本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
一、前言
上一篇我们成功升级了Azure Agent,实现了「多工具支持」和「多轮记忆」两大核心功能,摆脱了"单一文本总结、无上下文记忆"的局限,让Agent从基础工具升级为实用型智能助手,同时掌握了Agent的模块化扩展逻辑------通过工具映射字典,可灵活新增功能,无需重构核心代码。
这一篇我们进入「实战落地」阶段------结合职场高频需求,基于上一篇的模块化架构,打造一个能直接用的办公助手型Agent,核心实现3个实用功能,全程复用你已有的Azure GPT-4模型和azure_config.json配置文件。
本篇核心目标:让Agent能"读文件、做总结、存结果",适配Word、PDF、TXT三种常见办公文件格式,解决职场中"手动读取文件、总结内容、保存结果"的重复工作,真正实现"一键操作、全程自动化"。同时,我们会优化Agent的稳定性和容错性,避免因文件格式错误、内容为空导致的程序崩溃,让实操更顺畅。
新增的「文件读取模块」和「结果保存模块」是本次实战的重点:

二、实操
安装依赖:
python
# 补充文件读取依赖(支持Word/PDF/TXT)
pip install python-docx # 读取Word文件(.docx格式)
pip install PyPDF2 # 读取PDF文件(.pdf格式)
# 结果保存依赖(复用之前的,若已安装可跳过)
pip install openpyxl # 保存为Excel(可选,本次默认保存为TXT,更简单)完整代码:
python
from openai import AzureOpenAI
import json
import os
from docx import Document # 读取Word文件
from PyPDF2 import PdfReader # 读取PDF文件
# ===================== 1. Azure配置加载(完全复用 上一篇,无需修改) =====================
CONFIG_FILE = "azure_config.json"
def load_azure_config():
"""加载Azure OpenAI配置,沿用 上一篇的容错处理,避免配置错误导致程序崩溃"""
if os.path.exists(CONFIG_FILE):
try:
with open(CONFIG_FILE, "r", encoding="utf-8") as f:
config = json.load(f)
# 验证核心配置是否完整(适配GPT-4部署,与 上一篇一致)
required_keys = ["azure_endpoint", "api_key", "deployment_name"]
if all(key in config for key in required_keys):
return config
else:
print("⚠️ Azure配置文件不完整,将重新引导输入")
except Exception as e:
print(f"⚠️ 配置文件读取失败({str(e)}),将重新引导输入")
# 若配置文件不存在/读取失败,引导用户重新输入并生成新文件(与 上一篇逻辑一致)
config = {
"azure_endpoint": input("请输入Azure Endpoint:"),
"api_key": input("请输入Azure OpenAI API Key:"),
"deployment_name": input("请输入GPT-4模型部署名称:")
}
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=4)
return config
# 初始化Azure OpenAI客户端(稳定调用GPT-4,版本与 上一篇一致)
config = load_azure_config()
client = AzureOpenAI(
azure_endpoint=config["azure_endpoint"],
api_key=config["api_key"],
api_version="2024-08-01-preview" # 兼容GPT-4的稳定版本,与 上一篇保持一致
)
# ===================== 2. 核心工具模块(新增文件读取+结果保存,复用 上一篇工具) =====================
# 工具1:读取文件(支持Word/PDF/TXT,自动识别格式,新增工具)
def read_file(file_path: str) -> str:
"""读取文件内容,自动识别文件格式,返回纯文本,添加容错处理,延续 上一篇容错思路"""
# 验证文件是否存在
if not os.path.exists(file_path):
return f"❌ 文件不存在,请检查文件路径是否正确(当前路径:{file_path})"
# 自动识别文件格式(根据后缀名)
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == ".docx": # Word文件
doc = Document(file_path)
content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])
elif file_ext == ".pdf": # PDF文件
reader = PdfReader(file_path)
content = "\n".join([page.extract_text() for page in reader.pages if page.extract_text().strip()])
elif file_ext == ".txt": # TXT文件
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
else:
return f"❌ 不支持该文件格式({file_ext}),仅支持.docx/.pdf/.txt"
# 验证文件内容是否为空
if not content.strip():
return "❌ 文件内容为空,无法进行处理"
return content
except Exception as e:
return f"❌ 文件读取失败:{str(e)}(可能是文件损坏或格式异常)"
# 工具2:文本总结(复用 上一篇的核心逻辑,优化GPT-4提示词,适配文件内容)
def summary_tool(text: str) -> str:
"""文件内容总结工具,GPT-4驱动,沿用 上一篇逻辑,总结更贴合职场需求(简洁、重点突出)"""
try:
response = client.chat.completions.create(
model=config["deployment_name"],
messages=[
{"role": "system", "content": "你是职场办公总结助手,总结文件内容时,需突出核心要点、关键数据和结论,语言简洁、专业,控制在150字内,避免冗余,适配职场汇报场景。"},
{"role": "user", "content": f"请总结以下文件内容:\n{text}"}
],
temperature=0.2 # 降低随机性,确保总结结果稳定、准确,与 上一篇一致
)
return response.choices[0].message.content.strip()
except Exception as e:
return f"❌ 总结失败:{str(e)}(请检查Azure配置或网络连接)"
# 工具3:结果保存(保存为TXT文件,默认保存在当前目录,方便查找,新增工具)
def save_result(result: str, file_name: str = None) -> str:
"""保存处理结果到TXT文件,自动生成文件名,返回保存路径,延续 上一篇简洁实用的设计思路"""
# 自动生成文件名(若未指定),格式:处理时间_结果.txt
if not file_name:
import datetime
now = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = f"agent_result_{now}.txt"
# 确保文件名以.txt结尾
if not file_name.endswith(".txt"):
file_name += ".txt"
# 保存文件
try:
with open(file_name, "w", encoding="utf-8") as f:
f.write(f"Agent处理结果({datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')})\n")
f.write("="*50 + "\n")
f.write(result)
return f"✅ 结果已保存至:{os.path.abspath(file_name)}"
except Exception as e:
return f"❌ 结果保存失败:{str(e)}"
# ===================== 3. 实战Agent核心(整合所有工具,沿用 上一篇架构,带记忆+智能解析) =====================
class OfficeAgent:
def __init__(self):
self.history = [] # 多轮记忆(复用 上一篇的记忆机制,记住用户之前处理的文件和结果)
self.last_file_path = None # 新增:记录最近一次成功读取的文件路径,解决"总结这个文件"识别问题
# 工具映射,沿用 上一篇的字典映射逻辑,新增文件读取和结果保存工具,扩展性不变
self.tools = {
"读取文件": read_file,
"总结文件": summary_tool,
"保存结果": save_result
}
def parse_intent(self, instruction: str) -> tuple:
"""智能解析用户指令,沿用 上一篇的关键词匹配逻辑,优化文件相关指令识别,无需死板输入指令头"""
# 关键词匹配,适配职场常用指令,容错性强(不区分大小写),延续 上一篇设计
instruction_lower = instruction.lower()
file_path = None
# 提取文件路径(支持绝对路径和相对路径)
if any(ext in instruction for ext in [".docx", ".pdf", ".txt"]):
# 简单提取文件路径(适配空格、中文路径)
import re
pattern = r"([^\s]+?\.(docx|pdf|txt))"
match = re.search(pattern, instruction)
if match:
file_path = match.group(1)
self.last_file_path = file_path # 读取新文件时,更新最近文件路径
else:
# 未提取到新路径,使用最近一次成功读取的文件路径(解决"总结这个文件"无路径问题)
file_path = self.last_file_path
# 判断任务类型,新增文件读取相关意图识别,与 上一篇意图解析逻辑一致
if any(keyword in instruction_lower for keyword in ["读取", "打开"]):
return "读取文件", file_path, instruction
elif any(keyword in instruction_lower for keyword in ["总结", "概括", "提炼"]):
return "总结文件", file_path, instruction
elif any(keyword in instruction_lower for keyword in ["保存", "导出"]):
return "保存结果", None, instruction
else:
# 若未识别到任务类型,默认执行"总结文件"(若有文件路径),否则提示,与 上一篇逻辑一致
return "未知", file_path, instruction
def run(self, instruction: str) -> str:
"""Agent运行入口,串联「解析指令→调用工具→保存结果→记忆上下文」全流程,沿用 上一篇核心逻辑"""
print(f"🔍 Agent接收指令:{instruction}")
intent, file_path, raw_instruction = self.parse_intent(instruction)
# 处理不同任务类型
if intent == "读取文件":
if not file_path:
result = "❌ 未识别到文件路径,请输入包含.docx/.pdf/.txt的文件路径(如:读取文件 D:/test.docx)"
else:
result = self.tools["读取文件"](file_path)
# 读取成功后,将文件路径和内容存入记忆,沿用 上一篇记忆存储逻辑,同时更新最近文件路径
if not result.startswith("❌"):
self.last_file_path = file_path # 读取成功,更新最近文件路径
self.history.append(("读取文件", file_path, result[:50] + "...")) # 只存前50字,避免记忆过大
elif intent == "总结文件":
if not file_path:
# 优化提示:若未识别到路径,提示用户先读取文件,而非重复要求输入路径
result = "❌ 未识别到文件路径,请先读取文件(如:读取文件 D:/test.pdf),再输入「总结这个文件」"
else:
# 先读取文件,再进行总结,整合新增工具与 上一篇总结工具
file_content = self.tools["读取文件"](file_path)
if file_content.startswith("❌"):
result = file_content # 读取失败,直接返回错误信息
else:
result = self.tools["总结文件"](file_content)
# 总结成功后,存入记忆,沿用 上一篇记忆逻辑
self.history.append(("总结文件", file_path, result))
elif intent == "保存结果":
# 从记忆中获取最近一次的处理结果,复用 上一篇的记忆调用逻辑
if not self.history:
result = "❌ 暂无可保存的结果,请先处理文件(读取/总结)"
else:
last_task, last_file, last_result = self.history[-1]
save_msg = self.tools["保存结果"](last_result)
result = f"📌 最近一次处理:{last_task}({last_file})\n{save_msg}"
else:
# 未识别到任务类型,提示用户输入正确指令,与 上一篇提示风格一致
result = "❌ 未识别到任务,请输入以下类型的指令:\n1. 读取文件:包含.docx/.pdf/.txt路径(如:读取 D:/会议纪要.docx)\n2. 总结文件:包含文件路径或先读取文件后输入「总结这个文件」\n3. 保存结果:保存最近一次的处理结果(如:保存结果)"
# 将本次交互存入记忆(用于多轮对话),沿用 上一篇记忆管理逻辑
self.history.append(("用户指令", raw_instruction, result))
# 控制记忆长度,避免占用过多内存(只保留最近5次交互,与 上一篇一致)
if len(self.history) > 5:
self.history.pop(0)
return result
# ===================== 4. 运行测试(实战场景,直接复制样本测试) =====================
if __name__ == "__main__":
# 初始化职场办公型Agent,沿用 上一篇的初始化逻辑
office_agent = OfficeAgent()
print("✅ 职场办公型Azure Agent已启动(基于GPT-4驱动)")
print("📌 支持功能:读取Word/PDF/TXT + 自动总结 + 保存结果(延续 上一篇记忆+多工具能力)")
print("📌 示例指令(直接复制使用):")
print(" 1. 读取文件 D:/docker/会议纪要.docx")
print(" 2. 总结文件 D:/docker/项目计划.pdf 或 先读取文件后输入「总结这个文件」")
print(" 3. 保存结果")
print("📌 输入「退出」即可结束运行")
# 交互测试,模拟职场实际使用场景,延续 上一篇的交互风格
while True:
user_input = input("\n请输入指令:")
if user_input in ["退出", "exit", "quit"]:
print("❌ Agent已停止运行")
break
# 运行Agent并输出结果
result = office_agent.run(user_input)
print(f"\nAgent:{result}\n")三、测试
启动成功:
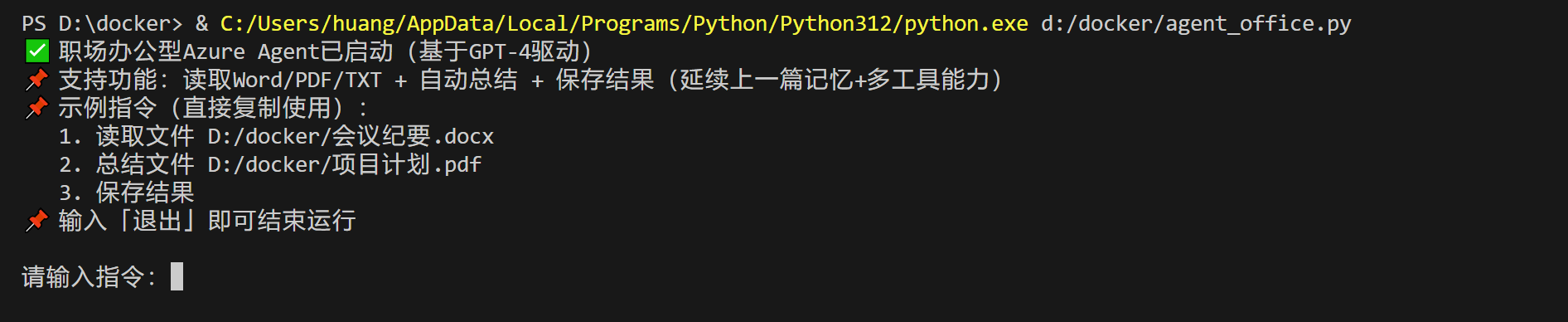
测试前准备:在电脑中准备1个Word(.docx)、1个PDF(.pdf)或1个TXT(.txt)文件,记住文件的「绝对路径」(如:D:/docker/会议纪要.docx、E:/test/项目方案.pdf)。
比如我用下面的文本,分别存储txt, pdf, word三个文件。
2026.03.09项目会议:确定需求优先级,A模块优先开发,责任人张三,截止3月15日。
用户反馈:系统响应慢,主要出现在数据查询环节,建议优化索引。
面试评价:候选人熟悉OpenAI调用,提示工程基础较好,可安排二面。
放到同一个目录,当然也不是必须,只是减少测试过程的绝对路径引用:
测试1 读取文件:
输入 "读取文件 /路径/文件名":
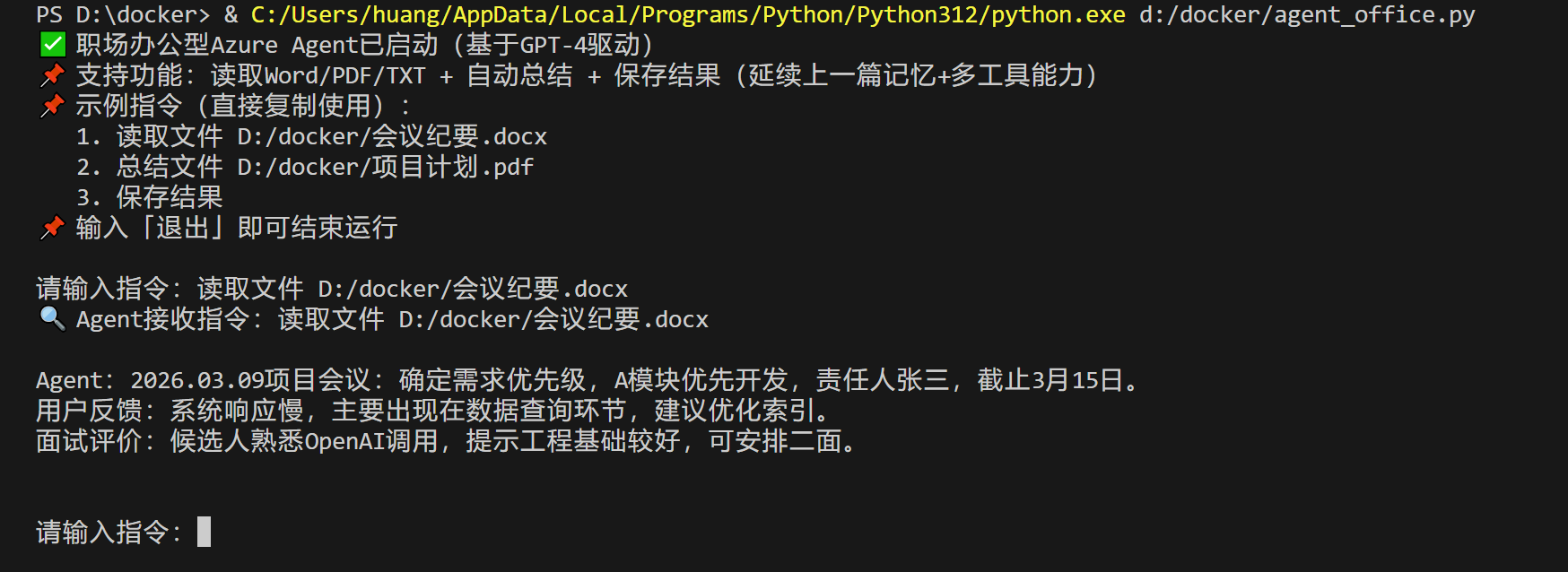
预期结果:Agent会读取文件内容,返回"文件读取成功,内容预览:XXX...",同时将文件内容存入记忆(沿用第三篇的记忆机制)。
测试2 总结文件:
输入 "总结文件 路径/文件名"

预期结果:Agent会先读取PDF文件,再通过GPT-4生成简洁的总结(150字内,突出核心要点),同时存入记忆。
测试3 保存结果
直接输入保存结果指令:
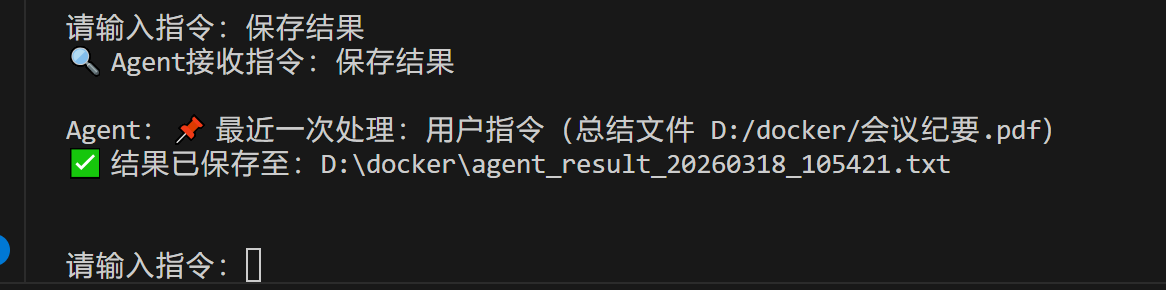
预期结果:Agent会将上一次的总结结果保存为TXT文件,返回保存路径(如:D:/docker/agent_result_yyyymmdd_时间戳.txt),打开该文件即可查看完整总结,新增功能适配第三篇的记忆调用逻辑。
测试4 连续执行
这次测试连续执行的效果,也就是从第二步开始不再提供路径和文件名,测试其记忆功能:
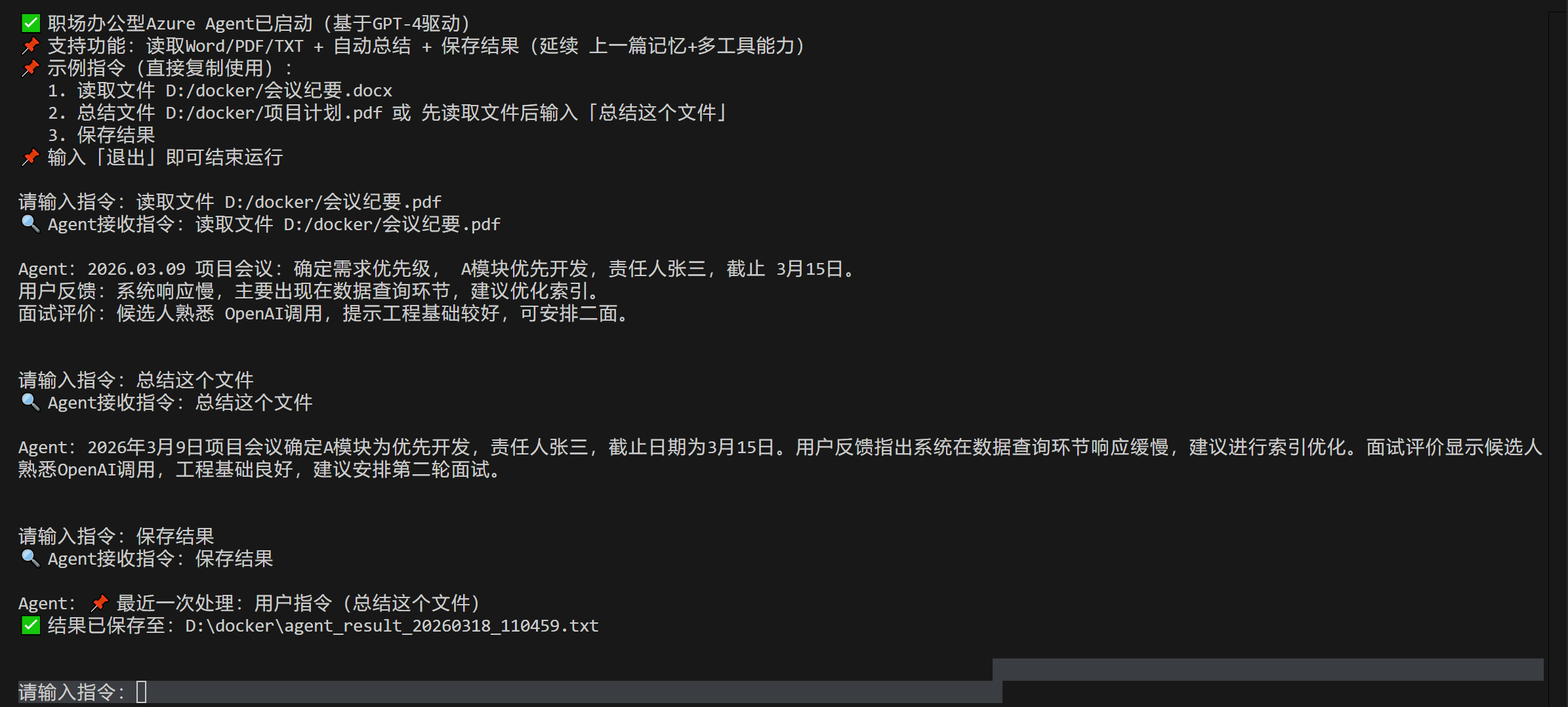
可以看到效果达到预期。
四、知识点讲解
- 新增模块核心逻辑
-
文件读取模块:通过后缀名自动识别文件格式,适配Word/PDF/TXT三种职场常用格式,添加了文件存在性、内容为空、文件损坏等容错处理,避免程序崩溃;
-
结果保存模块:自动生成文件名(含时间戳),默认保存为TXT格式,同时返回绝对路径,方便用户快速查找;
-
智能意图解析:在上一篇关键词匹配逻辑的基础上,优化文件相关指令识别,无需用户死板输入"文本总结",只需输入自然语言(如"总结这个PDF""读取Word文件"),Agent即可自动识别任务,更贴合职场实际使用习惯。
五、总结
本篇我们基于上一篇的"记忆+多工具"架构,成功搭建了「可落地的Azure Agent」,实现了"读取Word/PDF/TXT文件→自动总结→保存结果"的完整闭环。
下一篇,将进一步升级Agent:实现「批量处理文件」和「Excel格式保存」功能,同时优化Agent的交互体验,添加进度提示,让Agent能处理更多职场场景,真正成为你的"办公小助手"。