1.JDBC简介
JDBC(Java Data Base Connectivity,Java数据库连接)是Java程序和数据库之间的桥梁,包含 了⼀套Java定义的用于执行SQL语句的接口,使开发者能够编写数据库的程序。JDBC 的主要作用是: 与数据库建立连接、发送SQL语句和处理数据库执行结果。
访问数据库步骤
- 加载驱动
- 确认用户名、密码、url
- 创建Statement
- 执行SQL并接受返回的结果
- 关闭连接
2.JDBC配置
2.1建立连接
首先我们需要获取jar包,这里以oracle举例。将jar包复制到libs文件中,点击jar包右键,选择添加到库
2.2基础配置
注册驱动
java
//注册驱动,有三种方式,我比较习惯使用class.forname
Class.forName("oracle.jdbc.driver.OracleDriver");
//获取连接
Connection con = DriverManager.getConnection(
"jdbc:oracle:thin:@localhost:1521:XE",
"XIAOMING",
"123456"
);配置Statement
prepareStatement会先初始SQL,先把这个SQL提交到数据库中进行预处理,多次使用可提高效率;可以保证SQL安全问题,防止SQL注入,可以重复使用;createStatement不会初始化,没有预处理,只能在SQL中拼接参数,容易造成SQL注入,如果要删除多条数据,需要写多条SQL语句;
java
String sql = "select * from family_member where name";
Statement stat = con.createStatement();
ResultSet resultSet = stat.executeQuery(sql);
while(resultSet.next()){
System.out.println(resultSet.getString("name")
+"\t"
+resultSet.getString("gender")
);
}
java
String sql = "select * from family_member where name = ?";
PreparedStatement stat = con.prepareStatement(sql);
stat.setString(1,"爸爸");
ResultSet resultSet = stat.executeQuery();
while(resultSet.next()){
System.out.println(resultSet.getString("name")
+"\t"
+resultSet.getString("gender")
);
}释放资源
java
resultSet.close();
stat.close();
con.close();3.Spring实战 --手动构建DataSource
3.1配置类结构
整个配置类包含三部分:
- 数据源配置:连接信息 + 连接池参数
- Druid 监控 Servlet:提供可视化监控页面
- Druid Web 过滤器:统计 Web 请求与 SQL 的关联
3.2配置
数据源核心配置
java
@Bean
public DataSource dataSource() throws SQLException {
DruidDataSource ds = new DruidDataSource();
//基础连接信息
ds.setUrl("jdbc:oracle:thin:@localhost:1521:XE");
ds.setDriverClassName("oracle.jdbc.driver.OracleDriver");
ds.setUsername("XIAOMING");
ds.setPassword("123456");
//连接池大小控制
ds.setMinIdle(5); //最小连接数
ds.setMaxWait(60000); //获取连接的最大等待时间
ds.setMaxActive(20); //最多20个连接同时活跃
ds.setInitialSize(5); //5个初始连接
//空闲连接回收策略
ds.setMinEvictableIdleTimeMillis(60000); //最小回收等待时间
ds.setMaxEvictableIdleTimeMillis(900000); //最大回收等待时间
ds.setTimeBetweenEvictionRunsMillis(30000); //每30s检测一次
//连接检测
ds.setValidationQuery("SELECT 1 FROM DUAL"); //检测语句
ds.setTestWhileIdle(true); //空闲时检测
ds.setTestOnBorrow(false); //借出不检测
ds.setTestOnReturn(false); //还回不检测
//废弃处理
ds.setRemoveAbandoned( true); //自动回收泄露的连接
ds.setRemoveAbandonedTimeout(180); //设置3分钟未关闭为泄露
ds.setLogAbandoned(true); //回收时打印
//扩展功能
ds.setFilters("stat,wall"); //stat=SQL监控,wall=SQL防火墙
ds.setPoolPreparedStatements(true); //开启预先输入缓存
ds.setUseGlobalDataSourceStat( true); //启用全局数据源统计
return ds;
}注意 :setFilters("stat,wall") 中的 wall 是 Druid 的 SQL 防火墙,能防御 SQL 注入攻击,实际开发中很有用。
Druid监控页面Servlet
java
@Bean
public ServletRegistrationBean<StatViewServlet> statViewServlet() {
ServletRegistrationBean<StatViewServlet> servletReg =
new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
servletReg.addInitParameter("loginUsername", "admin"); // 监控页登录账号
servletReg.addInitParameter("loginPassword", "123456"); // 监控页登录密码
return servletReg;
}DruidWeb过滤器
这个过滤器的作用是将 HTTP 请求和执行的 SQL 语句关联起来,让你在监控页面能看到"哪个接口执行了什么 SQL,耗时多少"。
java
@Bean
public FilterRegistrationBean<WebStatFilter> webStatFilter() {
FilterRegistrationBean<WebStatFilter> filterReg = new FilterRegistrationBean<>();
filterReg.setFilter(new WebStatFilter());
filterReg.addUrlPatterns("/*");
filterReg.addInitParameter("exclusions", "*.js,*.css,/druid/*");
return filterReg;
}3.3验证配置
-
测试数据库连接和业务代码
java@GetMapping("/listAll") public Result listAll() { List<familyMember> listall= familyMemberService.listAll(); if(listall.size()>0){ return Result.ok(listall); }else{ return Result.fail("没有数据"); } }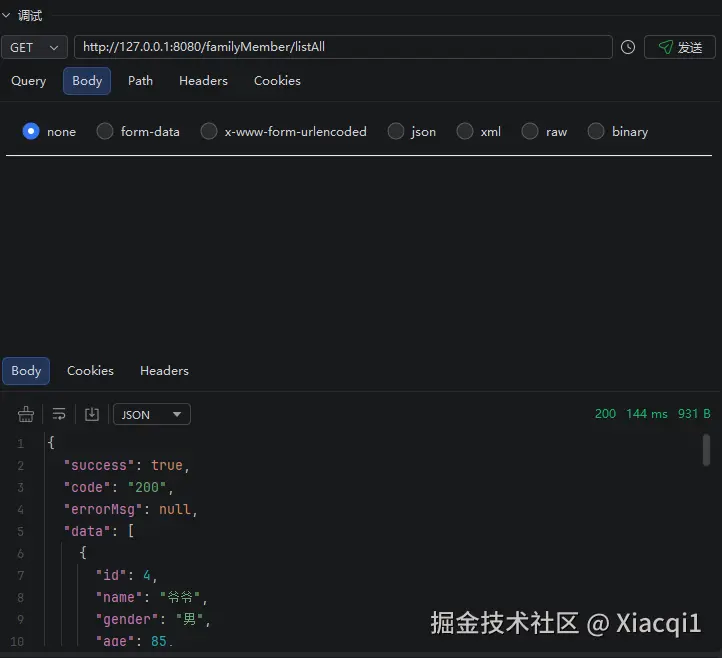
-
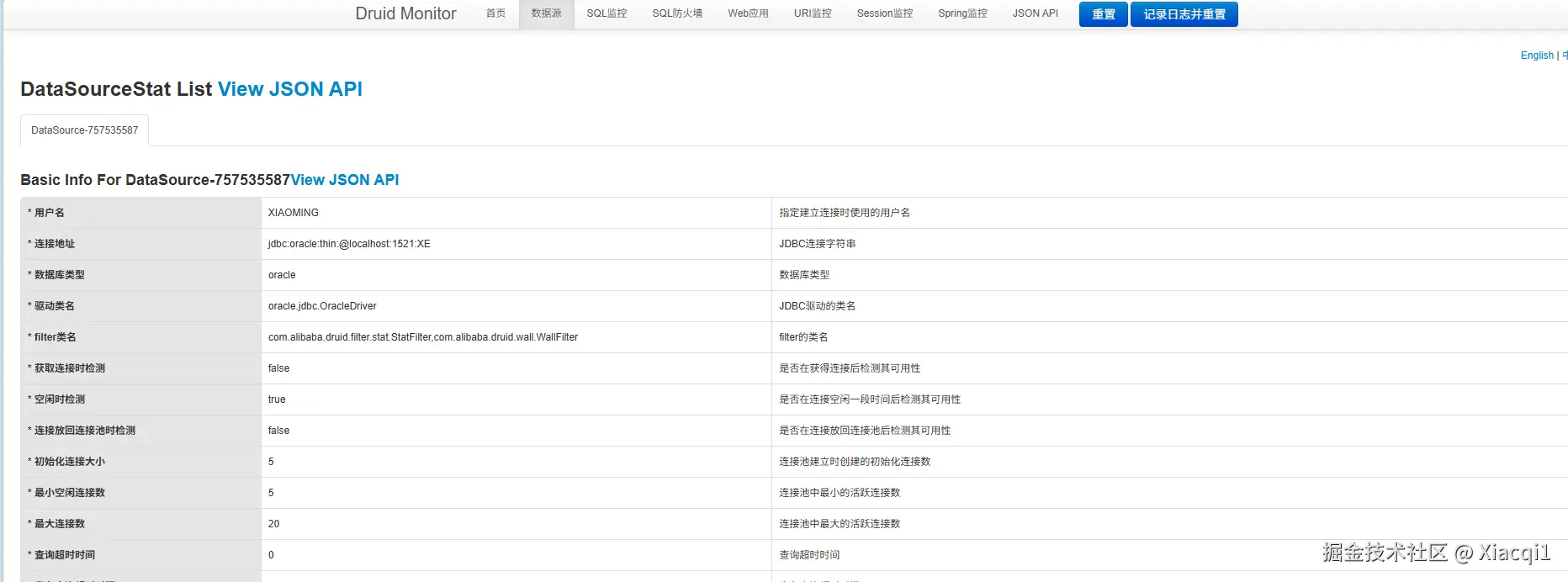
访问监控页面
http://localhost:8080/druid