作业生命周期
作业生命周期(第一张) 是理解一切的起点。一个程序从 spark-submit 提交开始,经历七步:
提交 → Cluster Manager 分配资源 → Worker 启动 Executor → Executor 向 Driver 注册 → Driver 触发 Action 开始调度 → Executor 执行 Task → 结果返回 Driver。这七步走完,作业完成,Executor 被释放。
最重要的认知是:Driver 始终是大脑,Executor 只是无脑的执行者,它们完全听从 Driver 的调度。

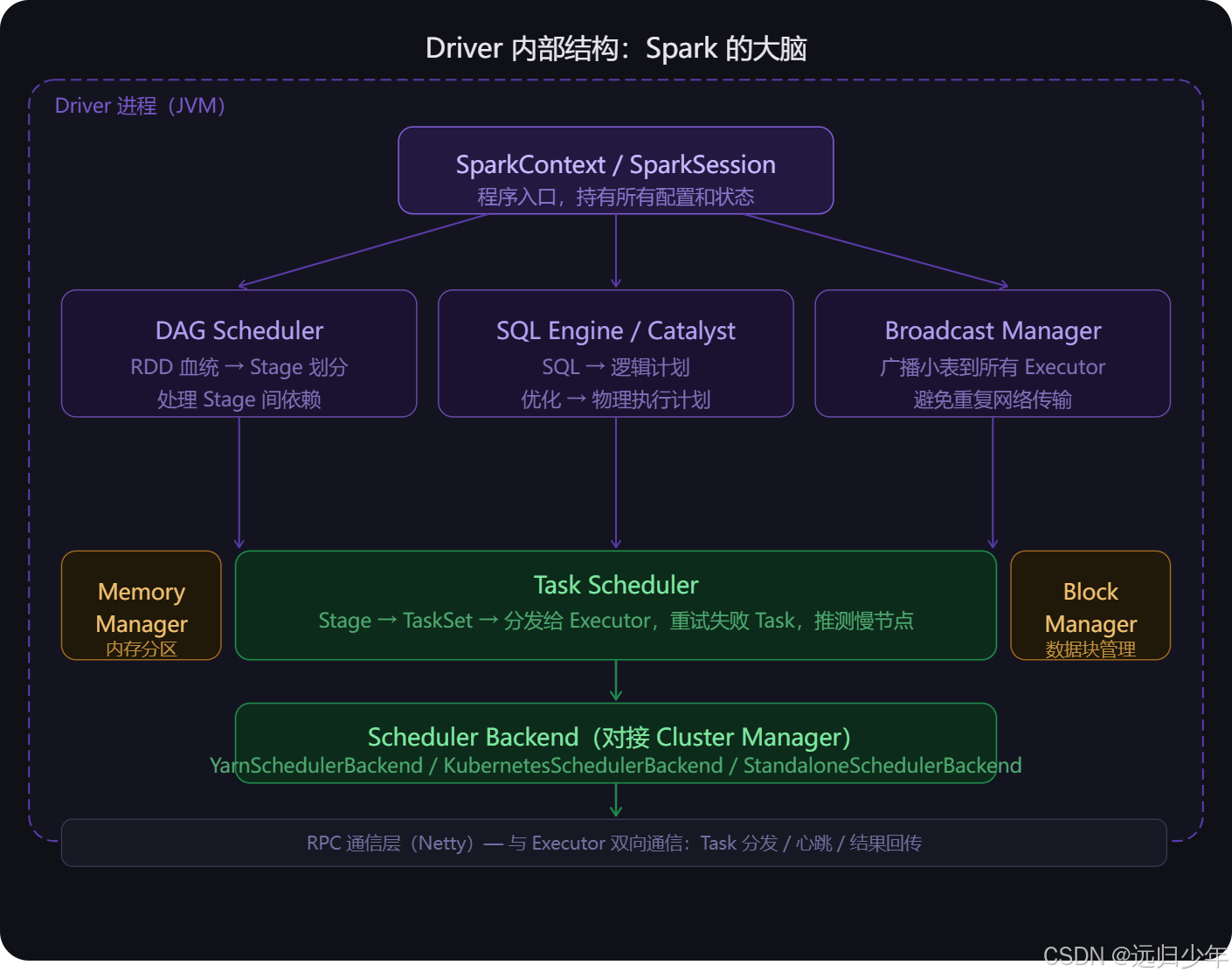
Driver 内部结构
Driver 内部结构(第二张) 拆解了"大脑"的各个部件。
- DAG Scheduler 负责把 RDD 血统转成 Stage 依赖关系,是逻辑层。
- Task Scheduler 负责把 Stage 拆成 Task 并通过 Scheduler Backend 发给 Executor,是物理层。
- SQL Engine / Catalyst 专门处理 DataFrame 和 SQL 的查询优化,在 Task 生成之前就把执行计划优化到最佳。
- Broadcast Manager 把小表一次性广播到所有 Executor 的内存,后续 join 时直接本地查询,避免 Shuffle。
- Memory Manager 和 Block Manager 则负责整个作业期间的内存分配和数据块追踪。
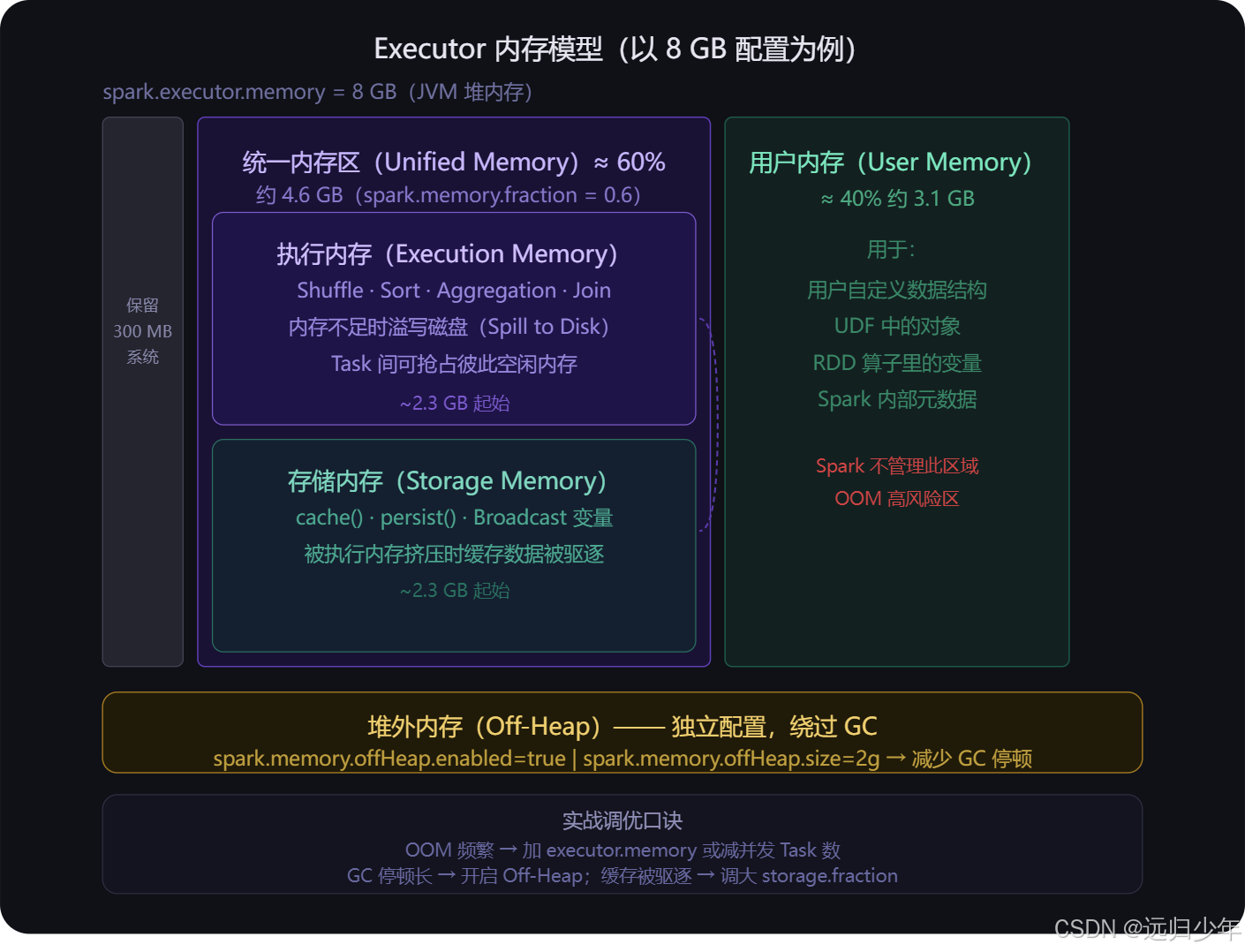
Executor 内存模型
Executor 内存模型(第三张) 是性能调优的地基,必须搞懂。
8GB 的 Executor 内存被划为三块:
- 300MB 系统保留;
- 剩余的 60%(约 4.6GB)是 统一内存区,由执行内存和存储内存动态共享,执行内存用于 Shuffle/Sort/Join,存储内存用于 cache() 和广播变量;
- 剩余的 40%(约 3.1GB)是用户内存,给你自己写的 UDF、RDD 算子里的 Python/Java 对象用,Spark 不管理这块,写出内存泄漏最容易在这里崩。
- 另外堆外内存(Off-Heap)是完全独立的,不受 JVM GC 管理,大状态计算时开启可以显著减少 GC 停顿。
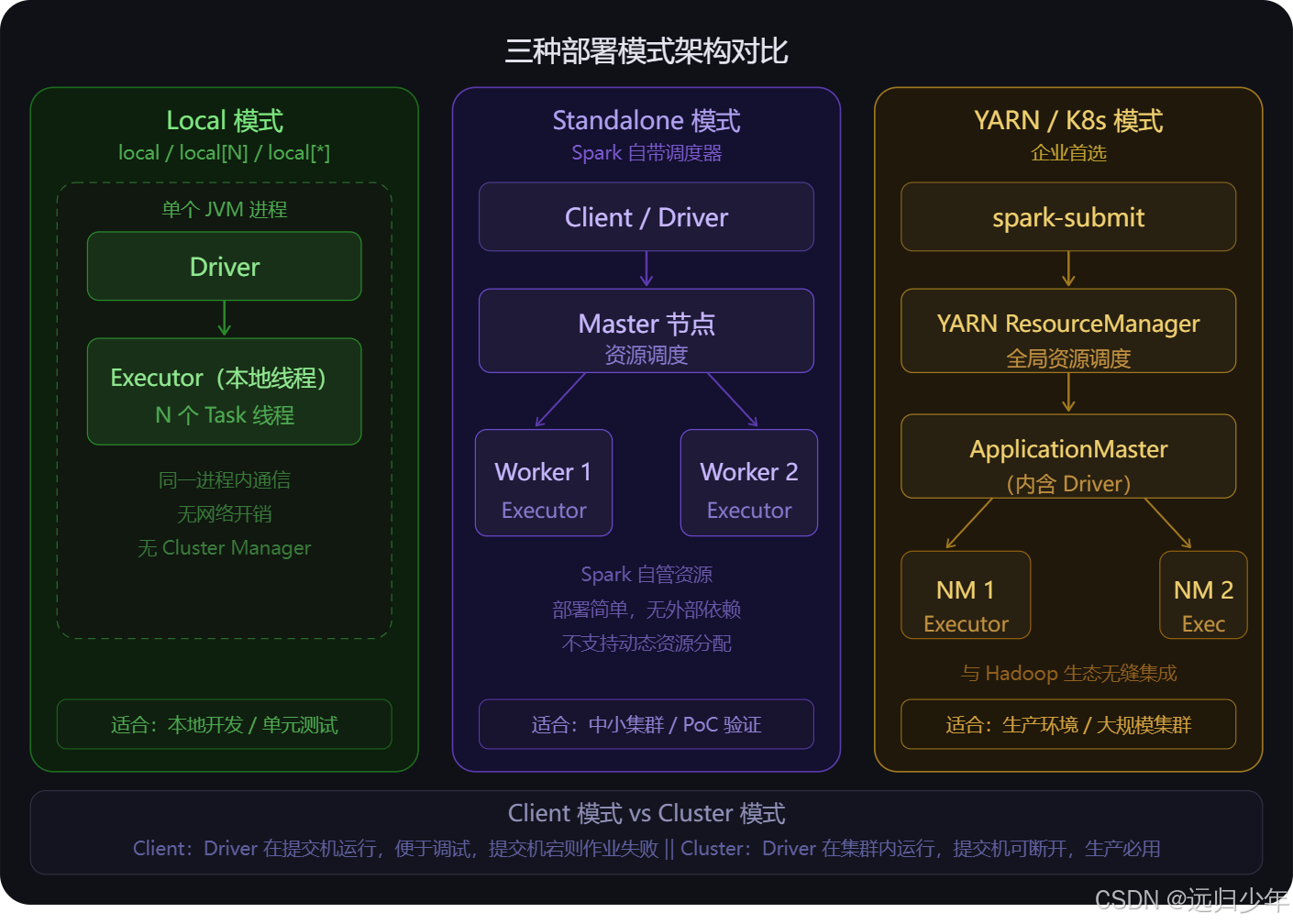
三种部署模式
三种部署模式(第四张) 的本质差异在于"Driver 在哪、谁管资源"。
- Local 模式一切在一个 JVM 进程里,没有网络开销,只用来本地开发。
- Standalone 是 Spark 自带的轻量调度器,适合快速搭建小集群。
- YARN/K8s 是企业生产环境的标配,YARN 与 Hadoop 生态深度整合,K8s 则更适合云原生环境。
注意: YARN/K8s 还有 client 和 cluster 两种提交模式的区别------cluster 模式下 Driver 运行在集群内部,提交机断开没关系,生产一律用 cluster 模式。
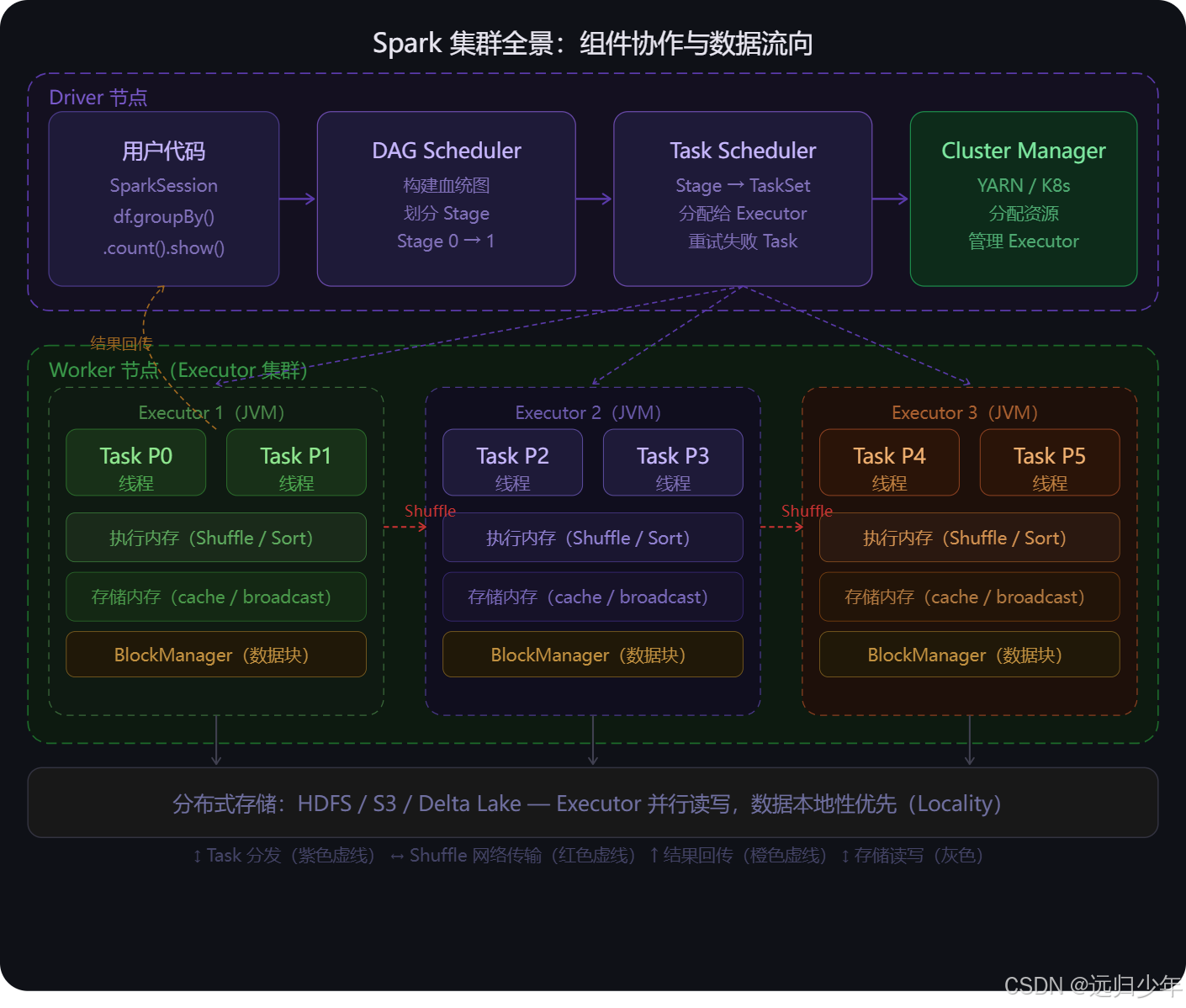
全景流向图
全景流向图(第五张) 把所有组件拼在一起。
- 数据流方向:
存储层(S3/HDFS)→ Executor 并行读入各自的 Partition → Task 线程处理 → Shuffle 数据在 Executor 间网络传输 → 最终结果回传 Driver。 - 调度流方向:
Driver Task Scheduler → 通过虚线分发 Task 给三个 Executor → Executor 执行后结果沿橙色虚线返回。
两个流向交叉运行,就是 Spark 一次作业的真实样子。