文章目录
-
-
- 概念与指标
- 阶段一:单机架构与应用数据分离
- 阶段二:流量爆发引入应用集群与负载均衡
- 阶段三:打破数据瓶颈的读写分离与缓存机制
- 阶段四:垂直分库与微服务拆分
- [阶段五:Docker 容器化与 K8S 编排](#阶段五:Docker 容器化与 K8S 编排)
-
对于很多开发者而言,如果没有经历过中大型系统的实际开发,往往很难从全局视角理解技术架构的演变过程。本文将以一个"电子商务"应用(包含商品浏览、购物车、订单支付等核心业务)为例,带大家推演系统从百级并发到千万级并发情况下的服务端架构演进之路。在此过程中,我们会探讨每个阶段面临的瓶颈以及引入的相关技术,并最终揭示 Docker 和 Kubernetes(K8s)等云原生技术如何成为现代复杂架构的高效解药。
概念与指标
在深入架构演进之前,我们需要对一些核心术语建立共识:
- 系统(System)与组件(Component): 系统通常由多个相互配合的程序组成;为了分离职责,我们会将其拆分为不同的模块或组件(如支付组件、库存组件)。
- 分布式与集群(Cluster): 当这些模块被部署在不同的物理服务器上并通过网络通信时,就形成了分布式系统 ;而为了实现特定目标,将多台相同职责的服务器集中起来协同工作,则称为集群。
- 主(Master)与从(Slave): 在集群中,承担核心写入或控制职责的节点称为"主",负责附属职责(如读取同步、备份)的称为"从"。
- 中间件(Middleware): 连接不同应用程序、工具或数据库的桥梁(如消息队列、缓存中间件)。
衡量一个系统架构好坏有几个关键的评价指标:
- 可用性(Availability): 系统正常提供服务的期望概率,常说的"4个9"即 99.99% 的可用性(意味着每年宕机时间不超过 52.6 分钟)。
- 响应时长(RT - Response Time): 从用户完成输入到系统给出反馈的时长。
- 吞吐量(Throughput)与 并发(Concurrent): 吞吐量是单位时间内的成功处理量(如 TPS/QPS),并发是同一时刻系统支持的最高请求量。
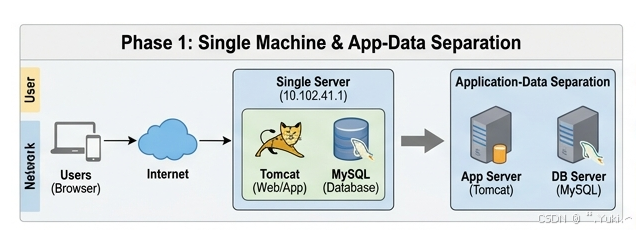
阶段一:单机架构与应用数据分离
项目初期,为了利用精干团队快速将业务推向市场并验证想法,单机架构是最合适的选择。此时,所有的鸡蛋都放在一个篮子里:Web 服务(如 Nginx/Tomcat)、应用程序代码、甚至是数据库(如 MySQL)全都挤在同一台物理机或云服务器上。
然而,随着第一批用户的到来,系统迎来了第一次大考。电商应用中的图片加载、动态页面渲染(消耗 CPU 和内存)与数据库的查询写入(消耗磁盘 I/O)开始互相抢占单台服务器的物理资源。一旦数据库执行一个复杂的查询,整个 Web 服务可能就会卡顿。
为了以最小代价提升承载力,系统演进为应用数据分离架构。此时,我们将数据库服务独立部署到数据中心的另一台高配置服务器上,应用服务通过局域网访问数据。这为系统争取了成倍的性能空间。
-
读取过程
- 用户在浏览器输入域名,DNS 解析为应用服务器的 IP。
- 请求到达应用服务器(Tomcat),应用代码发起 SQL 查询。
- 请求通过网络打到独立的数据库服务器,数据库从磁盘或内存中检索商品信息并返回给应用。
- 应用服务器拼接 HTML 或 JSON,返回给用户。
-
写入过程
- 用户提交注册表单,请求到达应用服务器。
- 应用服务器进行参数校验后,生成
INSERTSQL 语句,通过网络发送至数据库服务器。 - 数据库将新用户数据落盘,返回成功信号,应用服务器提示用户注册成功。
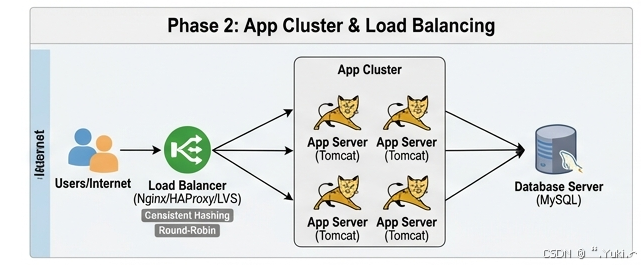
阶段二:流量爆发引入应用集群与负载均衡
当应用出现爆款(例如平台推出了秒杀活动),单台应用服务器的 CPU 和内存再次告急。此时面临两种扩展策略:纵向扩展(Scale Up,购买更昂贵的超级服务器) 和 横向扩展(Scale Out,增加普通服务器数量分担流量) 。由于单台硬件的性能增长存在物理上限,且成本呈指数级激增,横向扩展成为了必然选择,这就诞生了应用服务集群架构。
为了解决"海量用户流量究竟该分配给哪台应用服务器"的问题,系统引入了负载均衡组件(如 Nginx、HAProxy、LVS 等)。负载均衡器就像一个尽职的交通警察,根据特定的算法调度流量。
-
读取与写入的共性链路
- 用户的请求首先会打到负载均衡服务器(如 Nginx)。
- Nginx 根据配置的算法(如轮询 Round-Robin、加权轮询、或者基于客户端 IP 的哈希算法 Hash)计算出目标应用服务器(假设有 Server A, Server B, Server C)。
- Nginx 将请求转发给 Server B(假设被选中)。
- Server B 执行业务逻辑,并通过网络去读取或写入唯一的那个后台数据库。
- Server B 将结果返回给 Nginx,Nginx 再转交给用户。
应用层虽然可以无限横向增加机器,但所有成千上万的并发请求,最终都汇聚到了同一个单点数据库上。数据库的 I/O 瓶颈即将爆发。
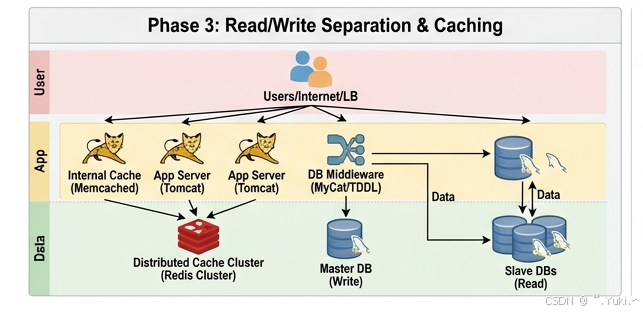
阶段三:打破数据瓶颈的读写分离与缓存机制
在电商场景中,经典的法则是"读多写少"(浏览商品的人数远远大于最终下单付款的人数,比例可能高达 10:1 甚至更高)。既然所有的应用服务器都在挤压单一数据库,我们架构演进的下一步就是读写分离(主从分离)。
设定一个主库(Master)负责所有写入操作,并配置多个从库(Slave)。主库的数据变更会通过 Binlog(二进制日志)实时或半实时地同步到从库,从库专门用来分担庞大的读取压力。同时,为了避免每次代码里都要写死"读哪个库、写哪个库",我们会引入 MyCat、ShardingSphere 等数据库中间件,让应用层像操作单机数据库一样无感操作主从集群。
进一步分析发现,系统中存在大量被频繁读取且极少变动的"热点数据"(如商品类目、首页推荐商品)。每次都去数据库查太慢了,于是我们引入了分布式缓存(如 Redis Cluster),把高频数据放在内存里。
-
读取过程
- 用户请求到达应用服务器。
- 应用首先查询 Redis 缓存中是否有该商品数据。
- 缓存命中(Cache Hit): 直接从 Redis 内存中拿到数据返回,耗时极短(毫秒级),不经过数据库。
- 缓存未命中(Cache Miss): 应用层通过数据库中间件,将查询请求路由到某个数据库从库(Slave)。
- 从库返回数据给应用,应用将数据写入 Redis 缓存以便下次使用,并返回给用户。
-
写入过程
- 用户请求到达应用层。
- 应用通过中间件将
UPDATE语句路由到数据库主库(Master) 执行。 - 主库完成写入,并将变更日志(Binlog)异步同步给所有从库(存在几十毫秒的延迟)。
- 为了保证数据一致性,应用在写入主库成功后,会删除或更新 Redis 中对应的旧缓存。
阶段四:垂直分库与微服务拆分
随着公司业务版图的扩张(加入金融、物流、直播等),数据量爆炸式增长。单个数据库即使做了主从分离,其磁盘容量和单表查询效率也达到了极限(例如单表数据上亿)。我们开始实施垂直分库 :根据业务领域,将原来的大一统数据库拆分为 "用户库"、"订单库"、"商品库"。
与此同时,技术团队规模可能已经达到了几百人。所有人都在同一个代码工程(单体架构)里提交代码,极其容易引发冲突,每次发布都需要停机几十分钟。微服务架构(Microservices) 应运而生。我们将庞大的系统拆分为一个个独立的、职责单一的微服务(用户服务、订单服务、支付服务),交由不同团队独立开发、独立部署。
为了让微服务之间能够顺畅沟通并对外提供统一入口,我们引入了 API Gateway(网关) ,并通过 Spring Cloud 或 Dubbo 等服务治理框架进行服务注册、发现和 RPC 调用。对于耗时较长、无需即时返回的业务(如支付成功后发短信),我们引入了 Kafka / RabbitMQ 等消息队列 进行异步解耦。
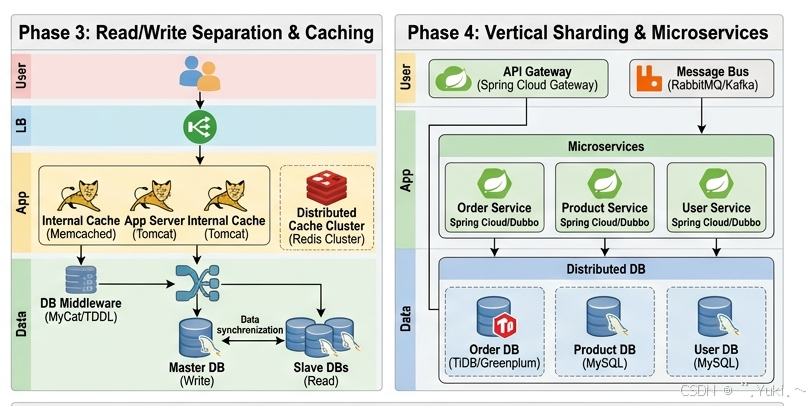
读写数据过程(以跨服务业务为例:用户下单):
- 入口分发: 用户的下单请求首先到达 API 网关 ,网关进行鉴权后,将请求路由给 "订单微服务"。
- 跨服务调用(读): 订单服务自身没有商品和库存信息,它通过 RPC(如 Dubbo/Feign)同步调用 "商品微服务" 查询商品是否存在,调用 "库存微服务" 检查库存是否充足(这些微服务会各自去查自己的 Redis 或专属从库)。
- 核心落盘(写): 检查通过后,订单微服务将订单数据写入自己专属的 "订单主库"。
- 异步解耦(写): 订单服务向 消息队列(MQ) 发送一条"订单已创建"的消息,然后立刻向用户返回"下单成功,请支付"。
- 后续消费: "库存微服务"和"积分微服务"在后台默默监听 MQ 里的消息,收到消息后,分别去扣减库存库的记录和增加用户库的积分。(最终一致性)
阶段五:Docker 容器化与 K8S 编排
微服务架构完美解决了组织协同和复杂业务解耦的问题,但却将巨大的压力转移给了运维团队 。
过去只需要部署一个 Tomcat 工程,现在需要部署几十上百个微服务。每个微服务对操作系统版本、JDK 版本、环境变量的要求都不一样(经典的"在我的电脑上明明能跑"问题)。同时,面对"双十一"这种脉冲式流量,靠人工去临时购买服务器、配环境、部署代码,根本来不及。
这就是 Docker 容器化技术 大显身手的时刻。Docker 将应用及其所有依赖环境(操作系统内核之上的所有东西)打包成一个轻量级的、标准化的镜像(Image)。无论在开发环境、测试环境还是生产环境,只要启动这个镜像,服务就能瞬间完美运行,彻底抹平了环境差异的痛点。
面对成千上万个 Docker 容器,我们需要一个极其高效的"大管家",这就是 Kubernetes(K8S)容器编排引擎。K8S 将底层物理服务器池化,它可以:
- 自动调度: 决定哪个容器运行在哪个物理节点上最合适。
- 自愈能力: 一旦某个支付服务的容器崩溃,K8S 会在几秒钟内在另一台机器上重新拉起一个新容器。
- 弹性伸缩(HPA): 当监控到 CPU 使用率飙升时,K8S 可以全自动地将订单服务的容器数量从 10 个扩容到 100 个,流量低谷时再自动缩容。
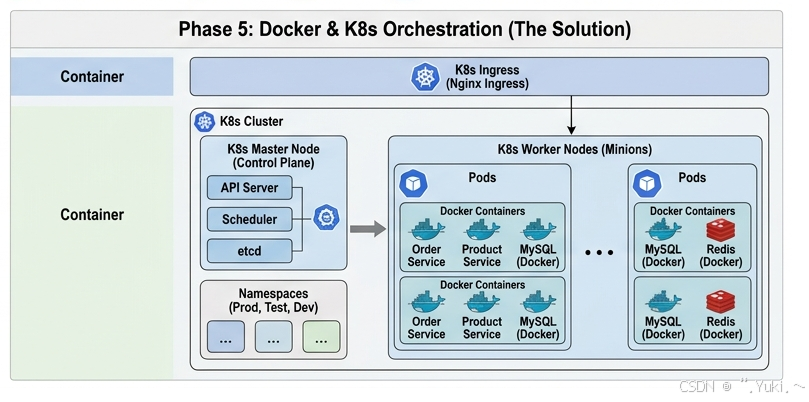
读写数据
在系统层面,业务的读写逻辑与阶段四类似,但底层网络与部署形态发生了根本改变:
- Ingress 接入: 外部流量首先打入 K8S 集群的 Ingress 控制器(充当集群总入口)。
- Service 发现与负载: 请求被转发到具体的 K8S Service(如
order-service)。Service 就像一个内部的负载均衡器,它知道当前有多少个健康的Pod(Docker 容器的载体)在运行。 - Pod 处理请求: 流量打入某个具体的 Docker 容器中。如果此时大促流量涌入导致该 Pod 的 CPU 飙升,K8S 的 HPA(水平 Pod 自动扩缩容)会迅速克隆出多个相同的 Pod 来分担流量。
- 持久化数据: 容器虽然是随时生灭的(无状态),但它们会通过网络连接到外部稳定的高可用数据库集群或云原生数据库中进行读写,保证业务数据永不丢失。