当你的朋友推荐餐厅时,你已经在进行贝叶斯推理------只是你没意识到而已
引言:为什么82%的医生会答错?
在医学教育中有一个经典案例:当医生们面对乳腺癌筛查问题时,82%的人给出了错误答案。
问题是这样描述的:1%的女性患有乳腺癌,筛查测试的灵敏度为80%(真阳性率),假阳性率为9.6%。
如果一位女性检测结果为阳性,她实际患病的概率是多少?
大多数医生回答70-80%,而正确答案仅为7.8%。这个巨大的认知差距不是医生的错,而是因为我们被训练用频率主义 思维思考,而不是贝叶斯思维。
本文将深入技术底层,从源码实现和算法架构的角度,揭示贝叶斯方法如何从简单的概率公式演变为现代人工智能的核心引擎。
一、贝叶斯定理:从公式到代码
1.1 数学本质
贝叶斯定理的数学表达非常简单:
P(A∣B)=P(B)P(B∣A)P(A)
但这个简洁的公式背后,隐藏着深刻的哲学转变:频率主义问"数据有多奇怪",而贝叶斯问"假设有多可信" 。
1.2 源码实现:朴素贝叶斯分类器
让我们通过代码来理解贝叶斯定理的实际运作。以下是一个基于NumPy的朴素贝叶斯训练实现 :
python
def nb_fit(X, y):
# 获取所有类别
classes = y[y.columns[0]].unique()
# 计算类先验概率 P(y)
class_count = y[y.columns[0]].value_counts()
class_prior = class_count / len(y)
# 计算类条件概率 P(x|y)
prior = dict()
for col in X.columns:
for j in classes:
p_x_y = X[(y==j).values][col].value_counts()
for i in p_x_y.index:
prior[(col, i, j)] = p_x_y[i] / class_count[j]
return classes, class_prior, prior这段代码揭示了贝叶斯学习的本质:统计频率。它计算每个类别出现的概率(先验),以及每个特征在给定类别下出现的概率(似然)。这正是贝叶斯定理的"学习"阶段。
预测阶段的实现更直观地展示了贝叶斯公式的应用 :
python
def predict(X_test):
res = []
for c in classes:
p_y = class_prior[c] # 先验 P(y)
p_x_y = 1
for i in X_test.items():
# 条件独立假设:朴素贝叶斯的核心
p_x_y *= prior[tuple(list(i)+[c])] # 似然 P(x|y)
# 后验 ∝ 先验 × 似然
res.append(p_y * p_x_y)
return classes[np.argmax(res)] # 最大后验概率这里的关键是条件独立假设:特征之间相互独立。
这正是 "朴素" 二字的来源------虽然现实中特征往往相关,但这个假设大大简化了计算。
二、概率图模型:从朴素到贝叶斯网络
朴素贝叶斯的条件独立假设过于严格,现实世界中的变量往往存在复杂的依赖关系。
贝叶斯网络 (Bayesian Networks)通过有向无环图(DAG)来建模这种依赖关系 。
2.1 架构设计
贝叶斯网络的架构可以用以下公式表示:
P(X1,X2,...,Xn)=∏i=1nP(Xi∣Parents(Xi))
这个公式的优雅之处在于它将联合概率分解为局部条件概率的乘积。
下图展示了一个简单的贝叶斯网络结构 :
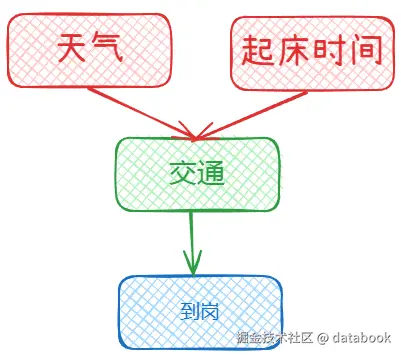
在这个网络中,每个节点都有其条件概率表(CPT):
| 天气 | 概率 |
|---|---|
| 晴 | 0.2 |
| 雨 | 0.8 |
| 起床时间 | 概率 |
|---|---|
| 早 | 0.95 |
| 晚 | 0.05 |
| 天气 | 起床时间 | 交通堵塞概率 |
|---|---|---|
| 晴 | 早 | 0.05 |
| 晴 | 晚 | 0.3 |
| 雨 | 早 | 0.4 |
| 雨 | 晚 | 0.9 |
2.2 推理算法实现
贝叶斯网络中的推理本质上是在给定证据的情况下计算后验概率。
一个朴素但直观的精确推理算法如下:
python
def exact_inference(bn, query_vars, evidence):
# 1. 计算所有因子的乘积
joint_factor = product_of_all_factors(bn)
# 2. 以证据为条件
conditioned_factor = condition(joint_factor, evidence)
# 3. 边缘化隐藏变量
marginalized = marginalize(conditioned_factor, hidden_vars)
# 4. 归一化得到后验分布
posterior = normalize(marginalized)
return posterior这个算法的核心是三种因子操作 :
因子乘积:组合两个因子,生成更大的联合分布
python
def factor_product(phi, psi):
# phi(X,Y) * psi(Y,Z) -> phi_psi(X,Y,Z)
# (phi * psi)(X,Y,Z) = phi(X,Y) * psi(Y,Z)
pass因子边缘化:对特定变量求和,将其从结果范围中删除
python
def factor_marginalization(phi, variable):
# 对variable的所有可能取值求和
result = {}
for assignment in phi.table:
if variable not in assignment:
result[assignment] += phi.table[assignment]
return result因子条件化:根据证据删除不一致的行
python
def factor_conditioning(phi, evidence):
# 删除与evidence不一致的行
result = {}
for assignment, prob in phi.table.items():
if matches_evidence(assignment, evidence):
result[assignment] = prob
return normalize(result)2.3 解释抵消(Explaining Away)
贝叶斯网络中最有趣的现是解释抵消 。考虑地震和盗窃都可能导致报警器响:
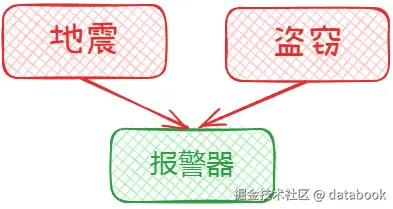
计算表明 :
python
# 参数设置
p_b = p_e = 0.05 # 先验概率
# 报警器响的概率
p_a = 0.05 * 0.95 + 0.05 * 0.95 + 0.05**2 = 0.0975
# 已知报警器响,盗窃的概率
p_b_given_a = (0.05 * 1) / 0.0975 ≈ 0.51
# 但如果同时知道地震发生了
p_b_given_a_e = 0.05 # 盗窃概率回落到先验水平!这就是 "解释抵消":一旦知道一个原因,另一个原因的可能性就会下降。
三、近似推理:当精确计算变得不可能
随着变量数量增加,精确推理的复杂度呈指数级增长。对于超过一定规模的网络,我们必须采用近似方法 。
3.1 MCMC:马尔科夫链蒙特卡罗
MCMC的核心思想不是计算后验分布,而是从中采样 。
以下是吉布斯采样(Gibbs Sampling)的简化实现 :
python
def gibbs_sampling(bn, evidence, num_samples):
# 初始化:随机赋值所有变量
current = random_assignment(bn)
samples = []
for i in range(num_samples):
for each variable v:
# 计算v的条件分布,保持其他变量不变
dist = conditional_distribution(v, current, bn)
# 从该分布中采样新值
current[v] = sample_from(dist)
# 保存当前样本
samples.append(current.copy())
return samplesMCMC的魔法在于:经过足够多的迭代后,采样分布会收敛到真实的后验分布。
3.2 变分推理:将推理转化为优化
变分推理提供了另一种思路 :通过最小化KL散度来近似后验分布。
KL(Q∣∣P)=∑QlogPQ
这个优化视角将贝叶斯推理重新解释为 :
plain
目标 = 最小化 [KL(Q||先验) - E_Q[log似然]]这种观点巧妙地将贝叶斯推理与机器学习中的风险最小化框架统一起来。
3.3 贝叶斯优化:黑盒函数优化
贝叶斯优化是贝叶斯方法在工程中的典型应用,用于优化表达式未知的函数 。其核心流程如图:
plain
初始化采样点 → 高斯过程回归 → 构造采集函数 → 确定下一个采样点 → 迭代高斯过程回归(GPR)的预测公式 :
μ(x)=k(x)TK−1f(X)
σ2(x)=k(x,x)−k(x)TK−1k(x)
其中采集函数UCB(Upper Confidence Bound)的典型形式为:
UCB(x)=μ(x)+κσ(x)
这个公式巧妙地平衡了探索 (高σ区域)和利用(高μ区域)。
四、现代应用:贝叶斯深度学习
将贝叶斯方法与深度学习结合,可以获得不确定性估计这一关键能力 。
4.1 贝叶斯神经网络
传统神经网络给出点估计(固定权重),而贝叶斯神经网络估计权重的分布:
python
# 传统神经网络
y = f(Wx + b) # W是固定值
# 贝叶斯神经网络
W ~ Normal(μ_W, σ_W) # 权重是分布
y = f(Wx + b) # y也是分布最常见的先验是权重矩阵上的单位高斯分布 。这种设置让我们不仅能得到预测值,还能知道预测的置信度。
4.2 PyMC3实现示例
使用PyMC3进行贝叶斯推断的代码非常直观 :
python
import pymc3 as pm
with pm.Model():
# 先验:进球率λ服从Gamma分布
lambda_ = pm.Gamma('lambda', alpha=1.4, beta=1)
# 似然:进球数服从泊松分布
goals = pm.Poisson('goals', mu=lambda_, observed=data)
# 后验采样
trace = pm.sample(1000)
# 后验预测分布
ppc = pm.sample_posterior_predictive(trace)这段代码展示了贝叶斯工作流的完整循环:先验 → 数据 → 后验 → 预测。
五、技术洞察:贝叶斯方法的工程价值
5.1 不确定性量化
传统机器学习模型往往过于自信。贝叶斯方法天然提供不确定性估计,这在以下场景至关重要:
- 医疗诊断:知道模型"不确定"比给出错误答案更重要
- 自动驾驶:在不确定时请求人工干预
- 金融风控:量化预测的置信区间
5.2 小样本学习
贝叶斯方法通过先验知识,能在数据稀缺时依然做出合理推断。
这正是"先验"的工程价值------注入领域知识,减少对数据的依赖。
5.3 在线学习
贝叶斯的迭代性质(今天的后验是明天的先验)完美适配在线学习场景:
plain
prior_{t+1} = posterior_t这种特性使得贝叶斯方法在推荐系统、实时广告竞价等场景中表现优异。
结语:从直觉到工程
回顾开篇的医生问题,如果我们用自然频率思考,一切变得简单:1000名女性中,10人患病(8人阳性),990人未患病(95人假阳性),阳性总数103人,真正患病的只有8人。
这个简单的计数过程,本质上就是贝叶斯定理。而本文展示的各类算法------从朴素贝叶斯的几行代码,到贝叶斯网络的图模型,再到MCMC和变分推理的复杂数学------都是这个简单思想的延伸和应用。
正如一位研究者所言:"贝叶斯方法的概念非常简单,它的核心是贝叶斯定理。这个定理已经250多年了,但结合现代计算技术,它焕发出新的活力" 。
在数据科学和人工智能领域,贝叶斯思维不仅是一种统计工具,更是一种思考方式------它教会我们保持谦逊,拥抱不确定性,并根据新证据持续更新信念。