在高并发系统中,缓存是提升性能、降低数据库负载的关键组件。然而,缓存并非万能------当恶意请求或异常流量持续查询不存在的数据 时,缓存层无法命中,所有请求直击后端数据库,导致系统雪崩式崩溃。这种现象被称为 "缓存穿透"(Cache Penetration)。
一、什么是缓存穿透?
缓存穿透 指客户端持续请求根本不存在于数据库中的数据 (如 user_id = -1 或随机生成的无效 ID),由于这些数据既不在缓存中,也不在数据库中,每次请求都会绕过缓存直达数据库,造成数据库压力剧增,甚至宕机。
典型场景
- 黑客恶意攻击,构造大量非法 ID;
- 前端传参校验缺失,用户输入无效查询条件;
- 爬虫遍历非连续主键空间。
二、缓存穿透 vs 缓存击穿 vs 缓存雪崩
为避免混淆,我们先厘清三个高频概念:
| 问题类型 | 触发原因 | 影响范围 | 防御手段 |
|---|---|---|---|
| 缓存穿透 | 查询不存在的数据 | 单点/批量无效请求 | 空值缓存、布隆过滤器 |
| 缓存击穿 | 热点 key 过期瞬间被大量并发访问 | 单个热点 key | 互斥锁、逻辑过期、永不过期 |
| 缓存雪崩 | 大量 key 同时过期或缓存节点宕机 | 全局性 | 随机 TTL、多级缓存、高可用部署 |
关键区别:穿透是"查无此物",击穿是"热点失效",雪崩是"集体失效"。
三、防御缓存穿透的两大核心方案
方案 1:空值缓存(Null Caching)
原理
当查询数据库返回空结果时,仍将该 key 写入 Redis,value 可设为特殊标记(如 "NULL"),并设置较短 TTL(如 30--300 秒)。
Redis 命令示例
bash
# 查询用户
GET user:999999
# 返回 nil → 查询 DB → DB 也无此用户
# 写入空值缓存
SET user:999999 "NULL" EX 60优点
- 实现简单,无需额外依赖;
- 有效拦截重复无效请求。
风险与注意事项
- 内存浪费:若攻击者使用海量不同无效 ID,可能撑爆缓存;
- TTL 设计:不宜过长(避免脏数据),也不宜过短(失去防护意义);
- 清理策略:建议配合 LRU 或定期清理脚本。
方案 2:布隆过滤器(Bloom Filter)
原理
布隆过滤器是一种概率型数据结构 ,用于快速判断"某元素是否可能存在于集合中"。它由一个位数组和多个哈希函数组成。
- 若 BF 返回 "不存在" → 数据一定不存在(100% 准确);
- 若 BF 返回 "可能存在" → 需进一步查缓存或 DB(存在误判)。
在 Redis 中的实现
Redis 官方通过 RedisBloom 模块提供原生支持(需单独加载):
bash
# 添加元素
BF.ADD user_ids 1001
BF.ADD user_ids 1002
# 查询是否存在
BF.EXISTS user_ids 999999 # 返回 0 → 一定不存在
BF.EXISTS user_ids 1001 # 返回 1 → 可能存在(需查缓存)优势
- 空间效率极高:1 亿条数据仅需 ~100MB;
- 查询速度极快:O(k) 时间复杂度(k 为哈希函数数量);
- 天然防穿透:无效 ID 在 BF 层即被拦截。
局限性
- 存在误判率 (可通过参数调整,如
error_rate=0.01); - 不支持删除(可改用 Counting Bloom Filter,但 RedisBloom 默认不支持);
- 需预加载全量合法 ID(适用于 ID 集合相对稳定的场景,如用户表、商品 SKU)。
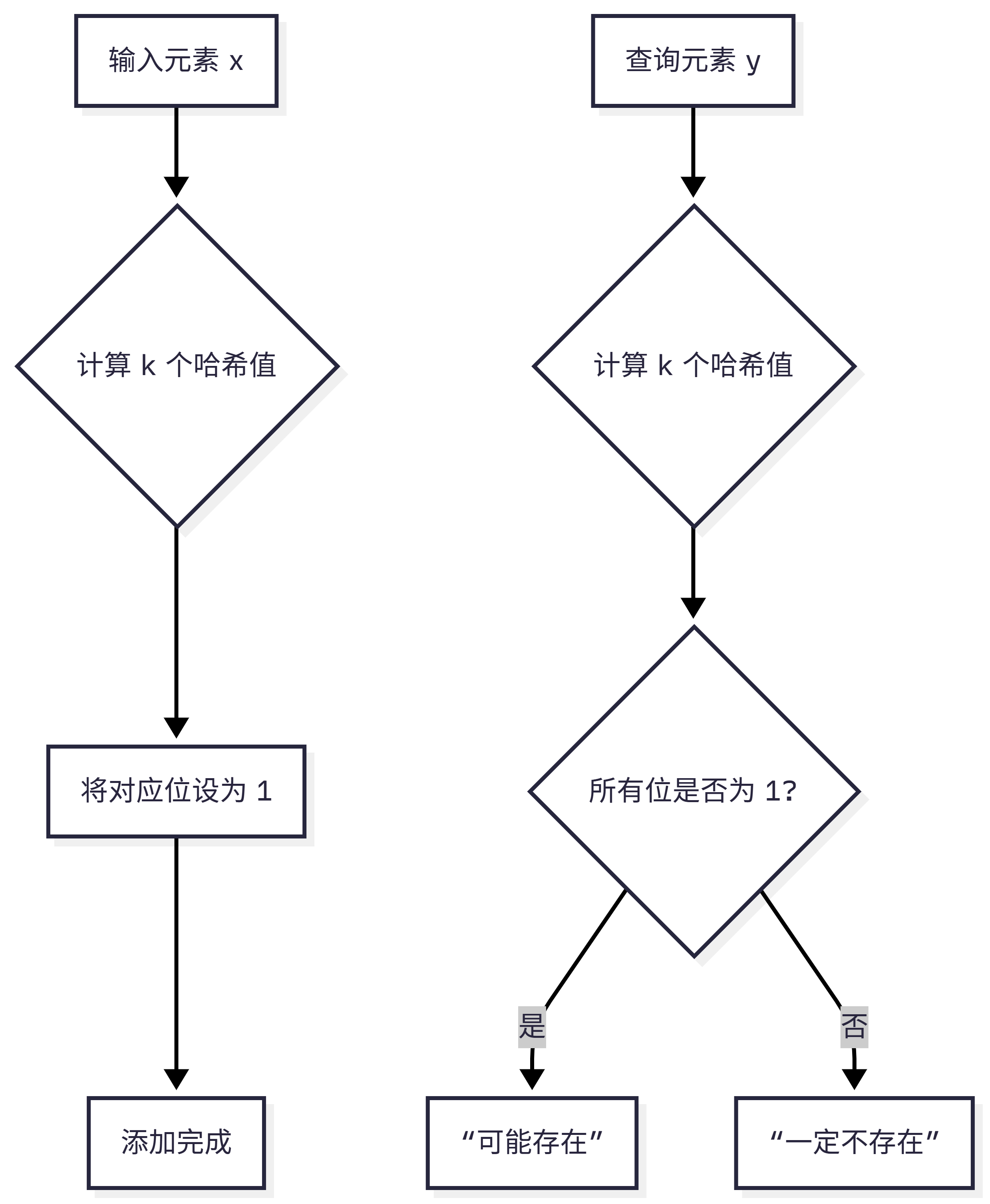
实战演示:布隆过滤器如何工作?
1. 核心思想:用"位"代替"值"
传统集合(如 HashSet)存储元素本身,而布隆过滤器不存元素 ,只用一个位数组(bit array) 和 多个哈希函数 来"标记"某个元素"可能被加入过"。
它回答的是:
- "这个元素一定不存在 " → 100% 准确;
- "这个元素可能存在 " → 可能误判(False Positive)。
2. 布隆过滤器的组成
- 一个长度为 m 的位数组(初始全为 0)
- k 个独立的哈希函数 (如 MurmurHash、FNV 等),每个函数将输入映射到
[0, m-1]的整数
3. 实际操作流程
步骤 1:添加元素(ADD)
假设我们要添加元素 "apple":
- 用 k 个哈希函数分别计算:
hash1("apple") = 3hash2("apple") = 17hash3("apple") = 99
- 将位数组的第 3、17、99 位 设为 1
text
位数组(部分):
索引: ... 3 ... 17 ... 99 ...
值: ... 1 ... 1 ... 1 ...注意:不存储 "apple" 本身,只记录它的"指纹位置"。
步骤 2:查询元素(EXISTS)
现在查询 "banana" 是否存在:
- 用同样的 k 个哈希函数计算:
hash1("banana") = 5hash2("banana") = 17hash3("banana") = 88
- 检查位数组的第 5、17、88 位:
- 如果任意一位是 0 → "banana" 一定不存在
- 如果所有位都是 1 → "banana" 可能存在(但可能是其他元素"污染"了这些位)
4. 举例说明误判(False Positive)
- 先加入
"apple"→ 设置位 3, 17, 99 为 1 - 再加入
"orange"→ 假设计算得位 5, 17, 200 为 1 - 现在位 17 已被两个元素共用
此时查询 "cherry",若其哈希结果恰好是 3, 5, 17 ,而这三个位都已被设为 1(尽管 "cherry" 从未加入),布隆过滤器就会误判为"可能存在"。
但只要有一个位是 0,就100% 确定不存在------这是布隆过滤器最强大的特性。
5. 可视化流程图
6. 关键数学关系(决定性能的核心)
布隆过滤器的效果由三个参数决定:
| 参数 | 含义 |
|---|---|
| n | 预期插入的元素数量 |
| m | 位数组长度(bit 数) |
| k | 哈希函数个数 |
最优哈希函数数量:
k=mnln2 k = \frac{m}{n} \ln 2 k=nmln2
误判率(False Positive Rate):
p≈(1−e−knm)k p \approx \left(1 - e^{-\frac{kn}{m}}\right)^k p≈(1−e−mkn)k
实践建议:
若你预计存 100 万个 ID,希望误判率 ≤1%,则:
- 所需位数组大小 m ≈ 9.6 MB(约 958 万 bits)
- 哈希函数数量 k ≈ 7
RedisBloom 的 BF.RESERVE 命令正是基于此公式设计:
bash
BF.RESERVE my_bf 0.01 1000000 # 1% 误判率,100 万容量7. 现实中的限制与应对
| 限制 | 说明 | 应对方案 |
|---|---|---|
| 不能删除元素 | 清除某 bit 会影响其他元素 | 改用 Counting Bloom Filter(每个位用计数器代替) |
| 必须预估容量 | 超出容量后误判率飙升 | 监控 BF.INFO,或使用可扩展 BF(如 Scalable Bloom Filter) |
| 不支持精确查询 | 只能做"存在性"初筛 | 后续仍需查缓存或 DB 确认 |
布隆过滤器就像一个"超级快速的黑名单筛查员":
它能 100% 确认"坏人不在名单里",
但说"可能是好人"时,你需要再查身份证确认。
实战演示:Redis 原生支持:RedisBloom 模块
Redis 自 4.0 起支持模块机制,RedisBloom 是官方推荐的布隆过滤器实现(需单独加载)。
1. 常用命令
| 命令 | 说明 |
|---|---|
BF.RESERVE key error_rate capacity [expansion] |
创建 BF,指定误判率与容量 |
BF.ADD key item |
添加单个元素 |
BF.MADD key item1 item2 ... |
批量添加 |
BF.EXISTS key item |
判断是否存在 |
BF.MEXISTS key item1 item2 ... |
批量判断 |
BF.INFO key |
查看内部状态(容量、插入数、哈希函数数等) |
注意:若未显式
RESERVE,首次ADD会自动创建,默认capacity=1000,error_rate=0.01。
2. 示例
bash
# 创建一个容量 10000、误判率 1% 的 BF
BF.RESERVE user:exists 0.01 10000
# 添加用户 ID
BF.ADD user:exists u12345
BF.ADD user:exists u67890
# 查询
BF.EXISTS user:exists u12345 # 返回 1(可能存在)
BF.EXISTS user:exists u99999 # 返回 0(一定不存在)3. 如何验证 Redis 服务器已加载 RedisBloom 模块?
在使用 Redis 布隆过滤器前,首要前提是确认 Redis 服务端已正确加载 RedisBloom 模块 。否则,执行 BF.ADD 等命令会返回 "unknown command" 错误。
方法一:使用 MODULE LIST 命令
这是最权威、无副作用的检查方式。通过任意 Redis 客户端(如 redis-cli)执行:
bash
MODULE LIST-
若输出包含如下内容,说明 RedisBloom 已加载:
bash1) 1) "name" 2) "bf" 3) "ver" 4) "70209" 5) "path" 6) "/opt/redisbloom/redisbloom.so"其中
"name": "bf"是 RedisBloom 模块的标识符。 -
若返回空数组
(empty array),则表示未加载任何模块,包括 RedisBloom。
提示:该命令无需权限,且不会修改任何数据,适合在生产环境安全使用。
方法二:尝试执行布隆过滤器命令(快速验证)
直接调用一个 RedisBloom 特有命令进行试探:
bash
BF.ADD __test_bf__ item1- 成功返回
(integer) 1或OK→ 模块已加载; - 返回
(error) ERR unknown command 'BF.ADD'→ 模块未加载。
注意:此操作会创建一个临时 key(建议命名为
__test_bf__并立即删除):
bashDEL __test_bf__
方法三:检查 Redis 配置或启动日志
如果有服务器访问权限,可进一步确认模块是否被配置加载:
-
查看
redis.conf是否包含:confloadmodule /path/to/redisbloom.so -
查看启动日志(如 systemd 或 Docker 日志):
bashjournalctl -u redis | grep -i bloom # 或 docker logs <redis-container> | grep "Module 'bf'"成功加载时通常会输出:
Module 'bf' loaded from /path/to/redisbloom.so
不推荐的方法:依赖 INFO 命令
虽然 INFO SERVER 能显示 Redis 版本和模式,但不会明确列出已加载的模块,因此无法用于可靠判断。
快速决策表
| 场景 | 推荐方法 |
|---|---|
| 开发/测试环境快速验证 | BF.ADD + 删除测试 key |
| 生产环境安全检查 | MODULE LIST |
| 运维排查部署问题 | 检查 redis.conf + 启动日志 |
四、请求流程图解(含防护机制)
带布隆过滤器的典型请求链路:
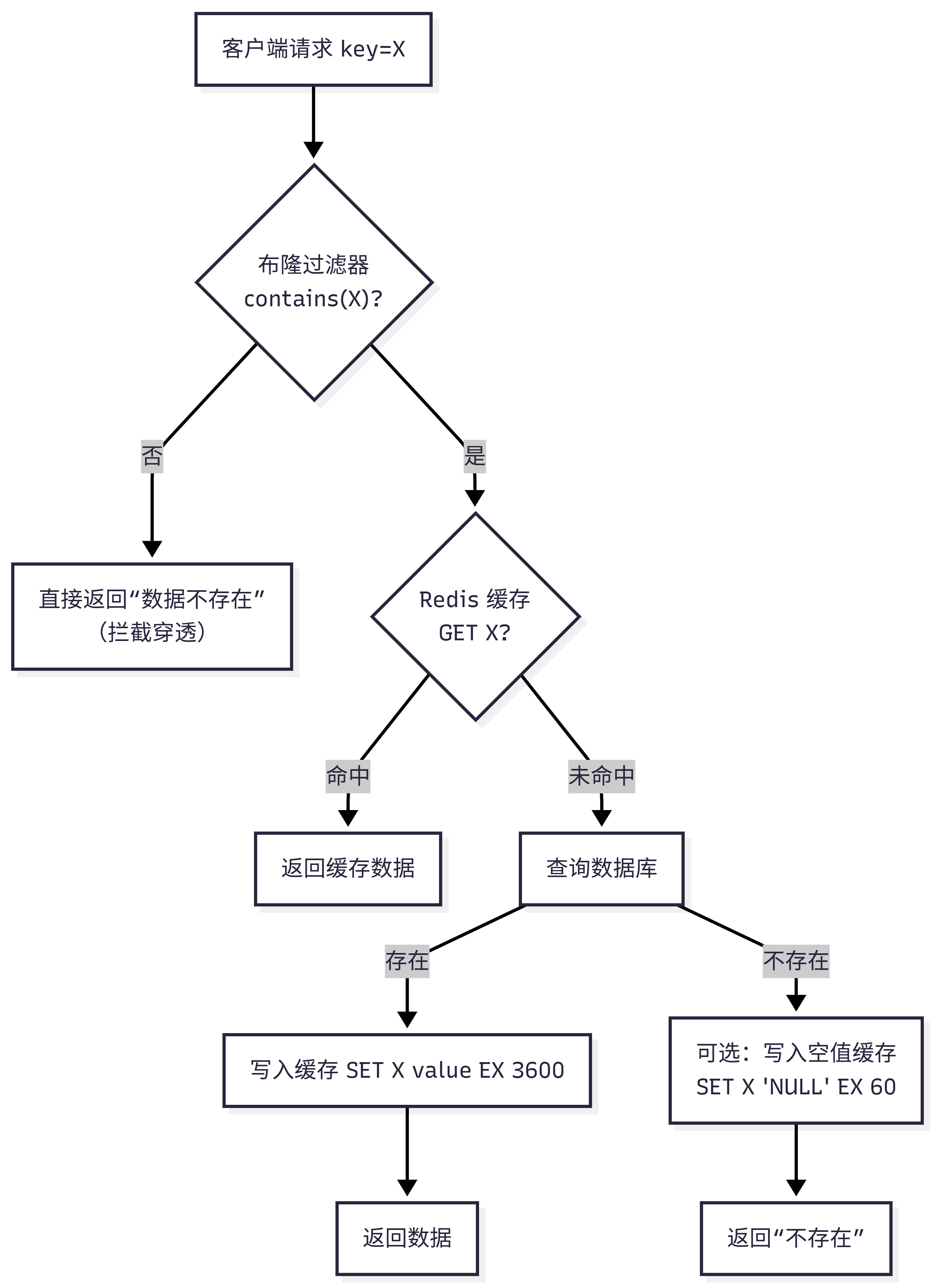 说明:布隆过滤器作为第一道防线,空值缓存作为第二道补充,形成双重防护。
说明:布隆过滤器作为第一道防线,空值缓存作为第二道补充,形成双重防护。
五、常用 Redis 命令速查表
| 场景 | 命令示例 | 说明 |
|---|---|---|
| 空值缓存写入 | SET invalid_key "NULL" EX 60 |
TTL 建议 30--300s |
| 布隆过滤器初始化 | BF.RESERVE user_bf 0.01 1000000 |
误判率 1%,容量 100 万 |
| 添加合法 ID | BF.ADD user_bf 12345 |
批量可用 BF.MADD |
| 查询是否存在 | BF.EXISTS user_bf 99999 |
返回 0/1 |
| 查看 BF 信息 | BF.INFO user_bf |
查看 size、capacity 等 |
注:RedisBloom 模块需在启动时加载,或通过
MODULE LOAD动态加载。
六、高频面试题
Q1:如何防止 Redis 缓存穿透?
答:主要两种方式:(1) 对查询结果为空的 key 写入短 TTL 的空值缓存;(2) 使用布隆过滤器在缓存前拦截非法请求。两者可结合使用。
Q2:布隆过滤器为什么会有误判?能删除元素吗?
答 :误判源于多个 key 的哈希值可能映射到位数组的相同位置,导致"假阳性"。标准布隆过滤器不支持删除 ,因为多个元素可能共享同一个 bit 位。若清零某一位,可能导致其他合法元素被误判为"不存在",破坏"无漏判"特性。
若需删除,可使用 Counting Bloom Filter(RedisBloom 社区版部分支持)。
Q3:空值缓存会不会被恶意利用打爆内存?
答:会。因此应限制空值缓存的 TTL,并配合布隆过滤器减少无效 key 写入。也可对 key 做合法性校验(如 ID > 0)前置过滤。
Q4:布隆过滤器适合什么场景?
答 :适合静态或缓慢变化的集合(如用户 ID、商品 SKU、黑名单),且能接受少量误判的场景。不适合频繁增删或要求 100% 精确的场景。