论文信息
论文标题: Lost in Stories: Consistency Bugs in Long Story Generation by LLMs
论文作者: Junjie Li, Xinrui Guo et al. - Microsoft, Beijing
论文链接: http://arxiv.org/abs/2603.05890
代码链接: https://picrew.github.io/constory-bench.github.io/
论文关键词: Long-form Story Generation, Narrative Consistency
研究背景与动机
- 长文本生成的挑战: 随着 LLMs 上下文窗口的扩大,模型生成的叙事内容可达数万字 。然而,模型在保持全局一致性(如追踪实体、事件、世界规则等)方面仍面临巨大挑战,往往只能做到局部流畅 。
- 现有评估的局限: 目前的基准测试主要关注情节质量和流畅度,缺乏对跨上下文矛盾的系统隔离和可重复的大规模评估机制 。
- 缺乏可解释性: 现有的"LLM-as-a-judge"协议通常缺乏明确的文本证据和可解释的依据 。
核心贡献
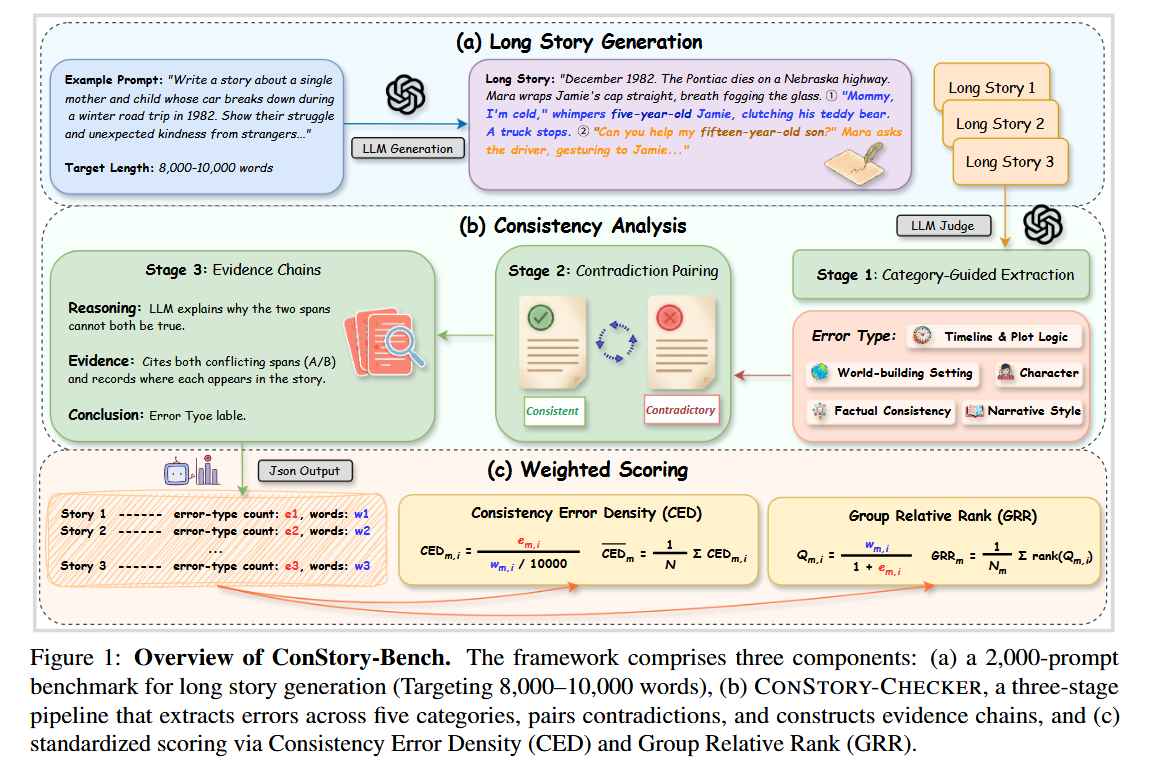
该研究提出了一个名为 ConStory-Bench 的基准测试框架,包含以下三个核心组件 :
- 大规模数据集: 包含 2,000 个提示词(Prompts),涵盖四种叙事任务场景(生成、续写、扩充、补完) 。
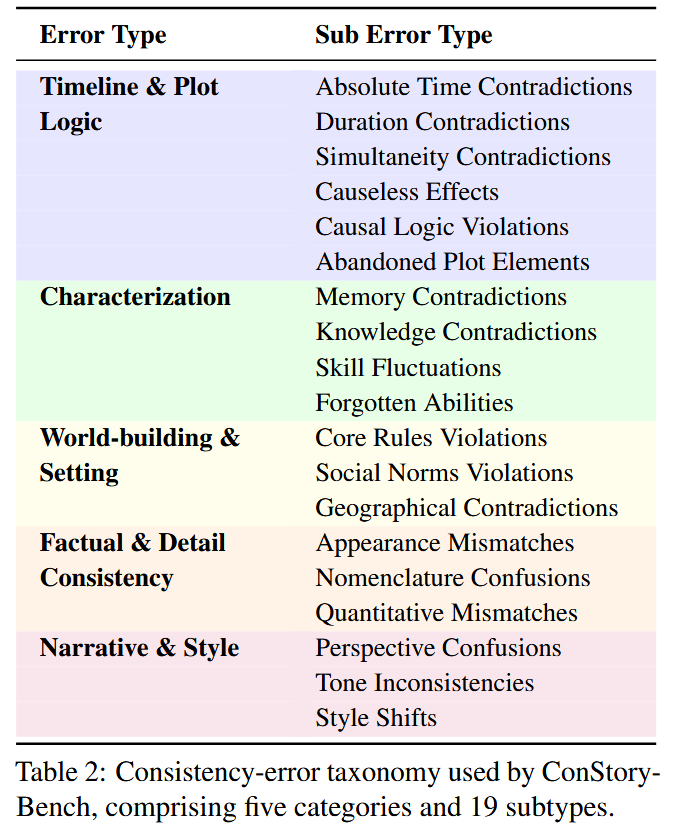
- 细粒度分类法: 定义了 5 个一级错误类别和 19 个细粒度子类型 。
- 自动化评估流水线 (CONSTORY-CHECKER): 一个四阶段的自动化流水线,能够检测矛盾并通过精确的文本引用提供证据链 。
一致性错误分类法
研究将一致性错误分为五大维度 :
- 时间线与情节逻辑: 如时间跨度冲突、因果逻辑违背、被遗忘的情节元素 。
- 人物塑造: 包括记忆矛盾(忘记之前的经历)、技能波动、能力丢失 。
- 世界观与设定: 涉及核心规则违背、社会规范违背、地理位置冲突 。
- 事实与细节一致性: 如外貌描述不匹配、名称混淆(角色名拼写变动)、数量矛盾 。
- 叙事与风格: 包括人称混淆(如从第一人称突变为第三人称)、语调不一致、风格漂移 。
CONSTORY-CHECKER 评估方法
该工具通过四个阶段实现自动化评估 :
- 阶段 1:分类引导提取。 利用特定类别的提示词扫描叙事,提取易错片段 。
- 阶段 2:矛盾配对。 将提取的片段进行两两对比,分类为"一致"或"矛盾" 。
- 阶段 3:证据链构建。 记录矛盾原因、引用原文位置并得出结论 。
- 阶段 4:JSON 报告生成。 输出标准化的结构化报告 。
下面是针对 TimeLine & Plot Logic Category 的评估,供参考:

探究发现
通过对多种闭源和开源模型(如 GPT-5, Gemini 2.5, Claude 4.5, Qwen 3, DeepSeek V3 等)的评估,得出以下结论 :
- 性能差异显著: GPT-5-REASONING 在一致性指标上表现最佳,其次是 Gemini-2.5-Pro 和 Claude-Sonnet-4.5 。
- 错误随长度线性增长: 随着生成长度增加,错误数量呈近似线性增长趋势 。
- 重灾区: 事实与细节一致性以及时间线与情节逻辑是最主要的失败模式 。
- 不确定性关联: 错误往往出现在模型Token 级别熵(Entropy)较高(即模型信心较低)的区域 。
- 位置分布: 矛盾点主要集中在叙事的中部(40%-60% 区域),而设定的"事实点"多出现在前部 。
- 任务难度: 自由生成任务(Generation)的一致性挑战最大,其错误密度(CED)通常高于有上下文约束的任务 。
文章局限性
- 文化单一性:目前仅限于英文小说,主要遵循西方叙事传统 。
- 判断二元化:将一致性建模为二元判断,可能误判一些故意的文学手法(如反转或延迟信息披露) 。
- 领域局限:主要聚焦于虚构文学,未涵盖技术文档或学术写作等长文本场景 。
- 文本长度较短:评测的生成文本长度不满足现实中网文的场景数十万字的需求。
- 缺乏对于长文本故事发展变化的适配,没有考虑的数十万字故事发展的一致性。故事是动态演进的,不是静态的,一致性是动态的。