一:对齐算法场景说明
备份的时候,为什么必须要Barrier,保障每个算子状态是将一条数据完整处理完毕的。
在Flink中,采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
二:检查点的分界线
- 设计思想:借鉴水位线的设计,在数据流中插入一种特殊数据结构,用于标记触发检查点保存的时间点。
- 生成与传递 :
- Source 任务收到保存检查点指令后,在当前数据流中插入该结构。
- 下游所有任务遇到该结构时,开始对状态做持久化快照保存。
- 核心作用 :
- 利用数据流的顺序处理特性,该结构作为 "分界线":
- 屏障之前的数据:已处理完成,状态变更会体现在当前检查点中。
- 屏障之后的数据:状态变更不会体现在当前检查点中,需保存到下一个检查点。
- 利用数据流的顺序处理特性,该结构作为 "分界线":
- 名称由来 :这种特殊数据形式将流上数据按不同检查点分隔开,因此被称为检查点的 "分界线"(Checkpoint Barrier)。
- 核心过程:
- 核心组件 :JobManager 中存在 "检查点协调器",专门负责协调处理检查点相关工作。
- 指令下发 :检查点协调器会定期向 TaskManager 发送指令,要求保存检查点(指令中携带检查点 ID)。
- Source 任务执行 :
- TaskManager 通知所有 Source 任务,将自身的偏移量(算子状态)进行保存。
- Source 任务将 ** 带有检查点 ID 的分界线(Checkpoint Barrier)** 插入到当前数据流中,并像正常数据一样向下游传递。
- 完成上述操作后,Source 任务即可继续读取新数据。
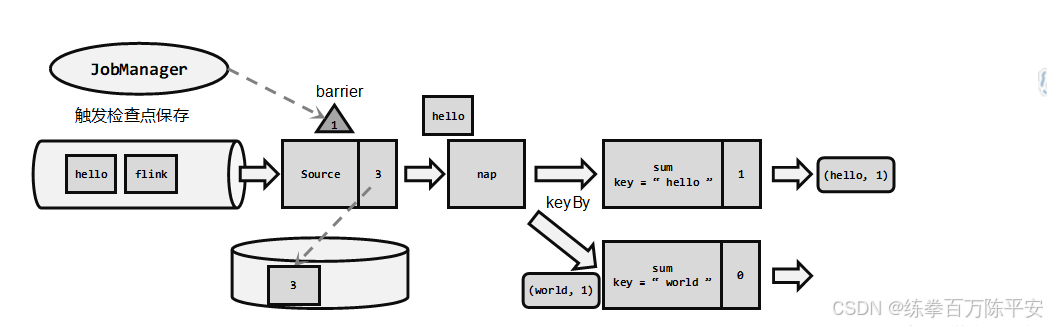
上游一个并行度,下游多个并行度,分界线会进行广播
上游多个并行度,下游一个并行度,分界线会进行聚合到一个子任务上。不存在取最小。
三:Barriar对齐精准一次
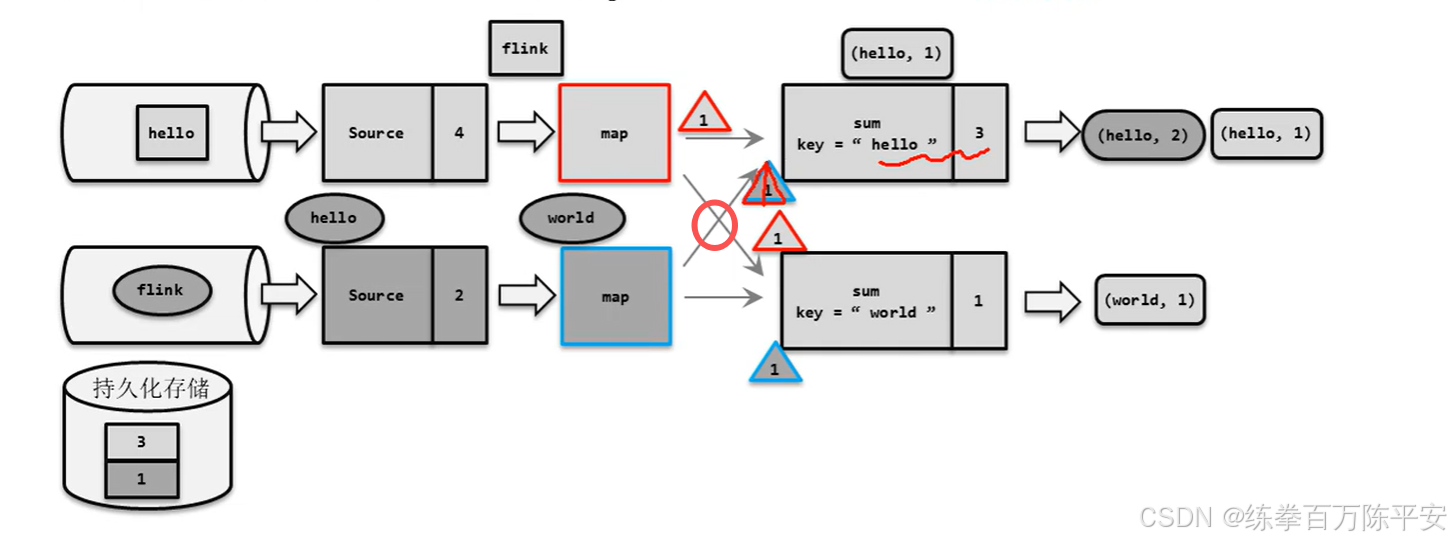
keyby算子中,上下游进行广播的时候的,等所有的Barrier都到了。再说。
所有Barrier之前的数据,在等待过程中,都不进行处理。可以验证保证数据精准一次。
Barrier到了之后,Barrier之后的元素又到了,那么就不处理!因为处理有可能把状态给改掉,导致状态持久化之后,数据错乱。
四:Barriar对齐的至少一次
上边哪种会应用处理速度,所以,这是优化版本Flink1.1版本提供的。
如果对时效性要求特别高,对准确性没有那么高。如果keyby之后某个上游算子的barrier来的特别早,然后紧接着又来了谁,精准一次就不会在处理。但是至少一次就会在等待其他barrier的时候把这条数据给处理掉。这样状态中就有可能保留了这条数据。
后续检查点恢复的时候, 可能会造成这条数据重复消费。
这种就叫Barrier对齐至少一次。其中某个算子可能只收到了部分barrier。
五:非Barrier对齐的精准一次
时效性又好,又准确。
keyby之后,有任何一个bariier的数据到了,直接开发备份,然后把其他检查点到了之后,把他们的数据也保存持久化下来。也就是存的不仅仅是状态,还有在途的数据。