tags: Redis, 数据结构, 底层实现
Redis数据结构
一、对外数据结构(存储数据类型)
Redis 为开发者提供了五种基本数据结构,每种结构都有特定的应用场景。
1.1 String(字符串)
描述:
- 最基本的数据类型,可以存储文本、数字或二进制数据。
- 最大容量为 512MB。
底层实现:
- 简单动态字符串(SDS,Simple Dynamic String)
- 支持预分配和惰性释放,减少内存重分配次数。
常用命令:
SET、GET、INCR、DECR、APPEND
应用场景:
- 缓存用户信息、会话
- 计数器(文章阅读量、点赞数)
- 分布式锁
1.2 List(列表)
描述:
- 有序的字符串列表,支持从两端插入和删除。
- 元素可以重复。
底层实现:
- Redis 3.2 之前:小数据用 ziplist,大数据用 linkedlist。
- Redis 3.2 之后:统一使用 quicklist(ziplist 组成的双向链表)。
- Redis 7.0 之后:quicklist 中的 ziplist 被 listpack 替换。
常用命令:
LPUSH、RPUSH、LPOP、RPOP、LRANGE
应用场景:
- 消息队列
- 最新文章列表
- 记录用户操作日志
1.3 Set(集合)
描述:
- 无序且唯一的字符串集合。
- 支持交集、并集、差集等集合运算。
底层实现:
- 小数据用 intset(整数集合),大数据用 hashtable。
常用命令:
SADD、SREM、SISMEMBER、SINTER、SUNION
应用场景:
- 标签系统
- 共同好友
- 抽奖去重
1.4 Zset(有序集合)
描述:
- 有序的字符串集合,每个元素关联一个分数(score)。
- 按分数排序,支持按分数范围查询。
底层实现:
- 小数据用 ziplist/listpack,大数据用 skiplist + hashtable。
- Redis 7.0 之后,小数据时用 listpack 代替 ziplist。
常用命令:
ZADD、ZREM、ZRANGE、ZREVRANGE、ZSCORE
应用场景:
- 排行榜
- 延时任务
- 带权重的消息队列
1.5 Hash(哈希)
描述:
- 键值对集合,类似对象属性。
- 支持字段级别的操作。
底层实现:
- 小数据用 ziplist/listpack,大数据用 hashtable。
常用命令:
HSET、HGET、HMSET、HMGET、HGETALL
应用场景:
- 存储对象(用户信息、商品信息)
- 购物车
二、底层数据结构
2.1 简单动态字符串(SDS)
特点:
- O(1) 获取长度:保存了字符串长度字段。
- 二进制安全 :可以存储任意二进制数据,包括
\0。 - 内存预分配:减少内存重分配次数。
- 惰性释放:缩短字符串时不立即释放内存,留作后续使用。
结构:
c
struct sdshdr {
int len; // 已使用长度
int free; // 未使用长度
char buf[]; // 字节数组
};2.2 压缩列表(ziplist) - 已弃用
概述:
- 早期用于 List、Hash、Zset 的小规模存储。
- 内存紧凑,适合存储少量小数据。
结构 :
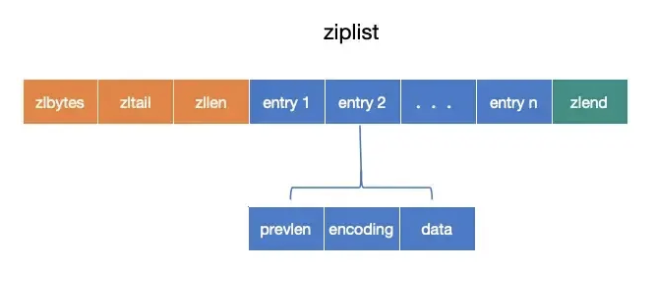
- zlbytes:4 字节,记录整个 ziplist 占用的字节数。
- zltail:4 字节,记录最后一个 entry 的偏移量。
- zllen:2 字节,记录 entry 数量。
- entry:不定长,存储具体数据。
- zlend:1 字节,结束标记(255)。
entry 结构:
- prevlen:前一个 entry 的长度(1 或 5 字节)。
- encoding:当前 entry 的类型和长度(1、2 或 5 字节)。
- data:实际数据。
问题:级联更新
- 如果某个 entry 长度从小于 254 变为大于等于 254,其下一个 entry 的 prevlen 需要从 1 字节扩展为 5 字节。
- 可能引发连锁反应,导致多个 entry 需要重新分配内存。
2.3 紧凑列表(listpack) - Redis 7.0 引入
概述:
- 替代 ziplist,解决级联更新问题。
- 设计更简单,编码更灵活。
结构 :
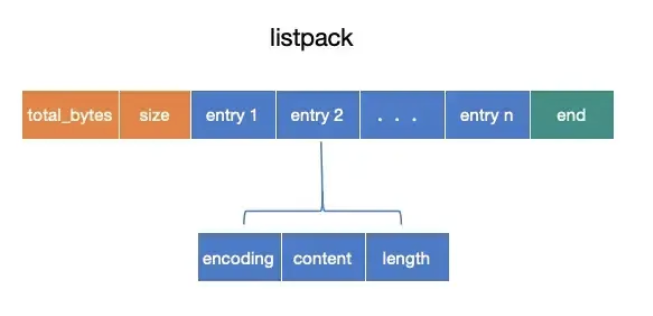
- total-bytes:整个 listpack 的字节数。
- num-elements:entry 数量。
- entry:包含 encoding、data、entry-len。
- entry-len:放在 entry 末尾,记录当前 entry 的总长度(变长编码)。
改进:
- 去掉了 prevlen 字段,改为在 entry 末尾记录自身长度。
- 反向遍历时,通过 entry-len 向前移动,避免了级联更新。
2.4 快速列表(quicklist)
概述:
- Redis 3.2 引入,List 的默认底层实现。
- 宏观上是双向链表,微观上是 ziplist/listpack 数组。
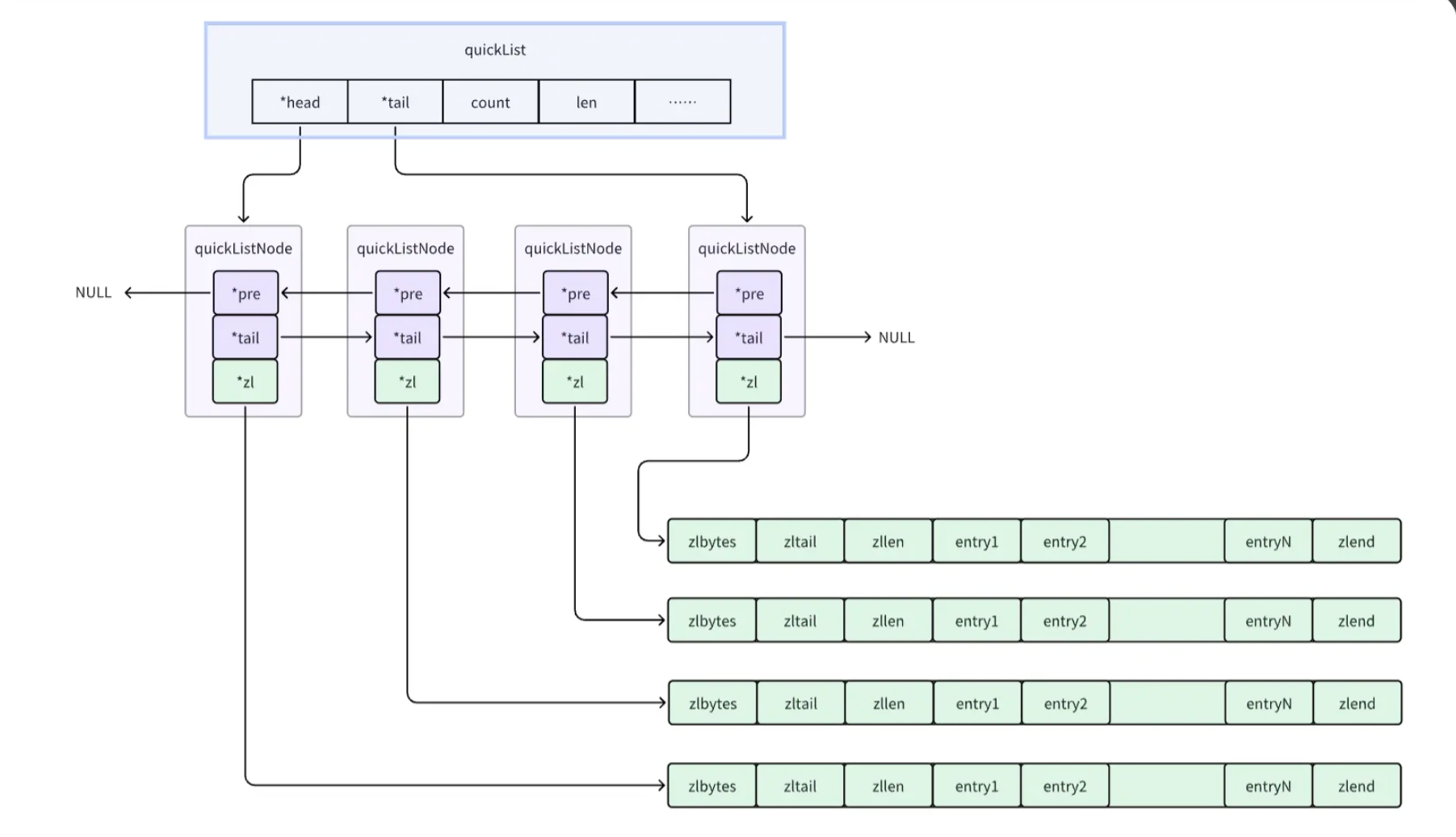
结构:
c
typedef struct quicklist {
quicklistNode *head; // 头节点
quicklistNode *tail; // 尾节点
unsigned long count; // 所有 ziplist 中 entry 总数
unsigned int len; // quicklist 节点数
int fill : 16; // 每个节点最大容量(由 list-max-ziplist-size 配置)
unsigned int compress : 16; // 压缩深度(由 list-compress-depth 配置)
} quicklist;节点结构:
c
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; // 指向 ziplist 或 listpack
unsigned int sz; // ziplist/listpack 占用的字节数
unsigned int count : 16; // entry 数量
unsigned int encoding : 2; // 编码方式:1-RAW, 2-LZF
unsigned int container : 2; // 容器类型:2-ziplist/listpack
unsigned int recompress : 1; // 是否需要重新压缩
} quicklistNode;优点:
- 平衡了内存使用和操作效率。
- 支持节点压缩,节省内存。
2.5 跳跃表(skiplist)
概述:
- 用于 Zset 的大数据存储。
- 有序数据结构,支持平均 O(log N) 的查找、插入、删除。
结构 :

- 多层链表结构,底层包含所有元素,上层是索引层。
- 每个节点包含:
- 元素值(member)
- 分数(score)
- 后退指针(backward)
- 层数组(level\[\]),每层包含前进指针和跨度。
插入过程:
- 随机生成节点层数(1-32),层数越高概率越低(p=0.25)。
- 从最高层开始查找插入位置。
- 在各层链表中插入节点。
优点:
- 支持范围查询。
- 比平衡树(如红黑树)实现简单,并发友好。
2.6 哈希表(hashtable)
概述:
- 用于实现 Set、Hash 以及全局键空间。
- 采用链地址法解决哈希冲突。
渐进式 rehash:
- Redis 使用两个哈希表(ht0 和 ht1),在扩容时逐步迁移数据。
- 每次对字典的增删改查操作时,迁移少量 bucket。
- 避免一次性 rehash 导致的阻塞。
三、数据结构选择与配置
3.1 配置参数
| 数据类型 | 配置项 | 含义 |
|---|---|---|
| List | list-max-ziplist-size |
quicklist 中每个节点的最大容量 |
| List | list-compress-depth |
节点压缩深度 |
| Hash | hash-max-ziplist-entries |
使用 ziplist/listpack 的最大 entry 数 |
| Hash | hash-max-ziplist-value |
使用 ziplist/listpack 时单个 value 的最大字节数 |
| Zset | zset-max-ziplist-entries |
使用 ziplist/listpack 的最大 entry 数 |
| Zset | zset-max-ziplist-value |
使用 ziplist/listpack 时单个 value 的最大字节数 |
| Set | set-max-intset-entries |
使用 intset 的最大元素数 |
3.2 性能考虑
- 小数据优化:多数数据类型在小数据时使用紧凑结构(ziplist/listpack、intset),节省内存。
- 大数据切换:超过阈值后切换为标准结构(hashtable、skiplist、linkedlist),保证操作效率。
- 内存 vs 性能:根据业务特点调整配置参数,平衡内存使用和操作性能。
四、总结
- 对外数据结构:String、List、Set、Zset、Hash,满足不同业务需求。
- 底层实现:SDS、ziplist、listpack、quicklist、skiplist、hashtable,针对不同场景优化。
- 配置调优:通过配置文件参数,优化内存使用和性能。
- 版本演进:Redis 7.0 用 listpack 替代 ziplist,解决级联更新问题。