论文总结
2、对于生物年龄的预测,作者的方法和现有研究有些差异。作者认为:个体的实际老龄化程度本质上是一个潜变量,目前缺乏测量的金标准8,13,46。传统的老化模型主要依靠有监督的方法,目标是更准确地预测实际年龄13;然而,年龄的准确预测并不意味着衰老的准确评估。 正如现有证据所述,衰老的代谢物如端粒长度47和表观遗传年龄13与不良结局显示出微弱的相关性,这也在我们的结果(图2b , c)中观察到。 因此,我们采用最新的观点,使用一种无监督的方法来更好地捕获老化信号13。
3、这篇论文提出利用大语言模型(LLM) 基于常规健康体检报告预测个体的整体生物学年龄 和六个器官特异性年龄(心血管、肝脏、肺、肾脏、代谢、肌肉骨骼)。研究在六个大规模人群队列(总样本量超1000万)中验证,结果显示:
-
LLM预测的整体年龄对全因死亡率的预测效能(C-index=0.757)显著优于传统衰老指标(如表观遗传时钟、衰弱指数、端粒长度等)。
-
年龄差(预测年龄−实际年龄)与多种衰老相关表型、慢性疾病及死亡风险显著相关,是独立的风险因子。
-
LLM具备强泛化能力 和动态评估能力,能利用历史健康数据不断优化预测。
-
基于LLM识别的蛋白质组学生物标志物中,56.7%为新型候选蛋白,且能有效预测死亡和疾病。
-
可解释性分析(思维链、SHAP等)显示LLM的决策与现有流行病学证据一致。
摘要
准确且便捷的个体衰老评估对于识别健康风险和预防衰老相关疾病至关重要。然而,当前的衰老代理指标常面临方法学限制、不良结局关联薄弱以及普遍适用性有限等挑战。本文提出一个框架,利用大型语言模型(LLM)仅凭健康检查报告估算个体整体和器官特异性衰老。我们在六个基于人群的队列中验证了该方法,涵盖超过1000万参与者,并证明了其有效性和可靠性。结果显示,LLM预测的整体年龄在全因死亡率中达到了0.757(95% CI 0.752--0.761)的一致性指数(C指数),显著优于端粒长度、虚弱指数、八个表观遗传年龄和四个机器学习模型预测。整体年龄差距与多种衰老相关表型和健康结局高度相关,所有原因死亡的危险比为1.055(95% CI 1.050--1.060)。对于器官特异性衰老,LLM预测的年龄和年龄差距在预测相应器官特异性疾病方面也优于机器学习模型。此外,我们还考察了LLMs的动态衰老评估能力,并利用年龄差距识别与加速衰老相关的蛋白质组生物标志物,并开发了270种疾病的风险预测模型。还进行了可解释性分析,以探讨LLMs的决策过程。总之,我们的基于LLM的衰老评估框架提供了一种精确、可靠且经济高效的整体及器官特异性衰老估算方法。它具有在大规模普通人群中个性化衰老评估和健康管理的潜力。
引言
衰老是导致死亡和慢性病的主要风险因素,给社会带来了重大健康负担1--5。以往研究表明,衰老是一个复杂且多维的过程6,7,在身体8,9、器官10--12、分子13,14及其他层面表现出显著的异质性,受环境和遗传等多种因素影响15。对于临床实践,整体衰老代理指标能更好地评估整体健康状况,而器官特定衰老代理则能洞察特定器官的健康状况。所有代理指标无法用年代年龄充分表示。因此,必须开发整体和器官特定的衰老代理指标,以更准确反映多维衰老的进程,从而指导健康风险和潜在干预措施2,8,16。尽管有这一需求,开发实用方法以准确且便捷地评估大规模普通人群的衰老仍是一个关键挑战8。以往的研究已发展出多种衰老代理指标,如虚弱指数和生物年龄。虚弱指数评估整体情况衰老涵盖多个方面,包括身体、认知、心理、感官、营养、社会和疾病7,17,18,而生物年龄则反映整体或器官特定的衰老,从表观遗传19--21、表型标记22、23和多组学标志物10、13、24、25。尽管前景看好,这些代理面临三大挑战:方法学局限、与不良结果关联较弱以及泛化性有限8,13。首先,传统的生物年龄模型通常采用监督学习方法训练,标签为时间顺序13。证据表明,虽然更大的样本量和更高维度的特征提高了按年龄预测的时间顺序,但它们也往往会抹去年龄差距与衰老之间的关联13。其次,传统的生物衰老代理指标与不良健康结果的关联较弱8,13。这可能是因为以往的代理指标只捕捉衰老的特定方面,而忽视了其他影响因素。尽管虚弱指数与不良结局相关性较强,但目前仅限于整体衰老,主要应用于中年和老年人群体7,18。第三,大多数代理是为特定群体设计的,限制了其在不同区域的泛化性8。此外,在现实医疗环境中,针对大规模普通人群的老龄评估还需考虑经济成本和便利性。例如,由于成本高昂且程序复杂,表观遗传数据的测量往往不切实际。有人建议,非监督模型可能更适合捕捉老化信号13。作为迄今为止最先进的无监督模型,大型语言模型(LLM)首先会在各领域积累大量知识进行预训练,以获得通用能力26。然后,他们会被微调以激活其领域专长,包括衰老。在实际应用中,LLM可以利用获得的衰老相关知识和个性化健康信息,通过生成最可能的token,直接推断个体衰老状态。该框架可能解决上述三个关键挑战。(1) LLM避免了传统监督模型中常见的老化测量标签问题13。(2)LLM整合了更广泛的相关因素,如生物指标、生活方式、社会经济地位、病史和遗传因素,这些因素与衰老密切相关15,以推断个体衰老。这加强了衰老代理与不良结果之间的关联。(3)LLM可以处理任何格式的数据,这与传统的机器学习模型需要预定义格式不同。这种便利性使其非常适合在初级医疗环境中大规模应用。仅凭健康检查报告,LLMs即可快速全面评估个体整体及特定器官的衰老,促进专家级医疗资源的公平性和可及性27。因此,本研究重点是利用和验证大型语言模型(LLM)来评估多维普通人群中的衰老,旨在探索该框架的更广泛应用。我们利用了五个具有全国代表性的人群:英国生物样本库(UKB)、国家健康与营养检查调查(NHANES)、中国健康与退休纵向研究(CHARLS)、中国纵向健康长寿调查(CLHLS)和中国家庭小组研究(CFPS),以及我们的数据------西北中国真实世界与基于人口的队列(NCRP),总样本超过一千万个,以评估该框架的表现。本研究概述见图1。首先,我们基于常规健康指标构建了文本健康检查报告,并使用八个大型语言模型(LLM)通过快速学习评估个体整体和器官特异性衰老(提示见扩展数据图1)。我们将这些LLM预测的年龄定义为更全面的衰老代理指标,基于多项测量的组合。随后,我们通过考察预测年龄、年龄差距(LLM预测年龄与实际年龄的差异)与多种衰老相关不良结局之间的关联,验证了这些代理指标。我们对结果进行了比较传统机器学习模型及其他经典衰老代理指标(例如表观遗传年龄、端粒和虚弱指数)。最后,我们考察了LLMs的动态衰老评估能力,应用了生物和临床下游任务中的年龄差距,并对LLMs在评估衰老中的可解释性进行了分析。
结果
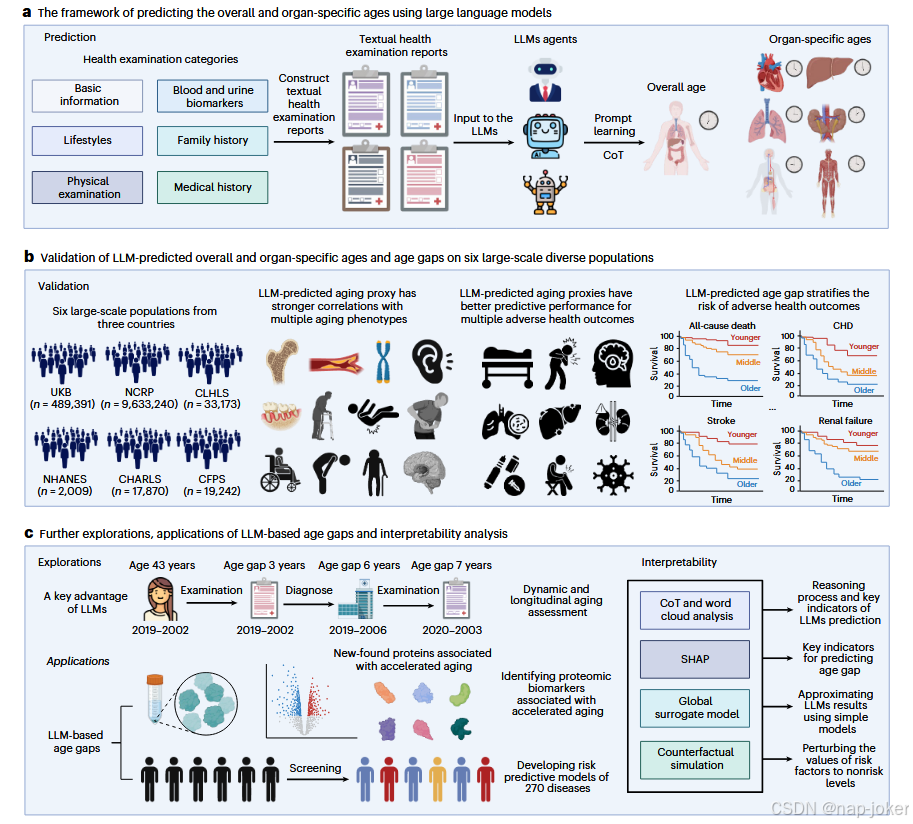
图1 |学习概述。a, 利用LLM预测整体及器官特异年龄的框架。器官特定年龄包括心血管年龄、肝脏年龄、肺年龄、新陈代谢年龄和肌肉骨骼年龄。b、对六个多样化人群进行验证。我们首先验证了LLM预测的年龄是否与传统机器学习模型及其他经典衰老代理相比,与衰老相关表型及不良健康结局的关联更强。随后,我们对六个队列进行了生存分析,以验证年龄差距在区分不良健康结局风险方面的表现。 c、进一步探讨LLM优势、基于LLM的年龄差距应用及可解释性分析。我们考察了LLMs的动态和纵向衰老评估能力,并探讨了基于LLM的年龄差距在生物学和临床下游任务中的应用,如识别与加速衰老相关的蛋白质组生物标志物和建模个人健康风险。可解释性分析揭示了LLMs的内部预测过程。图像是用BioRender创建的。
研究对象
六个基于人口的队列包括UKB(n = 489,391,年龄范围38--73岁,女性54.3%)、NHANES(人口=2,009,年龄范围50--75岁,女性48.3%)、NCRP(n=9,633,240,年龄范围18--110岁,女性52.5%)、CHARLS(n=17,870,年龄范围40--70岁,女性50.8%)、CLHLS(n=33,173,年龄范围80--123岁,女性61.6%)和CFPS(n=19,242,年龄范围40--70岁,女性51.0%),总计参与者10,194,925人。UKB随访11--16年,NHANES随访17--20年,NCRP随访5年,CLHLS随访10--20年,CFPS随访6--10年,分别记录了42,737人(8.7%)、875人(43.6%)、307,331人(3.2%)、24,293人(73.2%)和1,135人(5.9%)。CHARLS的死亡记录并非每次随访均公开,因此我们未进行相关分析。此外,英国地区LLM预测的总体年龄中位数为62岁(范围35--85岁)。其他人群特征可见补充表1。
LLMs能够有效预测整体和器官特定的年龄
为了验证LLM能够有效预测整体和器官特异年龄,我们进行了多项分析,将LLM的预测与其他衰老代理指标(包括年龄年龄、虚弱指数(补充表2)、端粒长度、八个表观遗传年龄和四个ML预测年龄(方法)进行比较。我们首先比较了6个不同衰老代理与12个衰老相关表型之间的关联。这些代理包括时间年龄、4个ML预测的整体年龄和LLM预测的整体年龄。结果表明,LLM预测的整体年龄在五个表型中表现出显著更强的关联性,优于其他代理指标:脚跟骨矿物质密度(β = −0)。 127,95% CI −0.140至−0.115)、牙齿问题(β = 0.170,95% CI 0.144--0.197)、行走缓慢(β = 0.521,95% CI 0.456--0.586)、长期疾病(β = 0.514,95% CI 0.483--0.546)及虚弱指数(β = 0.226,95% CI 0.214--0.237)。此外,与四种ML预测的整体年龄相比,LLM预测的整体年龄在十种表型间的相关性显著增强(见图2a)。随后,我们进一步比较八个衰老代理指标的一致性指数(C指数),以预测36项健康结局。LLM预测的整体年龄在全因死亡率(0.757,95% CI 0.752--0.761)、冠心病(CHD)(0.709,95% CI 0.698--0.721)、中风(0.733,95% CI 0.714--0.752)、慢性阻塞性肺病(COPD)(0.735,95% CI 0.7140.757)、肾衰竭(0.767,95% CI 0.758--0.775)、关节炎(0.673,95% CI 0.666--0.681)及其他22项结局(图2b及扩展数据图2a)方面表现优异。此外,我们分析了NHANES 1999--2002队列的数据,比较LLM预测的整体年龄与八个表观遗传年龄在预测全因及特定原因死亡率上的预测表现。结果增强了我们对UKB的研究结果,表明LLM预测的整体年龄在预测全因死亡率方面持续获得更高的C指数(0.716,95% CI 0.697--0.735)和特定原因死亡率(见图2c)。为进一步验证LLM预测的器官特异年龄在预测器官特异性疾病方面是否优于ML预测的年龄,我们还比较了它们的C指数。结果显示,LLM预测的心血管、肝脏、肾脏和肌肉骨骼年龄在相应器官特异性结局中均表现出显著更高的C指数(图2d)。进行了敏感性分析以评估我们发现的稳健性(方法)。结果显示,LLMs的性能稳健,且未受以下因素显著影响报告写作风格或提示模板变体(附图。表1 - 4和附表3)。
年龄差距是不良结局发生的强预测因子
根据模型预测的年龄,可以计算出相应的年龄差距。具体而言,基于LLM的年龄差距是指LLM预测的年龄与实际年龄之间的差异,而基于ML的年龄差距则被定义为ML预测的年龄对实际年龄回归的残差(方法)。我们首先比较了LLMs和4种ML模型得到的总体年龄差距与12种衰老相关表型之间的关联。结果表明,与ML模型相比,基于LLM的总体年龄差距与大多数表型之间表现出显著更强的相关性(图3a )。然后,我们估计了基于LLM的总体年龄差距与不良健康结果之间的关系。
随着总体年龄差距的增加,随访期间事件累积发生率的变化趋势(图3b ),表明总体年龄差距可以判别疾病风险。即使在Cox模型中调整共同协变量后,总体年龄差距仍然是全因死亡(风险比( HR )) ( 1 )的独立危险因素。055,95 % CI 1 . 050 ~ 1 . 060 )、冠心病( HR 1 . 072,95 % CI为1 . 067 ~ 1 . 077)、脑卒中( HR 1 . 058,95 % CI 1 . 049 ~ 1 . 067)和其他结局(附表4)。为了估计基于LLM的器官特异性年龄差距与健康结果之间的关联,我们使用Cox模型,调整共同协变量(图3c和附表4)。在UKB中,心血管年龄差距的增加与心血管疾病的相关性更强,如CHD ( HR 1 . 045,95 % CI为1 . 042 ~ 1 . 049 )和行程( HR 1 . 029,95 % CI为1 . 022 ~ 1 . 035)。其他5个器官的年龄差距也发现了类似的规律,表明每个器官特异性年龄差距与相应器官特异性疾病的关联更强。值得注意的是,我们还发现器官-整体年龄差距是健康结局(方法和图3d)的独立危险因素。这种器官-整体的年龄差距表明了一个特定器官相对于整体衰老的速度有多快。Cox分析显示,心血管-总体年龄差距是8个健康结局的显著危险因素,与冠心病( HR 1 . 073,95 % CI为1 . 064 ~ 1 . 082)和脑卒中( HR 1 . 063,95 % CI为1 . 047 ~ 1 . 079)的相关性最强。 此外,其他器官-总体年龄差距的增加也与器官特异性疾病(附表5)的风险增加有关。综上,对于年龄快于机体整体的器官,其相应的疾病风险会增加。在补充分析中,我们比较了基于LLM的年龄差距与端粒长度、衰弱指数和其他年龄差距(扩展数据图。2b和3 )的预测性能。结果表明,对于大多数健康结果,基于LLM的年龄差距达到了最高的C指数。
LLMs在衰老评估中的优势
除了可以更好地预测不良结局的无监督老化建模外,LLMs在老化评估方面还具有三个优势,包括泛化性强、能力演化和动态老化评估。为了研究的可推广性,我们在NCRP,CHARLS,CFPS和CLHLS上重复了上述分析。在NCRP、CHARLS和CFPS (图4a , b和扩展数据图4a - c , f , g)中观察到与主要发现类似的结果,表明LLMs具有很强的可推广性;然而,在CLHLS和NCRP (扩展数据图4d , e , h)的老年参与者中发现了相反的结果,这意味着目前的LLMs可能不太适合评估老年个体的衰老。对于能力进化,我们比较了来自8个LLMs的预测年龄在预测健康结果中的作用。 结果显示,在大多数健康结果中,Llama370B - Instruct比Llama3 - 8B - Instruct具有更高的C指数。同理,在Qwen1中。5和Qwen2序列,随着模型参数规模的增大,C指数呈现上升趋势。此外,Qwen2 - 72B - Chat的表现优于Qwen1。与Qwen1相比,多数情况下5 - 72B - Chat和Qwen2 - 7B - Chat获得了更高的C指数。5个参数低于32B的模型(图4c )。总的来说,较大的参数和较新的LLMs通常预测得更好。这意味着一般LLMs可以通过增加知识密度来增强其老化评估能力,而不需要对额外的人口数据进行增量训练,这强调了在能力演化方面的优势。与使用2年期报告( 0。613,95 % CI 0 . 590 ~ 0 . 635)或仅使用1年期报告( 0。610,95 % CI 0 . 587 ~ 0 . 633)相比。这些发现意味着LLMs可能通过积累纵向数据和更新记忆来加强其老化建模,从而实现随着时间的推移而越来越精确的预测。
与加速衰老相关的蛋白质组学生物标志物
为了鉴定与加速老化相关的蛋白质组学生物标志物,我们进行了差异分析(方法)。结果显示,总体年龄差距在前10 %和后10 %的参与者之间的蛋白质丰度存在显著差异,瘦素( leptin,LEP ) ( log2倍变化( log2FC )),1显著上调。737 )、催产素/后叶激素运载蛋白I前原肽( oxytocin /后叶激素运载蛋白I prepropeptide,OXT ) ( 1.615 )、成纤维细胞生长因子21 ( fibroblast growth factor 21,FGF21 ) ( 1.614 )、胎盘碱性磷酸酶( alkaline phosphatase,placental,ALPP ) ( 1.089 )和清道夫受体富含半胱氨酸家族成员4结构域( scavenger receptor cysteine rich family member with four domains,SSC4D ) ( 1.043 );下调胰岛素样生长因子结合蛋白1 ( insulin like growth factor binding protein 1,IGFBP1 ) ( -1.067 )、生长激素1 ( growth hormone 1,GH1 ) ( -0.763 )、胰岛素样生长因子结合蛋白2 ( insulin like growth factor binding protein 2,IGFBP2 ) ( -0.643 )、碳酸酐酶6 ( CA6 ) ( - 0 . 479 )和促肾上腺皮质激素释放激素( CRH ) ( -0.447 ) (图5a ;调整后P < 0 . 001) .先前的研究表明,LEP28,OXT29,FGF21 ( ref.30 ),IGFBP1 ( ref.31 ),IGFBP2 ( ref.31 )和GH1 ( ref.32 )等基因与衰老相关,与我们的结果一致。此外,器官特异性年龄差距也与相应的器官功能相关。例如,有证据表明羟酸氧化酶1 ( HAO1 ) 33和FGF21 (参考34 )与肝脏功能有关,这与我们对肝脏( HAO1 , log2FC = 1 . 122 ; FGF21 , log2FC = 1 . 223 ;扩展数据图6a和补充表6)的研究结果一致。蛋白质组学富集分析确定了整体衰老与脂质氧化之间的显著关联(标准化富集分数( normalized enrichment score , NES )) = 2。 05 )、脂质修饰( NES = 2。08)和一元羧酸分解代谢( NES = 1。96) (图5b ),与前人研究结果一致35。器官特异性衰老通路在Extended Data Fig 6b中进一步详细说明。遵循蛋白质组学24中的经典方法,LLM鉴定的衰老相关蛋白与已建立的衰老生物钟20,24,36 - 40 (例如,有蛋白质预测年龄( ProtAge )的49例)重叠;图5c和附表7 ),但发现了316个新候选者( 56。7 %在以往研究中未见报道)。半数以上预测全因死亡率( C指数> 0.5 ; P < 0.05),表现最好的是(例如胰岛素样生长因子结合蛋白4 ( insulin like growth factor binding protein 4 , IGFBP4 )),C指数0。681;图5d )超过临床相关性阈值。 器官特异性蛋白(例如,心血管和肝脏)也表现出大于53 %的新颖性(扩展数据图7)。LLM鉴定的衰老相关蛋白预测全因死亡和疾病的结果详见附表8和附表9。我们还比较了随着蛋白质(图5d和附表9)数量的减少,老化时钟在预测全因死亡率方面的性能。LLM -衰老蛋白模型的C - index与Prot Age ( P = 0。216)相当,但显著高于经典霍瓦特clock和DNAm Pheno Age clock ( P < 0 . 001)。 同样,对于CHD、COPD、肾脏疾病和2型糖尿病( T2D )等疾病,LLM -老化蛋白模型与Prot Age无统计学差异,但优于霍瓦特时钟和DNAm Pheno Age时钟。值得注意的是,对于肝脏疾病,LLM -老化蛋白模型优于所有其他老化时钟,包括Prot Age (附表10)。总之,利用LLMs,我们鉴定了与加速衰老相关的蛋白质组学生物标志物,包括与已建立的衰老生物钟重叠的生物标志物和新的生物标志物。这些LLM定义的衰老相关蛋白在预测全因死亡率和各种疾病,尤其是肝脏疾病方面优于传统的衰老生物钟。
利用年龄差距对个体健康风险进行建模
为了探索基于LLM的年龄差距的临床应用,我们系统地分析了它们与270种疾病(方法)的关联。之后,调整共同的协变量后,结果显示总体年龄差距与肾小球肾炎( HR 1 . 267,95 % CI为1 . 208 ~ 1 . 330)的相关性最强。第二和第三高HR分别为胰腺分泌紊乱( HR 1 . 240,95 % CI 1 . 207 ~ 1 . 272)和动脉粥样硬化( HR 1 . 236,95 % CI为1 . 202 ~ 1 . 272) (图5e )。年龄差距与其他疾病之间的显著关联见扩展数据图8和补充表11。利用常见的临床预测因子和总体年龄差距,我们建立了风险预测模型。结果显示,将总体年龄差距纳入模型预测子宫癌的C指数最高,达到0。861 ( 95 % CI为0 . 816 ~ 0 . 897)。 观察到胸膜斑块( 0。857,95 % CI 0 . 821 ~ 0 . 886)和Bartholin腺疾病( 0。837,95 % CI 0 . 741 ~ 0 . 902)的第二和第三高C指数(图5f )。纳入总体年龄差距有助于预测性能(扩展数据图9)的提高。我们的研究结果表明,基于LLM的年龄差距在疾病风险筛查中具有很大的潜力。此外,我们利用总体年龄差距来估计NCRP纵向队列中个体的加速老化速率。率被定义为总体年龄差距的平均年增长率,并计算了其与8种健康结果的关联。 结果显示,较高的加速老化率与全因死亡和多种疾病的风险增加显著相关(图5g )。这些发现为在纵向人口队列可获得性不断增强的背景下加速老龄化提供了新的视角8。
面向老化评估的LLMs可解释性分析
通过使用思维链( Chain of Thought,CoT ) 41,LLM为其预测(方法)提供了分步解释。图6a给出了这个推断过程的一个例子。我们从这些CoT输出中提取关键词并生成词云(图6b )。结果表明,手握力、体重指数( BMI )、呼吸测试和病史是预测总体年龄的关键因素,而吸烟状况、血压、胆固醇和酗酒是预测心血管年龄的关键因素。每个器官的年龄预测是根据与其功能具体相关的指标来确定的。我们还设计了一个多智能体管道,输出一个更加详细、透明的思维过程(扩展数据图10a , b)。 为了验证CoT推理的特征重要性,我们进行了SHapley Additive ExPlanations ( SHAP ) analysis42 ( Methods )。结果揭示了指标对单个案例和整个样本的贡献。对于一个有代表性的个体(图6c ),当前吸烟状态是最重要的预测因素,具有最高的正Shapley值,表明吸烟者的年龄差距增加。对于整个样本(图6d ),我们证实了BMI、收缩压和吸烟状态在影响年龄差距中的重要性。值得注意的是,通过SHAP确定的关键指标与CoT确定的关键指标以及先前的全球负担研究基本一致43。
为了进一步探索LLMs的决策过程,我们采用了全局代理模型方法44 ( Method )。结果显示,对于总体年龄的预测,腰臀比的回归系数为4。105 ( 95 % CI为3 . 840 ~ 4 . 370),日常健康食品(是)为- 1.117 ( ref =日常健康食品(不含);95 % Ci-1.188 ~ -1.046 )。这表明较高的腰臀比可能与预测的总体年龄呈正相关,而日常健康饮食则表现出相反的趋势。进一步的结果可以在图6e中找到。这些发现为预测因子与LLMs最终预测结果之间的函数关系提供了更直观的理解。 为了验证LLM识别的重要危险因素是否与流行病学证据一致,我们进行了45次反事实模拟(方法和图6f)分析。Wilcoxon符号秩检验结果显示,LLMs风险因素重要性排序与流行病学方法( P = 0。72)风险因素重要性排序无显著性差异。此外,LLM的预测显示与全球风险因素负担相一致43。所有证据表明,LLMs可能对流行病学知识有可靠的理解。
讨论
在本研究中,我们利用健康检查报告和LLMs通过即时学习来预测整体和器官特异性年龄。来自6个大规模人群队列的证据表明,LLM预测的总体年龄与大多数衰老相关表型和健康结果的关联最强,而LLM预测的器官特异性年龄与相应器官特异性疾病的关联更强。衍生的年龄差距有效地区分了各种健康结果的未来风险,在生物和临床下游任务中具有潜在的应用价值。与传统的统计模型和ML模型相比,LLMs具有更好的泛化能力,能够提供对老龄化的动态和纵向评估。 此外,可解释性分析表明,LLMs能够可靠地评估个体衰老。我们的研究为LLMs在大规模普通人群老龄化评估中的应用提供了证据。个体的实际老龄化程度本质上是一个潜变量,目前缺乏测量的金标准8,13,46。传统的老化模型主要依靠有监督的方法,目标是更准确地预测实际年龄13;然而,年龄的准确预测并不意味着衰老的准确评估。 正如现有证据所述,衰老的代谢物如端粒长度47和表观遗传年龄13与不良结局显示出微弱的相关性,这也在我们的结果(图2b , c)中观察到。 因此,我们采用最新的观点,使用一种无监督的方法来更好地捕获老化信号13。LLMs作为最强大的无监督模型,在预训练过程中获得了大量与老化相关的知识。他们将这些知识编码为模型参数,实现了信息压缩26,48。在推断过程中,LLMs利用这些先验知识和个体健康报告来评估多维老龄化。基于最大值概率预测机制26,LLMs可以推断老龄化的潜变量(附图。5和6 )。这种无监督的建模方法将更广泛的风险因素纳入到预测过程中,为整体和器官特异性衰老提供了更全面的代用指标。与传统方法(图。2和3 )相比,它与多种与衰老相关的表型和健康结果之间的联系更强,而(图。2和3 )是评估衰老指标的重要指标13。验证跨种群中的老化代理是重要的8,我们提出的方法具有很强的可推广性。 不同于传统的统计或ML模型,这些模型往往是针对特定人群开发的,难以转移到其他地区49,LLMs可以有效地评估不同人群的老龄化程度(图4a , b和扩展数据图4)。我们的方法的优势在于LLMs对变量设计、命名、计量单位和语言差异的适应性,使其能够专注于医学文本中的知识26,48。与基于表观遗传学和组学的老化时钟相比,所提出的框架成本低且更方便。这些能力和便利性使得LLM特别适合在低资源地区的应用。 值得一提的是,LLMs在所有队列中均表现不佳,CLHLS和NCRP的对比结果提示了一种可能性;目前LLMs在医学领域的可推广性可能无法在老年人群中推广。此外,对于脆弱人群,这种LLMs可能难以提供预测能力,这可能是由于缺乏来自这些群体的代表性预训练数据50 - 52。为了进一步确保LLMs在初级卫生保健机构中应用的公平性,有必要增加对弱势群体的关注,并使用包括这些群体在内的更具代表性的数据集来训练LLMs。与传统模型相比,LLMs的一个关键优势是其能够实时地学习和记忆53,54。 对于老龄化评估而言,这体现在LLMs能够将个体的历史健康数据与新发生的健康事件(例如,一种新疾病的诊断或重复的生物标志物测量)进行有效整合,从而实现对老龄化(扩展数据图5)的动态、实时评估。ML模型通常无法处理文本数据,这在初级卫生保健场景中很常见。它们还需要预定义的数据格式,使得处理不断积累和变化的信息具有挑战性。相比之下,LLMs可以轻松地处理真实世界的文本数据,并且随着更多历史数据的积累( 53,54 ),可以不断更新和完善他们对个体衰老的理解。最终,LLMs可以作为用户健康的数字孪生体。与依赖单一组学数据的传统老化生物钟,如霍瓦特的表观遗传生物钟20和Prot Age蛋白质组模型24相比,基于LLM的框架显示出更优异的多维整合和发现新的生物标志物,而这些生物标志物在以前的主要研究中没有报道过20,24,36 - 40;56。7 %的LLM鉴定的衰老相关蛋白( 316种蛋白)未被报道,其中55 . 1 %的新蛋白与全因死亡率显著相关。 此外,肿瘤坏死因子受体超家族成员12A ( tumor necrosis factor receptor superfamily member 12A,TNFRSF12A ) 55和激活素A受体样1型( activin A receptor like type 1,ACVRL1 ) 56可能通过调节炎症反应和血管内皮功能障碍参与全身衰老,而丝氨酸蛋白酶8 ( serine protease 8,PRSS8 ) 57和V - set and immunoglobulin domain containing 4 ( VSIG4 ) 58表现出器官特异性的预测能力,可能在上皮屏障维持和免疫微环境重塑中发挥作用。值得注意的是,少于40个LLM鉴定蛋白的稀疏组实现了对全因死亡率和慢性疾病的出色预测,与最新的基于专门蛋白质组学的ProtAge24相当,并优于Horvath20等传统老化时钟(图5d )。 虽然以欧洲为中心的队列限制了可推广性,但LLM驱动的框架本质上是可扩展的。未来的工作应优先验证这些发现的可能生物学机制。值得注意的是,我们的方法避免了大规模组学分析的成本和复杂性,表明临床文本挖掘可能为转化老人学研究确定重要的生物标志物。我们对基于LLM的年龄差距的临床应用进行了探索。先前的研究主要集中在评估年龄差距与全因死亡率之间的关系,以及几种重要的慢性疾病8,10 - 13,24。 与它们相比,我们的研究提供了基于LLM的270种疾病的年龄差距的综合评估,从而提供了加速老化和疾病的全景视图。结果表明,肾小球肾炎与整体加速衰老( HR 1 . 267)的相关性最高,这在之前的工作中没有发现。此外,通过结合常规临床预测因素和年龄差距,我们开发了270种疾病的风险预测模型(图5f )。我们的研究结果表明,仅使用年龄差距可以有效地预测各种疾病,纳入年龄差距可以提高模型性能(扩展数据图9),这与现有证据11是一致的。 我们还在纵向NCRP队列中评估了加速老化速率与健康结局之间的关联,发现较高的加速老化速率与全因死亡率和多种疾病的风险增加有关(图5g ),进一步丰富了纵向队列研究中加速老化的证据。8 .除了这些应用外,未来的研究可以利用LLMs探索其在加速老化个体个性化健康干预中的应用,旨在降低该群体发生不良结局的风险。
在医疗人工智能59中,可解释性和可靠性至关重要,我们尝试解决这些挑战。我们要求LLMs采用CoT方法显式地展示其内部推理过程41 (图6a )。词云分析显示,吸烟状况和肺功能检查是肺龄的关键指标,而饮食习惯和肝功能是肝龄的重要指标(图6b ),与已有知识一致。SHAP analysis42进一步表明,BMI、收缩压和当前吸烟是与加速衰老(图6c , d)相关的最大影响因素,这与之前的文献43一致。 全局代理模型揭示了LLMs在决策过程中潜在的潜在功能关系(图6e )。此外,反事实模拟分析强调与总体年龄差距最相关的危险因素与端粒长度的观察结果一致(图6f )。我们还开发了多智能体Pipeline60,以增强临床应用的鲁棒性和可靠性。总体而言,多个角度的证据表明,LLMs在衰老评估中的应用具有较高的可解释性和可靠性。目前的研究存在一些局限性。 首先,个体多维老化的评估不是基于多模态数据的,这可能会限制LLMs的预测性能;然而,仅使用文本健康报告提供了便利,促进了更广泛的人口覆盖。其次,本研究中使用的LLMs是通用模型,而不是专门的生物医学模型。他们没有专门针对生物医学数据进行训练,这可能会阻碍他们对衰老更深入的理解。尽管如此,这些通用LLMs的预训练数据包括来自PubMed和PubMed Central的数百万篇文章,其中有大量与衰老相关的研究。 第三,我们的可解释性分析没有发现与加速老化相关的新的不良预后因素,这是对现有知识的整合和验证。这是因为我们使用的数据来自常规健康报告,对相关指标的广泛研究已经存在。最后,目前仍然缺乏一个量化衰老的金标准,并且LLM预测的年龄和年龄差距的验证并不详尽。尽管如此,使用各种与衰老相关的表型和健康结果进行验证提供了一种相对可信的方法,并且在6个不同人群中的验证确保了我们结果的稳健性。我们的研究也提供了一些优势。 首先,本研究使用LLMs来评估个体的多维老化。我们创新性地提出了一种无监督的建模方法来评估老化。该方法生成的年龄估计值和年龄差距在预测各种衰老相关表型和健康结果方面优于表观遗传年龄和最先进的ML模型。其次,利用LLMs的强大泛化能力,我们验证了它们在数千万以上不同人群中评估老龄化的鲁棒性,以及独特的数据格式。第三,利用LLMs的"实时学习和记忆"能力,我们提供了一个动态老化评估框架,这对传统方法是具有挑战性的。 它可以处理累积的、纵向的健康信息,也可以对个体的老化轨迹进行建模。第四,所提出的老化评估框架方便且具有成本效益。LLMs只需要健康体检报告,就可以提供便捷、可靠、低成本的老龄化评估,增强了专家级医疗资源的公平性。第五,通过我们的方法,我们鉴定了多个与加速衰老相关的新的蛋白质组学生物标志物,并提供了衰老和疾病的全景视图。总之,LLMs可以利用常规健康体检报告来预测总体和器官特异性年龄。我们的研究在包括数千万总人口的六个队列中验证了该方法的有效性和可靠性。 通过应用LLM预测的年龄和年龄差距,我们可以实现对个体衰老和相关健康风险的更精确建模,从而提高大规模普通人群的健康效益。
方法
数据来源
来自UKB、NHANES、NCRP、CHARLS、CLHLS和CFPS的参与者被纳入本研究。我们使用UKB和NHANES进行初步分析,并使用其他四个队列作为进一步验证。UKB是来自全英国22个评估中心的前瞻性队列招募参与者,对全人群进行基线调查( 2006 - 2010年),并对选定的个体进行3次追踪调查( ( 2012 - 2013年、2014 +年、2019 +年) )。评估内容包括人口学信息、社会经济因素、生活方式、体格测量、血液检测和其他健康相关信息。在这项研究中,我们从最初的基线评估中纳入了489,391人,年龄在38 - 73岁和54岁之间。女性占3 %。 NHANES是美国自1999年以来通过两年评估周期持续开展的具有全国代表性的横断面调查。在这项研究中,我们使用了连续两个调查周期( 1999 - 2000年和2001 - 2002年)的数据,包括人口学特征、饮食摄入、检查数据、实验室生物标志物和问卷调查。为了建立纵向死亡随访,我们将这些调查中的21 004名0 ~ 85岁的参与者与2019年的国家死亡指数( National Death Index,NDI )记录联系起来。这种联系建立了一个包括11,432名参与者的前瞻性队列。 然后,我们将该队列与NHANES 1999 - 2002 DNA甲基化芯片和表观遗传生物标记数据集相关联,并选择50 - 75岁的参与者作为研究人群,共获得20009个个体( 48。3 %的女性)。本研究团队开发的NCRP是一项基于人群的大规模研究,旨在收集全面的纵向健康数据61。队列基线建立于2019年,使用来自7,523个初级医疗保健中心的居民健康档案和年度健康体检记录。通过年度健康体检计划进行随访,涵盖一般健康状况、生活方式因素、体格检查、血液生化检测和仪器评估5个关键类别。 此外,疾病诊断和实时入院记录从当地区域医疗系统记录中获得,从2016年至2023年。死因别死亡率数据从当地死亡登记处收集。最终,该队列共纳入9,633,240名参与者。CHARLS是一项前瞻性队列研究,收集了中国45岁及以上家庭和个人的高质量微观数据。2011年进行了全国基线调查,2013年、2015年、2018年和2020年进行了后续的全国追踪调查。CHARLS问卷包括人口学、家庭状况、健康状况、体格测量、社会经济和生活方式等内容,以及社区基本信息。 我们选取了2011年、2013年和2015年的17,870名参与者,年龄在40 - 70岁之间,其中包括50名女性。8 %。中国老年健康影响因素跟踪调查( CLHLS )是由北京大学健康老龄化课题组牵头开展的一项社会调查,调查对象为中国65岁及以上老年人及其后代。调查内容包括人口学信息、社会经济背景、家庭结构、生活方式、健康状况、病史、体格测量和死亡率调查等。追踪调查始于1998年,分别于2000年、2002年、2005年、2008 - 2009年、2011 - 2012年、2014年和2017 - 2018年进行了追踪调查,其中80岁及以上的老年人占67人。4 %。 在我们的分析中,我们从1998 - 2008年的5次浪潮中挑选了80岁以上的老年人(年龄80 ~ 123岁),共33173人,其中61人。6 %为女性。CFPS构成了全面的、纵向的社会调查倡议。该调查于2010年正式启动,随后每两年进行一次( 2012年、2014年、2016年、2018年、2020年)调查。该调查涵盖了广泛的研究主题,包括经济活动、教育、家庭关系、移民、健康等。从CFPS ( 2010、2012和2014年)最初的3次调查波中,我们抽取了19 242个样本,年龄在40 ~ 70岁之间,其中女性51.0 %。
用于评估老龄化的指标
在前期研究11的基础上,定义总体年龄和6个器官特异性年龄来评估衰老的不同维度,包括总体年龄、心血管年龄、肝龄、肺龄、肾龄、代谢系统年龄和肌肉骨骼年龄。考虑到不同队列收集的健康信息存在差异,我们在每个队列中纳入了不同的指标。在UKB中,我们纳入了几乎所有的常规指标,共计152项,以全面评估个体整体和器官特异性年龄(附表12)。 其中包括基本信息(年龄、性别、教育、就业、收入),生活方式(吸烟、饮酒、饮食、体力活动和睡眠情况),体格检查(人体测量,血压,手握力和肺活量测试),实验室测量(血常规、血生化及尿常规检查),以及家族史和病史。与以往研究手动选择评估器官特异性衰老的指标不同( 11(例如,只选取了脉率、收缩压和舒张压来预测心血管年龄) ),我们将这一选择过程分配给LLMs。 LLMs可以通过CoT方法将个体个性化的健康数据与其预训练的器官特异性老化知识整合起来,为不同器官选择最相关的指标。通过利用注意力机制对这些指标进行综合分析,LLMs可以产生器官特异性年龄(详见" LLMs和预测过程"部分)的预测。对于1999 - 2000年的NHANES队列,我们纳入了124个指标,而对于2001 - 2002年的NHANES队列,我们纳入了114个变量。将这些指标分为5组:基本信息、生活方式因素、体格检查、实验室检查、病史(附表13)。 由于NHANES队列只包含与死亡相关的健康结果,我们使用所有可用的变量来允许LLMs预测总体年龄而不是器官特异性年龄,因为后者无法得到有效验证。
在NCRP中,纳入了69项健康体检指标,以评估总体和器官特异性年龄(附表14)。将这些指标分为8组:基本信息(年龄、性别、受教育程度、职业)、生活方式(吸烟状况、饮酒状况、膳食模式和体力活动情况)、一般情况(如身高、体重、BMI、腰围、收缩压等)、体格检查(如淋巴结检查、桶状胸腹部肿块等)、影像学检查(胸部X线及腹部超声检查)、实验室检查(如血常规、肝功能、肾功能、尿常规、大便隐血、心电图等)、家族史和病史。 这些指标一般可以通过初级卫生保健系统内的常规健康体检获得,使其适用于大规模的普通人群。在CHARLS、CLHLS和CFPS中,由于收集到的健康指标相对有限,不具有器官特异性衰老的代表性,我们使用LLMs仅预测总体年龄。在CHARLS中,我们纳入了54个指标;在CLHLS中,采用了57个指标,而在CFPS中,仅采用了29个指标。三个队列均包括与基本信息、生活方式、体格检查、病史( CHARLS还纳入了血液检查)相关的指标。具体使用的指标详见附表15 - 17。
对于健康结局,我们采用了13个结局指标进行主要分析:全因死亡、CHD、中风、COPD、哮喘、肝脏疾病、胆囊疾病、肾功能衰竭、肾病综合征、T2D、甲状腺疾病、关节炎和系统性结缔组织疾病。除全因死亡率外,各结局均与器官特异性衰老(例如, CHD和中风与心血管衰老有关, COPD和哮喘与肺衰老有关)有关。所有结局定义为事件首次发生,按照国际疾病分类第十次修订版( ICD-10 ) 62(附表18)进行编码。 我们使用了四个数据源来确定这些结果:基本医疗数据,医院住院记录,死亡登记数据和自我报告的医疗条件。在NHANES中,随访数据仅用于死亡结局。因此,我们只构建了全因死亡率和三种死因特异性死亡率的队列,包括心脏病死亡、癌症死亡和糖尿病死亡。这些死亡结局均与衰老密切相关。在NCRP中,纳入了8个健康结局:全因死亡、冠心病、脑卒中、COPD、肝脏疾病、肾衰竭、T2D和关节炎。这些结果来源于四个来源:医院住院数据、健康体检结果、自我报告和死亡记录。 在其他三个人群中,基于基线和随访调查确定了几种常见的健康结果:CHARLS,心脏病,中风,COPD,肝脏疾病,肾脏疾病和糖尿病;对于CFPS,全因死亡率、冠心病、脑卒中、肝脏疾病、肾脏疾病和糖尿病;而对于CLHLS,全因死亡率、心脏病、中风、COPD、糖尿病和关节炎。这些结果的来源包括自我报告和跟踪调查。每种结局的发生也被定义为其初始发生。在NCRP中,结局采用ICD - 10编码,而其他三个队列采用基于问卷的编码。
LLMs及其预测过程
我们应用了几个开源的通用LLMs来评估每个个体的整体和器官特异性老化。一般的LLMs在多样的、大规模的语料库(互联网上公开的各类数据,如新闻、维基百科、研究论文、代码等)上进行了广泛的预训练,以纳入来自多个领域的世界知识26。为了提高模型在各种下游任务和会话交互中的性能,开发人员通常使用少量的指令数据进行有监督的微调,然后进行人类反馈强化学习,以与人类的偏好保持一致,并最小化错误或有害的输出26。在完成这些训练阶段后,可以使用LLMs进行推理。 在各种排行榜上最具有代表性和最先进的开源通用LLMs包括Llama和Qwen家族63,64。基于两个考虑,我们采用Llama3 - 70B - Instruct作为我们分析的主要模型。( 1 ) LLMs的代表:Llama3 - 70B - Instruct是我们研究时可获得的最具代表性的开源LLMs之一。它在各种下游任务中表现出了先进的性能,得到了研究界的广泛认可。( 2 )开源可用性:虽然GPT - 4是目前最强大的LLM之一,但它是一个闭源模型,这限制了它在我们自己的计算服务器上的部署。考虑到我们数据集的敏感性,特别是UKB和NCRP,确保数据安全是当务之急。 因此,我们选择使用开源的LLMs进行本研究。为了进一步分析,我们使用了Llama3 - 8B - Instruct、Qwen2 - 72B - Instruct、Qwen2 - 7B - Instruct、Qwen1。5 - 110B - Chat、Qwen1 . 5 - 72B - Chat、Qwen1 . 5 - 32B - Chat和Qwen1 . 5 - 14B -聊天。Llama系列由Meta公司开发并开源,Qwen系列由阿里云公司开发。关于模型训练和参数设置的进一步细节可在他们各自的技术报告63,64中获得。先前的研究表明,即使没有对额外的特定领域数据进行有监督的微调,一般的LLM也可以。
仅通过应用适当的提示学习,即可有效理解领域知识并解决领域特定任务,而无需修改模型参数26。对于老龄评估任务,LLMs的具体工作步骤如下。(1) 模型预训练和知识压缩。在预训练阶段,LLMs吸收大量生物医学文献(如PubMed文章、临床报告和健康记录),通过预测下一个符号编码以下知识:生物标志物与衰老的统计关联(例如,"AST升高"和"肝脏衰老"的共现)、风险暴露与衰老的关联(例如,"每周跑三次长距离"与"较低生物年龄"之间的隐含联系)以及疾病进展与衰老之间的关联(例如,"自诊断2型糖尿病以来5年"对应"更高的生物年龄")。(2)功能聚焦和变量选择的提示学习。通过使用具体提示(例如,"根据以下健康信息估算生物年龄......"),LLM激活与衰老相关的内部子网络,将其注意力机制引导到关键标志(例如"炎症因子水平"和"AST水平")、风险暴露因素(例如"每天睡眠4小时")以及疾病和健康状况(例如"10年高血压病史")。根据先前的知识和个人个性化信息,选择与个体衰老最相关的变量。(3)潜变量空间中的概率映射。LLMs不直接"计算"老化代理,而是将输入文本编码为高维向量,然后匹配参数空间中最接近的"老化模式"。例如,输入描述激活一个类似于"加速衰老研究"的向量簇,输出则反映模型对预训练数据中类似案例分布的似然估计。总之,LLMs通过将非结构化文本数据映射到潜在变量空间,识别文本中嵌入的老化信息,从而实现概率性推断老化(我们在补充图6中用示例说明了这一点)。提示为大型语言模型提供上下文,概述背景知识,指定要执行的任务,并详细说明完成的方法26。在响应提示时,LLM执行"下一个令牌预测"任务,依次选择最可能出现的后续令牌,直到响应完全生成。基于以往经验,我们设计了一套提示模板,使LLM能够通过四个模块预测整体及特定器官年龄:角色定义、背景知识、任务描述和健康信息(扩展数据图1)。角色定义模块将LLM定位为老龄化专家,与背景知识模块一起激活并利用模型在预训练阶段获得的与老龄相关知识。任务描述模块明确了LLM被分配的具体目标,并规定了响应格式。最后,健康信息模块集成了构建的健康信息文本,作为LLM主要分析的内容。研究表明,CoT通过促使模型在给出最终答案前仔细思考,从而提升LLM在复杂任务中的表现,从而减少"幻觉"的发生41。因此,我们在提示中融入了CoT推理,使LLM能够全面分析个体的健康指标并提供综合答案。需要指出的是,我们在评估整体年龄和器官特定年龄时同时采用了提示学习和CoT推理,但在构建提示模板时,我们采用了两种策略。第一个策略是构建统一的提示模板(扩展数据图1),要求大型语言模型在单一响应中输出整体和器官特定年龄的预测。当LLM输出对应各年龄段的CoT过程时,等同于将模型的注意力65引导到与该年龄段相关的输入文本和先前知识上。通过计算提示词中关键词的语义相似度,并基于预训练的衰老相关知识确定知识相关性,LLMs为输入文本中的每个词汇赋予权重,自动选择关键指标,以预测不同器官的年龄。例如,预测肝龄时优先考虑AST和ALT,而肌酐和尿素则更为关键。我们所有的主要分析,包括Llama3-70B-Instruct及其他七个大型语言模型,均基于这一策略进行。所有模型均使用相同的提示模板来预测整体及器官特定年龄(针对NCRP、CHARLS、CLHLS和CFPS,因其数据为中文,相应提示模板被翻译为中文),并遵循相同的提示学习和CoT推理过程。第二种策略用于互补分析。我们基于大型语言模型开发了多智能体流水线,设计用于更稳健的临床应用(扩展数据图10a)。多智能体技术通过不同的提示将LLM实例化为多个专家代理60。这些专家代理有明确的任务,并协作完成复杂的工作流程。在我们的多剂流程中,我们将整个衰老评估任务分为四个模块,包括医学信息提取、健康指标的全面分析、与整体及器官特异性衰老相关的因素分析,以及整体和器官特异性衰老的评估。针对每个模块,我们设计了基于LLM的智能代理来执行相关任务。例如,在医疗信息提取模块中,医疗信息提取代理对现实世界的原始数据进行预处理。信息被提取并组织为四类:生活方式、体格检查、血液和尿液生物标志物,以及病史和家族史。在综合健康指标分析模块中,健康检查专家检索并提供最新的医疗参考标准和指南,而医生代理则分析每项指标。此外,还会使用健康指标检查器来核实医生代理人的分析是否完整或存在任何事实错误。在分析与整体及器官特异性衰老相关因素的模块中,使用了不同的衰老分析剂。这些代理通过整合预训练的衰老知识与个性化健康信息,分析并提取每个人的衰老相关因素。这适用于整体衰老以及每种器官特异性衰老的评估。每个衰老分析剂独立运作(例如,整体衰老分析剂仅负责分析与整体衰老相关的因素,而肝脏衰老分析剂则专注于肝脏衰老相关因素)。通过设计不同的提示词,为每个代理定义了不同的角色,提供多样的背景知识并描述多样化的任务(扩展数据图10b)。最后,在第四模块中,各类衰老专家代理基于衰老分析代理(关键选定指标)提供的衰老相关因素,通过最大概率预测机制推断整体及器官特异年龄。所有代理均使用Llama3-70B-Instruct构建,采用CoT策略。与第一种策略相比,该方法在任务细分性和输出透明度方面有所提升。我们仅采纳了UKB中的测试集样本(n = 53,704)进行分析。所有LLM均部署在8块NVIDIA-A100 GPU、20块NVIDIA-A40 GPU和8块Ascend-910B GPU。在推理阶段,我们采用了vLLM包,利用了PagedAttention机制,该技术已被证明显著提升了LLMs66的推理速度。具体来说,所有八个LLMs都应用于UKB(英文文本),只有Qwen1.5-32B-Chat应用于NCRP(中文文本),只有Qwen2-72B-Chat应用于CHARLS、CLHLS和CFPS(中文文本)。所有模型都采用贪婪抽样来生成后续代币,从而最大限度地减少推断过程中的随机性。参数设置包括温度为0,最大令牌为4,096。本次分析中使用了 Python v.3.10.8、Pytorch v.2.1.0 和 vLLM v.0.5.5。
年龄差距的定义与计算
在以往的研究中,年龄差距被广泛用作加速衰老的衡量标准。传统上,年龄差距被定义为模型预测年龄回归后对时间顺序年龄11、67、68的残差。这一定义源自传统的建模方法,在监督回归模型中使用时间年龄作为标签;然而,回归模型常常会回归到平均极限67,68,导致年龄预测在时间线两个极端的个体中存在显著偏差。通过对预测年龄按时间年龄回归,残差代表个体预测年龄与同龄人平均预测年龄的偏差。这反映了个体相对于同龄人看起来更年长还是更年轻11。在我们的研究中,由于采用无监督建模方法来估算整体和器官特定年龄,使用年龄作为回归标签所带来的偏差并未出现。因此,我们将年龄差距定义为LLM预测年龄与实际年龄的差异,即每个人与自身比较,而非参考总体。年龄差距大于0表示个体看起来比实际年龄更老,而年龄差小于0则表示个体看起来更年轻。它是加速衰老的综合代理指标,整合了个体的生物学、生理、生活方式、疾病、遗传和社会维度。它反映了个体在多种暴露综合影响下的加速衰老状态,涵盖了与衰老相关的不良健康结果风险信息。最终,我们获得了整体年龄差距和六个器官特异性年龄差,分别捕捉了整体和器官特异性衰老11。此外,我们计算了各器官特定年龄与整体年龄之间的器官-整体年龄差,这是任何现有研究未曾评估的指标,可能反映了特定器官相较于整体身体的相对衰老情况。
验证LLM预测的年龄和年龄差距
为评估LLM预测的整体年龄是否与年龄相关表型与年龄相关性强,相较于按时间年龄和传统ML预测的整体年龄,我们分别构建了每种表型的线性回归或逻辑回归模型,并比较不同衰老代理的标准化回归系数(β)。具体来说,对于连续值表型,包括跟骨密度、动脉硬度指数、调整端粒长度、虚弱指数、整体健康评分和反应时间,我们采用了线性回归模型。对于二元表型(0--1值),如听力问题、牙齿问题、行走迟缓、跌倒风险、一般疼痛和长期疾病,我们采用逻辑回归模型。所有模型均针对共同变量进行了调整,包括UKB评估中心、人口统计因素(性别、收入、就业、教育和族裔)、生活方式(吸烟状况和饮酒状况)、体格检查(BMI)和病史(高血压)。用于比较的机器学习模型包括支持向量机(SVM)、随机森林(RF)、极端梯度增强(XGBoost)和深度神经网络(DNN)。对于建模方法和机器学习模型的预测变量,我们遵循了之前的研究11。我们排除了UKB中任何缺失预测变量的参与者,最终得到179,013个样本。然后将数据集按7:3比例拆分为候选训练集和测试集。在候选训练集中,我们仅选择健康个体(即从未被诊断为重大疾病,遵循先前定义者)来训练机器学习模型(n = 39,131)。该训练过程的目标是准确预测年龄。随后,我们将训练好的机器学习模型应用于测试集,预测参与者的整体年龄,并计算调整后的年龄差距(回归残差)。按照上述流程,我们获得了12个与衰老相关的表型的β。随后,我们比较了测试集中不同年龄代理指标(包括年龄差距)之间的β值(n = 53,704)。对于脚跟骨密度和调整端粒长度,负β值且绝对大小较大表示关联更强,而其余十种表型中,正β值且绝对大小较大被认为更好。第二阶段验证是比较LLM预测年龄、传统机器学习预测年龄和经典衰老代理在预测各种衰老相关健康结局方面的表现11,24。一个好的衰老指标应显示出与多种健康结果(包括全因死亡率)更强的关联。我们分析中考虑的经典衰老代理包括年龄、端粒长度、虚弱指数以及八个表观遗传年龄:HorvathAge20、HannumAge21、SkinBloodAge69、PhenoAge36、ZhangAge70、LinAge71、WeidnerAge72和VidalBraloAge73。虚弱指数基于之前的方法74构建,同时适应英国基础(UKB)现有数据(详见补充表2定义)。端粒长度来自英国官方预处理数据集,八个表观遗传年龄来自官方NHANES数据集(https://wwwn.cdc gov/nchs/nhanes/dnam/)。对于每个健康结局,我们仅纳入无疾病参与者,其中"无疾病"意味着排除基线时正在评估疾病的参与者。例如,在验证衰老代理指标预测先天性心脏病和中风表现时,曾经历重大不良心血管事件(包括先天性心脏病、中风、肺心脏病和心力衰竭)的个体被排除在外。终点定义为结果的首次发生,即死亡或随访结束,以先到者为准。我们采用Cox比例风险模型计算每个衰老代理的C指数。较高的C指数表示对相应健康结果的预测能力更强,表明给定的衰老代理指标与健康结果的关联更为紧密。Cox模型未纳入协变量,我们的目标是比较单一衰老指标在预测健康结果上的准确性。C指数及其95%置信区间通过十倍交叉验证估计。每个折叠计算了C指数,平均C指数作为点估计值。S.E.M.C指数跨折叠计算,95%置信区间基于t分布(d.f. = 9)推导。对于器官特异性年龄,我们重复了这一程序,比较了LLM预测的器官特定年龄与机器学习模型所得的年龄。机器学习模型的构建,包括建模方法和预测变量的选择,严格遵循以往研究以确保一致性和可比性。我们还在另外七个LLM中重复了该分析程序,并比较了所有LLM预测的整体年龄与测试集中不良健康结局的关联(n = 53,704)。为验证基于LLM的年龄差距是否构成全因死亡和多重慢性病的风险因素,我们对每种健康结局构建的队列进行了生存分析。为了可视化年龄差距的判别性能,我们选择了年龄差距值中前10%、中间10%和下10%的样本,并绘制了KM曲线。随后,为估计年龄差距与多重健康结局的关联,我们对整个队列进行了Cox分析,调整了常见协变量,包括UKB评估中心、人口统计因素(年龄、性别、收入、就业、教育和族裔)、生活方式(吸烟状况和饮酒状况)、体格检查(BMI)和病史(高血压)。这使我们能够获得基于LLM的整体年龄差距和器官特异性年龄差距的95%置信区间。此外,我们计算了器官与整体年龄差距,并进行了类似分析,以确定这些器官与整体年龄差距是否也是与衰老相关健康结果独立的风险因素。为确保我们发现的稳健性,我们进行了多项额外分析,包括(1)重复其他基于人群的队列的验证分析,如NCRP、CHARLS、CLHLS和CFPS;(2) 在 UKB 中随机洗牌文本序列按更广泛类别报告,并重新评估预测表现和LLM预测年龄的一致性(随机洗牌九次);(3)对大型语言模型中所用提示词的调整;以及(4)在健康检查报告中减少健康指标数量。所有分析均使用Python v.3.10.8和R v.4.4.2进行。
个体衰老的动态与纵向评估
利用LLMs53,54强大的记忆力和实时动态输入输出能力,我们旨在评估LLMs是否能在纵向群体队列中实现个体衰老的更精确建模。本分析采用了NCRP队列中30至70岁成年人的数据,他们连续三年(2019年至2021年)接受年度健康检查。排除任何变量数据缺失的个体后,最终研究队列共有462,262名参与者。按照上述数据预处理步骤,我们获取了每个人的年度健康检查报告,并为LLMs输入设计了基于多回合对话的提示。具体来说,在第一轮推断中,LLM的创作仅基于2019年的健康检查报告。第二轮提示包含了2020年健康检查报告,以及前一轮对话的历史背景,包括第一轮的输入和输出。这一迭代过程在第三轮中继续,加入了2021年健康检查报告(扩展数据图5)。我们设计了两个实验组和一个对照组进行比较。对照组采用单回合对话法,仅根据2021年健康检查报告的提示来预测个人2021年的总体年龄。实验组1通过两轮对话结合了2020年和2021年的健康检查报告,预测2021年的整体年龄(即与LLM进行的两次对话;扩展数据图5)。实验组2进一步扩展了这一方法,通过三回合对话纳入2019年、2020年和2021年的数据,预测2021年的整体年龄。利用这三组预测的年龄,我们计算了相应的年龄差距。对照组的年龄差定义为静态预测的年龄差,而实验组1和实验组2的年龄差分别定义为动态预测年龄差1和动态预测年龄差2。随后,我们利用这三个年龄差距构建了Cox模型,分别预测八种健康结局:全因死亡率、先天性心脏病、中风、慢性阻塞性肺病、肝病、肾衰竭、2型糖尿病和关节炎。为评估纳入更多历史健康信息是否能提升基于LLM的年龄差距对未来健康风险的预测能力,我们比较了各模型的C指数值。该比较使我们能够评估多回合对话中逐步精细的年龄差距估计是否提升了不良健康结果的预测准确性。
基于LLM的年龄差距的生物学与临床应用
基于LLM的年龄差距被应用于多个生物学和临床下游任务:识别与加速衰老相关的蛋白质组生物标志物,以及建模个人健康风险。在第一个任务中,我们利用整体年龄差距和器官特异性年龄差距,分别识别与整体加速和器官加速衰老相关的蛋白质组生物标志物。我们比较了年龄差距前10%与底10%人群的蛋白质组学特征。蛋白质组谱中的差异丰度通过线性建模分析,并根据年龄和性别调整,并结合经验贝叶斯调节和通过Benjamini--Hochberg方法进行P值修正。我们用火山图来可视化结果。在加速衰老组中,显示显著丰度差异(调整后的P < 0.01和绝对log²折叠变化>0.2)的蛋白质被鉴定为LLM相关蛋白。随后将蛋白质数据映射到基因标识符,并进行了基因集富集分析(GSEA),以识别与整体及器官特异性加速衰老相关的生物通路,结果通过GSEA富集图和点图可视化。NES是通过对每个基因集的原始富集得分进行归一化,以考虑基因组大小的变化来计算的。随后,我们整理了一系列经典的衰老相关研究,包括Horvath的clock20、DNAm PhenoAge36、ProtAge24、DunedinPACE37以及三篇近期讨论衰老相关蛋白或遗传位点的综述38--40。通过维恩图可视化了这些研究中识别出的蛋白质和基因之间的相似点和差异。LLM识别出的未在上述研究中提及的蛋白质被选中用于进一步预测衰老相关结局,如死亡率和疾病。特别是针对每个单蛋白,我们进行了十倍交叉验证,分析其与全因死亡率及多种特定疾病之间的关联,计算了C指数和95%置信区间。我们进一步应用弹性净正则化Cox回归筛选血浆蛋白,随后通过依次添加一个蛋白质构建Cox模型,评估其在预测全因死亡率或器官特异性疾病方面的逐步贡献,量化指标为对一致性指数和95%置信区间75,76。具体来说,对于多蛋白组合,我们从已建立的衰老生物标志物(Horvath时钟、DNAm表龄和蛋白年龄)以及LLM鉴定候选物中汇编了蛋白质集。每组特征选择分为两阶段:(1)单变量过滤以排除边缘关联较弱的蛋白质(排除阈值,Wald P > 0.1),随后进行弹性净正则化,系统性变化α从0(脊回归)到1(LASSO),以0.1个增量进行,通过五次交叉验证确定最优λ,最小化部分似然偏差。保留非零系数的蛋白质通过弹性净回归得出的系数绝对大小进行排名,这些系数按重要性由高至低顺序纳入嵌套的Cox模型中。通过十倍交叉验证评估模型表现,生成C指数和95%置信区间。为了可视化蛋白质数值与表现的关系,我们采用了局部加权回归(LOESS;span = 0.5)并采用不确定性估计(95% CI,即 TRUE)。使用邓内特事后程序测试衰老钟之间的统计差异,并用本贾米尼-霍赫伯格方法控制假发现率。通过55,000个来自独特UKB参与者访问样本的蛋白质组生物标志物数据生成。Olink采用近距离延伸测定法对血浆样本进行了蛋白质组学分析。英国研究委员会报告了严格的质量控制流程,包括样本筛选、异常值去除和排除标记数据,结果实现了高质量且变异性低,蛋白质检测率超过51%,且91%的样本通过了质量控制。血浆蛋白浓度通过归一化蛋白表达值表示,这些值通过两步方法计算,涉及批内强度和跨批次强度归一化77,78。第二项任务,我们首先评估了英国群体中270种疾病风险与整体年龄差距与器官特异性差距之间的关联(n=179,013,样本无缺失预测变量)。对于每个年龄差距和疾病,我们只选择无疾病的人群,并构建Cox模型以估计该年龄差距的调整后心率。模型对共同变量进行了调整。我们报告了具有统计学意义的发现,全面概述了基于LLM的年龄差距作为独立风险预测变量的疾病。随后,我们为UKB人群中270种疾病(n = 179,013,样本中无任何预测因子缺失)建立了风险预测模型。对于每种疾病,我们仅选择无疾病个体作为研究样本,并采用五重交叉验证方法评估模型的预测表现。我们使用Cox模型,终点定义为基线评估后疾病发生的时间。预测表现采用C指数进行评估。评估整体预测价值的增加疾病风险预测中的年龄差距,我们建立了四个具有不同预测变量组的模型11:(1) 模型1:仅测量整体年龄差距。(2)模型2:按年龄和性别顺序排列。(3)模型3:按年龄、性别、生活方式(吸烟状况、饮酒状况及健康饮食)、体格检查(BMI和腰髋比)及医学诊断(高血压)。(4)模型4:按年龄、性别、生活方式(吸烟状况、饮酒状况和健康饮食)、体格检查(BMI和腰臀比)、医学诊断(高血压)及整体年龄差距。 最后,我们利用2019--2021年NCRP的纵向健康检查数据,计算30至70岁人群的加速衰老速率(样本与上述动态衰老评估分析相同,n = 462,262)。该比率被定义为个人整体年龄差距的年均增长。随后,我们利用Cox模型估算了这一整体衰老率与八种与衰老相关的健康结果之间的关联。模型对上述常见协变量进行了调整,并获得了相应的调整心率
模型的可解释性
为了提升LLM预测的可解释性,我们进行了多项分析。我们采用的第一个方法是CoT,它促使大型语言模型明确表达它们在预测41中依赖的因素。为了可视化这些洞见,我们生成了词云,突出最常被识别出的影响因素。这种方法不仅对LLMs的推理进行了定性分析,还提供了对每个个体预测基础的更透明和直观的理解。此外,我们利用SHAP提升了研究的可解释性42。我们首先拟合了一个线性回归模型,使用45个健康指标作为预测变量,整体年龄差距作为反应变量。基于合作博弈论的SHAP,通过将每个预测分解为各个特征的贡献,提供了一个稳健的框架来解释模型预测。这种方法允许两种不同的解释层次:(1)局部解释,解释每个特征对单个预测的影响;以及(2)全局解释,即在整个数据集中对特征重要性进行排名。通过R中的iml包计算了shapely值,使我们能够量化收缩压、白蛋白和BMI等健康指标对年龄差距预测的贡献。通过利用SHAP,我们补充了基于CoT推理对LLMs的显式解释,从而从另一个视角探讨了与加速衰老相关的变量重要性。我们采用的第三种方法是全球代理模型44。该方法涉及训练一个更简单、更易解释的模型,模拟用于年龄预测的复杂黑箱模型的行为。具体来说,我们使用一个简单的线性回归模型作为替代模型,以近似LLM预测的整体年龄。替代模型是利用LLMs的原始输入特征和LLMs的目标预测(LLM预测的整体年龄)进行训练的。其目标是以更透明的方式捕捉预测变量与目标变量之间的关系。我们可视化了特征回归系数,以进一步解释LLMs潜在的内部决策过程。最后,我们采用了反事实模拟方法45,估算各种风险因素与加速衰老的关联,通过与流行病学证据进行比较,验证模型对特征在预测整体年龄中重要性的理解。该方法涉及将特定风险因素的数值扰动至非风险水平,并利用大型语言模型重新评估数据,生成新的整体年龄预测。通过对原始样本和扰动样本的联合数据集进行线性回归,其中每个风险因素的整体年龄差均被回归,我们将回归系数的排名顺序与同一风险因素上调整端粒长度回归所得的排名顺序进行比较,以评估LLM预测与流行病学证据之间的对应性。我们还进行了Wilcoxon签名排名检验,以确定两组风险因素重要性排名是否存在显著差异。纳入了十个常见风险因素:当前吸烟、每日饮酒、每周≥5次频繁摄入加工肉类)、每周≥次频繁摄入红肉、频繁摄入盐分(通常或始终)、每日中度至剧烈体育活动不足(<15分钟)、肥胖(BMI≥28)、收缩压升高(≥140毫米汞柱)、高血压史和糖尿病史。识别出具有这些风险因素的个体,并将这些因素的数值调至正常水平。例如,当前吸烟被影响为非吸烟者,肥胖被影响到BMI为27.9公斤m−2,高血压病史被影响为无。随后,所有扰动数据都被大型语言模型重新处理,生成新的整体年龄预测。随后,我们基于原始和被扰动的整体年龄预测计算了相应的年龄差距。每个风险因素作为二元变量处理,线性回归模型拟合年龄差距,调整年龄、性别、收入、就业和教育程度。