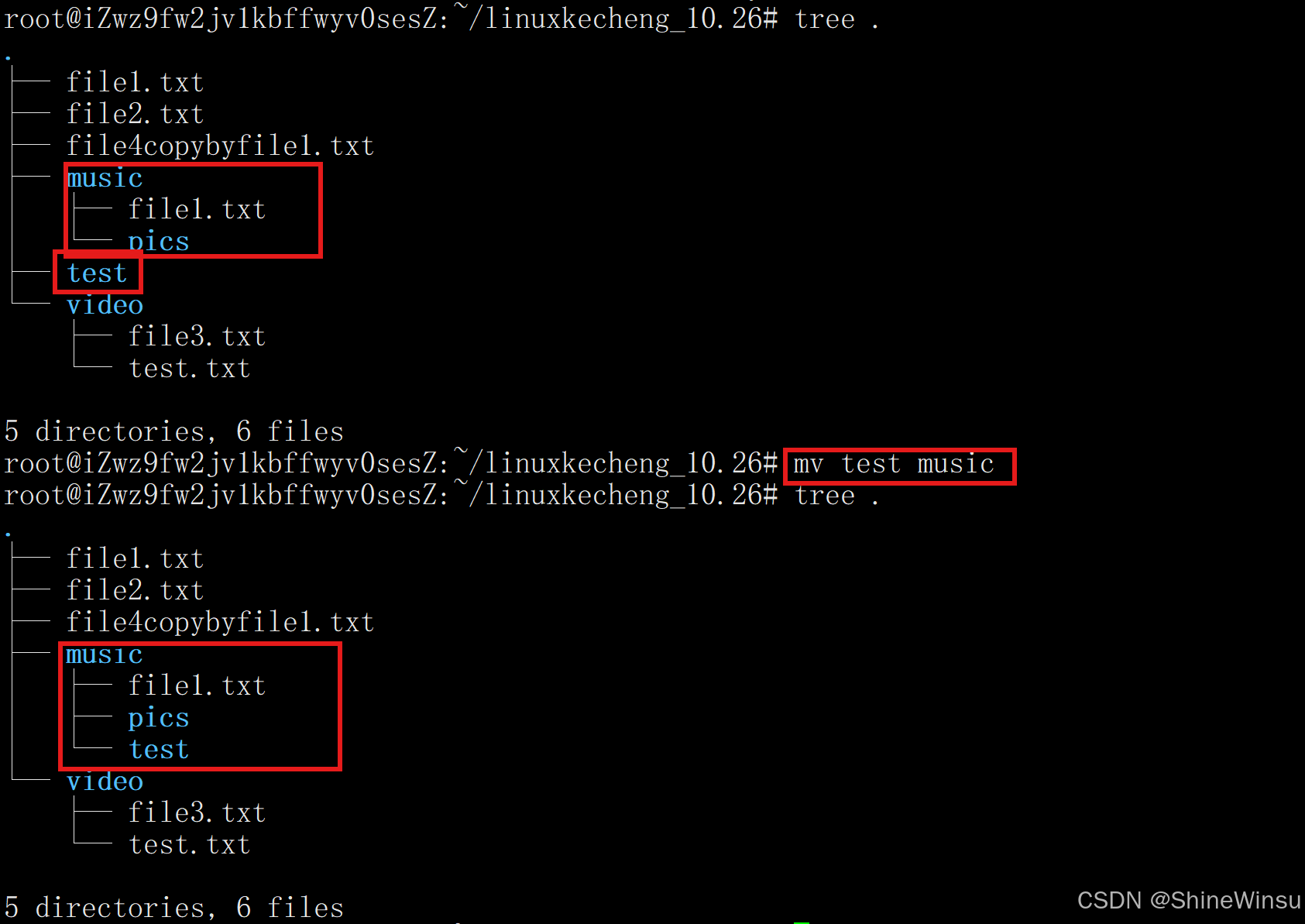
移动目录到另一个目录:
mv pics/ ./media/ # 将 pics 目录(含所有内容)移动到 media 目录下 mv dir1/ dir2/ ./archive/ # 同时移动 dir1、dir2 两个目录到 archive 目录
3. 选项 -f:强制覆盖
当目标已存在时,-f 会跳过询问直接覆盖,适合自动化场景:
mv -f old_config.ini config.ini # 强制用 old_config.ini 覆盖已存在的 config.ini
mv -f ./temp/* ./data/ # 强制移动 temp 下所有文件到 data 目录,覆盖同名文件4. 选项 -i:交互确认
删除前询问,避免误操作(尤其重要文件):
mv -i important.txt ./backup/ # 若 backup 中已有 important.txt,会提示"是否覆盖?"5. 进阶场景:结合通配符批量操作
# 重命名当前目录所有 .txt 文件为 .md(利用循环+mv)
for file in *.txt; do mv "$file" "${file%.txt}.md"; done
# 移动所有以 2023_ 开头的目录到 ./history/ 目录
mv 2023_*/ ./history/四、关键注意事项
-
与
cp的核心区别:cp是 "复制"(源文件 / 目录保留),mv是 "移动"(源文件 / 目录会被删除),类似 Windows 的 "复制 + 粘贴" 与 "剪切 + 粘贴"。
-
目录操作无需
-r:mv移动目录时不需要-r选项(与cp不同),直接写目录名即可递归移动所有内容:mv big_dir/ ./storage/ # 正确:直接移动整个目录,无需加 -r -
权限要求:
- 移动文件 / 目录:需对源文件 / 目录有 "读 + 执行" 权限;
- 移动到目标目录:需对目标目录有 "写 + 执行" 权限,否则提示
Permission denied。
-
跨文件系统移动的特性 :若源和目标在不同磁盘分区(文件系统),
mv会先复制文件,再删除源文件(耗时较长);同一分区内移动则仅修改路径(瞬间完成)。 -
避免覆盖的技巧 :不确定目标是否存在时,可先用
ls 目标路径确认,或直接用-i选项触发询问,降低误操作风险。
mv 命令的强大之处在于 "一键两用"------ 既能快速整理文件(移动到对应目录),又能批量重命名,配合 -f/-i 选项可灵活控制覆盖行为。熟练掌握后,能显著提升文件管理效率,是日常操作和脚本编写的必备工具!
echo指令:
echo 是 Linux 系统中用于输出文本到终端的基础命令,功能简洁但实用性极强,常用于脚本编写、命令行调试和信息提示。以下是详细介绍:
一、核心功能与基本语法
- 核心功能:在终端输出指定的文本内容,可直接输出字符串、变量值或命令执行结果,大家可以类比printf。
- 基本语法 :
echo [选项] 文本内容,文本内容一般是加双引号或者单引号
二、常用选项与实战示例
1. 基础输出:直接打印字符串
echo "Hello, Linux!" # 输出:Hello, Linux!
echo 欢迎学习Linux # 输出:欢迎学习Linux(字符串无特殊字符时可省略引号)
2. 选项 -n:输出后不换行
默认 echo 输出后会自动换行,-n 可取消换行,让后续输出紧跟在同一行。
echo -n "请输入用户名: "
read username # 输入框会紧跟"请输入用户名: ",不换行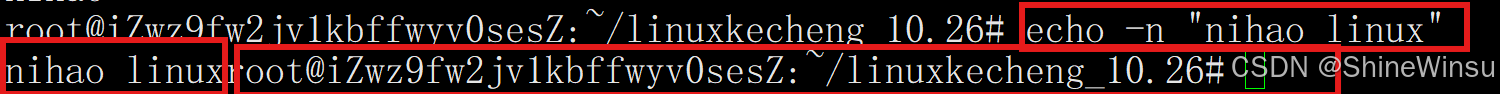 可以看到,就不进行换行了
可以看到,就不进行换行了
3. 选项 -e:解析转义字符
-e 允许 echo 识别并解析文本中的转义字符 (如换行 \n、制表符 \t、回车 \r 等)。
| 转义字符 | 含义 | 示例 |
|---|---|---|
\n |
换行 | echo -e "Line1\nLine2" → 输出两行 |
\t |
制表符(Tab) | echo -e "Name\tAge" → 输出 "Name Age" |
\r |
回车(覆盖当前行开头) | echo -e "Loading...\rDone" → 输出 "Done ..." |
\\ |
输出反斜杠本身 | echo -e "Path: /usr\\local/bin" → 输出 "Path: /usr/local/bin" |
类比C语言的转义符
示例:
# 输出带格式的文本
echo -e "ID\tName\tAge\n1\tAlice\t25\n2\tBob\t30"
# 输出:
# ID Name Age
# 1 Alice 25
# 2 Bob 304. 输出环境变量
echo 可直接输出环境变量 的值(变量需用 $ 引用)。
echo $HOME # 输出当前用户的家目录路径(如 /home/user)
echo $PATH # 输出环境变量 PATH 的值(系统命令搜索路径)5. 输出命令执行结果(命令替换)
通过命令替换 ($(命令) 或 命令),echo 可输出其他命令的执行结果。
echo "当前时间: $(date)" # 输出"当前时间: 2025-10-27 10:00:00"
echo "当前目录文件数: $(ls | wc -l)" # 输出当前目录的文件数量三、典型应用场景
1. 脚本中的信息提示
在 Shell 脚本中,echo 常用于打印步骤说明、变量值或错误提示。
#!/bin/bash
echo "开始执行脚本..."
name="Linux"
echo "欢迎使用 $name 系统!"
echo "脚本执行完毕。"2. 快速创建简单文件
结合重定向,echo 可快速创建或追加内容到文件,这个我们后面会讲到,嘎嘎好使的一个文件
echo "Hello" > new.txt # 创建 new.txt 并写入"Hello"
echo "World" >> new.txt # 追加"World"到 new.txt3. 调试与验证
在命令行中快速验证变量、命令结果或转义字符的效果。
# 验证变量是否定义
echo $undefined_var # 未定义的变量输出空值
# 验证转义字符解析
echo -e "a\tb\tc"四、注意事项
- 引号的使用 :若文本含空格、特殊字符(如
$、>),建议用双引号包裹,避免解析错误。 - 与
printf的区别 :echo更简洁,适合简单输出;printf支持格式化输出(类似 C 语言printf),适合复杂格式场景。
echo 是 Linux 命令行中最 "轻量" 的输出工具,从简单的文本打印到脚本中的信息交互,都能高效完成。掌握其选项和场景用法,能让你在命令行和脚本编写中更加得心应手!
cat指令:
cat 是 Linux 系统中用于查看、拼接、创建文件内容的基础命令,全称为 "concatenate"(连接),功能简洁且高频使用,是文件内容操作的核心工具之一。以下从功能、选项、实战场景及注意事项展开详细说明:
一、核心功能与基本语法
- 核心功能:
- 查看文件内容:将文件内容直接输出到终端;
- 拼接文件:将多个文件的内容合并输出或写入新文件;
- 创建 / 追加文件:结合重定向快速创建或追加文本到文件。
- 基本语法 :
cat [选项] [文件1] [文件2] ...
二、常用选项及实战示例
1. 基础用法:查看单个文件内容
cat file.txt # 直接输出 file.txt 的内容到终端
2. 选项 -n:显示行号
在输出内容前,为每一行标注行号(包括空行)。
cat -n poem.txt
# 输出示例:
# 1 床前明月光
# 2 疑是地上霜
# 3 举头望明月
# 4 低头思故乡这个就很简单的操作了,我就不演示了。
3. 选项 -b:显示非空行的行号
仅为非空行标注行号,空行不编号,适合阅读结构化文本。
cat -b log.txt
# 输出示例:
# 1 2025-10-27 INFO: 启动成功
# (空行不编号)
# 2 2025-10-27 WARN: 资源不足4. 选项 -s:压缩连续空行为一行
将文件中的连续空行合并为一个空行,使输出更简洁。
cat -s essay.txt # 原本的多行空行会被压缩为一行5. 拼接多个文件
将多个文件的内容按顺序合并输出,或写入新文件。
# 合并 file1.txt 和 file2.txt 并输出到终端
cat file1.txt file2.txt
# 合并 file1.txt 和 file2.txt 并写入 new.txt(覆盖原有内容)
cat file1.txt file2.txt > new.txt
# 合并多个文件并追加到 existing.txt
cat file3.txt file4.txt >> existing.txt 还是那句话,嘎嘎好使。
还是那句话,嘎嘎好使。
6. 结合管道与其他命令
将 cat 的输出通过管道传递给其他命令,实现内容过滤、统计等操作。
# 查看文件并筛选含"error"的行
cat error.log | grep "error"
# 统计文件行数
cat data.txt | wc -l
# 格式化 JSON 文件(需安装 jq)
cat config.json | jq .7. 创建 / 追加文件(结合重定向)
快速创建新文件或追加内容到已有文件。
# 创建 new.txt 并写入"Hello, Cat!"
cat > new.txt << EOF
Hello, Cat!
EOF
# 追加内容到 existing.txt
cat >> existing.txt << EOF
This is appended by cat.
EOF三、典型应用场景
1. 快速查看小文件内容
对于几行到几十行的小文件,cat 可直接输出内容,无需打开编辑器。
cat README.md # 查看项目说明文件2. 合并日志或配置文件
将分散的日志文件、配置片段合并为一个完整文件。
# 合并多个日志片段为完整日志
cat log_part1 log_part2 log_part3 > full_log.txt 将test和test1文件的内容都输入到temp这个文件里,这里的>是用到了重定向操作,下面我们会说。
将test和test1文件的内容都输入到temp这个文件里,这里的>是用到了重定向操作,下面我们会说。
3. 脚本中生成配置文件
在自动化脚本中,通过 cat 和重定向快速生成配置文件。
#!/bin/bash
cat > nginx.conf << EOF
server {
listen 80;
server_name example.com;
root /var/www/html;
}
EOF四、注意事项
-
不适合大文件 :若文件过大(如几 GB 的日志),
cat会将全部内容输出到终端,导致界面卡顿甚至崩溃,此时建议用less或tail分页查看。 -
与
tac的区别:tac是cat的反向操作,会倒序输出文件内容(从最后一行到第一行)。tac file.txt # 倒序显示 file.txt 的内容
cat 命令的核心价值在于 "简洁高效"------ 从简单的文件查看,到复杂的文件拼接、脚本化内容生成,都能快速完成。熟练掌握其选项和组合用法,能大幅提升文件内容操作的效率,是 Linux 日常使用的必备工具之一!
知识点:
OK大家,在又学习了一部分指令之后,我们就要再次开始学习一些Linux系统的知识点,可以这么说,指令只是辅助,真正重要的还是知识点。
Linux系统中一切皆文件:
在 Linux 系统中,"一切皆文件" 是其核心设计哲学之一,意味着硬件设备、目录、普通文件、进程、网络接口等所有系统资源,都被抽象为 "文件" 的形式进行统一管理。这种设计让 Linux 能通过一套简洁的接口(如文件读写、权限控制)来操作所有资源,大幅提升了系统的一致性和可管理性。以下是详细说明:
一、"一切皆文件" 的具体体现
1. 普通文件
- 存储数据的实体,如文本文件(
.txt)、二进制程序(/bin/ls)、脚本(.sh)、多媒体文件等,通过ls -l可查看其属性(权限、大小、修改时间等)。
2. 目录(文件夹)
- 用于组织文件的 "特殊文件",在
ls -l输出中以d开头(如drwxr-xr-x),本质是记录子文件 / 子目录的列表文件。通过cd、mkdir、rmdir等命令操作,与普通文件的管理逻辑一致。
3. 硬件设备
- 所有硬件都被抽象为 "设备文件",存于
/dev目录:- 磁盘:
/dev/sda(第一个磁盘)、/dev/sda1(第一个磁盘的第一个分区); - 终端:
/dev/tty(当前终端)、/dev/pts/0(虚拟终端); - 输入输出设备:
/dev/zero(零字节输出)、/dev/null(空设备,丢弃所有写入内容)。
- 磁盘:
4. 进程与管道
- 进程:每个运行的程序对应
/proc目录下的 "虚拟文件"(如/proc/1234记录 PID 为 1234 的进程信息),可通过读取这些文件查看进程状态、内存使用等; - 管道:
|(管道符)实现的进程间通信,本质是 "管道文件",用于数据流转(如ls | grep txt中,ls的输出写入管道文件,grep从管道文件读取)。
5. 网络接口
- 网络设备被抽象为文件,如
/sys/class/net/eth0记录网卡eth0的配置,可通过修改该目录下的文件来配置 IP、子网掩码等。
二、"一切皆文件" 的核心优势
1. 统一的操作接口
- 无论操作普通文件、目录、硬件还是进程,都可通过文件操作命令 (
cat、rm、chmod、grep等)或系统调用 (open、read、write等)实现,降低了学习和开发成本。例如:- 查看网卡配置:
cat /sys/class/net/eth0/address(等同于查看普通文件); - 控制进程:
echo 1 > /proc/sys/kernel/sysrq(通过写入文件开启系统请求键功能)。
- 查看网卡配置:
2. 灵活的权限管理
- 所有 "文件" 都遵循 Linux 的UGO 权限模型 (用户 - 组 - 其他),可通过
chmod、chown统一设置读写执行权限,保障系统安全。例如:- 限制普通用户访问磁盘设备:
chmod 600 /dev/sda(仅 root 可读写); - 共享目录给某用户组:
chown :devteam /data && chmod 770 /data。
- 限制普通用户访问磁盘设备:
3. 高效的资源抽象
- 将复杂的硬件、进程、网络等资源抽象为文件,让开发者无需关注底层细节,只需专注于 "文件式" 交互,大幅提升了系统的可扩展性和兼容性。
三、理解误区与补充
- 误区 :"一切皆文件" 并非指所有资源都是 "存储在磁盘的普通文件",而是逻辑上的抽象 (如
/proc下的进程文件是内存中的虚拟文件,重启后消失)。 - 补充 :Linux 通过 "文件类型" 区分不同资源,
ls -l输出的第一个字符表示类型:-:普通文件;d:目录;l:符号链接;b:块设备;c:字符设备;p:管道;s:套接字。
"一切皆文件" 是 Linux 设计的精妙之处,它让系统的所有资源都能通过一套简洁的逻辑管理,这也是 Linux 在服务器、嵌入式等领域具备强大灵活性和可定制性的核心原因之一。理解这一哲学,是掌握 Linux 系统原理的关键起点。
反正就是一句话,在Linux系统中,一切皆是文件,哪怕是我们的键盘,显示器,鼠标等等,也都是文件,大家可以直接类比我们之前学习C语言所说的stdin、stdout、stderr文件流就知道了,这是很重要的一个知识,还有就是,在我们进入Linux系统的时候,其实系统是默认给我们打开了输入和输出这两个文件,所以我们才能直接进行输入和输出,不难我们是得先打开输入和输出文件,才能进行输入和输出,希望大家注意。
重定向操作:
OK,知道了Linux系统一切皆文件之后,我们来看看另一个很关键的知识点:重定向操作:
在 Linux 中,重定向操作 用于改变命令的输入源 或输出目标,将原本在终端显示的内容(或需要从终端输入的内容)重定向到文件、设备甚至其他命令,是实现命令自动化、数据持久化和流程串联的核心技巧。以下是详细说明:
一、输出重定向:控制命令的 "输出流向"
输出重定向用于将命令的 ** 标准输出(stdout,正常结果)或标准错误(stderr,错误提示)** 从终端重定向到文件或其他位置。
1. 覆盖式输出重定向 >
-
功能:将命令的输出覆盖写入到指定文件(若文件存在则清空原有内容,不存在则创建)。
-
语法:
命令 > 目标文件,这个命令一般是echo指令或者cat指令,大家多练习记忆。 -
示例 :
# 将ls的结果覆盖写入到list.txt(原list.txt内容会被清空) ls > list.txt # 将错误输出覆盖写入到error.log(如执行不存在的命令) ls non_exist_dir > error.log # 错误!标准错误不会被>捕获,需用2>

注意点:
那么我们在使用>进行输入的时候,其实系统是先把指定文件原本的内容先清空,然后再把命令的输出内容输入到指定文件:
 这是一个注意点,然后就是由这个注意点我们可以延伸出一个用法,即使用>去将指定文件里面的内容清空:
这是一个注意点,然后就是由这个注意点我们可以延伸出一个用法,即使用>去将指定文件里面的内容清空:

操作方法也很简单,就是>前面什么都没有,然后后面空格一下,跟上你要指定的文件名字就行。
2. 追加式输出重定向 >>
那大家看完了上面的>会自动清除文件原本的内容,肯定会想,那要是我不想清除原本的内容呢?我就是想累加内容进去,这要怎么办呢?其实这就需要>>了
-
功能:将命令的输出追加写入到指定文件(保留原有内容,新内容添加到末尾)。
-
语法:
命令 >> 目标文件 -
示例 :
# 将date的结果追加到log.txt(不覆盖原有内容) date >> log.txt # 批量追加多个命令的输出 echo "Start" >> log.txt ls >> log.txt echo "End" >> log.txt

可以看到,还是好使的。
3. 错误输出重定向 2>
-
功能 :专门捕获命令的标准错误(stderr) ,并覆盖 / 追加到文件。
2是标准错误的文件描述符(stdout 是1,默认可省略)。 -
语法 :
命令 2> 错误文件(覆盖)、命令 2>> 错误文件(追加) -
示例 :
# 将错误输出覆盖写入error.log ls non_exist_dir 2> error.log # 将错误输出追加到error.log rm non_exist_file 2>> error.log
4. 同时重定向标准输出和错误 &>
-
功能 :一次性捕获命令的标准输出和标准错误,并覆盖 / 追加到同一文件。
-
语法 :
命令 &> 目标文件(覆盖)、命令 &>> 目标文件(追加) -
示例 :
# 将所有输出(包括错误)覆盖写入到all.log sudo systemctl restart nginx &> all.log # 追加所有输出到日志 apt update &>> update.log
上面的3和4在目前这个阶段不必太在乎,我们后面有学到会再说的,大家可以类比C里面的perror函数和errorno,其实也就是stderr。
二、输入重定向:控制命令的 "输入来源"
输入重定向用于将命令的输入源从终端改为文件或其他内容,避免手动输入的繁琐。
1. 输入重定向 <
-
功能:将指定文件的内容作为命令的标准输入(stdin)。
-
语法:
命令 < 输入文件 -
示例 :
# 将file.txt的内容作为cat的输入(等同于cat file.txt) cat < file.txt # 批量处理文件内容(如用grep筛选) grep "error" < system.log # 从system.log中搜索"error"
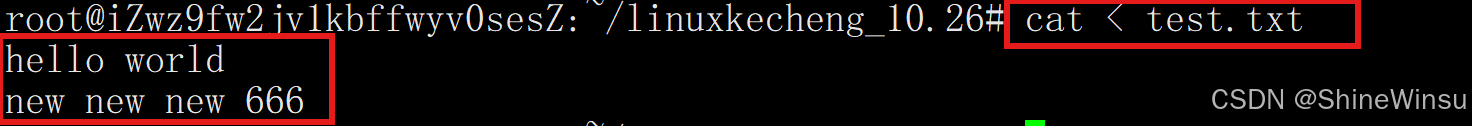
那么我们前面说过了,在Linux系统中,输入和输出也是文件,所以我们也可以直接运行cat:
 此时其实就是默认为键盘输入到显示上,所以我们输入一个内容,回车一下,就会输出刚才输入的内容,至于想退出,按一下ctrl加z就行。
此时其实就是默认为键盘输入到显示上,所以我们输入一个内容,回车一下,就会输出刚才输入的内容,至于想退出,按一下ctrl加z就行。
2. 多行输入重定向 <<(Here Document)
-
功能 :在命令行中直接输入多行文本作为命令的输入,无需依赖外部文件。
-
语法 :
命令 << 分界符(输入多行内容后,以分界符结束),后面是可以跟着输出重定向到某个指定文件里。 -
示例 :
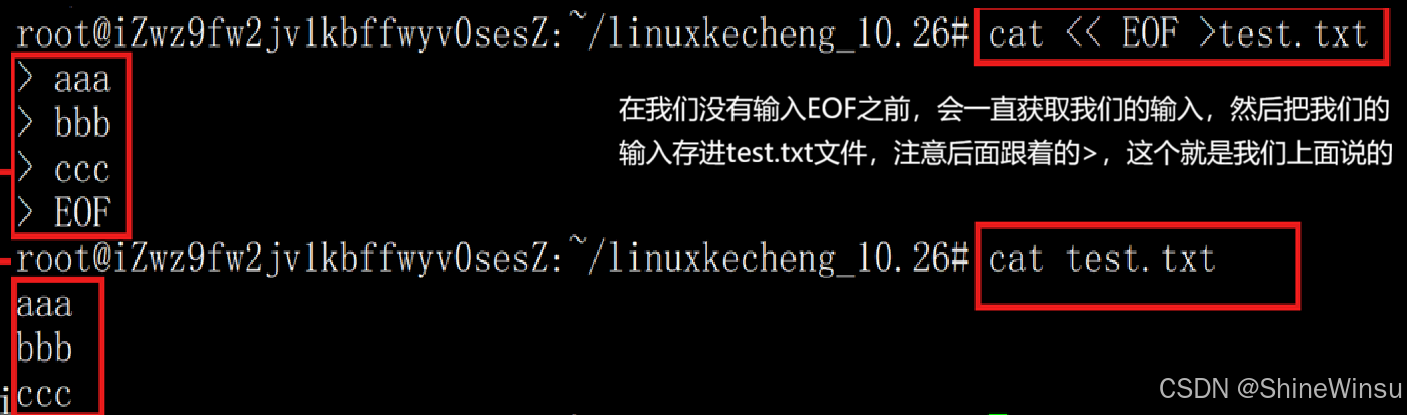
# 向file.txt写入多行内容 cat << EOF > file.txt Hello, Linux! This is a test. EOF # 输入到EOF时结束,内容写入file.txt # 给用户设置密码(无需手动输入) passwd user1 << EOF newpassword newpassword EOF
这个也是比较好使的一个操作:
三、管道重定向 |:命令间的数据流转
管道|用于将前一个命令的标准输出 直接作为后一个命令的标准输入,实现命令 "串联",是 Linux 中 "组合拳" 式操作的核心,这个在这里大家先看看,我们后面会详细讲到。
语法:命令1 | 命令2 | 命令3
示例:
# 筛选进程:先列出所有进程,再搜索含"nginx"的进程
ps aux | grep nginx
# 统计行数:先列出txt文件,再统计数量
ls *.txt | wc -l
# 复杂处理:查找错误日志并统计关键词出现次数
cat error.log | grep "error" | sort | uniq -c 四、特殊重定向场景
1. 重定向到 "空设备" /dev/null
-
功能 :将输出丢弃(常用于屏蔽无关输出)。
-
示例 :
# 屏蔽命令的所有输出(包括错误) find / -name "*.log" &> /dev/null # 仅屏蔽错误输出 ls non_exist_dir 2> /dev/null
2. 重定向到 "标准输出" 或 "标准错误"
-
语法 :
command > /dev/stdout(输出到终端)、command 2> /dev/stderr(错误输出到终端) -
示例 :
# 将文件内容同时输出到终端和日志 cat file.txt | tee log.txt # tee命令可同时输出到终端和文件,等效于cat file.txt > log.txt && cat file.txt
五、重定向的执行顺序与优先级
-
重定向操作从左到右执行 ,但需注意逻辑顺序:
# 先将ls的结果写入list.txt,再将错误输出追加到error.log ls non_exist_dir > list.txt 2>> error.log
总结
重定向操作是 Linux 命令行的 "粘合剂"------ 通过>/>>控制输出持久化,2>捕获错误,</<<简化输入,|串联命令,让复杂任务能通过简单的命令组合实现。掌握这些技巧,能大幅提升自动化脚本编写、日志管理和数据处理的效率,是 Linux 进阶的必备技能!
more指令:
其实这个指令,已经out了,我们简单了解一下就行:
more 是 Linux 系统中用于分页查看文件内容 的命令,功能类似 cat,但会将文件内容逐页显示(而非一次性输出全部),方便阅读大文件时的内容导航。以下是详细介绍:
一、核心功能与基本语法
- 核心功能:分页显示文件内容,支持按页、按行导航,避免大文件内容 "刷屏"。
- 基本语法 :
more [选项] 文件名
二、常用选项与操作指令
1. 基础用法:分页查看文件
more file.txt # 分页显示 file.txt 的内容,按空格键翻页,按 q 退出2. 选项 -n:指定每页显示的行数
控制每页输出的行数,避免内容过多或过少。
more -n 20 log.txt # 每页显示20行内容3. 交互指令(在 more 界面中输入)
在 more 分页界面中,可通过以下指令导航:
- 空格键 :翻到下一页;
- Enter 键 :翻到下一行;
q键 :退出more,返回命令行;/关键词:向下搜索文件中含 "关键词" 的行;n键:跳转到下一个匹配的 "关键词" 行;:f :显示当前文件的文件名和行号;
三、典型应用场景
1. 查看大文件内容
对于行数较多的文件(如系统日志、配置文件),more 可分页展示,避免内容一次性输出导致终端卡顿。
bash
more /var/log/syslog # 分页查看系统日志
这个还是简单的,但是呢,在大部分Linux发行版本中,more指令是不支持往前看的,只能不断往后看,所以,我们一般是用less指令去进行查看。
less指令:
less 是 Linux 中功能最强大的分页文件查看工具 ,堪称查看文件内容的 "正统选择"。它不仅解决了 more 只能向前翻页的局限,还支持前后自由浏览、灵活搜索、行号显示等丰富功能,且查看大文件时不会预先加载整个文件(占用内存更少),是日常查阅日志、配置文件的首选工具。以下是详细介绍:
一、核心功能与基本语法
- 核心功能:分页显示文件内容或命令输出,支持前后翻页、双向搜索、行号标注等交互操作,适配大文件和复杂查阅场景。
- 基本语法:
less [选项] 文件名也可结合管道接收其他命令的输出:命令 | less
二、常用选项(启动时配置)
| 选项 | 功能说明 | 示例 |
|---|---|---|
-i |
搜索时忽略大小写(如搜索 "Error" 会匹配 "error""ERROR") | less -i log.txt |
-N |
显示每行的行号(方便定位具体内容) | less -N config.conf |
三、核心交互指令(查看时操作)
进入 less 界面后,通过以下按键实现交互,无需输入命令,直接按键盘即可:
1. 翻页与滚动
PageDown或空格键:向下翻一页;PageUp或b键:向上翻一页;Enter键:向下滚动一行;k键:向上滚动一行;G键 :直接跳转到文件末尾;gg键 :直接跳转到文件开头;50G键:跳转到第 50 行(将 50 替换为任意行号即可)。
2. 双向搜索(核心优势)
/字符串:向下搜索 "字符串"(从当前位置往后找),例如/error搜索所有 "error";?字符串:向上搜索 "字符串"(从当前位置往前找),例如?success反向搜索 "success";n键:重复上一次搜索(顺着之前的方向继续找下一个匹配项);N键:反向重复上一次搜索(逆着之前的方向找匹配项)。
3. 其他实用指令
q键 :退出less,返回命令行(最常用指令);u键:向上滚动半页;d键:向下滚动半页;v键 :在less中直接打开系统默认编辑器(如 Vim)编辑当前文件;:f 键:显示当前文件的文件名、总行数、当前行号等信息。
四、典型应用场景
1. 查看大文件(日志 / 配置)
less 不预先加载整个文件,查看 GB 级日志时不会卡顿,配合行号和搜索功能快速定位问题:
# 显示行号查看系统日志,搜索"warning"
less -N /var/log/syslog
# 进入后输入 /warning 向下搜索,按 n 查看下一个匹配项2. 分页查看命令输出
将复杂命令的输出通过管道传递给 less,避免刷屏:
# 递归列出 /etc 目录下所有文件,分页查看
ls -laR /etc | less -i
# 进入后可搜索关键词,如 /nginx 查找与 Nginx 相关的文件3. 忽略大小写搜索
查看日志时无需纠结大小写,快速匹配所有相关内容:
# 忽略大小写查看应用日志,搜索"timeout"
less -i app.log
# 输入 /timeout 会匹配"Timeout""TIMEOUT"等所有形式五、与 more、cat 的核心区别
| 工具 | 核心优势 | 适用场景 |
|---|---|---|
cat |
一次性输出全部内容 | 小文件快速查看、文件拼接 |
more |
简单分页,上手快 | 临时查看小到大文件,仅需向前翻页 |
less |
前后翻页、双向搜索、低内存占用 | 大文件查阅、复杂搜索定位、日常高频使用 |
less 的设计完全贴合 "高效查阅文件" 的需求,尤其是双向搜索和自由翻页功能,让处理大文件和复杂内容时得心应手。记住核心交互指令(翻页、搜索、退出),就能快速上手,成为 Linux 文件查看的 "效率工具"!,大家以后直接用less就行,嘎嘎好使。
head指令和tail指令:
这两个指令其实也是用于查看文件内容:
head 和 tail 是 Linux 中用于查看文件开头或末尾内容的轻量工具,两者互补,分别聚焦文件的 "头部" 和 "尾部",尤其适合快速预览日志、配置文件等的关键信息,避免查看完整文件的繁琐。以下是详细介绍:
一、head 指令:查看文件开头内容
核心功能
默认显示文件的前 10 行内容,可通过选项指定行数,快速预览文件开头的关键信息(如配置文件的注释、日志的启动记录等)。
语法
head [选项] 文件名常用选项与示例
-
默认用法:显示前 10 行
bashhead file.txt # 输出 file.txt 的前 10 行
-
-n 行数:指定显示的行数(-n可省略,直接写数字)bashhead -n 5 log.txt # 显示 log.txt 的前 5 行 head -3 config.conf # 简写形式,显示前 3 行
-
-c 字节数:按字节数显示(而非行数),适合查看二进制文件或固定长度的头部head -c 100 data.bin # 显示 data.bin 的前 100 个字节 -
查看多个文件:同时显示多个文件的开头,每个文件前会标注文件名
head -n 2 file1.txt file2.txt # 输出示例: # ==> file1.txt <== # line1 of file1 # line2 of file1 # ==> file2.txt <== # line1 of file2 # line2 of file2
二、tail 指令:查看文件末尾内容
核心功能
默认显示文件的最后 10 行内容,支持指定行数,最常用的场景是实时跟踪日志文件的新增内容(如应用运行时的最新输出),使用方法和上面head的使用方法才能到,我就不放示例图了
语法
tail [选项] 文件名常用选项与示例
-
默认用法:显示最后 10 行
tail file.txt # 输出 file.txt 的最后 10 行 -
-n 行数:指定显示的行数(-n可省略,直接写数字)tail -n 5 log.txt # 显示 log.txt 的最后 5 行 tail -3 config.conf # 简写形式,显示最后 3 行 -
-f:实时跟踪文件新增内容("follow"),文件有新内容写入时会自动刷新显示,按Ctrl+C退出tail -f /var/log/syslog # 实时查看系统日志的最新输出(常用于监控应用运行状态) -
-F:比-f更强大,若文件被删除后重新创建,会自动继续跟踪新文件(适合日志轮转场景)tail -F app.log # 即使 app.log 被删除重建,仍能继续跟踪新内容 -
-c 字节数:按字节数显示末尾内容tail -c 50 data.bin # 显示 data.bin 的最后 50 个字节
三、典型组合场景
-
查看文件中间内容 :结合
head和tail提取文件的中间部分# 显示 file.txt 的第 11-20 行(先取前 20 行,再取其中的后 10 行) head -n 20 file.txt | tail -n 10 -
实时监控并过滤日志 :配合
grep只跟踪含特定关键词的新增日志tail -f app.log | grep "error" # 实时显示 app.log 中新增的含"error"的行 -
预览大文件的首尾:快速了解大文件的开头(如格式说明)和末尾(如最新记录)
head -n 5 large_file.log # 查看开头的格式说明 tail -n 5 large_file.log # 查看最新的 5 条记录
四、核心区别与适用场景
| 命令 | 核心作用 | 典型场景 |
|---|---|---|
head |
查看文件开头(默认前 10 行) | 预览配置文件的注释、数据文件的表头 |
tail |
查看文件末尾(默认后 10 行),支持实时跟踪 | 监控日志的最新输出、查看数据文件的最后记录 |
head 和 tail 是 "轻量高效" 的代表,无需加载整个文件即可快速定位关键内容,尤其 tail -f 是运维和开发中监控实时日志的必备技巧。掌握这两个命令,能大幅提升日常文件预览和日志监控的效率!
查看大文件中间内容的数据(管道重定向 |):
OK大家,我们知道,用head只能看头部指定行数的数据,用tail则只能看尾部指定行数的数据,那么如果我们想要看中部指定函数的数据呢?其实这就要用到我们的管道重定向 |了。
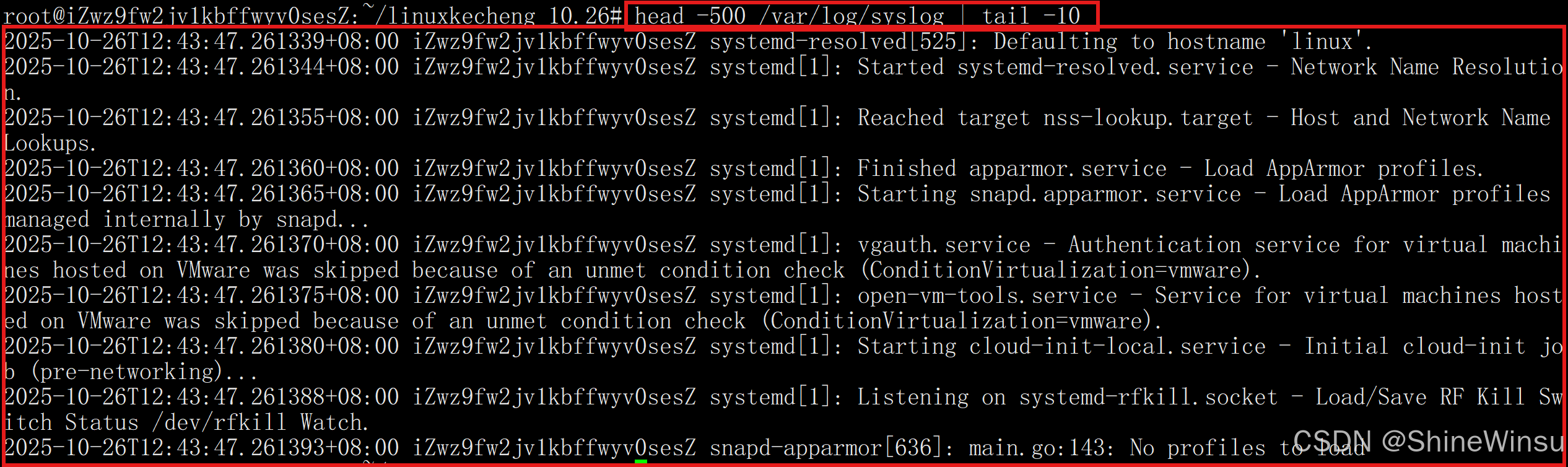
大家可以先看下面这个示例图:
接下来我给大家详细讲一下管道重定向 |:
管道重定向 |:
在 Linux 中,管道重定向 | (竖线符号)是实现命令间数据流转 的核心工具,它能将前一个命令的标准输出(stdout) 直接作为后一个命令的标准输入(stdin),让多个命令像 "流水线" 一样协同工作,完成复杂任务。这种 "组合命令" 的方式是 Linux 命令行高效处理数据的精髓。
一、管道的核心作用与语法
- 核心逻辑:
命令1 | 命令2 | 命令3 ...前一个命令的输出 → 作为后一个命令的输入,依次传递,最终输出处理结果,所以我们要知道,|前后都得是命令才行,命令什么什么|命令什么什么 - 本质:管道就像一根 "数据导管",连接多个命令,避免了中间文件的创建(无需先将命令 1 的输出保存到文件,再让命令 2 读取该文件)。
二、典型用法与场景示例
1. 基础示例:筛选与统计
# 场景:列出当前目录的文件,筛选出以 .txt 结尾的,再统计数量
ls | grep ".txt" | wc -l
# 拆解:
# 1. ls → 输出所有文件/目录名(标准输出)
# 2. grep ".txt" → 接收 ls 的输出,筛选出含 .txt 的行(作为输入)
# 3. wc -l → 接收 grep 的输出,统计行数(即 .txt 文件的数量)2. 进阶示例:日志分析
# 场景:查看系统日志,筛选出 ERROR 级别的记录,按时间排序后显示最后5条
cat /var/log/syslog | grep "ERROR" | sort | tail -n 5
# 拆解:
# 1. cat 读取日志 → 输出所有内容
# 2. grep 筛选含 ERROR 的行
# 3. sort 对结果按行排序(默认按字符顺序,日志通常含时间可自然排序)
# 4. tail 显示最后5条(最新的5个错误)3. 复杂示例:文本处理与格式化
# 场景:从用户信息文件 /etc/passwd 中提取用户名,排除 root,按字母排序
cat /etc/passwd | cut -d ":" -f 1 | grep -v "root" | sort
# 拆解:
# 1. cat /etc/passwd → 输出用户信息(格式:用户名:密码:UID:...)
# 2. cut -d ":" -f 1 → 以 ":" 为分隔符,提取第1列(用户名)
# 3. grep -v "root" → 排除含 root 的行
# 4. sort → 对用户名按字母排序三、管道的关键特性
-
只传递标准输出(stdout) :命令的标准错误(stderr)不会被管道传递 ,默认会直接输出到终端。若需传递错误输出,需先将其重定向到标准输出(
2>&1):# 示例:查找不存在的文件,让错误信息也通过管道被 grep 捕获 find / -name "non_exist" 2>&1 | grep "Permission denied" -
多管道串联:管道可连接任意多个命令,形成 "命令链",每个环节专注处理一部分任务:
# 从日志中提取 IP 地址,去重后统计出现次数,显示前3名 cat access.log | grep -oE "([0-9]+\.){3}[0-9]+" | sort | uniq -c | sort -nr | head -n 3 -
与重定向结合:管道的最终结果可通过输出重定向保存到文件:
# 将筛选后的日志结果保存到 error_summary.log cat /var/log/app.log | grep "CRITICAL" | tee error_summary.log # tee 命令:同时输出到终端和文件(比单纯 > 更灵活)
四、管道与重定向的区别
- 管道
|:连接命令与命令,传递数据(前一个的输出 → 后一个的输入)。 - 重定向
>/>>/<:连接命令与文件,改变数据的来源或去向(命令的输入 / 输出 → 文件)。
管道是 Linux 命令行 "组合思维" 的核心体现 ------ 通过将简单命令按逻辑串联,能快速实现复杂功能,无需编写额外脚本。掌握管道的用法,是从 "单个命令使用" 到 "高效批量处理" 的关键一步,也是 Linux 命令行效率的 "倍增器"!
返回:
OK大家,那我们继续看这个图:
我们上面说了管道的用途,那么其实上面这幅图就等价于我们下面的操作:
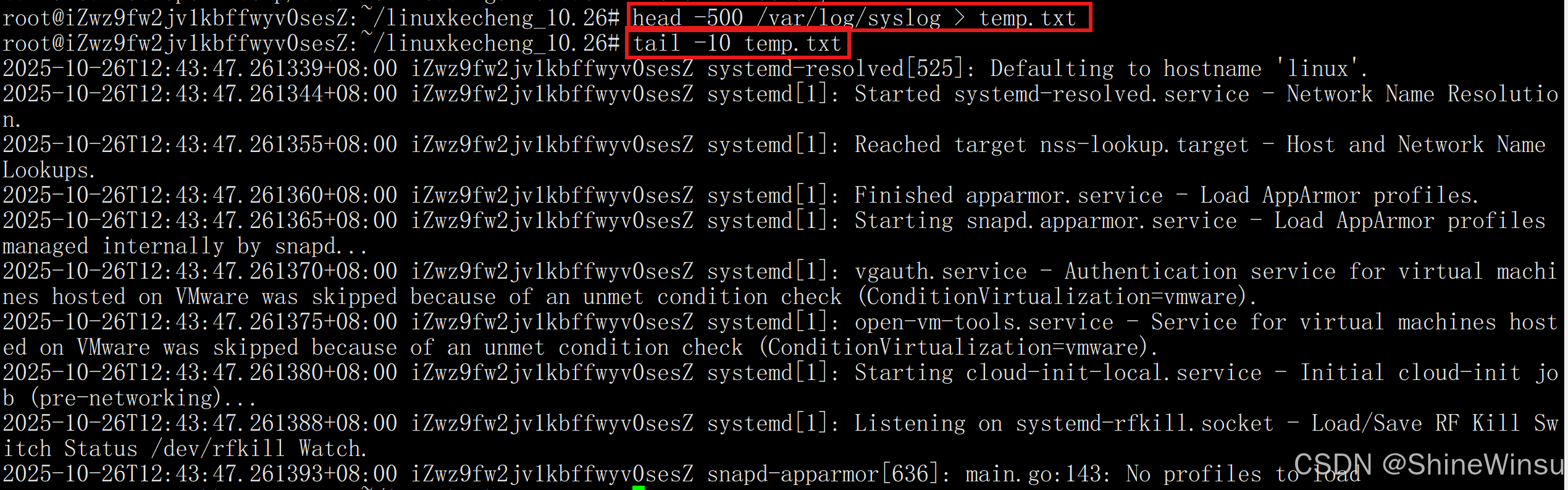
我们是先把日志中前500行都输入给temp.txt这个文件,然后再对这个文件tail后10行,由此得到结果,那么这么一来显然很麻烦,管道重定向|的关键就凸显出来了,大家要是对管道重定向|不是很理解,大家可以先结合着上面那副图进行理解,但是本质上管道重定向|就是个中转站,即管道就像一根 "数据导管",连接多个命令,避免了中间文件的创建(无需先将命令 1 的输出保存到文件,再让命令 2 读取该文件),大家要仔细理解这句话
下面是比较通俗易懂的解释:
咱们可以把管道 | 想象成一根看不见的 "水管",这个水管的作用特别简单:让前一个命令 "吐出来" 的东西,直接 "流进" 后一个命令里,中间不用落地(不用存成文件)。
举个生活中的例子你就明白了:假设你要做一杯 "加冰的橙汁",步骤是:
- 榨橙汁(命令 1:榨出橙汁)
- 过滤渣子(命令 2:过滤掉杂质)
- 加冰块(命令 3:降温调味)
没有管道的话,你得:
- 先把榨好的橙汁倒进一个杯子(存成中间文件);
- 再把杯子里的橙汁倒进过滤器(命令 2 读取中间文件);
- 过滤完再倒进另一个杯子,加冰(命令 3 再读一次中间文件)。
有了管道 | 之后呢?就像用一根水管把榨汁机、过滤器、加冰器串起来:榨汁机榨出的橙汁直接通过水管流进过滤器,过滤完直接流进加冰器,全程不用杯子(中间文件),一步到位。
放到 Linux 命令里,比如你想 "统计当前目录下有多少个 txt 文件":
-
没有管道时,你得:
- 先用
ls > all_files.txt把所有文件名存到文件里; - 再用
grep ".txt" all_files.txt > txt_files.txt筛选出 txt 文件,存到新文件; - 最后用
wc -l txt_files.txt统计这个新文件的行数。
- 先用
-
有了管道
|后,直接写成:ls | grep ".txt" | wc -l
这里的 | 就像三根水管:ls 输出的文件名 → 直接通过 | 流给 grep 筛选 → 筛选后的结果再通过 | 流给 wc -l 统计,全程没有任何中间文件,既省时间又省空间。
总结来说,管道的本质就是:让命令之间 "直接对话",数据在内存里直接传递,跳过存文件、读文件的步骤,就像工厂里的流水线,上一步的产品直接送进下一步加工,效率大大提升。
所以我们在使用|的时候,我们就要自己脑子里模拟一下,是要达到什么效果,以及是需要怎么运行的,这样子才能正确且准确的使用|。
希望大家理解,这个很重要,以后我们会经常使用。
date指令:
date 是 Linux 系统中用于显示或设置系统时间和日期的命令,功能简洁但实用,既能查看当前时间,也能按指定格式输出,还可用于脚本中记录操作时间等场景。以下是详细介绍:
一、核心功能与基本用法
- 核心功能:显示当前系统时间 / 日期,或自定义格式输出,也可修改系统时间(需 root 权限)。
- 基本语法 :
date [选项] [格式]
二、常用场景与示例
1. 显示当前时间(默认格式)
直接输入 date,会以系统默认格式显示当前时间(包含星期、月、日、时间、时区、年):
date
# 输出示例(不同系统可能略有差异):
# Mon Oct 27 15:30:45 CST 2025
# 含义:2025年10月27日 星期一 15:30:45(中国标准时间)2. 自定义时间格式(核心用法)
date 支持通过格式符 自定义输出样式,常用格式符如下(完整格式符可通过 man date 查看):
| 格式符 | 含义 | 示例(当前时间) |
|---|---|---|
%Y |
4 位年份 | 2025 |
%m |
2 位月份(01-12) | 10 |
%d |
2 位日期(01-31) | 27 |
%H |
24 小时制小时(00-23) | 15 |
%M |
分钟(00-59) | 30 |
%S |
秒(00-59) | 45 |
%w |
星期(0-6,0 代表周日) | 1(代表周一) |
%F |
简化日期(等价于 %Y-%m-%d) |
2025-10-27 |
%T |
简化时间(等价于 %H:%M:%S) |
15:30:45 |
示例:
# 显示"年-月-日 时:分:秒"
date +"%Y-%m-%d %H:%M:%S"
# 输出:2025-10-27 15:30:45
# 显示"月/日/年 星期"
date +"%m/%d/%Y 星期%w"
# 输出:10/27/2025 星期1
# 简化写法(用%F和%T)
date +"%F %T"
# 输出:2025-10-27 15:30:453. 显示其他时间(过去 / 未来)
通过 -d 选项可查看相对时间 (如昨天、明天、1 小时前)或指定日期:
# 显示昨天的日期
date -d "yesterday" +"%F"
# 输出:2025-10-26
# 显示明天此时的时间
date -d "tomorrow" +"%F %T"
# 输出:2025-10-28 15:30:45
# 显示1小时后的时间
date -d "+1 hour" +"%H:%M"
# 输出:16:30
# 显示指定日期(2024年1月1日)是星期几
date -d "2024-01-01" +"%w"
# 输出:1(代表周一)4. 设置系统时间(需 root 权限)
普通用户只能查看时间,修改系统时间需用 sudo:
# 设置时间为2025年10月27日 16:00:00
sudo date -s "2025-10-27 16:00:00"
# 单独设置日期
sudo date -s "2025-10-28"
# 单独设置时间
sudo date -s "17:30:00"注意:设置后需同步硬件时钟(避免重启后失效),执行
sudo hwclock -w即可。
5. 脚本中记录时间
在 Shell 脚本中,date 常用于标记操作时间(如日志文件名):
#!/bin/bash
# 创建含当前时间的日志文件
log_file="backup_$(date +%Y%m%d_%H%M%S).log"
echo "备份开始于 $(date +%F %T)" > $log_file三、总结
date 命令的核心价值在于时间的灵活展示与控制:
- 日常使用中,通过自定义格式可快速获取需要的时间样式(如
date +%F查看简洁日期); - 脚本中,结合相对时间和格式符能实现自动化时间记录;
- 管理员可通过
-s选项校准系统时间。
简单几句命令,就能轻松掌控系统的 "时间维度",是 Linux 中不可或缺的基础工具。
时间戳:
时间戳本质是 从「1970 年 1 月 1 日 00:00:00 UTC」(Unix 纪元时间)到某个时间点的总秒数,是计算机存储和传递时间的 "通用语言"。
核心特点
- 无格式、无时区:就是一串数字(如 1755000000),避免了 "年 / 月 / 日" 格式混乱和时区差异问题。
- 跨系统通用:所有操作系统、编程语言都支持,方便数据交互(比如日志同步、接口通信)。
Linux 中常用操作
-
查看当前时间戳(用
date +%s):date +%s
输出示例:1755012345(代表当前时间距离Unix纪元的总秒数)
-
时间戳转成可读时间(用
date -d @时间戳):date -d @1755012345
输出示例:Wed Jul 16 10:05:45 CST 2025(转成当地可读时间)
-
自定义格式转换:
date -d @1755012345 +"%Y-%m-%d %H:%M:%S"
输出:2025-07-16 10:05:45
简单说,时间戳就是计算机的 "时间身份证",一串数字就能精准定位某个时刻,不用纠结格式和时区~
cal指令:
cal 是 Linux 中用于快速查看公历日历的命令,无需打开额外工具,就能直观展示月历、年历或指定日期的日历信息,用法简单且实用性强。以下是详细介绍:
一、核心功能与基本语法
- 核心功能:显示指定月份、年份的日历,或当前系统的日历(默认显示当月)。
- 语法 :
cal [选项] [月份] [年份]- 无参数 / 选项:默认显示当前月的日历;
- 1 个参数:若为数字(1-9999),显示该年份的全年日历;
- 2 个参数:分别表示 "月份 年份",显示指定年月的日历(如
cal 10 2025显示 2025 年 10 月)。
二、常用选项与实战示例
1. 基础用法:查看当前月日历
cal
# 输出示例(2025年10月,会标注当前日期,通常用星号或高亮显示):
# October 2025
# Su Mo Tu We Th Fr Sa
# 1 2 3 4 5
# 6 7 8 9 10 11 12
# 13 14 15 16 17 18 19
# 20 21 22 23 24 25 26
# 27 28 29 30 312. 选项 -3:显示近三个月日历
同时展示上一个月、当前月、下一个月的日历,方便查看相邻月份的日期关联:
cal -3
# 输出会包含 2025年9月、10月、11月 三个月的日历3. 选项 -j:显示日期对应的 "年内天数"
将日历中的日期替换为 "当年的第几天"(从 1 月 1 日开始计数):
cal -j # 显示当月日期对应的年内天数
# 输出示例(10月1日是当年第274天):
# October 2025
# Su Mo Tu We Th Fr Sa
# 274 275 276 277 278
# 279 280 281 282 283 284 285
# ...4. 选项 -y:显示当前年份的全年日历
一次性展示一整年的 12 个月日历,适合快速查阅全年日期:
cal -y
# 输出2025年1-12月的完整日历,按月份排列5. 查看指定年月 / 年份的日历
# 查看2024年5月的日历(参数顺序:月份 年份)
cal 5 2024
# 查看2026年的全年日历(1个参数表示年份)
cal 2026三、注意事项
- 年份范围限制:支持 1-9999 年的日历查询,超出范围会提示 "无效年份";
- 月份参数:若输入两个参数,第一个必须是 1-12 的有效月份,否则报错;
- 日期标注:默认会用特殊符号(如
*)标注当前系统日期,直观识别当天。
cal 命令的核心价值是 "快速便捷",无论是日常查日期、规划行程,还是脚本中获取日历信息,都能一键完成,是 Linux 中最实用的 "小工具" 之一。
OK大家,到了这里,我们再暂做休息一下,下篇博客再继续对Linux基础指令的了解。
结语:
亲爱的朋友们,当你看到这里时,我们已经一同走过了 Linux 基础指令的大半旅程。从切换目录的cd、创建目录的mkdir,到删除文件的rm、复制移动的cp与mv,再到查看内容的cat、less,以及灵活高效的重定向、管道和时间管理命令,每一个指令都像是 Linux 世界里的一把钥匙,为我们打开了通往高效文件管理与系统操作的大门。这段旅程或许充满了陌生的语法和繁琐的参数,但我相信,当你亲手敲下命令、看到预期结果的那一刻,所有的疑惑都会化为豁然开朗的喜悦,所有的付出都将沉淀为扎实的技术底气。
回顾这段学习历程,我们不仅掌握了一个个孤立的指令,更理解了 Linux 系统的核心设计哲学。"一切皆文件" 的理念贯穿始终,让我们明白无论是硬件设备、目录文件,还是进程网络,都能通过统一的接口进行管理,这种简洁而强大的设计思维,正是 Linux 能够在服务器、嵌入式等领域占据核心地位的关键。而重定向与管道的组合使用,更让我们见识到 Linux "组合拳" 的魅力 ------ 无需复杂脚本,只需将简单指令串联起来,就能完成批量处理、日志分析等复杂任务,这种高效务实的设计,恰恰是技术人最值得借鉴的思维方式。
在学习过程中,我们难免会遇到各种 "坑":用rm -rf时担心误删重要文件,用cp复制目录时忘记加-r选项报错,用管道筛选内容时搞不清命令执行顺序...... 但这些 "坑" 恰恰是成长的阶梯。每一次报错都是一次提醒,每一次调试都是一次进步。就像我们在使用man命令查询帮助时会发现,即使是最基础的指令,也隐藏着许多未曾探索的功能;就像我们在实践tree指令时,会惊叹于目录结构的清晰呈现所带来的便捷 ------Linux 的学习从来不是一蹴而就的,它需要我们在实践中不断摸索、在使用中持续深化。
或许有朋友会觉得,这些基础指令太过简单,不值得花费大量时间钻研。但请相信,任何高深的技术都离不开扎实的基础。就像盖房子一样,只有地基打得牢固,才能支撑起高耸的楼宇。在实际工作中,无论是服务器运维、脚本编写,还是开发环境配置,这些基础指令都是我们每天都会用到的 "基本功"。当你能够熟练运用find结合管道快速定位文件,能够用date和时间戳精准记录日志,能够用cal规划工作行程时,你会发现自己的工作效率得到了质的提升;当你在面试中能够清晰解释rm与rmdir的区别、more与less的优劣时,你会明白这些基础知识点正是拉开差距的关键。
学习 Linux 的过程,就像是一场修行。它没有捷径可走,唯有 "多敲、多练、多思考"。不要害怕犯错,每一次错误都是一次宝贵的经验;不要满足于 "会用",要深究 "为什么这么用";不要局限于课本上的示例,要尝试在实际场景中灵活运用。比如,在整理个人文件时,用mkdir -p创建多级目录分类存储;在分析日志时,用grep+awk+sort组合筛选关键信息;在备份数据时,用cp -p保留文件属性确保数据完整 ------ 把学到的指令融入日常使用,让技术服务于实际需求,这才是学习的真正意义。
同时,Linux 的学习也是一个 "循序渐进" 的过程。我们今天掌握的这些基础指令,只是 Linux 知识体系的冰山一角。接下来,我们还会接触到权限管理、用户配置、进程控制等更深入的内容,而这些内容都需要以今天的基础为前提。就像cd指令是我们探索目录的起点,这些基础指令也是我们通往 Linux 高阶学习的起点。请保持这份探索的热情和求知的欲望,就像我们用head和tail查看文件内容时,既关注开头的关键信息,也不忽视结尾的重要记录,在 Linux 的学习之路上,既要仰望星空,也要脚踏实地。
还要提醒大家的是,Linux 的社区文化是开放而包容的。当你遇到问题时,除了用man命令查询官方帮助,还可以在 Stack Overflow、Linux 中国等平台寻求答案;当你发现了新的用法或技巧时,也可以分享给身边的朋友,在交流中共同进步。技术的价值不仅在于解决问题,更在于传递与分享。就像echo指令既能输出信息,也能通过重定向传递数据,我们在学习技术的同时,也要学会传递知识、分享经验,在互助中成长,在交流中提升。
亲爱的朋友们,这段 Linux 基础指令的学习之旅暂时告一段落,但这绝不是终点,而是新的起点。接下来,我们还会继续探索更多 Linux 的奥秘,解锁更多实用的技巧和工具。或许未来的学习之路会更加艰难,但请相信,你今天付出的每一份努力,都会在未来的某一天给予你回报;你今天打下的每一个基础,都会成为你未来驰骋技术海洋的底气。
请记住,技术的学习是一个持续迭代的过程。就像 Linux 系统会不断更新升级一样,我们的知识体系也需要不断补充完善。保持好奇心,保持求知欲,保持对技术的热爱,在 Linux 的世界里不断探索、不断前行。相信终有一天,你会感谢今天这个努力的自己;相信终有一天,你也能成为别人口中 "精通 Linux" 的技术大牛。
最后,祝愿每一位朋友都能在 Linux 的学习之路上收获满满,都能将学到的技术运用到实际工作和生活中,都能在技术的海洋中找到属于自己的方向。让我们以这些基础指令为起点,带着热情与坚持,继续深耕细作,筑牢技术之路,未来可期,一起加油!