结合 ONNX Runtime 中 TensorRT 执行提供者的核心实现,展示了 NodeComputeInfo 如何在实际中被使用。
📊 NodeComputeInfo 的三个核心函数
在 TensorRT EP 中,NodeComputeInfo 结构体包含了三个关键函数指针,每个都在不同的阶段发挥作用:
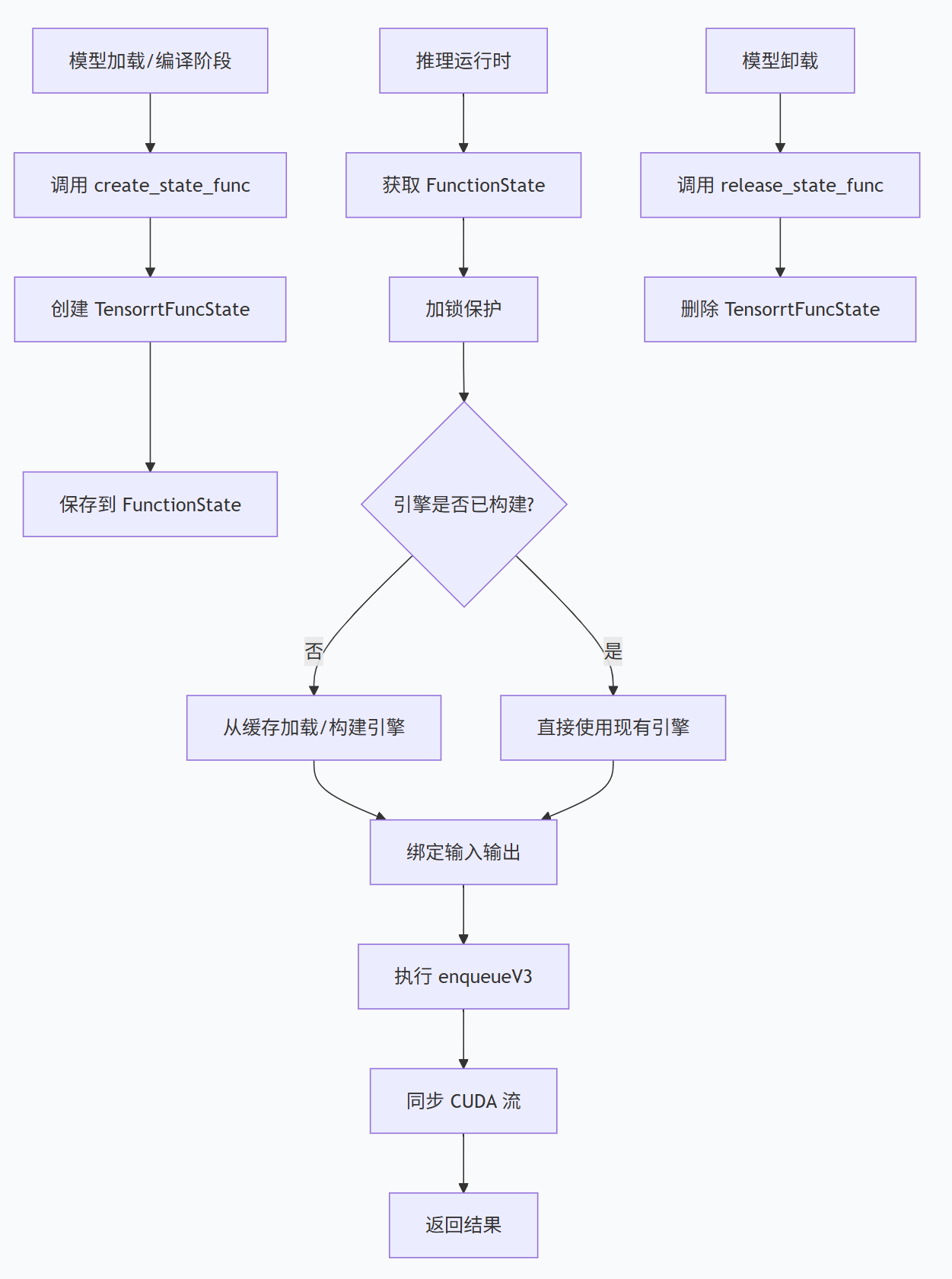
1. create_state_func - 创建编译状态
compute_info.create_state_func = [=](ComputeContext* context, FunctionState* state) {
std::unique_ptr<TensorrtFuncState> p = std::make_unique<TensorrtFuncState>();
// ... 初始化状态
*state = p.release();
return 0;
};作用 :在编译阶段 为每个算子节点创建专有的状态对象 TensorrtFuncState。这个状态对象包含了:
-
TensorRT 核心对象 :
builder_、engine_、context_、network_ -
编译配置:fp16_enable、int8_enable、dla_enable 等
-
输入输出信息:input_info_、output_info_、shape_ranges_
-
缓存相关:engine_cache_enable、cache_path_
-
互斥锁:tensorrt_mu_(用于多线程同步)
这个状态对象会通过 *state = p.release() 传递给 ONNX Runtime 运行时。
2. release_state_func - 释放编译状态
compute_info.release_state_func = [](FunctionState state) {
delete static_cast<TensorrtFuncState*>(state);
};作用 :当算子节点不再需要时(如模型卸载),释放之前创建的 TensorrtFuncState 对象,防止内存泄漏。
3. compute_func - 实际计算函数
这是最复杂的部分,负责运行时的实际推理执行。主要步骤包括:
a) 线程安全同步
std::lock_guard<std::mutex> lock(*(trt_state->tensorrt_mu_ptr));TensorRT 的 builder 和 engine 创建不是线程安全的,所以需要加锁保护。
b) 获取输入输出信息
const std::unordered_map<std::string, size_t>& input_indexes = (trt_state->input_info)[0];
const std::unordered_map<std::string, size_t>& output_indexes = (trt_state->output_info)[0];c) 引擎缓存管理
if (trt_state->engine_cache_enable && trt_engine == nullptr) {
// 从缓存加载序列化的 engine
std::ifstream engine_file(engine_cache_path, std::ios::binary | std::ios::in);
// 反序列化 engine
*(trt_state->engine) = std::unique_ptr<nvinfer1::ICudaEngine>(
trt_state->runtime->deserializeCudaEngine(engine_buf.get(), engine_size));
}d) 动态形状处理
if (shape_ranges.find(input_name) != shape_ranges.end()) {
// 根据实际输入更新优化 profile
ApplyProfileShapesFromInputTensorValue(...);
}e) 引擎构建(如果需要)
if (engine_update) {
// 重新构建 engine
trt_config->setFlag(nvinfer1::BuilderFlag::kFP16);
serialized_engine = std::unique_ptr<nvinfer1::IHostMemory>(
trt_builder->buildSerializedNetwork(*trt_state->network->get(), *trt_config));
}f) 实际推理执行
// 绑定输入输出缓冲区
BindContextInput(...);
BindContextOutput(...);
// 执行推理
if (!trt_context->enqueueV3(stream)) {
return ORT_MAKE_STATUS(ONNXRUNTIME, FAIL, "TensorRT EP execution context enqueue failed.");
}g) CUDA Graph 支持
if (cuda_graph_enable_ && IsGraphCaptureAllowed()) {
cuda_graph_.SetStream(stream);
CaptureBegin(0);
// ... 执行推理
CaptureEnd(0);
}🔄 整个流程的时序
💡 关键设计点
-
状态隔离 :每个节点有自己的
TensorrtFuncState,避免节点间干扰 -
延迟构建:引擎可以在第一次推理时构建(从缓存加载)
-
缓存机制:支持 engine 缓存加速后续加载
-
线程安全:通过互斥锁保护 TensorRT 的非线程安全操作
-
动态形状:支持运行时调整输入形状
这就是 NodeComputeInfo 在 TensorRT EP 中的完整实现,它将 ONNX 算子的编译时信息(通过 create_state_func)和运行时执行(通过 compute_func)完美地结合起来。