一. Pandas 介绍
- Pandas 是基于NumPy的一种工具,该工具是解决数据分析 任务而创建的,Pandas 提供了大量能使我们快速便捷地处理数据的功能。
- Pandas 与出色Jupyter 工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的。
- Pandas 的主要数据结构是Series (一维数据)与DatabaseFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域的大多数案例。
- 处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化、Pandas是处理数据的理想工具。
环境安装:
- Anaconda环境:无需安装
- 普通Python环境:pip install padas -i https://pypi.tuna.tsinghua.edu.cn/simple
二. Series (一维数据)
Series是一种类似于一维数组的数据结构(对象),由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
2.1 Series的创建
两种创建方式:
(1). 由列表或者NumPy数组创建
默认索引为0到N - 1的整数型索引
(2).由字典创建
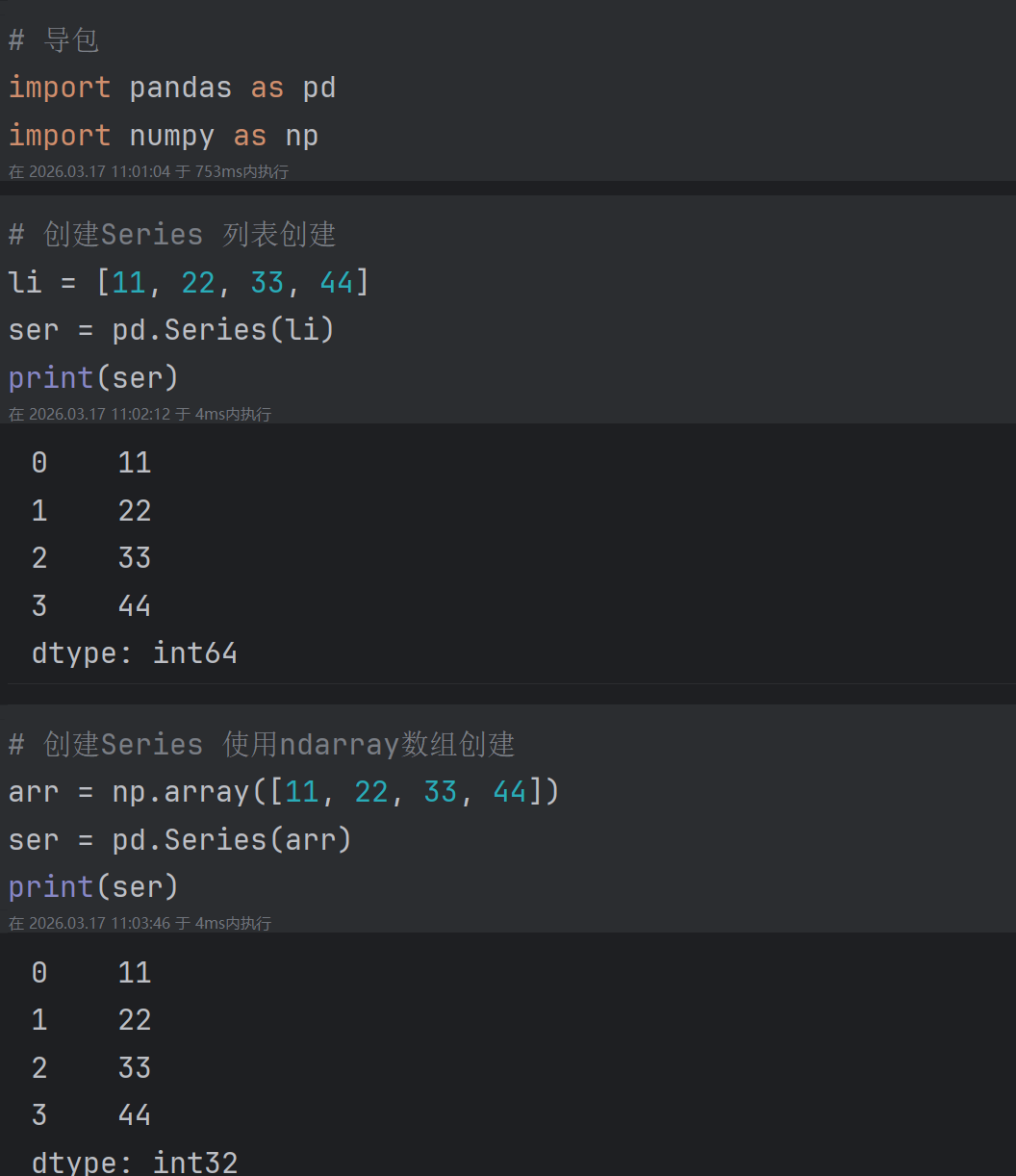
2.1.1 由列表或者NumPy数组创建
代码演示1:
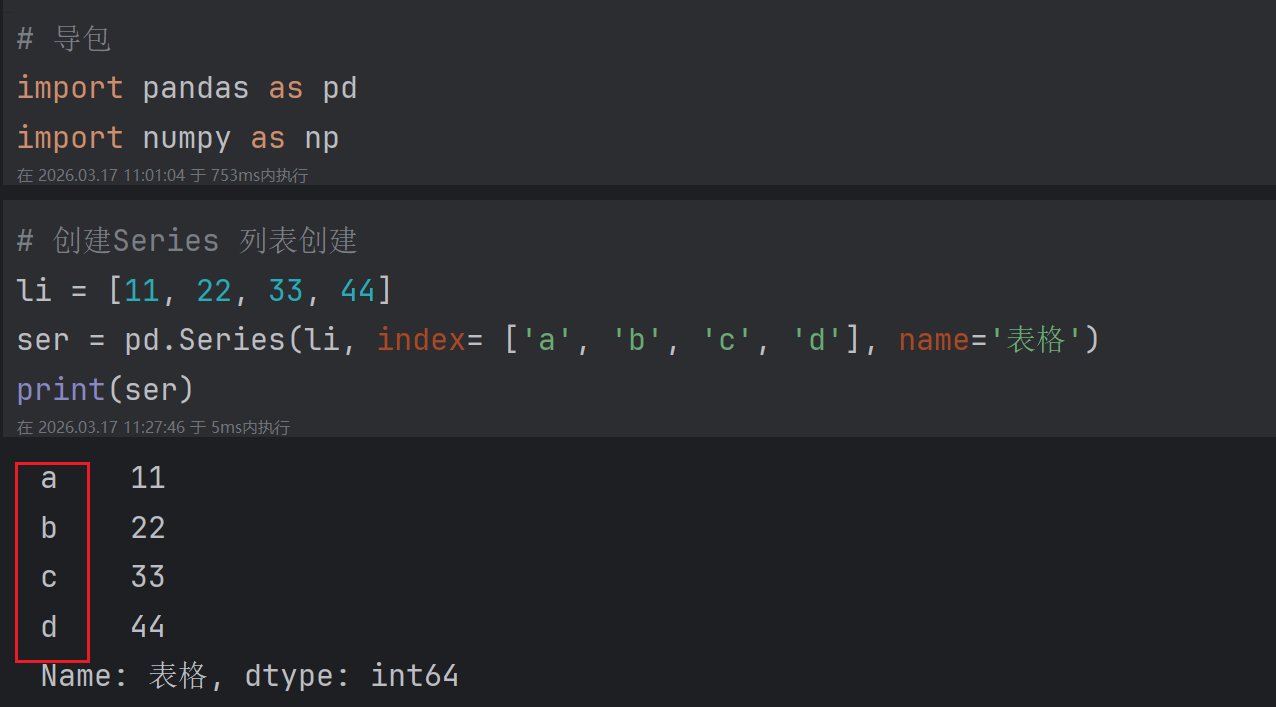
代码演示2:
Series():在创建的时候,还可以传入很多的参数 最常用的是index在创建时候指定索引,如果不指定则默认为 0... n - 1。
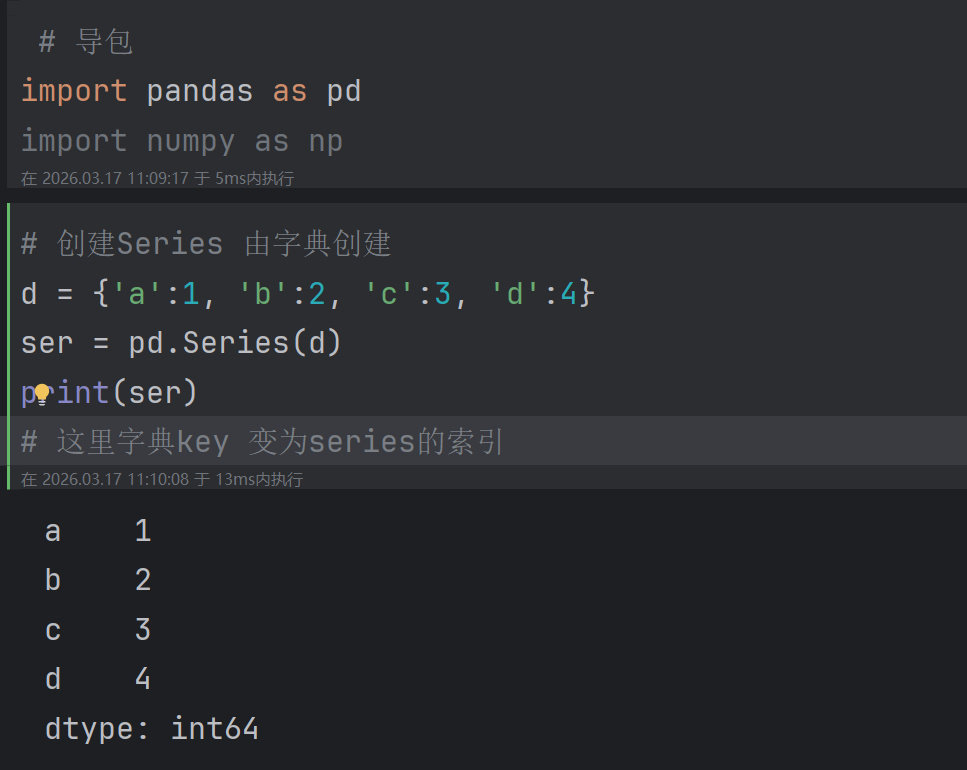
2.1.2 由字典创建
代码演示:
2.1.3 series的两个属性
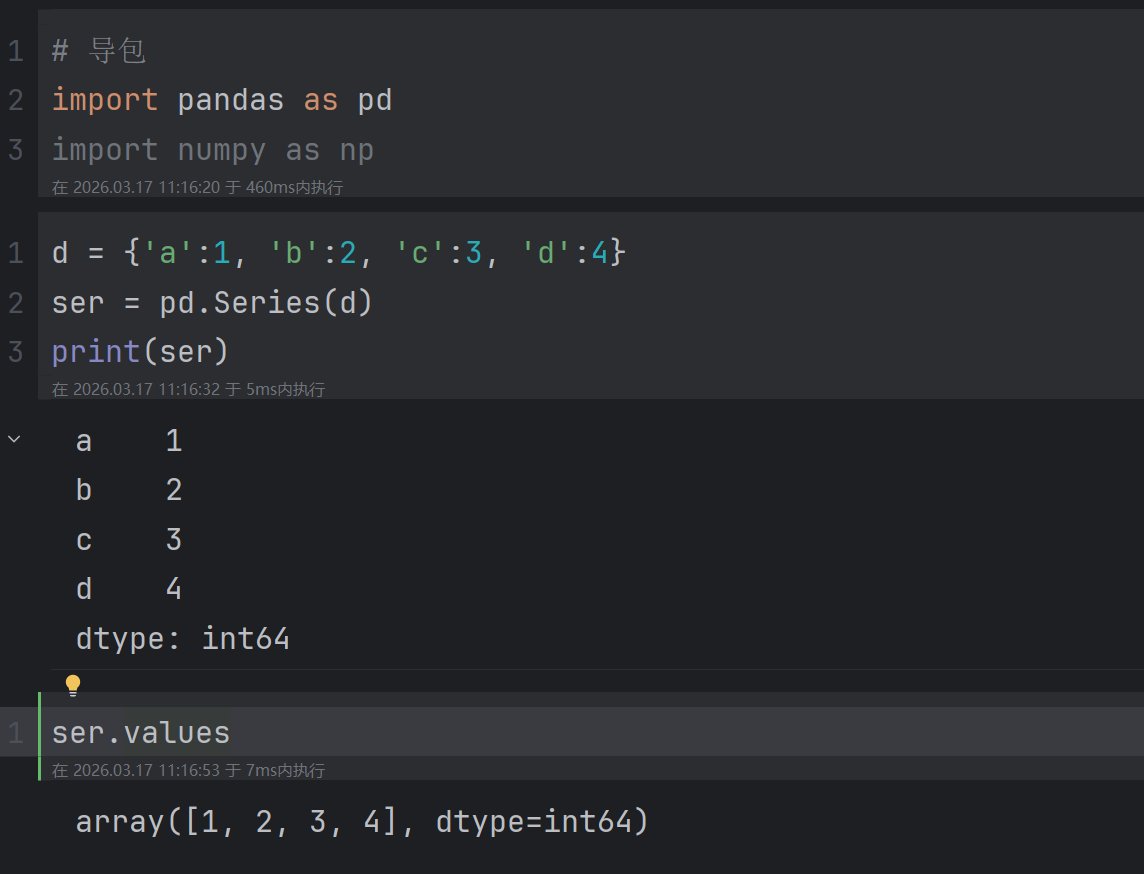
2.1.3.1 values
作用: 返回 Series 中的数据,格式为 NumPy 数组(ndarray)
2.1.3.2 index
作用: 返回 Series 的索引(标签),格式为 Pandas Index 对象
2.2 Series的索引
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的仍然是一个Series类型)。分为显示索引和隐式索引。
2.2.1 显示索引
- 使用index中的元素作为索引值
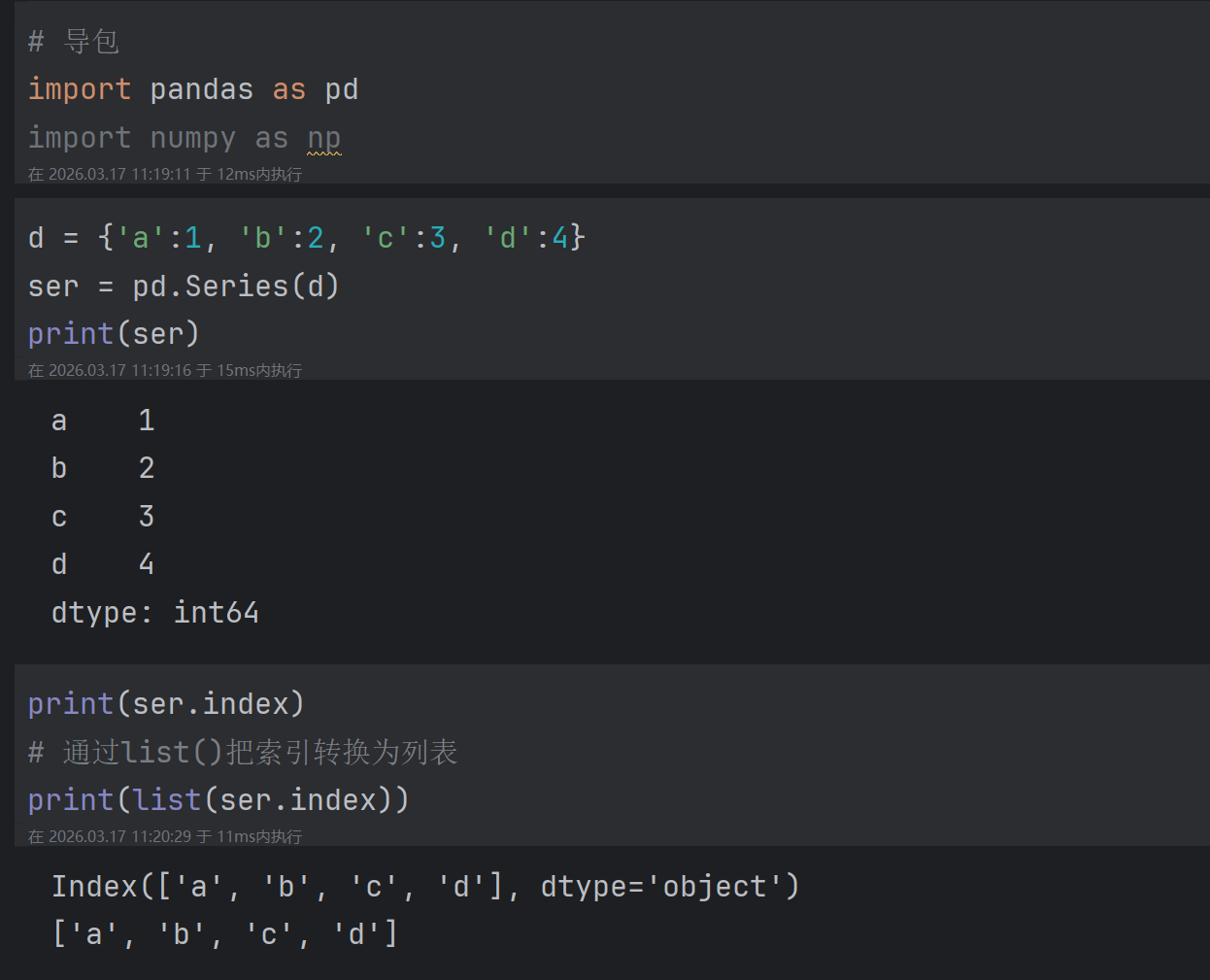
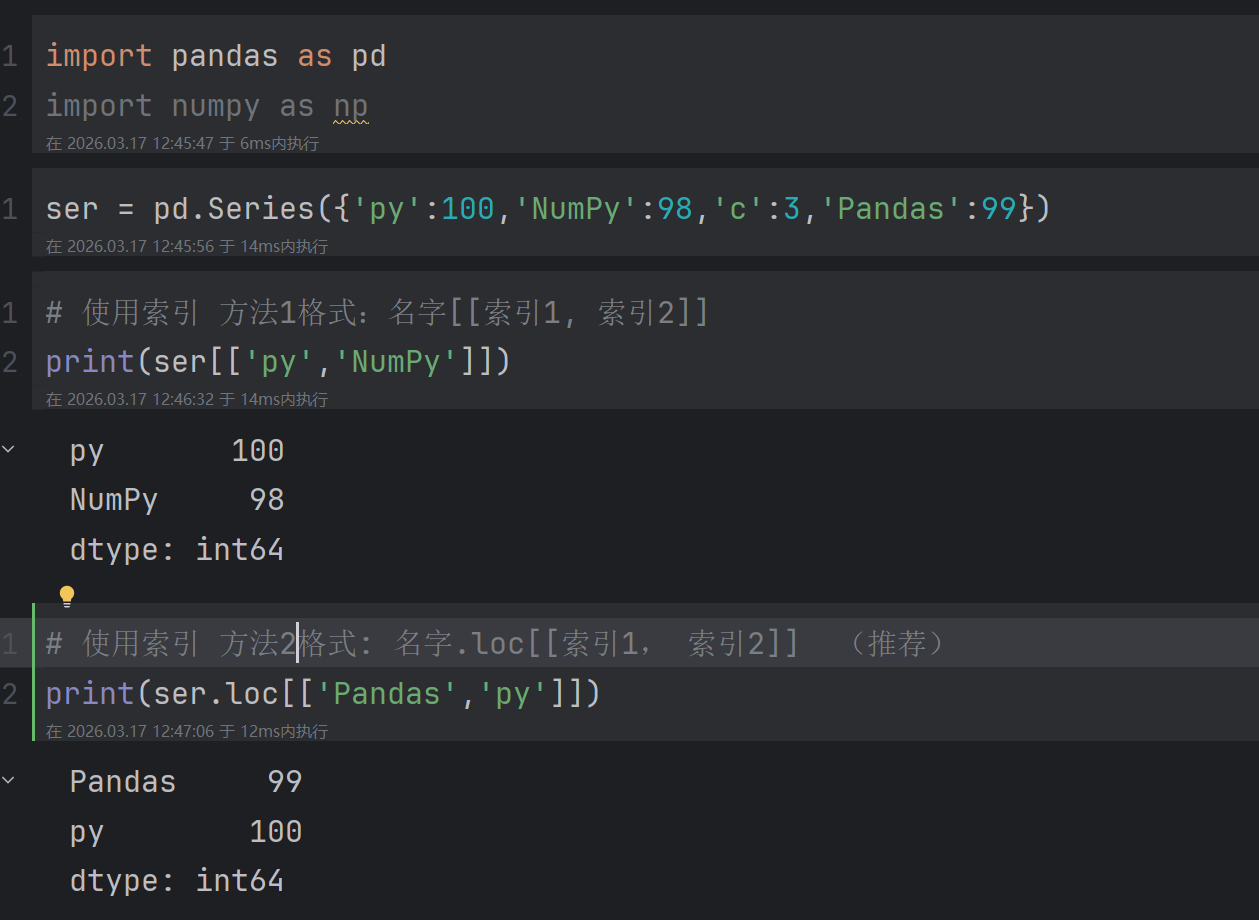
- 使用.loc\[\] (推荐)
2.2.1.1 通过索引取单个元素
2.2.1.2 索引同时取出多个元素
注意:返回的元素类型为Series
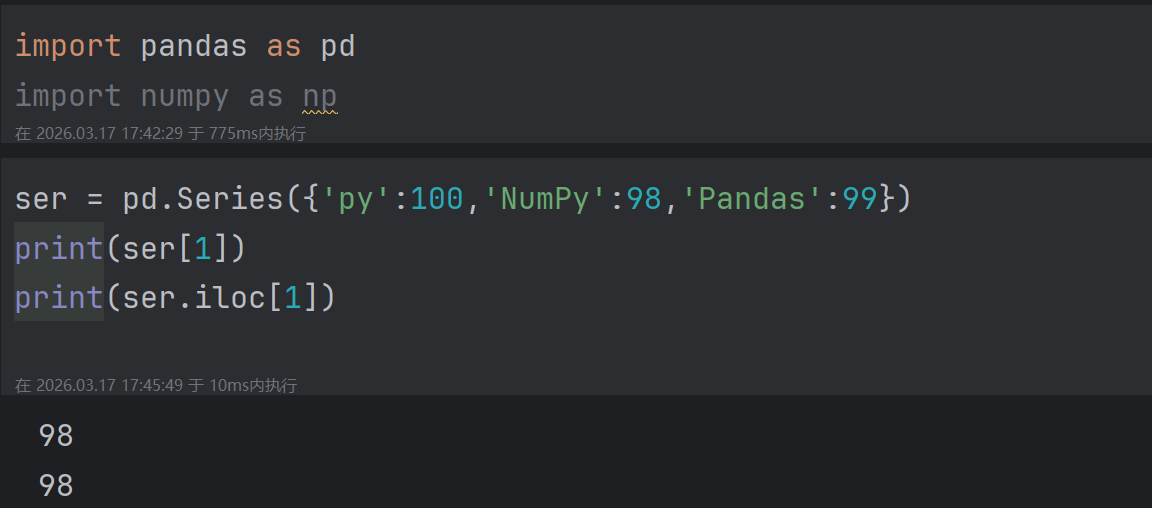
2.2.2 隐式索引
隐式索引是指 Pandas 自动生成的默认整数索引 ,从 0 开始,到
n-1结束(n是数据个数)。也叫默认索引 或位置索引。
2.2.2.1 通过索引取单个元素
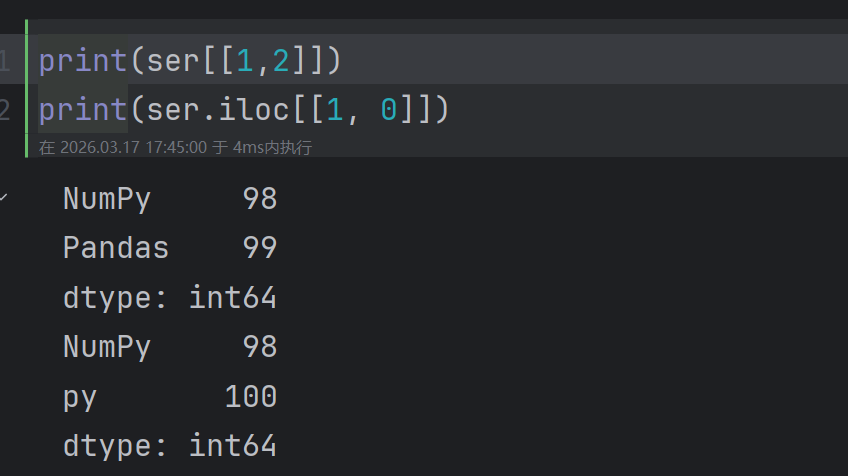
2.2.2.2 索引同时取出多个元素
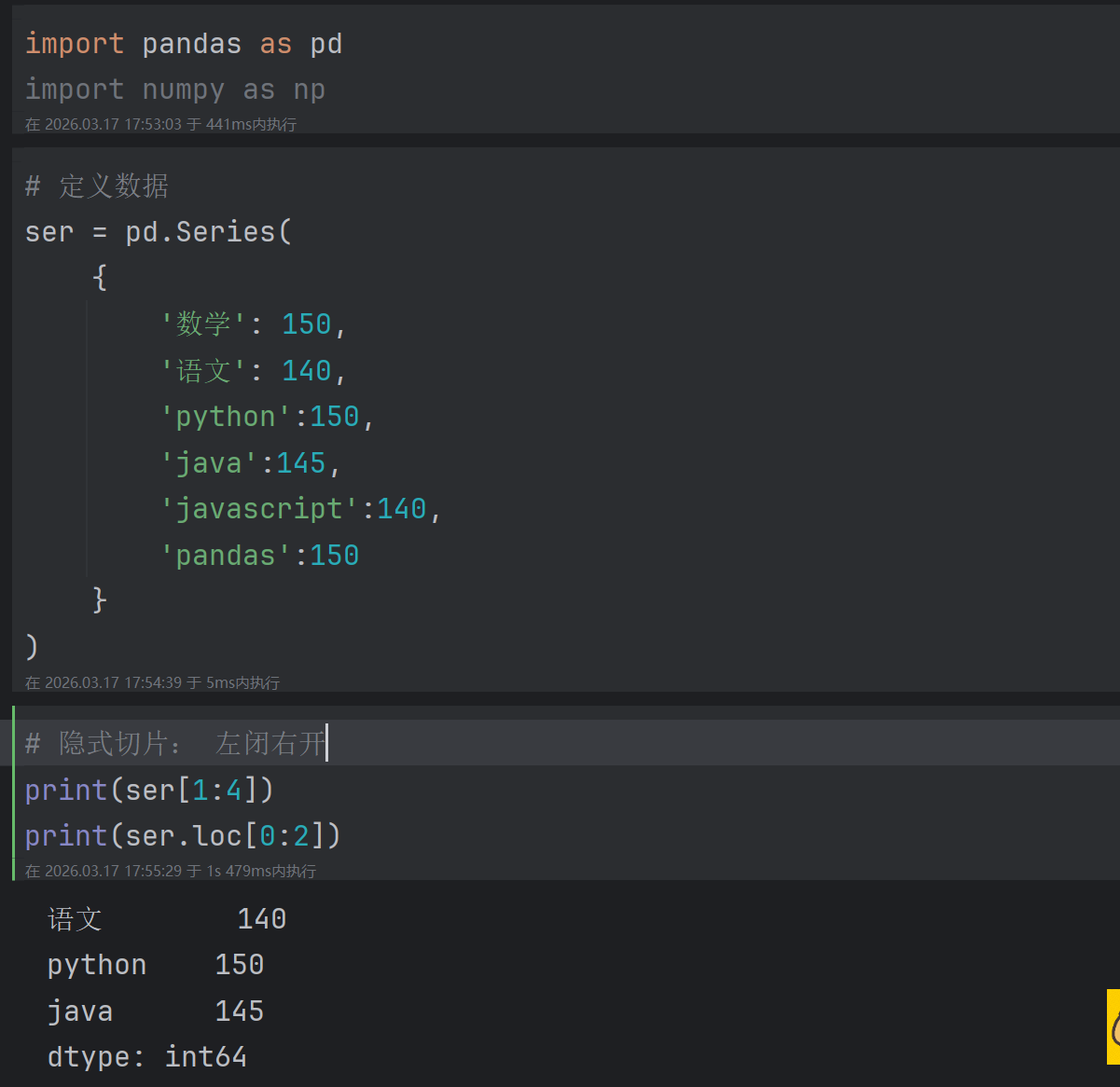
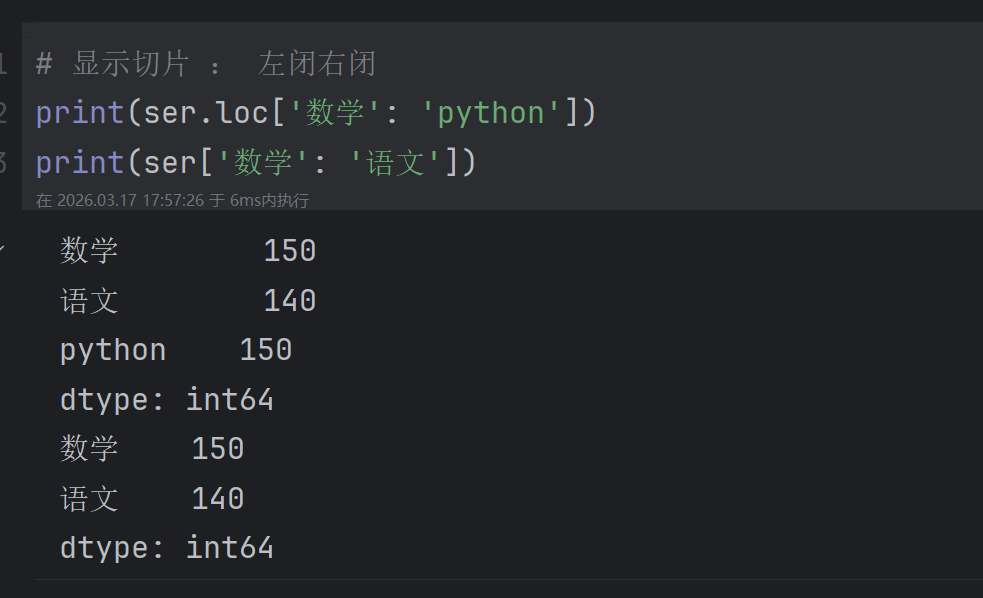
2.3 Series显示切片和隐式切片
这里就类比列表的切片进行学习即可。
 2.4 Series的基本属性
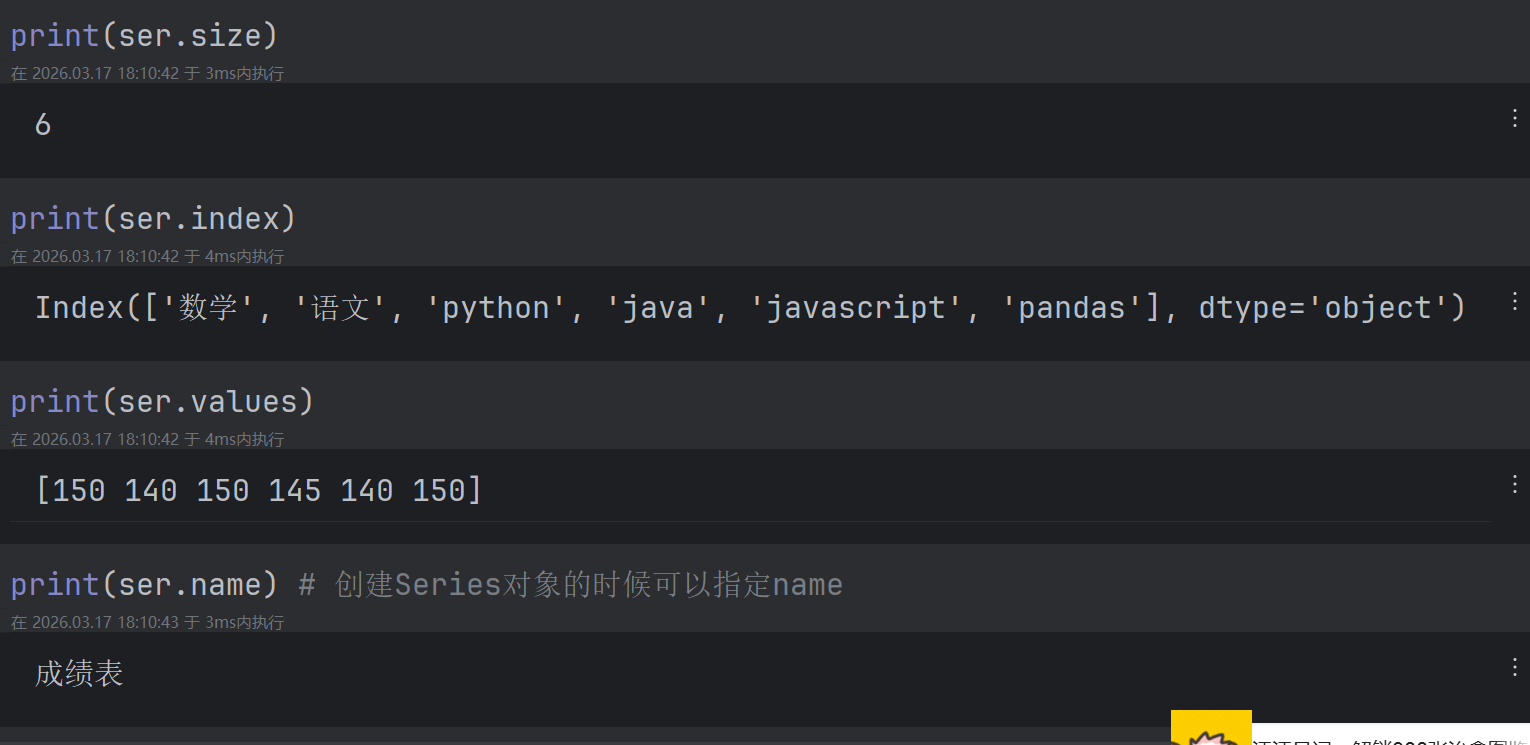
2.4 Series的基本属性
- shape - 形状
- size - 长度
- index - 索引
- values - 值
- name - 名字
逐个代码演示: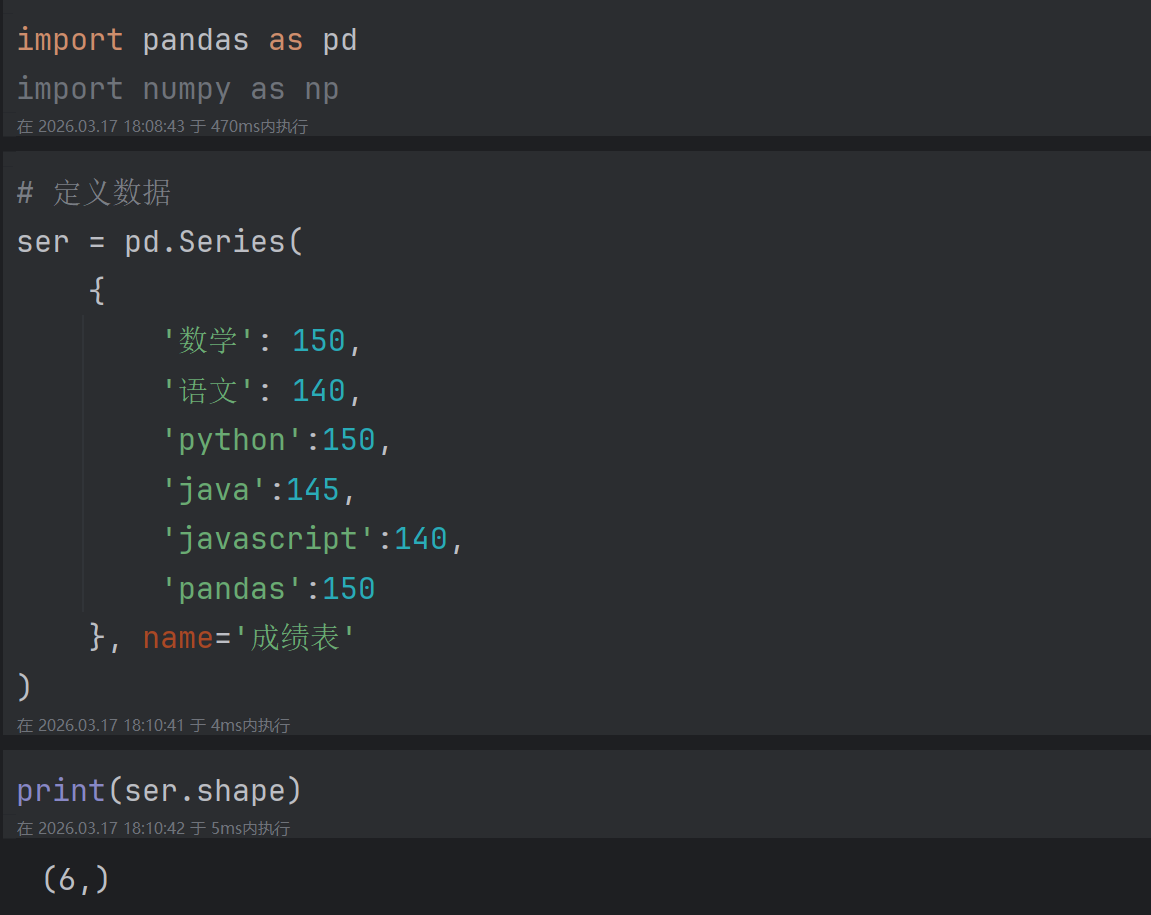
2.5 Serives的基本方法
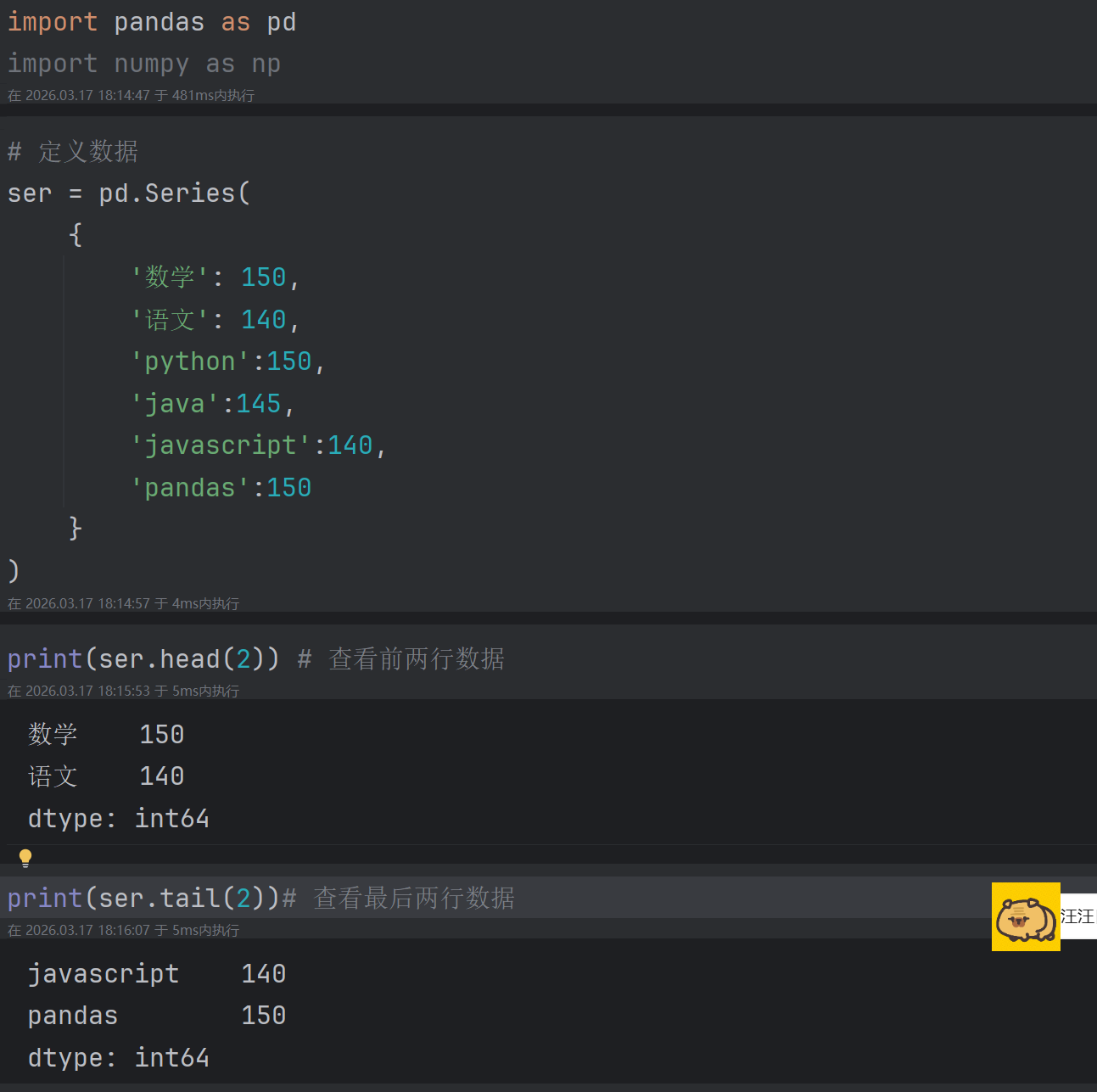
- head() : 查看前几条数据,默认5条
- tail() : 查看后几条数据,默认5条
1. head() / tail()
作用: 查看前几条数据,默认5条
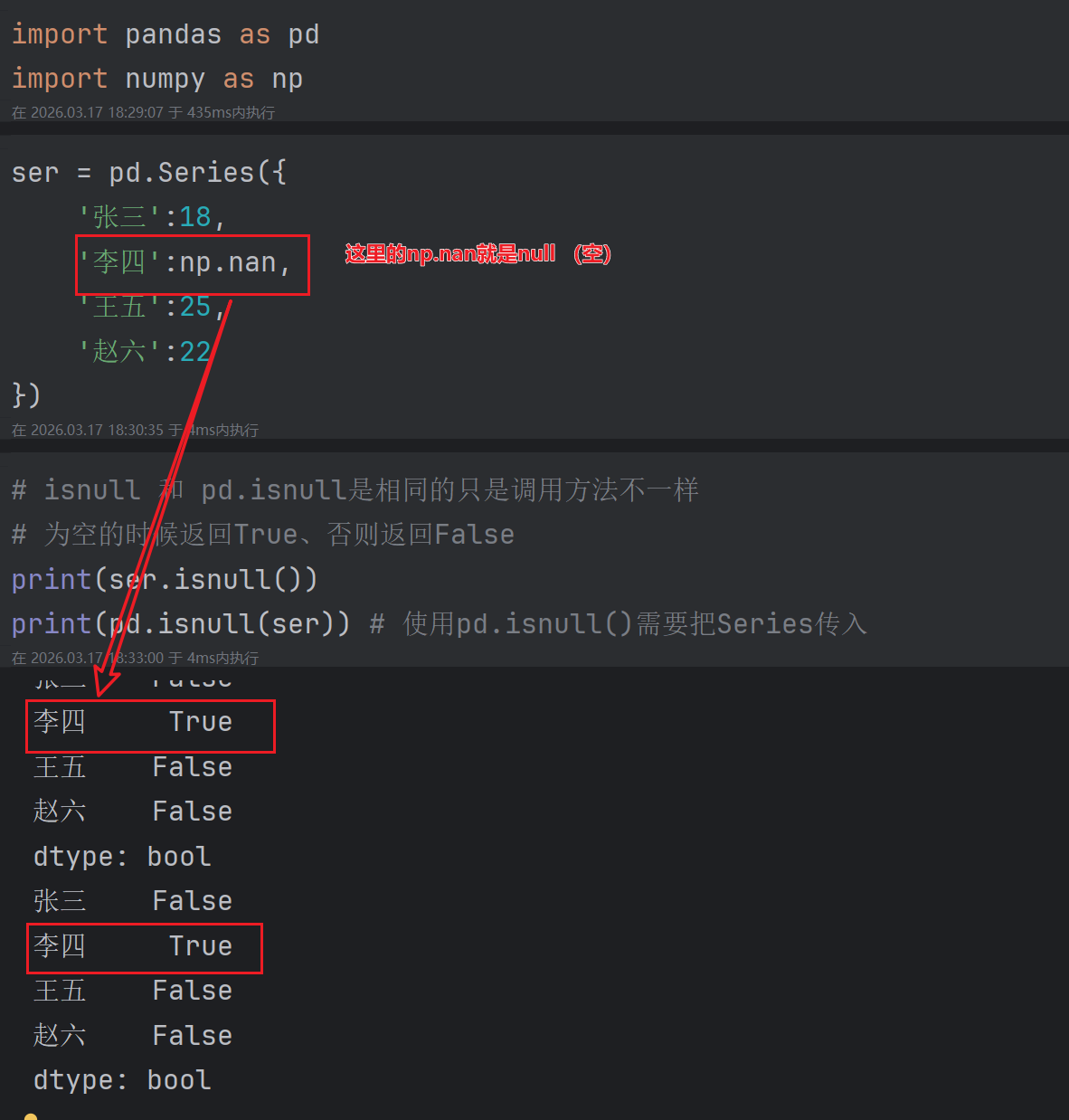
2. 检测缺失数据
pd.isnull()/isnull():检测缺失值,缺失返回True,否则False
pd.notnull()/notnull():检测非缺失值,不缺失返回True,否则False
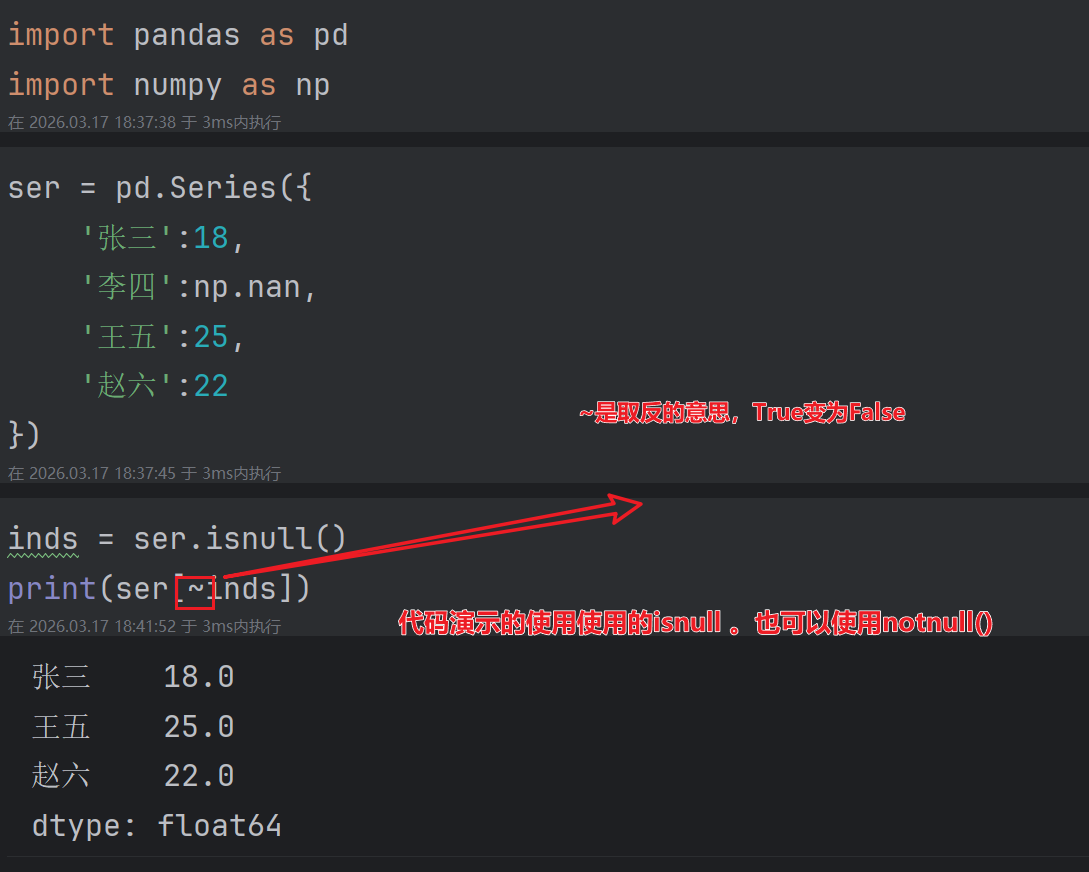
3. 使用bool值索引过滤数据
前面我们提到过,在使用索引时可以传入一个列表,一次性通过索引取出多个值。
这里也可以传入一个布尔值数组,当列表中元素为
True时,会取出对应位置的值;为False时,则不会取出。
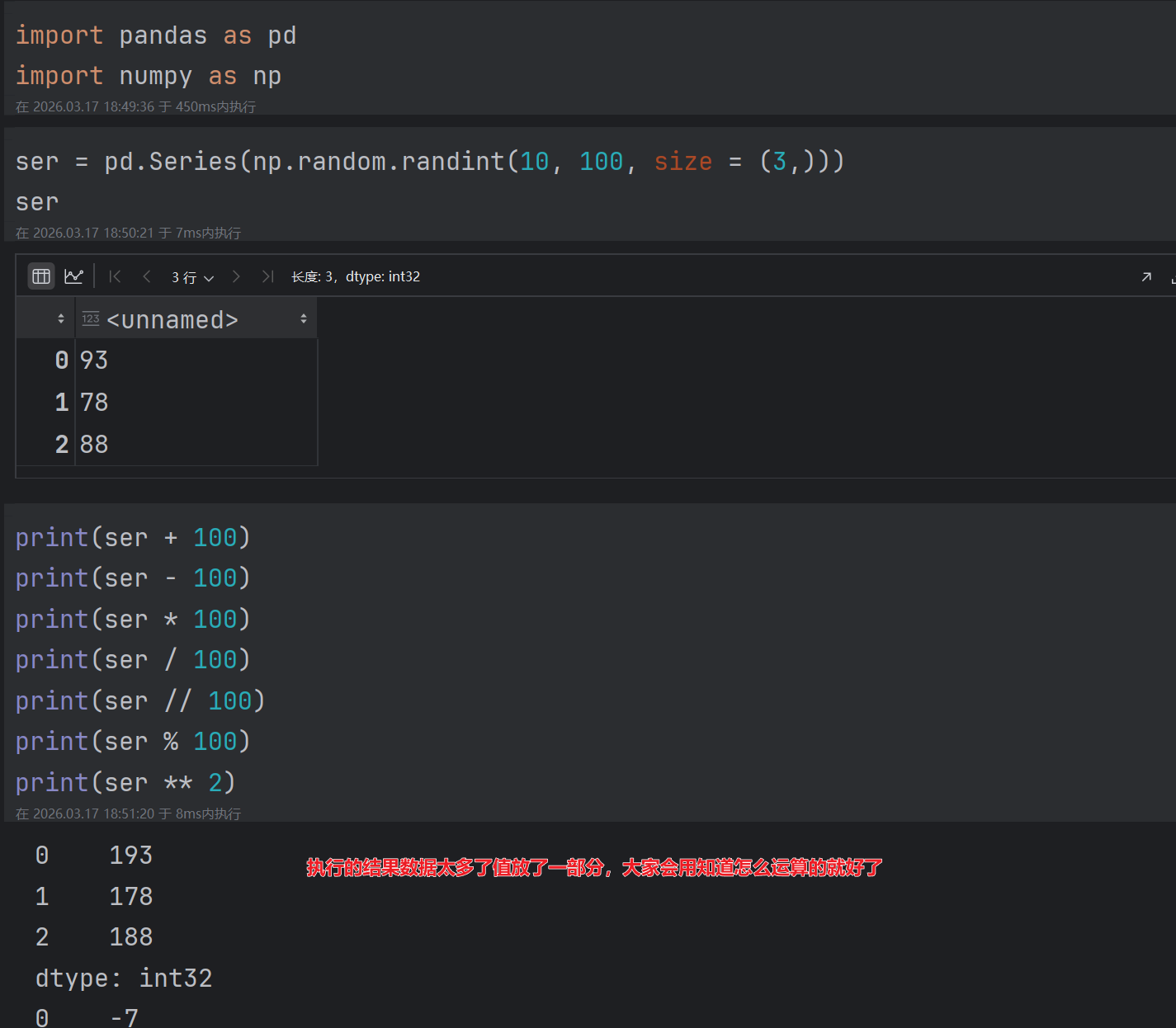
2.6 Series的运算
2.6.1 基本的算术运算
使用于NumPy的数组运算也适用于Series。
2.6.2 Series之间的运算
- 在运算中自动对齐索引
- 如果索引不对呀,则补充NaN
- Series没有广播机制
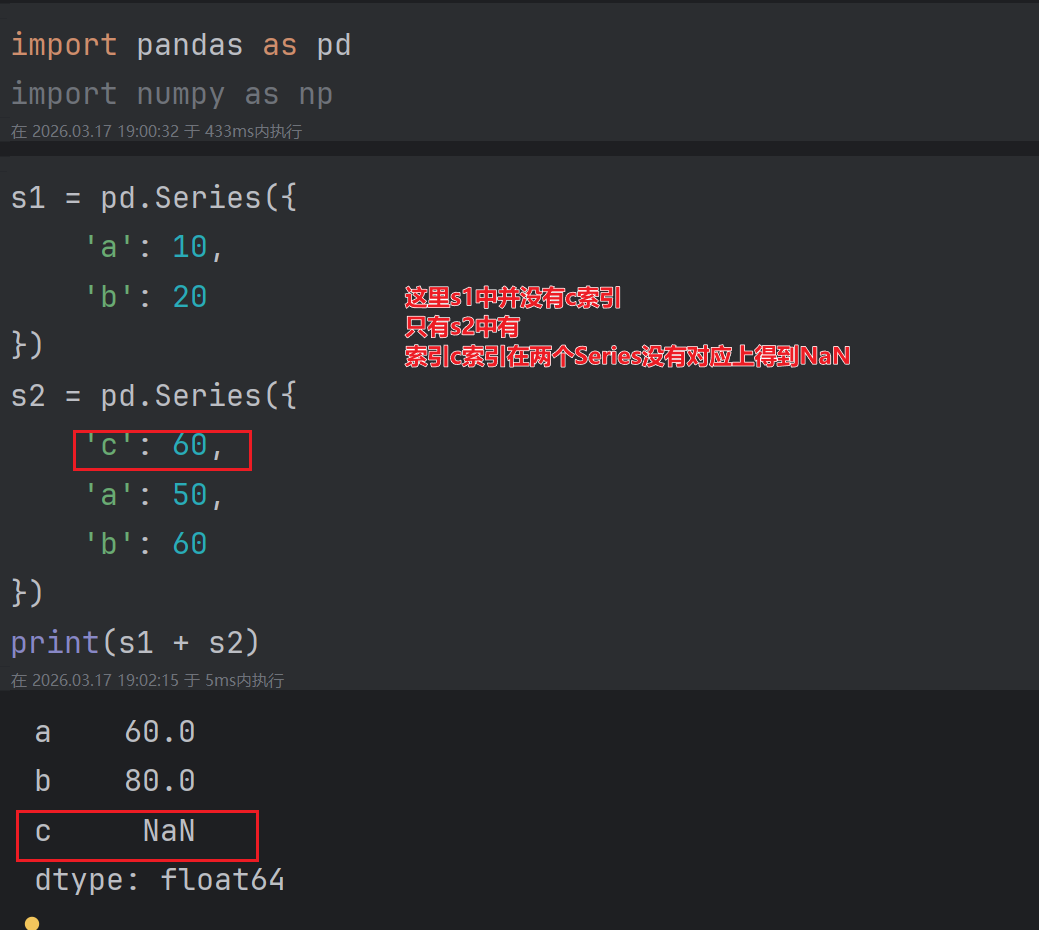
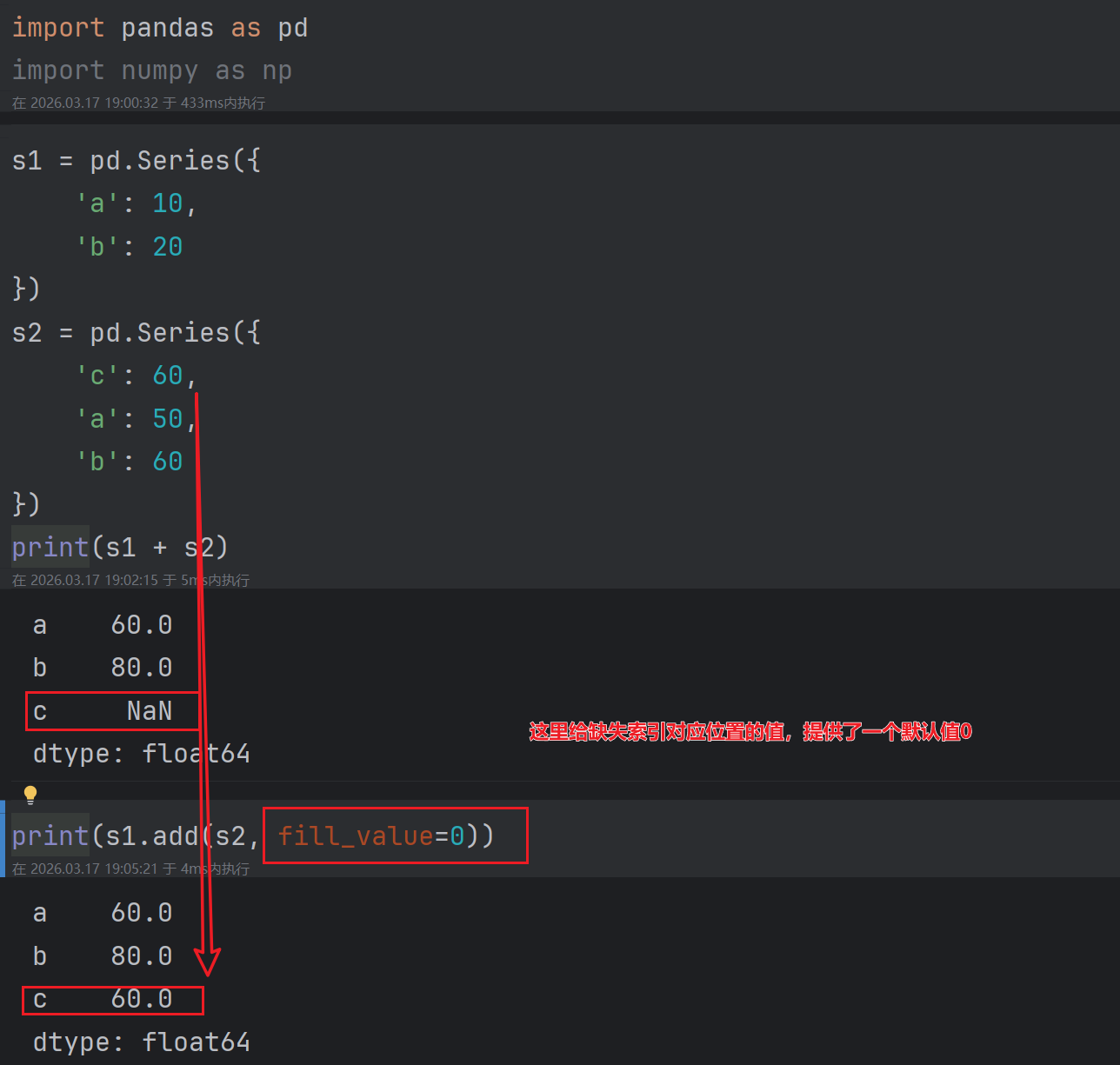
注意:如果我们想保留所有的index,则需要使用**.add()函数。**
| 运算类型 | 方法名 (Method) | 对应运算符 (Operator) | 描述 |
|---|---|---|---|
| 加法 | .add() |
+ |
逐元素相加 |
| 减法 | .sub() 或 .subtract() |
- |
逐元素相减 |
| 乘法 | .mul() |
* |
逐元素相乘 |
| 除法 | .div(), .divide() 或 .truediv() |
/ |
逐元素相除(浮点除法) |
| 整除 | .floordiv() |
// |
逐元素向下取整除法 |
| 取模 | .mod() |
% |
逐元素取余数 |
| 幂运算 | .pow() |
** |
逐元素求幂 |
上面的表格中就不在演示了和add用法相同。
三. DataFrame(二维数据)
DataFrame是一个【表格型】的数据结构,可以看做事【由Series组成的字典】(共用一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维扩展到多维。DataFeame即有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(NumPy的二维数组)
3.1 DataFrame的创建
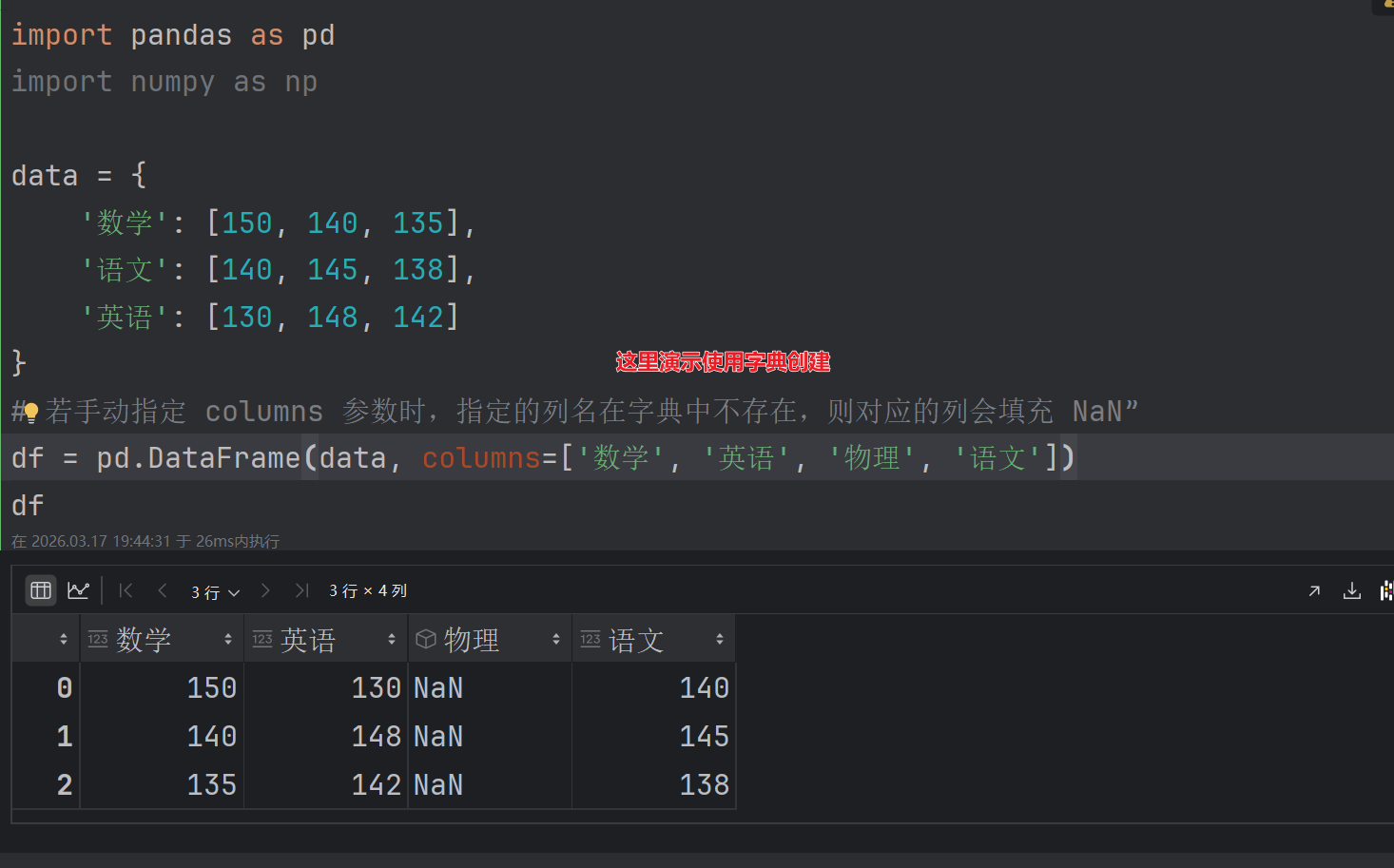
- 最常用的方法是传递一个字典创建,DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
- 此外,DataFrameme会自动加上每一行的索引(和Series一样)
- "若手动指定 columns 参数时,指定的列名在字典中不存在,则对应的列会填充 NaN"。
3.2 DataFrame的基本属性
- .values: 返回底层数据,是一个 NumPy 的二维数组(ndarray),不包含行列标签。
- .columns: 返回列名组成的 Index 对象,可用来查看或修改列名。
- .index: 返回行索引组成的 Index 对象,可以是整数、字符串、日期等。
- .shape: 返回一个元组 (行数, 列数),快速了解数据规模。
- .head(n): 预览数据开头 n 行(默认 n=5),常用于快速检查数据结构。
- .tail(n): 预览数据末尾 n 行(默认 n=5),常用于检查数据结尾或排序后的结果。
后面会持续更新....