一、什么是算子(Operator)
在 Apache Flink 中,算子(Operator) 是流处理程序的基本计算单元,负责对数据流执行转换、聚合、过滤、连接等操作。每个算子接收上游数据流,经过业务逻辑处理后输出新的数据流。
Flink 程序本质上是一个有向无环图(DAG),节点就是算子,边就是数据流(DataStream)。
二、Flink 整体算子架构图
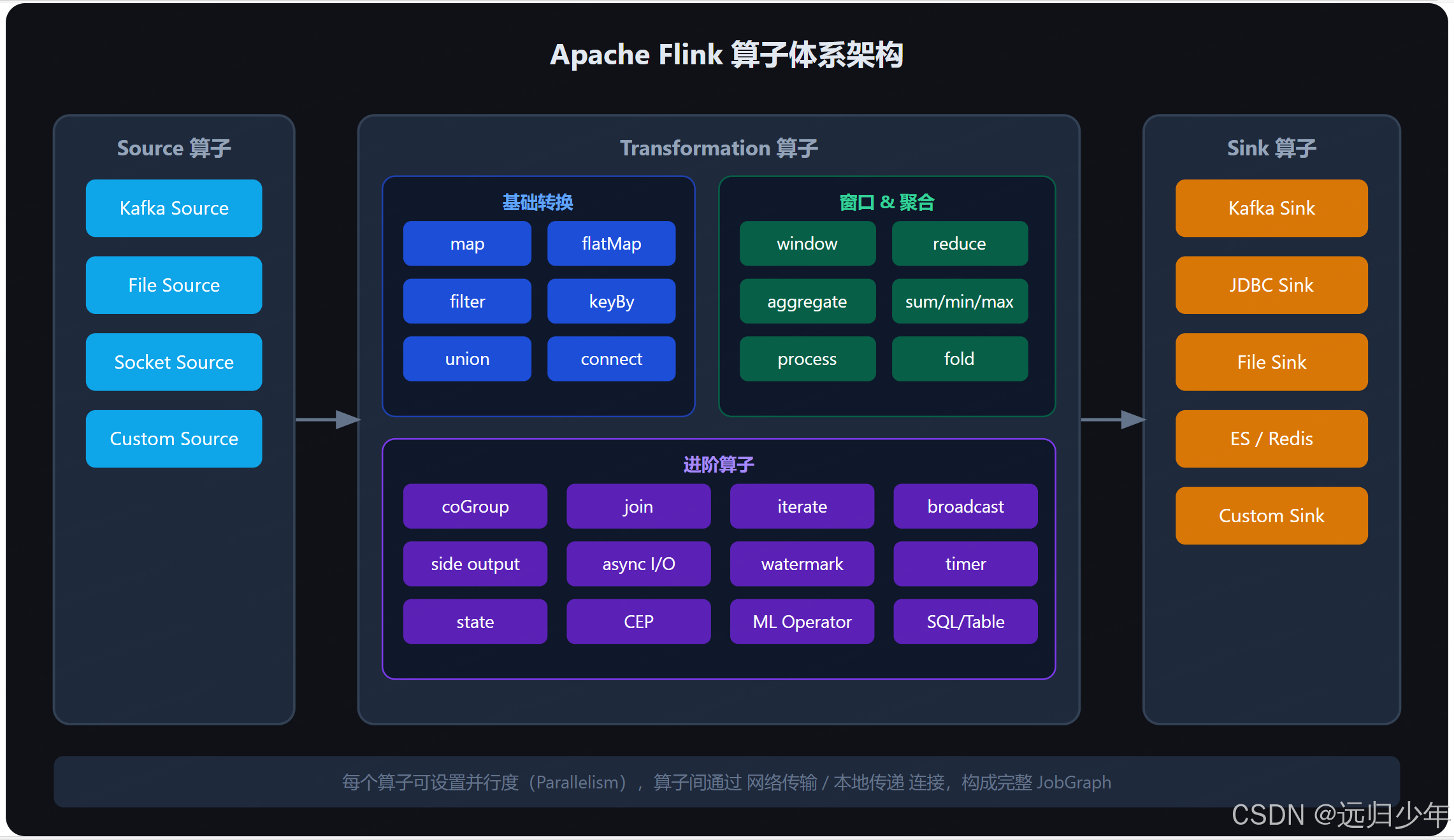
三、算子的核心概念
3.1 并行度(Parallelism)
每个算子可以独立设置并行度,Flink 会将算子实例化为多个 SubTask 并行执行。
java
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>(...))
.setParallelism(4); // Source 并行度 4
stream.map(s -> s.toUpperCase())
.setParallelism(8); // map 算子并行度 83.2 算子链(Operator Chain)
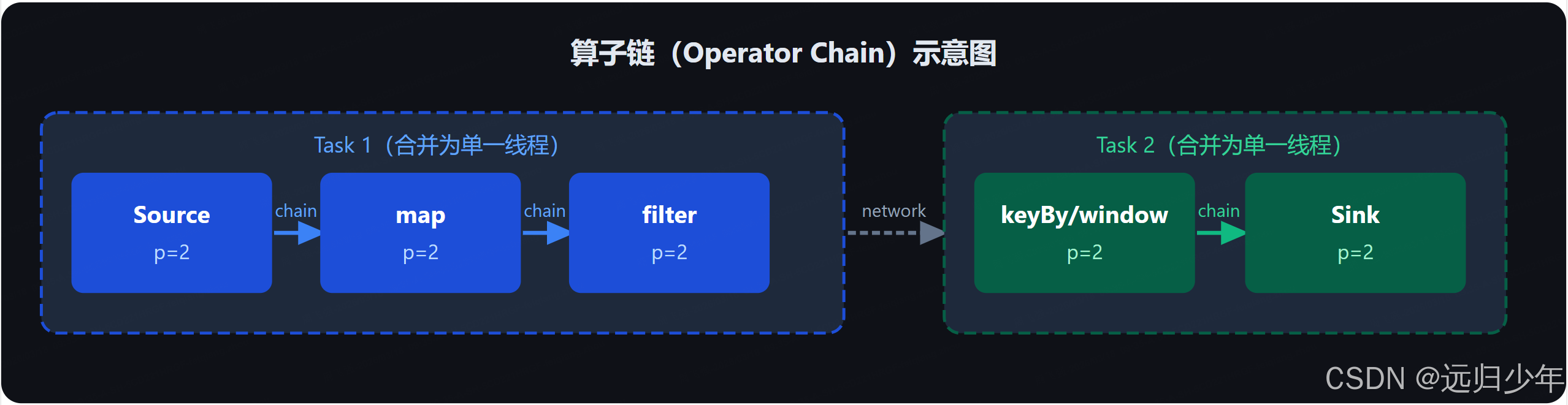
Flink 会将满足条件的相邻算子合并为一个 Task,减少线程切换和序列化开销:
- 两算子并行度相同
- 下游算子只有一个上游
- 分区策略为 Forward
四、基础转换算子详解
4.1 map
对流中每个元素做一对一转换,输入一个元素,输出一个元素。
java
DataStream<Integer> lengths = stream.map(s -> s.length());4.2 flatMap
输入一个元素,输出零个或多个元素(展平)。
java
DataStream<String> words = stream.flatMap((line, out) -> {
for (String word : line.split(" ")) out.collect(word);
});4.3 filter
按条件过滤元素,返回 true 则保留。
java
DataStream<String> filtered = stream.filter(s -> s.startsWith("ERROR"));4.4 keyBy
按 key 对流进行逻辑分区,相同 key 的元素进入同一 SubTask,是有状态计算的前提。
java
KeyedStream<Event, String> keyed = stream.keyBy(event -> event.userId);⚠️
keyBy不是算子,它产生的是KeyedStream,其后才能接reduce、aggregate、window等有状态算子。
五、窗口算子体系
窗口是 Flink 处理有界有序批次数据的核心机制,分为 Keyed Window 和 Non-Keyed Window 。

5.1 窗口函数(Window Function)
| 函数类型 | 特点 | 场景 |
|---|---|---|
ReduceFunction |
增量聚合,延迟低 | 实时求和、最大值 |
AggregateFunction |
增量聚合,更灵活 | 自定义累加器 |
ProcessWindowFunction |
全量访问窗口数据 | 复杂计算、TopN |
apply |
旧版全量 | 遗留代码兼容 |
java
// 增量聚合 + ProcessWindowFunction 组合(推荐)
stream.keyBy(r -> r.userId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new CountAgg(), new WindowResultFunction());六、状态算子(Stateful Operator)
状态是 Flink 的核心竞争力,算子可在处理过程中维护状态。

6.1 Keyed State 代码示例
java
public class CountFunction extends KeyedProcessFunction<String, Event, String> {
// 声明状态
private ValueState<Long> countState;
@Override
public void open(Configuration config) {
ValueStateDescriptor<Long> desc =
new ValueStateDescriptor<>("count", Long.class, 0L);
countState = getRuntimeContext().getState(desc);
}
@Override
public void processElement(Event event, Context ctx, Collector<String> out) throws Exception {
long count = countState.value() + 1;
countState.update(count);
// 注册定时器
ctx.timerService().registerEventTimeTimer(event.timestamp + 60_000L);
out.collect(event.userId + " -> count: " + count);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) {
out.collect("Timer fired at: " + timestamp);
countState.clear();
}
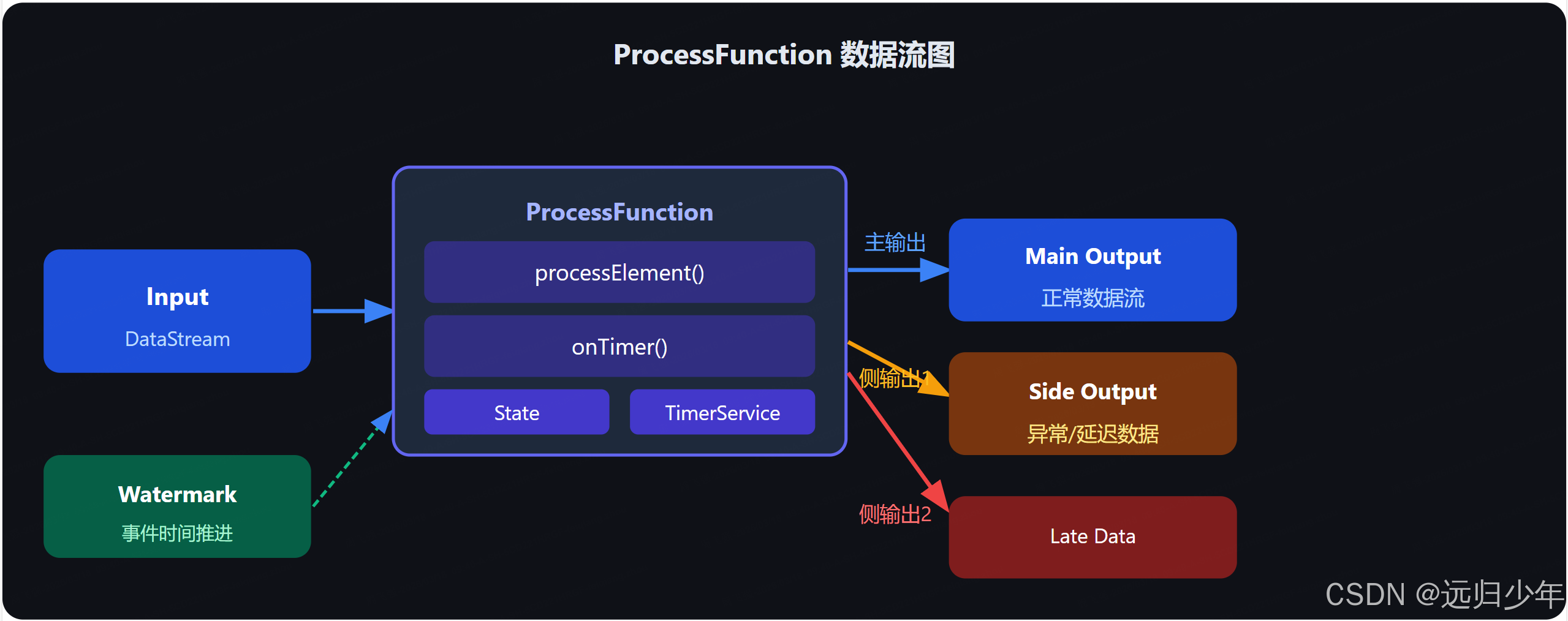
}七、ProcessFunction 进阶算子
ProcessFunction 是 Flink 最底层、最强大的算子,提供:
- 访问 事件时间 和 处理时间
- 注册 定时器(Timer)
- 输出到 侧输出流(Side Output)
- 访问 状态
八、双流算子(Two-Input Operators)
8.1 connect + CoProcessFunction
java
DataStream<String> stream1 = ...;
DataStream<Integer> stream2 = ...;
ConnectedStreams<String, Integer> connected = stream1.connect(stream2);
connected.process(new CoProcessFunction<String, Integer, String>() {
@Override
public void processElement1(String s, Context ctx, Collector<String> out) {
out.collect("Stream1: " + s);
}
@Override
public void processElement2(Integer i, Context ctx, Collector<String> out) {
out.collect("Stream2: " + i);
}
});8.2 Interval Join
两个 KeyedStream 按时间范围关联,是流式 Join 的核心。
java
orderStream.keyBy(o -> o.userId)
.intervalJoin(clickStream.keyBy(c -> c.userId))
.between(Time.minutes(-5), Time.minutes(0))
.process(new ProcessJoinFunction<Order, Click, Result>() {
@Override
public void processElement(Order order, Click click, Context ctx, Collector<Result> out) {
out.collect(new Result(order, click));
}
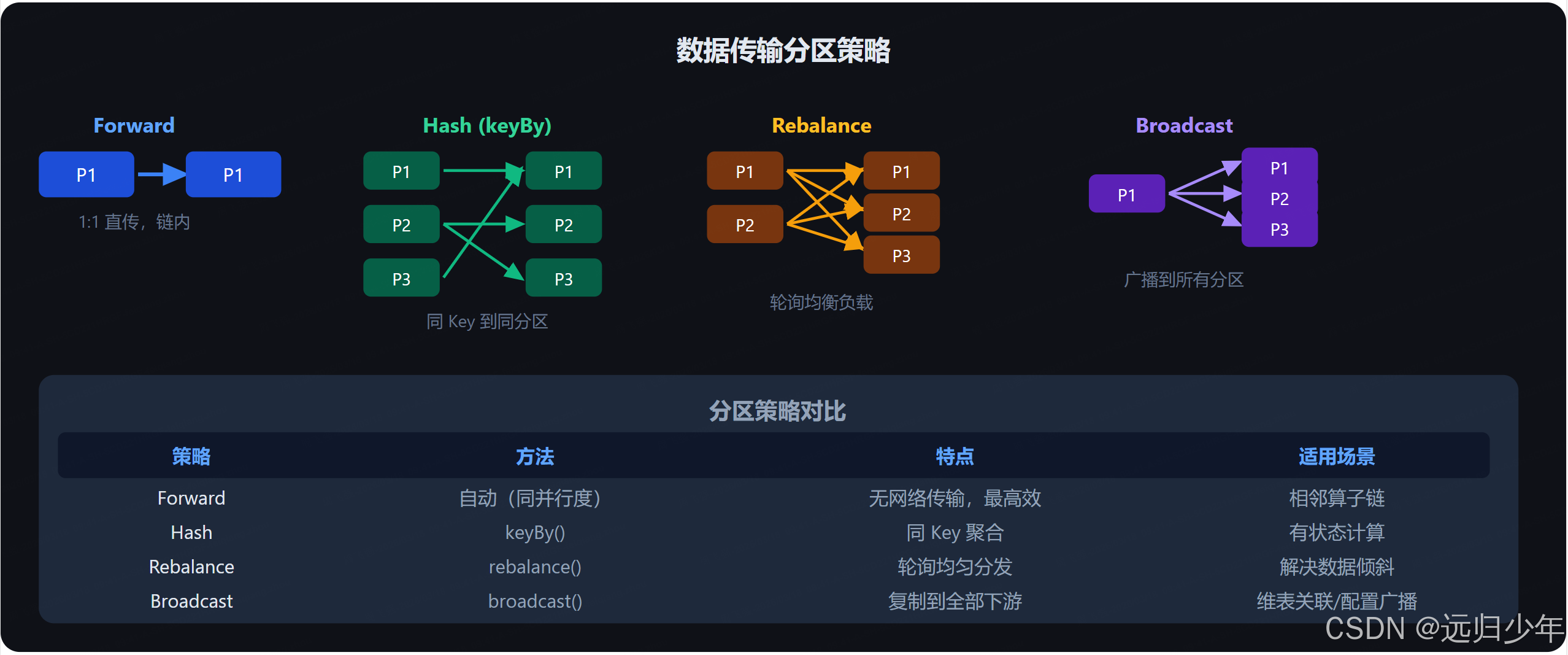
});九、算子数据传输策略
不同分区策略决定了上下游算子间的数据路由方式:
十、Async I/O 算子
在需要查询外部系统(Redis、HBase、HTTP API)时,Async I/O 可避免同步阻塞,大幅提升吞吐量。
java
DataStream<String> result = AsyncDataStream.unorderedWait(
inputStream,
new AsyncRedisFunction(), // 实现 AsyncFunction
1000, // timeout
TimeUnit.MILLISECONDS,
100 // 最大并发请求数
);十一、算子调优进阶指南
11.1 常见性能问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 数据倾斜 | keyBy 后某 key 数据量过大 | 二阶段聚合、局部聚合预处理 |
| 反压(Backpressure) | 下游处理速度跟不上上游 | 增加并行度、优化算子逻辑 |
| 状态过大 | State 无限增长 | 设置 TTL、使用 RocksDB |
| Checkpoint 超时 | 状态太大或 IO 慢 | 增量 Checkpoint、调大超时 |
| 内存溢出 | 窗口数据或状态堆积 | 调整 managed memory、增加 TM 内存 |
11.2 算子 TTL 配置
java
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(24))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot()
.build();
ValueStateDescriptor<Long> desc = new ValueStateDescriptor<>("count", Long.class);
desc.enableTimeToLive(ttlConfig);11.3 禁用算子链
java
// 全局禁用
env.disableOperatorChaining();
// 单个算子断链
stream.map(...)
.disableChaining()
.filter(...);
// 从当前算子开始新链
stream.map(...)
.startNewChain()
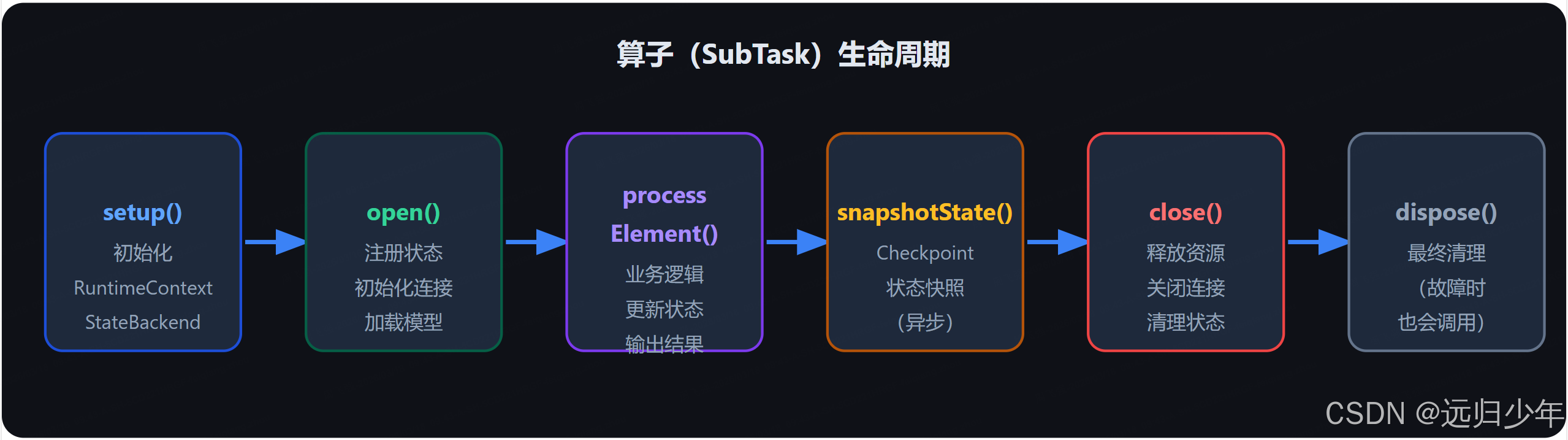
.filter(...);十二、算子生命周期
十三、总结与学习路线
基础入门
└── map / flatMap / filter / keyBy
└── window 窗口算子
└── reduce / aggregate / ProcessWindowFunction
└── ProcessFunction + State + Timer
└── CEP / Async I/O / Broadcast State
└── 算子调优 / 状态管理 / Checkpoint 原理核心记忆点
- 算子 = 计算节点,DataStream = 数据边
- keyBy 不是算子,是分区策略,其后才可有状态操作
- ProcessFunction 是最底层最强大的算子,涵盖状态、定时器、侧输出
- 窗口函数 优先选增量聚合 + ProcessWindowFunction 组合,兼顾效率和灵活性
- 算子链 减少序列化开销,但调试时可禁用
- 状态 TTL 防止状态无限增长是生产必备配置
- Async I/O 是访问外部系统的标准方案,避免同步阻塞
📌 参考资料:Apache Flink 官方文档