摘要 :本文在 Decoder-only Transformer 与 Mixture-of-Experts(MoE)的基础上,系统介绍 DeepSeekMoE 的架构设计及与 LLaMA、标准 Transformer、GShard 的对比。内容包括:MoE 在 Transformer 中的位置(用 MoE 层替代 FFN)、DeepSeekMoE 的两大策略(细粒度专家切分、共享专家隔离)、数学形式与负载均衡、不同规模配置(2B / 16B / 145B)及与稠密模型的计算/性能对比、以及与 Transformer / LLaMA / GShard 的架构对比表。旨在帮助读者理解 DeepSeekMoE 如何通过专家专业化实现「少激活、多参数」的高效扩展。
关键词:DeepSeekMoE;Mixture-of-Experts;细粒度专家切分;共享专家隔离;Decoder-only;LLaMA;GShard;大语言模型
💡 理解要点 :DeepSeekMoE 是在 Decoder-only Transformer 骨架下,将部分或全部 FFN 替换为 MoE 层 的稀疏大模型;通过细粒度专家切分 和共享专家隔离 提升专家专业化程度,在总参数量不变、激活计算显著更少的前提下,达到接近稠密模型(DeepSeek 7B / 67B、LLaMA2 7B)的性能。论文见 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models。
📊 架构图说明 :MoE 层的整体数据流(自注意力 → MoE 层 → 残差)与 Decoder Only Transformer 一致,区别在于 MoE 层内部为「路由 + 多专家 FFN」;论文 Figure 2 给出了从 GShard 到 DeepSeekMoE 的示意图,可配合 论文 阅读。
1. 引言:DeepSeekMoE 的架构定位
DeepSeekMoE 是深度求索在 2024 年提出的 MoE(Mixture-of-Experts) 语言模型架构,与 DeepSeek LLM(稠密 Decoder-only)同属一脉,但通过 稀疏激活 在扩大总参数量的同时控制计算成本。其核心目标是 极致的专家专业化 :让每个专家学习非重叠、聚焦的知识,避免传统 MoE 中的「知识混杂」与「知识冗余」。
🔍 实际例子 :传统 top-2 MoE 像「每道题只请 2 位老师」,但老师数量少时每位老师要教很多不同科目,容易混杂;DeepSeekMoE 通过「把老师拆成更细的专业组」+「固定几位通用老师」让每位老师更专注,从而用更少的实际参与计算(激活参数)达到接近稠密模型的效果。
与 标准 Transformer 、LLaMA (以及 DeepSeek LLM)的对比可概括为:前两者在每一层使用单一 FFN ,所有 token 都经过同一组参数;DeepSeekMoE 在指定层用 MoE 层 替代 FFN,每个 token 只经过被路由到的少数专家,总参数量大、激活参数量与计算量小。
2. 标准 Decoder 块回顾
整体数据流与 Decoder Only Transformer 一致(本节仅讨论标准 Decoder,即每层均为自注意力 + 单一 FFN):
输入 → Embedding(+ 可选 RoPE)→ 若干 Decoder 层(自注意力 + FFN)→ 输出层 → Softmax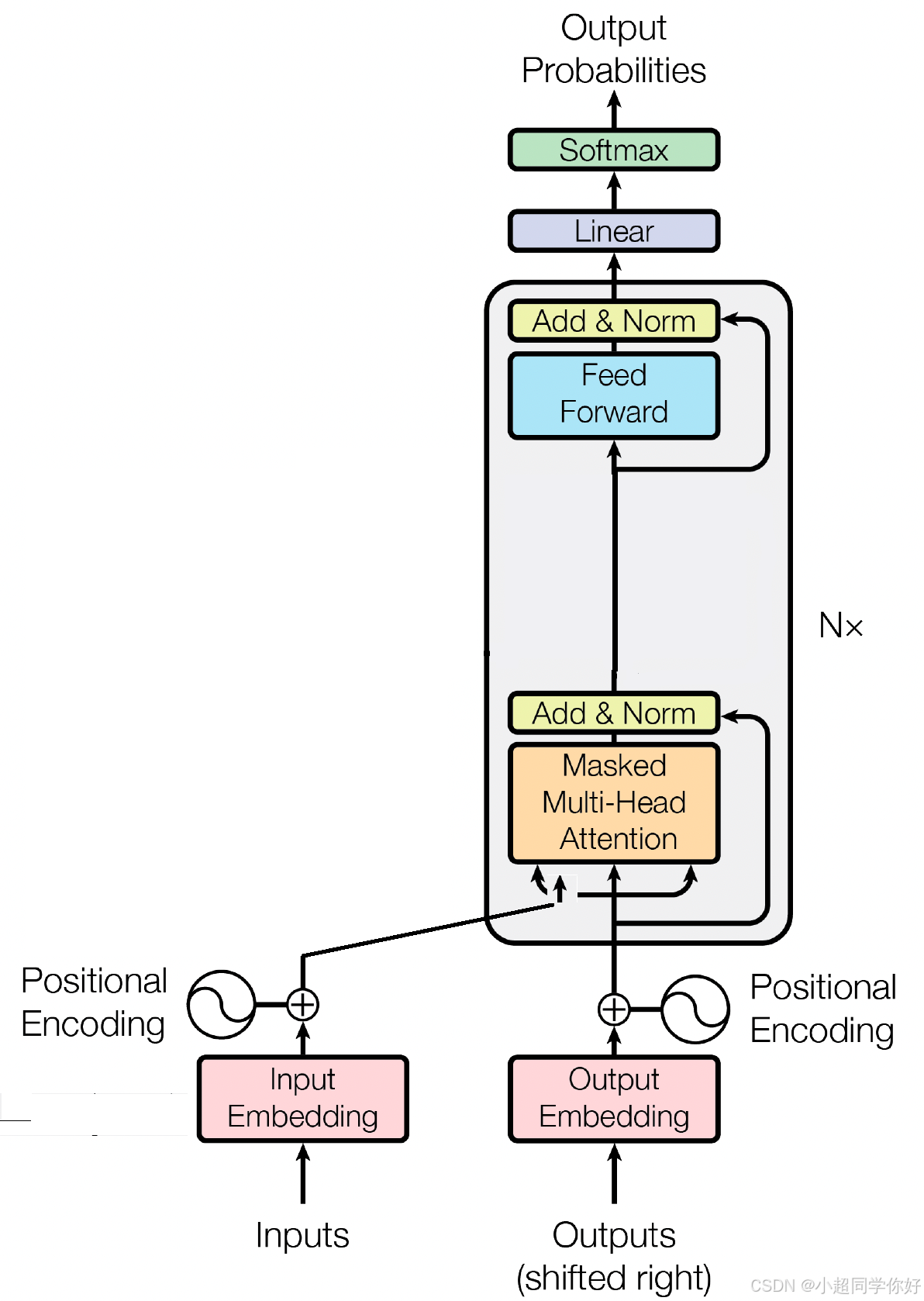
单层结构
在 Decoder Only Transformer 与 LLaMA 架构 中,每一层可简写为(略去归一化):
u 1 : T l = S e l f A t t ( h 1 : T l − 1 ) + h 1 : T l − 1 , h t l = F F N ( u t l ) + u t l . \mathbf{u}^{l}{1:T} = \mathrm{SelfAtt}(\mathbf{h}^{l-1}{1:T}) + \mathbf{h}^{l-1}{1:T}, \qquad \mathbf{h}^{l}{t} = \mathrm{FFN}(\mathbf{u}^{l}{t}) + \mathbf{u}^{l}{t}. u1:Tl=SelfAtt(h1:Tl−1)+h1:Tl−1,htl=FFN(utl)+utl.
即:自注意力 → 残差 → FFN → 残差 。FFN 对所有 token 共享,形状一般为 d → 4 d → d d \to 4d \to d d→4d→d。
FFN(前馈网络)简介
FFN (Feed-Forward Network,前馈网络)是 Decoder 中紧接在自注意力之后的子层,对每个 token 的位置独立 做非线性变换:同一层内所有 token 共用同一组 FFN 参数,输入、输出形状均为 L × d model L \times d_{\text{model}} L×dmodel( L L L 为序列长度, d model d_{\text{model}} dmodel 为隐藏维度)。
结构 :一般为「两线性层 + 中间激活」,即先把 d model d_{\text{model}} dmodel 维映射到中间维度 d f f d_{ff} dff(常见取 d f f = 4 ⋅ d model d_{ff} = 4 \cdot d_{\text{model}} dff=4⋅dmodel),经激活后再映射回 d model d_{\text{model}} dmodel,即 d → 4 d → d d \to 4d \to d d→4d→d 。标准 Transformer 使用 ReLU;LLaMA 与 DeepSeek 采用 SwiGLU 门控形式 ( σ s w i s h ( x W 1 ) ⊙ ( x W 3 ) ) W 2 \big(\sigma_{\mathrm{swish}}(x W_1) \odot (x W_3)\big) W_2 (σswish(xW1)⊙(xW3))W2,详见 LLaMA 架构 §3.3 前馈网络:SwiGLU。
在 MoE 语境下,每个专家 在结构上就是一个这样的 FFN(相同 d → 4 d → d d \to 4d \to d d→4d→d 与激活方式);下一节将说明如何用 MoE 层替代 FFN。
3. 用 MoE 层替代 FFN
在部分层 用 MoE 层 替代 FFN 时,整体数据流变为:
输入 → Embedding(+ 可选 RoPE)→ 若干 Decoder 层(自注意力 + FFN 或 MoE)→ 输出层 → SoftmaxDeepSeekMoE 中:除第一层外均可为 MoE 层(16B 为「除第一层外全部 MoE」),其余组件(自注意力、归一化、残差)与 LLaMA 风格一致。
3.1 MoE 层:路由 + 多专家 FFN
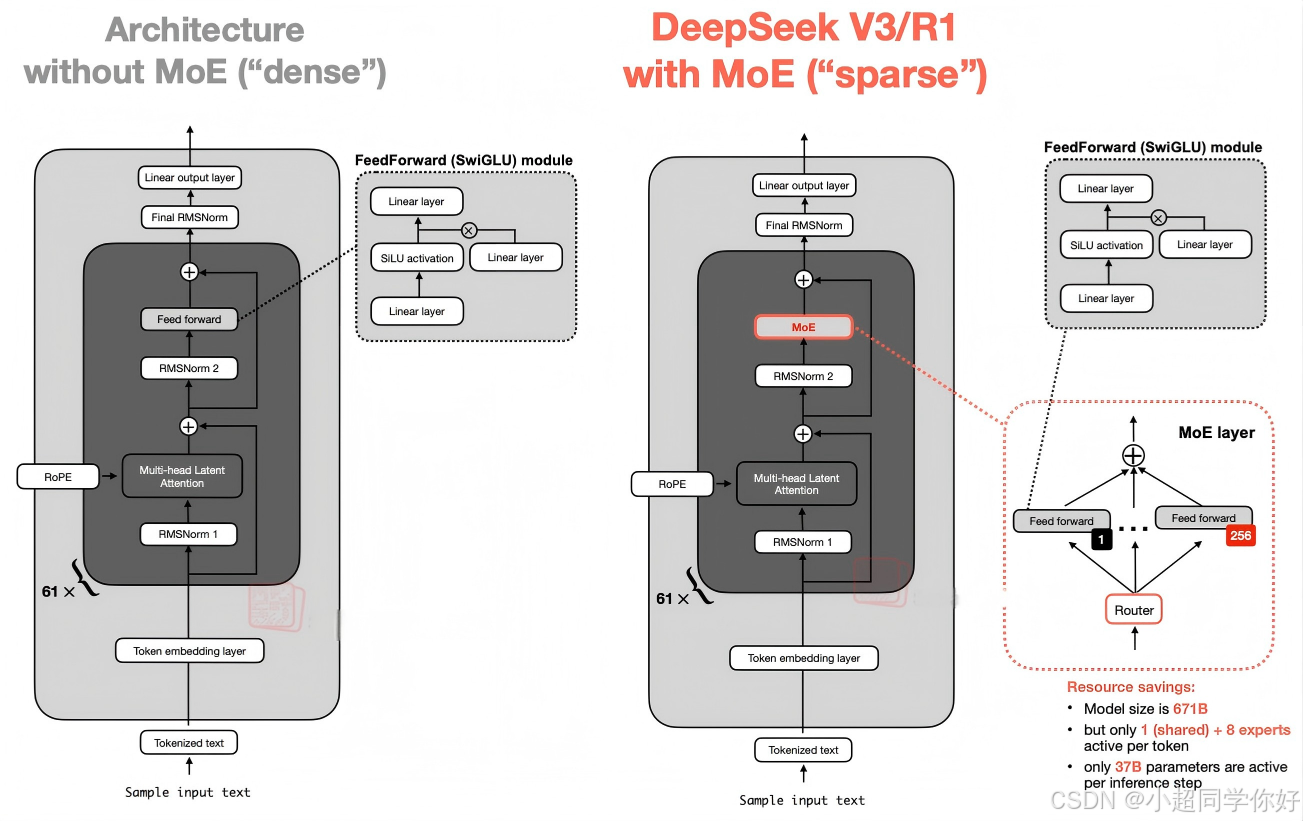
常见做法是在部分层 用 MoE 层 替代 FFN,其余层保持普通 FFN。一个 MoE 层由 N N N 个专家 组成,每个专家结构上与标准 FFN 相同(见 §2.1.1);对每个 token 由一个路由器(Router) 计算与各专家的亲和度,并选取 Top- K K K 个专家进行前向计算,最后按门控加权求和并加残差:
h t l = ∑ i = 1 N g i , t F F N i ( u t l ) + u t l , \mathbf{h}^{l}{t} = \sum{i=1}^{N} g_{i,t}\, \mathrm{FFN}{i}(\mathbf{u}^{l}{t}) + \mathbf{u}^{l}_{t}, htl=i=1∑Ngi,tFFNi(utl)+utl,
其中 g i , t g_{i,t} gi,t 仅在 i ∈ T o p K ( { s j , t } , K ) i \in \mathrm{TopK}(\{s_{j,t}\}, K) i∈TopK({sj,t},K) 时非零( s i , t s_{i,t} si,t 为 token t t t 对专家 i i i 的亲和度,通常为 softmax 后的分数)。这样总参数量 约为 N N N 个 FFN,但每 token 实际计算 只经过 K K K 个 FFN,计算量约为稠密 FFN 的 K / N K/N K/N 倍(当 K ≪ N K \ll N K≪N 时显著省算力)。
💡 理解要点:MoE 的本质是「参数多、计算省」------总参数可以做得很大(很多专家),但每次前向只激活少数专家,从而在扩展规模时控制 FLOPs。
3.2 GShard 式 MoE(对照基线)
GShard、Switch Transformer 等采用 top- K K K 路由 (如 N = 16 N=16 N=16, K = 2 K=2 K=2):每个 token 只进入 K K K 个专家。DeepSeekMoE 论文指出这类设计存在 知识混杂 (一个专家要学多种知识)和 知识冗余 (不同专家重复学通用知识)的问题,从而提出细粒度专家切分 与共享专家隔离两项策略。
4. DeepSeekMoE 架构:两大策略
DeepSeekMoE 在保持专家总参数量与每 token 激活计算量不变 的前提下,做两件事:(1)把专家切得更细 并多激活几个 ,提高组合灵活性;(2)固定一部分专家为共享专家,所有 token 都经过,用于承载通用知识,减轻路由专家的冗余。
4.1 细粒度专家切分(Fine-Grained Expert Segmentation)
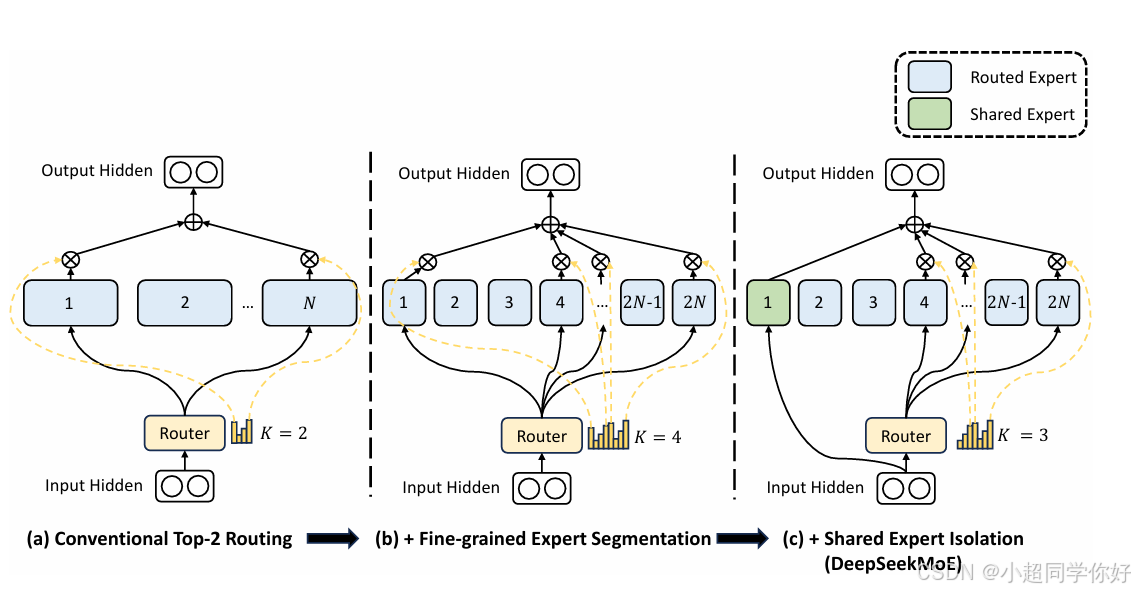
做法 :在总专家参数量不变的前提下,将每个「大专家」切成 m m m 个「小专家」(即把每个专家 FFN 的中间维度变为原来的 1 / m 1/m 1/m),于是专家总数从 N N N 变为 m N mN mN ;同时将每 token 激活的专家数从 K K K 变为 m K mK mK ,以保持每 token 的 FFN 计算量不变。
数学形式 (论文式 6--8):设第 l l l 层 MoE 有 m N mN mN 个专家,token t t t 的隐藏状态为 u t l \mathbf{u}^{l}_{t} utl,则
h t l = ∑ i = 1 m N g i , t F F N i ( u t l ) + u t l , \mathbf{h}^{l}{t} = \sum{i=1}^{mN} g_{i,t}\, \mathrm{FFN}{i}(\mathbf{u}^{l}{t}) + \mathbf{u}^{l}_{t}, htl=i=1∑mNgi,tFFNi(utl)+utl,
g i , t = { s i , t , s i , t ∈ T o p K ( { s j , t ∣ 1 ≤ j ≤ m N } , m K ) 0 , otherwise , s i , t = S o f t m a x i ( u t l ⊤ e i l ) . g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \mathrm{TopK}(\{s_{j,t} \mid 1\le j\le mN\}, mK) \\ 0, & \text{otherwise} \end{cases}, \qquad s_{i,t} = \mathrm{Softmax}{i}(\mathbf{u}^{l}{t}{}^{\top} \mathbf{e}^{l}_{i}). gi,t={si,t,0,si,t∈TopK({sj,t∣1≤j≤mN},mK)otherwise,si,t=Softmaxi(utl⊤eil).
其中 e i l \mathbf{e}^{l}_{i} eil 为专家 i i i 的 router 向量。效果 :组合数从 ( N K ) \binom{N}{K} (KN) 变为 ( m N m K ) \binom{mN}{mK} (mKmN),例如 N = 16 , K = 2 , m = 4 N=16,K=2,m=4 N=16,K=2,m=4 时从 120 增至约 44 亿种组合,路由更灵活,有利于专家专业化。
🔍 实际例子:原来 16 个「大专家」、对序列里的每一个 token,路由器只选出 2 个专家来算这个 token。相当于 16 选 2;现在 64 个「小专家」、每 token 选 8 个,相当于 64 选 8,可表达的「专家组合」种类暴增,每个小专家可以更专注一类子任务。
4.2 s i , t s_{i,t} si,t 的分数计算(路由分数从何而来)
s i , t s_{i,t} si,t 表示「当前 token t t t 对专家 i i i 的亲和度分数」,计算分两步。
第一步:点积得到原始分数(logit)
logit i = u t l ⊤ e i l \text{logit}i = \mathbf{u}^{l}{t}{}^{\top} \mathbf{e}^{l}_{i} logiti=utl⊤eil
- u t l \mathbf{u}^{l}_{t} utl:token t t t 在该层 MoE 的输入隐藏状态 ( d d d 维),即经过自注意力与残差后的向量。
- e i l \mathbf{e}^{l}_{i} eil:专家 i i i 的 router 向量 (同样 d d d 维),由训练学习得到,可理解为「专家 i i i 擅长处理哪类 token」的方向。
点积越大,表示该 token 的表示与专家 i i i 的「偏好方向」越一致,越适合交给该专家处理。对 i = 1 , ... , m N i=1,\ldots,mN i=1,...,mN 各算一次,得到 m N mN mN 个标量。
第二步:对全体专家做 Softmax 归一化
s i , t = S o f t m a x i ( u t l ⊤ e i l ) s_{i,t} = \mathrm{Softmax}{i}\big(\mathbf{u}^{l}{t}{}^{\top} \mathbf{e}^{l}_{i}\big) si,t=Softmaxi(utl⊤eil)
下标 i i i 表示在「专家」这一维上做 softmax :固定 token t t t,把 m N mN mN 个专家的点积结果组成向量后做 softmax, s i , t s_{i,t} si,t 即为专家 i i i 对应的归一化分数。因此对每个 token t t t 有 ∑ i = 1 m N s i , t = 1 \sum_{i=1}^{mN} s_{i,t} = 1 ∑i=1mNsi,t=1,且 s i , t ≥ 0 s_{i,t} \ge 0 si,t≥0。
符号小结
| 符号 | 含义 |
|---|---|
| u t l \mathbf{u}^{l}_{t} utl | token t t t 的当前隐藏状态(MoE 层输入) |
| e i l \mathbf{e}^{l}_{i} eil | 专家 i i i 的 router 向量(可学习参数) |
| u t l ⊤ e i l \mathbf{u}^{l}{t}{}^{\top} \mathbf{e}^{l}{i} utl⊤eil | token 与专家的匹配度(标量 logit) |
| s i , t s_{i,t} si,t | 对全体专家 softmax 后、专家 i i i 的归一化分数 |
后续 Top- m K mK mK 路由即在这组 s 1 , t , ... , s m N , t s_{1,t},\ldots,s_{mN,t} s1,t,...,smN,t 中取最大的 m K mK mK 个专家,仅它们对应的 g i , t g_{i,t} gi,t 非零并参与加权求和。
💡 专家分工是学出来的,不是人事先指定的 :我们并不会规定「专家 1 做数学、专家 2 做代码」;每个专家的 router 向量 e i l \mathbf{e}^{l}_{i} eil 与专家内部 FFN 参数均由训练学习得到。这类似于多头自注意力中的多个头------我们只设定头的数量与结构,每个头学到什么样的注意力模式、关注哪些特征,都由数据与损失驱动而自动形成。MoE 中不同专家「擅长」哪类 token/子任务,同样是在训练中隐式涌现的,而非人工分工。
4.3 共享专家隔离(Shared Expert Isolation)
做法 :从 m N mN mN 个专家中固定 K s K_s Ks 个为共享专家 ,每个 token 必定经过这 K s K_s Ks 个专家 ;其余 m N − K s mN - K_s mN−Ks 个为路由专家 ,仍用 Top- ( m K − K s ) (mK - K_s) (mK−Ks) 路由,使每 token 激活的专家总数仍为 m K mK mK( K s K_s Ks 共享 + ( m K − K s ) (mK - K_s) (mK−Ks) 路由),从而计算量不变。
数学形式(论文式 9--11):
h t l = ∑ i = 1 K s F F N i ( u t l ) + ∑ i = K s + 1 m N g i , t F F N i ( u t l ) + u t l , \mathbf{h}^{l}{t} = \sum{i=1}^{K_s} \mathrm{FFN}{i}(\mathbf{u}^{l}{t}) + \sum_{i=K_s+1}^{mN} g_{i,t}\, \mathrm{FFN}{i}(\mathbf{u}^{l}{t}) + \mathbf{u}^{l}_{t}, htl=i=1∑KsFFNi(utl)+i=Ks+1∑mNgi,tFFNi(utl)+utl,
g i , t = { s i , t , s i , t ∈ T o p K ( { s j , t ∣ K s + 1 ≤ j ≤ m N } , m K − K s ) 0 , otherwise . g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \mathrm{TopK}(\{s_{j,t} \mid K_s+1\le j\le mN\}, mK - K_s) \\ 0, & \text{otherwise} \end{cases}. gi,t={si,t,0,si,t∈TopK({sj,t∣Ks+1≤j≤mN},mK−Ks)otherwise.
效果 :通用知识集中在共享专家中,路由专家更专注于差异化、专业化知识,减少不同专家之间的参数冗余,进一步提升参数效率。
💡 理解要点:共享专家 = 「必选课」,路由专家 = 「选修课」;必选课承担共通基础,选修课各司其职,避免重复建设。
4.4 负载均衡(Load Balance)
MoE 训练中常出现路由崩塌 (少数专家被过度选择)或设备间负载不均。DeepSeekMoE 使用两类辅助损失:
- 专家级均衡损失 L E x p B a l \mathcal{L}_{\mathrm{ExpBal}} LExpBal:鼓励各路由专家被选中的频率与门控期望不要偏差过大,缓解路由崩塌。
- 设备级均衡损失 L D e v B a l \mathcal{L}_{\mathrm{DevBal}} LDevBal:当专家分布在不同设备上时,鼓励各设备上的总计算量接近,减少瓶颈。详见论文式 (12)--(17)。
4.5 到底怎么选专家?专家矩阵多大?
下面用「工程实现」视角,把 4.1~4.4 落到可执行步骤。
4.5.1 每个 token 如何选择要激活的专家
对单个 token 向量 u ∈ R d \mathbf{u}\in\mathbb{R}^{d} u∈Rd(例如 d = 4096 d=4096 d=4096):
- 用 router 计算它对每个专家的分数。可理解为一个线性层:
s = S o f t m a x ( W r u ) \mathbf{s} = \mathrm{Softmax}(W_r \mathbf{u}) s=Softmax(Wru),其中 W r ∈ R m N × d W_r\in\mathbb{R}^{mN\times d} Wr∈RmN×d。 - 如果有共享专家(前 K s K_s Ks 个),它们直接激活(不参与竞争)。
- 在其余路由专家里,取 Top- ( m K − K s ) (mK-K_s) (mK−Ks) 个分数最大的专家。
- 只运行这些被选中的专家 FFN,得到输出后按门控权重加权求和,再加残差。
可写成极简伪代码:
python
scores = softmax(W_router @ u) # [mN]
active_shared = [0, 1, ..., K_s - 1] # 固定激活
active_routed = topk(scores[K_s:], mK - K_s) # 竞争激活
active = active_shared + active_routed
h = u + sum(scores[i] * expert_i(u) for i in active)💡 一句话记忆:先「打分」,再「选前几名」,只算被选中的专家。
4.5.2 专家里的矩阵大小到底是多少
一个专家本质上就是一个 FFN。若按 LLaMA/DeepSeek 常见 SwiGLU 形式,可写成:
F F N ( u ) = ( S w i s h ( u W 1 ) ⊙ ( u W 3 ) ) W 2 . \mathrm{FFN}(\mathbf{u}) = \big(\mathrm{Swish}(\mathbf{u}W_1)\odot(\mathbf{u}W_3)\big)W_2. FFN(u)=(Swish(uW1)⊙(uW3))W2.
若输入维度为 d model d_{\text{model}} dmodel、中间维度为 d f f d_{ff} dff,则单个专家参数形状通常为:
- W 1 W_1 W1: d model × d f f d_{\text{model}}\times d_{ff} dmodel×dff
- W 3 W_3 W3: d model × d f f d_{\text{model}}\times d_{ff} dmodel×dff
- W 2 W_2 W2: d f f × d model d_{ff}\times d_{\text{model}} dff×dmodel
细粒度切分(系数 m m m)后,每个小专家中间维度变为 d f f / m d_{ff}/m dff/m,即:
- W 1 W_1 W1: d model × ( d f f / m ) d_{\text{model}}\times (d_{ff}/m) dmodel×(dff/m)
- W 3 W_3 W3: d model × ( d f f / m ) d_{\text{model}}\times (d_{ff}/m) dmodel×(dff/m)
- W 2 W_2 W2: ( d f f / m ) × d model (d_{ff}/m)\times d_{\text{model}} (dff/m)×dmodel
专家数量从 N N N 变为 m N mN mN,每 token 激活从 K K K 变为 m K mK mK,因此整体保持「总专家参数不变、每 token 计算量近似不变」。
4.5.3 一个和本文一致的数字例子
设某层原本是 GShard 风格:
- N = 16 , K = 2 N=16,\ K=2 N=16, K=2
- d model = 4096 , d f f = 11008 d_{\text{model}}=4096,\ d_{ff}=11008 dmodel=4096, dff=11008(常见量级)
则「一个大专家」大致是:
- W 1 W_1 W1: 4096 × 11008 4096\times11008 4096×11008
- W 3 W_3 W3: 4096 × 11008 4096\times11008 4096×11008
- W 2 W_2 W2: 11008 × 4096 11008\times4096 11008×4096
现在做 DeepSeekMoE 细粒度切分,取 m = 4 m=4 m=4:
- 专家数: 16 → 64 16\rightarrow64 16→64
- 每 token 激活: 2 → 8 2\rightarrow8 2→8
- 每个小专家中间维度: 11008 → 2752 11008\rightarrow2752 11008→2752
- 每个小专家矩阵:
W 1 : 4096 × 2752 , W 3 : 4096 × 2752 , W 2 : 2752 × 4096 W_1: 4096\times2752,\ W_3: 4096\times2752,\ W_2: 2752\times4096 W1:4096×2752, W3:4096×2752, W2:2752×4096
若再加共享专家(例如 K s = 2 K_s=2 Ks=2):
- 每个 token 固定走 2 个共享专家;
- 其余 6 个从 62 个路由专家里 Top-6 选出;
- 最终总激活数仍是 8(计算预算不变)。
🔍 直观理解:共享专家负责「通用基础能力」,路由专家负责「差异化能力」;token 先上必修课(共享),再选修最匹配的 6 门课(路由)。
5. 与 Transformer、LLaMA、GShard 的架构对比
| 维度 | 标准 Transformer | LLaMA | GShard 式 MoE | DeepSeekMoE |
|---|---|---|---|---|
| 骨架 | Encoder-Decoder | Decoder-only | Decoder-only(部分层 MoE) | Decoder-only(部分层 MoE) |
| FFN 层 | 每层单一 FFN,全量计算 | 每层单一 FFN,全量计算 | 部分层为 MoE: N N N 专家、Top- K K K 激活 | 部分层为 MoE:m N mN mN 细粒度专家 ,K s K_s Ks 共享 + ( m K − K s ) (mK-K_s) (mK−Ks) 路由 |
| 专家粒度 | --- | --- | 粗( N N N 个完整 FFN) | 细(每个专家为 1/m 个标准 FFN) |
| 共享专家 | --- | --- | 无 | 有 ( K s K_s Ks 个常开) |
| 归一化 / 注意力 | LayerNorm, Post-Norm, ReLU | RMSNorm, Pre-Norm, SwiGLU, RoPE | 与骨干一致(如 LLaMA) | 与骨干一致(如 LLaMA) |
| 设计目标 | Seq2Seq | 通用生成 | 参数扩展、省计算 | 专家专业化 + 省计算 |
💡 理解要点 :Transformer / LLaMA 是「每层一个 FFN,全 token 全算」;GShard 是「每层多专家、每 token 只算 Top- K K K」;DeepSeekMoE 在 GShard 思路上做了细粒度切分 和共享专家,在不增加单 token 计算的前提下提高专家专业化与参数效率。
6. 规模与配置概览(2B / 16B / 145B)
论文给出了三种规模的配置与效果,便于理解「总参数 vs 激活参数 vs 计算量」的差异。
6.1 DeepSeekMoE 2B(验证架构)
- 总参数 :约 2B;激活参数:约 0.3B。
- 配置 :9 层,隐藏维度 1280;MoE 层:1 个共享专家 + 63 个路由专家 ,每个专家为标准 FFN 的 0.25 倍 ;每 token 激活 1 共享 + 7 路由 (即 K s = 1 K_s=1 Ks=1, m K − K s = 7 mK-K_s=7 mK−Ks=7)。
- 结果 :在多项基准上优于 GShard 2B、与 GShard 2.9B 相当(后者专家参数与计算约为 1.5×);并接近同参数量稠密模型(MoE 理论上界),说明架构有效。
6.2 DeepSeekMoE 16B(实用规模)
- 总参数 :约 16.4B;激活参数:约 2.8B。
- 配置 :28 层,隐藏维度 2048;除第一层外均为 MoE:2 共享 + 64 路由 ,专家大小为标准 FFN 的 0.25;每 token 2 共享 + 6 路由。
- 结果 :在约 40% 计算量 下,与 DeepSeek 7B 、LLaMA2 7B(稠密)表现相当;Chat 版与 DeepSeek Chat 7B、LLaMA2 SFT 7B 可比。单卡 40GB 可部署。
6.3 DeepSeekMoE 145B(初步探索)
- 总参数 :约 144.6B;激活参数:约 22.2B。
- 配置 :62 层,隐藏维度 4096;4 共享 + 128 路由 ,专家大小为标准 FFN 的 0.125 ;每 token 4 共享 + 12 路由。
- 结果 :在约 28.5% (甚至 18.2% ,半激活版本)计算量下,与 DeepSeek 67B(稠密)表现相当;相对 GShard 137B 有稳定优势。
🔍 实际例子:16B 的 DeepSeekMoE 用「约 2.8B 激活参数、约 40% 的 FLOPs」达到 7B 稠密模型的效果;145B 版本用「约 22B 激活、约 28.5% 计算」对标 67B 稠密,体现了「大参数、小激活」的 MoE 优势。
7. 小结与相关文档
- DeepSeekMoE 在 Decoder-only 骨架下,用 MoE 层 替代部分 FFN,通过细粒度专家切分 和共享专家隔离提升专家专业化,在总参数更大、激活计算更少的情况下逼近稠密模型性能。
- 与 Transformer (每层单一 FFN)、LLaMA (同上 + RMSNorm/SwiGLU/RoPE)、GShard (粗粒度 Top- K K K MoE)的差异主要体现在:专家粒度更细、引入共享专家、以及负载均衡设计。
- 论文实验表明:2B 接近 MoE 理论上界,16B 以约 40% 计算对标 7B 稠密,145B 以约 28.5% 计算对标 67B 稠密。
相关文档:
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比
- Transformer 13. DeepSeek LLM 架构解析:与 LLaMA 以及 Transformer 架构对比
论文 :DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. arXiv:2401.06066.